Implications of NVM Based Storage on Memory Subsystem Management



Abstract
:Featured Application
Abstract
1. Introduction
- Q1.
- What will be the potential benefit in the memory-storage hierarchy of a desktop PC if we adopt fast NVM storage?
- Q2.
- Is the buffer cache still necessary for NVM based storage?
- Q3.
- Is prefetching still effective for NVM based storage?
- Q4.
- Is the performance effect of I/O modes (i.e., synchronous I/O, buffered I/O, and direct I/O) similar to HDD storage cases?
- Q5.
- What is the impact of concurrent storage accesses on the performance of NVM based storage?
- We can decrease the main memory size without performance penalties when NVM storage is adopted instead of HDD.
- Buffer caching is still effective in fast NVM storage but some judicious management techniques like admission control are necessary.
- Prefetching is not effective in NVM storage.
- The effect of synchronous I/O and direct I/O in NVM storage is less significant than that in HDD storage.
- Performance degradation due to the contention of multi-threads is less severe in NVM based storage than in HDD. This implies that NVM can constitute a contention-tolerable storage system for applications with highly concurrent storage accesses.
2. PCM and STT-MRAM Technologies
3. Performance Implication of NVM Based Storage
3.1. Effect of the Memory Size
3.2. Effectiveness of Buffer Cache
3.3. Effects of Prefetching
3.4. Effects of Concurrent Accesses
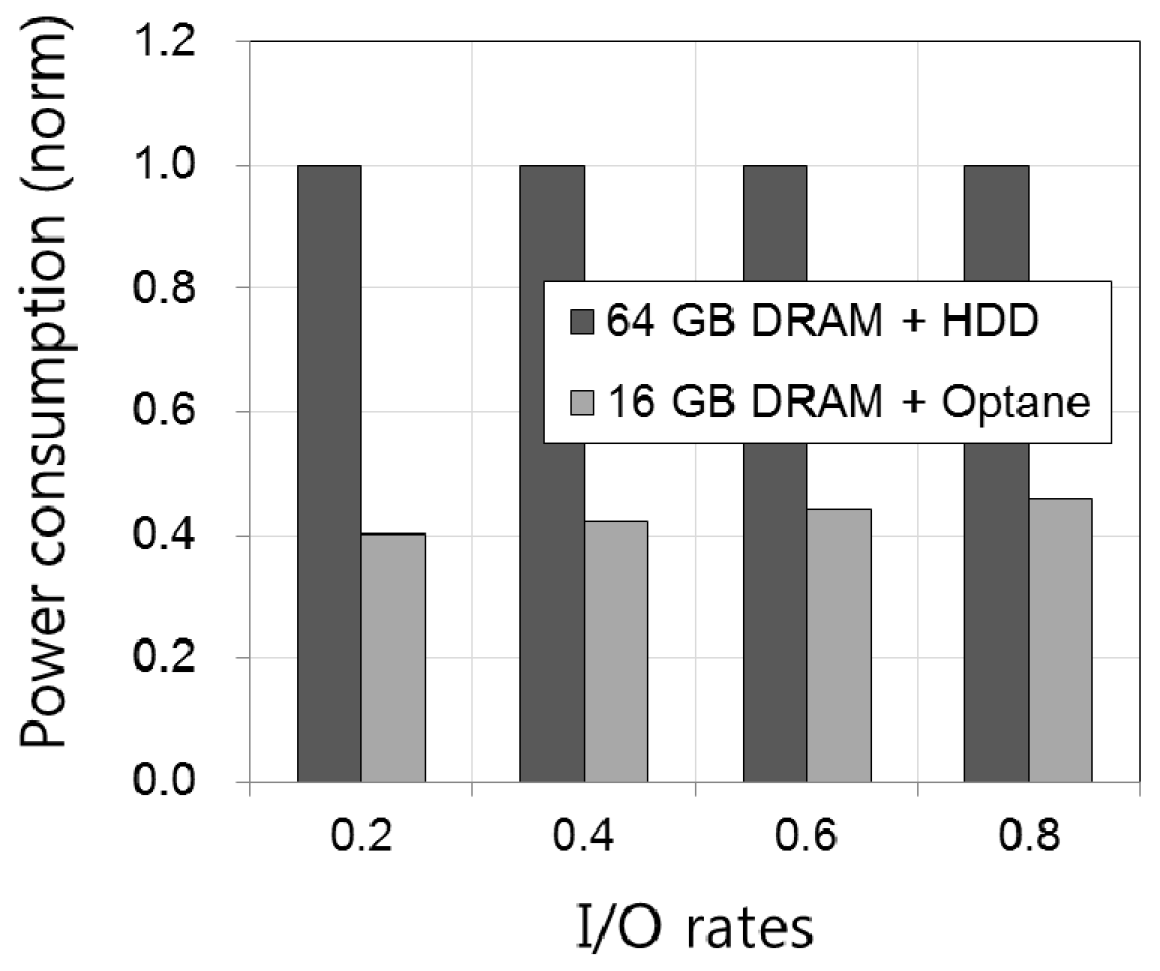
3.5. Implications of Alternative PC Configurations
- PDRAM_static = Unit_static_power (W/GB) × Memory_size (GB) and,
- PDRAM_active = Read_energyDRAM (J) × Read_freqDRAM (/s) + Write_energyDRAM (J) × Write_freqDRAM (/s).
- PNVM_idle = Idle_rateNVM × Idle_powerNVM (W) and,
- PNVM_active = Read_energyNVM (J) × Read_freqNVM (/s) + Write_energyNVM (J) × Write_freqNVM (/s).
- PHDD_idle = Idle_rateHDD × Idle_powerHDD (W),
- PHDD_active = Active_rateHDD × Active_powerHDD (W), and
- PHDD_standby = Transition_freqHDD (/s) × (Spin_down_energyHDD (J) + Spin_up_energyHDD (J)).
4. Related Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ng, S. Advances in disk technology: Performance issues. Computer 1998, 31, 75–81. [Google Scholar] [CrossRef]
- Evans, C. Flash vs 3D Xpoint vs storage-class memory: Which ones go where? Comput. Wkly. 2018, 3, 23–26. [Google Scholar]
- Stanisavljevic, M.; Pozidis, H.; Athmanathan, A.; Papandreou, N.; Mittelholzer, T.; Eleftheriou, E. Demonstration of Reliable Triple-Level-Cell (TLC) Phase-Change Memory. In Proceedings of the of the 8th IEEE International Memory Workshop, Paris, France, 15–18 May 2016; pp. 1–4. [Google Scholar]
- Zhang, W.; Li, T. Exploring phase change memory and 3D die-stacking for power/thermal friendly, fast and durable memory architectures. In Proceedings of the of the 18th IEEE International Conference on Parallel Architectures and Compilation Techniques (PACT), Raleigh, NC, USA, 12–16 September 2009; pp. 101–112. [Google Scholar]
- Lee, E.; Jang, J.; Kim, T.; Bahn, H. On-demand Snapshot: An Efficient Versioning File System for Phase-Change Memory. IEEE Tran. Knowl. Data Eng. 2012, 25, 2841–2853. [Google Scholar] [CrossRef]
- Qureshi, M.K.; Srinivasan, V.; Rivers, J.A. Scalable high performance main memory system using phase-change memory technology. In Proceedings of the 36th International Symposium on Computer Architecture (ISCA), Austin, TX, USA, 20–24 June 2009; pp. 24–33. [Google Scholar]
- Nale, B.; Ramanujan, R.; Swaminathan, M.; Thomas, T. Memory Channel that Supports near Memory and Far Memory Access; PCT/US2011/054421; Intel Corporation: Santa Clara, CA, USA, 2013. [Google Scholar]
- Ramanujan, R.K.; Agarwal, R.; Hinton, G.J. Apparatus and Method for Implementing a Multi-level Memory Hierarchy Having Different Operating Modes; US 20130268728 A1; Intel Corporation: Santa Clara, CA, USA, 2013. [Google Scholar]
- Eilert, S.; Leinwander, M.; Crisenza, G. Phase Change Memory: A new memory technology to enable new memory usage models. In Proceedings of the 1st IEEE International Memory Workshop (IMW), Monterey, CA, USA, 10–14 May 2009; pp. 1–2. [Google Scholar]
- Lee, E.; Yoo, S.; Bahn, H. Design and implementation of a journaling file system for phase-change memory. IEEE Trans. Comput. 2015, 64, 1349–1360. [Google Scholar] [CrossRef]
- Lee, E.; Kim, J.; Bahn, H.; Lee, S.; Noh, S. Reducing Write Amplification of Flash Storage through Cooperative Data Management with NVM. ACM Trans. Storage 2017, 13, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Lee, E.; Bahn, H.; Yoo, S.; Noh, S.H. Empirical study of NVM storage: An operating system’s perspective and implications. In Proceedings of the IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, Paris, France, 9–11 September 2014; pp. 405–410. [Google Scholar]
- Lee, S.; Bahn, H.; Noh, S.H. CLOCK-DWF: A write-history-aware page replacement algorithm for hybrid PCM and DRAM memory architectures. IEEE Trans. Comput. 2014, 63, 2187–2200. [Google Scholar] [CrossRef]
- Kwon, O.; Koh, K.; Lee, J.; Bahn, H. FeGC: An Efficient Garbage Collection Scheme for Flash Memory Based Storage Systems. J. Syst. Softw. 2011, 84, 1507–1523. [Google Scholar] [CrossRef]
- Weis, N.; Wehn, L.; Igor, I.; Benini, L. Design space exploration for 3d-stacked drams. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, Grenoble, France, 14–18 March 2011; pp. 1–6. [Google Scholar]
- Elliot, J.; Jung, E.S. Ushering in the 3D Memory Era with V-NAND. In Proceedings of the Flash Memory Summit, Santa Clara, CA, USA, 12–15 August 2013. [Google Scholar]
- Wright, C.D.; Aziz, M.M.; Armand, M.; Senkader, S.; Yu, W. Can We Reach Tbit/sq.in. Storage Densities with Phase-Change Media? In Proceedings of the European Phase Change and Ovonics Symposium (EPCOS), Grenoble, France, 29–31 May 2006. [Google Scholar]
- Bedeschi, F.; Fackenthal, R.; Resta, C.; Donz, E.M.; Jagasivamani, M.; Buda, E.; Pellizzer, F.; Chow, D.W.; Cabrini, A.; Calvi, G.M.A.; et al. A multi-level-cell bipolar-selected phase-change memory. In Proceedings of the 2008 IEEE International Solid-State Circuits Conference-Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 3–7 February 2008. [Google Scholar]
- Zhang, Y.; Wen, W.; Chen, Y. STT-RAM Cell Design Considering MTJ Asymmetric Switching. SPIN 2012, 2, 1240007. [Google Scholar] [CrossRef]
- Kultursay, E.; Kandemir, M.; Sivasubramaniam, A.; Mutlu, O. Evaluating STT-RAM as an Energy-Efficient Main Memory Alternative. In Proceedings of the IEEE International Symposium Performance Analysis of Systems and Software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 256–267. [Google Scholar]
- Lee, B.C.; Ipek, E.; Mutlu, O.; Burger, D. Architecting phase change memory as a scalable DRAM alternative. In Proceedings of the 36th ACM/IEEE International Symposium on Computer Architecture (ISCA), Austin, TX, USA, 20–24 June 2009. [Google Scholar]
- PCMSim. Available online: http://code.google.com/p/pcmsim (accessed on 18 January 2020).
- Norcutt, W. IOzone Filesystem Benchmark. Available online: http://www.iozone.org/ (accessed on 1 October 2019).
- Tarasov, V.; Hildebrand, D.; Kuenning, G.; Zadok, E. Virtual Machine Workloads: The Case for New NAS Benchmarks. In Proceedings of the 11th USENIX Conference on File and Storage Technologies (FAST), 12–15 February 2013; pp. 307–320. [Google Scholar]
- Lee, K.; Won, Y. Smart layers and dumb result: IO characterization of an Android-based smartphone. In Proceedings of the International Conference on Embedded Software (EMSOFT), Tampere, Finland, 7–12 October 2012; pp. 23–32. [Google Scholar]
- Stonebraker, M.; Madden, S.; Abadi, D. The End of an Architectural Era (It’s Time for a Complete Rewrite). In Proceedings of the 33rd Very Large Data Bases Conference (VLDB), Viena, Austria, 23–27 September 2007. [Google Scholar]
- Intel® SSD Client Family. Available online: https://www.intel.com/content/www/us/en/products/memory-storage/solid-state-drives/consumer-ssds.html (accessed on 18 January 2020).
- Mogul, J.C.; Argollo, E.; Shah, M.; Faraboschi, P. Operating system support for NVM+DRAM hybrid main memory. In Proceedings of the 12th USENIX Workshop on Hot Topics in Operating Systems (HotOS), Monte Verita, Switzerland, 18–20 May 2009; pp. 4–14. [Google Scholar]
- Lee, B.C.; Ipek, E.; Mutlu, O.; Burger, D. Phase change memory architecture and the quest for scalability. Commun. ACM 2010, 53, 99–106. [Google Scholar] [CrossRef]
- Condit, J.; Nightingale, E.B.; Frost, C.; Ipek, E.; Lee, B.; Burger, D.; Coetzee, D. Better I/O through byte-addressable, persistent memory. In Proceedings of the ACM Symposium on Operating Systems Principles (SOSP), Big Sky, MT, USA, 11–14 October 2009; pp. 133–146. [Google Scholar]
- Wu, X.; Reddy, A.L.N. SCMFS: A File System for Storage Class Memory. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seattle, WA, USA, 12–18 November 2011. [Google Scholar]
- Baek, S.; Hyun, C.; Choi, J.; Lee, D.; Noh, S.H. Design and analysis of a space conscious nonvolatile-RAM file system. In Proceedings of the IEEE Region 10 Confe4rence (TENCON), Hong Kong, China, 14–17 November 2006. [Google Scholar]
- Edel, N.K.; Tuteja, D.; Miller, E.L.; Brandt, S.A. MRAMFS: A compressing file system for non-volatile RAM. In Proceedings of the 12th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Volendam, The Netherlands, 4–8 October 2004; pp. 569–603. [Google Scholar]
- PRAMFS. Available online: http://pramfs.sourceforge.net (accessed on 1 October 2019).
- Baek, S.; Sun, K.; Choi, J.; Kim, E.; Lee, D.; Noh, S.H. Taking advantage of storage class memory technology through system software support. In Proceedings of the Workshop on Interaction between Operating Systems and Computer Architecture (WIOSCA), Beijing, China, June 2009. [Google Scholar]
- Coburn, J.; Caufield, A.; Akel, A.; Grupp, L.; Gupta, R.; Swanson, S. NV-Heaps: Making persistent objects fast and safe with next-generation, non-volatile memories. In Proceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Newport Beach, CA, USA, 5–11 March 2011; pp. 105–118. [Google Scholar]
- Volos, H.; Tack, A.J.; Swift, M.M. Mnemosyne: Lightweight persistent memory. In Proceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Newport Beach, CA, USA, 5–11 March 2011; pp. 91–104. [Google Scholar]
- Yang, J.; Minturn, D.B.; Hady, F. When poll is better than interrupt. In Proceedings of the USENIX Conference File and Storage Technologies (FAST), San Jose, CA, USA, 14–17 February 2012. [Google Scholar]
- Caulfield, A.M.; De, A.; Coburn, J.; Mollov, T.I.; Gupta, R.K.; Swanson, S. Moneta: A High-Performance Storage Array Architecture for Next-Generation, Non-volatile Memories. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture, Northwest, Washington, DC, USA, 4–8 December 2010; pp. 385–395. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DRAM | STT-MRAM | PCM | NAND Flash | |
|---|---|---|---|---|
| Maturity | Product | Prototype | Product | Product |
| Read latency | 10 ns | 10 ns | 20–50 ns | 25 us |
| Write latency | 10 ns | 10 ns | 80–500 ns | 200 us |
| Erase latency | N/A | N/A | N/A | 200 ms |
| Energy per bit access (r/w) | 2 pJ | 0.02 pJ | 20pJ/100 pJ | 10 nJ |
| Static power | Yes | No | No | No |
| Endurance (writes/bit) | 1016 | 1016 | 106–108 | 105 |
| Cell size | 6–8 F2 | >6 F2 | 5–10 F2 | 4–5 F2 |
| MLC | N/A | 4 bits/cell | 4 bits/cell | 4 bits/cell |
| Component | 16 GB DRAM + NVM PC | 64 GB DRAM + HDD PC | Note |
|---|---|---|---|
| CPU | $317 (1) | $317 (1) | (1) Intel Core i7-7700 3.6 GHz 4-Core Processor |
| Mainboard | $56 (2) | $114 (3) | (2) ASRock H110M-HDS R3.0 Micro ATX LGA1151 Motherboard (3) ASRock B250 Pro4 ATX LGA1151 Motherboard |
| DRAM | $70 (4) | $280 (5) | (4) Corsair Vengeance LPX 16 GB (5) Corsair Vengeance LPX 16 GB (16 GB × 4) |
| Storage | $370 (6) | $50 (7) | (6) Intel Optane 900P (280 GB) (7) Seagate Barracuda Compute HDD 2 TB |
| Misc (CPU Cooler, Case, Power) | $156 | $156 | |
| Total Price | $969 | $917 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bahn, H.; Cho, K. Implications of NVM Based Storage on Memory Subsystem Management. Appl. Sci. 2020, 10, 999. https://doi.org/10.3390/app10030999
Bahn H, Cho K. Implications of NVM Based Storage on Memory Subsystem Management. Applied Sciences. 2020; 10(3):999. https://doi.org/10.3390/app10030999
Chicago/Turabian StyleBahn, Hyokyung, and Kyungwoon Cho. 2020. "Implications of NVM Based Storage on Memory Subsystem Management" Applied Sciences 10, no. 3: 999. https://doi.org/10.3390/app10030999
APA StyleBahn, H., & Cho, K. (2020). Implications of NVM Based Storage on Memory Subsystem Management. Applied Sciences, 10(3), 999. https://doi.org/10.3390/app10030999