Graph Convolutional Networks for Privacy Metrics in Online Social Networks


Abstract
:1. Introduction
2. Related Work
- (1)
- We combine a user’s attribute information, behaviour characteristics, friend relationships, and graph structure information to obtain the user’s comprehensive privacy scores.
- (2)
- We innovatively introduce the deep learning framework into the field of privacy measurement, which addresses the shortcomings of previous studies that can only calculate privacy metrics for a single user each time, extracts the hidden relationship between different features, and accurately and efficiently measures the privacy of users in the whole network.
- (3)
- We introduce the few-shot learning method and SGCs (simplifying graph revolutionary networks), which can alleviate the difficulties of labelled data in the security field and long, time-consuming training in deep learning.
- (4)
- We crawl real datasets on social networks, perform statistical analysis, extract features, and conduct an experimental demonstration of our model.
3. Datasets and Notation
3.1. Datasets
3.2. Problem Description and Notation
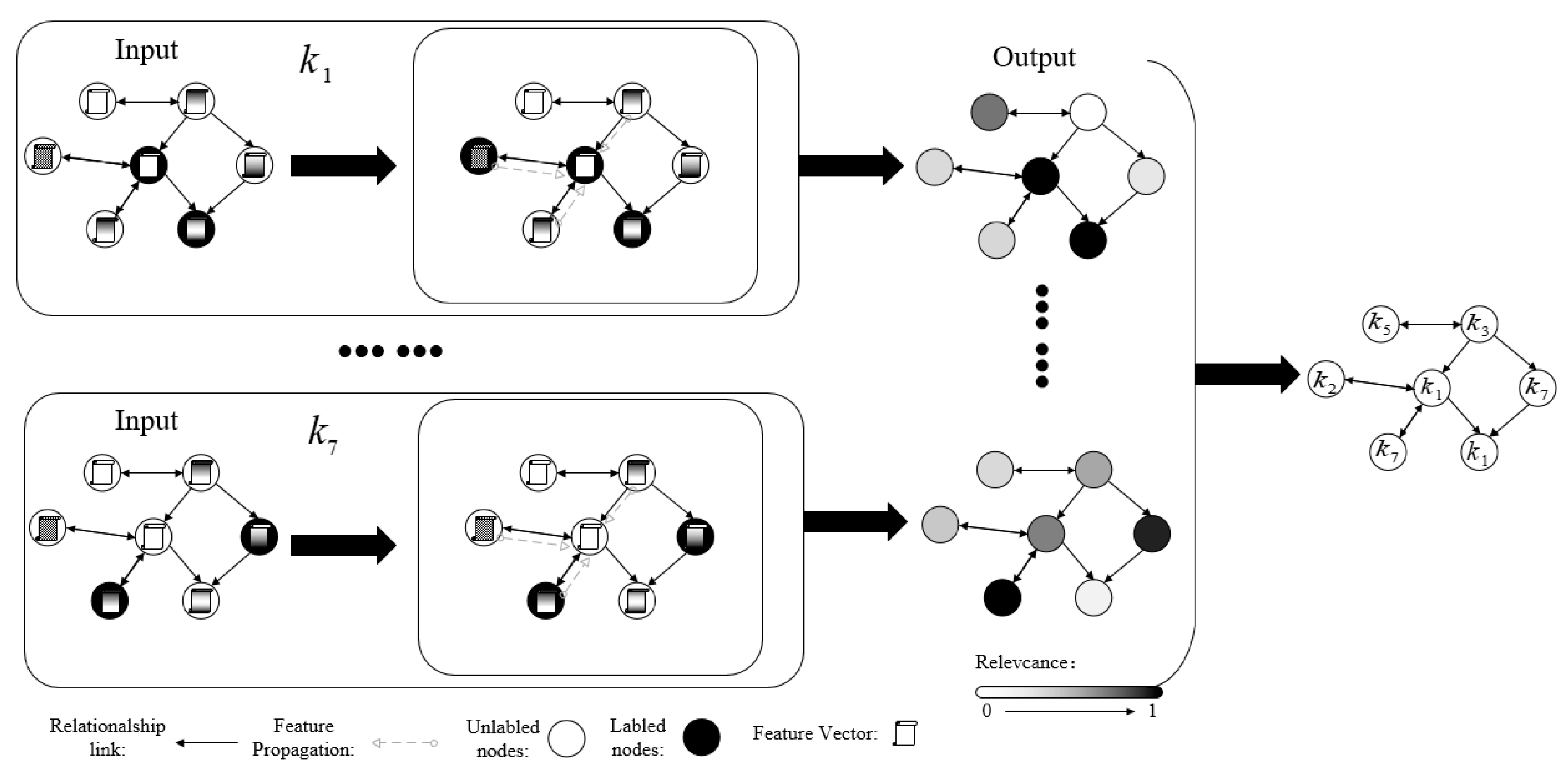
4. Framework Design
4.1. GCNs
4.2. SGC
4.3. Framework Structure
5. Experimental Evaluation
5.1. Parameter Selection
5.2. Experiment 1
5.3. Experiment 2
6. Discussions and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fang, L.; LeFevre, K. Privacy wizards for social networking sites. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 351–360. [Google Scholar]
- Qiu, M.; Gai, K.; Xiong, Z. Privacy-preserving wireless communications using bipartite matching in social big data. Futur. Gener. Comput. Syst. 2018, 87, 772–781. [Google Scholar] [CrossRef]
- Xu, L.; Jiang, C.; Chen, Y.; Wang, J.; Ren, Y. A framework for categorizing and applying privacy-preservation techniques in big data mining. Computer 2016, 49, 54–62. [Google Scholar] [CrossRef]
- Lam, I.F.; Chen, K.T.; Chen, L.J. Involuntary information leakage in social network services. In International Workshop on Security; Springer: Berlin, Germany, 2008; pp. 167–183. [Google Scholar]
- Patsakis, C.; Zigomitros, A.; Papageorgiou, A.; Galván-López, E. Distributing privacy policies over multimedia content across multiple online social networks. Comput. Netw. 2014, 75, 531–543. [Google Scholar] [CrossRef] [Green Version]
- Oukemeni, S.; Rifà-Pous, H.; Puig, J.M.M. Privacy Analysis on Microblogging Online Social Networks: A Survey. ACM Comput. Surv. CSUR 2019, 52, 60. [Google Scholar] [CrossRef] [Green Version]
- Altenburger, K.M.; Ugander, J. Monophily in social networks introduces similarity among friends-of-friends. Nat. Hum. Behav. 2018, 2, 284. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR’2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Dey, R.; Tang, C.; Ross, K.; Saxena, N. Estimating age privacy leakage in online social networks. In Proceedings of the INFOCOM, 2012 Proceedings IEEE, Orlando, FL, USA, 25–30 March 2012; IEEE: New York, NY, USA, 2012; pp. 2836–2840. [Google Scholar]
- Srivastava, A.; Geethakumari, G. Measuring privacy leaks in online social networks. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; IEEE: New York, NY, USA, 2013; pp. 2095–2100. [Google Scholar]
- Liang, K.; Liu, J.K.; Lu, R.; Wong, D.S. Privacy concerns for photo sharing in online social networks. IEEE Internet Comput. 2015, 19, 58–63. [Google Scholar] [CrossRef]
- Maximilien, E.M.; Grandison, T.; Sun, T.; Richardson, D.; Guo, S.; Liu, K. Privacy-as-a-service: Models, algorithms, and results on the Facebook platform. In Web 2.0 Security and Privacy Workshop; IEEE: New York, NY, USA, 2009; Volume 2. [Google Scholar]
- Liu, K.; Terzi, E. A framework for computing the privacy scores of users in online social networks. ACM Trans. Knowl. Discov. Data 2010, 5, 6. [Google Scholar] [CrossRef] [Green Version]
- Aghasian, E.; Garg, S.; Gao, L.; Yu, S.; Montgomery, J. Scoring Users’ Privacy Disclosure Across Multiple Online Social Networks. IEEE Access 2017, 5, 13118–13130. [Google Scholar] [CrossRef]
- Pensa, R.G.; Di Blasi, G.; Bioglio, L. Network-aware privacy risk estimation in online social networks. Social Netw. Anal. Min. 2019, 9, 15. [Google Scholar] [CrossRef] [Green Version]
- Pensa, R.G.; Di Blasi, G. A privacy self-assessment framework for online social networks. Expert Syst. Appl. 2017, 86, 18–31. [Google Scholar] [CrossRef]
- Alsarkal, Y.; Zhang, N.; Xu, H. Your Privacy Is Your Friend’s Privacy: Examining Interdependent Information Disclosure on Online Social Networks. In Proceedings of the 51st Hawaii International Conference on System Sciences, Waikoloa Village, HI, USA, 2–6 January 2018. [Google Scholar]
- Serfontein, R.; Kruger, H.; Drevin, L. Identifying Information Security Risks in a Social Network Using Self-organising Maps. In Proceedings of the IFIP World Conference on Information Security Education, Lisbon, Portugal, 25–27 June 2019; Springer: Cham, Germany; pp. 114–126. [Google Scholar]
- Djoudi, A.; Pujolle, G. Social Privacy Score through Vulnerability Contagion Process. In Proceedings of the 2019 Fifth Conference on Mobile and Secure Services (MobiSecServ), Miami Beach, FL, USA, 2–3 March 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Yu, L.; Motipalli, S.M.; Lee, D.; Liu, P.; Xu, H.; Liu, Q.; Tan, J.; Luo, B. My Friend Leaks My Privacy: Modeling and Analyzing Privacy in Social Networks. In Proceedings of the 23nd ACM on Symposium on Access Control Models and Technologies, Indianapolis, IN, USA, 13–15 June 2018; ACM: New York, NY, USA, 2018; pp. 93–104. [Google Scholar]
- De Salve, A.; Guidi, B.; Michienzi, A. Exploiting Community Detection to Recommend Privacy Policies in Decentralized Online Social Networks. In Proceedings of the European Conference on Parallel Processing, Turin, Italy, 27–31 August 2018; Springer: Cham, Germany; pp. 573–584. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph Neural Networks for Social Recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 417–426. [Google Scholar]
- Zhang, W.; Shu, K.; Liu, H.; Wang, Y. Graph Neural Networks for User Identity Linkage. arXiv 2019, arXiv:1903.02174. [Google Scholar]
- Mei, B.; Xiao, Y.; Li, R.; Li, H.; Cheng, X.; Sun, Y. Image and attribute based convolutional neural network inference attacks in social networks. IEEE Trans. Netw. Sci. Eng. 2018, 1. [Google Scholar] [CrossRef]
- Li, X.; Cao, Y.; Shang, Y.; Liu, Y.; Tan, J.; Guo, L. Inferring user profiles in online social networks based on convolutional neural network. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Melbourne, Victoria, Australia, 19–20 August 2017; Springer: Cham, Germany, 2017; pp. 274–286. [Google Scholar]
- Chen, J.; Ma, T.; Xiao, C. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling. In Proceedings of the International Conference on Learning Representations (ICLR’2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liao, R.; Zhao, Z.; Urtasun, R.; Zemel, R. Lanczosnet: Multi-scale deep graph convolutional networks. arXiv 2019, arXiv:1901.01484. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI’19), Hilton Hawaiian Village, Honolulu, HI, USA, January 27–February 1 2019. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Han, B.; Cook, P.; Baldwin, T. Geolocation prediction in social media data by finding location indicative words. In Proceedings of the 24th International Conference on Computational Linguistics, Mumbai, India, 8–15 December 2012; Dublin City University and Association for Computational Linguistics: Dublin, German, 2012; pp. 1045–1062. [Google Scholar]
- Kampffmeyer, M.; Chen, Y.; Liang, X.; Wang, H.; Zhang, Y.; Xing, E.P. Rethinking knowledge graph propagation for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11487–11496. [Google Scholar]
- Wang, X.; Ye, Y.; Gupta, A. Zero-shot recognition via semantic embeddings and knowledge graphs. In Computer Vision and Pattern Recognition (CVPR); IEEE Computer Society: San Francisco, CA, USA, 2018; pp. 6857–6866. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with local and global consistency. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–13 December 2003. [Google Scholar]
- Douze, M.; Szlam, A.; Hariharan, B.; Jégou, H. Low-shot learning with large-scale diffusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–24 June 2018. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O.; Schmid, C. Graph convolutional networks for learning with few clean and many noisy labels. arXiv 2019, arXiv:1910.00324. [Google Scholar]
- Wu, F.; Zhang, T.; Souza, A.H.D., Jr.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying graph convolutional networks. arXiv 2019, arXiv:1902.07153. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nodes | Edges |
|---|---|---|
| Dataset 1 | 3244 | 6452 |
| Dataset 2 | 704,903 | 1,527,106 |
| Features | ||
|---|---|---|
| Attribute extraction difficulty | Attribute sensitivity | The number of likes |
| The number of comments | The number of @ | The number of reposts |
| The number of topics involved | The number of follower | The number of follow |
| The number of published Weibo | The number of published pictures | The number of published videos |
| Account usage time | Authenticated user or not | The time of last Weibo |
| Attribute | Sensitivity |
|---|---|
| Phone Number | 0.5669 |
| 0.3260 | |
| Hometown | 0.2253 |
| Birthdate | 0.2748 |
| Address | 0.4212 |
| Job Details | 0.2024 |
| Relationship Status | 0.1731 |
| Interests | 0.1255 |
| Education | 0.1575 |
| Dataset 1 | |||||||
| 52% | 40% | 42% | 52% | 36% | 38% | 54% | |
| 70% | 52% | 50% | 62% | 48% | 46% | 74% | |
| 80% | 62% | 58% | 82% | 58% | 54% | 86% | |
| 84% | 74% | 70% | 86% | 68% | 62% | 92% | |
| 92% | 88% | 82% | 92% | 84% | 84% | 98% | |
| Dataset 2 | |||||||
| 64% | 44% | 54% | 62% | 50% | 42% | 70% | |
| 76% | 60% | 64% | 72% | 58% | 56% | 80% | |
| 80% | 62% | 70% | 78% | 58% | 58% | 86% | |
| 84% | 78% | 82% | 84% | 80% | 78% | 96% | |
| 96% | 92% | 86% | 94% | 88% | 84% | 100% | |
| Models | Dataset 1 (Seconds) | Dataset 2 (Hours, Minutes) |
|---|---|---|
| GCNs | 0.57 s | 23 h 36 m |
| FastGCN | 3.88 s | 14 h 22 m |
| SGC | 0.14 s | 9 h 17 m |
| GCNs | FastGCN | SGC | |
|---|---|---|---|
| Dataset 1 | |||
| 47.14% | 46% | 46.57% | |
| 55.71% | 54.86% | 56% | |
| 69.71% | 67.71% | 68.57% | |
| 76.57% | 75.14% | 76.57% | |
| 83.86% | 84.86% | 85.57% | |
| Dataset 2 | |||
| 54.57% | 51.71% | 54.86% | |
| 64.86% | 60% | 66% | |
| 72.57% | 69.57% | 72.29% | |
| 81.43% | 76.86% | 82.57% | |
| 91.86% | 88.57% | 91.43% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Xin, Y.; Zhao, C.; Yang, Y.; Chen, Y. Graph Convolutional Networks for Privacy Metrics in Online Social Networks. Appl. Sci. 2020, 10, 1327. https://doi.org/10.3390/app10041327
Li X, Xin Y, Zhao C, Yang Y, Chen Y. Graph Convolutional Networks for Privacy Metrics in Online Social Networks. Applied Sciences. 2020; 10(4):1327. https://doi.org/10.3390/app10041327
Chicago/Turabian StyleLi, Xuefeng, Yang Xin, Chensu Zhao, Yixian Yang, and Yuling Chen. 2020. "Graph Convolutional Networks for Privacy Metrics in Online Social Networks" Applied Sciences 10, no. 4: 1327. https://doi.org/10.3390/app10041327
APA StyleLi, X., Xin, Y., Zhao, C., Yang, Y., & Chen, Y. (2020). Graph Convolutional Networks for Privacy Metrics in Online Social Networks. Applied Sciences, 10(4), 1327. https://doi.org/10.3390/app10041327