4.1. Evaluation of Effective Cognition by Physics of Notations Method
Systematic application of Physics of Notations theory on Processing Modeler follows.
4.1.1. Principle of Semiotic Clarity
When this principle is applied to symbols in the Processing Modeler, it is evident that both input data and output data symbols are overloaded. In version 2, one symbol represents nine different data types: vector, raster, string, file, table, table field, number, extent and boolean. The newer version 3 offers 22 different types of input data. The user has to assign the data type immediately when an input data symbol is assigned to the model. The data type (for example point, line, polygon) is assigned immediately when a model is designed, despite there being no evidence about data type in the graphical symbol.
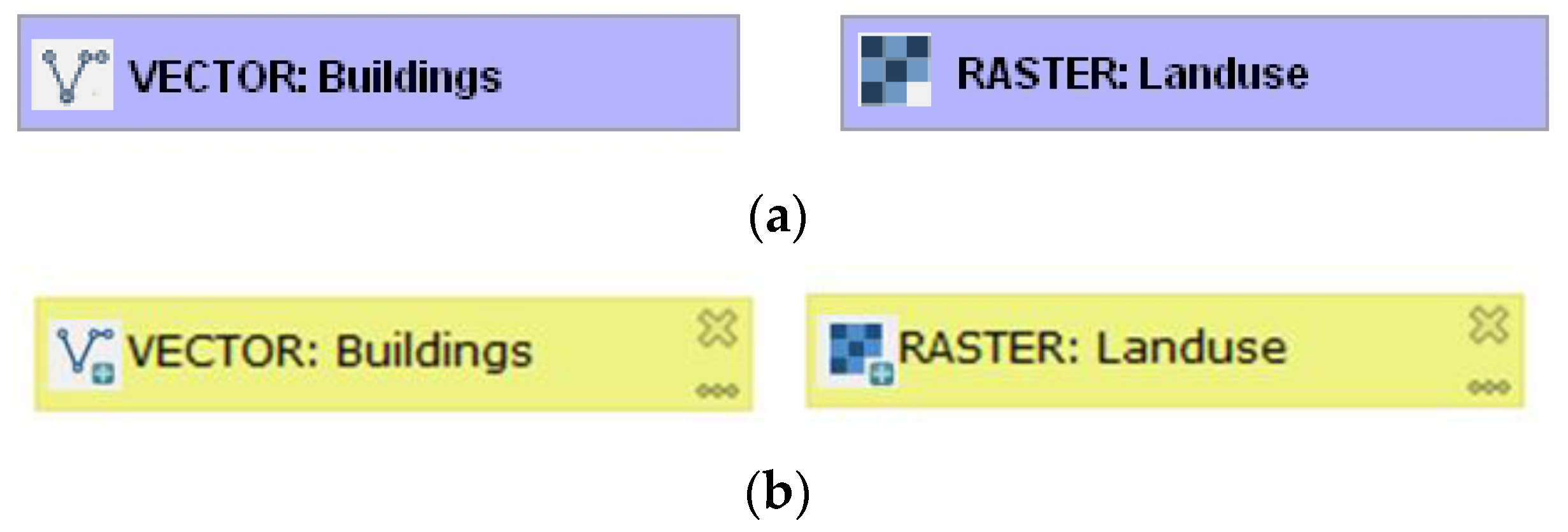
Detected symbol overloads could be solved in the following manner: remove the inner
plus icon at the left in the symbol and replace it with more specific icons that express the type of data. Suggestions for vector and raster data symbols are given in
Figure 4. Both icons are adopted from the QGIS interface. The lower pair uses the compound icons from version 3, where the symbols for vector and raster are supplemented by a small plus icon to express input of data. These compound icons are better than simple icons in version 2. The former and larger plus icon is substituted by a plus icon that forms a part of the vector or raster icon. New icons could be suggested for file, folder, string, number, table and field using any universal icon. Data such as extent, CRS, map layer, etc. need domain-specific icons. The same inner icon sets could be used for the output data symbol where a compound symbol can contain bigger icon of data type and small output arrow that is original in output symbol. The suggestions follow Szczpanek icon theory [
15]. These suggestions would increase the number of icons in the graphical vocabulary and solve the overload of the two original symbols for input/output data.
4.1.2. Principle of Perceptual Discriminability
The colour, shape, orientation, brightness and other visual variables are what the user uses for discrimination of symbols in practice. Systematic couple comparison shows the distance between every two symbols. The visual distance is measured by several different characteristics (number of visual variables). Pairwise comparison of the version 3 symbols according to this principle is given in
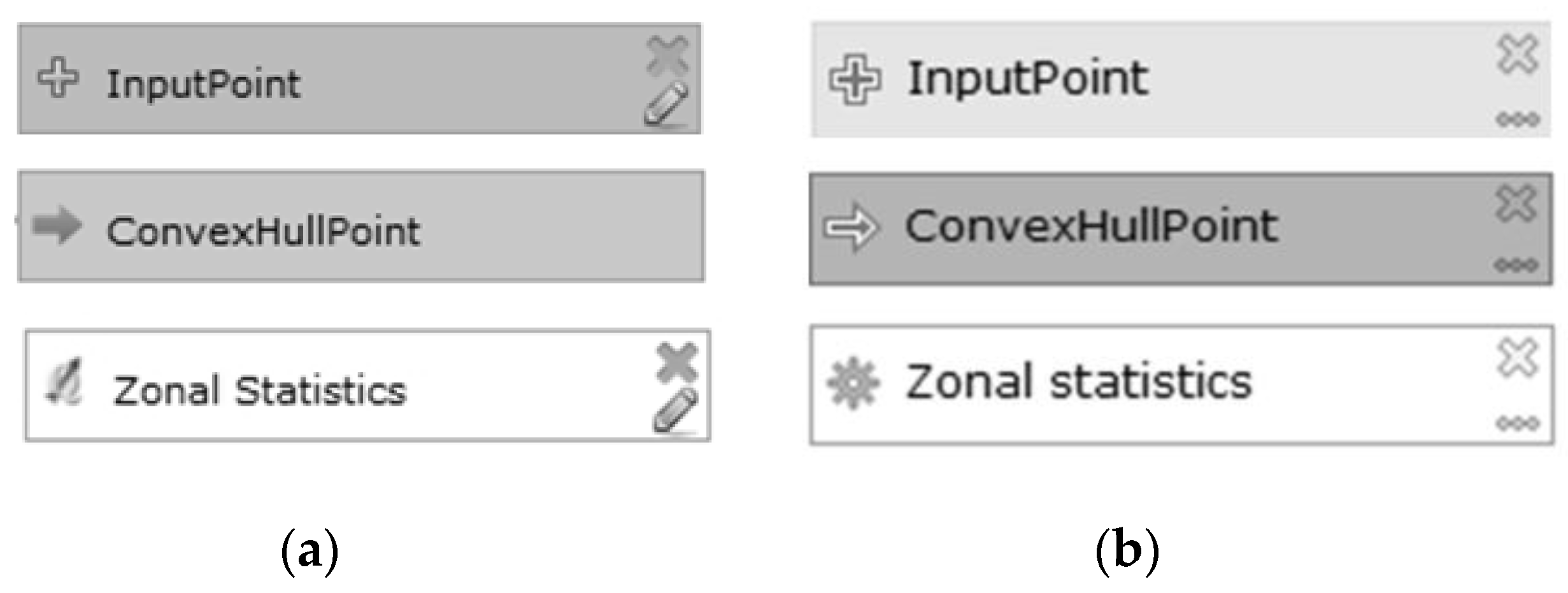
Table 1. In the Processing Modeler, the symbols differ only in colour and brightness, and the rectangular shape is the same for all symbols. The visual distance is two in all pairs. The characteristics are poorer in the symbols of the older version 2. The only differences are in colour, and there the visual distance is one (the difference in brightness is only between the data symbol and operation symbol). Perceptual discriminability of the symbol through colour is almost satisfactory by differing in tone. The Processing Modeler does not have the option for the user to define the colour to express other meanings of symbols, for example, to distinguish the final data and intermediate data in a large model.
Considering this principle of perceptual discriminability, the distinctiveness of the white symbol from the canvas is poor. The model’s canvas and symbol for operation have the same white colour, from which a new recommendation emerged: change the fill colour for the operation symbol from white to orange-brown (
Figure 5). The result of the pairwise comparison of all symbols in the vocabulary remains the same. The discriminability of symbol and canvas is better than with the white symbol.
4.1.3. Principle of Visual Expressiveness
The recommendation according to this principle is to use maximum visual variables in symbols. Only colour is used as the fill for graphic elements. Other visual variables such as symbol
shape,
size,
texture,
orientation and
position are not used in the Processing Modeler. The shape is the same rectangle for all symbols. The size of the symbols does not vary and cannot be changed. Brightness is used in version 3 (
Figure 3). The new symbol vocabulary is improved by using a greater variation in brightness between symbols and maybe various shapes of symbols. The visual variable of position is only applied when the output data symbol is automatically placed near the right side of the producing operation (
Figure 6). This manner of near-automatic placement of output symbols is the same in version 3 (Figure 13). However, the position of the output data symbol is very often changed by the user, which then moves the operation symbol. The former position of output data remains without following the symbol of the sourcing process. The mutual position linking the symbol is not fixed. The positioning of the output data symbol is only a weak and unstable use of the
position variable.
The graphical vocabulary is at a low level 1 in a maximum scale of 8 in terms of the principle of Visual Expressiveness.
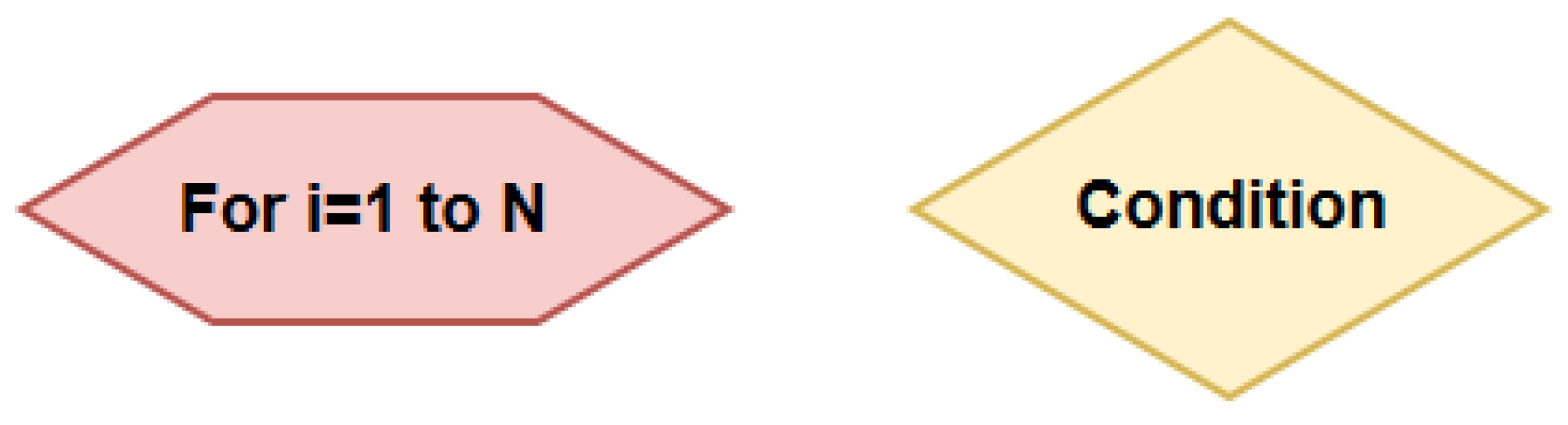
The QGIS Processing Modeler does not offer the
loop and
condition functions. To implement these functions in order to control operations, the draft offered in this paper uses the visual variables of shape and colour (
Figure 7). The pink rectangle with oblique sides represents the cycle operation, and the light yellow rhombus represents the condition. These symbol shapes correspond to the classic shapes of flowchart symbols. In the vocabulary in version 3, these shapes differ from basic rectangular shapes in vocabulary and colour. By using these new symbols, the number of variables used increases to two. The total number of symbols would be five in the vocabulary. These symbols fulfil the principles of Discriminability and Visual Expressiveness. The principle of Graphic Economy would also be fulfilled (explanation of the principle of Graphic Economy follows).
4.1.4. Principle of Graphic Economy
The number of base graphical elements is three, which meets the requirement for cognitive management and the requirement for a range of 7 ± 2 symbols. Even with all the previous suggestions for changes with two symbols for the condition and cycle (under the principle of Visual Expressiveness) and suggestion for a blue symbol for the sub-models (see below in the Complexity Management principle), the total number of symbols is six. Altogether, the requirement of that principle is fulfilled. The vocabulary will be economical.
4.1.5. Principle of Dual Coding
This principle suggests accompanied descriptive text to the symbols. For models in the Processing Modeler, the text completes the data symbol with the data name and the operation symbol with the operation name. The user assigns the data name arbitrarily, which is always an input parameter. The input data symbol is never bound to specific data stored on the storage medium in the model’s design mode. The name can be edited as desired. The operation name is added to the symbol automatically according to the selected operation and can also be changed in version 3 (not possible in version 2). The option to edit the operation name is a good improvement in functionality and allows the model to be better understood. Renaming the operation is especially advantageous when the same operation appears multiple times in one model. Therefore, it is possible to describe or specify the meaning of the operation.
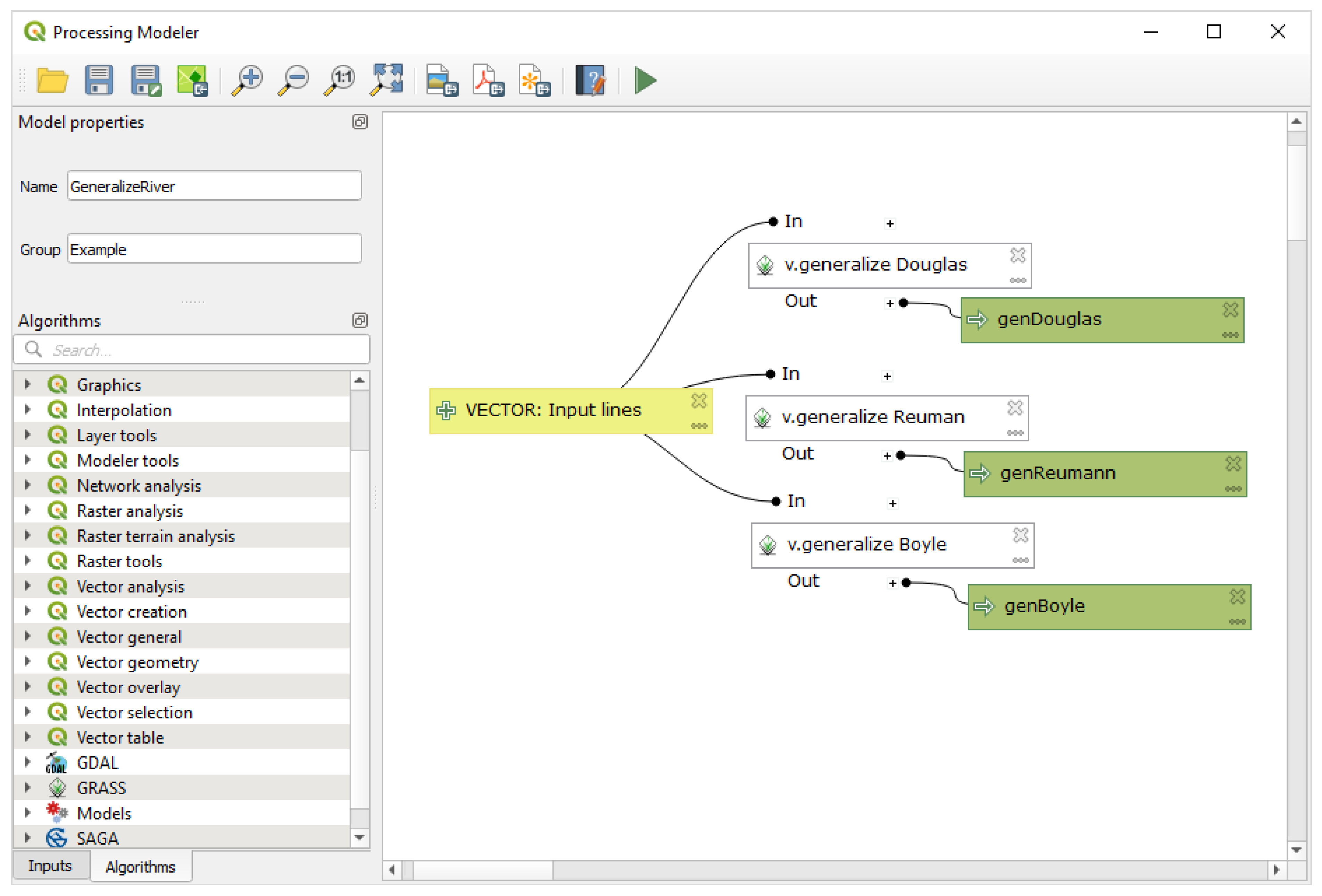
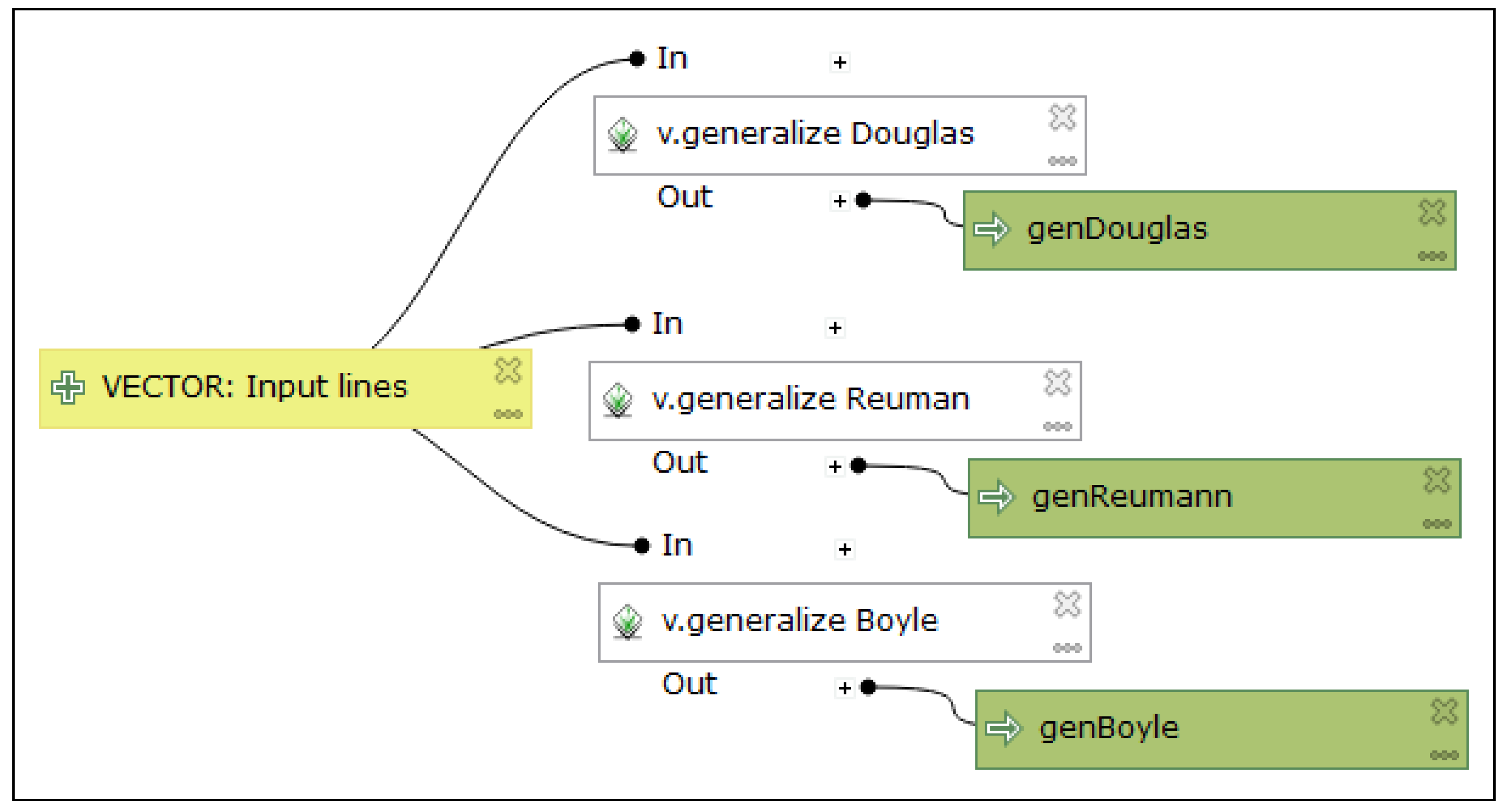
Figure 8 depicts a diagram where
v.generalize operations are called three times, but each time with a different generalisation algorithm. The selected algorithm is added manually by the user to the operation name. The operation name’s editing option improves the clarity of the model.
For long names that do not fit into the rectangle, the name is automatically truncated and completed with an ellipsis (
Figure 9). If a Semantic Transparency modification (see below—deletion of functional icons) were implemented, it would increase the space for longer operation and input data names, which would be beneficial.
To follow the principle of Dual Coding, modifying the input data labels is suggested. It would be helpful if labels concerning the data type improved the data symbols by using capitals. Examples are given in
Figure 10. If this is added automatically when symbols are added, the user only need arbitrarily select the data name. Additionally, the user’s data name (e.g., input lines) emphasises the spatial type. Manually describing a data type is possible in the current stage of notation. There is a space for good use of Dual Coding by users in naming symbols. The Processing Modeler meets the Dual Coding principle; however, comprehensibility could be improved with the proposed modification by specifying the data type with captioning.
The text is still used in the models to list the operation parameters when the plus symbol is pressed above the operation (
Figure 11). After this, the black dot divides itself into several black dots according to the number of join connector lines. The operation parameter list does not contain the values of these parameters and often dumps overlapping lines leading to the rectangle. This is retained in version 3. It would be useful to add a list of specific parameter values here. The current form of textual information is not useful to users. It is perhaps only useful in terms of expressing which symbol assigns concrete parameters to the operation.
4.1.6. Principle of Semantic Transparency
Symbols could be associated with the real meaning of an element according to this principle. The shape and colour of the symbols do not carry any association; they are semantically general in the Processing Modeler. This is the same in other visual programming languages for the GIS application. In those symbols, the inner icon of the
plus sign symbol on the input data symbol is used at the left. The output data symbol depicts an inward
arrow icon. Icons can also carry semantic meaning. These icons can be considered almost semantically immediate. The
plus icon indicates new data for processing. The
arrow icon indicates the processing result in a certain direction. However, the previous proposal under the principle of Semiotic Clarity is useful and also improves semantic immediacy. It suggests that each data type has an icon, such as in
Figure 4 (the plus icon is replaced or is a part of the compound symbol in version 3). Here, it is clear that the change resulting from applying the Semiotic Clarity principle also leads to an improvement in Semantic Transparency.
For operations, icons are mainly used to represent the source library. Rather, these icons are semantically generic because they do not explain anything about the purpose of the operation. However, these icons are a good guideline for determining the source library. It should be considered that many libraries contain operations with the same name (clip, buffer, etc.). In the Processing Modeler, version 3 sometimes uses an icon that represents the type of operation (namely for QGIS operations).
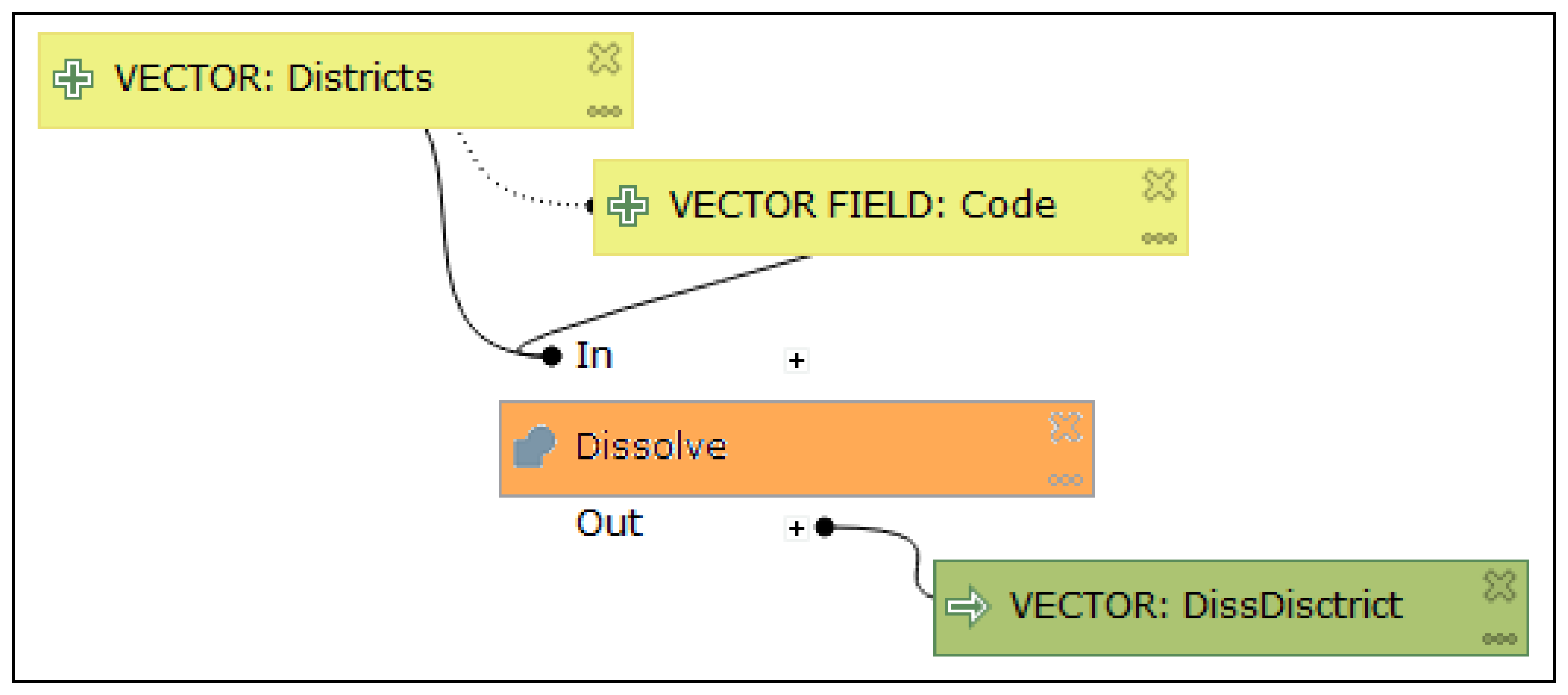
Figure 5 shows the operation Dissolve, which has a specific icon that represents this operation. Another specific icon for the operation ‘Merge vector layer’ is a model in Figure 13. The size and graphics of the icons are not suitable for improving the association of operation and their meanings. The icons are small and use only grey tones. A good example of large colour and detailed icons that describe the purpose of the operation is demonstrated in the Spatial Model Editor (
Figure 12) embedded in the ERDAS IMAGINE software [
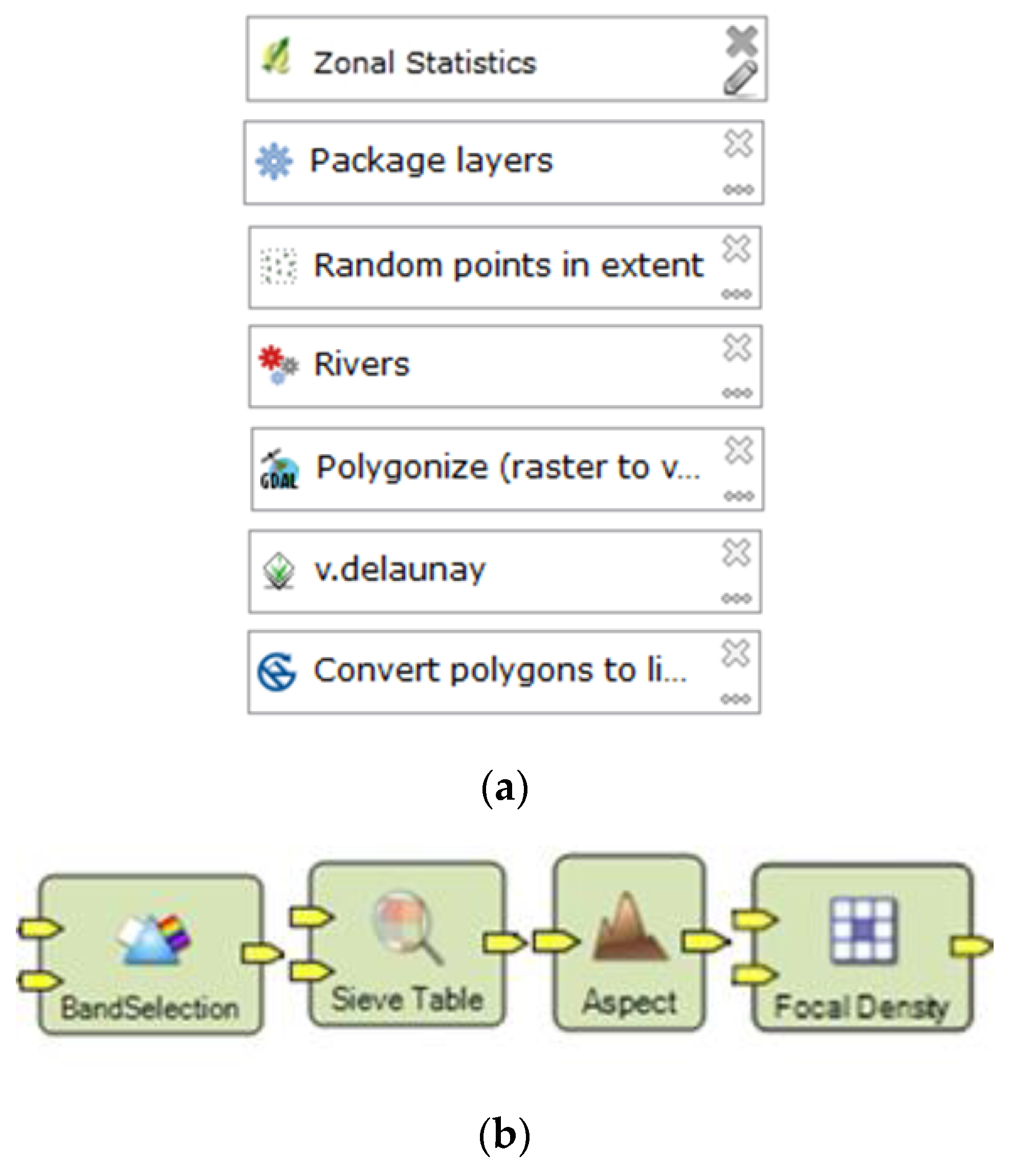
32]. The icons take up more space than the lower text in the symbol. The icons are prominent. The graphical vocabulary of the Spatial Model Editor has a high Semantic Transparency. The graphical vocabulary of the Spatial Model Editor is inspiring for the redesign of Processing Modeler symbols. The final recommendation is to reshape the rectangle to square to adopt bigger icons and then put the text label bellow icon.
The graphical vocabulary of the QGIS Processing Modeler has semantic opacity, except for some operations, where a greater positive semantic immediacy can be observed (
Figure 12—a third symbol from the top:
Random points in extent).
4.1.7. Principle of Complexity Management
This principle recommends producing hierarchical levels of the diagram and dividing it into separate modules and hierarchy. In textual/visual programming, this is achieved with sub-programs (sub-routines) or sub-models that can be designed and managed separately. The hierarchical model contains only two levels, no more.
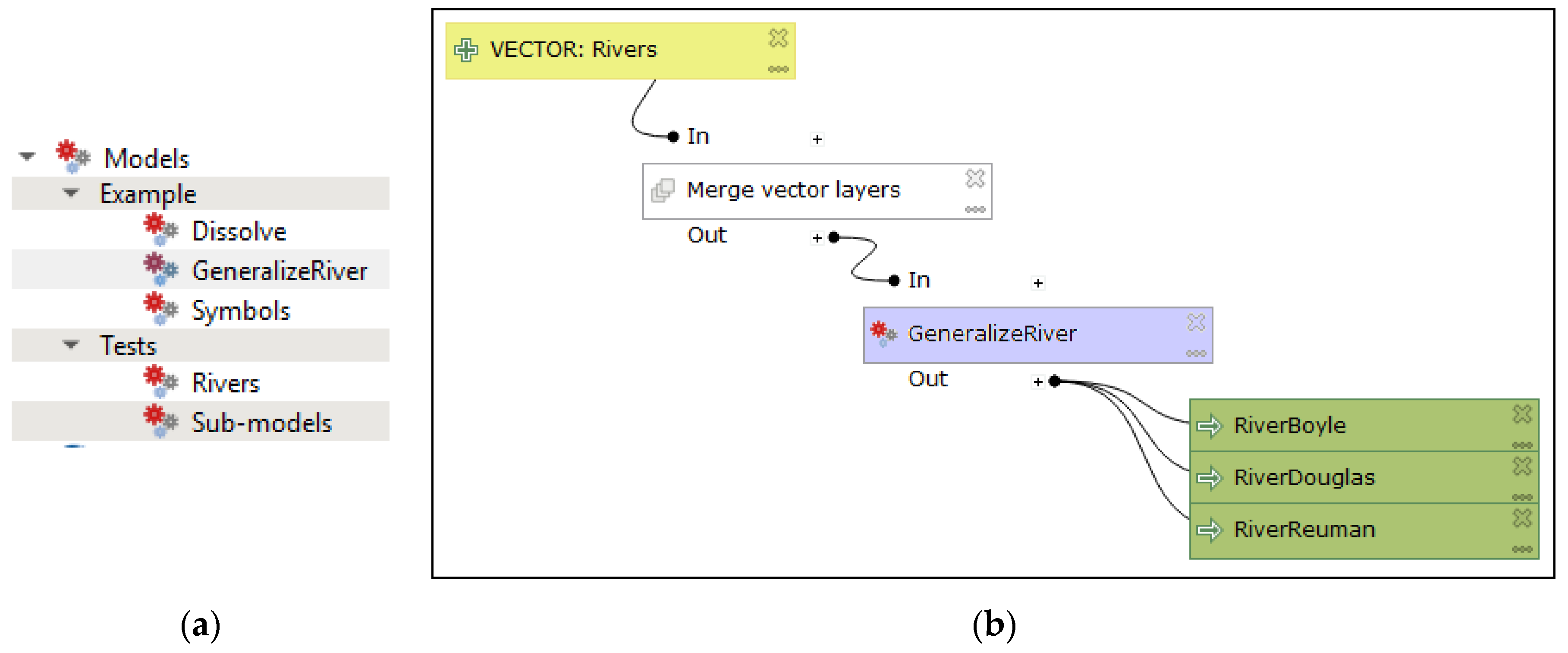
The Processing Modeler allows existing models to be added to other models in the interface—panel algorithms (
Figure 13). This has the right degree of modularity according to Complexity Management in both versions 2 and 3. The symbol of the model has a three-gear wheel icon (three connected balls in version 2) at the left of the symbol. Otherwise, a white rectangle is used. Since it would be good to differentiate the symbol of the individual operation from the sub-model with an icon, a colour fill other than white would be appropriate. A suggested depiction—blue fill colour for sub-models—is shown in
Figure 13. The visual resolution of other symbols is maintained. The number of symbols increases to seven after a new one is added for the sub-model. The final count of seven symbols fulfils the principle of Graphic Economy.
4.1.8. Principle of Cognitive Interaction
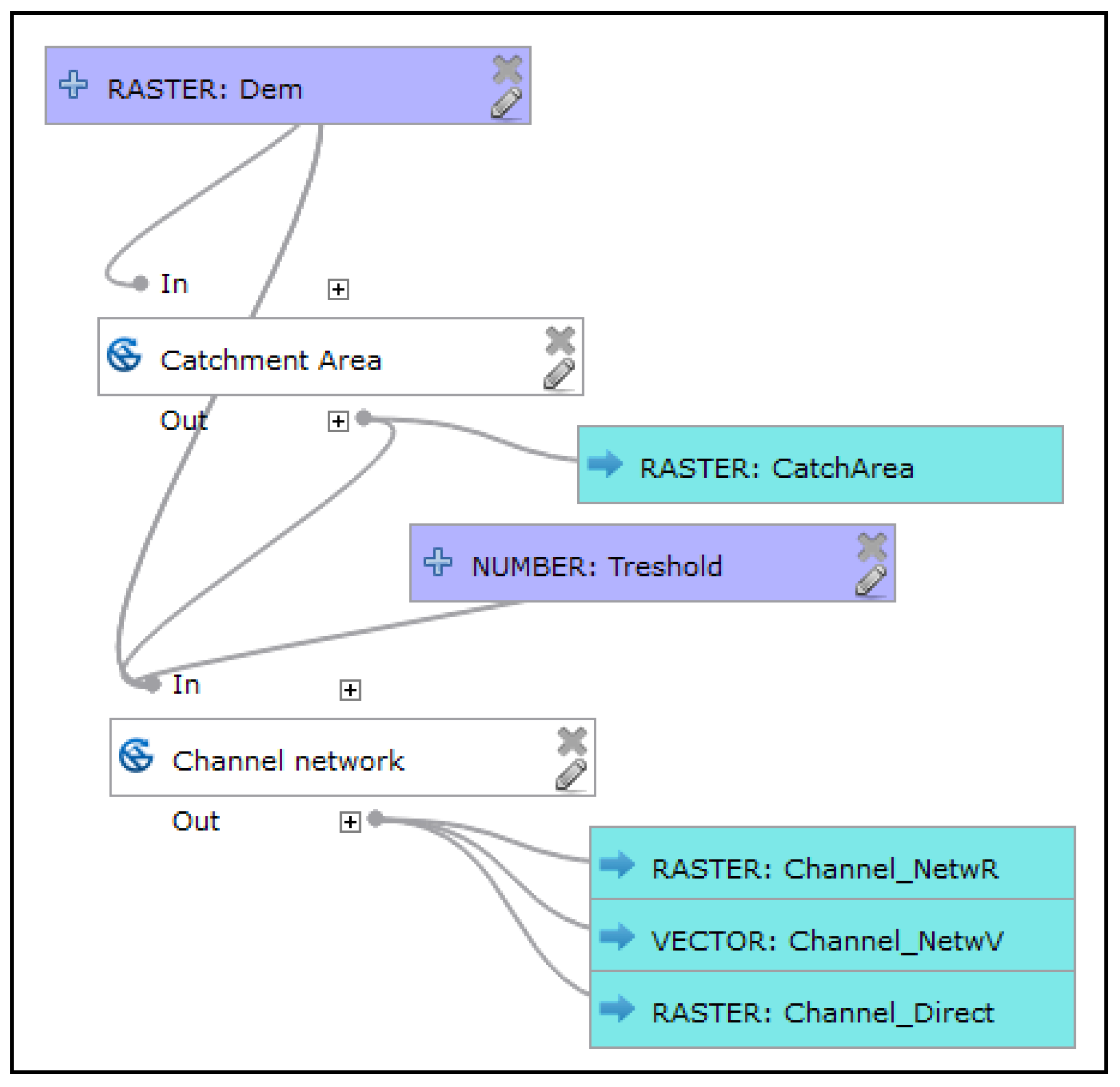
The principle recommends increasing the options for navigating in the model. The connector lines affect navigation. In the Processing Modeler, round connector lines join symbols. The lines are rendered automatically. Symbols very often overlap lines when symbols are manually moved (
Figure 6). Lines also sometimes cross each other, and they are not parallel. The user must manually attempt to find the best position for symbols in order to prevent overlapping and perplexing criss-crossing of curved lines. Previous research recommended that the number of edge crossings in drawings should be minimised [
33]. For these reasons, curved connector lines do not appear to be the proper solution. It is often difficult to trace the connector’s direction. A suggested change is to replace curved lines with straight lines (
Figure 14). Straight lines ensure good continuity for reading. Good continuity means minimizing the angular deviation from the straight line of two followed edges connecting two nodes [
34]. In this new suggestion for the Processing Modeler, straight lines could be optionally angled at an oblique or right angle when it is necessary to avoid a symbol. An acute angle is not suitable because of its smooth line tracking. If curved connectors remain in notation, there is necessary to add the user control over shaping these connectors to prevent crossing and overlapping.
Operation symbols linked with lines and a black dot offset from the edge of the symbol unnecessarily occupy space in the model’s area. It would be possible to terminate the lines directly on an edge or at the plus sign of the symbol to save space.
Finally, the ability to display a model’s thumbnail in the separate preview window helps to navigate the model. The preview window has not yet been implemented. In terms of cognitive interaction, version 3 was supplemented by a zooming function. The functions zoom in and zoom out in the model was absent in version 2.
Aligning the symbols makes reading the model quicker and easier. No automatic function for aligning the model to the grid is implemented. Symbols usually snap to a grid in other graphical software. No snapping function is given in the Processing Modeler. Post alignment to the vertical or horizontal line of the model could, therefore, be beneficial for design. All arrangement of symbol positions depends on user diligence, which is entirely manual work in the Processing Modeler. Manually aligning is a time-consuming activity.
4.2. Evaluation by Eye-Tracking Measurements
The eye-tracking experiment was designed in a complex way to confirm or reject the hypothesis H1 and H2. All tested diagrams are in
Appendix A. The design of the test contain more tasks to find maximum information. Some models serve for evaluation repetitively for a different purpose, e.g., find symbol, compare orientation, or read the labels. After testing only reliable answers and correct record by eye-tracker were finally evaluated and presented in the article.
The first evaluation concerned the discriminability of symbols. These tasks required finding input data and output data symbols in the models. The task was: “
Click on the symbol where the input data are” (task A1, A2, A3 in
Appendix A). The number of incorrect answers recorded was zero. The next task was “
Click on the symbol where the output data are” (task A4, A5, A6). The wrong answers were two times 2 (A4, A5), and 4 for task A6. However, model A6 has a big influence of arrangement to answer. It means that the input and output symbols were nearly high in
Perceptual Discriminability, but the errors report about space for improvements of symbols such as inner icons that are suggested in
Section 4.1. for increasing transparency and using all visual variables.
Besides the number of correct/wrong answers, the time of the first click was recorded. The distribution of times had not normal distribution (tested by Shapiro-Wilk test). Non-parametrical test Kruskal-Wallis tested if the medians of the “first click time” of all tasks (A1–A5) is equal. Kruskal-Wallis tested whether time samples originate from the same distribution. The result of the statistical test revealed the there is no significant difference between finding the symbol of input and output. It means that basic symbols are discriminable and none of them is dominant in perception.
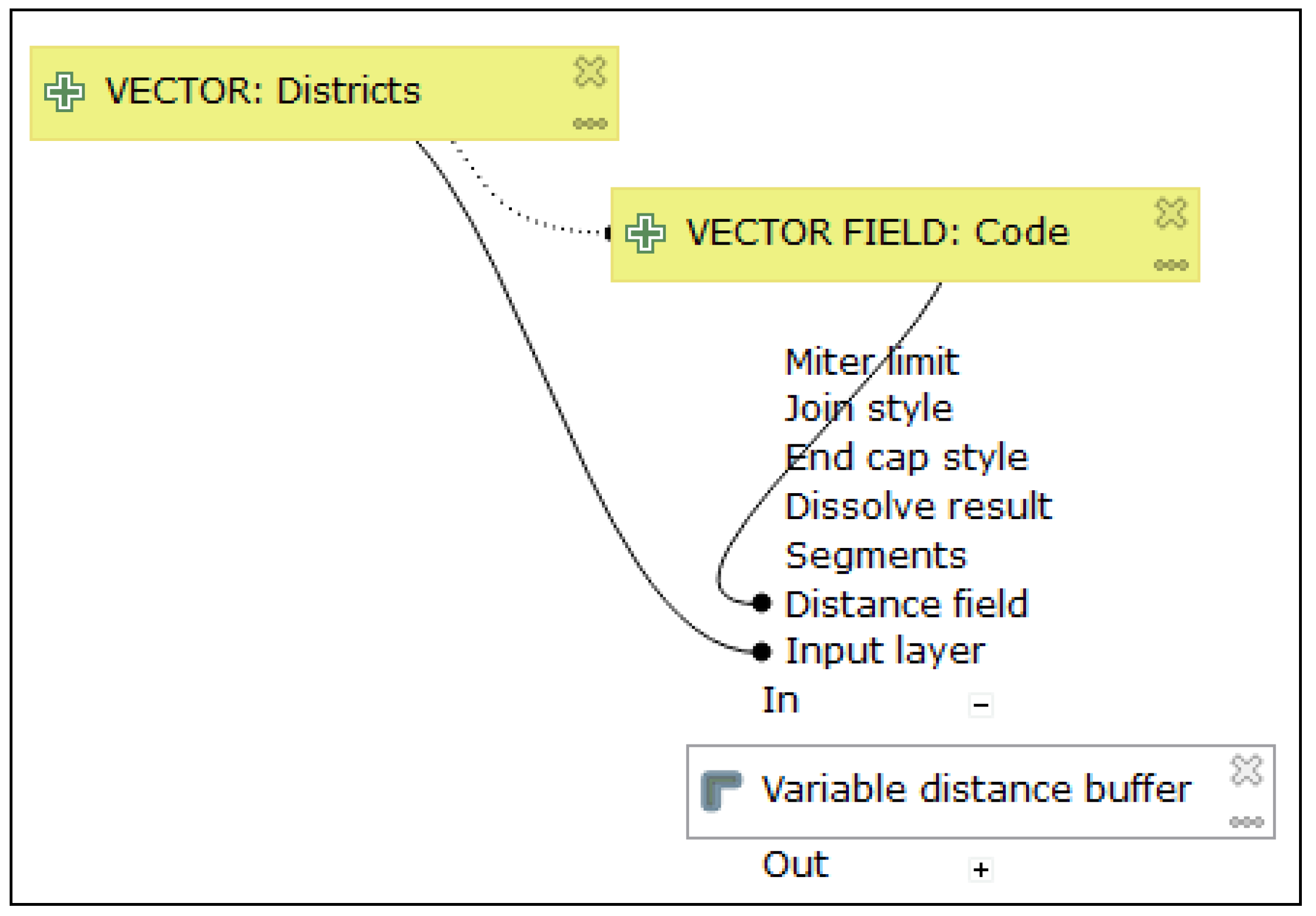
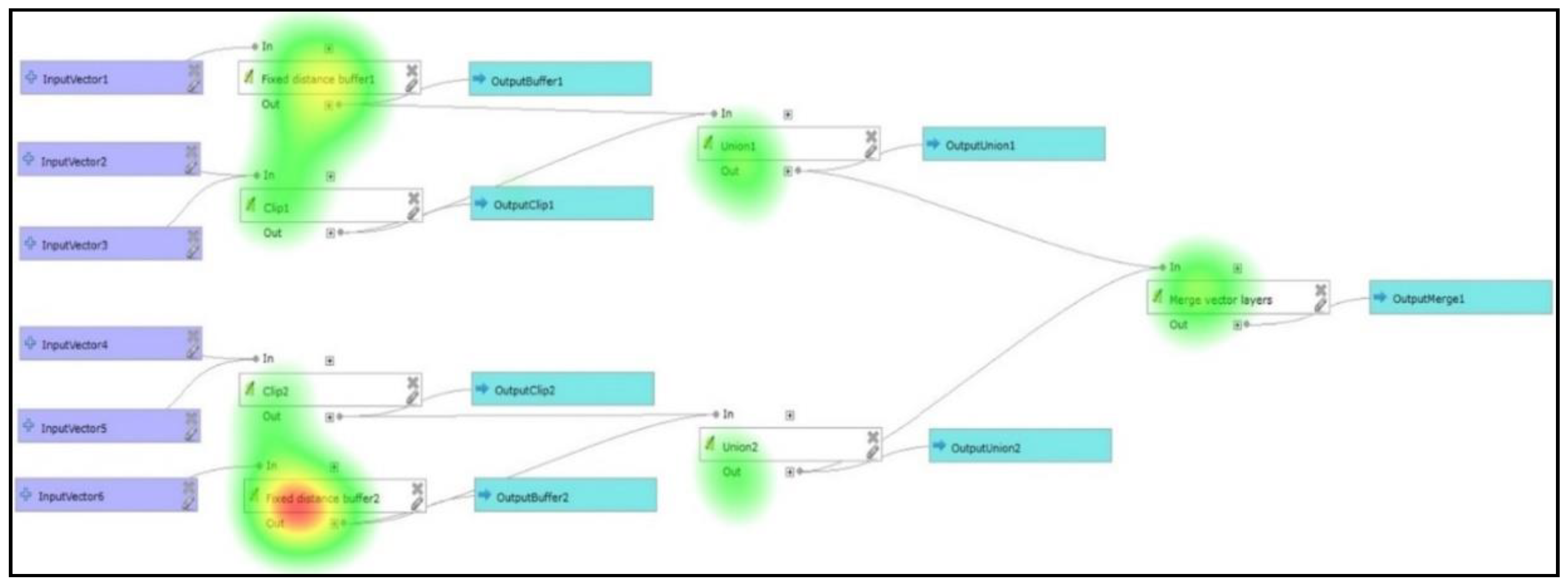
The next task aimed to verify the influence of
Dual Coding (but the influence of the discriminability present). The task was: “
Click on the symbol where the ‘Fixed Distance Buffer’ operation is called” (task A13, A14, A15). Once again, it was necessary to find the white symbol and read the labels in the symbols. A total of 21 correct answers were recorded (one incorrect). The results for 22 respondents were calculated as an attention heat map (
Figure 15). The heat map expresses the calculation of places where the peaks of gaze fixations are by all respondents. The figure shows that all white symbols correctly attracted the gaze of respondents. Respondents searched for white operation symbols and then read a particular operation label. The highest attentions were recorded at the two places where the
Fixed Distance Buffer operation was (top and bottom). Next, the lower peaks of fixations are at another white symbol with the different operation. It is evident that white colours of operation attract the gaze. Both principles of
Visual Expressiveness (and also
Perceptual Discriminability), by using white colour fill, and
Dual Coding were verified. In fact, this stimulus did not confirm the poor distinguishing of white symbols from a white canvas. The poorest distinguishing result was expected in the theoretical part of this article.
The principle of Semantic Transparency was difficult to test. The transparency of the icons was tested with the task:
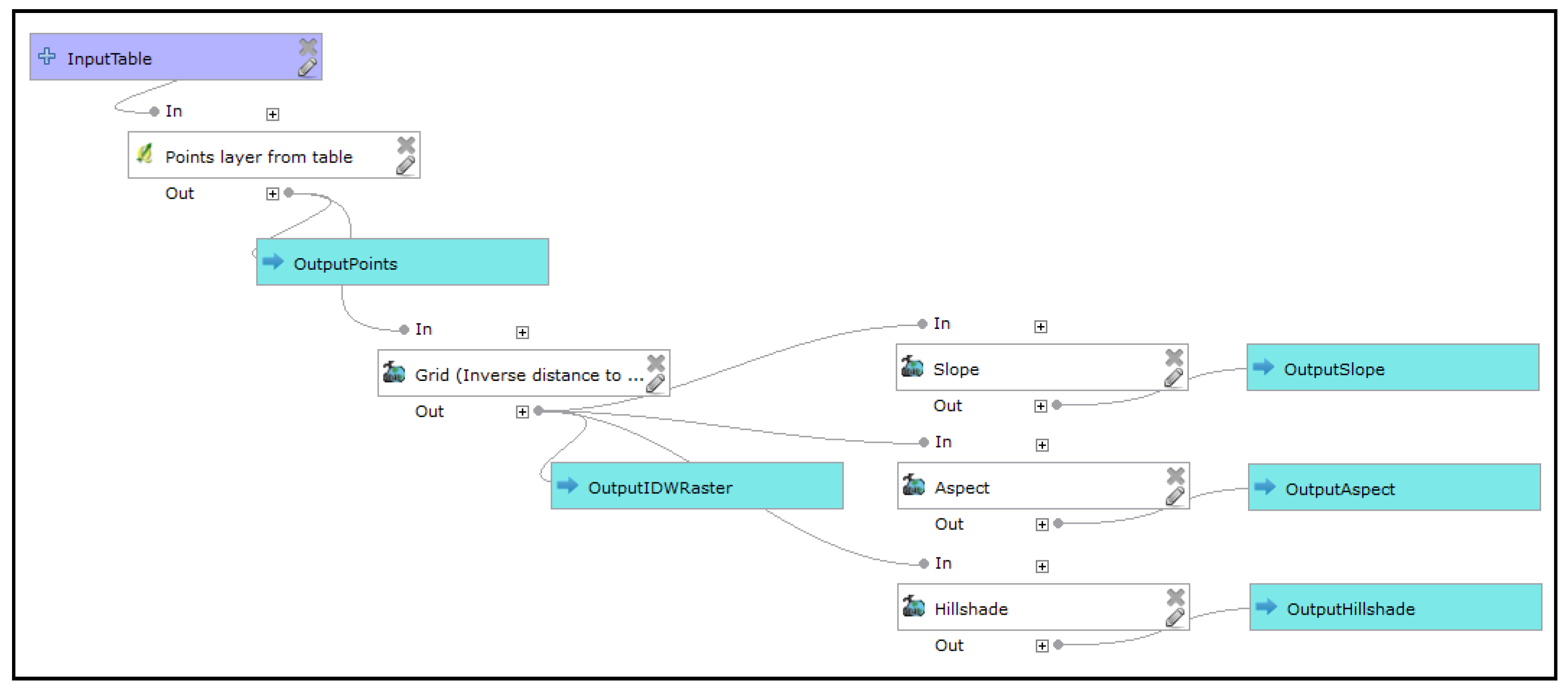
“Are all operations from the same source library?” The tested model is shown in
Figure 16 (
Appendix A16, 17, 18). Three incorrect answers were recorded from 22 respondents.
Semantic Transparency of data types was only possible to solve in the Processing Modeler with expressive text. This was verified in a model where the task was: “Does the input data have the same data type as the output data?” (A10, 11, 12). The data symbols were labelled with the words “table” and “raster” as a part of the data name in the model. It is “user design help” to the respondents to distinguish the data type. The number of incorrect answers was three for two models and two incorrect answers for A11 task. In these models, the response time was longer than the previously presented models and tasks. The average time of fixation was also longer. It verifies the necessity of reading labels by users. The solution of semantic transparency by text label consume more time for comprehension. The longer times confirms the hypothesis H2 about negative influences of insufficiencies to effective comprehension.
Both of the experiments mentioned above (about source library and the comparison of the data type of input and output data) verified that Semantic Transparency was low in the Processing Modeler.
The results about the number of correct and incorrect answers in all tasks presented in this section report that some insufficiencies adversely affect the cognition as it is stated in hypothesis H1.
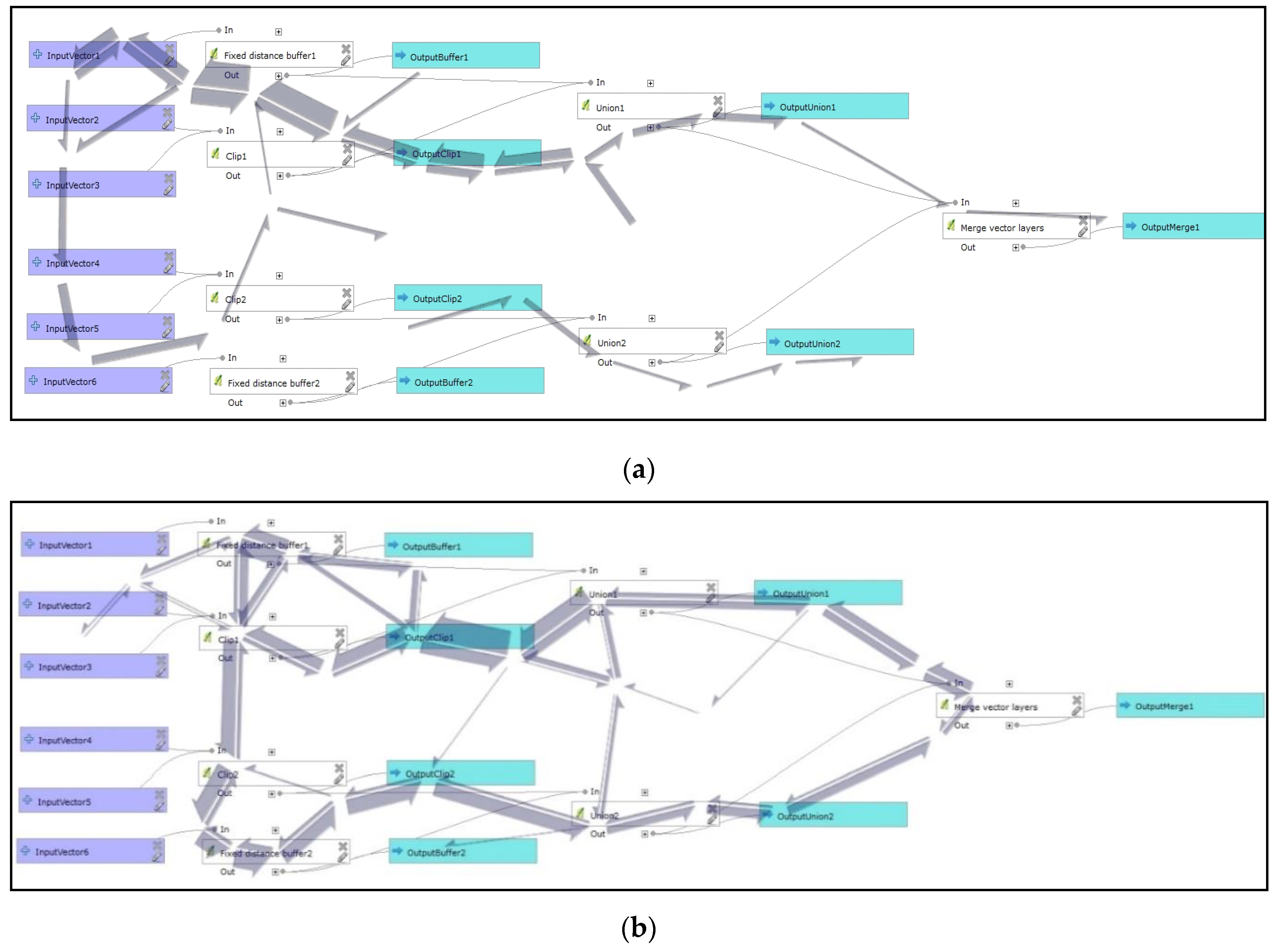
From eye-tracking testing, we received not only cross-validation of results by Physics of Notations but other new information. The interesting information was finding the reading patterns and influence of flow orientation to the respondent reading directions. To find the reading pattern of users, gazes were aggregated. A comparison of the same diagram from the free viewing section and a section with tasks is given in
Figure 17. Aggregations in both cases revealed that the orientation of data flow expressed by connector lines had a significant influence. Reading began in the middle of the stimulus according to the middle fixation cross in the previous stimulus. Gazes were attracted to the upper left corner and continued horizontally to the right. People’s habits of reading lines of text were very strong, especially in free viewing (
Figure 17a). The lower part of
Figure 17b also depicts strongly followed lines. Only a small number of gazes skips between two main horizontal workflow lines. Free viewing was not as systematic as task-oriented gaze aggregations.
Two models tested the effect of
symbol alignment in the model. This finding can be linked to the principle of
Cognitive Interaction. The first model had aligned symbols; the second model had no aligned symbols. The functionality was the same. The question was the same for both models:
“How many functions are in the model?” (task A8, A9). It was enough to count only the white rectangles in large models. The number of the expected correct answers was eight. The first aligned model recorded two incorrect answers and the second recorded seven. The average task time was much shorter in the first tasks. The non-parametrical Kruskal-Wallis test was used for eye-tracking metrics due to non-parametrical distribution of measured values. It tested if medians of groups are equal means they have the same distribution [
35]. The significance level for all Kruskal-Wallis tests was set to p-value 0.05. The test was run three times for several fixations, scanpath lengths and number of fixations per second. The test compared tree measured values for the aligned and non-aligned model (A8 and A9). Kruskal-Wallis test found statistically significant differences for all metrics: the number of fixations, scanpath lengths, and number of fixations per second. The model where the symbols were unaligned showed much worse values for all metrics (task A9). Therefore, aligning the symbols in the model made it easier to read and understand the model. This eye-tracking evaluation supports the recommendation for the new function of the automatic alignment of symbols in this graphical editor.
Three groups of models with the same functionality were prepared to test
the orientation of flow and find if any orientation is better for users. The models in each group differed only by orientation. Three orientations were tested: vertical, horizontal, and diagonal. Comparing the orientation could be also assumed as a contribution to the principle of
Cognitive Interaction. An example diagonal orientation of flow in a model is shown in
Figure 16, horizontal in
Figure 17. Variations of these models with three types of orientations were designed. The triplets are [A10, A11, A12], [A13, A14, A15], [A16, A17, A18] in
Appendix A. To prevent the bias, the same task was in each group. The aim was to find the best model orientation. The results from a Kruskal-Wallis test were not statistically significant. In some cases, horizontal orientation had the shortest average time of solution. In some models, diagonal orientation was better in average times of fixation, and horizontal models had the shortest scanpath length. The results were completely ambiguous, and the orientation preferences were not the same in all triplets. There is certainly a great deal of effect depending on the given question and model sizes. Eye-tracking did not reveal the best orientation of flow.










































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





