1. Introduction
Granular mixture is widely applied in industrial manufacturing, agricultural production and civil engineering, including powder metallurgy, food accumulation and building materials. For these mixtures, porosity is one of the most crucial factors that has a considerable impact on mixture structure and performance. However, due to the complex particle composition, it is hard to calculate or predict the mixture porosity without the help of lab experiments.
In order to solve the above problems, many researchers have proposed different methods to calculate and analyze the porosity of granular mixtures. In particuology, packing density calculation models based on the packing theory were derived, including the Furnas model [
1], linear packing density model [
2], compressible packing model [
3] and other improved models [
4,
5]. All of them are analytical models which were used to analyze particle spatial distributions and mixture packing densities. However, some literature [
6,
7] confirmed that these models were not accurate enough for complex problems and where particles have a wide range of sizes. A typical mixture in pavement engineering, however, is mainly composed of mineral aggregates with a wide range of particles sizes. The fine aggregates are less than 2.36 mm while the large particles can be larger than 19.0 mm. Additionally, in pavement engineering, mixtures are formed through the lab or field compacting process which is dependent on the particle physical interactions. Evidently, these analytical models cannot consider the particle interactions during the compacting process. Based on the two considerations above, the authors believe that the conventional analytical models as discussed above are not applicable for predicting porosities of pavement mixtures.
In pavement engineering, experimental testing methods were popularly used for studying mixture porosities [
8,
9]. In the past decades, many research studies were conducted for building the relationship between porosities and compositions of mixtures, while most of them were applied to specific projects or limited conditions [
10,
11]. Since 2005, with the rapid development of the discrete element methods (DEM), virtual mixture models have been developed for studying mix porosities [
12,
13], where particle gradations and morphological features were considered. With the DEM-based study, the researchers tended to explore the relations between the mix porosity and its mix composition. However, in the existing literature, the research purposes were mainly focused on evaluating a limited number of mixtures instead of finding a universal model for predicting mixture porosities [
14,
15].
In the past decades, machine learning algorithms have been widely used to solve problems which have multiple variables with no clear relations. Various models have been developed in industrial design [
16], disease diagnosis [
17], engineering analysis [
18], material optimization [
19,
20,
21], etc., which validated the high accuracy and the universal application of machine learning algorithms. Back Propagation Neural Network algorithm (BPNN), which is a multilayer feedforward neural network trained according to the error back propagation algorithm, is one of the most widely used algorithms. There are some advantages to this method: strong nonlinear mapping ability, highly self-learning and adaptive ability, good generalization ability and certain fault-tolerant ability. In recent years, some research efforts have been made in asphalt pavement engineering to study asphalt mixture’s volumetric properties, gradations and asphalt contents with the BPNN [
20,
22,
23]. Additionally, the BPNN-based methods were also used for the prediction of cement concrete compression strength [
24,
25,
26]. As demonstrated in the literature, the BPNN was useful and efficient in solving asphalt or concrete pavement problems.
Obviously, the BP models have advantages for predicting mixture porosities. However, a reliable database which has enough data is one of the key requirements for using such a BP model. It is hard to obtain such a consistent database with the traditional experimental methods since their testing results are dependent on the testing methods, materials, specification and so on. One advantage of the DEM-based modeling approaches is lab-independent. First of all, with the DEM model, users can control one or a few key factors without effects from the other factors. For instance, it is possible to build a DEM model of mixture where all the particles have identical shapes if one wants to explore effects of gradations without influences of particle shapes. As a result, it is possible to obtain consistent results which stick to certain conditions. Secondly, limited by materials and testing conditions, it is very difficult to obtain a large amount of consistent experimental data. With the DEM model, however, it becomes possible to obtain a large amount of data as long as one has the DEM modeling techniques and computer facilities.
Against the background discussed above, the main objectives of this research are to explore the prediction of granular materials’ porosities by combining the DEM simulation and the BPNN methods. The granular materials in this research refer to mineral aggregates whose sizes range from 2.36 mm to 19 mm. They are key constituents of asphalt mixtures which take over 90% of the overall mass and their porosities may significantly impact mixture volumetric and mechanical properties [
27,
28]. Compared to aggregates, asphalt acts more like lubricant during the compaction stage and its impact to mixture porosity can be ignored in this article [
12,
29]. According to the Chinese specifications, mixtures whose maximum particle sizes are from 13.2 mm to 19.0 mm are popularly used as high-quality pavement construction. As demonstrated in the previous research [
13,
30], both gradations and particle shapes could have certain impacts on mixture volumetric properties. When both gradations and particle shapes are considered simultaneously, it is not easy to make a consistent conclusion. Therefore, in this article the aggregate gradations were selected as the major control parameters, while the particle shapes were considered as minor parameters by introducing a reduction factor.
3. Data analysis and BP Neural Network Model Building
MATLAB software included plenty of useful functions of neural network algorithm in the Neural Network Toolbox as shown in the literature [
32]. These functions provide the possibility to build a basic model for those not professional at machine learning. Therefore, the BPNN models in this article were built with “newff” function in Neural Network Toolbox of MATLAB, which is easy for reference.
In general, the BP neural network model includes an input layer, an output layer and multiple hidden layers. The previous research shows that the three layer BP neural network with one hidden layer can approximate any non-linear function [
32]. Hence, the model in this article was established with one hidden layer and the model structure is shown in
Figure 4.
In the BP model, there are three kinds of key parameters: (1) input and output variables; (2) transfer function; (3) the number of hidden layer nodes and their corresponding weight thresholds. Through the above three parameters, a complete BP neural network prediction model can be obtained and calculated through Equation (1).
where (1)
represents model input variables (particle volume fraction of different particle size groups);
represents model output result; k represents the number of input variables in the range of 1 to m; m represents the total number of input variables, four for Gradation-13 and five for Gradation-16; (2)
refers to transfer function; (3)
i represents the number of hidden layer nodes in the range of 1 to
n;
n refers to the total number of hidden layer nodes;
represents weight from input layer to hidden layer;
refers to weight from hidden layer to output layer;
represents threshold from input layer to hidden layer;
represents threshold from hidden layer to output layer.
In addition, in order to evaluate model training accuracy, Mean Square Error (MSE) and coefficient of determination (
) of the output results are applied and MSE can be calculated according to Equation (2).
where
represents the test value and
represents the real value. Meanwhile,
n refers to the test set sample number.
In “newff” function, there are not too many parameters to be determined. Hence, all of them are listed in the following
Table 8.
Because of the high relativity between gradation and mixture porosity, the prediction accuracy was great enough when the default functions were applied. In order to simplify the procedures of building the prediction model, the default transfer functions were finally determined. It should be noted that the determination of other key parameters is illustrated in the following Chapter 3.1, Input and output variables processing.
3.1. Input and Output Variables Processing
For the model in this article, the input layer contains four variables (i.e., particle volume fraction of 13.2–16.0 mm, 9.5–13.2 mm, 4.75–9.5 mm and 2.36–4.75 mm) for Gradation-13 and five variables for Gradation-16, and output layer includes the only dependent variable, porosity, for both gradation types.
The first and foremost step in BP neural network modeling is to process the original input data. Because the recorded data are relatively close to each other in the whole range of 0.30–0.45, it is necessary to standardize the original data and transfer variables into the range of [–1, 1] according to Equation (3). Meanwhile, the original gradation should also be processed through Equation (3). This procedure can achieve the best performance for modeling.
where
and
represent 1 and −1 respectively in this article, while
and
refer to the maximum and minimum value of recorded porosity and
refers to original porosity, while
refers to standardized porosity.
Through the above equation, the procedure for standardizing the input variables includes these three parts: (1) finding maximum and minimum values in the recorded porosity as and ; (2) calculating each standardized porosity () value through Equation (3); (3) recording standardized porosity () values.
The next step is to divide the available data set into two groups, one for training and another for testing the developed model. Meanwhile, the testing set will not be used in the model training process. It should be noted that grouping is done randomly. In this study, 200 particle compositions and corresponding porosity for both Gradation-13 and Gradation-16 were randomly divided into training and testing groups.
Finally, the output results still need to be anti-standardized in a similar way by following Equation (4):
where,
and
refer to the maximum and minimum value of recorded porosity and
refers to prediction porosity, while
refers to standardized prediction porosity.
The standardized and anti-standardized can be completed automatically by function “mapminmax” in MATLAB only if the original data is inputted.
3.2. Transfer Function Determination
There are three transfer functions commonly used in the BP neural network model and these functions are applied in the hidden and output layer. The default transfer functions in “newff” function include a hyperbolic tangent function(“tansig”) in hidden layer as shown in Equation (5) and a pure linear function(“purelin”) in the output layer in Equation (6).
The final prediction formula can be obtained by training the model to determine the appropriate parameters. Among these parameters, the number of hidden layer nodes should be tested by user. The other corresponding parameters could be determined automatically.
3.3. Hidden Layer Node Number Determination
Generally, the model accuracy will be improved by increasing the training sample size. However, when the sample size is large enough, even more data cannot improve the model performance. For the purpose of studying the relationship between original sample size and training model performance, different training sample sizes were tested and compared. The mean square error (MSE) and coefficient of determination (R2) between prediction value and virtual test value were calculated to evaluate the accuracy and stability of final prediction model. Seven models for Gradation-13 were built in this article with sample sizes of 25, 50, 75, 100, 125, 150 and 175 respectively. For all seven models, 25 samples were applied as the testing group to check the model performance by calculating R2.
For the BP model, except for training sample size, the hidden layer node number also plays a significant role in model training. According to empirical Equation (7), the range of node number is set as 3 to 13.
where,
m and
n refer to the number of input and output layer nodes respectively and a refers to a regulating constant in the range of 1 to 10. For each group, 10 parallel tests were carried out to determine the optimum node number. The detailed procedure is omitted in this article since it was introduced in another publication [
32]. The following
Figure 5 shows that coefficient of determination (R
2) changes with node number.
It can be observed that: (1) the optimum node number can be different for different models; (2) with training sample size increasing, model performance is less sensitive to node number. The optimum hidden layer node number for all seven groups are shown in the following
Table 9.
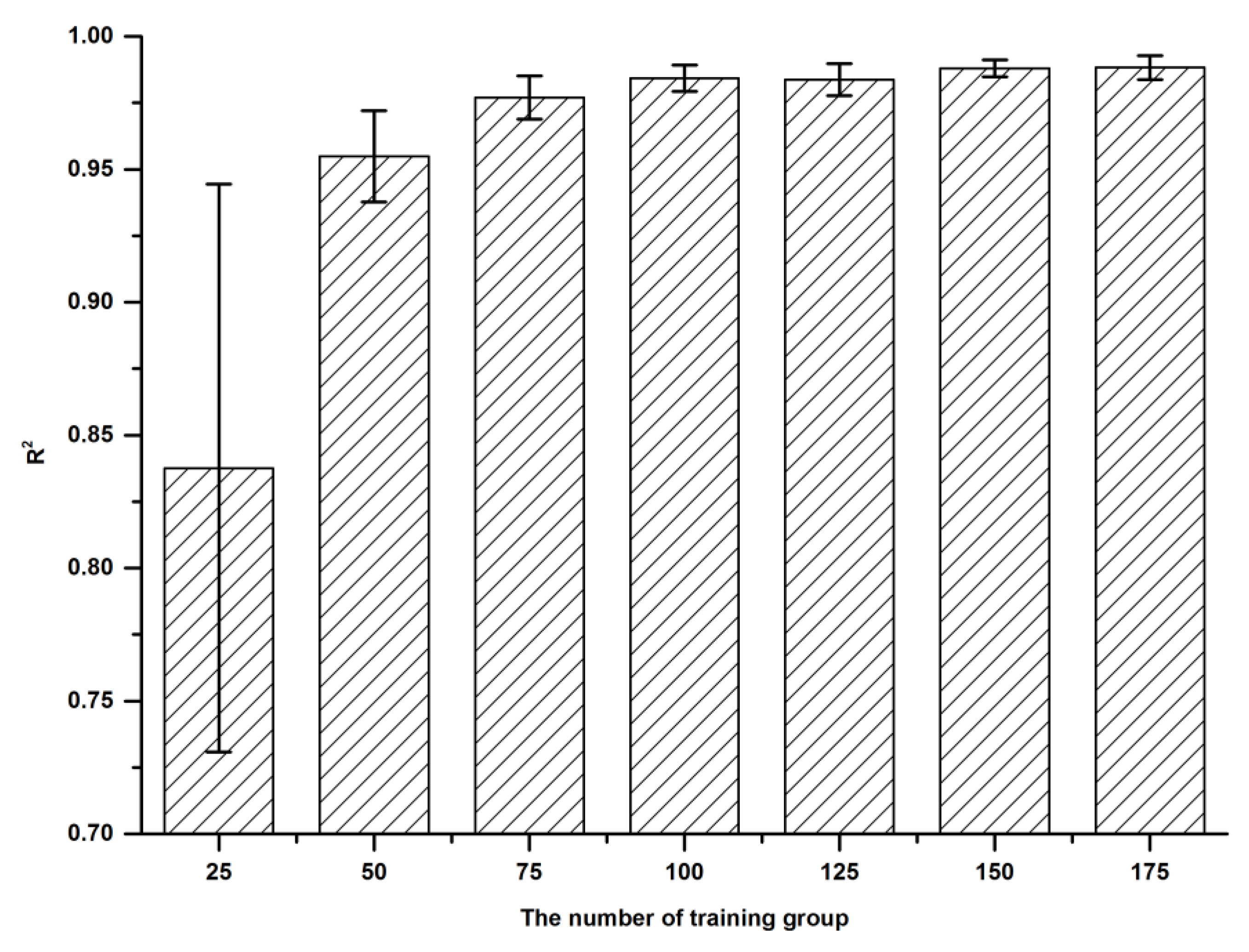
Meanwhile, the following
Figure 6 shows the R
2 for different models based on their optimum node number. The error bars here represent standard deviation.
From this figure, it is clear that with the increase of training group sizes, R2 rises sharply in the initial stage. After the number of training groups goes up to more than 75, the growth rate of R2 becomes very small. Meanwhile, for model accuracy, when the amount of training data is too small, the model error is very large. With the increase of training data size, the model tends to be more stable. In this state, a more accurate prediction model can be obtained.
Based on the above analysis, the number of training sets was recommended as 75 or 100, considering training accuracy and efficiency. Meanwhile, the best number of testing sets is about 1/2–1/3 of the training set.
3.4. Testing Results
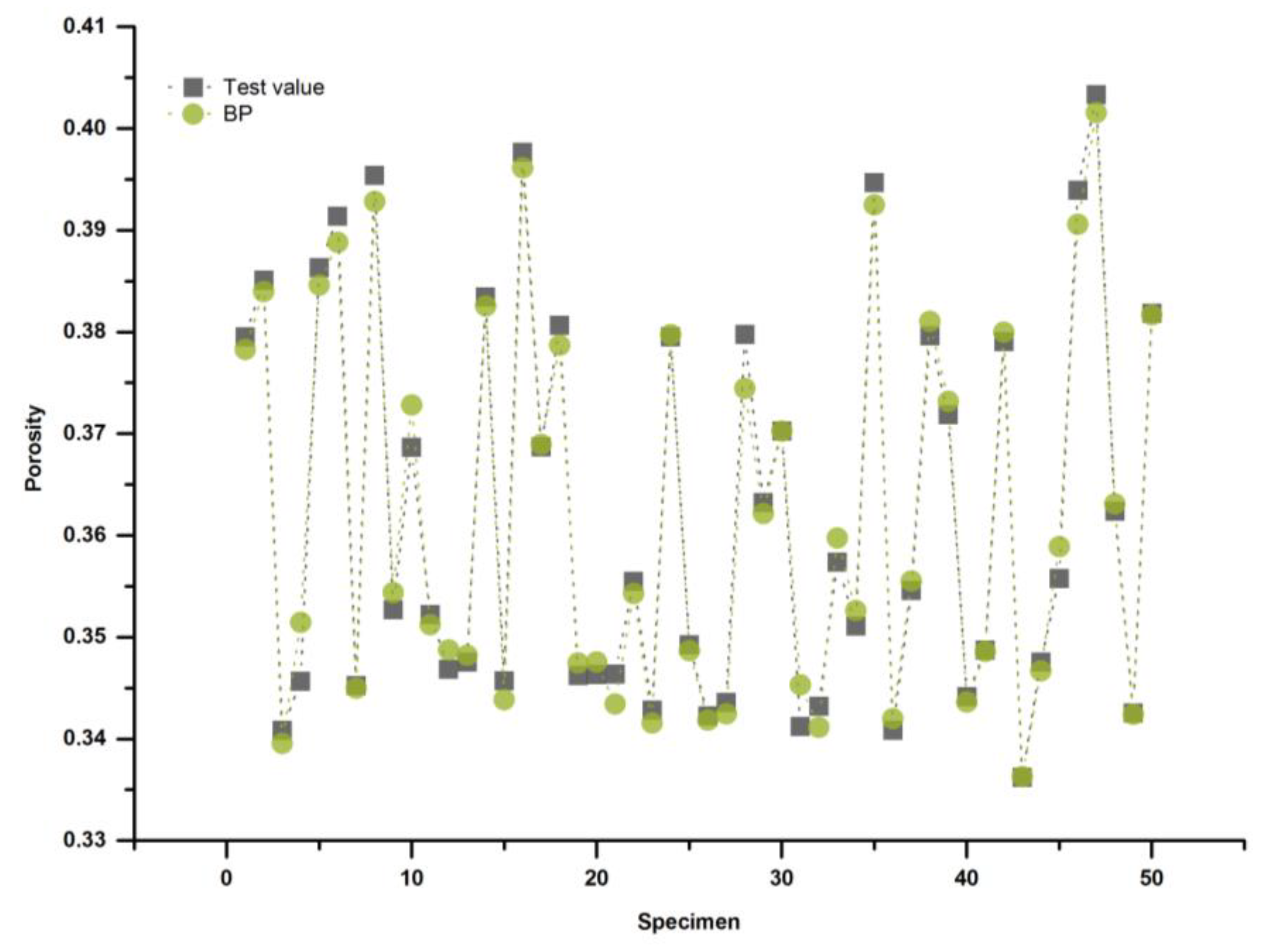
On the basis of the existing database, 150 groups were used as the training group and 50 groups were applied as the testing group to build the BP neural network model. The training results are shown in
Figure 7 for Gradation-13 and
Figure 8 for Gradation-16.
In the process of data transmission, through repeated training, four hidden layer nodes for Gradation-13 and five nodes for Gradation-16 were finally determined as the most suitable number of hidden layer nodes.
For two models, their coefficients of determination both achieve 99%, which means porosity prediction models have enough accuracy to provide reliable results.
In addition, all the related parameters applied in model training are listed in the following tables.
Table 10 and
Table 11 provide the gradation and porosity normalization parameters (
for Gradation-13 and Gradation-16. Through these parameters, the original gradation and porosity data could be normalized according to Equation (3). Then, the weights and thresholds used to transfer data from the input layer to the hidden layer are shown in
Table 12, while those parameters from the hidden layer to the output layer are shown in
Table 13.
The complete prediction calculation process is listed as follows:
Through the above steps, the porosity of a certain kind of particulate mixture can be accurately predicted.
4. Verification and Application of Prediction Method
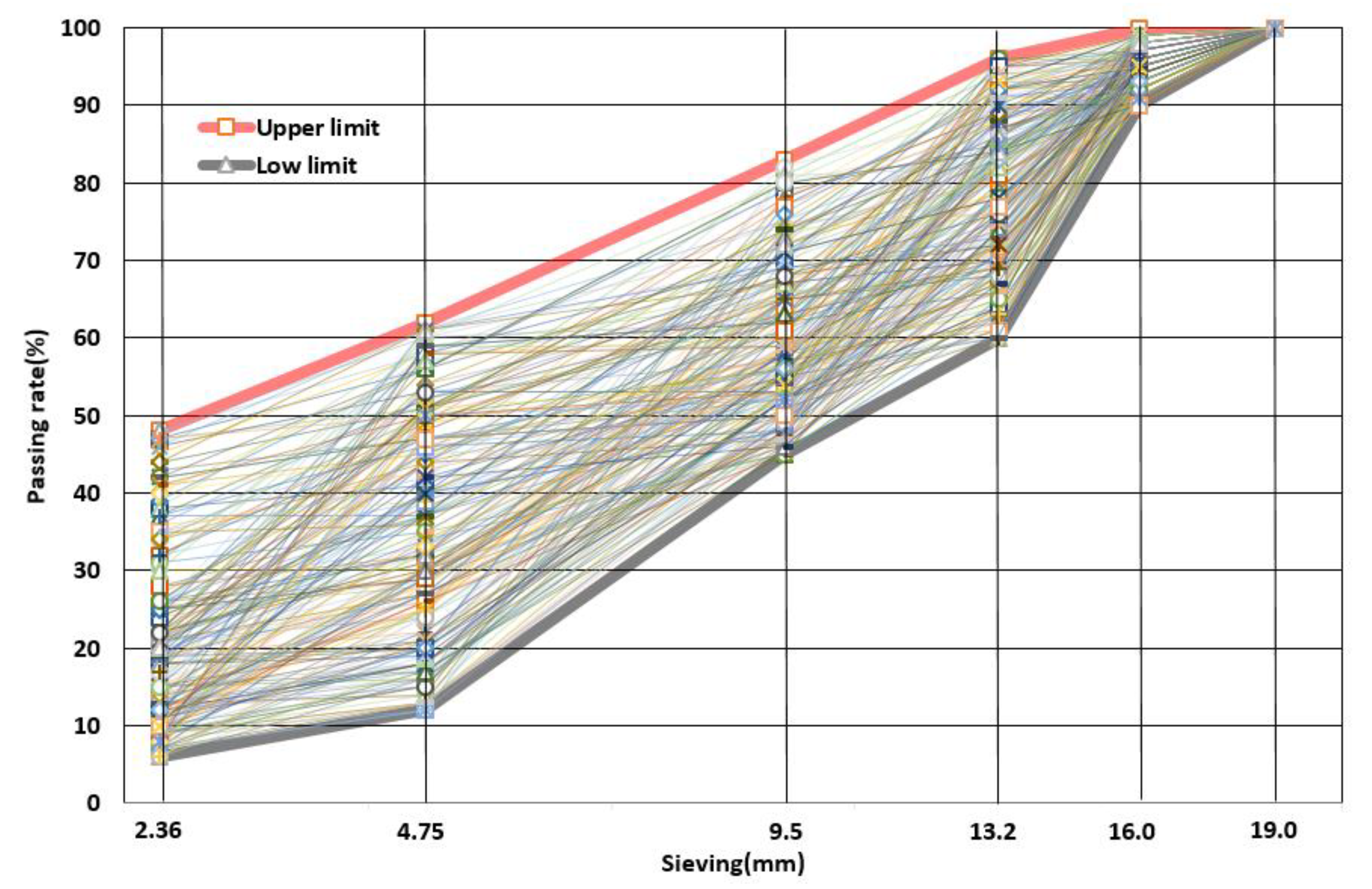
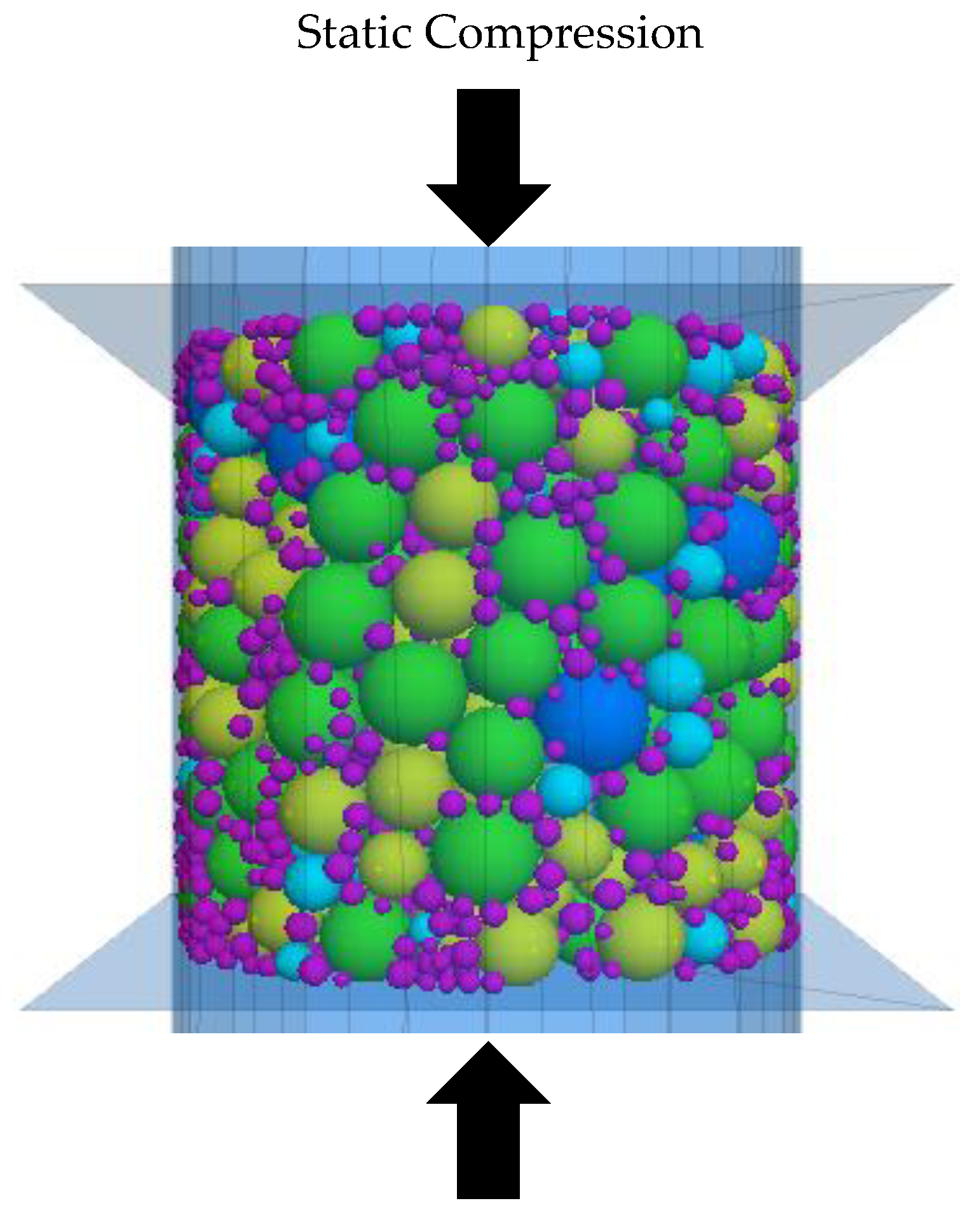
For the purpose of evaluating model validity and accuracy, a static compression test was also completed in laboratory. The steel balls were used to compare with the virtual ball element model. Meanwhile, the relationship among the measured porosity, the simulated porosity and the predicted value was compared. In order to simulate the real composition of granular particles applied in highway engineering, a great number of steel balls in different sizes were prepared and mixed in the same proportion as uniformly as possible, then sieved to several different size groups. The original particle size distribution and sieved results of the steel balls are shown in
Table 14 and
Figure 9.
According to
Table 14 and
Figure 9, every sieving group was mixed with several different particle size groups uniformly. For 9.5–13.2 mm group, 13.0 mm particles were not found, so 12.303 mm balls were added to keep a continuous and real size distribution in the steel balls.
Then, in order to make the results of laboratory and DEM comparable, the size of steel ball experiments’ container was exactly the same as the DEM model. According to different gradations, the steel balls were mixed in a standard Marshall mold, whose diameter was 100 mm as shown in
Figure 10. Because there was no filler or binder in this mixture, universal testing machine were applied to compact the mixed steel balls with a static pressure of 600 kPa. Meanwhile, particles’ total volume was measured by the displacement method. On the other hand, virtual compression tests on computer and porosity prediction on BP neural network model were completed at the same time. The detailed test data is shown in the following
Figure 11.
As can be seen from the above figure, model prediction accuracy for the steel ball test was very high and model error was extremely slight. The maximum relative error of prediction was no more than 1.15%. This proved the credibility of the prediction model. Meanwhile, the results of lab tests and virtual tests were very close, which also proved that for the sphere element-based model, sufficient credible raw data could be obtained by DEM.
5. Reduction Factor Analysis Considering Particle Shape Effect on Mixture Porosity
From the above illustration, a porosity prediction model for sphere element has been established. However, as mentioned in the Introduction, paving materials in reality generally have complex but similar particle shape combinations, which indicate that shape effect is non-negligible but consistent. Therefore, a reduction factor to consider particle shape effect was introduced in this chapter.
A gradation was selected randomly for comparing the mixture porosity between sphere elements model and real aggregate shape model. The volume of each particle size group was:
A total number of 15 DEM models with different real aggregated shapes were built based on previous researches [
33,
34,
35,
36,
37]. It should be noted that there is only one particle shape in each specimen to amplify its effect, as shown in
Figure 12.
All the aggregate shapes used in this chapter were quite common. Although there are some special shapes in civil engineering, for instance, elongated particle, their volume percentages in mixture were generally low and strictly controlled, due to their poor engineering properties. The model parameters were identical with sphere element-based models. In this way, these mixtures’ porosities were recorded and plotted on the following
Figure 13.
From
Figure 13, the red line represents the mixture porosity of the sphere elements-based model, which was 0.381, while the green points refer to 15 mixture porosities in 15 real aggregate shapes respectively. It can be observed that there is an obvious difference between these two models. Nevertheless, this difference is quite stable and consistent among 15 green points. Detailed statistical analysis has been done as shown in the following
Table 15.
From
Table 15, 95% confidence interval has been determined and plotted as shown in
Figure 13. Therefore, a shape reduction factor range was recommended considering the shape effect through Equations (10) and (11).
When the prediction results based on sphere element models are multiplied by shape reduction factor, a more accurate result could be obtained.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}