Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor





Abstract
:1. Introduction
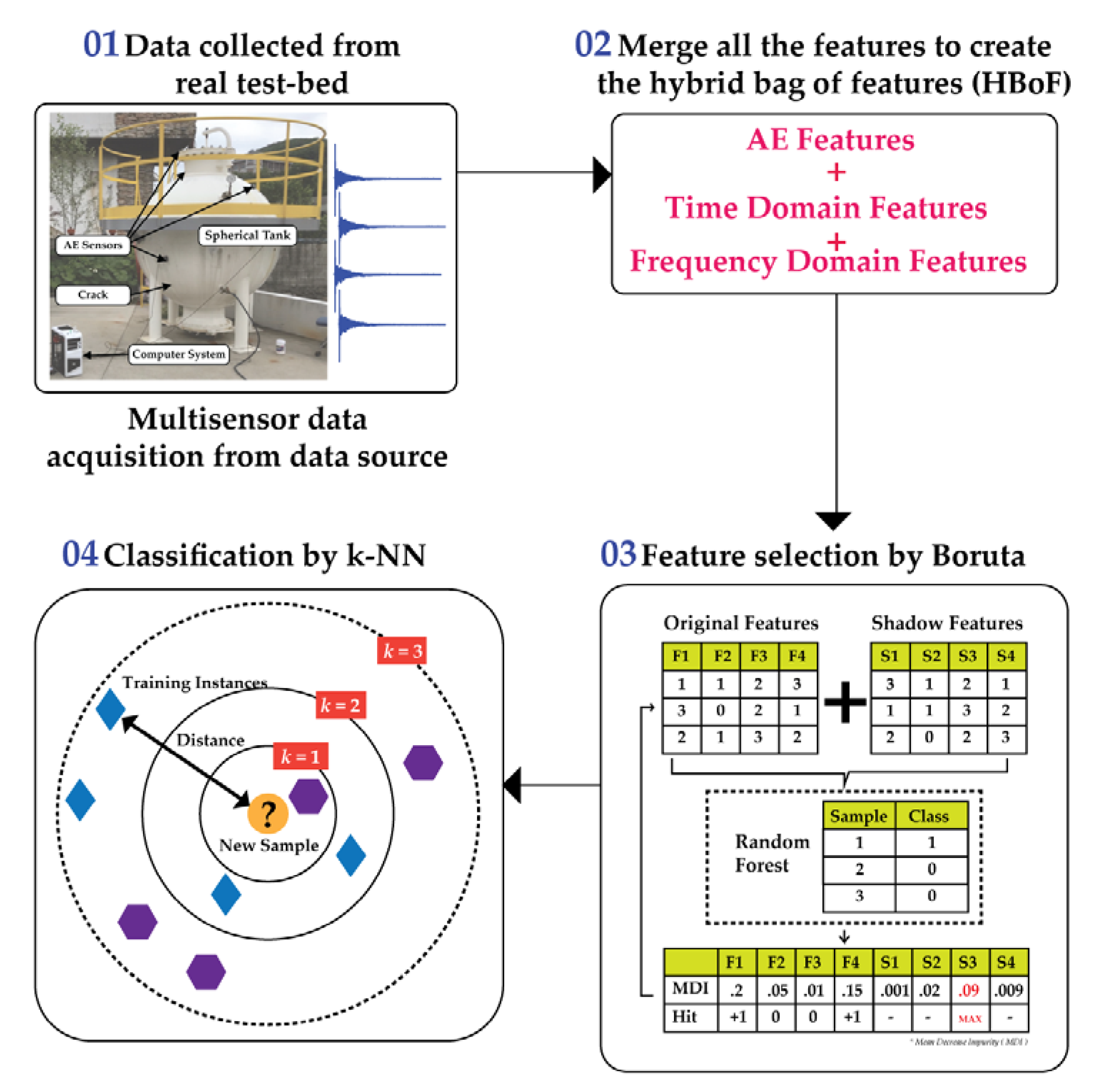
- An HBoF extraction method is designed by combining two types of analysis: (a) analysis of the properties of the AE domain from signals and (b) analysis of the statistical properties from time-domain and frequency-domain of the signal,
- A non-redundant feature selection method based on wrapper principle, Boruta, is utilized to analyze the HBoF to capture the final features,
- Finally, by using those features by Boruta selection as and input, the k-NN is applied for final multi-class classification.
2. Methodology
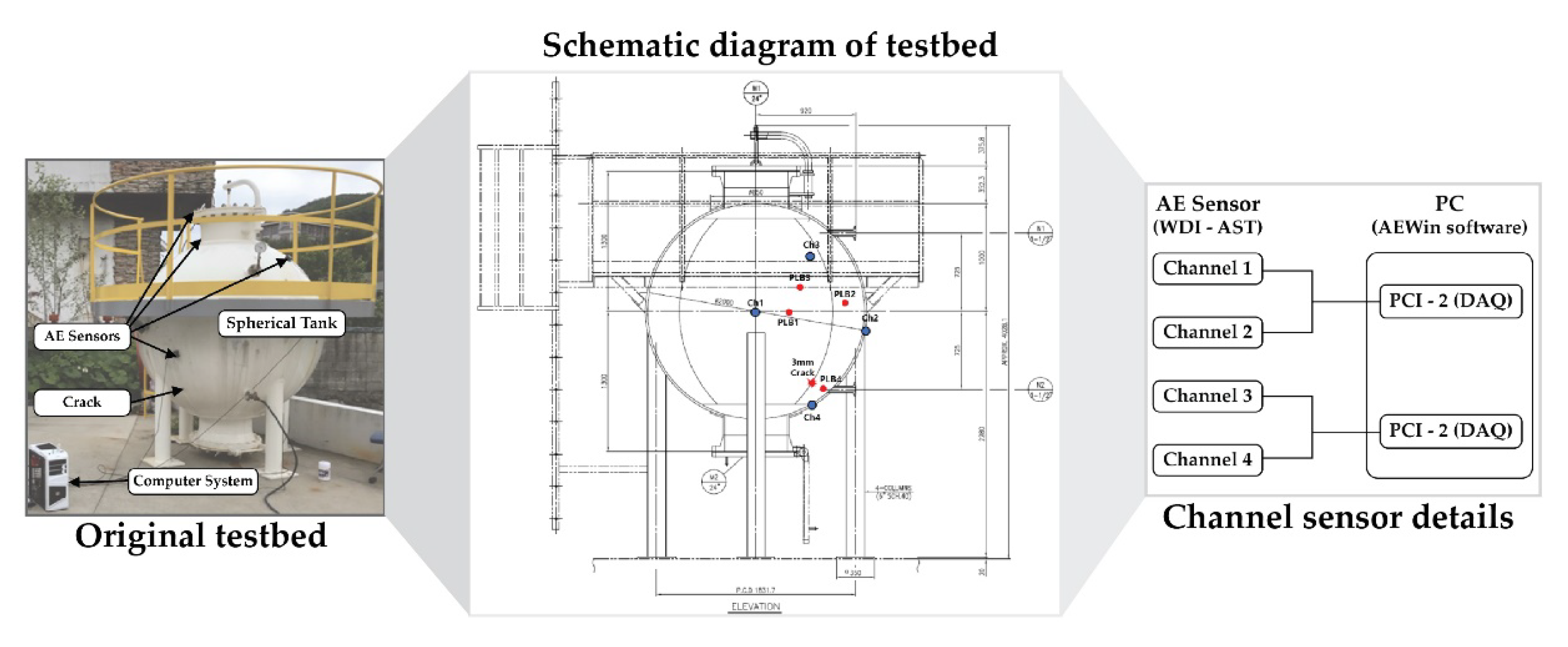
2.1. Data Acquisition Set-Up
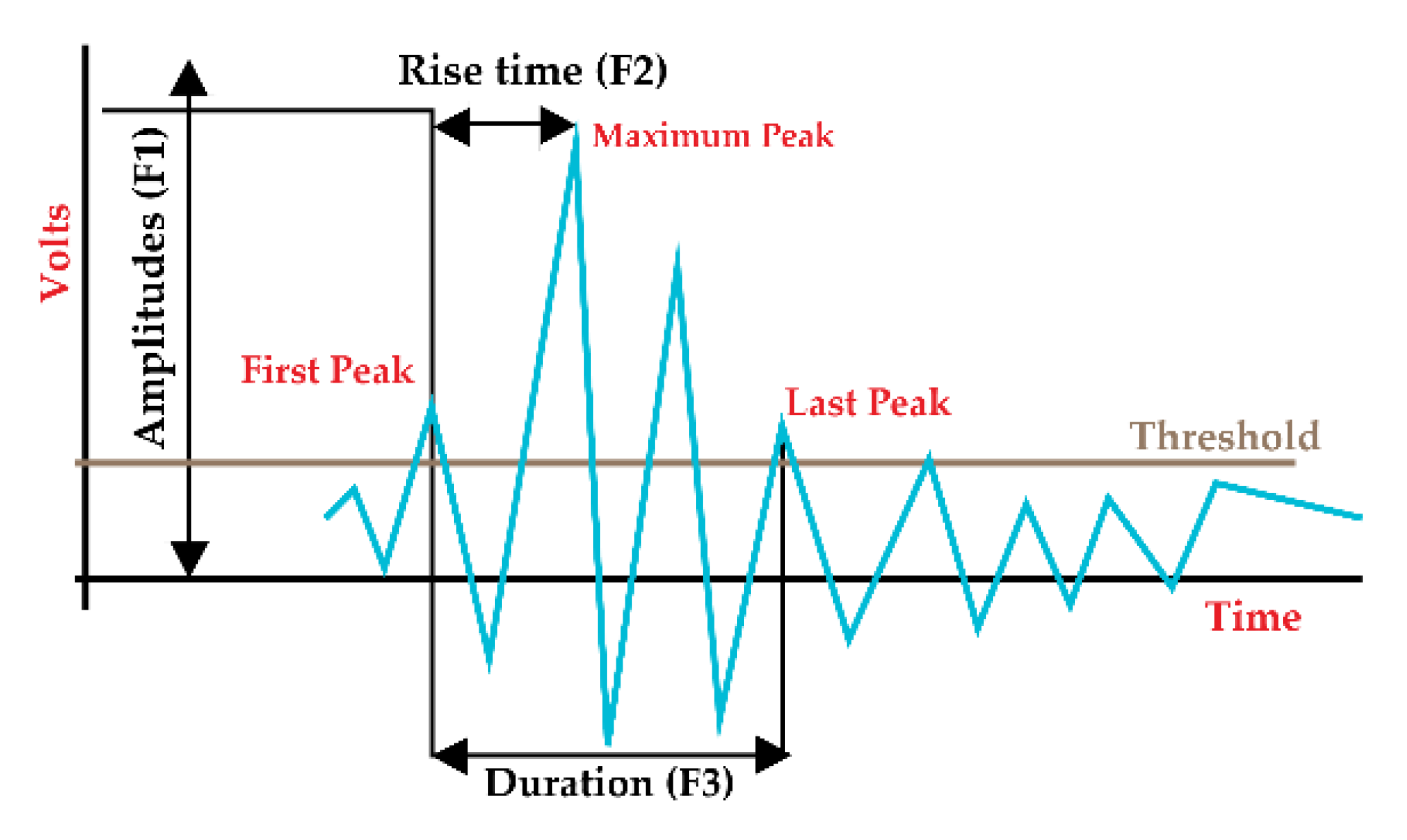
2.2. Hybrid Bag of Features (HBoF)
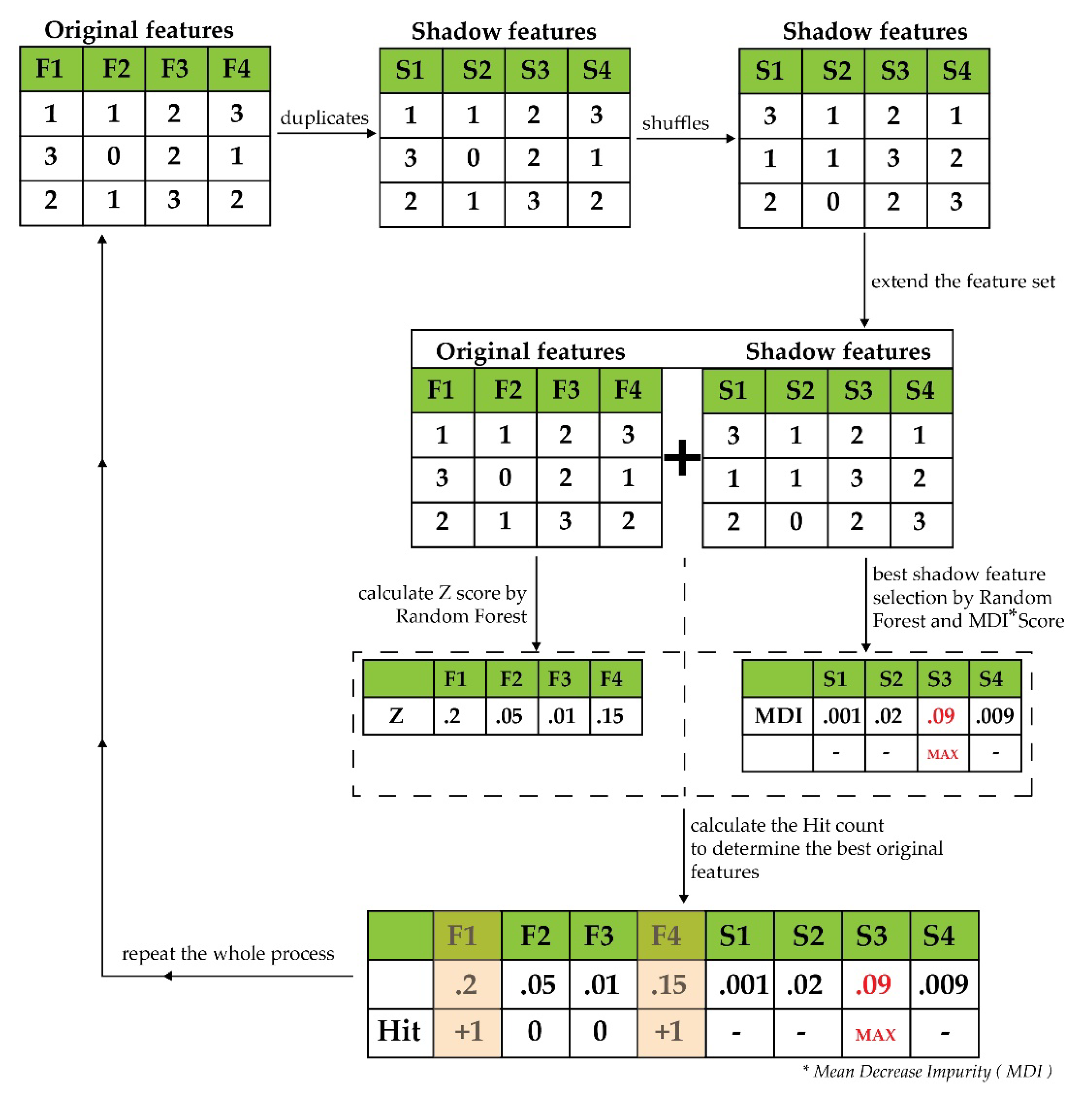
2.3. Feature Selection by Boruta
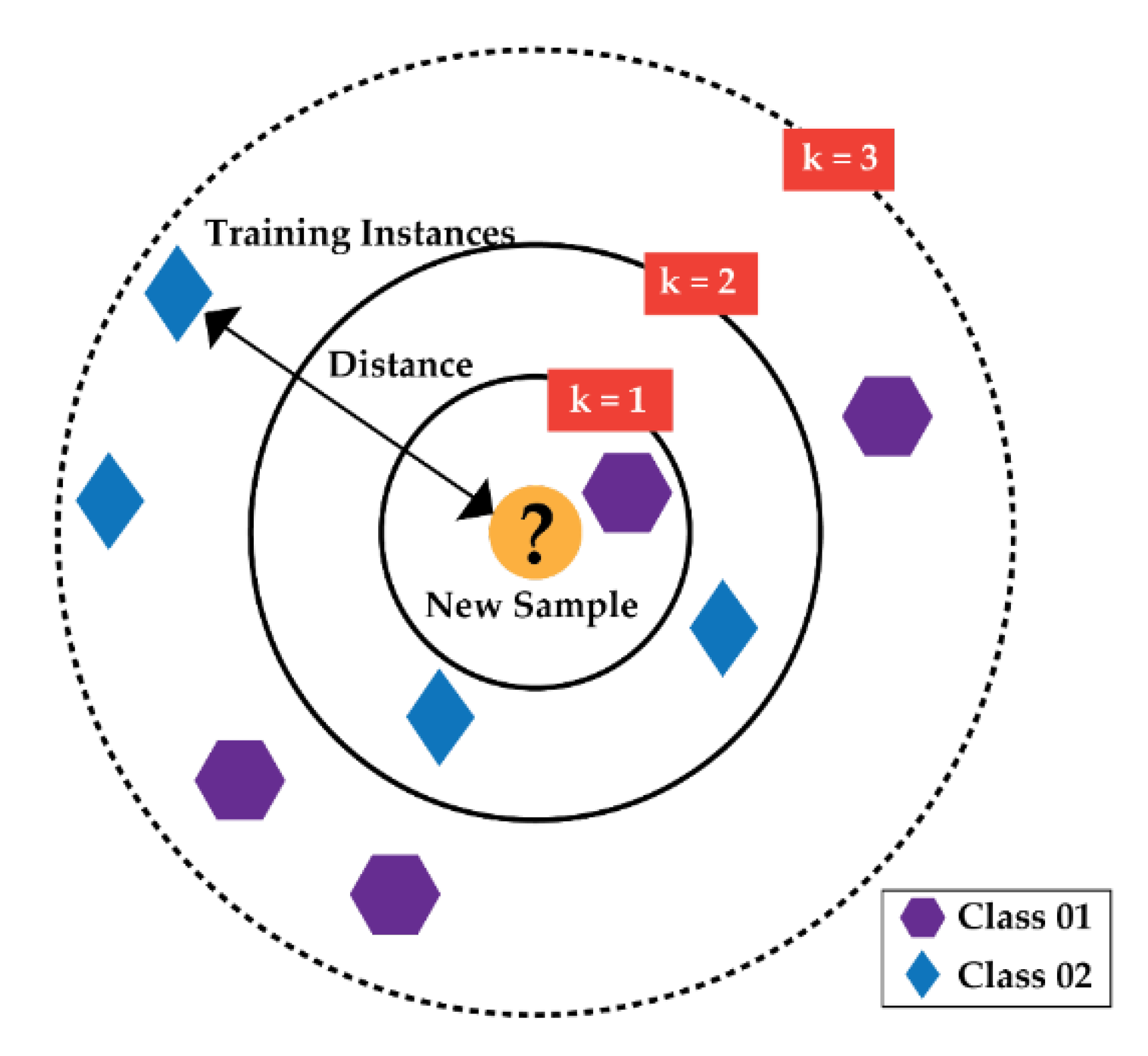
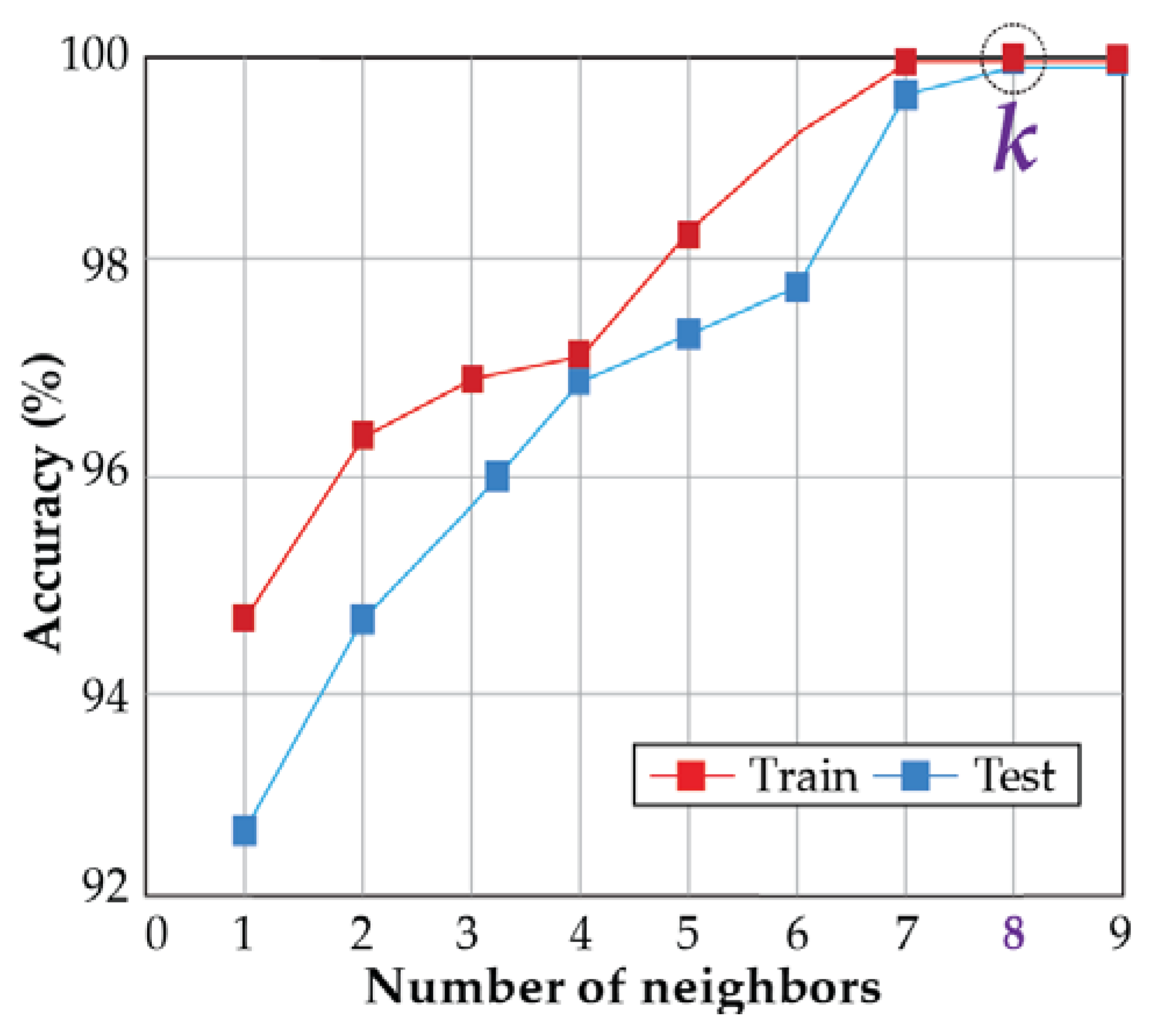
2.4. K-Nearest Neighbor Algorithm Based Classification
3. Result Analysis and Comparative Discussions
3.1. Dataset Description
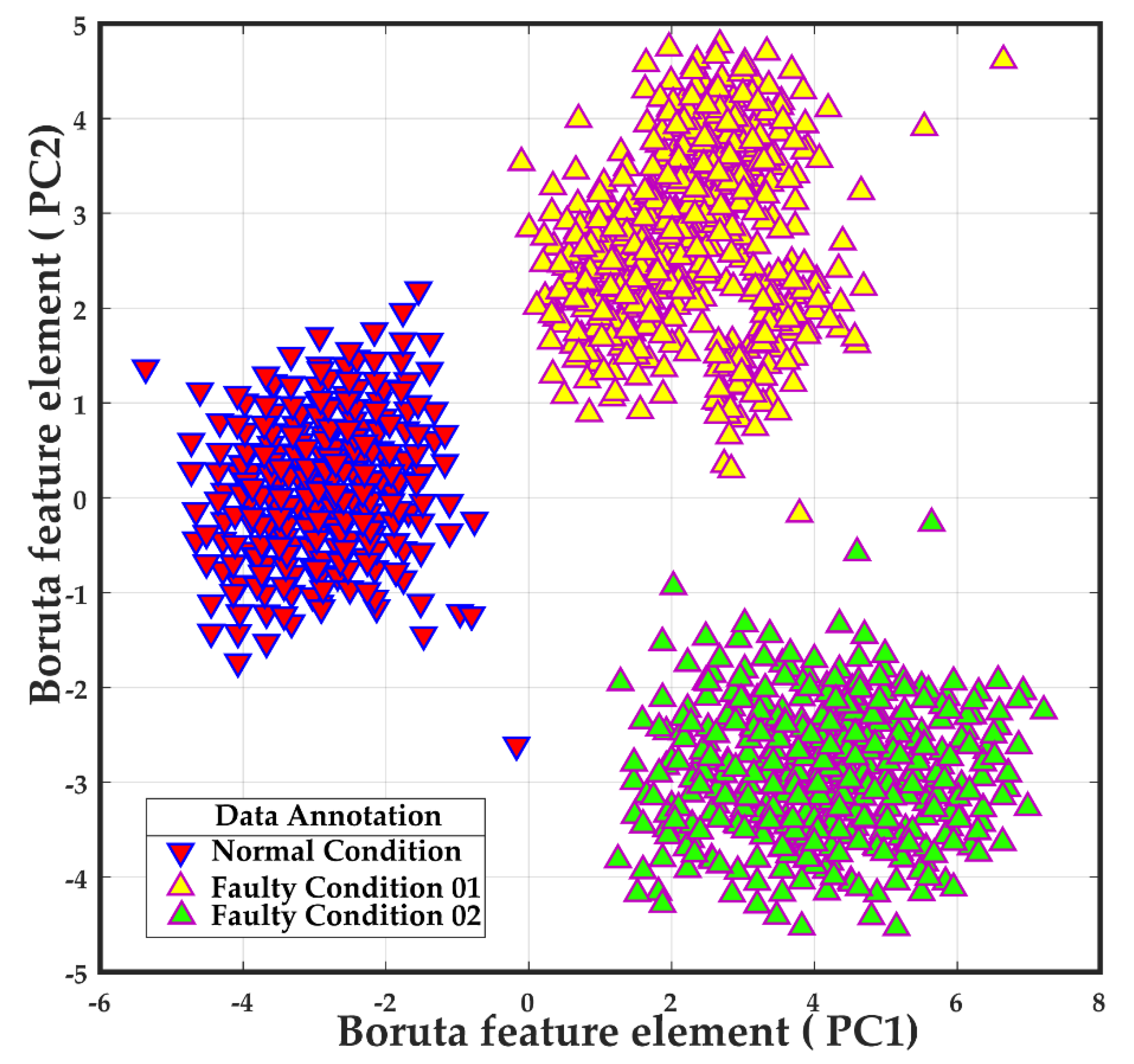
3.2. Performance Analysis of the Feature Selector Boruta
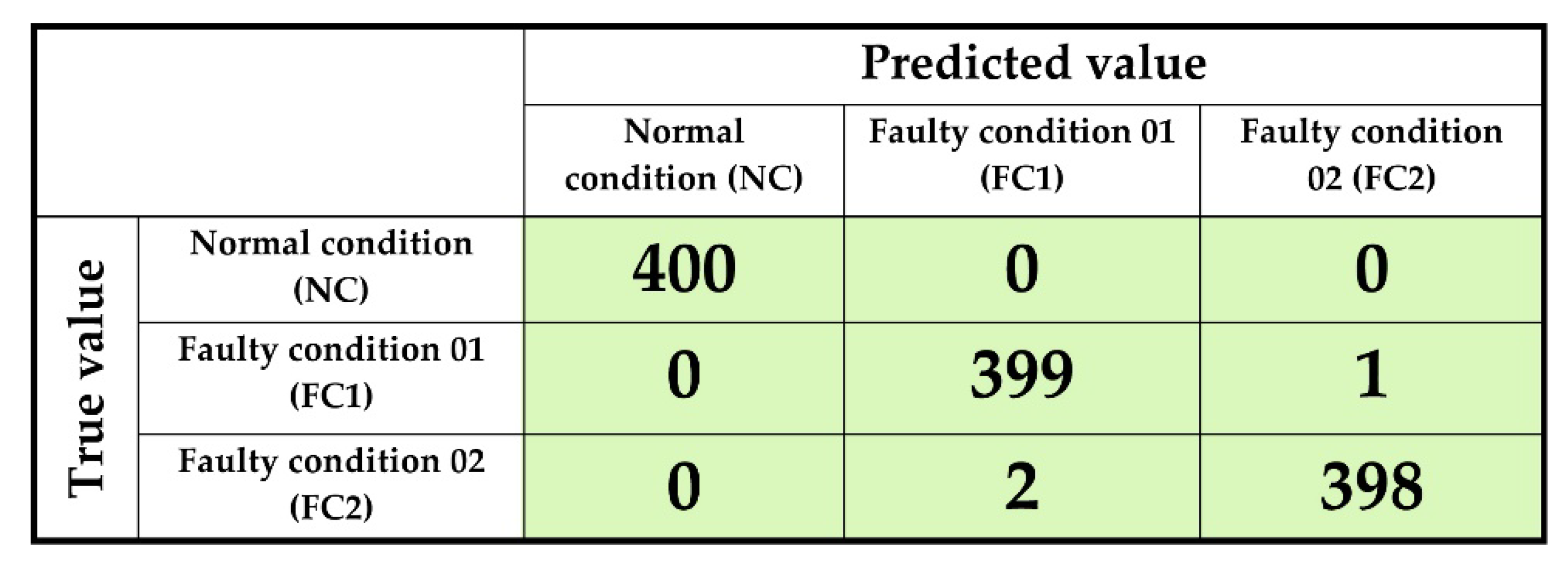
3.3. Diagnostic Performance Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Saidur, R. A review on electrical motors energy use and energy savings. Renew. Sustain. Energy Rev. 2010, 14, 877–898. [Google Scholar] [CrossRef]
- Morofuji, K.; Tsui, N.; Yamada, M.; Maie, A.; Yuyama, S.; Li, Z.W. Quantitative Study of Acoustic Emission Due To Leaks from Water Tanks. Group 2003, 21, 213–222. [Google Scholar]
- Luo, T.; Wu, C.; Duan, L. Fishbone diagram and risk matrix analysis method and its application in safety assessment of natural gas spherical tank. J. Clean. Prod. 2018, 174, 296–304. [Google Scholar] [CrossRef]
- Korkmaz, K.A.; Sari, A.; Carhoglu, A.I. Seismic risk assessment of storage tanks in Turkish industrial facilities. J. Loss Prev. Process Ind. 2011, 24, 314–320. [Google Scholar] [CrossRef]
- Li, W.; Dai, G.; Wang, Y.; Long, F. Study of Tank Acoustic Emission Testing Signals Analysis Method Based on Wavelet Neural Network. In Proceedings of the ASME 2011 Pressure Vessels and Piping Conference, Baltimore, MD, USA, 17–21 July 2011; ASME: New York, NY, USA, 2011; Volume 1, pp. 699–703. [Google Scholar]
- Amar, M.; Gondal, I.; Wilson, C. Vibration spectrum imaging: A novel bearing fault classification approach. IEEE Trans. Ind. Electron. 2015, 62, 494–502. [Google Scholar] [CrossRef]
- Sohaib, M.; Islam, M.; Kim, J.; Jeon, D.-C.; Kim, J.-M. Leakage Detection of a Spherical Water Storage Tank in a Chemical Industry Using Acoustic Emissions. Appl. Sci. 2019, 9, 196. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.; Sohaib, M.; Kim, J.; Kim, J.-M. Crack Classification of a Pressure Vessel Using Feature Selection and Deep Learning Methods. Sensors 2018, 18, 4379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sohaib, M.; Kim, C.-H.; Kim, J.-M. A Hybrid Feature Model and Deep-Learning-Based Bearing Fault Diagnosis. Sensors 2017, 17, 2876. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hasan, M.J.; Sohaib, M.; Kim, J.M. 1D CNN-based transfer learning model for bearing fault diagnosis under variable working conditions. In Proceedings of the Advances in Intelligent Systems and Computing, Changsha, China, 18–20 October 2019; Volume 888, pp. 13–23. [Google Scholar]
- Hasan, M.; Kim, J.-M. A Hybrid Feature Pool-Based Emotional Stress State Detection Algorithm Using EEG Signals. Brain Sci. 2019, 9, 376. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Yu, Z.; Liang, X.; Ye, C. Vibration-Based Structural Damage Identification and Evaluation for Cylindrical Shells Using Modified Transfer Entropy Theory. J. Press. Vessel Technol. 2018, 140, 61204–61214. [Google Scholar] [CrossRef]
- Hasan, M.; Kim, J.-M. Fault Detection of a Spherical Tank Using a Genetic Algorithm-Based Hybrid Feature Pool and k-Nearest Neighbor Algorithm. Energies 2019, 12, 991. [Google Scholar] [CrossRef] [Green Version]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Nilsson, R.; Peña, J.M.; Björkegren, J.; Tegnér, J. Consistent feature selection for pattern recognition in polynomial time. J. Mach. Learn. Res. 2007, 8, 589–612. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R news 2002, 2, 18–22. [Google Scholar]
- Pandya, D.H.; Upadhyay, S.H.; Harsha, S.P. Fault diagnosis of rolling element bearing with intrinsic mode function of acoustic emission data using APF-KNN. Expert Syst. Appl. 2013, 40, 4137–4145. [Google Scholar] [CrossRef]
- Yigit, H. A weighting approach for KNN classifier. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–9 November 2013; Volume 1, pp. 228–231. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Equation | Property | Equation | Property | Equation |
|---|---|---|---|---|---|
| F4 | F5 | F6 | |||
| F7 | F8 | ||||
| F9 | F10 | F11 |
| Health Condition | Crack Size (mm) | Channels | Number of Samples | ||
|---|---|---|---|---|---|
| Length (mm) | Width (mm) | Depth (mm) | |||
| Normal Condition (NC) | N/A | N/A | N/A | 4 | 400 |
| Faulty Condition 01 (FC1) | 3 | 0.5 | 0.4 | 4 | 400 |
| Faulty Condition 02 (FC2) | 6 | 0.7 | 0.5 | 4 | 400 |
| Health Types | Class Based Accuracy (%) | Recall Score (%) | F1 Score (%) |
|---|---|---|---|
| Normal Condition (NC) | 100 | 100 | 100 |
| Faulty Condition 01 (FC1) | 99.50 | 99.75 | 99.62 |
| Faulty Condition 02 (FC2) | 99.74 | 99.50 | 99.62 |
| Average | 99.75 | 99.75 | 99.75 |
| Approach | Classification Accuracy (%) | Average Classification Accuracy (%) | Decrement from the Proposed Method (%) | ||
|---|---|---|---|---|---|
| NC | FC1 | FC2 | |||
| Proposed | 100 | 99.5 | 99.7 | 99.7 | - |
| HBof + k-NN | 80 | 68.2 | 59.7 | 69.3 | 30.4 |
| HBof + t-SNE + k-NN | 75.5 | 35 | 34.2 | 48.23 | 51.5 |
| HBoF+ PCA + k-NN | 79.5 | 82.5 | 78.9 | 80.3 | 19.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.J.; Kim, J.; Kim, C.H.; Kim, J.-M. Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor. Appl. Sci. 2020, 10, 2525. https://doi.org/10.3390/app10072525
Hasan MJ, Kim J, Kim CH, Kim J-M. Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor. Applied Sciences. 2020; 10(7):2525. https://doi.org/10.3390/app10072525
Chicago/Turabian StyleHasan, Md Junayed, Jaeyoung Kim, Cheol Hong Kim, and Jong-Myon Kim. 2020. "Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor" Applied Sciences 10, no. 7: 2525. https://doi.org/10.3390/app10072525
APA StyleHasan, M. J., Kim, J., Kim, C. H., & Kim, J.-M. (2020). Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor. Applied Sciences, 10(7), 2525. https://doi.org/10.3390/app10072525