Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks



Abstract
:1. Introduction
2. Methodology
2.1. Selection of CNN Backbone
2.2. Region-Based Object Detection Framework
2.2.1. Faster R-CNN (Region-Based Convolutional Neural Networks)
2.2.2. R-FCN (Region-Based Fully Convolutional Network)
2.2.3. FPN (Feature Pyramid Network)-Based Faster R-CNN
2.3. Combination of Deformable Operation Module
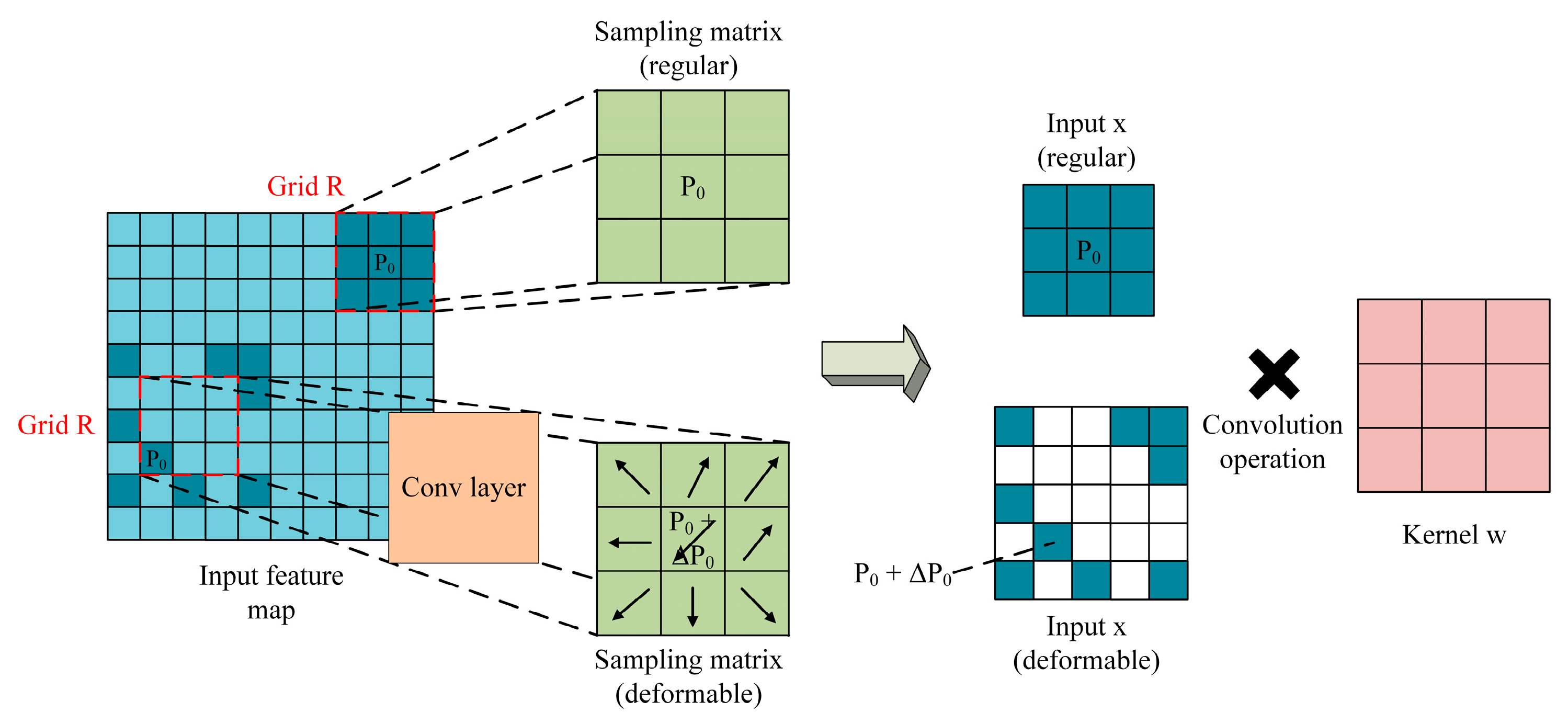
2.3.1. Deformable Convolution
2.3.2. Deformable RoI Pooling
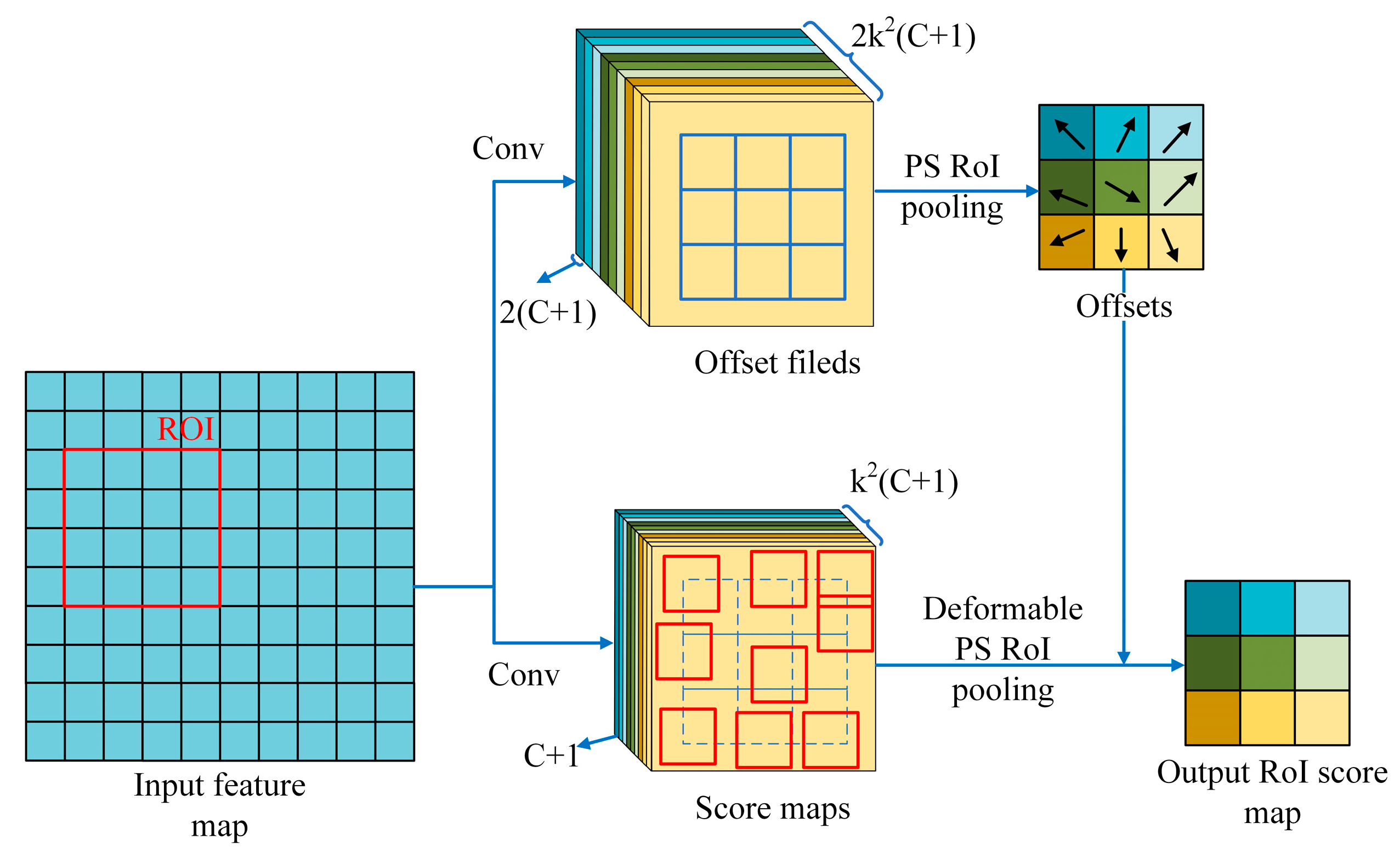
2.3.3. Deformable Position-Sensitive (PS) RoI Pooling
3. Implementation
3.1. Building the Database
3.2. Workstation and Training Settings
3.3. Evaluation Index
4. Discussions and Comparative Study of the Testing Results
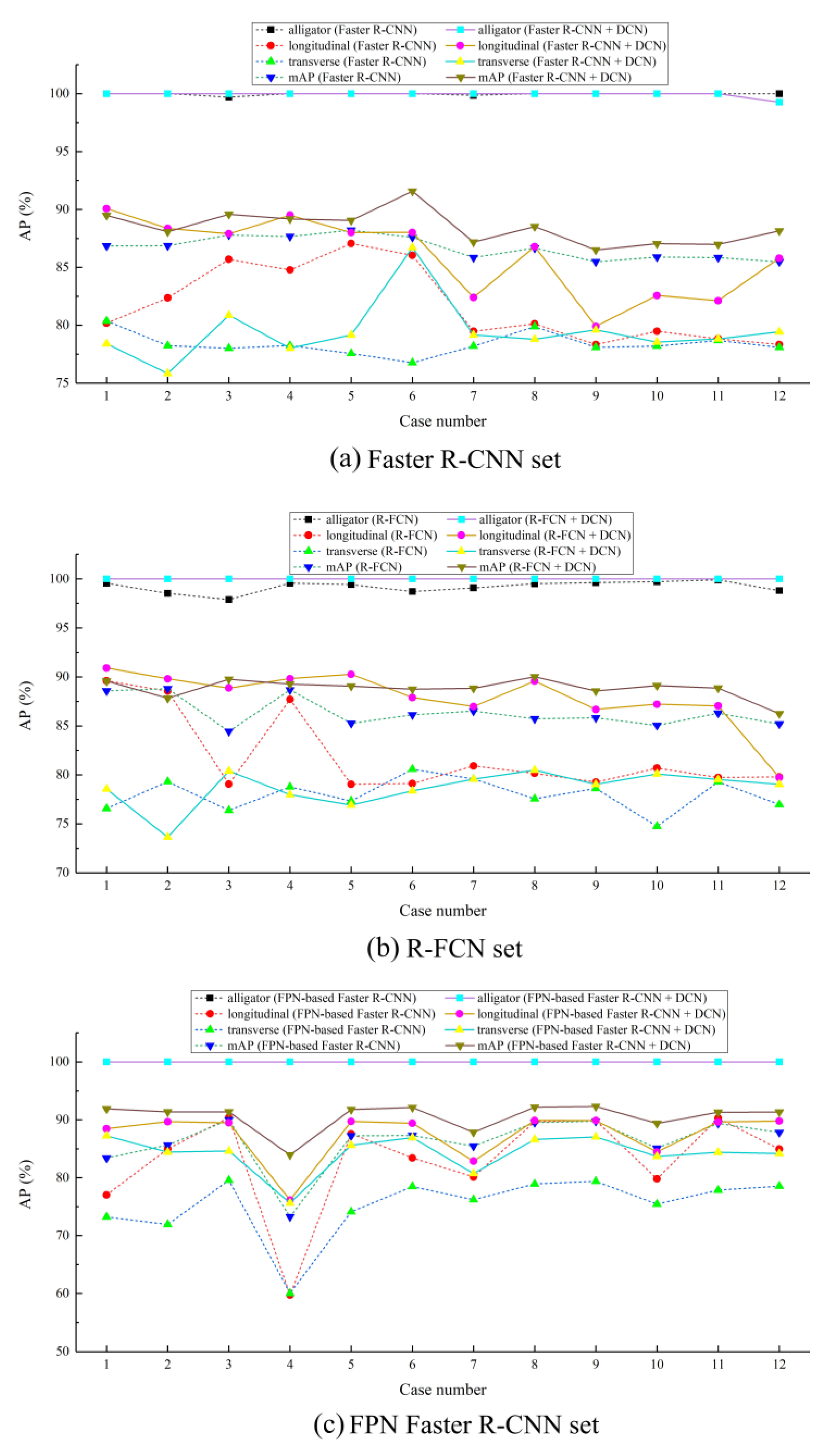
4.1. Training Results Based on Faster R-CNN
4.2. Training Results Based on R-FCN
4.3. Training Results Based on FPN-Based Faster R-CNN
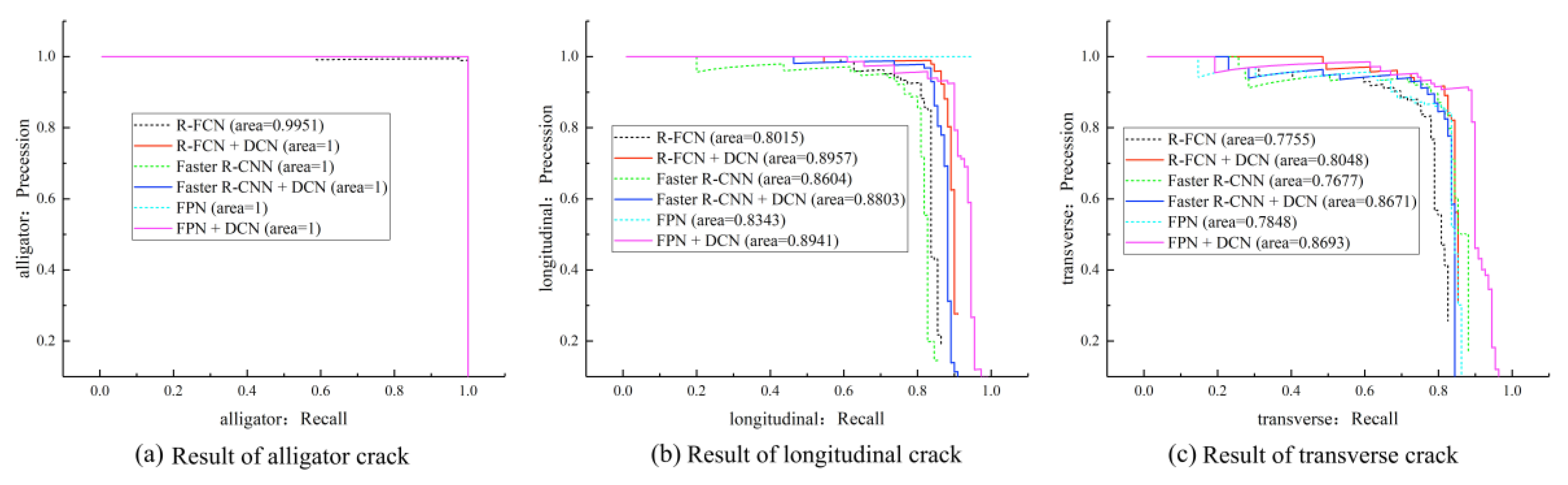
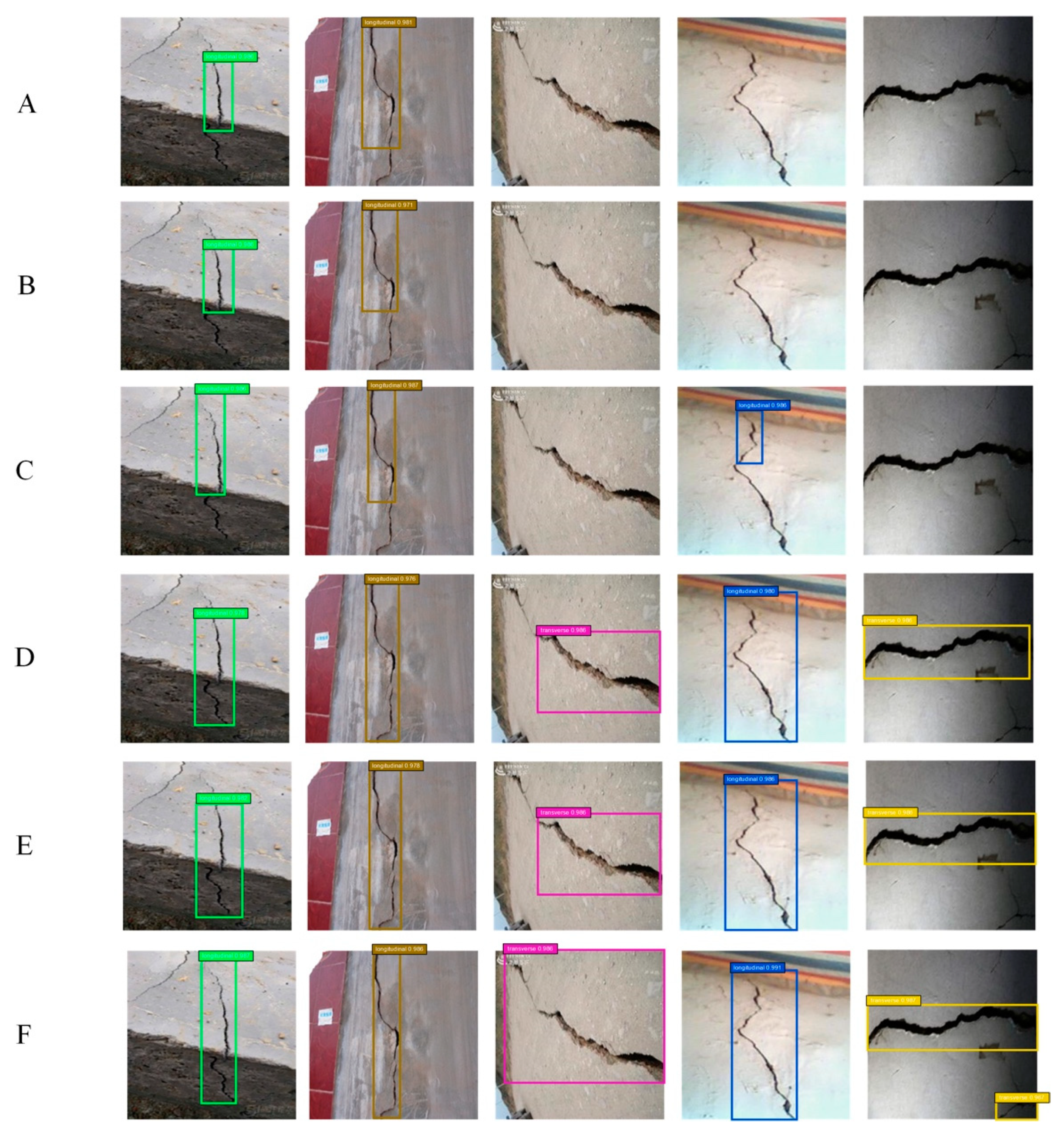
4.4. Analysis and Discussion of the Testing Results
5. Performance on Detecting Cracks with Out-of-Plane Deformation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Zhou, Z.; Zhang, B. Application of bionic crack monitoring in concrete bridges. J. Highw. Transp. Res. Dev. 2012, 6, 44–49. [Google Scholar] [CrossRef]
- Rehman, S.K.U.; Ibrahim, Z.; Memon, S.A.; Jameel, M. Nondestructive test methods for concrete bridges: A review. Constr. Build. Mater. 2016, 107, 58–86. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-T.; Stubbs, N. Nondestructive crack detection algorithm for full-scale bridges. J. Struct. Eng. 2003, 129, 1358–1366. [Google Scholar] [CrossRef]
- Hopwood, T. Acoustic emission inspection of steel bridges. Public Works 1988, 119, 66–70. [Google Scholar]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Ohno, K.; Ohtsu, M. Crack classification in concrete based on acoustic emission. Constr. Build. Mater. 2010, 24, 2339–2346. [Google Scholar] [CrossRef]
- Aggelis, D.G. Classification of cracking mode in concrete by acoustic emission parameters. Mech. Res. Commun. 2011, 38, 153–157. [Google Scholar] [CrossRef]
- Farhidzadeh, A.; Salamone, S.; Singla, P. A probabilistic approach for damage identification and crack mode classification in reinforced concrete structures. J. Intell. Mater. Syst. Struct. 2013, 24, 1722–1735. [Google Scholar] [CrossRef]
- Aldahdooh, M.; Bunnori, N.M. Crack classification in reinforced concrete beams with varying thicknesses by mean of acoustic emission signal features. Constr. Build. Mater. 2013, 45, 282–288. [Google Scholar] [CrossRef]
- Worley, R.; Dewoolkar, M.M.; Xia, T.; Farrell, R.; Orfeo, D.; Burns, D.; Huston, D.R. Acoustic emission sensing for crack monitoring in prefabricated and prestressed reinforced concrete bridge girders. J. Bridge Eng. 2019, 24, 04019018. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Mokhtari, S.; Nazef, A.; Nam, B.H.; Yun, H.B. Improvement of crack detection accuracy using a novel crack de-fragmentation technique in image-based road assessment. J. Comput. Civ. Eng. 2016, 30, 04014118. [Google Scholar] [CrossRef]
- Liu, Y.F.; Cho, S.; Spencer, B.F.; Fan, J.S. Concrete crack assessment using digital image processing and 3d scene reconstruction. J. Comput. Civ. Eng. 2016, 30, 04014124. [Google Scholar] [CrossRef]
- Turner, D.Z. Peridynamics-based digital image correlation algorithm suitable for cracks and other discontinuities. J. Eng. Mech. 2015, 141, 04014115. [Google Scholar] [CrossRef]
- Wang, K.C.P. Designs and implementations of automated systems for pavement surface distress survey. J. Infrastruct. Syst. 2000, 6, 24–32. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Nakamura, S.; Saegusa, R.; Hashimoto, S. Image-based crack detection for real concrete surfaces. Ieej Trans. Electr. Electron. Eng. 2010, 3, 128–135. [Google Scholar] [CrossRef]
- Georgieva, K.; Koch, C.; König, M. Wavelet transform on multi-gpu for real-time pavement distress detection. Comput. Civ. Eng. 2015, 1, 99–106. [Google Scholar]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Lei, B.; Ning, W.; Xu, P.P.; Song, G. New crack detection method for bridge inspection using UAV incorporating image processing. J. Aerosp. Eng. 2018, 31, 04018058. [Google Scholar] [CrossRef]
- Ellenberg, A.; Kontsos, A.; Bartoli, I.; Pradhan, A. Masonry crack detection application of an unmanned aerial vehicle. Comput. Civ. Build. Eng. 2014, 1, 1788–1795. [Google Scholar]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Fatigue crack detection using unmanned aerial systems in fracture critical inspection of steel bridges. J. Bridge Eng. 2018, 23, 04018078. [Google Scholar] [CrossRef]
- Dai, S.; Liu, X.; Kumar, N. Experimental study on the fracture process zone characteristics in concrete utilizing dic and ae methods. Appl. Sci. 2019, 9, 1346. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Zeng, W.; Liu, W.; Zhang, H.; Wang, X. Crack propagation and fracture process zone (FPZ) of wood in the longitudinal direction determined using digital image correlation (DIC) technique. Remote Sens. 2019, 11, 1562. [Google Scholar] [CrossRef] [Green Version]
- Périé, J.-N.; Passieux, J.-C. Special issue on advances in digital image correlation (DIC). Appl. Sci. 2020, 10, 1530. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.-H. Crack and noncrack classification from concrete surface images using machine learning. Struct. Health Monit. 2019, 18, 725–738. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Beckman, G.H.; Polyzois, D.; Cha, Y.-J. Deep learning-based automatic volumetric damage quantification using depth camera. Autom. Constr. 2019, 99, 114–124. [Google Scholar] [CrossRef]
- Dung, C.V.; Duc, A.L. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.-J. SDDNet: Real-time crack segmentation. IEEE Trans. Ind. Electron. 2019, 99, 12. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 1, pp. 764–773. [Google Scholar]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable convnet with aspect ratio constrained nms for object detection in remote sensing imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef] [Green Version]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. DeCNT: Deep deformable cnn for table detection. IEEE Access 2018, 6, 74151–74161. [Google Scholar] [CrossRef]
- Mustafa, R.; Mohamed, E.A. Concrete crack detection based multi-block clbp features and svm classifier. J. Theor. Appl. Inf. Technol. 2015, 81, 151–160. [Google Scholar]
- Wang, S.F.; Qiu, S.; Wang, W.J.; Xiao, D.; Wang, C.P. Cracking classification using minimum rectangular cover-based support vector machine. J. Comput. Civ. Eng. 2017, 31, 04017027. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; Volume 1, pp. 5353–5360. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 1, pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 2117–2125. [Google Scholar]
- Cho, H.; Yoon, H.-J.; Jung, J.-Y. Image-based crack detection using crack width transform (CWT) algorithm. IEEE Access 2018, 6, 60100–60114. [Google Scholar] [CrossRef]
- Manca, M.; Karrech, A.; Dight, P.; Ciancio, D. Image processing and machine learning to investigate fibre distribution on fibre-reinforced shotcrete round determinate panels. Constr. Build. Mater. 2018, 190, 870–880. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; Volume 1, pp. 3708–3712. [Google Scholar]
- Kim, B.; Cho, S. Automated vision-based detection of cracks on concrete surfaces using a deep learning technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [Green Version]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; Volume 1, pp. 124–129. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case Number | Anchor Scale | RPN Batchsize | Learning Rate | Without Deformable Module——[email protected] | With Deformable Module——[email protected] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Alligator | Longitudinal | Transverse | mAP | Alligator | Longitudinal | Transverse | mAP | ||||
| 1 | 8,16,32 | 64 | 0.0001 | 100 | 80.18 | 80.37 | 86.85 | 100 | 90.08 | 78.41 | 89.50 |
| 2 | 0.0005 | 100 | 82.36 | 78.24 | 86.87 | 100 | 88.37 | 75.84 | 88.07 | ||
| 3 | 0.001 | 99.71 | 85.69 | 78.01 | 87.80 | 100 | 87.91 | 80.87 | 89.59 | ||
| 4 | 256 | 0.0001 | 100 | 84.77 | 78.25 | 87.67 | 100 | 89.51 | 78.02 | 89.18 | |
| 5 | 0.0005 | 100 | 87.06 | 77.56 | 88.21 | 100 | 88.01 | 79.16 | 89.06 | ||
| 6 | 0.001 | 100 | 86.04 | 76.77 | 87.60 | 100 | 88.03 | 86.71 | 91.58 | ||
| 7 | 32,64,128 | 64 | 0.0001 | 99.86 | 79.48 | 78.20 | 85.85 | 100 | 82.40 | 79.16 | 87.19 |
| 8 | 0.0005 | 100 | 80.13 | 79.88 | 86.67 | 100 | 86.79 | 78.79 | 88.53 | ||
| 9 | 0.001 | 100 | 78.34 | 78.09 | 85.48 | 100 | 79.91 | 79.60 | 86.50 | ||
| 10 | 256 | 0.0001 | 100 | 79.48 | 78.20 | 85.89 | 100 | 82.57 | 78.55 | 87.04 | |
| 11 | 0.0005 | 100 | 78.83 | 78.69 | 85.84 | 100 | 82.12 | 78.82 | 86.98 | ||
| 12 | 0.001 | 100 | 78.34 | 78.09 | 85.48 | 99.27 | 85.79 | 79.43 | 88.16 | ||
| Case Number | Anchor Scale | RPN Batchsize | Learning Rate | Without Deformable Module——[email protected] | With Deformable Module——[email protected] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Alligator | Longitudinal | Transverse | mAP | Alligator | Longitudinal | Transverse | mAP | ||||
| 1 | 8,16,32 | 64 | 0.0001 | 99.57 | 89.60 | 76.56 | 88.58 | 100 | 90.91 | 78.55 | 89.58 |
| 2 | 0.0005 | 98.53 | 88.55 | 79.31 | 88.80 | 100 | 89.81 | 73.64 | 87.82 | ||
| 3 | 0.001 | 97.89 | 79.06 | 76.37 | 84.44 | 100 | 88.86 | 80.39 | 89.75 | ||
| 4 | 256 | 0.0001 | 99.57 | 87.70 | 78.77 | 88.68 | 100 | 89.83 | 77.98 | 89.27 | |
| 5 | 0.0005 | 99.43 | 79.04 | 77.33 | 85.27 | 100 | 90.27 | 76.91 | 89.06 | ||
| 6 | 0.001 | 98.71 | 79.10 | 80.57 | 86.13 | 100 | 87.90 | 78.37 | 88.75 | ||
| 7 | 32,64,128 | 64 | 0.0001 | 99.09 | 80.91 | 79.58 | 86.53 | 100 | 86.98 | 79.56 | 88.84 |
| 8 | 0.0005 | 99.51 | 80.15 | 77.55 | 85.73 | 100 | 89.57 | 80.48 | 90.01 | ||
| 9 | 0.001 | 99.62 | 79.26 | 78.61 | 85.83 | 100 | 86.68 | 79.02 | 88.57 | ||
| 10 | 256 | 0.0001 | 99.71 | 80.69 | 74.74 | 85.05 | 100 | 87.22 | 80.10 | 89.11 | |
| 11 | 0.0005 | 99.90 | 79.73 | 79.28 | 86.30 | 100 | 87.04 | 79.52 | 88.85 | ||
| 12 | 0.001 | 98.81 | 79.79 | 76.97 | 85.19 | 100 | 79.72 | 79.02 | 86.25 | ||
| Case Number | Anchor Scale | RPN Batchsize | Learning Rate | Without Deformable Module——[email protected] | With Deformable Module——[email protected] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Alligator | Longitudinal | Transverse | mAP | Alligator | Longitudinal | Transverse | mAP | ||||
| 1 | 8,16,32 | 64 | 0.0001 | 100 | 77.03 | 73.22 | 83.42 | 100 | 88.47 | 87.23 | 91.90 |
| 2 | 0.0005 | 100 | 84.99 | 71.92 | 85.64 | 100 | 89.68 | 84.42 | 91.36 | ||
| 3 | 0.001 | 100 | 90.38 | 79.58 | 89.99 | 100 | 89.48 | 84.61 | 91.36 | ||
| 4 | 256 | 0.0001 | 100 | 59.71 | 60.02 | 73.24 | 100 | 76.14 | 75.65 | 83.93 | |
| 5 | 0.0005 | 100 | 87.60 | 74.11 | 87.24 | 100 | 89.74 | 85.62 | 91.79 | ||
| 6 | 0.001 | 100 | 83.43 | 78.48 | 87.30 | 100 | 89.41 | 86.93 | 92.11 | ||
| 7 | 32,64,128 | 64 | 0.0001 | 100 | 80.16 | 76.21 | 85.46 | 100 | 82.85 | 80.74 | 87.86 |
| 8 | 0.0005 | 100 | 89.67 | 78.93 | 89.53 | 100 | 89.90 | 86.60 | 92.17 | ||
| 9 | 0.001 | 100 | 89.89 | 79.38 | 89.76 | 100 | 89.89 | 87.04 | 92.31 | ||
| 10 | 256 | 0.0001 | 100 | 79.82 | 75.44 | 85.09 | 100 | 84.45 | 83.69 | 89.38 | |
| 11 | 0.0005 | 100 | 90.28 | 77.87 | 89.38 | 100 | 89.63 | 84.40 | 91.31 | ||
| 12 | 0.001 | 100 | 84.95 | 78.54 | 87.83 | 100 | 89.80 | 84.18 | 91.33 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Chu, H.-H.; Shi, P.; Wang, W.; Kong, X. Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks. Appl. Sci. 2020, 10, 2528. https://doi.org/10.3390/app10072528
Deng L, Chu H-H, Shi P, Wang W, Kong X. Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks. Applied Sciences. 2020; 10(7):2528. https://doi.org/10.3390/app10072528
Chicago/Turabian StyleDeng, Lu, Hong-Hu Chu, Peng Shi, Wei Wang, and Xuan Kong. 2020. "Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks" Applied Sciences 10, no. 7: 2528. https://doi.org/10.3390/app10072528
APA StyleDeng, L., Chu, H. -H., Shi, P., Wang, W., & Kong, X. (2020). Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks. Applied Sciences, 10(7), 2528. https://doi.org/10.3390/app10072528