Visual and Quantitative Evaluation of Amyloid Brain PET Image Synthesis with Generative Adversarial Network



Abstract
:1. Introduction
2. Materials and Methods
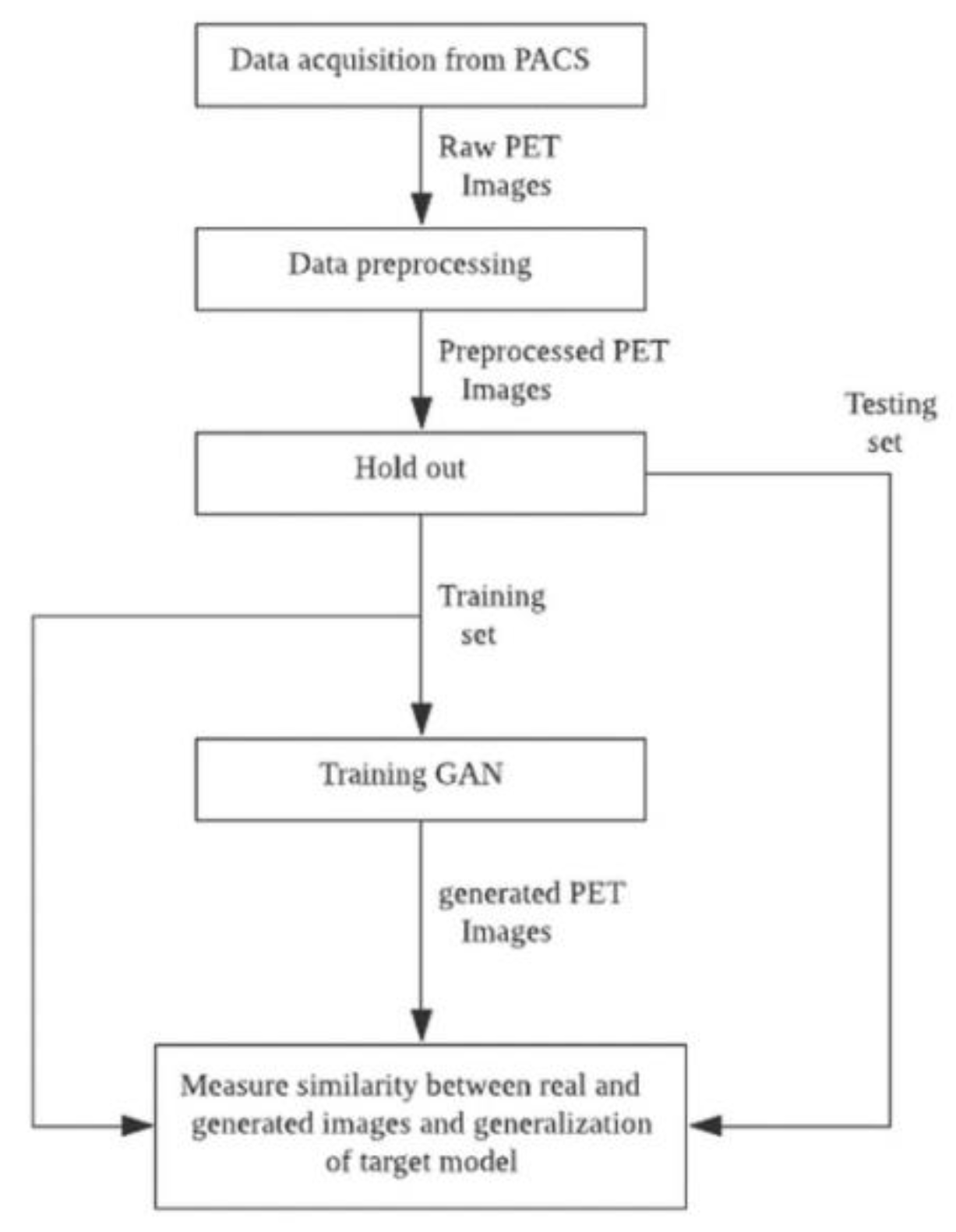
2.1. Experiment
2.2. Data Acquisition and Pre-Processing
2.3. Target Model to Enhance with Generated Set
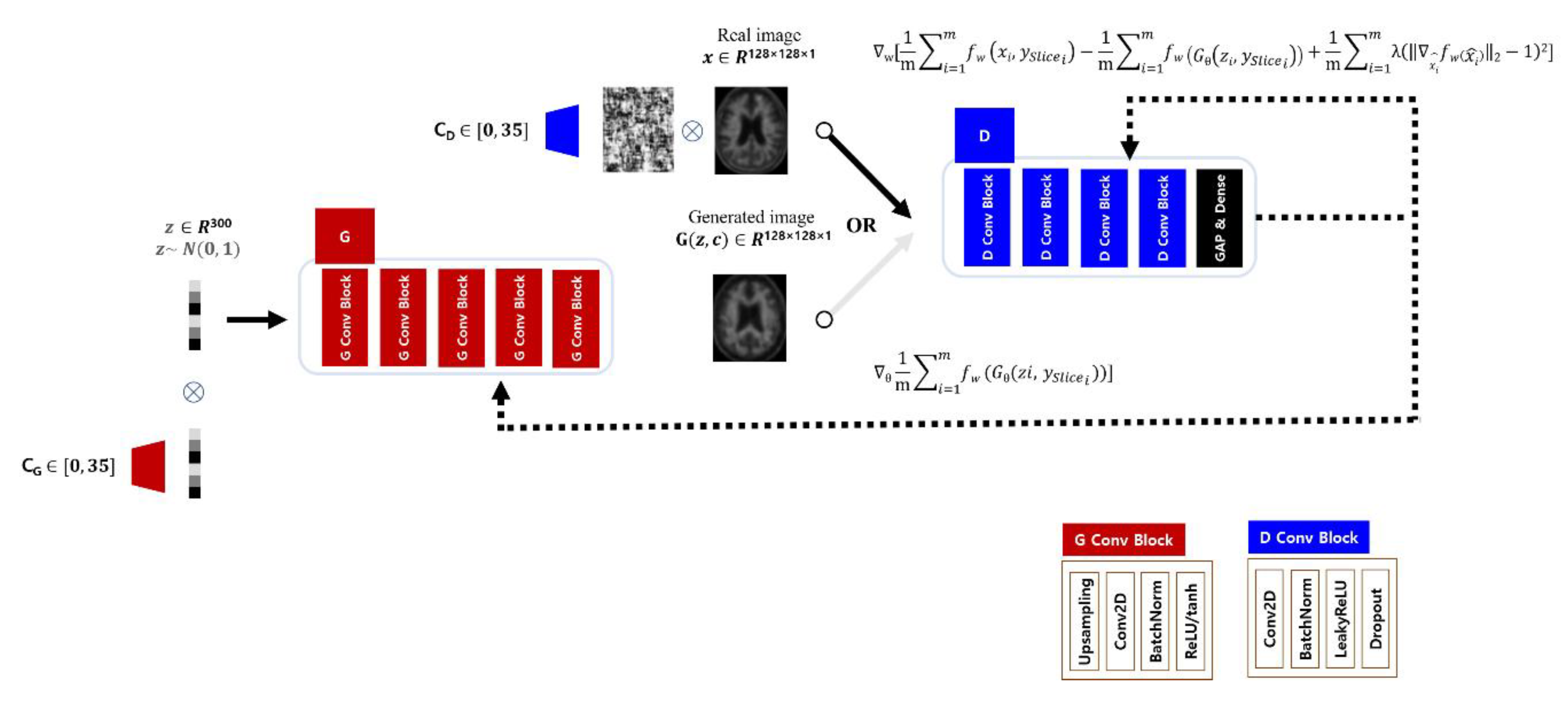
2.4. Generative Adversarial Network for Data Augmentation
2.5. Performance Metrics
2.5.1. Visual Turing Test and Feature Visualization
2.5.2. Quantitative Measure
2.6. Statistical Analysis
3. Results
3.1. Demographic Data
3.2. Visual Turing Test
3.3. Feature Visualization
3.4. Quantitative Measurements
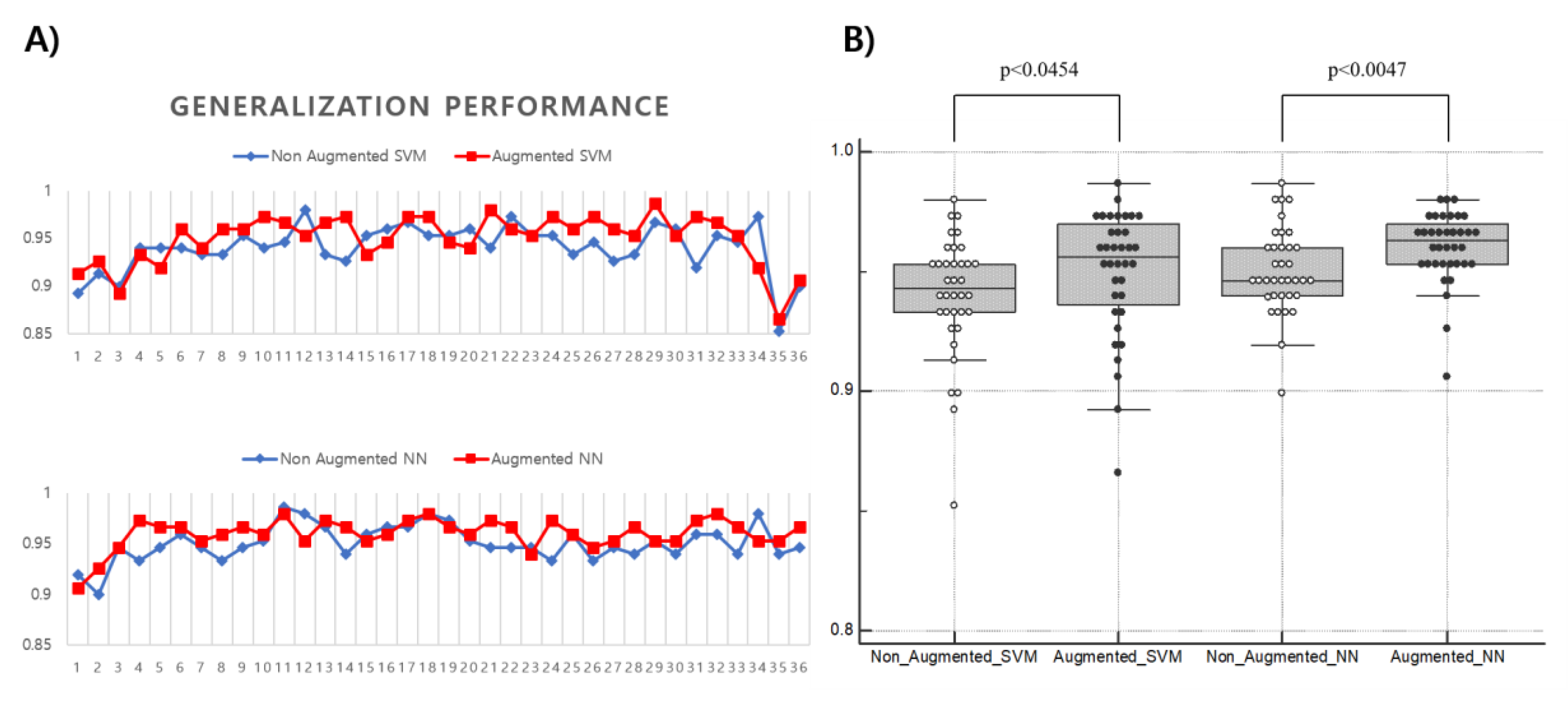
3.5. Generalization Test
4. Discussion
4.1. Medical Image Synthesis with Quantitative Measurements
- The practitioner cannot predict what the samples generated from GAN will look like until they are confirmed, unlike conventional DA.
- It is not easy to visually evaluate how similar the real distribution is to the generated distribution.
- Models trained without validation of augmented data may learn data that is characteristics of diseases but falls outside of a given class with an arbitrary label.
4.2. Comparison between t-SNE and Quantitative Measurements
4.3. Comparison between Model-Agnostic Metrics
4.4. Role of Quantitative Measurements in Future Generative Data Augmentation Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Dementia. Available online: https://www.who.int/news-room/fact-sheets/detail/dementia (accessed on 25 November 2019).
- World Health Organization. Risk Reduction of Cognitive Decline and Dementia: WHO Guidelines; World Health Organization: Geneva, Switzerland, 2019. [Google Scholar]
- National Institutes of Health. What Is Alzheimer’s Disease? Available online: https://www.nia.nih.gov/health/what-alzheimers-disease (accessed on 20 December 2019).
- Villemagne, V.L. Amyloid imaging: Past, present and future perspectives. Ageing Res. Rev. 2016, 30, 95–106. [Google Scholar] [CrossRef] [PubMed]
- Villemagne, V.L.; Rowe, C.C.; Macfarlane, S.; Novakovic, K.; Masters, C.L. Imaginem oblivionis: The prospects of neuroimaging for early detection of Alzheimer’s disease. J. Clin. Neurosci. 2005, 12, 221–230. [Google Scholar] [CrossRef] [PubMed]
- Michaelis, M.L.; Dobrowsky, R.T.; Li, G. Tau neurofibrillary pathology and microtubule stability. J. Mol. Neurosci. 2002, 19, 289–293. [Google Scholar] [CrossRef]
- Haass, C.; Selkoe, D.J. Soluble protein oligomers in neurodegeneration: Lessons from the Alzheimer’s amyloid β-peptide. Nat. Rev. Mol. Cell Biol. 2007, 8, 101. [Google Scholar] [CrossRef]
- Luna, A.; Vilanova, J.C.; Da Cruz, L.C.H., Jr.; Rossi, S.E. Functional Imaging in Oncology: Clinical Applications; Springer: Berlin/Heidelberg, Germany, 2014; Volume 2. [Google Scholar]
- Leuzy, A.; Chiotis, K.; Lemoine, L.; Gillberg, P.-G.; Almkvist, O.; Rodriguez-Vieitez, E.; Nordberg, A. Tau PET imaging in neurodegenerative tauopathies—Still a challenge. Mol. Psychiatry 2019, 24, 1112–1134. [Google Scholar] [CrossRef] [Green Version]
- Marcus, C.; Mena, E.; Subramaniam, R.M. Brain PET in the diagnosis of Alzheimer’s disease. Clin. Nucl. Med. 2014, 39, e413. [Google Scholar] [CrossRef] [Green Version]
- Chiaravalloti, A.; Castellano, A.E.; Ricci, M.; Barbagallo, G.; Sannino, P.; Ursini, F.; Karalis, G.; Schillaci, O. Coupled imaging with [18F] FBB and [18F] FDG in AD subjects show a selective association between amyloid burden and cortical dysfunction in the brain. Mol. Imaging Biol. 2018, 20, 659–666. [Google Scholar] [CrossRef]
- Kim, J.; Hong, J.; Park, H. Prospects of deep learning for medical imaging. Precis. Future Med. 2018, 2, 37–52. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Lakhani, P.; Sundaram, B. Deep learning at chest radiography: Automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology 2017, 284, 574–582. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Darrell, T. Constrained convolutional neural networks for weakly supervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1796–1804. [Google Scholar]
- Jiang, H.; Ma, H.; Qian, W.; Gao, M.; Li, Y. An automatic detection system of lung nodule based on multigroup patch-based deep learning network. IEEE J. Biomed. Health Inform. 2017, 22, 1227–1237. [Google Scholar] [CrossRef] [PubMed]
- Hwang, E.J.; Park, S.; Jin, K.-N.; Im Kim, J.; Choi, S.Y.; Lee, J.H.; Goo, J.M.; Aum, J.; Yim, J.-J.; Cohen, J.G. Development and Validation of a Deep Learning–Based Automated Detection Algorithm for Major Thoracic Diseases on Chest Radiographs. JAMA Netw. Open 2019, 2, e191095. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, J.; Li, A.; Hu, Z.; Wang, L. Accurate pulmonary nodule detection in computed tomography images using deep convolutional neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 559–567. [Google Scholar]
- Hwang, D.; Kim, K.Y.; Kang, S.K.; Seo, S.; Paeng, J.C.; Lee, D.S.; Lee, J.S. Improving the accuracy of simultaneously reconstructed activity and attenuation maps using deep learning. J. Nucl. Med. 2018, 59, 1624–1629. [Google Scholar] [CrossRef] [PubMed]
- Kang, E.; Min, J.; Ye, J.C. A deep convolutional neural network using directional wavelets for low-dose X-ray CT reconstruction. Med. Phys. 2017, 44, e360–e375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quan, T.M.; Nguyen-Duc, T.; Jeong, W.-K. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE Trans. Med. Imaging 2018, 37, 1488–1497. [Google Scholar] [CrossRef] [Green Version]
- Haeusser, P.; Mordvintsev, A.; Cremers, D. Learning by Association—A Versatile Semi-Supervised Training Method for Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 89–98. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Nevada, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-dose CT with a residual encoder-decoder convolutional neural network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Haradal, S.; Hayashi, H.; Uchida, S. Biosignal Data Augmentation Based on Generative Adversarial Networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 368–371. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in neural information processing systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Xu, Q.; Huang, G.; Yuan, Y.; Guo, C.; Sun, Y.; Wu, F.; Weinberger, K. An empirical study on evaluation metrics of generative adversarial networks. arXiv 2018, arXiv:1806.07755. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in neural information processing systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Chuquicusma, M.J.; Hussein, S.; Burt, J.; Bagci, U. How to fool radiologists with generative adversarial networks? A visual turing test for lung cancer diagnosis. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 240–244. [Google Scholar]
- Borji, A. Pros and cons of gan evaluation measures. Comput. Vision Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Theis, L.; Oord, A.v.d.; Bethge, M. A note on the evaluation of generative models. arXiv 2015, arXiv:1511.01844. [Google Scholar]
- Barthel, H.; Gertz, H.-J.; Dresel, S.; Peters, O.; Bartenstein, P.; Buerger, K.; Hiemeyer, F.; Wittemer-Rump, S.M.; Seibyl, J.; Reininger, C. Cerebral amyloid-β PET with florbetaben (18F) in patients with Alzheimer’s disease and healthy controls: A multicentre phase 2 diagnostic study. Lancet Neurol. 2011, 10, 424–435. [Google Scholar] [CrossRef]
- Lundeen, T.F.; Seibyl, J.P.; Covington, M.F.; Eshghi, N.; Kuo, P.H. Signs and artifacts in Amyloid PET. RadioGraphics 2018, 38, 2123–2133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- The Wellcome Centre for Human Neuroimaging. Statistical Parametric Mapping. Available online: https://www.fil.ion.ucl.ac.uk/spm/ (accessed on 11 February 2020).
- Rorden, C.; Bonilha, L.; Fridriksson, J.; Bender, B.; Karnath, H.-O. Age-specific CT and MRI templates for spatial normalization. Neuroimage 2012, 61, 957–965. [Google Scholar] [CrossRef] [Green Version]
- Hutton, C.; Declerck, J.; Mintun, M.A.; Pontecorvo, M.J.; Devous, M.D.; Joshi, A.D.; Initiative, A.s.D.N. Quantification of 18F-florbetapir PET: Comparison of two analysis methods. Eur. J. Nucl. Med. Mol. Imaging 2015, 42, 725–732. [Google Scholar] [CrossRef]
- Garcia, D.V.; Casteels, C.; Schwarz, A.J.; Dierckx, R.A.; Koole, M.; Doorduin, J. A standardized method for the construction of tracer specific PET and SPECT rat brain templates: Validation and implementation of a toolbox. PLoS ONE 2015, 10, e0122363. [Google Scholar] [CrossRef] [Green Version]
- Hammers, A.; Allom, R.; Koepp, M.J.; Free, S.L.; Myers, R.; Lemieux, L.; Mitchell, T.N.; Brooks, D.J.; Duncan, J.S. Three-dimensional maximum probability atlas of the human brain, with particular reference to the temporal lobe. Hum. Brain Mapp. 2003, 19, 224–247. [Google Scholar] [CrossRef]
- Daerr, S.; Brendel, M.; Zach, C.; Mille, E.; Schilling, D.; Zacherl, M.J.; Bürger, K.; Danek, A.; Pogarell, O.; Schildan, A. Evaluation of early-phase [18F]-florbetaben PET acquisition in clinical routine cases. NeuroImage Clin. 2017, 14, 77–86. [Google Scholar] [CrossRef]
- Kang, H.; Kim, W.-G.; Yang, G.-S.; Kim, H.-W.; Jeong, J.-E.; Yoon, H.-J.; Cho, K.; Jeong, Y.-J.; Kang, D.-Y. VGG-based BAPL score classification of 18F-Florbetaben Amyloid Brain PET. Biomed. Sci. Lett. 2018, 24, 418–425. [Google Scholar] [CrossRef]
- Cho, K.; Kim, W.-G.; Kang, H.; Yang, G.-S.; Kim, H.-W.; Jeong, J.-E.; Yoon, H.-J.; Jeong, Y.-J.; Kang, D.-Y. Classification of 18F-Florbetaben Amyloid Brain PET Image using PCA-SVM. Biomed. Sci. Lett. 2019, 25, 99–106. [Google Scholar] [CrossRef]
- Işın, A.; Direkoğlu, C.; Şah, M. Review of MRI-based brain tumor image segmentation using deep learning methods. Procedia Comput. Sci. 2016, 102, 317–324. [Google Scholar] [CrossRef] [Green Version]
- Sato, R.; Iwamoto, Y.; Cho, K.; Kang, D.-Y.; Chen, Y.-W. Accurate BAPL Score Classification of Brain PET Images Based on Convolutional Neural Networks with a Joint Discriminative Loss Function. Appl. Sci. 2020, 10, 965. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Vapnik, V.N. Support Vector Machine: Statistical Learning Theory; Wiley-Interscience: Hoboken, NJ, USA, 1998. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Transact. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, P.M.; Malhi, H.S. Transfer learning with convolutional neural networks for classification of abdominal ultrasound images. J. Digit. Imaging 2017, 30, 234–243. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Califonia, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Dowson, D.; Landau, B. The Fréchet distance between multivariate normal distributions. J. Multivar. Anal. 1982, 12, 450–455. [Google Scholar] [CrossRef] [Green Version]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, California, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Lopez-Paz, D.; Oquab, M. Revisiting classifier two-sample tests. arXiv 2016, arXiv:1610.06545. [Google Scholar]
- Ulloa, A.; Plis, S.; Erhardt, E.; Calhoun, V. Synthetic structural magnetic resonance image generator improves deep learning prediction of schizophrenia. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Shin, H.-C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.P.; Michalski, M. Medical image synthesis for data augmentation and anonymization using generative adversarial networks. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Granada, Spain, 16 September 2018; pp. 1–11. [Google Scholar]
- Mok, T.C.; Chung, A.C. Learning data augmentation for brain tumor segmentation with coarse-to-fine generative adversarial networks. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16 September 2018; pp. 70–80. [Google Scholar]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Aly, F. Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Cai, H.; Rong, S.; Song, Y.; Ren, K.; Zhang, W.; Yu, Y.; Wang, J. Activation maximization generative adversarial nets. arXiv 2017, arXiv:1703.02000. [Google Scholar]
- Gurumurthy, S.; Kiran Sarvadevabhatla, R.; Venkatesh Babu, R. Deligan: Generative adversarial networks for diverse and limited data. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 166–174. [Google Scholar]
- Che, T.; Li, Y.; Jacob, A.P.; Bengio, Y.; Li, W. Mode regularized generative adversarial networks. arXiv 2016, arXiv:1612.02136. [Google Scholar]
- Isaksson, A.; Wallman, M.; Göransson, H.; Gustafsson, M.G. Cross-validation and bootstrapping are unreliable in small sample classification. Pattern Recognit. Lett. 2008, 29, 1960–1965. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Division | Aβ Negative | Aβ Positive | Total | p-Value |
|---|---|---|---|---|---|
| # | data | 160 | 138 | 298 | |
| Sex | Male | 56 | 61 | 117 | 0.102 |
| Female | 104 | 77 | 181 | ||
| Age | 67.76 ± 9.09 | 69.56 ± 8.07 | 68.58 ± 8.67 | 0.0916 | |
| Diagnosis | NC 1 + SCD 2 | 58 | 4 | 62 | <0.0001 * |
| MCI 3 | 74 | 25 | 99 | ||
| AD 4 | 28 | 109 | 137 | ||
| Education(y) | 9.27 ± 4.23 | 10.07 ± 4.11 | 9.64 ± 4.19 | 0.0802 | |
| K-MMSE 5 | 25.24 ± 3.77 | 20.42 ± 4.61 | 22.98 ± 4.82 | <0.0001 * |
| Label | Metric | TL(4th) | FL(10th) | PP1(16th) | PP2(22nd) | PL1(28th) | PL2(34th) | Avg(SD) |
|---|---|---|---|---|---|---|---|---|
| Aβ (−) t/o 1 | MMD | 0.0990 | 0.0983 | 0.0822 | 0.0911 | 0.0896 | 0.0813 | 0.0902(0.00) |
| FID | 5.6293 | 5.4589 | 5.6456 | 5.7796 | 6.2149 | 6.4051 | 5.8556(0.37) | |
| 1-NN accuracy | 0.4565 | 0.4928 | 0.4130 | 0.4855 | 0.5507 | 0.4928 | 0.4819(0.05) | |
| Aβ (+) t/o | MMD | 0.1239 | 0.1120 | 0.1104 | 0.1130 | 0.1036 | 0.1144 | 0.1129(0.01) |
| FID | 6.3801 | 6.2410 | 6.4176 | 6.6572 | 6.8022 | 7.5409 | 6.6732(0.47) | |
| 1-NN accuracy | 0.4203 | 0.4493 | 0.4928 | 0.4855 | 0.5435 | 0.4420 | 0.4722(0.04) | |
| Aβ (−) o/g 2 | MMD | 0.3779 | 0.3245 | 0.2849 | 0.2317 | 0.2284 | 0.3054 | 0.2921(0.06) |
| FID | 9.4479 | 7.9763 | 7.9686 | 6.8253 | 7.2652 | 8.2666 | 7.9583(0.90) | |
| 1-NN accuracy | 0.9625 | 0.9125 | 0.8562 | 0.8687 | 0.8625 | 0.9375 | 0.9000(0.04) | |
| Aβ (+) o/g | MMD | 0.2860 | 0.2482 | 0.2123 | 0.1865 | 0.3289 | 0.2645 | 0.2544(0.05) |
| FID | 7.4191 | 6.8910 | 6.7300 | 5.8919 | 7.6111 | 7.197 | 6.9566(0.61) | |
| 1-NN accuracy | 0.8261 | 0.7391 | 0.6522 | 0.6233 | 0.7536 | 0.8551 | 0.8418(0.07) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.; Park, J.-S.; Cho, K.; Kang, D.-Y. Visual and Quantitative Evaluation of Amyloid Brain PET Image Synthesis with Generative Adversarial Network. Appl. Sci. 2020, 10, 2628. https://doi.org/10.3390/app10072628
Kang H, Park J-S, Cho K, Kang D-Y. Visual and Quantitative Evaluation of Amyloid Brain PET Image Synthesis with Generative Adversarial Network. Applied Sciences. 2020; 10(7):2628. https://doi.org/10.3390/app10072628
Chicago/Turabian StyleKang, Hyeon, Jang-Sik Park, Kook Cho, and Do-Young Kang. 2020. "Visual and Quantitative Evaluation of Amyloid Brain PET Image Synthesis with Generative Adversarial Network" Applied Sciences 10, no. 7: 2628. https://doi.org/10.3390/app10072628
APA StyleKang, H., Park, J. -S., Cho, K., & Kang, D. -Y. (2020). Visual and Quantitative Evaluation of Amyloid Brain PET Image Synthesis with Generative Adversarial Network. Applied Sciences, 10(7), 2628. https://doi.org/10.3390/app10072628