An Unsupervised Regularization and Dropout based Deep Neural Network and Its Application for Thermal Error Prediction


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
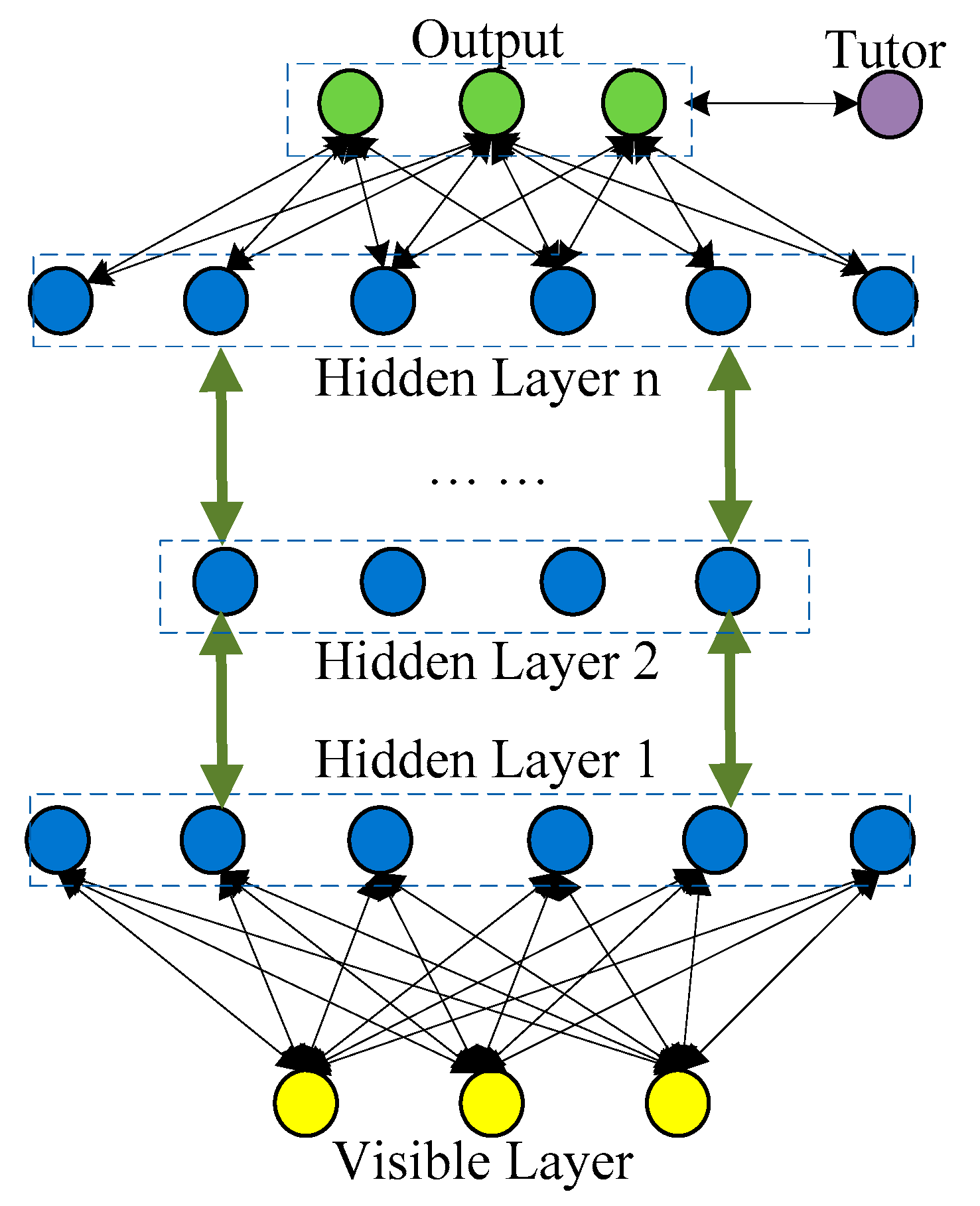
2. Self-Organizing Deep Neural Network
2.1. Network Structure
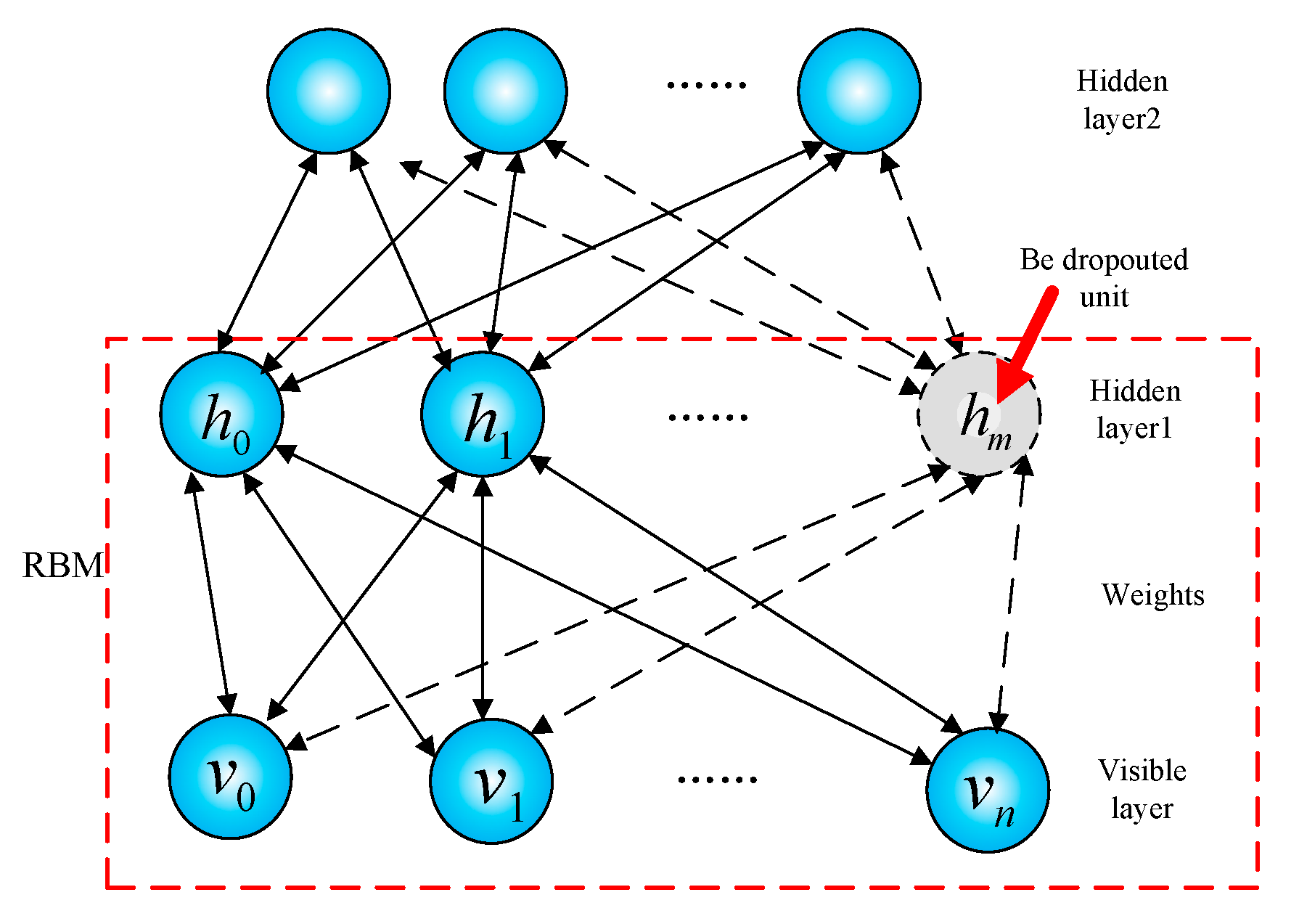
2.2. Self-Organization Algorithm for Unsupervised Training
2.3. Supervised Training Algorithm
- (1)
- Initialize the forward neural network, set the step length to .
- (2)
- Calculate the forward output,where is the output of the th neuron of the th layer.
- (3)
- Calculate the error signal based on:where represents the teacher’s signal, which represents ideal predicted temperature, and it is taken by hand when the whole dataset is processed in experiment. is the value of output layer, and the error signal.
- (4)
- Generate the backpropagation error. For neurons in the output layer, this is:For neurons in the hidden layer, we have:
- (5)
- Modify the weights based on:where is the learning rate.
- (6)
- When the iteration reaches , terminate the loop; otherwise, return to Step (2).
3. Experimental Validation
3.1. Experimental Setup
- (1)
- Set the network size according to the training data (including the number of hidden layers and the number of neurons in each layer) and initialize the network parameters.
- (2)
- Send the data to the input layer and start training the first RBM. Perform dropout to determine which feature detectors can be removed according to Equations (5) and (6) and use the remaining neurons to conduct the feature extraction.
- (3)
- Use the CD algorithm to quickly train an RBM and use Equations (7) and (8) to perform the data calculation. Reduce overfitting and improve computational efficiency by introducing the regularization enhancement factor.
- (4)
- Update the RBM network parameters.
- (5)
- Use the RBM output as the input of the next RBM and perform the same process on the next RBM.
- (6)
- When the last RBM is trained, perform the next step to output the data; otherwise, return to Step (2).
- (7)
- Use the backpropagation algorithm to conduct supervised training.
- (8)
- If the training termination conditions are met, stop training; otherwise, go back to Step (7).
- (9)
- Stop the operation.
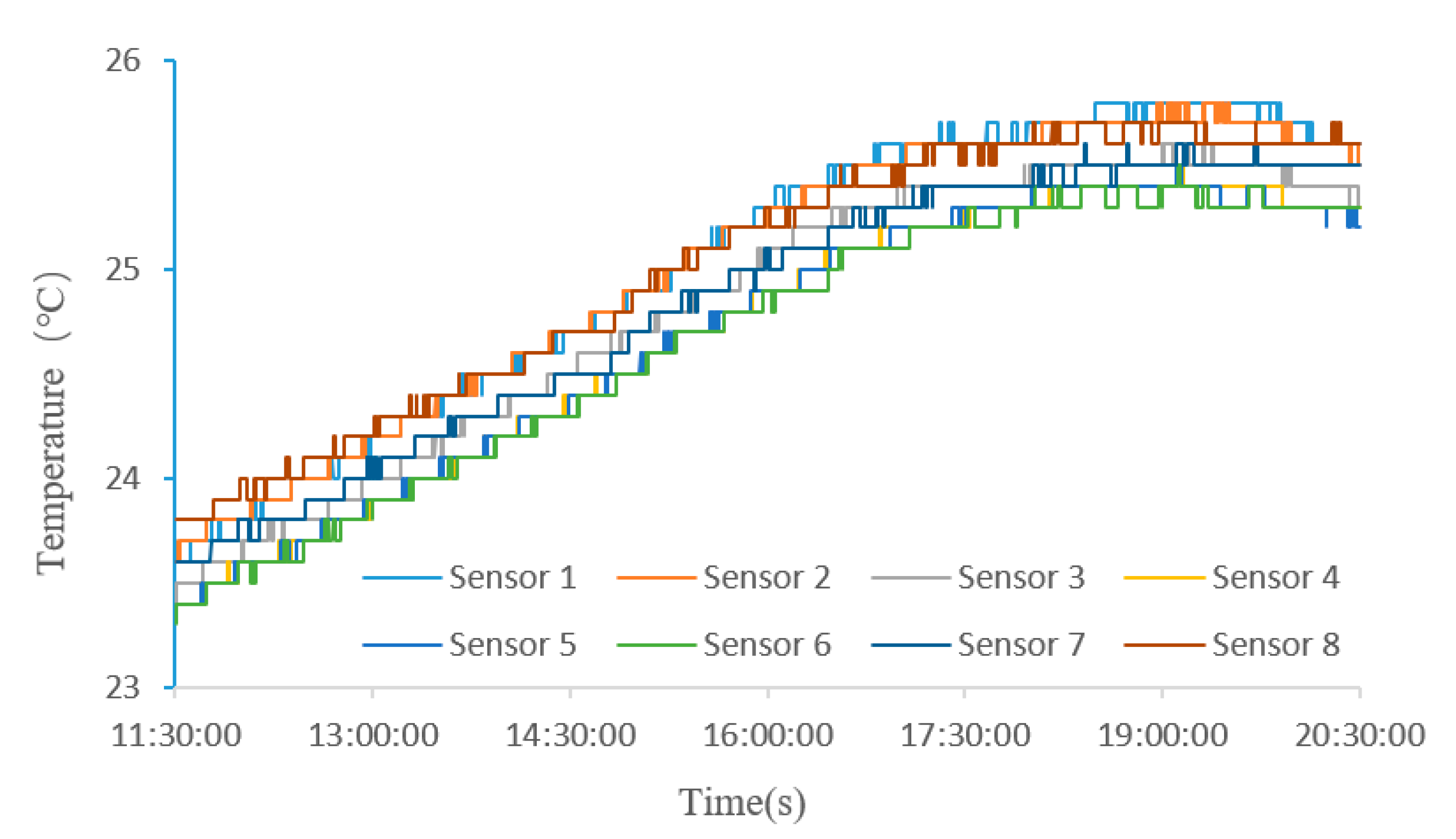
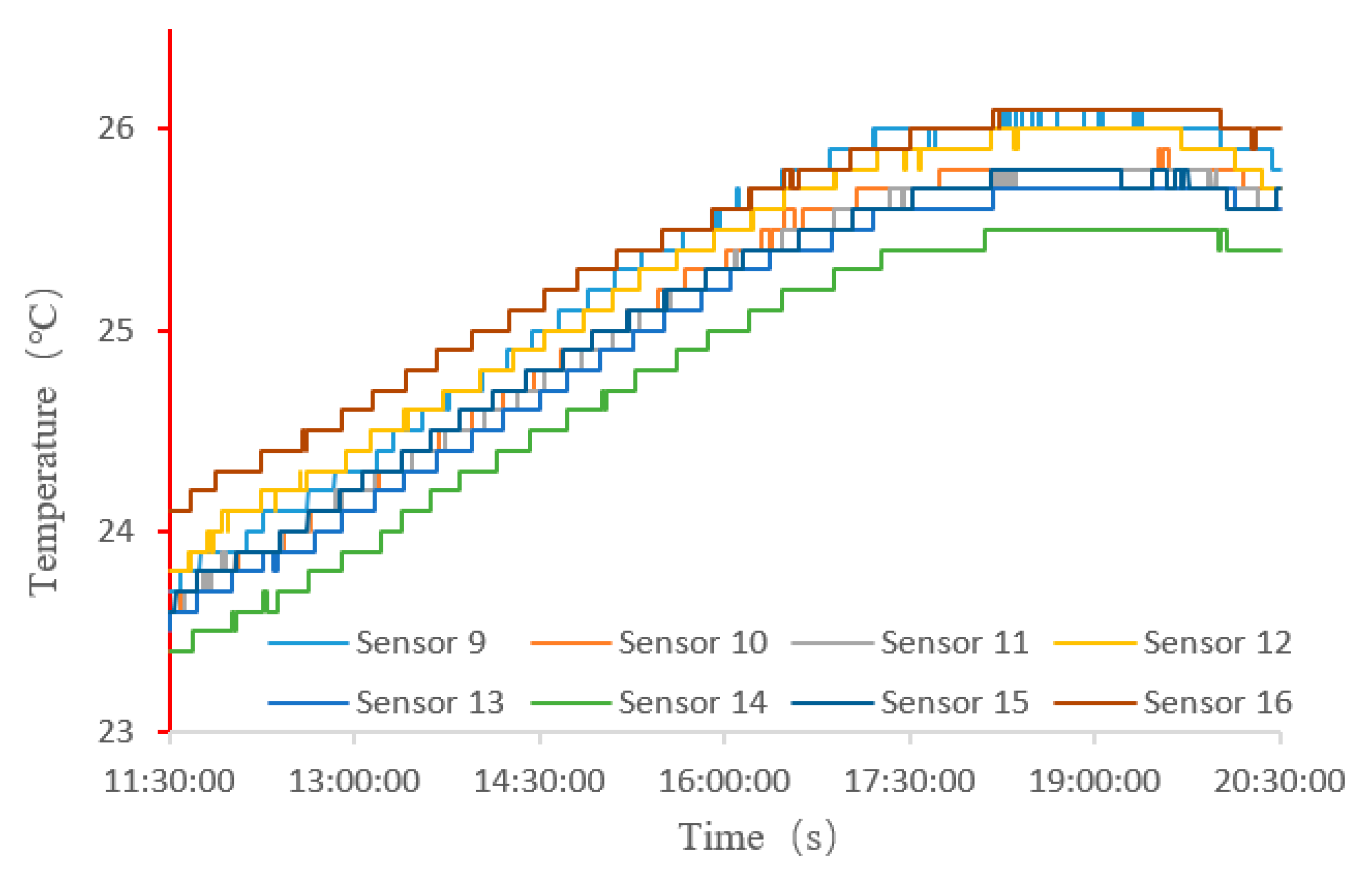
3.2. Acquisition of Experimental Data
3.2.1. Experimental Environment
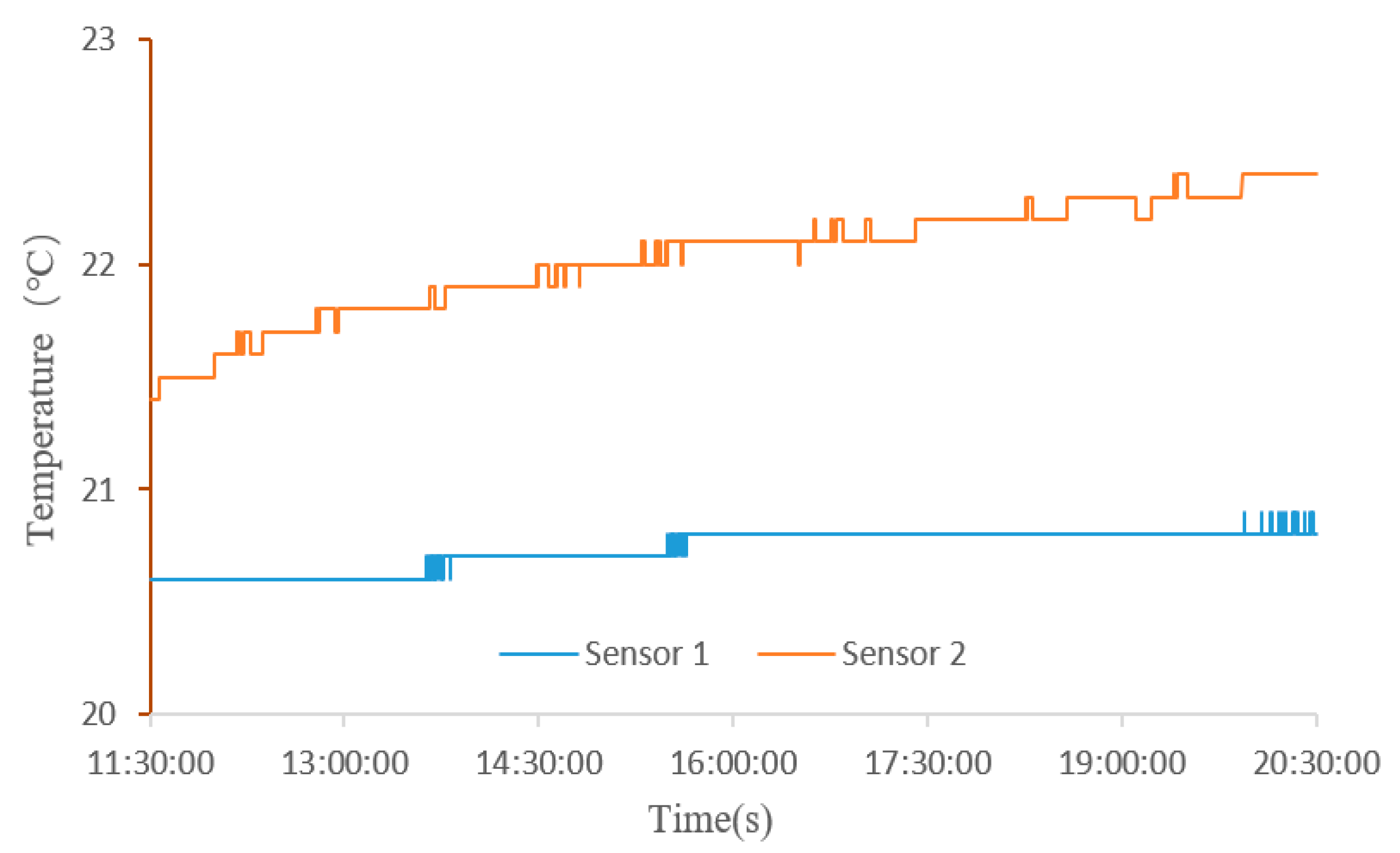
3.2.2. Deployment of Sensors
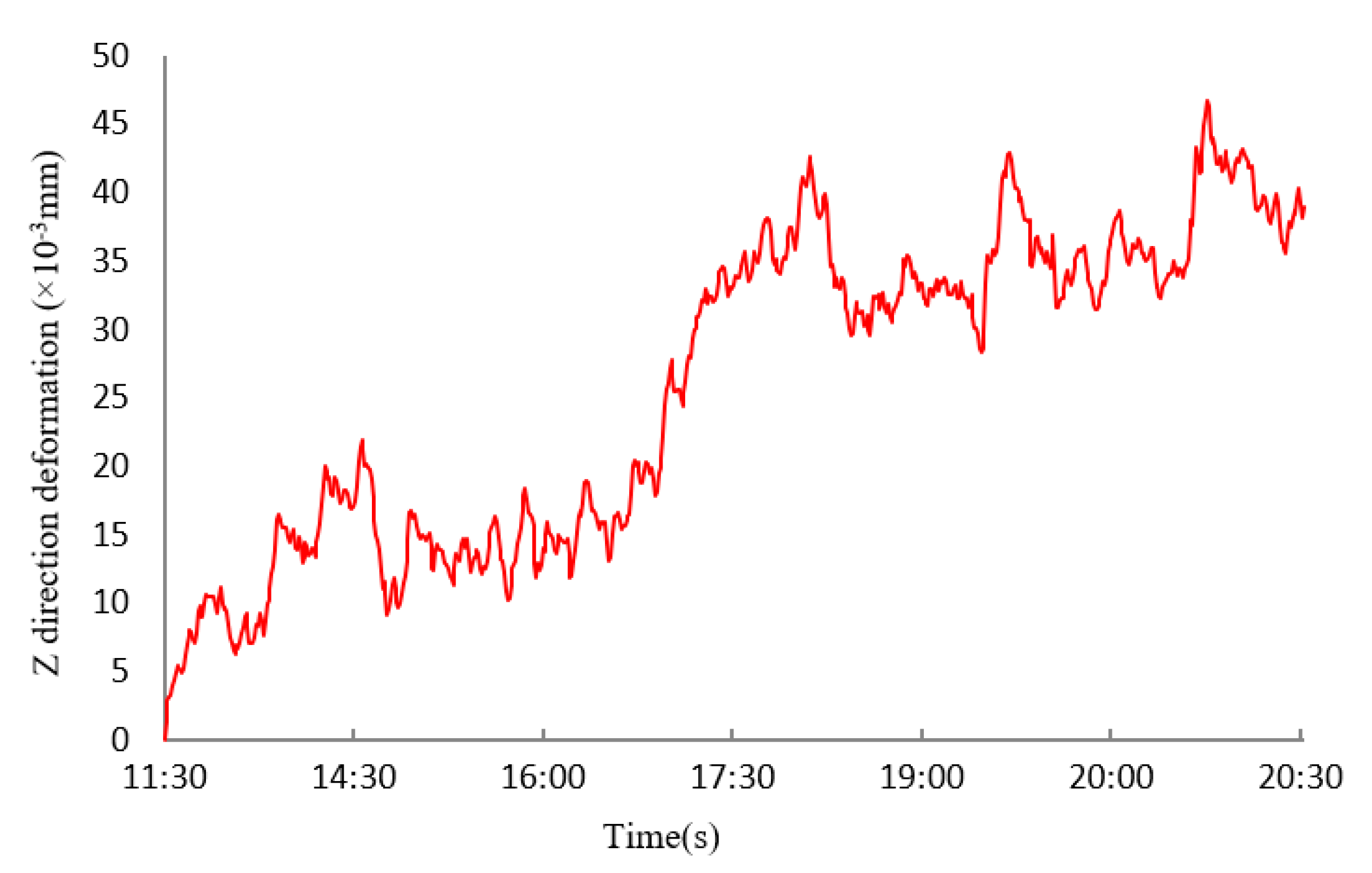
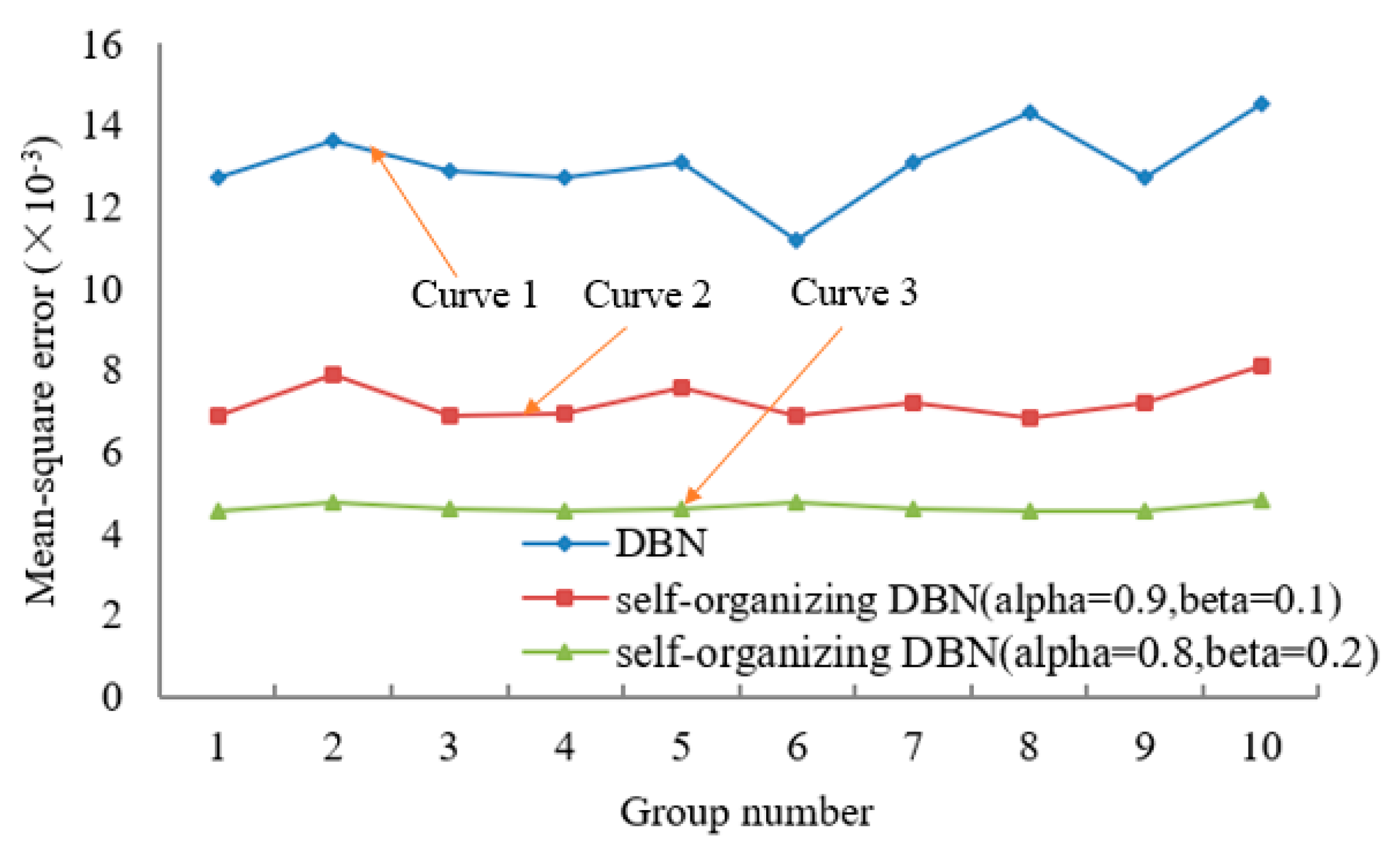
4. Comparison of Predicted Values and Experimental Results
5. Conclusions
- (1)
- In this study, a thermal error prediction model has been developed based on self-organizing DNN with the aim of improving feature extraction capabilities, reducing test errors, and improving convergence speed. The dropout mechanism was used to train the self-organizing capability of the hidden layer during unsupervised training of the neural network, thereby preventing synergy between neurons in the same layer and improved the feature extraction capability. Furthermore, a regularization enhancement factor was introduced into the training objective function to prevent overfitting and reduce training times.
- (2)
- The effects of ambient temperature changes on thermal error of the machine tool-foundation system was analyzed within a 9-h timeframe based on experimental data. A comparison of the prediction results of self-organizing DNN and traditional DNN revealed that the self-organizing DNN network predictive model proposed in this paper has better generalization ability and higher convergence speeds, moreover, adjusting the drop rate improves the overall predictive capability of the network. Moreover, because the machine’s environment and construction are different, if we want to transfer the trained model on other machines (or new testing environments), new training data must be collected, and the model must be re-trained or fine-tuned. So, the trained model is not universal, because it is only trained for the particular experiment. However, the methodology that we proposed in the paper is totally original and universal, we believe if more data could be collected in various conditions, a model with universal power could be trained.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tan, B.; Mao, X.; Liu, H.; Li, B.; He, S.; Peng, F.; Yin, L. A thermal error model for large machine tools that considers environmental thermal hysteresis effects. Int. J. Mach. Tools Manuf. 2014, 82, 11–20. [Google Scholar]
- Mian, N.S.; Fletcher, S.; Longstaff, A.P.; Myers, A. Efficient estimation by FEA of machine tool distortion due to environmental temperature perturbations. Precis. Eng. 2013, 37, 372–379. [Google Scholar]
- Pahk, H.; Lee, S.W. Thermal Error Measurement and Real Time Compensation System for the CNC Machine Tools Incorporating the Spindle Thermal Error and the Feed Axis Thermal Error. Int. J. Adv. Manuf. Technol. 2002, 20, 487–494. [Google Scholar] [CrossRef]
- Wang, H.; Wang, L.; Li, T.; Han, J. Thermal sensor selection for the thermal error modeling of machine tool based on the fuzzy clustering method. Int. J. Adv. Manuf. Technol. 2013, 69, 121–126. [Google Scholar]
- Yang, H. Dynamic modeling for machine tool thermal error compensation. J. Manuf. Sci. Eng. 2003, 125, 245–254. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, G.; Moon, K.S.; Sutherland, L.W. Compensation for the thermal error of a multi-axis machining center. J. Mater. Process. Technol. 1998, 75, 45–53. [Google Scholar]
- Kang, Y.; Chang, C.W.; Huang, Y.; Hsu, C.L.; Nieh, I.F. Modification of a neural network utilizing hybrid filters for the compensation of thermal deformation in machine tools. Int. J. Mach. Tools Manuf. 2007, 47, 376–387. [Google Scholar]
- Li, F.; Li, T.; Wang, H.; Jian, Y. A Temperature Sensor Clustering Method for Thermal Error Modeling of Heavy Milling Machine Tools. Appl. Sci. 2017, 7, 82. [Google Scholar]
- Chen, J.S.; Yuan, J.X.; Ni, J. Thermal error modeling for realtime compensation. Int. J. Adv. Manuf. Technol. 1996, 12, 266–275. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.S.; Choi, J.Y.; Choi, D.H. ICA based thermal source extraction and thermal distortion compensation method for a machine tool. Int. J. Mach. Tools Manuf. 2003, 43, 589–597. [Google Scholar] [CrossRef]
- Guo, Q.; Yang, J.; Wu, H. Application of ACO-BPN to thermal error modeling of NC machine tool. Int. J. Adv. Manuf. Technol. 2010, 50, 667–675. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, J.; Jiang, H. Machine tool thermal error modeling and prediction by grey neural network. Int. J. Adv. Manuf. Technol. 2012, 59, 1065–1072. [Google Scholar] [CrossRef]
- Wang, L.; Wang, H.; Li, T.; Li, F. A hybrid thermal error modeling method of heavy machine tools in z -axis. Int. J. Adv. Manuf. Technol. 2015, 80, 389–400. [Google Scholar]
- Gomez-Acedo, E.; Olarra, A.; de la Calle, L.N.L. A method for thermal characterization and modeling of large gantry-type machine tools. Int. J. Adv. Manuf. Technol. 2012, 62, 875–886. [Google Scholar] [CrossRef]
- Lee, S.K.; Yoo, J.H.; Yang, M.S. Effect of thermal deformation on machine tool slide guide motion. Tribol. Int. 2003, 36, 41–47. [Google Scholar] [CrossRef]
- Liu, Q.; Yan, J.; Pham, D.T.; Zhou, Z.; Xu, W.; Wei, Q.; Ji, C. Identification and optimal selection of temperature-sensitive measuring points of thermal error compensation on a heavy-duty machine tool. Int. J. Adv. Manuf. Technol. 2016, 85, 345–353. [Google Scholar]
- Gomez-Acedo, E.; Olarra, A.; Zubieta, M.; Kortaberria, G.; Ariznabarreta, E.; de la Calle, L.N.L. Method for measuring thermal distortion in large machine tools by means of laser multilateration. Int. J. Adv. Manuf. Technol. 2015, 80, 523–534. [Google Scholar] [CrossRef]
- Kogbara, R.B.; Iyengar, S.R.; Grasley, Z.C.; Rahman, S.; Masad, E.A.; Zollinger, D.G. Correlation between thermal deformation and microcracking in concrete during cryogenic cooling. NDT E Int. 2016, 77, 1–10. [Google Scholar]
- Lee, J.H.; Kalkan, I. Analysis of Thermal Environmental Effects on Precast, Prestressed Concrete Bridge Girders: Temperature Differentials and Thermal Deformations. Adv. Struct. Eng. 2012, 15, 447–460. [Google Scholar] [CrossRef]
- Hinton, G.E. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. Comput. Sci. 2012, 3, 212–223. [Google Scholar]
- Tian, Y.; Liu, Z.; Cai, L.; Pan, G. The contact mode of a joint interface based on improved deep neural networks and its application in vibration analysis. J. Vibroeng. 2016, 18, 1388–1405. [Google Scholar]
- Rumerlhar, D.E. Learning representation by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar]
- Available online: www.deeplearning.net (accessed on 15 April 2020).
- Liu, D.Y.; Gibaru, O.; Perruquetti, W. Differentiation by integration with Jacobi polynomials. J. Comput. Appl. Math. 2011, 235, 3015–3032. [Google Scholar] [CrossRef] [Green Version]










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Pan, G. An Unsupervised Regularization and Dropout based Deep Neural Network and Its Application for Thermal Error Prediction. Appl. Sci. 2020, 10, 2870. https://doi.org/10.3390/app10082870
Tian Y, Pan G. An Unsupervised Regularization and Dropout based Deep Neural Network and Its Application for Thermal Error Prediction. Applied Sciences. 2020; 10(8):2870. https://doi.org/10.3390/app10082870
Chicago/Turabian StyleTian, Yang, and Guangyuan Pan. 2020. "An Unsupervised Regularization and Dropout based Deep Neural Network and Its Application for Thermal Error Prediction" Applied Sciences 10, no. 8: 2870. https://doi.org/10.3390/app10082870
APA StyleTian, Y., & Pan, G. (2020). An Unsupervised Regularization and Dropout based Deep Neural Network and Its Application for Thermal Error Prediction. Applied Sciences, 10(8), 2870. https://doi.org/10.3390/app10082870