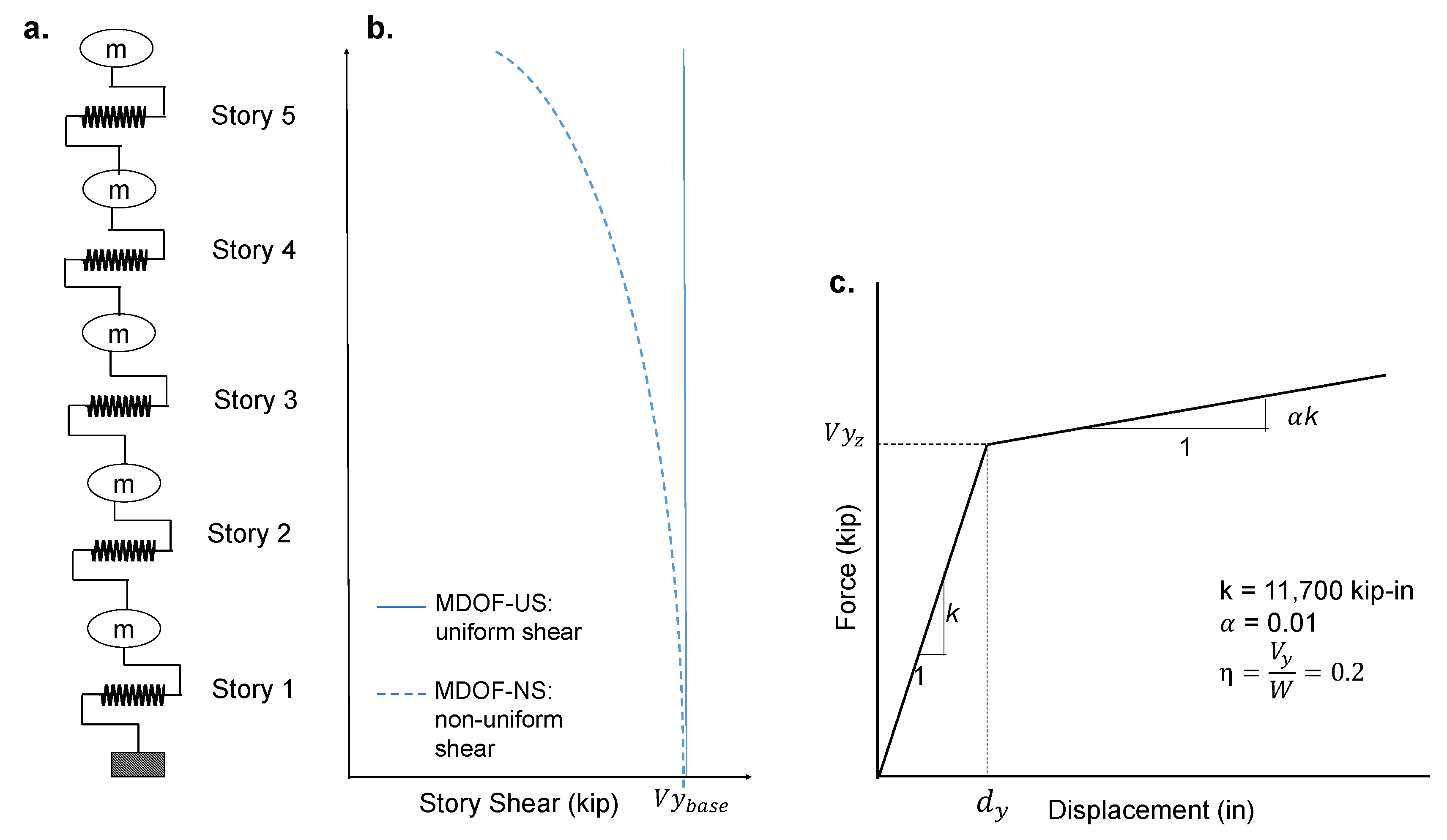
4.1.1. Model Description
Two MDOF models representing two five story buildings were used in this case study (
Figure 6a). The models were developed using
Steel01 material in OpenSees [
32] with the force-displacement behavior shown in
Figure 6c. The mass, stiffness, and damping of each story of the MDOF systems were based on pushover and eigenvalue analysis conducted in previous studies [
33,
34]. One of the MDOF systems, MDOF-US, had uniform shear capacity along the height of the building which is equal to the calculated base shear (
) at yield. The other MDOF system, MDOF-NS, was designed to have non-uniform shear capacity distribution along the height of the building. The shear capacity of MDOF-NS varied as follows,
where
is the yield shear at story
n,
is the height of the
n-th story from the base of the building,
is the ratio of the lateral stiffness at the top of the building to that at the base of the building [
45], and
H is the total building height. Equation (
19) was proposed in [
45] to take into account nonuniform stiffness of multistory buildings. The values of
and exponent
were taken as 0.3 and 1.5, respectively.
According to ASCE 7 [
46], the induced shear force at story
z,
, is determined as follows,
where
is the vertical distribution factor,
is the portion of the total effective seismic weight at story
z,
is the height of the story
z from the base of the building, and
p is an exponent related to the building natural period,
. For
s,
, for
s,
, and for
,
p is linearly interpolated. Thus, for the MDOF system at hand,
.
Table 3 shows the story values of the shear to base shear ratios according to code [
46] and for the two MDOF systems where the design of both systems was code conforming. However, MDOF-NS marginally met the code whereas MDOF-US had significantly higher values throughout the height and is a more conservative design which is often the case for low-to-medium rise buildings. For each model, a corresponding linear system was also developed using the
Elastic material from OpenSees [
32].
NTHA is performed on the models using both Set-1 and Set-2 records described in
Section 2.1.2. The acceleration was computed at each node along with the force and displacement for each spring element. Damage state was evaluated using Equation (
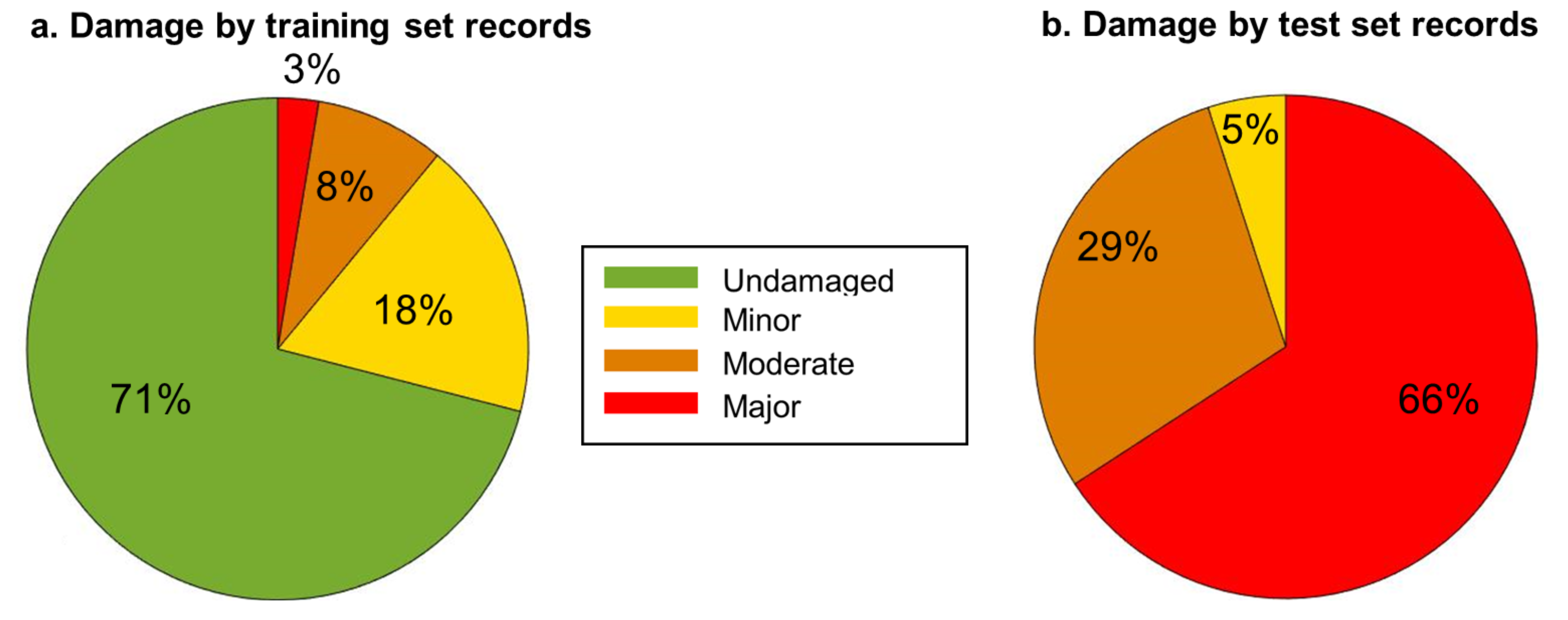
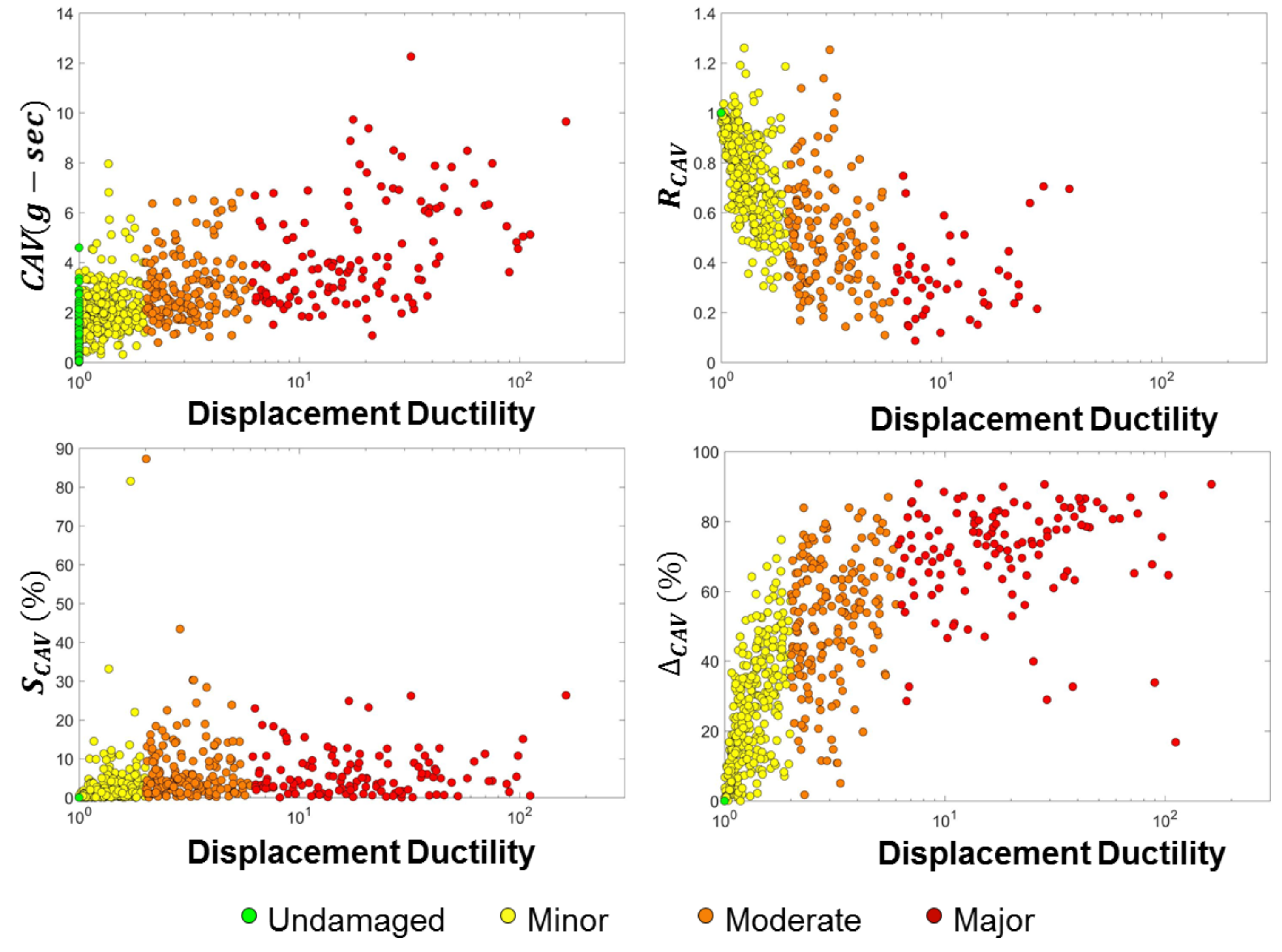
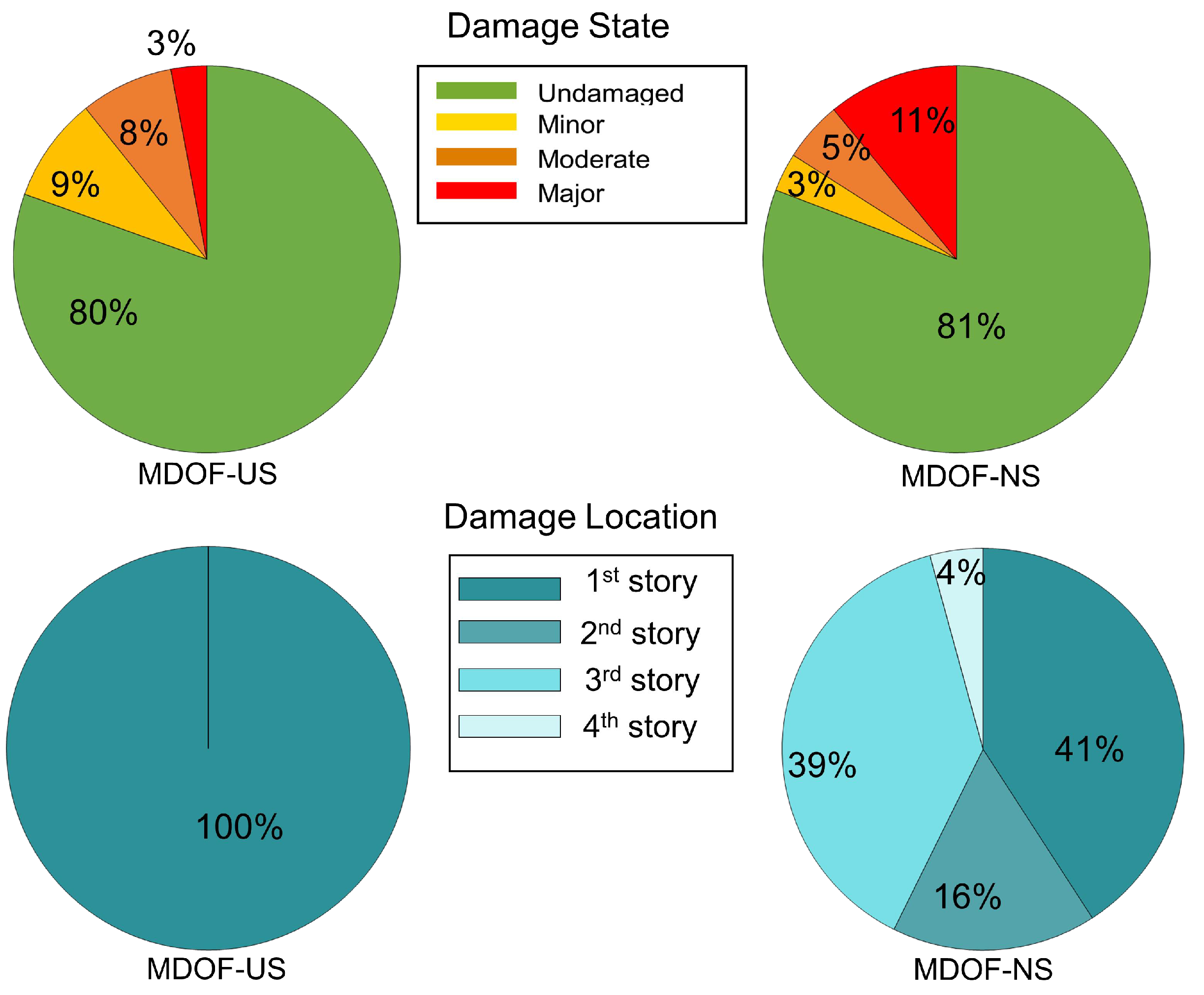
1) for each story. The worst damage state among the five stories was assigned as the damage state of the entire building and its location was assigned as the worst damage location. For the cases when the worst damage state occurred simultaneously at several locations, the lowest story was identified as the damage location. For the MDOF-US model, out of the 1710 cases, 1376 (80%), 150 (9%), 133 (8%), and 51 (3%) cases were respectively undamaged, minor damage, moderate damage, and major damage (
Figure 7). For the MDOF-NS model, 1382 (81%), 55 (3%), 86 (5%), and 187 (11%) cases were respectively undamaged, minor damage, moderate damage, and major damage (
Figure 7). The higher percentage of major damage in MDOF-NS was due to the non-uniform distribution of its shear capacity. The location of the worst damage for MDOF-US was the first story for all the 334 damaging events. In the case of MDOF-NS, damage locations of the 328 damaging events were distributed among all the bottom four stories (no damage was observed in the fifth story) but the majority of the damage locations were in the first and third stories. As previously discussed, the MDOF-US had a conservative design of uniform strength throughout the height. Therefore, the damage in this system occurred sequentially from bottom to top, i.e., the damage initiated at the first story and then moved up. For this reason, the extent of damage decreased with height for MDOF-US. However, for MDOF-NS, the strength variation resulted in concurrent damage at different stories, i.e., in many cases, the damage initiated at the second or third stories.
The features () and the ML approach (OLR algorithm) identified in the previous section were utilized to detect the location and severity of damage of the MDOF-US and MDOF-NS models. The of the first story was chosen where the earthquake force demand is expected to be the highest and the of the top story was selected as it is expected to capture the impact of damage at all lower stories. Moreover, in practice, the ground floor and roof of buildings are usually instrumented. Thus, using features associated with these two stories would be useful for direct applications to instrumented buildings. Using these features, the OLR was trained with TR-1 and tested against TE-1 and TE-2 for both MDOF-US and MDOF-NS with damage categories defined similar to the SDOF system.
Damage location was determined based on the assigned damaged state, i.e., the story that experienced the worst damage state was identified as the damage location. Using the damage state and location information obtained from the training set, the probability of the location of damage for a given damage state
was calculated where
n is the story number, i.e.,
and
y is the damage state, i.e.,
(
corresponds to the undamaged state). The probabilities of the worst damage location were subsequently determined by Equation (
21) for all five stories. The story with the highest
was considered as the damage location. Here,
was obtained using Equations (
11)–(
14).
4.1.2. Results
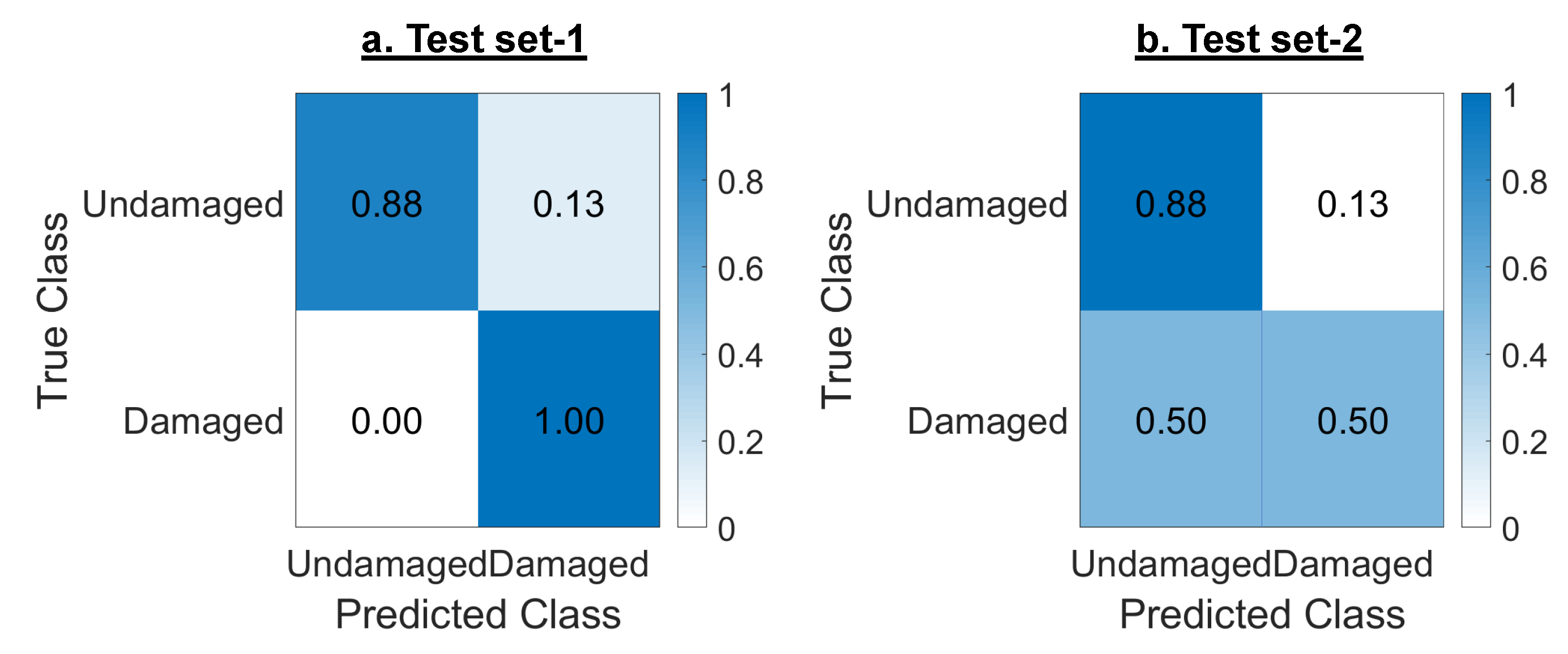
Table 4 shows the damage state and location accuracy values for the two MDOF models. Results reveal that MODF-US achieved damage state detection accuracy of 91% and 84% when tested with TE-1 and TE-2, respectively. The higher accuracy with TE-1 was expected since the test set came from the same distribution as the training set. The damage state detection accuracy for MDOF-US and MDOF-NS (91%) tested with TE-1 significantly improved to 97% for MDOF-NS when tested with TE-2.
Although accuracy is a widely used performance metric for ML models, other metrics can further explain the results, e.g., the recall value. Herein, the recall is defined as the proportion of the actual damages identified correctly for each damage state. The closer the recall value to 1, the better the performance of the model. The recall value for the undamaged state was computed using Equation (
22).
where TU = true undamaged cases, TD1 = true minor damage cases, TD2 = true moderate damage cases, and TD3 = true major damage cases. Similarly, recall values were calculated for the other damage states.
Table 5 presents the class-specific recall values for the two MDOF systems. From this table, it is evident that for MDOF-US, the model predicted very well the undamaged class (0.99) and the major damage class (0.92). For moderate damage, it did fairly with a 0.78 recall value. However, minor damage was mostly misclassified due to the definition of the damage states. Since minor damage was defined as
, with this narrow range, the model performed poorly to detect minor damages which was further worsened by the lack of data from minor damage states. Similar performance of the model was observed for MDOF-NS. Major damage class had a higher recall value (0.97) than the MDOF-US, because of more data available for this damage state. Both MDOF-US and MDOF-NS had the same recall for the undamaged class.
Table 4 also shows that damage locations were detected with 97.5% accuracy for MDOF-US with both TE-1 and TE-2. It is noted that three inaccurate cases were detected where the worst damage took place in both first and second stories, i.e., the first story was labeled as the correct location, but the model only identified the second story as the worst damage location. The damage locations were detected with 93% and 95% accuracy with TE-1 and TE-2, respectively, for MDOF-NS. Damage location detection for this model was more critical since the non-uniformity of stiffness introduced significant uncertainty about the damage locations. Thus, the results show that the damage location was identified with high confidence, even for non-uniform structural properties, using the proposed method.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}