
Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN)


Abstract
:1. Introduction
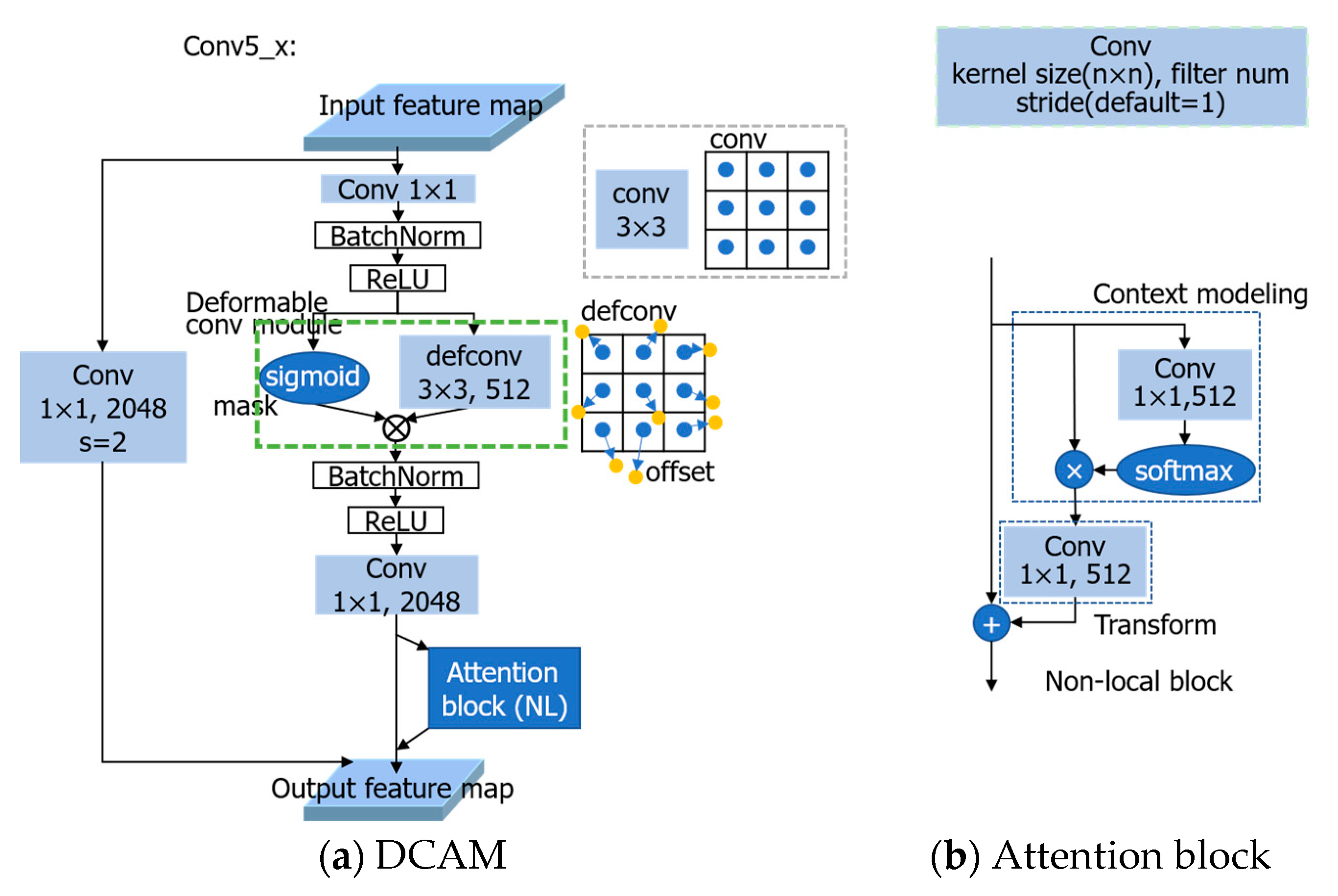
- First, we have designed a deformable convolution with attention module (DCAM) that generates the attention feature map corresponding to the deformable receptive field. The DCAM enables the network to adapt to diverse poses of pedestrians and occluded instances via deformable convolution. Furthermore, it can obtain attention features to capture effective contextual dependency information among different positions by a non-local (NL) attention block.
- Second, we have optimized the detection localization by using an improved loss function. The traditional smooth-L1 loss has been replaced with complete-IoU (CIoU) loss [13] for regression. The regression loss with CIoU, instead of the commonly used -norm, can facilitate prediction with more accurate localization, as shown in Figure 2.
- Third, effective techniques for pedestrian detection in diverse traffic scenes have been explored in our work. The distance IoU-based (DIoU) NMS was adopted to refine the prediction boxes to improve the detection performance of occluded instances. A preprocessing with adaptive local tone mapping (ALTM) based on the Retinex [15] algorithm was implemented to enhance the detection accuracy under poor illuminance.
- Finally, experiments on three well-known traffic scene pedestrian benchmarks, Caltech [8], CityPersons [9], and EuroCity Persons (ECP) datasets [14], demonstrated that the proposed method leads to notable improvement in performance for the detection of heavily occluded pedestrians. Compared with the published best results, our proposed method achieved significant improvements of 12.44%, 5.3%, and 5.0%, respectively, in of the heavily occluded sets of the Caltech [8], CityPersons [9], and ECP [14] datasets.
2. Related Works
2.1. Deep-Learning-Based Pedestrian Detection Methods
2.2. Occluded Pedestrian Detection Methods
2.3. Attention- and Deformable-Convolution-Related Methods
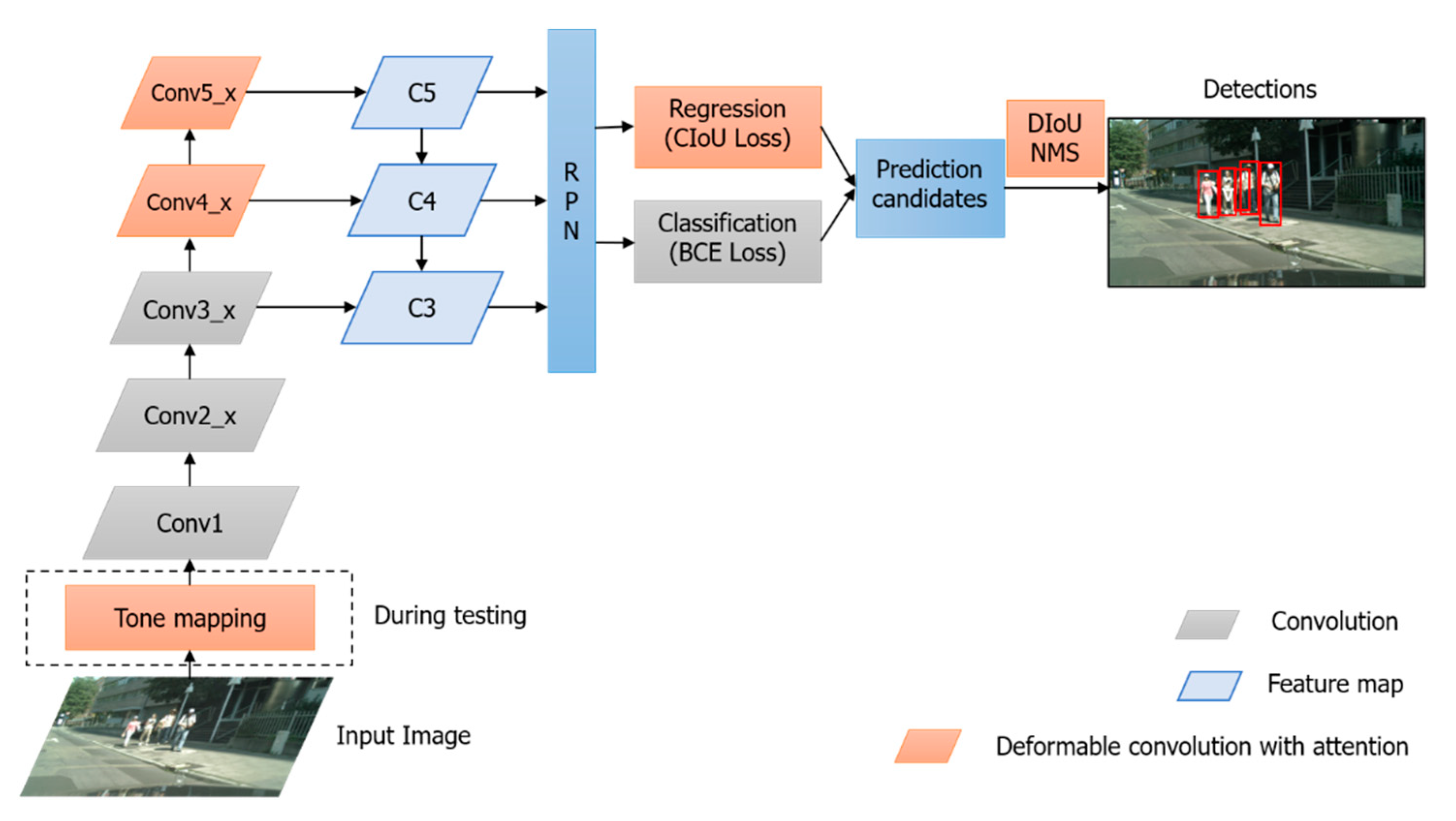
3. Deformable Attention-Guided Network (DAGN)
3.1. Deformable Convolution with Attention Module (DCAM)
3.2. Target Optimization
3.2.1. Loss Function
3.2.2. Non-Maximum Suppression for Prediction
3.3. Illumination Preprocessing for Testing
4. Experimental Results
4.1. Experimental Setup and Evaluation Metrics
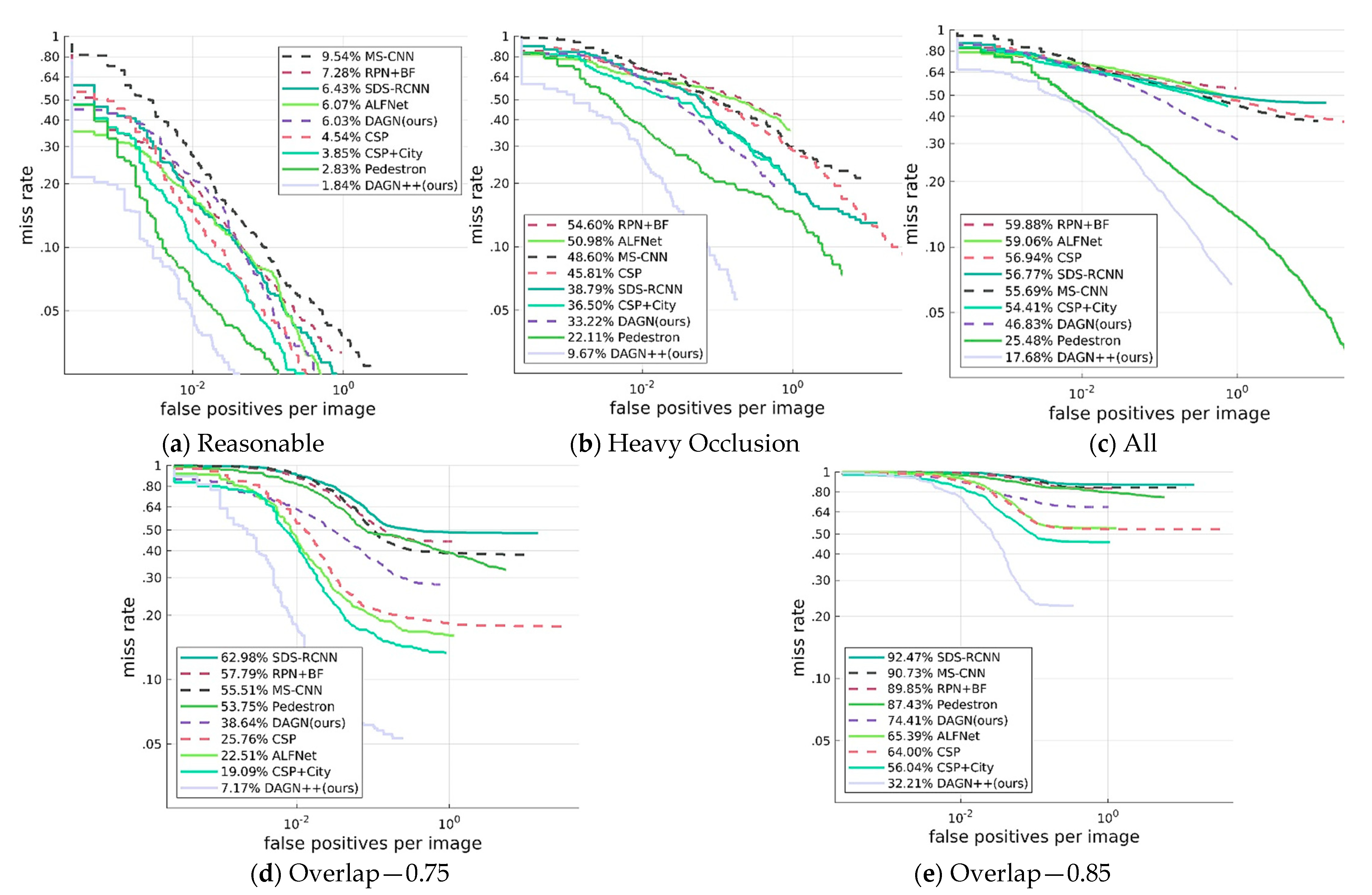
4.2. Caltech Pedestrian Dataset
4.2.1. Training Configuration on Caltech Dataset
4.2.2. Ablation Experiments on Caltech Pedestrian Dataset
4.2.3. Comparison with the State-of-the-Art Methods of Caltech Pedestrian Datasets
4.3. CityPersons Dataset
4.3.1. Training Configuration
4.3.2. Comparison with the State-of-the-Art Method of CityPersons
4.4. EuroCity Persons (ECP) Dataset
4.4.1. Training Configuration
4.4.2. Comparison with State-of-the-Art ECP Dataset
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5182–5191. [Google Scholar]
- Brazil, G.; Yin, X.; Liu, X. Illuminating Pedestrians via Simultaneous Detection and Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4960–4969. [Google Scholar]
- Xie, H.; Chen, Y.; Shin, H. Context-aware pedestrian detection especially for small-sized instances with Deconvolution Integrated Faster RCNN (DIF R-CNN). Appl. Intell. 2019, 49, 1200–1211. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster r-cnn doing well for pedestrian detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–457. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the Lecture Notes in Computer Science (Including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9908, pp. 354–370. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning efficient single-stage pedestrian detectors by asymptotic localization fitting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 11218, pp. 643–659. [Google Scholar] [CrossRef]
- Xie, H.; Shin, H. Two-stream small-scale pedestrian detection network with feature aggregation for drone-view videos. Multidimens. Syst. Signal Process. 2021, 32, 897–913. [Google Scholar] [CrossRef]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets V2: More deformable, better results. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. EuroCity Persons: A Novel Benchmark for Person Detection in Traffic Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1844–1861. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahn, H.; Keum, B.; Kim, D.; Lee, H.S. Adaptive local tone mapping based on retinex for high dynamic range images. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 11–14 January 2013; pp. 153–156. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A.; Ap, C. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ullah, I.; Manzo, M.; Shah, M.; Madden, M. Graph Convolutional Networks: Analysis, improvements and results. arXiv 2019, arXiv:1912.09592. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-Aware Fast R-CNN for Pedestrian Detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Cheng, J.; Liu, H.; Tang, M. PCN: Part and context information for pedestrian detection with CNNs. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017; pp. 1–13. [Google Scholar] [CrossRef]
- Ouyang, W.; Zhou, H.; Li, H.; Li, Q.; Yan, J.; Wang, X. Jointly Learning Deep Features, Deformable Parts, Occlusion and Classification for Pedestrian Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1874–1887. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion Loss: Detecting Pedestrians in a Crowd. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7774–7783. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-Aware R-CNN: Detecting Pedestrians in a Crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining pedestrian detection in a crowd. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6452–6461. [Google Scholar]
- Zhang, J.; Lin, L.; Zhu, J.; Li, Y.; Chen, Y.C.; Hu, Y.; Hoi, C.H.S. Attribute-aware Pedestrian Detection in a Crowd. IEEE Trans. Multimed. 2020, 9210, 1–13. [Google Scholar] [CrossRef]
- Zhang, C.; Kim, J. Object detection with location-aware deformable convolution and backward attention filtering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9444–9453. [Google Scholar] [CrossRef]
- Liu, N.; Long, Y.; Zou, C.; Niu, Q.; Pan, L.; Wu, H. Adcrowdnet: An attention-injective deformable convolutional network for crowd understanding. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3220–3229. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Woo1, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Drago, F.; Myszkowski, K.; Annen, T.; Chiba, N. Adaptive Logarithmic Mapping for Displaying High Contrast Scenes. Comput. Graph. Forum 2003, 22, 419–426. [Google Scholar] [CrossRef]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An Open-Source Deep Learning Platform from Industrial Practice. Front. Data Comput. 2019, 1, 105–115. [Google Scholar] [CrossRef]
- PaddleDetection, v2.0.0-rc0. Available online: https://github.com/PaddlePaddle/PaddleDetection (accessed on 23 February 2021).
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Pedestrian detection: The elephant in the room. arXiv 2020, arXiv:2003.08799. [Google Scholar]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 536–551. [Google Scholar] [CrossRef]











{kind=link}
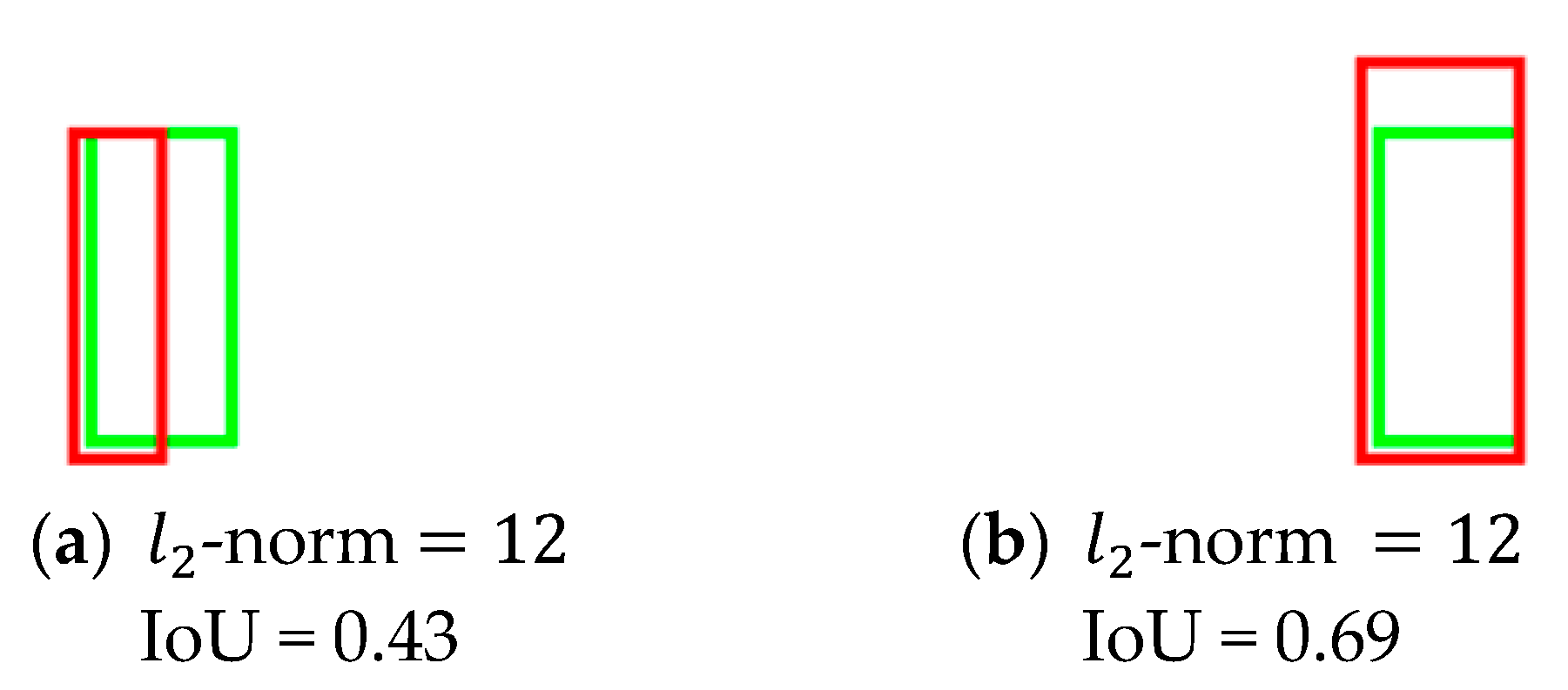{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Case | Height of Pedestrian (pixels) | Occlusion Area | Visibility |
|---|---|---|---|---|
| Caltech [8] | Reasonable | >50 | <35% | >0.65 |
| Heavy occlusion | >50 | 35–80% | 0.2–0.65 | |
| All | >20 | - | >0.2 | |
| CityPersons [9] | Reasonable | >50 | - | >0.65 |
| Heavy occlusion | >50 | - | >0.9 | |
| Partial occlusion | >50 | - | 0.65–0.9 | |
| Bare | >50 | - | <0.65 | |
| Small | 50–75 | - | >0.65 | |
| Medium | 75–100 | - | >0.65 | |
| Large scale | >100 | - | >0.65 | |
| EuroCity Persons [14] | Reasonable | >40 | <40% | - |
| Small | 30–60 | <40% | - | |
| Occluded | >40 | 40–80% | - | |
| All | >30 | - | - |
| Cascade R-CNN+FPN | DCAM (−8.51) | CIoU Loss (−4.17) | DIoU-NMS (−5.48) | ALTM (−3.92) | MR (%) |
|---|---|---|---|---|---|
| - | 55.30 | ||||
| - | √ | 46.79 | |||
| - | √ | √ | 42.62 | ||
| - | √ | √ | √ | 37.14 | |
| - | √ | √ | √ | √ | 33.22 |
| Method | Miss Rate | Hardware | Scale | Run Time (s/img) | ||
|---|---|---|---|---|---|---|
| R | HO | A | ||||
| MS-CNN [5] | 9.54 | 48.60 | 55.77 | Titan GPU | ×1 | 0.067 |
| RPN + BF [4] | 7.28 | 54.60 | 59.88 | Tesla K40 GPU | ×1.5 | 0.5 |
| SDS-RCNN [2] | 6.43 | 38.70 | 56.77 | Titan × GPU | ×1.5 | 0.21 |
| ALF [6] | 6.07 | 50.98 | 59.06 | GTX1080 Ti GPU | ×1 | 0.05 |
| CSP [1] | 4.54 | 45.81 | 56.94 | GTX1080 Ti GPU | ×1 | 0.058 |
| Pedestron [42] | 1.48 | 22.11 | 25.48 | Nvidia tesla V100 | ×1 | - |
| DAGN (ours) | 6.03 | 33.22 | 46.83 | Titan × GPU | ×1 | 0.11 |
| DAGN++ (ours) | 1.84 | 9.67 | 17.68 | Titan × GPU | ×1 | 0.11 |
| Method | Backbone | R | H | P | B | S | M | L | Run Time (s/img) |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [18] | VGG-16 | 15.4 | - | - | - | 25.6 | 7.2 | 7.9 | - |
| TLL [43] | ResNet-50 | 15.5 | 53.6 | 17.2 | 10.0 | - | - | - | - |
| RepLoss [25] | ResNet-50 | 13.2 | 56.9 | 16.8 | 7.6 | - | - | - | - |
| OR-CNN [26] | VGG-16 | 12.8 | 55.7 | 15.3 | 6.7 | - | - | - | - |
| ALF [6] | ResNet-50 | 12.0 | 51.9 | 11.4 | 8.4 | 19.0 | 5.7 | 6.6 | 0.27 |
| CSP [1] | ResNet-50 | 11.0 | 49.3 | 10.4 | 7.3 | 16.0 | 3.7 | 6.5 | 0.33 |
| APD [28] | ResNet-50 | 10.6 | 49.8 | 9.5 | 7.1 | - | - | - | 0.12 |
| APD [28] | DLA-34 | 8.8 | 46.6 | 8.3 | 5.8 | - | - | - | 0.16 |
| Pedestron [42] | HRNet | 7.5 | 33.9 | 5.7 | 6.2 | 8.0 | 3.0 | 4.3 | 0.33 |
| DAGN (ours) | ResNet-50 | 11.9 | 43.9 | 12.1 | 7.6 | 18.7 | 5.8 | 5.9 | 0.22 |
| DAGN++ (ours) | ResNet-50 | 8.4 | 28.6 | 7.0 | 5.6 | 9.2 | 2.4 | 5.6 | 0.22 |
| Method | Reasonable | Small | Occluded | All |
|---|---|---|---|---|
| SSD [16] | 13.1 | 23.5 | 46.0 | 29.6 |
| Faster R-CNN [18] | 10.1 | 19.6 | 38.1 | 25.1 |
| YOLOv3 [17] | 9.7 | 18.6 | 40.1 | 24.2 |
| Cascade R-CNN [31] | 6.6 | 13.6 | 31.3 | 19.3 |
| DAGN (ours) | 5.9 | 14.2 | 26.3 | 17.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Zheng, W.; Shin, H. Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN). Appl. Sci. 2021, 11, 6025. https://doi.org/10.3390/app11136025
Xie H, Zheng W, Shin H. Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN). Applied Sciences. 2021; 11(13):6025. https://doi.org/10.3390/app11136025
Chicago/Turabian StyleXie, Han, Wenqi Zheng, and Hyunchul Shin. 2021. "Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN)" Applied Sciences 11, no. 13: 6025. https://doi.org/10.3390/app11136025
APA StyleXie, H., Zheng, W., & Shin, H. (2021). Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN). Applied Sciences, 11(13), 6025. https://doi.org/10.3390/app11136025