
Gaussian Parameters Correlate with the Spread of COVID-19 Pandemic: The Italian Case




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Gaussian Growth Rate Model
3. Results and Discussion
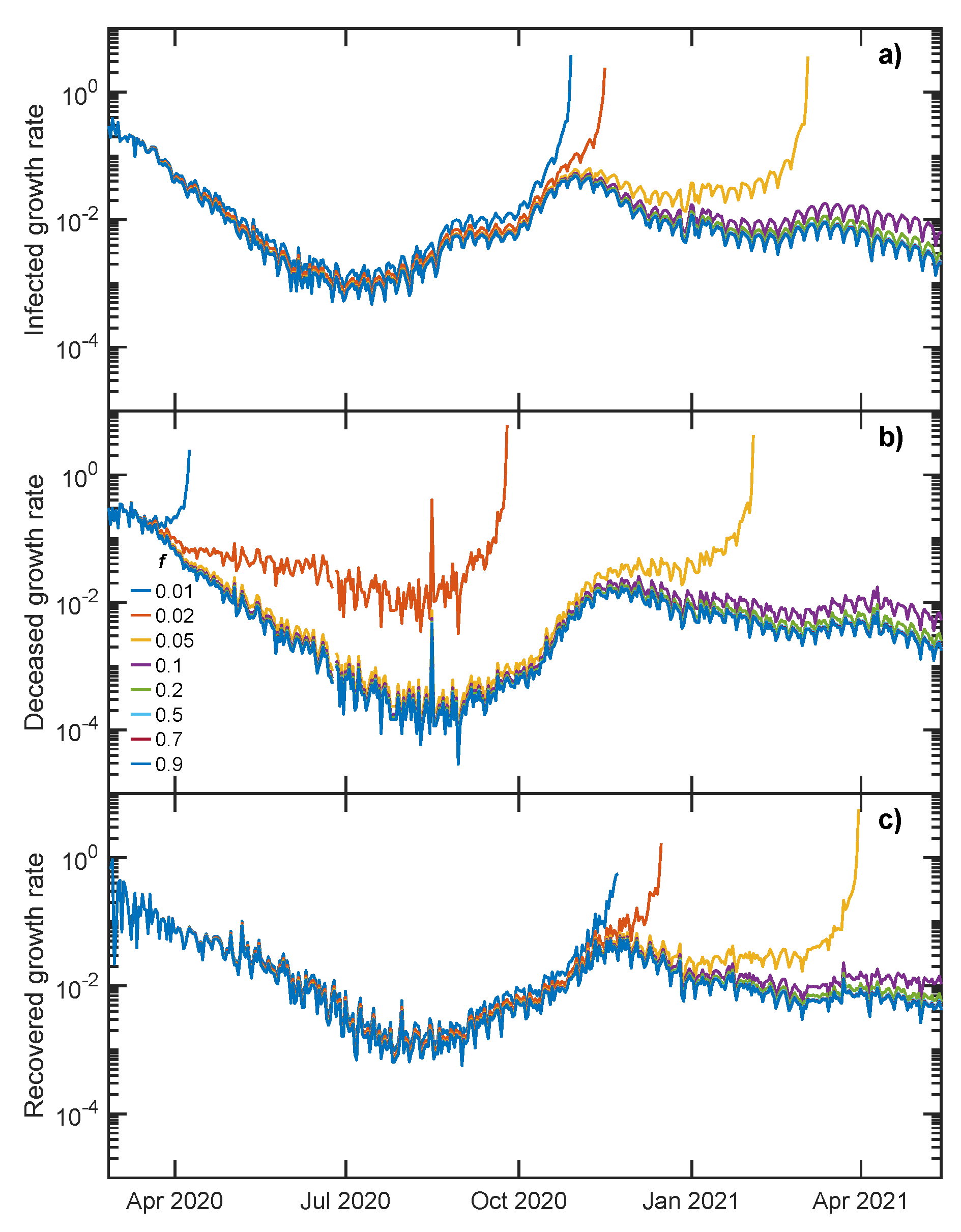
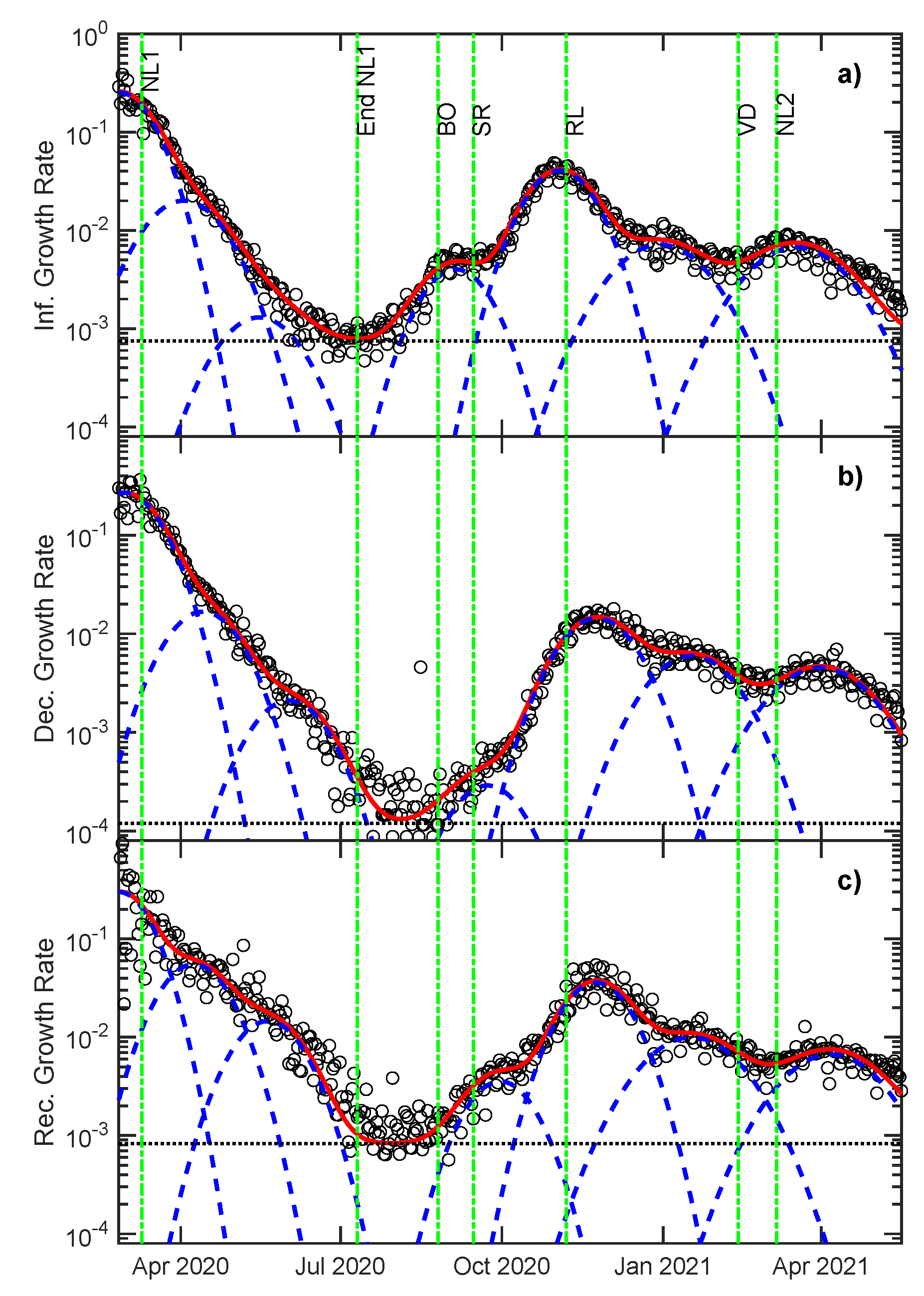
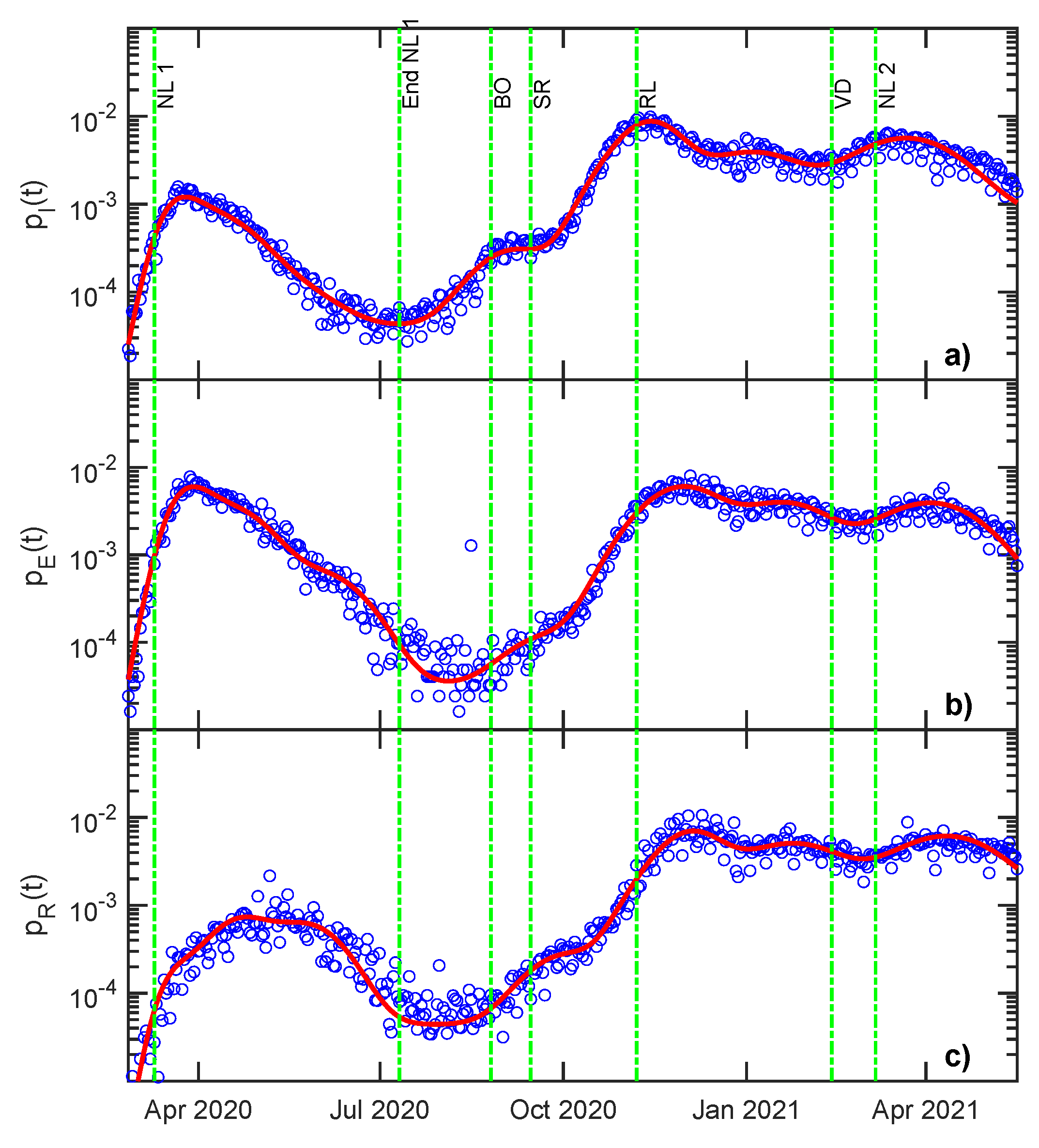
3.1. Growth Rate Analysis
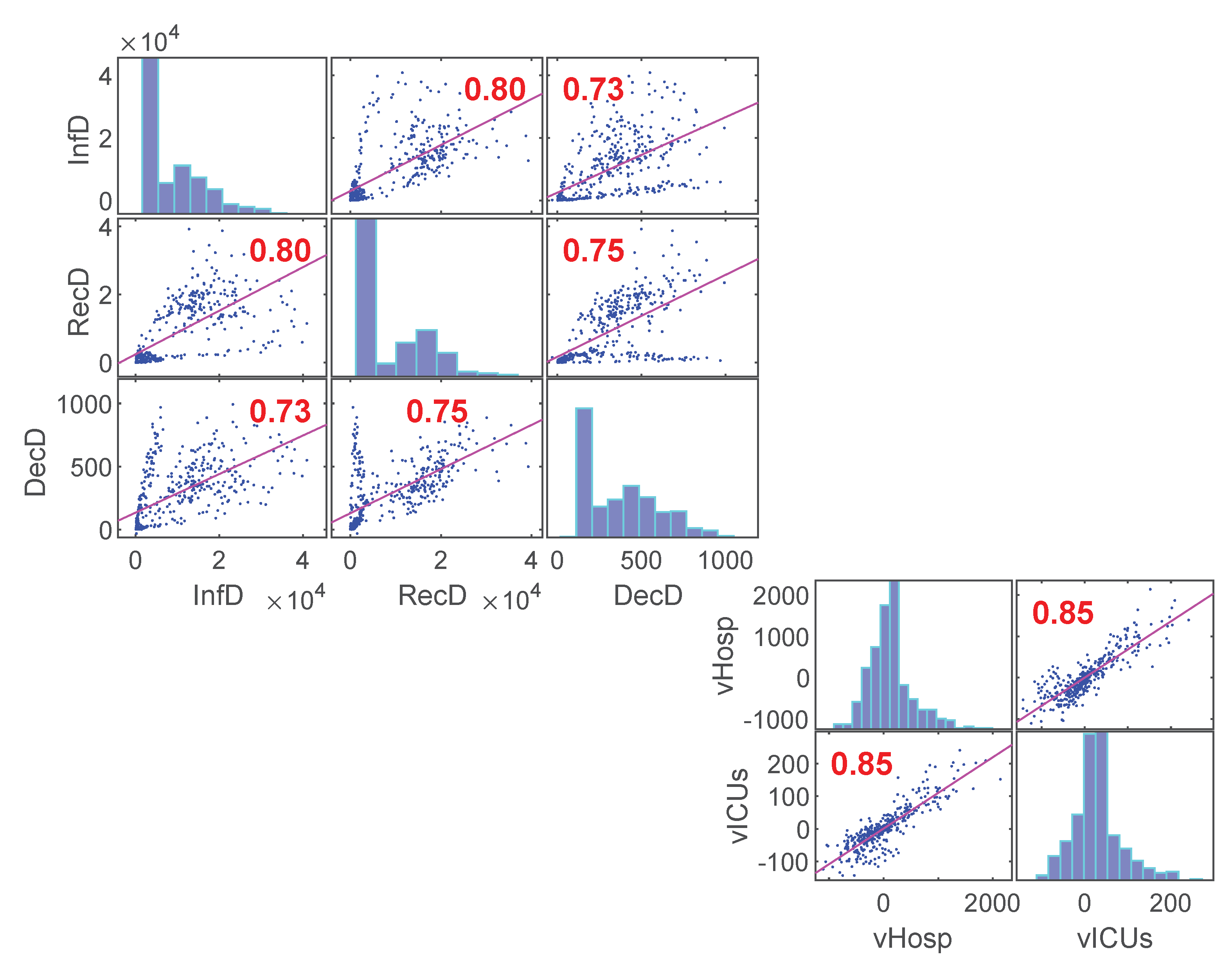
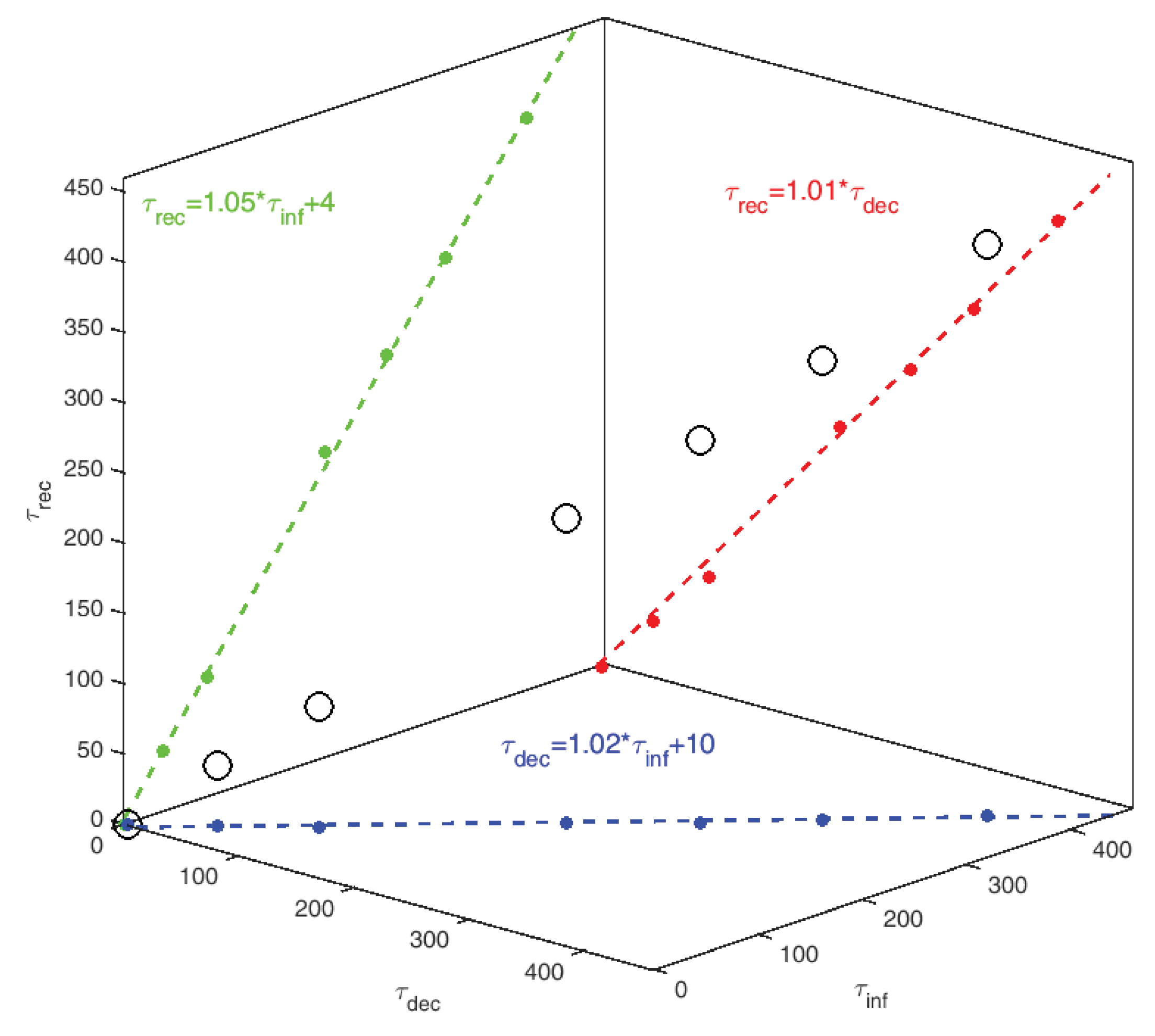
3.2. Statistical Analysis—Correlations
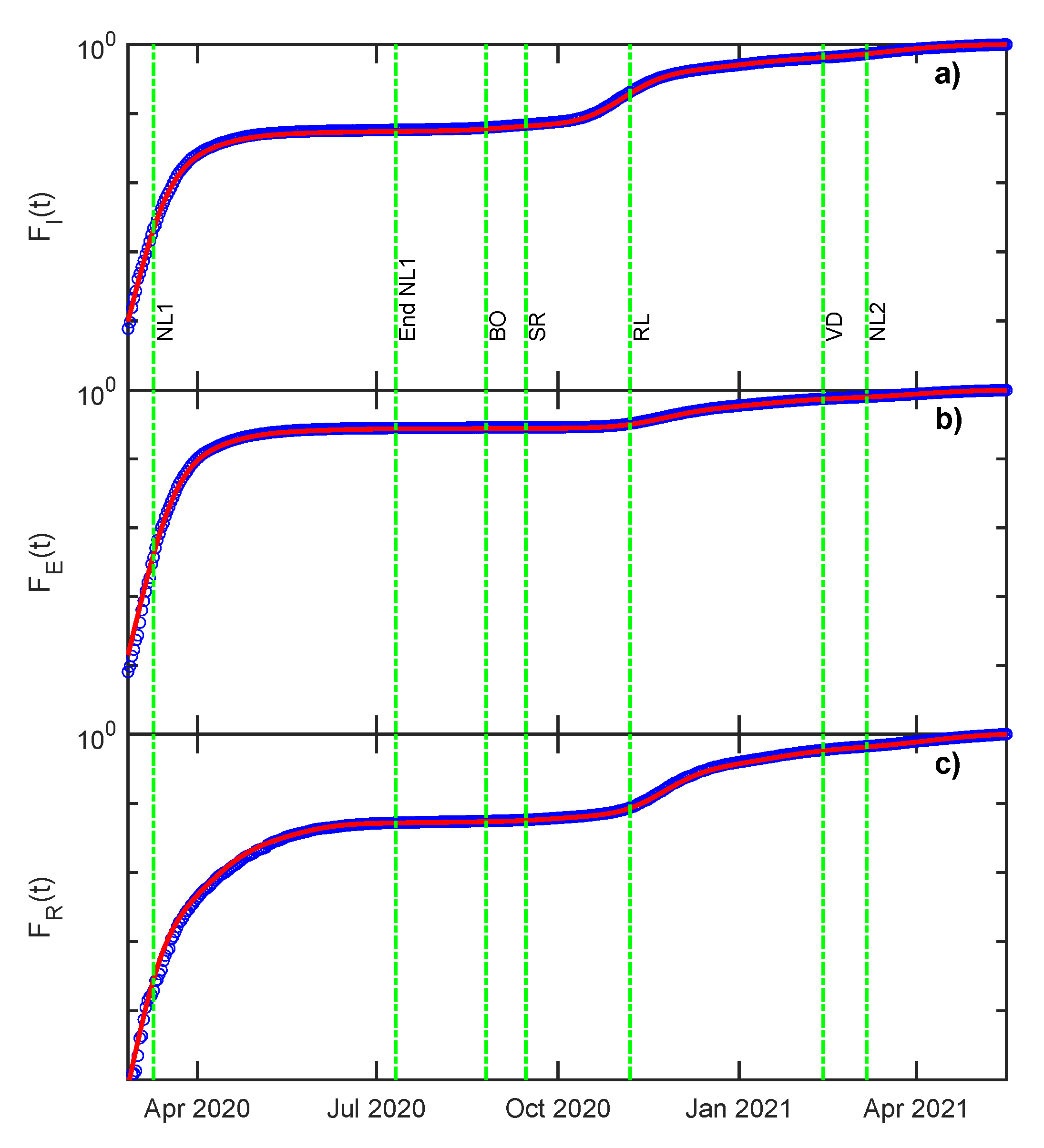
3.3. Statistical Analysis—Cumulative and Density Functions
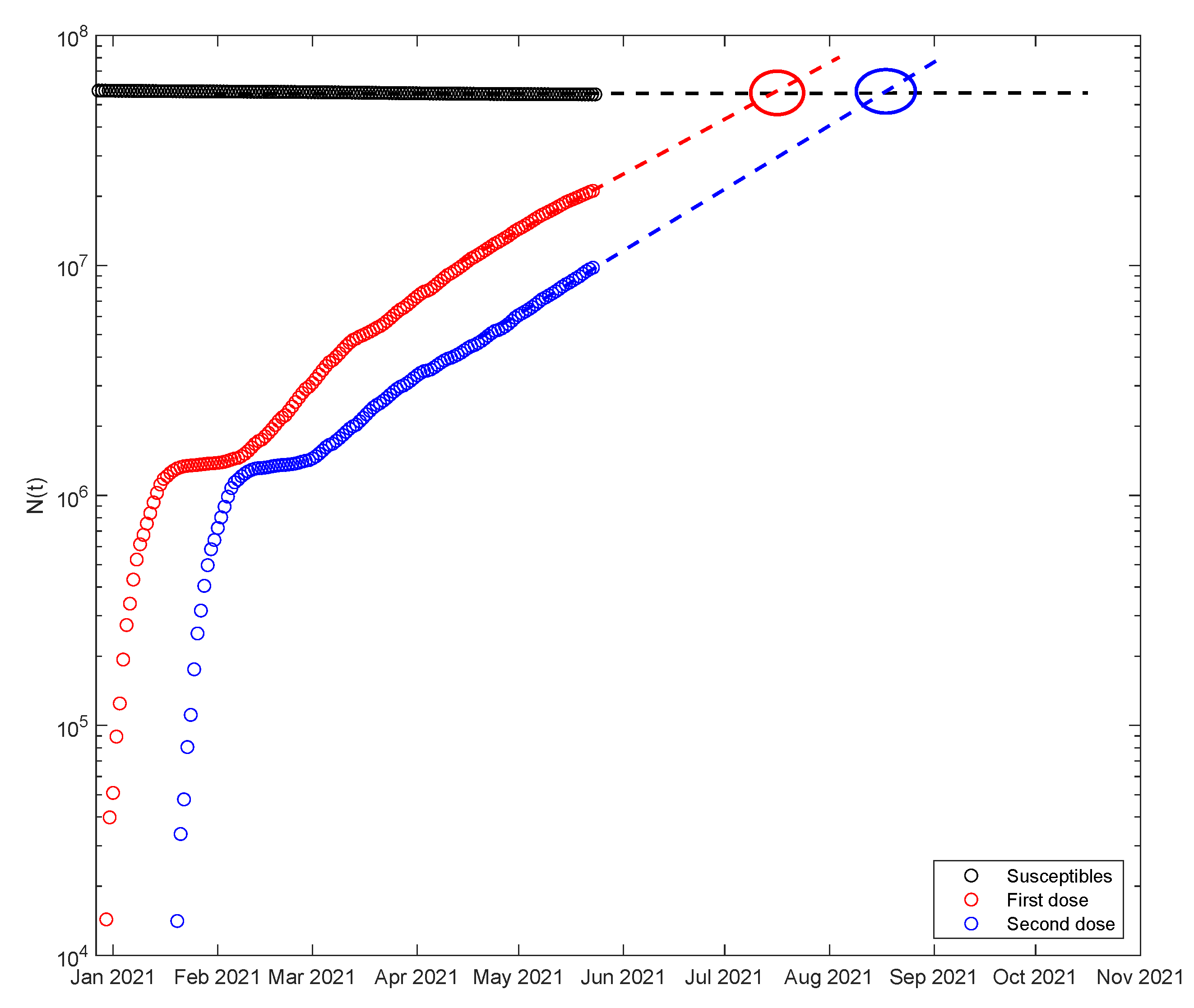
4. Conclusions and Future Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| COVID-19 | 2019 Coronavirus Desease |
| SIR | Susceptible-Infected-Recovered |
| ODE | Ordinary differential equation |
| ISS | National Health Institute of Italy |
| GGR | Gaussian Growth Rate |
| WHO | World Health Organization |
| CFR | Case-Fatality Ratio |
| IFR | Infection Fatality Ratio |
| ICU | admitted to Intensive Care |
| CDF | Cumulative Distribution Function |
| Probability Density Function |
References
- COVID Live Update. Reported Cases and Deaths by Country or Territory. Available online: https://www.worldometers.info/coronavirus/#countries (accessed on 24 May 2021).
- WHO. A Year without Precedent: WHO’s COVID-19 Response. Available online: https://www.who.int/news-room/spotlight/a-year-without-precedent-who-s-covid-19-response (accessed on 24 May 2021).
- WHO. WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 24 May 2021).
- Zhu, Z.; Lian, X.; Su, X.; Wu, W.; Marraro, G.; Zeng, Y. From SARS and MERS to COVID-19: A brief summary and comparison of severe acute respiratory infections caused by three highly pathogenic human coronaviruses. Respir. Res. 2020, 21, 224. [Google Scholar] [CrossRef]
- Abdelrahman, Z.; Li, M.; Wang, X. Comparative Review of SARS-CoV-2, SARS-CoV, MERS-CoV, and Influenza A Respiratory Viruses. Front. Immunol. 2020, 11, 2309. [Google Scholar] [CrossRef]
- Soufi, G.J.; Hekmatnia, A.; Nasrollahzadeh, M.; Shafiei, N.; Sajjadi, M.; Iravani, P.; Fallah, S.; Iravani, S.; Varma, R.S. SARS-CoV-2 (COVID-19): New Discoveries and Current Challenges. Appl. Sci. 2020, 10, 3641. [Google Scholar] [CrossRef]
- Vytla, V.; Ramakuri, S.K.; Peddi, A.; Srinivas, K.K.; Ragav, N.N. Mathematical Models for Predicting Covid-19 Pandemic: A Review. J. Phys. Conf. Ser. 2021, 1797, 012009. [Google Scholar] [CrossRef]
- Anirudh, A. Mathematical modeling and the transmission dynamics in predicting the Covid-19—What next in combating the pandemic. Infect. Dis. Model. 2020, 5, 366–374. [Google Scholar] [CrossRef]
- Adiga, A.; Dubhashi, D.; Lewis, B.; Marathe, M.; Venkatramanan, S.; Vullikanti, A. Mathematical Models for COVID-19 Pandemic: A Comparative Analysis. J. Indian Inst. Sci. 2020, 100, 793–807. [Google Scholar] [CrossRef] [PubMed]
- Holmdahl, I.; Buckee, C. Wrong but Useful—What Covid-19 Epidemiologic Models Can and Cannot Tell Us. N. Engl. J. Med. 2020, 383, 303–305. [Google Scholar] [CrossRef]
- Bertuzzo, E.; Mari, L.; Pasetto, D.; Miccoli, S.; Casagrandi, R.; Gatto, M.; Rinaldo, A. The geography of COVID-19 spread in Italy and implications for the relaxation of con finement measures. Nat. Commun. 2020, 11, 4264. [Google Scholar] [CrossRef]
- Ortega, J.M.; Bernabé-Moreno, J. Modelling the Degree of Emotional Concern: COVID-19 Response in Social Media. Appl. Sci. 2021, 11, 3872. [Google Scholar] [CrossRef]
- Sperrin, M.; McMillan, B. Prediction models for covid-19 outcomes. BMJ 2020, 371. [Google Scholar] [CrossRef]
- Valvo, P.S. A Bimodal Lognormal Distribution Model for the Prediction of COVID-19 Deaths. Appl. Sci. 2020, 10, 8500. [Google Scholar] [CrossRef]
- Syeda, H.B.; Syed, M.; Sexton, K.W.; Syed, S.; Begum, S.; Syed, F.; Prior, F.; Yu, F., Jr. Role of Machine Learning Techniques to Tackle the COVID-19 Crisis: Systematic Review. JMIR Med. Inform. 2021, 9, e23811. [Google Scholar] [CrossRef] [PubMed]
- Alvarez, M.; Gonzalez, E.; Trujillo de Santiago, G. Modeling COVID-19 epidemics in an Excel spreadsheet to enable first-hand accurate predictions of the pandemic evolution in urban areas. Sci. Rep. 2021, 11, 4327. [Google Scholar] [CrossRef] [PubMed]
- Bertozzi, A.L.; Franco, E.; Mohler, G.; Short, M.B.; Sledge, D. The challenges of modeling and forecasting the spread of COVID-19. Proc. Natl. Acad. Sci. USA 2020, 117, 16732–16738. [Google Scholar] [CrossRef]
- Giordano, G.; Blanchini, F.; Bruno, R.; Colaneri, P.; Filippo, A.; Matteo, A.; Colaneri, M. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat. Med. 2020, 26, 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Xu, K.; Li, Z.; Pang, K.; He, H. Improved Epidemic Dynamics Model and Its Prediction for COVID-19 in Italy. Appl. Sci. 2020, 10, 4930. [Google Scholar] [CrossRef]
- Capuano, F. Modeling Growth, Containment and Decay of the COVID-19 Epidemic in Italy. Front. Phys. 2020, 8, 554. [Google Scholar] [CrossRef]
- Jersakova, R.; Lomax, J.; Hetherington, J.; Lehmann, B.; Nicholson, G.; Briers, M.; Holmes, C. Bayesian imputation of COVID-19 positive test counts for nowcasting under reporting lag. arXiv 2021, arXiv:arXiv:2103.12661. [Google Scholar]
- Moriña, D.; Fernández-Fontelo, A.; Cabaña, A.; Arratia, A.; Puig, P. Bayesian Synthetic Likelihood Estimation for Underreported Non-Stationary Time Series: Covid-19 Incidence in Spain. arXiv 2021, arXiv:arXiv:2104.07575. [Google Scholar]
- Mukherjee, S.; Mondal, S.; Bagchi, B. Persistence of a pandemic in the presence of susceptibility and infectivity distributions in a population: Mathematical model. medRxiv 2021. [Google Scholar] [CrossRef]
- Kröger, M.; Schlickeiser, R. Gaussian Doubling Times and Reproduction Factors of the COVID-19 Pandemic Disease. Front. Phys. 2020, 8, 276. [Google Scholar] [CrossRef]
- Wu, D.; Mac Aonghusa, P.; O’Shea, D.F. Correlation of national and healthcare workers COVID-19 infection data; implications for large-scale viral testing programs. PLoS ONE 2021, 16, e0250699. [Google Scholar] [CrossRef]
- Singhal, A.; Singh, P.; Lall, B.; Joshi, S.D. Modeling and prediction of COVID-19 pandemic using Gaussian mixture model. Chaos Solitons Fractals 2020, 138, 110023. [Google Scholar] [CrossRef]
- Schüttler, J.; Schlickeiser, R.; Schlickeiser, F.; Kröger, M. Covid-19 Predictions Using a Gauss Model, Based on Data from April 2. Physics 2020, 2, 197–212. [Google Scholar] [CrossRef]
- Wu, K.; Darcet, D.; Wang, Q.; Sornette, D. Generalized logistic growth modeling of the COVID-19 outbreak: Comparing the dynamics in the 29 provinces in China and in the rest of the world. Nonlinear Dyn. 2020, 101, 1561–1581. [Google Scholar] [CrossRef] [PubMed]
- Ma, J. Estimating epidemic exponential growth rate and basic reproduction number. Infect. Dis. Model. 2020, 5, 129–141. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G.; Walker, G.T. A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. Contain. Pap. Math. Phys. Character 1927, 115, 700–721. [Google Scholar] [CrossRef] [Green Version]
- Protezione Civile Italiana. COVID-19 Epidemiological Data Monitoring. Available online: https://github.com/pcm-dpc/COVID-19 (accessed on 24 May 2021).
- Rodrigues, H. Application of SIR epidemiological model: New trends. arXiv 2016, arXiv:1611.02565. [Google Scholar]
- Wacker, B.; Schlueter, J. Time-Continuous and Time-Discrete SIR Models Revisited: Theory and Applications. Adv. Differ. Equ. 2020, 2020, 556. [Google Scholar] [CrossRef]
- Chowell, G.; Hincapie-Palacio, D.; Ospina, J.; Pell, B.; Tariq, A.; Dahal, S.; Moghadas, S.; Smirnova, A.; Simonsen, L.; Viboud, C. Using Phenomenological Models to Characterize Transmissibility and Forecast Patterns and Final Burden of Zika Epidemics. PLoS Curr. 2016, 8. [Google Scholar] [CrossRef] [PubMed]
- Aschwanden, C. Why herd immunity for COVID is probably impossible. Nature 2021, 591, 520–522. [Google Scholar] [CrossRef]
- Johns Hopkins University of Medicine. Mortality Analyses. Available online: https://coronavirus.jhu.edu/data/mortality (accessed on 24 May 2021).
- European Commision. EU Vaccines Strategy. Available online: https://ec.europa.eu/info/live-work-travel-eu/coronavirus-response/public-health/eu-vaccines-strategy_en (accessed on 24 May 2021).
- Hopkins Tanne, J. Covid-19: Biden aims for 70% of Americans to have at least one vaccination by 4 July. BMJ 2021, 373, n1155. [Google Scholar] [CrossRef] [PubMed]
- Johns Hopkins University of Medicine. What Is Herd Immunity and How Can We Achieve It with COVID-19? Available online: https://www.jhsph.edu/covid-19/articles/achieving-herd-immunity-with-covid19.html (accessed on 6 April 2021).
- Modi, C.; Böhm, V.; Ferraro, S.; Stein, G.; Seljak, U. Estimating COVID-19 mortality in Italy early in the COVID-19 pandemic. Nat. Commun. 2021, 12, 2729. [Google Scholar] [CrossRef]
- De Natale, G.; Ricciardi, V.; De Luca, G.; De Natale, D.; Di Meglio, G.; Ferragamo, A.; Marchitelli, V.; Piccolo, A.; Scala, A.; Somma, R.; et al. The COVID-19 Infection in Italy: A Statistical Study of an Abnormally Severe Disease. J. Clin. Med. 2020, 9, 1564. [Google Scholar] [CrossRef]
- Tsoularis, A.; Wallace, J. Analysis of Logistic Growth Models. Math. Biosci. 2002, 179, 21–55. [Google Scholar] [CrossRef] [Green Version]
- Phipps, S.J.; Grafton, R.Q.; Kompas, T. Robust estimates of the true (population) infection rate for COVID-19: A backcasting approach. R. Soc. Open Sci. 2020, 7, 200909. [Google Scholar] [CrossRef] [PubMed]
- Rees, E.; Nightingale, E.; Jafari, Y.; Waterlow, N.; Clifford, S.; Jombert, T.; Procter, S.; Knight, G. COVID-19 length of hospital stay: A systematic review and data synthesis. BMC Med. 2020, 18, 270. [Google Scholar] [CrossRef]
- Bellan, M.; Patti, G.; Hayden, E.; Azzolina, D.; Pirisi, M.; Acquaviva, A.; Aimaretti, G.; Valletti, P.; Angilletta, R.; Arioli, R.; et al. Fatality rate and predictors of mortality in an Italian cohort of hospitalized COVID-19 patients. Sci. Rep. 2020, 10, 20731. [Google Scholar] [CrossRef]
- Il Sole 24 Ore. History of Covid-19 from the Beginning. Available online: https://lab24.ilsole24ore.com/storia-coronavirus/ (accessed on 24 May 2021).
- Loewenthal, G.; Abadi, S.; Avram, O.; Halabi, K.; Ecker, N.; Nagar, N.; Mayrose, I.; Pupko, T. COVID-19 pandemic-related lockdown: Response time is more important than its strictness. EMBO Mol. Med. 2020, 12, e13171. [Google Scholar] [CrossRef]
- COVID-19 Health Emergency Committee (Italy). Anti-COVID-19 Vaccine Administrations Open Data. Available online: https://github.com/italia/covid19-opendata-vaccini (accessed on 24 May 2021).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corsaro, C.; Sturniolo, A.; Fazio, E. Gaussian Parameters Correlate with the Spread of COVID-19 Pandemic: The Italian Case. Appl. Sci. 2021, 11, 6119. https://doi.org/10.3390/app11136119
Corsaro C, Sturniolo A, Fazio E. Gaussian Parameters Correlate with the Spread of COVID-19 Pandemic: The Italian Case. Applied Sciences. 2021; 11(13):6119. https://doi.org/10.3390/app11136119
Chicago/Turabian StyleCorsaro, Carmelo, Alessandro Sturniolo, and Enza Fazio. 2021. "Gaussian Parameters Correlate with the Spread of COVID-19 Pandemic: The Italian Case" Applied Sciences 11, no. 13: 6119. https://doi.org/10.3390/app11136119
APA StyleCorsaro, C., Sturniolo, A., & Fazio, E. (2021). Gaussian Parameters Correlate with the Spread of COVID-19 Pandemic: The Italian Case. Applied Sciences, 11(13), 6119. https://doi.org/10.3390/app11136119