
Detecting Deception from Gaze and Speech Using a Multimodal Attention LSTM-Based Framework



Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
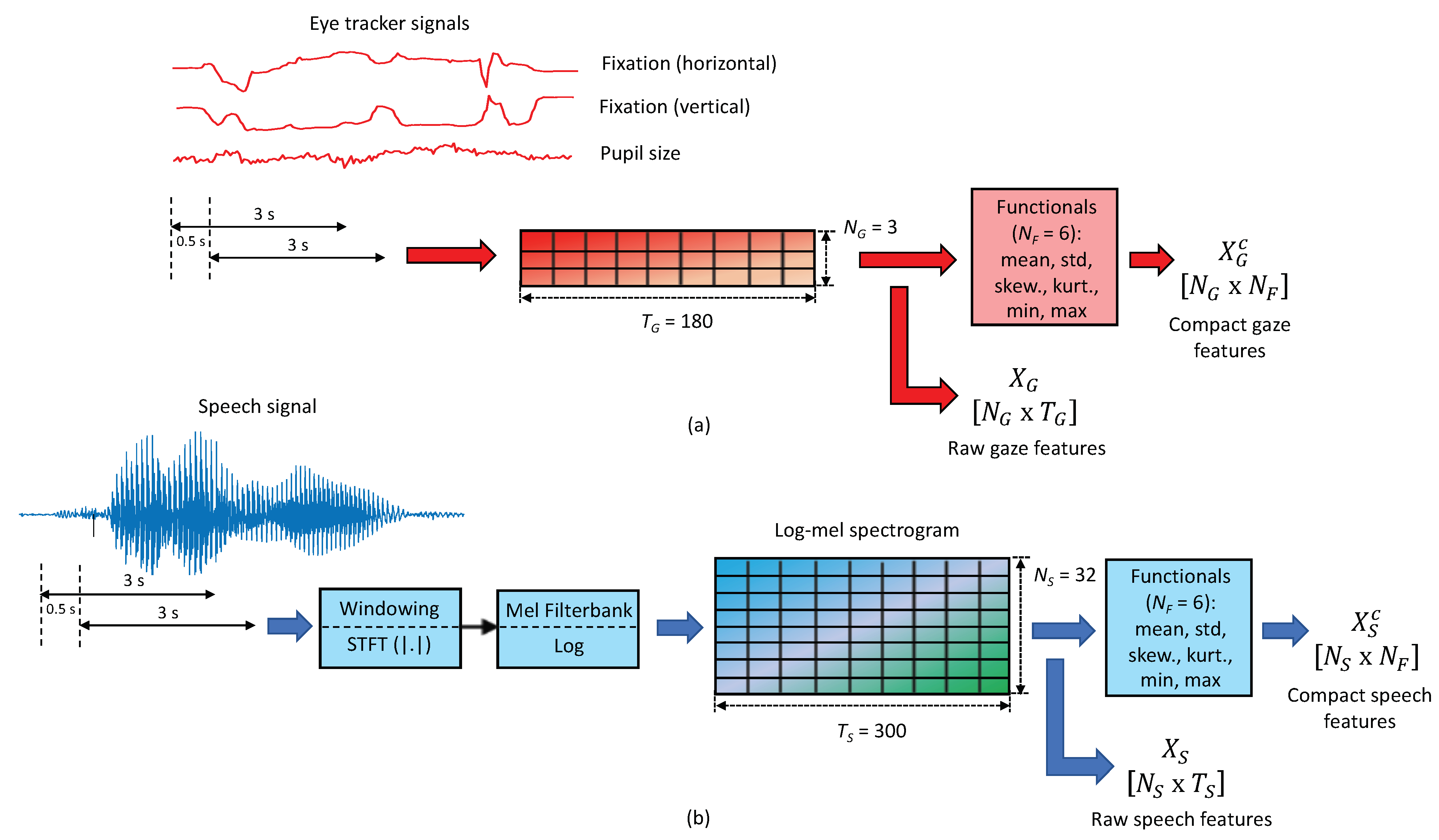
2.2. Feature Extraction
2.2.1. Gaze Features
2.2.2. Speech Features
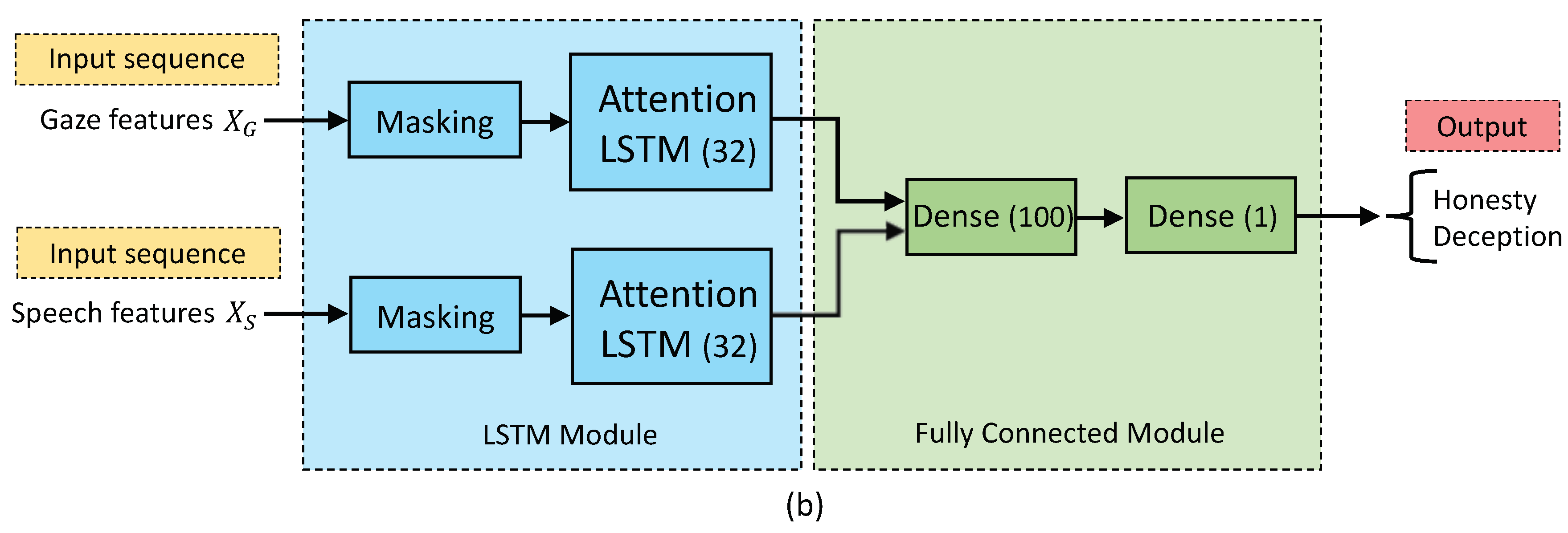
2.3. Deception Detection Systems
2.3.1. Single-Modal SVM-Based Add System
2.3.2. Single-Modal Attention LSTM-Based Add System
2.4. Multimodal Systems
2.5. Experimental Protocol
2.6. Assessment Measures
3. Results
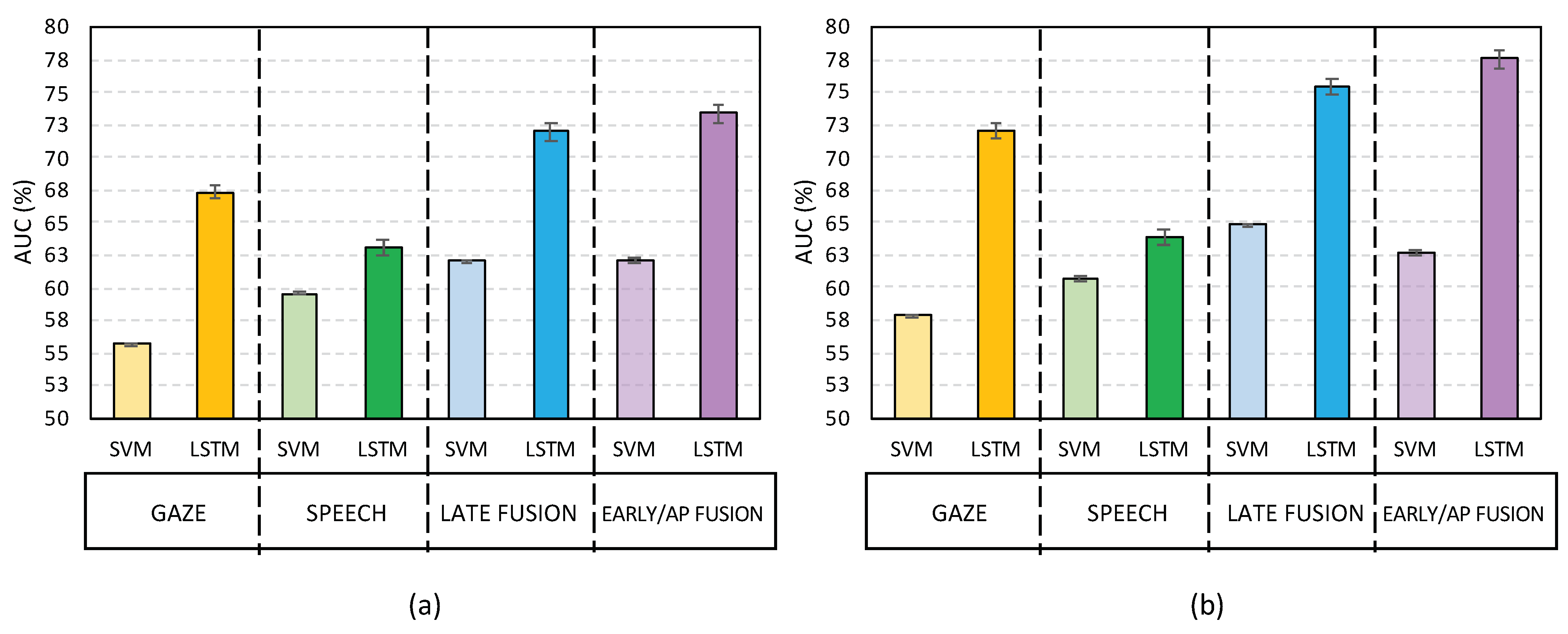
3.1. Results with a Single Modality
3.2. Results with the Multimodal Fusion
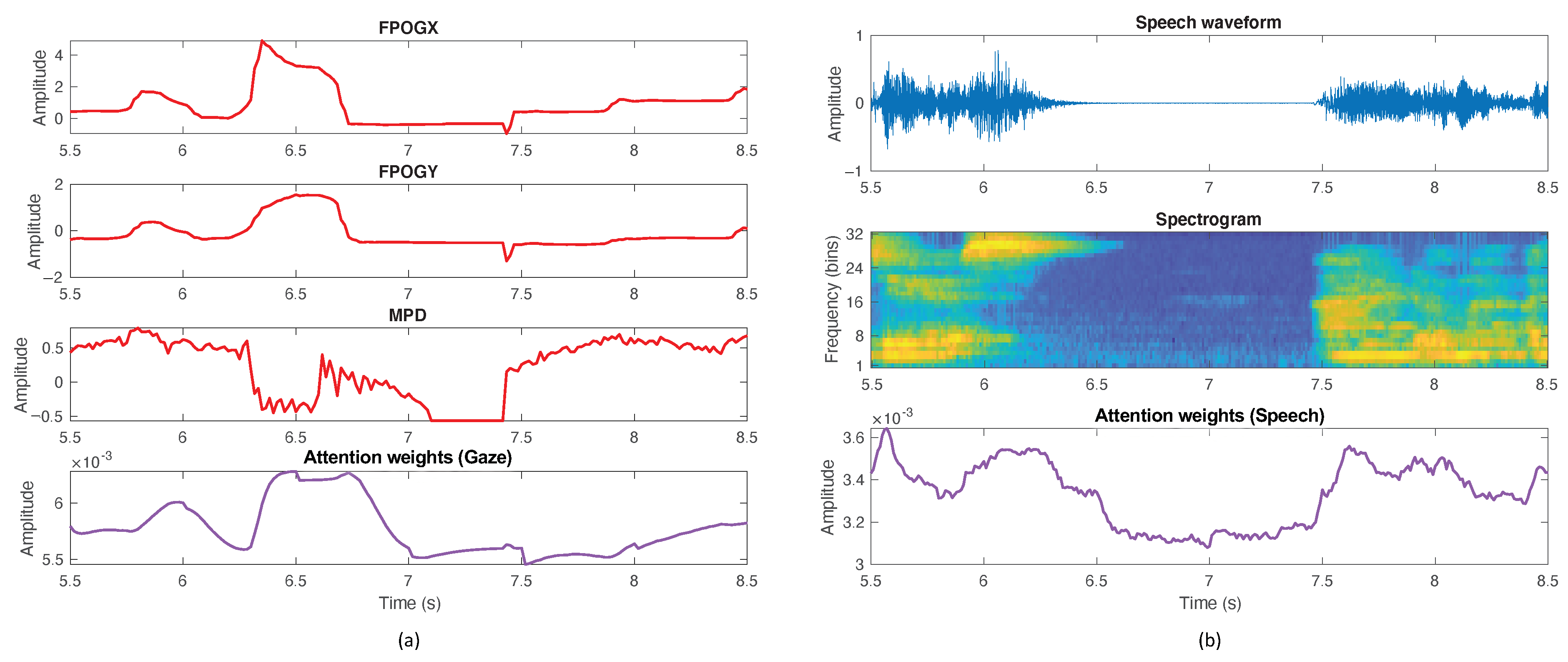
4. Discussion
Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| ADD | Automatic Deception Detection |
| AUC | Area-Under-the-Curve |
| AP | Attention Pooling |
| DACC | Deception Accuracy |
| EEG | Electroencephalogram |
| FPOGX | Horizontal Fixation Point-Of-Gaze |
| FPOGY | Vertical Fixation Point-Of-Gaze |
| HACC | Honesty Accuracy |
| KNN | K-Nearest Neighbors |
| LSTM | Long Short-Term Memory |
| MPD | Mean Pupil Diameter |
| RF | Random Forest |
| STFT | Short-Time Fourier Transform |
| SVM | Support Vector Machine |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segment Level | Turn Level | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Modality | System | DPREC | DREC | HPREC | HREC | DPREC | DREC | HPREC | HREC |
| Gaze | LSTM | 64.18 | 63.45 | 59.38 | 60.11 | 66.44 | 67.78 | 63.44 | 61.86 |
| Speech | LSTM | 71.52 | 53.21 | 59.08 | 75.92 | 71.87 | 44.44 | 56.56 | 80.31 |
| Late Fusion | LSTM | 72.20 | 62.50 | 63.33 | 72.82 | 75.32 | 57.75 | 62.71 | 78.87 |
| AP Fusion | LSTM | 72.15 | 66.58 | 67.42 | 70.99 | 74.01 | 68.06 | 69.46 | 73.32 |
References
- Meservy, T.; Jensen, M.; Kruse, J.; Burgoon, J.; Nunamaker, J.; Twitchell, D.; Tsechpenakis, G.; Metaxas, D. Deception detection through automatic, unobtrusive analysis of nonverbal behavior. IEEE Intell. Syst. 2005, 20, 36–43. [Google Scholar] [CrossRef]
- Tsikerdekis, M.; Zeadally, S. Online Deception in Social Media. Commun. ACM 2014, 57, 72–80. [Google Scholar] [CrossRef]
- Efthymiou, A.E. Modeling Human-Human Dialogues for Deception Detection. Master’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, 2019. [Google Scholar]
- Pérez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; Xiao, Y.; Linton, C.; Burzo, M. Verbal and Nonverbal Clues for Real-life Deception Detection. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 2336–2346. [Google Scholar] [CrossRef]
- Wang, J.T.Y.; Spezio, M.; Camerer, C.F. Pinocchio’s Pupil: Using Eyetracking and Pupil Dilation to Understand Truth Telling and Deception in Sender-Receiver Games. Am. Econ. Rev. 2010, 100, 984–1007. [Google Scholar] [CrossRef] [Green Version]
- Pak, J.; Zhou, L. Eye Movements as Deception Indicators in Online Video Chatting. In Proceedings of the AMCIS 2011 Proceedings, Detroit, MI, USA, 4–8 August 2011. [Google Scholar]
- Fukuda, K. Eye blinks: New indices for the detection of deception. Int. J. Psychophysiol. 2001, 40, 239–245. [Google Scholar] [CrossRef]
- Vrij, A.; Oliveira, J.; Hammond, A.; Ehrlichman, H. Saccadic eye movement rate as a cue to deceit. J. Appl. Res. Mem. Cogn. 2015, 4, 15–19. [Google Scholar] [CrossRef] [Green Version]
- Borza, D.; Itu, R.; Danescu, R. In the Eye of the Deceiver: Analyzing Eye Movements as a Cue to Deception. J. Imaging 2018, 4, 120. [Google Scholar] [CrossRef] [Green Version]
- Pak, J.; Zhou, L. Eye Gazing Behaviors in Online Deception. In Proceedings of the AMCIS 2013 Proceedings, Chicago, IL, USA, 15–17 August 2013. [Google Scholar]
- Belavadi, V.; Zhou, Y.; Bakdash, J.Z.; Kantarcioglu, M.; Krawczyk, D.C.; Nguyen, L.; Rakic, J.; Thuriasingham, B. MultiModal Deception Detection: Accuracy, Applicability and Generalizability*. In Proceedings of the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; pp. 99–106. [Google Scholar] [CrossRef]
- Gupta, V.; Agarwal, M.; Arora, M.; Chakraborty, T.; Singh, R.; Vatsa, M. Bag-of-Lies: A Multimodal Dataset for Deception Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 83–90. [Google Scholar] [CrossRef]
- Khan, W.; Crockett, K.; O’Shea, J.; Hussain, A.; Khan, B.M. Deception in the eyes of deceiver: A computer vision and machine learning based automated deception detection. Expert Syst. Appl. 2021, 169, 114341. [Google Scholar] [CrossRef]
- DePaulo, B.M.; Lindsay, J.J.; Malone, B.E.; Muhlenbruck, L.; Charlton, K.; Cooper, H. Cues to deception. Psychol. Bull. 2003, 129, 74–118. [Google Scholar] [CrossRef]
- Benus, S.; Enos, F.; Hirschberg, J.; Shriberg, E. Pauses in deceptive Speech. In Proceedings of the ISCA 3rd International Conference on Speech Prosody, Dresden, Germany, 2–5 May 2006. [Google Scholar]
- Kirchhübel, C. The Acoustic and Temporal Characteristics of Deceptive Speech. Ph.D. Thesis, Department of Electronics, University of York, York, UK, 2013. [Google Scholar]
- Hirschberg, J.B.; Benus, S.; Brenier, J.M.; Enos, F.; Friedman, S.; Gilman, S.; Girand, C.; Graciarena, M.; Kathol, A.; Michaelis, L.; et al. Distinguishing deceptive from non-deceptive speech. In Proceedings of the Interspeech 2005, Lisbon, Portugal, 4–8 September 2005. [Google Scholar] [CrossRef]
- Mermelstein, P. Distance measures for speech recognition, psychological and instrumental. Pattern Recognit. Artif. Intell. 1976, 116, 374–388. [Google Scholar]
- Wu, Z.; Singh, B.; Davis, L.S.; Subrahmanian, V.S. Deception detection in videos. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Xie, Y.; Liang, R.; Tao, H.; Zhu, Y.; Zhao, L. Convolutional Bidirectional Long Short-Term Memory for Deception Detection With Acoustic Features. IEEE Access 2018, 6, 76527–76534. [Google Scholar] [CrossRef]
- Rill-García, R.; Escalante, H.J.; Villaseñor-Pineda, L.; Reyes-Meza, V. High-Level Features for Multimodal Deception Detection in Videos. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1565–1573. [Google Scholar] [CrossRef] [Green Version]
- Abouelenien, M.; Pérez-Rosas, V.; Mihalcea, R.; Burzo, M. Detecting Deceptive Behavior via Integration of Discriminative Features From Multiple Modalities. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1042–1055. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning Precise Timing with LSTM Recurrent Networks. J. Mach. Learn. Res. 2003, 3, 115–143. [Google Scholar] [CrossRef]
- Zacarias-Morales, N.; Pancardo, P.; Hernández-Nolasco, J.A.; Garcia-Constantino, M. Attention-Inspired Artificial Neural Networks for Speech Processing: A Systematic Review. Symmetry 2021, 13, 214. [Google Scholar] [CrossRef]
- Kao, C.C.; Sun, M.; Wang, W.; Wang, C. A Comparison of Pooling Methods on LSTM Models for Rare Acoustic Event Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Xu, N.; Li, L.J.; Alwan, A. Attention based CLDNNs for short-duration acoustic scene classification. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; Volume 1, pp. 577–585. [Google Scholar]
- Huang, C.W.; Narayanan, S.S. Attention Assisted Discovery of Sub-Utterance Structure in Speech Emotion Recognition. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar] [CrossRef] [Green Version]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar] [CrossRef]
- Gallardo-Antolín, A.; Montero, J.M. A Saliency-Based Attention LSTM Model for Cognitive Load Classification from Speech. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 216–220. [Google Scholar] [CrossRef]
- Gallardo-Antolín, A.; Montero, J.M. External Attention LSTM Models for Cognitive Load Classification from Speech. Lect. Notes Comput. Sci. 2019, 11816, 139–150. [Google Scholar] [CrossRef]
- Fernández-Díaz, M.; Gallardo-Antolín, A. An attention Long Short-Term Memory based system for automatic classification of speech intelligibility. Eng. Appl. Artif. Intell. 2020, 96, 103976. [Google Scholar] [CrossRef]
- Gallardo-Antolín, A.; Montero, J.M. On combining acoustic and modulation spectrograms in an attention LSTM-based system for speech intelligibility level classification. Neurocomputing 2021, 456, 49–60. [Google Scholar] [CrossRef]
- Open Gaze API by Gazepoint. 2010. Available online: https://www.gazept.com/dl/Gazepoint_API_v2.0.pdf (accessed on 5 July 2021).
- Tomar, S. Converting video formats with FFmpeg. Linux J. 2006, 2006, 10. [Google Scholar]
- Vázquez-Romero, A.; Gallardo-Antolín, A. Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks. Entropy 2020, 22, 688. [Google Scholar] [CrossRef]
- Gil-Martín, M.; Montero, J.M.; San-Segundo, R. Parkinson’s Disease Detection from Drawing Movements Using Convolutional Neural Networks. Electronics 2019, 8, 907. [Google Scholar] [CrossRef] [Green Version]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar] [CrossRef]
- McFee, B.; Lostanlen, V.; McVicar, M.; Metsai, A.; Balke, S.; Thomé, C.; Raffel, C.; Malek, A.; Lee, D.; Zalkow, F.; et al. LibROSA/LibROSA: 0.7.2. 2020. Available online: https://librosa.org (accessed on 5 July 2021).
- Vapnik, V.; Chervonenkis, A.Y. A note on one class of perceptrons. Autom. Remote Control 1964, 25, 61–68. [Google Scholar]
- Huang, C.; Narayanan, S. Deep convolutional recurrent neural network with attention mechanism for robust speech emotion recognition. In Proceedings of the ICME 2017, Hong Kong, China, 10–14 July 2017; pp. 583–588. [Google Scholar]
- Abadi, M. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org (accessed on 5 July 2021).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 5 July 2021).







| Segment Level | Turn Level | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Modality | System | DACC | HACC | ACC | AUC | DACC | HACC | ACC | AUC |
| Gaze | SVM | 62.17 | 48.35 | 55.67 | 55.67 | 65.74 | 51.13 | 58.83 | 57.86 |
| LSTM | 63.45 | 60.11 | 61.88 | 67.37 | 67.78 | 61.86 | 64.98 | 72.09 | |
| Speech | SVM | 60.80 | 59.77 | 60.31 | 59.61 | 53.24 | 63.71 | 58.20 | 60.64 |
| LSTM | 53.21 | 75.92 | 63.89 | 63.12 | 44.44 | 80.31 | 61.41 | 63.83 | |
| Segment Level | Turn Level | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Modality | System | DACC | HACC | ACC | AUC | DACC | HACC | ACC | AUC |
| Late Fusion | SVM | 60.59 | 61.86 | 61.19 | 62.04 | 50.93 | 72.37 | 61.07 | 64.84 |
| Late Fusion | LSTM | 62.50 | 72.82 | 67.35 | 72.00 | 57.75 | 78.87 | 67.74 | 75.43 |
| Early Fusion | SVM | 58.97 | 63.23 | 60.97 | 62.12 | 48.98 | 71.03 | 59.41 | 62.75 |
| AP Fusion | LSTM | 66.58 | 70.99 | 68.66 | 73.45 | 68.06 | 73.32 | 70.55 | 77.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallardo-Antolín, A.; Montero, J.M. Detecting Deception from Gaze and Speech Using a Multimodal Attention LSTM-Based Framework. Appl. Sci. 2021, 11, 6393. https://doi.org/10.3390/app11146393
Gallardo-Antolín A, Montero JM. Detecting Deception from Gaze and Speech Using a Multimodal Attention LSTM-Based Framework. Applied Sciences. 2021; 11(14):6393. https://doi.org/10.3390/app11146393
Chicago/Turabian StyleGallardo-Antolín, Ascensión, and Juan M. Montero. 2021. "Detecting Deception from Gaze and Speech Using a Multimodal Attention LSTM-Based Framework" Applied Sciences 11, no. 14: 6393. https://doi.org/10.3390/app11146393
APA StyleGallardo-Antolín, A., & Montero, J. M. (2021). Detecting Deception from Gaze and Speech Using a Multimodal Attention LSTM-Based Framework. Applied Sciences, 11(14), 6393. https://doi.org/10.3390/app11146393