
Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database

Abstract
:1. Introduction
- This paper intruduces an intelligent pathological voice detection system that supports an accurate and objective diagnosis based on deep learning and the parameters introduced.
- The suggested combinations of various parameters and deep learning methods can effectively distinguish normal from pathological voices.
- A lot of experimental tests are performed to confirm the effectiveness of the pathological voice detection system using the Saarbruecken voice database.
- The experimental results emphasize the superiority of the proposed pathological voice detection system integrating machine learning methods and various parameters to monitor and diagnose a pathological voice for an effective and reliable system.
2. Related Work
3. Materials and Methods
3.1. Database
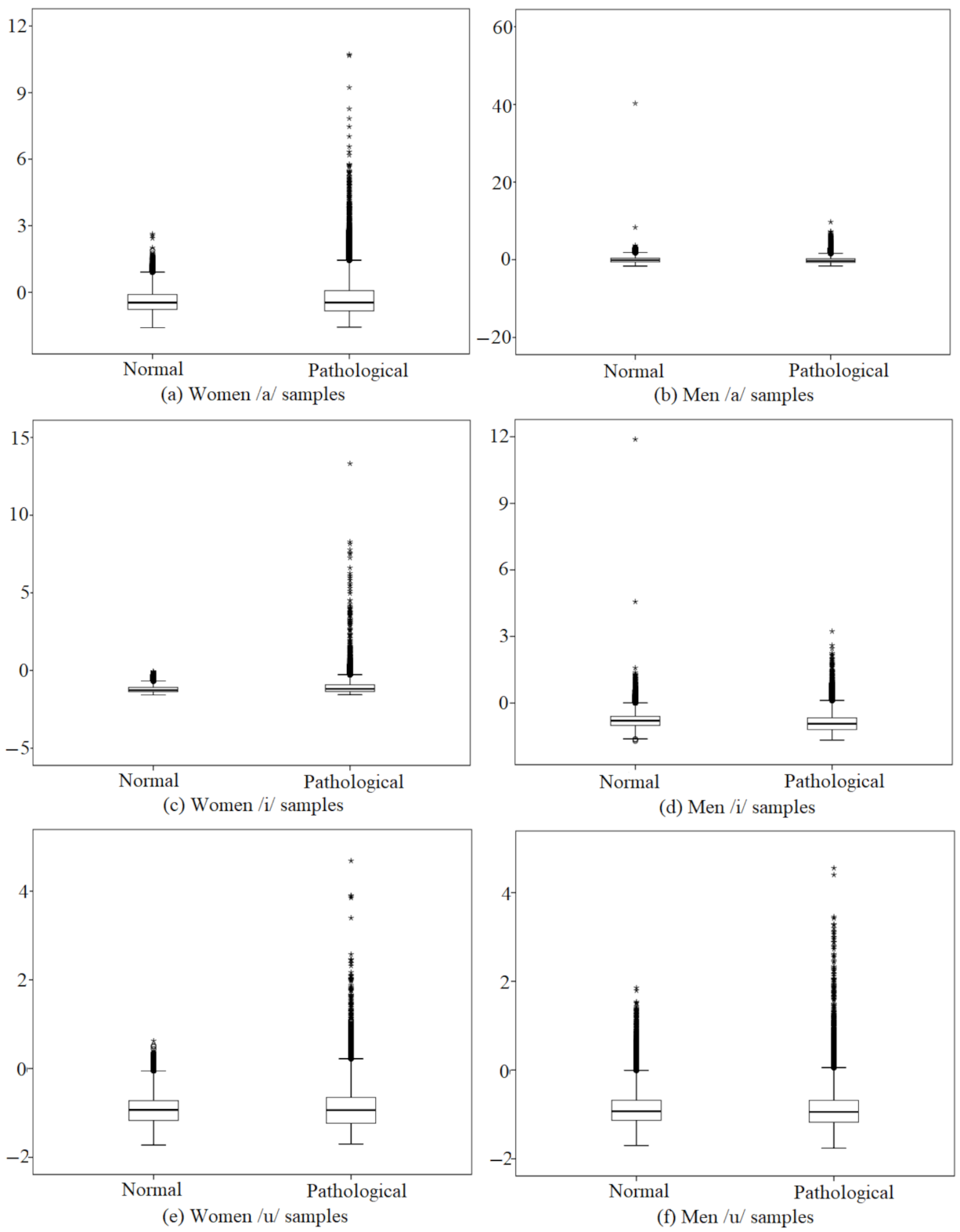
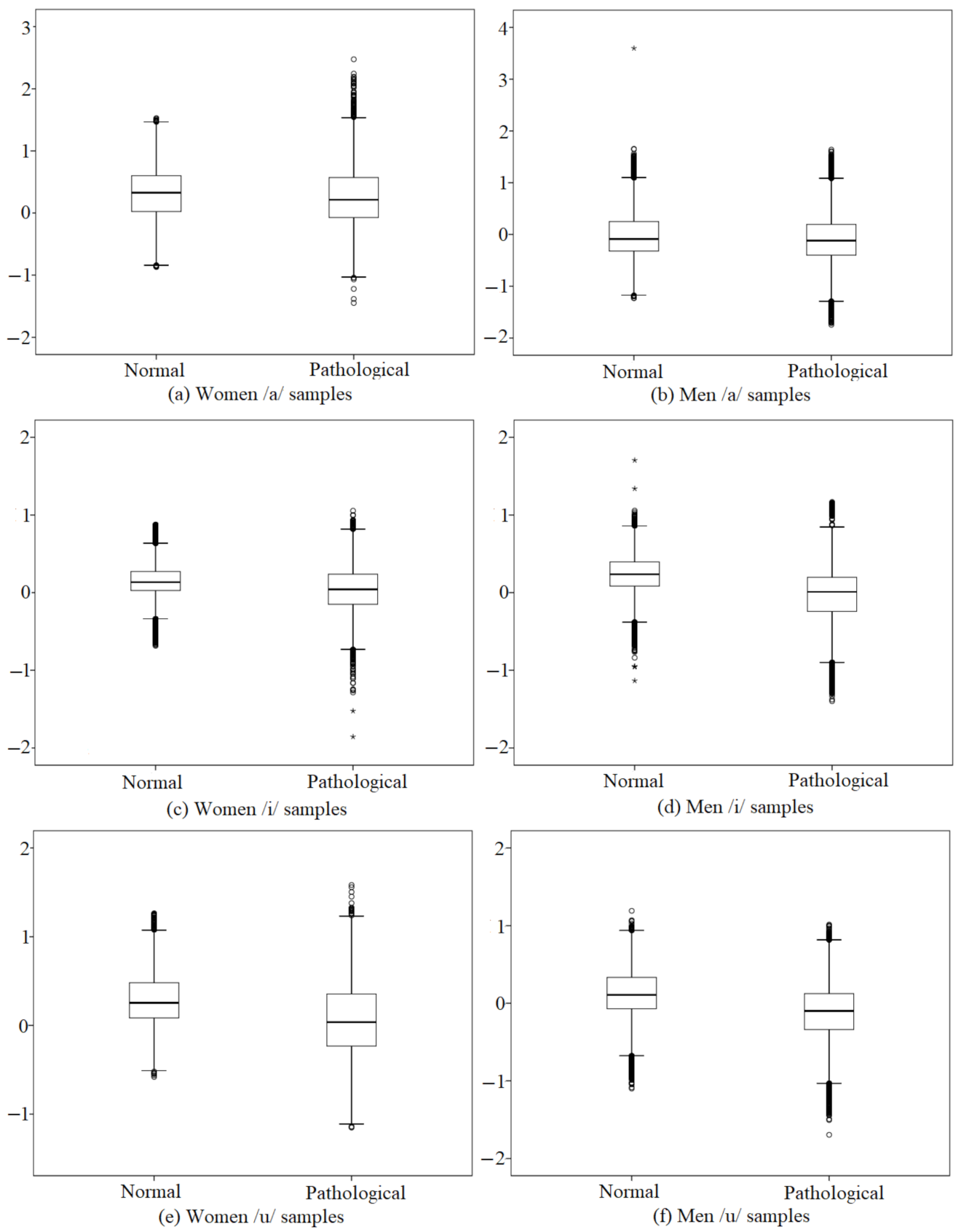
3.2. Feature Extraction
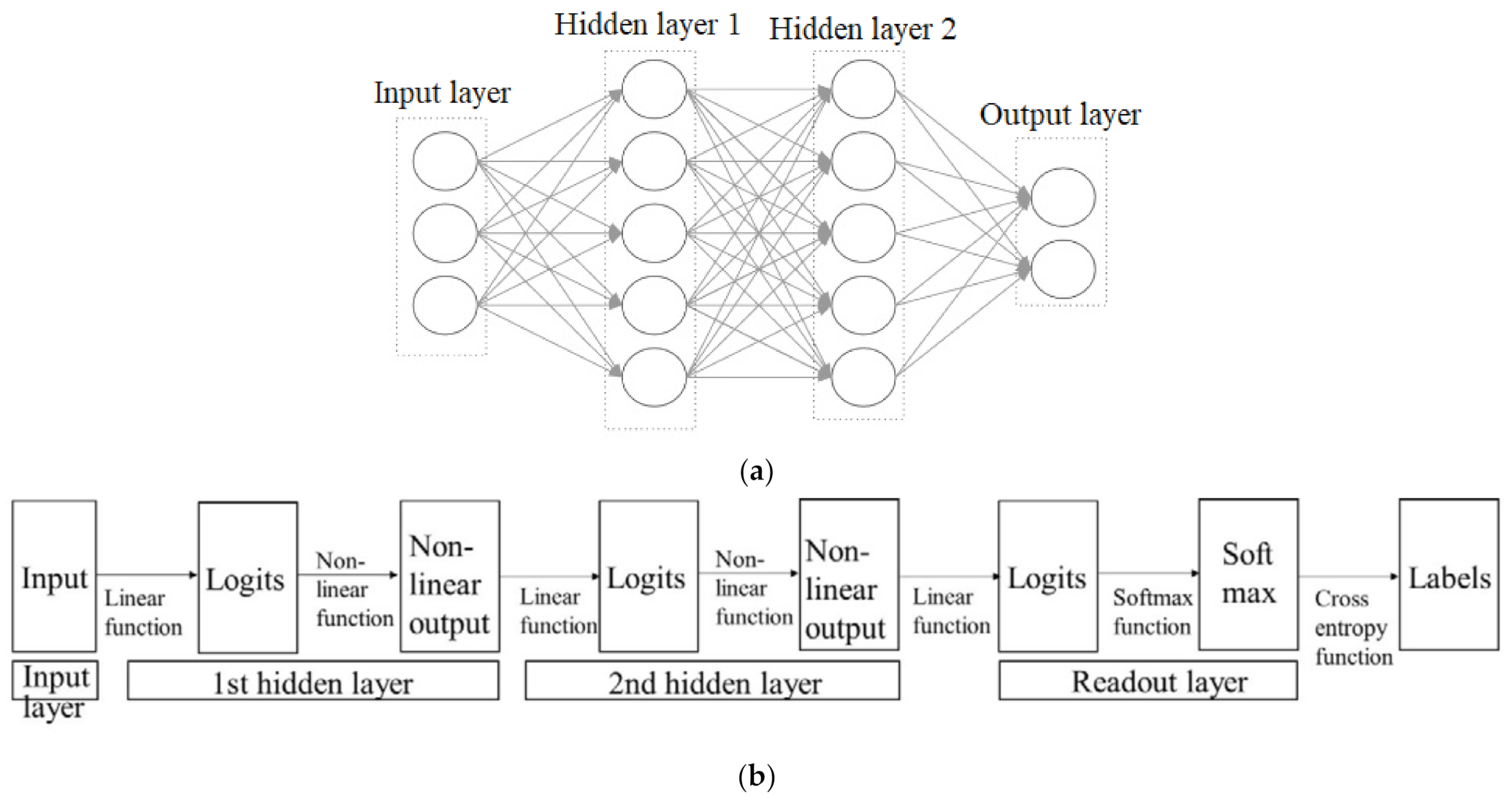
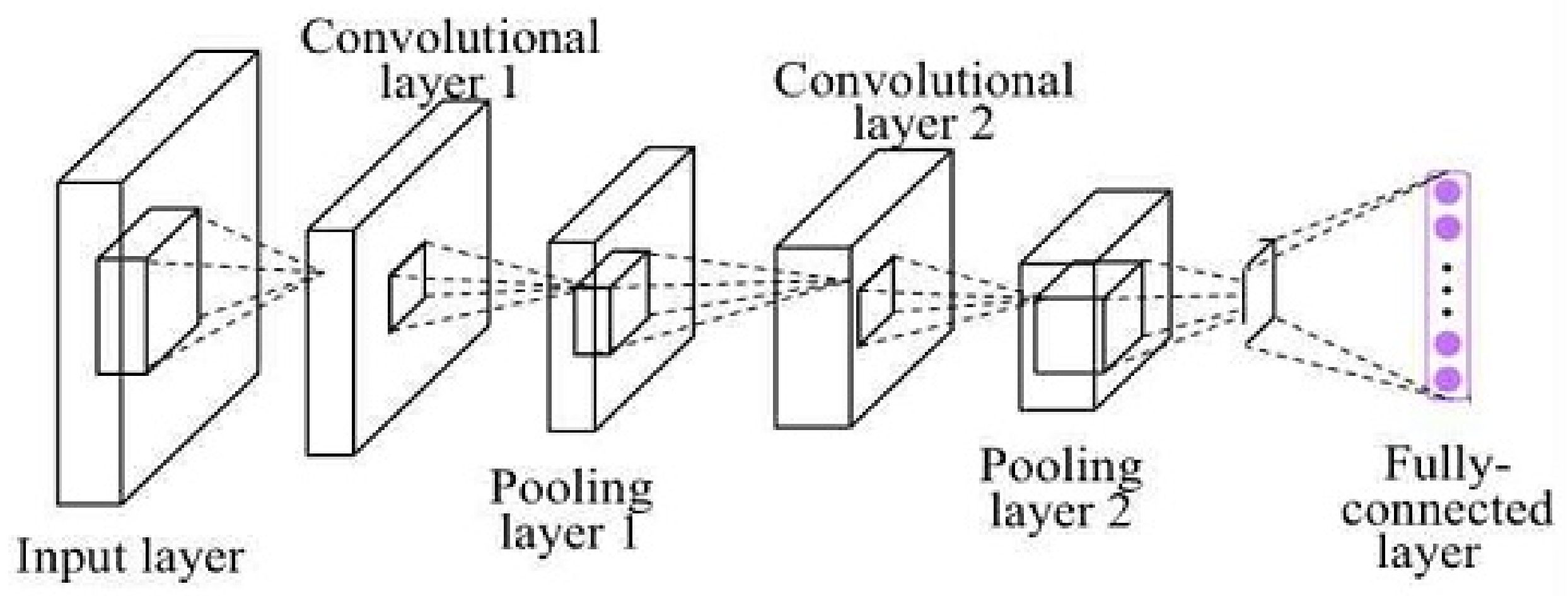
3.3. Deep Learning Methods
4. Experimental Results and Discussion
5. Conclusions
Funding
Conflicts of Interest
References
- Lee, J.-Y.; Jeong, S.; Hahn, M. Pathological Voice Detection Using Efficient Combination of Heterogeneous Features. IEICE Trans. Inf. Syst. 2008, 91, 367–370. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.-Y.; Jeong, S.; Choi, H.-S.; Hahn, M. Objective Pathological Voice Quality Assessment Based on HOS Features. IEICE Trans. Inf. Syst. 2008, 91, 2888–2891. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.Y.; Hahn, M. Automatic Assessment of Pathological Voice Quality Using Higher-Order Statistics in the LPC Residual Domain. EURASIP J. Adv. Signal Process. 2010, 2009, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhang, J.; Yan, Y. Discrimination between Pathological and Normal Voices Using GMM-SVM Approach. J. Voice 2011, 25, 38–43. [Google Scholar] [CrossRef] [PubMed]
- Elsisi, M.; Tran, M.-Q.; Mahmoud, K.; Mansour, D.-E.A.; Lehtonen, M.; Darwish, M.M.F. Towards Secured Online Monitoring for Digitalized GIS against Cyber-Attacks Based on IoT and Machine Learning. IEEE Access 2021, 9, 78415–78427. [Google Scholar] [CrossRef]
- Tran, M.-Q.; Liu, M.-K.; Elsisi, M. Effective multi-sensor data fusion for chatter detection in milling process. ISA Trans. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Elsisi, M.; Mahmoud, K.; Lehtonen, M.; Darwish, M.M.F. Reliable Industry 4.0 Based on Machine Learning and IoT for Analyzing, Monitoring, and Securing Smart Meters. Sensors 2021, 21, 487. [Google Scholar] [CrossRef] [PubMed]
- Naranjo, L.; Perez, C.J.; Martin, J.; Campos-Roca, Y. A two-stage variable selection and classification approach for Parkin-son’s disease detection by using voice recording replications. Comput. Methods Prog. Biomed. 2017, 142, 147–156. [Google Scholar] [CrossRef]
- Lopez-de-Ipina, K.; Satue-Villar, A.; Faundez-Zanuy, M.; Arreola, V.; Ortega, O.; Clave, P.; Sanz-Cartagena, M.; Mekyska, J.; Calvo, P. Advances in a multimodal approach for dysphagia analysis based on automatic voice analysis. In Advances in Neural Networks; Springer International Publishing: Cham, Switzerland, 2016; pp. 201–211. ISBN 978-3-319-33746-3. [Google Scholar]
- Gupta, R.; Chaspari, T.; Kim, J.; Kumar, N.; Bone, D.; Narayanan, S. Pathological speech processing: State-of-the-art, current challenges, and future directions. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6470–6474. [Google Scholar]
- Zheng, K.; Padman, R.; Johnson, M.P.; Diamond, H.S. Understanding technology adoption in clinical care: Clinician adop-tion behavior of a point-of-care reminder system. Int. J. Med. Inform. 2005, 74, 535–543. [Google Scholar] [CrossRef]
- Sim, I.; Gorman, P.; Greenes, R.A.; Haynes, R.B.; Kaplan, B.; Lehmann, H.; Tang, P.C. Clinical Decision Support Systems for the Practice of Evidence-based Medicine. J. Am. Med. Inform. Assoc. 2001, 8, 527–534. [Google Scholar] [CrossRef] [Green Version]
- Dankovičová, Z.; Sovák, D.; Drotár, P.; Vokorokos, L. Machine Learning Approach to Dysphonia Detection. Appl. Sci. 2018, 8, 1927. [Google Scholar] [CrossRef] [Green Version]
- Hemmerling, D.; Skalski, A.; Gajda, J. Voice data mining for laryngeal pathology assessment. Comput. Biol. Med. 2016, 69, 270–276. [Google Scholar] [CrossRef]
- Hammami, I.; Salhi, L.; Labidi, S. Voice Pathologies Classification and Detection Using EMD-DWT Analysis Based on Higher Order Statistic Features. IRBM 2020, 41, 161–171. [Google Scholar] [CrossRef]
- Minelga, J.; Verikas, A.; Vaiciukynas, E.; Gelzinis, A.; Bacauskiene, M. A Transparent Decision Support Tool in Screening for Laryngeal Disorders Using Voice and Query Data. Appl. Sci. 2017, 7, 1096. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Ghani, M.K.A.; Maashi, M.S.; Garcia-Zapirain, B.; Oleagordia, I.; AlHakami, H.; Al-Dhief, F.T. Voice Pathology Detection and Classification Using Convolutional Neural Network Model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Hegde, S.; Shetty, S.; Rai, S.; Dodderi, T. A Survey on Machine Learning Approaches for Automatic Detection of Voice Disorders. J. Voice 2019, 33, 947. [Google Scholar] [CrossRef] [PubMed]
- Eskidere, Ö.; Gürhanli, A. Voice Disorder Classification Based on Multitaper Mel Frequency Cepstral Coefficients Features. Comput. Math. Methods Med. 2015, 2015, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Lei, Z.; Kennedy, E.; Fasanella, L.; Li-Jessen, N.Y.-K.; Mongeau, L. Discrimination between Modal, Breathy and Pressed Voice for Single Vowels Using Neck-Surface Vibration Signals. Appl. Sci. 2019, 9, 1505. [Google Scholar] [CrossRef] [Green Version]
- Olivares, R.; Munoz, R.; Soto, R.; Crawford, B.; Cárdenas, D.; Ponce, A.; Taramasco, C. An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease. Appl. Sci. 2020, 10, 1827. [Google Scholar] [CrossRef] [Green Version]
- Silva, B.N.; Khan, M.; Wijesinghe, R.E.; Thelijjagoda, S.; Han, K. Development of Computer-Aided Semi-Automatic Diagnosis System for Chronic Post-Stroke Aphasia Classification with Temporal and Parietal Lesions: A Pilot Study. Appl. Sci. 2020, 10, 2984. [Google Scholar] [CrossRef]
- Hernandez, A.; Kim, S.; Chung, M. Prosody-Based Measures for Automatic Severity Assessment of Dysarthric Speech. Appl. Sci. 2020, 10, 6999. [Google Scholar] [CrossRef]
- William, J.B.; Manfred, P. Saarbrucken Voice Database: Institute of Phonetics, University of Saarland. 2007. Available online: http://www.stimmdatenbank.coli.uni-saarland.de/ (accessed on 13 May 2018).
- Lee, J.; Choi, H.-J. Deep Learning Approaches for Pathological Voice Detection Using Heterogeneous Parameters. IEICE Trans. Inf. Syst. 2020, 103, 1920–1923. [Google Scholar] [CrossRef]
- Nemer, E.; Goubran, R.; Mahmoud, S. Robust voice activity detection using higher-order statistics in the LPC residual domain. IEEE Trans. Speech Audio Process. 2001, 9, 217–231. [Google Scholar] [CrossRef]
- Moujahid, A. A Practical Introduction to Deep Learning with Caffe and Python. Available online: http://adilmoujahid.com/posts/2016/06/introduction-deep-learning-python-caffe/ (accessed on 28 June 2021).
- Ng, R. Feedforward Neural Network with PyTorch. Available online: https://www.deeplearningwizard.com/deep_learning/practical_pytorch/pytorch_feedforward_neuralnetwork/ (accessed on 25 July 2021).
- Choe, J.; Lee, J.; Kang, D.; Seo, S. AR based Beverage Information Visualization and Sharing System using Deep Learning. J. Digit. Contents Soc. 2020, 21, 445–452. [Google Scholar] [CrossRef]
- Adam, P.; Sam, G.; Soumith, C.; Gregory, C. Automatic differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Tavakoli, S.; Hajibagheri, A.; Sukthankar, G. Learning social graph topologies using generative adversarial neural networks. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling & Prediction, Washington, DC, USA, 5–8 July 2017. [Google Scholar] [CrossRef]
- Pourjabar, S.; Choi, G.S. CVR: A Continuously Variable Rate LDPC Decoder Using Parity Check Extension for Minimum Latency. J. Signal Process. Syst. 2020, 1–8. [Google Scholar] [CrossRef]
- Roshani, M.; Phan, G.T.; Ali, P.J.M.; Roshani, G.H.; Hanus, R.; Duong, T.; Corniani, E.; Nazemi, E.; Kalmoun, E.M. Evaluation of flow pattern recognition and void fraction measurement in two phase flow independent of oil pipeline’s scale layer thickness. Alex. Eng. J. 2021, 60, 1955–1966. [Google Scholar] [CrossRef]
- Fathabadi, F.R.; Grantner, J.L.; Shebrain, S.A.; Abdel-Qader, I. Multi-Class Detection of Laparoscopic Instruments for the Intelligent Box-Trainer System Using Faster R-CNN Architecture. In Proceedings of the 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 21–23 January 2021. [Google Scholar] [CrossRef]
- Voghoei, S.; Tonekaboni, N.H.; Wallace, J.G.; Arabnia, H.R. Deep learning at the edge. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 13–15 December 2018; pp. 895–901. [Google Scholar]
- Nabavi, M.; Nazarpour, V.; Alibak, A.H.; Bagherzadeh, A.; Alizadeh, S.M. Smart tracking of the influence of alumina nanoparticles on the thermal coefficient of nanosuspensions: Application of LS-SVM methodology. Appl. Nanosci. 2021, 11, 1–16. [Google Scholar] [CrossRef]
- Roshani, M.; Sattari, M.A.; Ali, P.J.M.; Roshani, G.H.; Nazemi, B.; Corniani, E.; Nazemi, E. Application of GMDH neural network technique to improve measuring precision of a simplified photon attenuation based two-phase flowmeter. Flow Meas. Instrum. 2020, 75, 101804. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
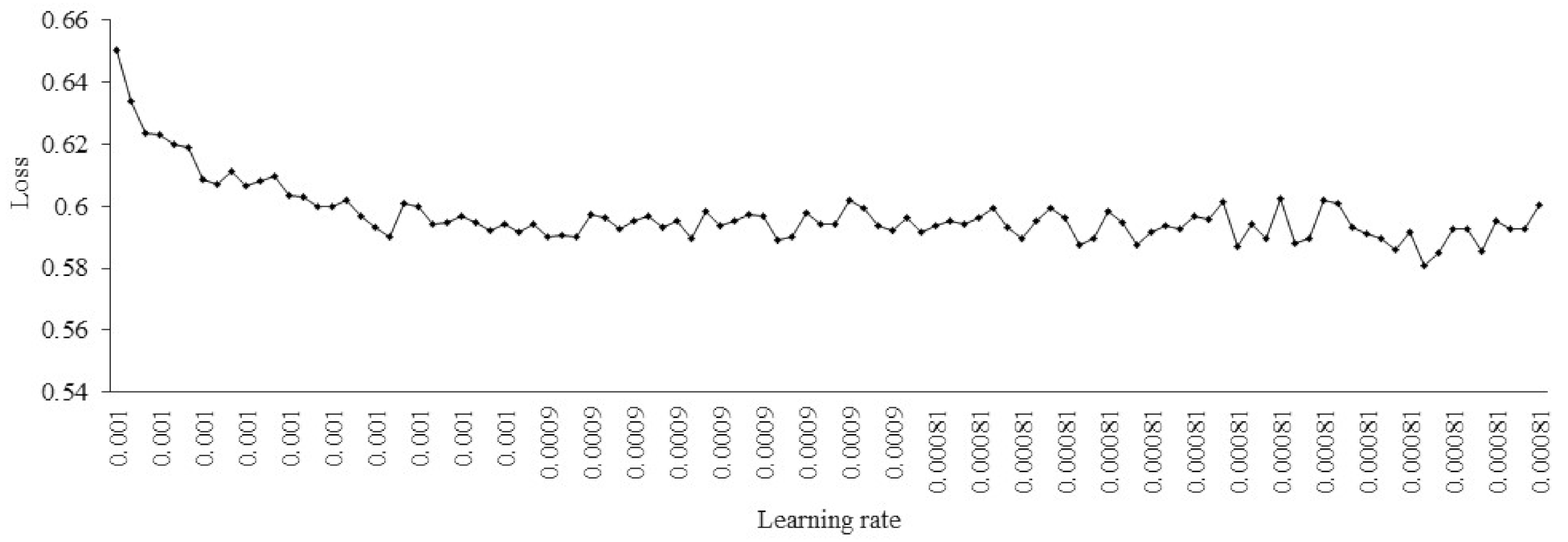{kind=link}
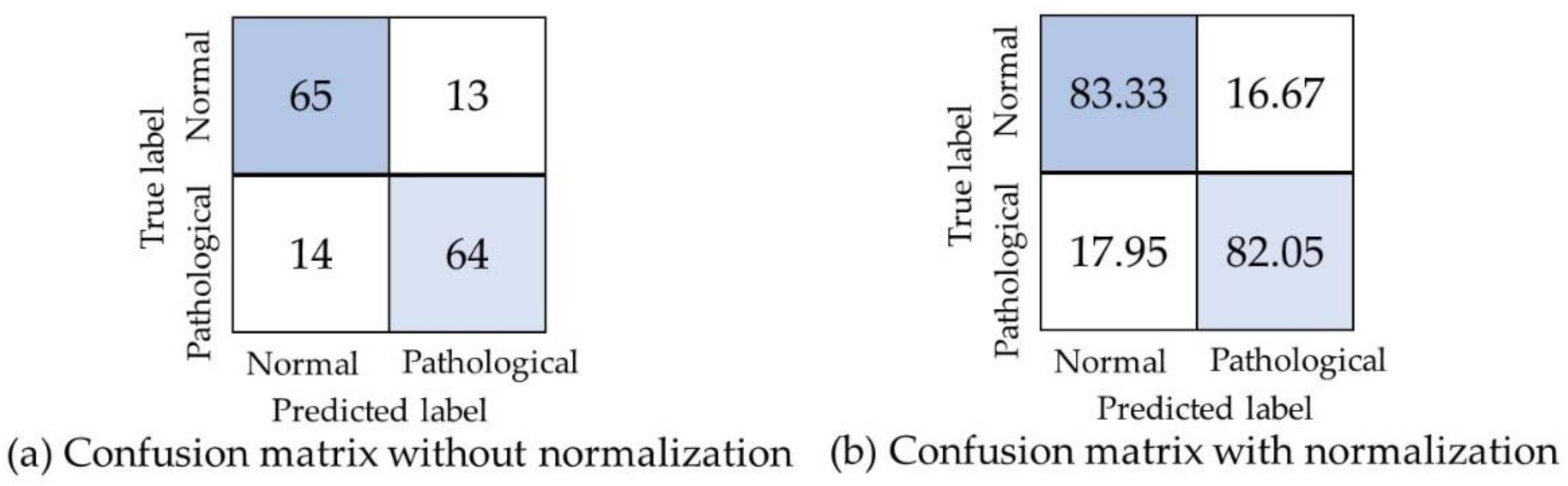{kind=link}
| Diagnosis of Pathological Voices | Number of Samples | |
|---|---|---|
| Female | Male | |
| Hyperfunctional dysphonia | 97 | 44 |
| Functional dysphonia | 51 | 33 |
| Laryngitis | 30 | 62 |
| Vocal fold polyp | 19 | 25 |
| Leukoplakia | 14 | 27 |
| Vocal fold cancer | 1 | 21 |
| Vocal nodule | 13 | 4 |
| Reinke edema | 27 | 7 |
| Hypofunctional dysphonia | 4 | 10 |
| Granuloma | 1 | 1 |
| GERD | 0 | 3 |
| Contact ulcers | 2 | 22 |
| Subtotal | 259 | 259 |
| Healthy voices | 259 | 259 |
| Total | 518 | 518 |
| Parameter | Value |
|---|---|
| Loss function | Tanh |
| Optimization algorithm | SGD + Momentum |
| Regularization | L2 |
| Mismatch propagation | BPTT |
| Minibatch size | 100 samples |
| Learning rate | 0.01 exponential attenuation |
| Loss function | Cross-entropy |
| Weights for samples | Yes |
| Parameter | Value |
|---|---|
| Activation function | ReLU |
| Kernel size | (2,2) |
| Optimizer | Adam |
| Epoch | 100 |
| Loss function | Cross-entropy |
| Dropout | 0.05 |
| Pooling window | Max pooling (2,2) |
| Neurons at dense layer | 512 |
| Women | Men | ||||
|---|---|---|---|---|---|
| Normal | Pathological | Normal | Pathological | ||
| /a/ | |||||
| Normalized kurtosis | Mean | −0.39 | −0.28 | −0.00 | −0.09 |
| Minimum value | −1.59 | −1.57 | −1.62 | −1.59 | |
| Maximum value | 2.63 | 10.72 | 40.27 | 9.70 | |
| Percentile 25 | −0.77 | −0.84 | −0.58 | −0.66 | |
| 50 | −0.47 | −0.46 | −0.10 | −0.28 | |
| 75 | −0.10 | 0.08 | 0.40 | 0.27 | |
| p-value | 0.000 * | 0.000 * | |||
| Normalized skewness | Mean | 0.33 | 0.26 | −0.01 | −0.08 |
| Minimum value | −0.87 | −1.44 | −1.23 | −1.75 | |
| Maximum value | 1.53 | 2.48 | 3.60 | 1.64 | |
| Percentile 25 | 0.02 | −0.07 | −0.32 | −0.40 | |
| 50 | 0.33 | 0.21 | −0.09 | −0.12 | |
| 75 | 0.60 | 0.57 | 0.25 | 0.19 | |
| p value | 0.000 * | 0.000 * | |||
| /i/ | |||||
| Normalized kurtosis | Mean | −1.19 | −1.07 | −0.78 | −0.90 |
| Minimum value | −1.57 | −1.56 | −1.70 | −1.67 | |
| Maximum value | −0.06 | 13.32 | 11.88 | 3.23 | |
| Percentile 25 | −1.36 | −1.35 | −1.01 | −1.20 | |
| 50 | −1.26 | −1.18 | −0.79 | −0.93 | |
| 75 | −1.08 | −0.91 | −0.60 | −0.67 | |
| p-value | 0.000 * | 0.000 * | |||
| Normalized skewness | Mean | 0.15 | 0.04 | 0.23 | −0.03 |
| Minimum value | −0.69 | −1.86 | −1.13 | −1.40 | |
| Maximum value | 0.88 | 1.05 | 1.70 | 1.17 | |
| Percentile 25 | 0.03 | −0.15 | 0.08 | −0.24 | |
| 50 | 0.13 | 0.04 | 0.24 | 0.01 | |
| 75 | 0.27 | 0.23 | 0.40 | 0.20 | |
| p-value | 0.000 * | 0.000 * | |||
| /u/ | |||||
| Normalized kurtosis | Mean | −0.94 | −0.90 | −0.89 | −0.89 |
| Minimum value | −1.72 | −1.70 | −1.70 | −1.76 | |
| Maximum value | 0.62 | 4.68 | 1.85 | 4.55 | |
| Percentile 25 | −1.17 | −1.23 | −1.13 | −1.17 | |
| 50 | −0.93 | −0.94 | −0.93 | −0.95 | |
| 75 | −0.72 | −0.65 | −0.68 | −0.68 | |
| p-value | 0.051 | 0.000 * | |||
| Normalized skewness | Mean | 0.28 | 0.06 | 0.13 | −0.12 |
| Minimum value | −0.58 | −1.15 | −1.10 | −1.69 | |
| Maximum value | 1.27 | 1.58 | 1.19 | 1.01 | |
| Percentile 25 | 0.08 | −0.23 | −0.07 | −0.34 | |
| 50 | 0.25 | 0.04 | 0.11 | −0.10 | |
| 75 | 0.48 | 0.35 | 0.33 | 0.12 | |
| p-value | 0.000 * | 0.000 * | |||
| FNN | |||||||
|---|---|---|---|---|---|---|---|
| Vowel | MFCC | MFCC + HOS | MFCC + delta | MFCC + delta + HOS | LPCC | LPCC + HOS | |
| /a/ | Women and men | 74.04 ± 1.08 | 75.00 ± 1.57 | 72.44 ± 1.26 | 74.04 ± 1.69 | 74.68 ± 0.98 | 76.92 ± 1.36 |
| Women | 73.72 ± 1.63 | 73.72 ± 1.06 | 76.28 ± 2.12 | 74.36 ± 1.42 | 68.59 ± 2.34 | 67.95 ± 3.27 | |
| Men | 72.44 ± 1.38 | 72.44 ± 1.39 | 80.13 ± 2.65 | 74.36 ± 1.93 | 74.36 ± 1.50 | 75.64 ± 1.46 | |
| /i/ | Women and men | 72.76 ± 1.60 | 73.08 ± 1.73 | 71.79 ± 0.91 | 75.64 ± 1.94 | 68.27 ± 1.04 | 73.40 ± 1.07 |
| Women | 79.49 ± 1.79 | 80.77 ± 2.36 | 75.00 ± 3.26 | 76.28 ± 1.93 | 69.23 ± 1.60 | 75.00 ± 1.82 | |
| Men | 71.15 ± 1.89 | 75.00 ± 2.16 | 70.51 ± 1.51 | 74.36 ± 2.03 | 73.08 ± 1.35 | 74.36 ± 0.74 | |
| /u/ | Women and men | 70.19 ± 1.01 | 70.51 ± 1.34 | 68.27 ± 1.44 | 70.19 ± 1.14 | 72.12 ± 1.21 | 73.40 ± 0.83 |
| Women | 72.44 ± 2.32 | 70.19 ± 1.14 | 73.08 ± 2.50 | 75.00 ± 1.49 | 69.87 ± 2.09 | 75.00 ± 1.73 | |
| Men | 73.72 ± 1.81 | 76.92 ± 1.70 | 71.79 ± 1.26 | 73.08 ± 2.01 | 78.21 ± 1.33 | 80.77 ± 1.14 | |
| CNN | |||||||
| /a/ | Women and men | 76.60 ± 1.30 | 76.60 ± 1.82 | 71.15 ± 1.83 | 70.51 ± 1.23 | 73.40 ± 1.02 | 76.28 ± 1.13 |
| Women | 74.36 ± 2.42 | 72.44 ± 1.70 | 72.44 ± 1.89 | 76.28 ± 3.05 | 66.03 ± 1.99 | 68.59 ± 1.60 | |
| Men | 75.64 ± 1.89 | 75.00 ± 1.60 | 74.36 ± 1.05 | 75.00 ± 1.84 | 72.44 ± 1.25 | 73.72 ± 1.22 | |
| /i/ | Women and men | 69.55 ± 1.13 | 72.12 ± 1.90 | 74.68 ± 1.17 | 75.00 ± 1.67 | 69.55 ± 1.09 | 72.12 ± 0.57 |
| Women | 76.92 ± 1.91 | 75.64 ± 2.18 | 69.87 ± 2.26 | 72.44 ± 1.79 | 69.23 ± 1.80 | 73.72 ± 0.95 | |
| Men | 73.08 ± 1.41 | 73.72 ± 2.00 | 71.79 ± 2.09 | 71.15 ± 1.95 | 69.87 ± 0.96 | 76.92 ± 1.36 | |
| /u/ | Women and men | 69.23 ± 0.83 | 70.19 ± 1.12 | 70.19 ± 0.79 | 70.51 ± 1.30 | 69.23 ± 0.90 | 70.83 ± 0.85 |
| Women | 71.15 ± 1.71 | 71.15 ± 0.97 | 75.00 ± 1.68 | 76.92 ± 1.87 | 67.95 ± 1.17 | 73.72 ± 1.8 | |
| Men | 74.36 ± 1.06 | 75.00 ± 1.28 | 77.56 ± 1.56 | 75.64 ± 1.23 | 82.69 ± 1.42 | 75.00 ± 1.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-Y. Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database. Appl. Sci. 2021, 11, 7149. https://doi.org/10.3390/app11157149
Lee J-Y. Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database. Applied Sciences. 2021; 11(15):7149. https://doi.org/10.3390/app11157149
Chicago/Turabian StyleLee, Ji-Yeoun. 2021. "Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database" Applied Sciences 11, no. 15: 7149. https://doi.org/10.3390/app11157149
APA StyleLee, J. -Y. (2021). Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database. Applied Sciences, 11(15), 7149. https://doi.org/10.3390/app11157149