
On IoT-Friendly Skewness Monitoring for Skewness-Aware Online Edge Learning



Abstract
:1. Introduction
- From the statistics community’s perspective, this research enriches skewness monitoring solutions in the running statistics domain. It is worth highlighting that our solutions can conveniently be implemented into efficient algorithms and deployed on IoT devices for practical usage. In fact, compared with the pervasive discussions about mean, median, and variance (or standard deviation), skewness has been considered “a forgotten statistic” [8], not to mention running skewness. In particular, this research reminds the statistics community of the real-world needs of running skewness in the context of IoT and edge learning.
- From the machine learning community’s perspective, this research paves the way for developing skewness-aware online learning techniques, which is particularly valuable and useful in the edge computing domain. It should be noted that although traditional skewness-aware machine learning has been studied [5,19], their generic strategy of curing high skewness (i.e., data pre-processing) cannot be applied to the online mode. In particular, this research reminds the machine learning community of the significance and the available methods of online skewness monitoring. After all, the slightest difference at the model training stage can lead to a huge error in the machine learning results.
- In addition, the shared formula derivation details (in Appendix A) can help both researchers and practitioners investigate other versions of running skewness and develop corresponding algorithms, so as to satisfy the diverse needs in practice. It should be noted that not only has our work developed an efficient cumulative version of running skewness, but we have also investigated the other two versions that can satisfy the forgetting mechanism in the modern edge learning proposals. This contribution essentially follows the spirit of open methods that can act “as a higher-level strategy over open-source tools and open-access data” to facilitate scientific work [20]. In fact, this research has revealed that the obscurity in some advanced statistical methods may hinder their recognition and employment (cf. Section 3.1.2).
- Overall, our work advocates and fosters cross-community research efforts on IoT-friendly online edge learning. Given the booming of edge intelligence [21] accompanied with the resource limits of IoT equipment (e.g., the embedded RAM is only 4KB in the current taxi-mounted GPS devices), multi-domain knowledge and expertise need to fuse together to address the challenges of online edge learning. Through this paper, we particularly expect to attract more attention from the statistics community and to inspire more skewness monitoring algorithms and techniques for the various needs in the diverse edge environments.
2. Related Work
3. Three Versions of Running Skewness and Efficient Calculation Methods
- RunningCumulative Sample Skewness recursively measures the skewness of the time series data filtered from the beginning of measurement up until the current moment. This skewness version is suitable for the situation when the individual data points in a time series are all equally important (e.g., [15]).
- RunningRolling(Simple Moving)Sample Skewness recursively measures the skewness of the time series data within a fixed-size while continuously moving sample window. This skewness version is able to match the learning scenario in which each datum is valid only for a period of time (e.g., [35]).
- RunningExponentially Weighted Sample Skewness also recursively and cumulatively measures the skewness of time series data. Different from the cumulative version, the data are accompanied with weighting factors that decrease exponentially as the data recede into the past. This skewness version would be more practical in the process industry [36] and in the financial sector, as the more recent data can better reflect the current system/market status.
3.1. Cumulative Sample Skewness (CSS)
3.1.1. Calculation of Cumulative Sample Mean (CSM)
3.1.2. Calculation of Cumulative Sample Variance (CSV)
3.1.3. Calculation of Cumulative Sample Skewness (CSS)
3.2. Rolling Sample Skewness (RSS)
3.2.1. Calculation of Rolling Sample Mean (RSM)
3.2.2. Calculation of Rolling Sample Variance (RSV)
3.2.3. Calculation of Rolling Sample Skewness (RSS)
3.3. Exponentially Weighted Sample Skewness (EWSS)
3.3.1. Calculation of Exponentially Weighted Sample Mean (EWSM)
3.3.2. Calculation of Exponentially Weighted Sample Variance (EWSV)
3.3.3. Calculation of Exponentially Weighted Sample Skewness (EWSS)
4. Algorithm Performance Evaluation
4.1. The CSS Calculation Method from GNU Scientific Library
| Algorithm 1 Cumulative Sample Skewness in GSL |
Input: The incoming observation value x. Global Parameters: The current amount of observations n, the sample mean of the current observation values, and the current values of auxiliary variables and . Output: Cumulative sample skewness of the observations.
|
4.2. The CSS Calculation Method from a Go Library
| Algorithm 2 Cumulative Sample Skewness in GoL |
Input: The incoming observation value x. Global Parameters: The current amount of observations n, the sample mean of the current observation values, and the current values of auxiliary variables (i.e., Core.sums [2]) and (i.e., Core.sums [3]). Output: Cumulative sample skewness of the observations.
|
4.3. Performance Comparison among the Three CSS Calculation Methods
4.3.1. Experimental Preparation
| Algorithm 3 Cumulative Sample Skewness in this Research |
Input: The incoming observation value x. Global Parameters: The current amount of observations n, the sample mean of the current observation values, and the current values of auxiliary variables (i.e., ) and (i.e., ). Output: Cumulative sample skewness of the observations. |
- The first workload type is to process data one by one. In this research, the programs screen the sample dataset and return the updated CCS value right after every single new price record is included in the processing.
- The second workload type is to process data chunk by chunk. In this research, the programs return the updated CSS value after every a new price records are included in the processing, while skipping the skewness calculation within the update intervals (i.e., supplementing to the if statement in all the algorithms). Note that the intermediate variables outside the if-else block are still updated continuously when screening the sample dataset.
4.3.2. Experimental Results
4.3.3. Correctness Verification
4.3.4. Performance Analysis
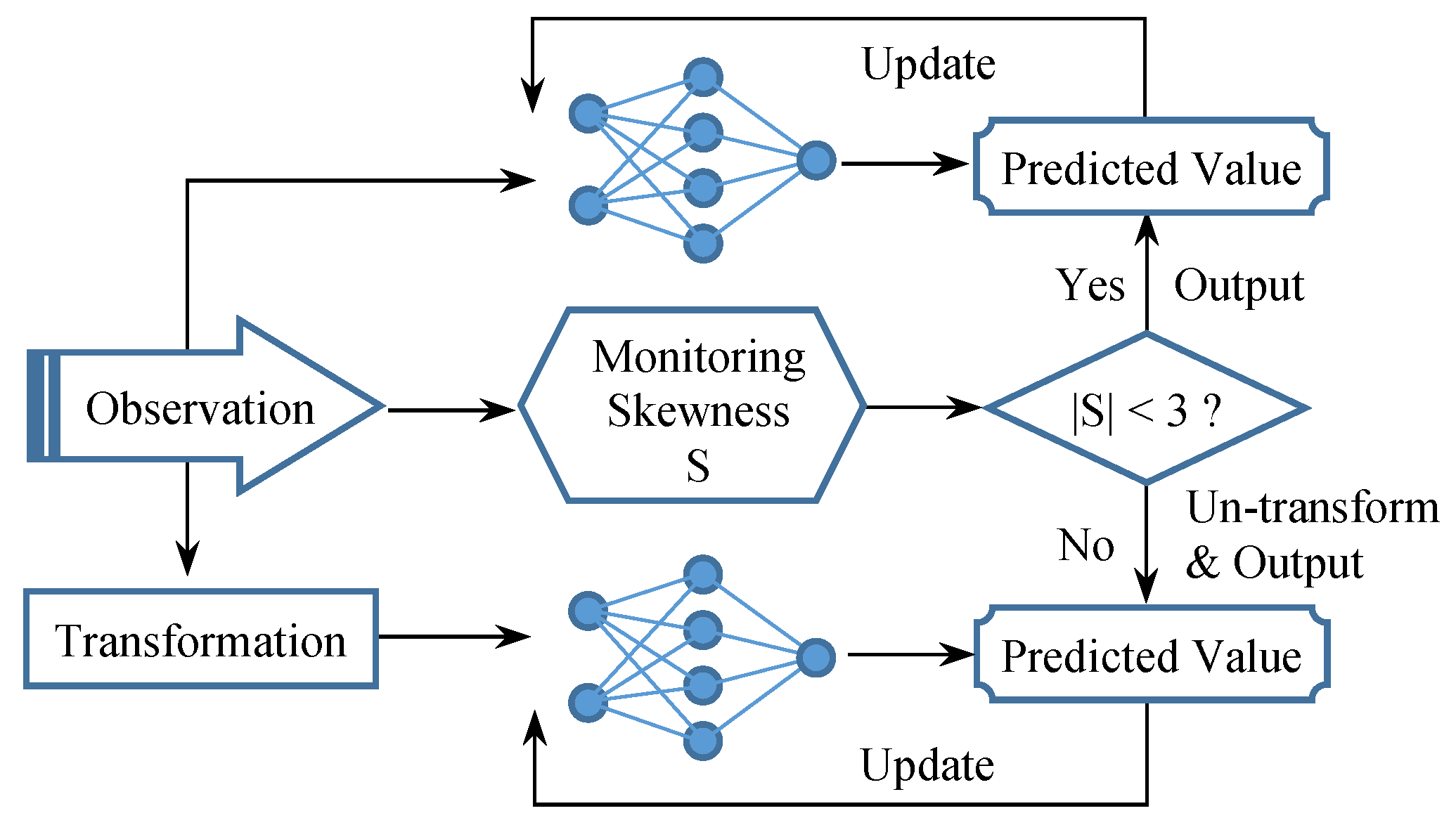
5. Validation and Discussion about Skewness-Aware Online Edge Learning
5.1. Automatic Decision Making in Sample Size for Initial Training
5.2. A Redundancy Mechanism for Skewness-Aware Online Edge Learning
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CSM | Cumulative Sample Mean |
| CSS | Cumulative Sample Skewness |
| CSV | Cumulative Sample Variance |
| EWSM | Exponentially Weighted Sample Mean |
| EWSS | Exponentially Weighted Sample Skewness |
| EWSV | Exponentially Weighted Sample Variance |
| GNU | GNU’s Not Unix |
| GoL | Go-language Library |
| GPS | Global Positioning System |
| GSL | GNU Scientific Library |
| IoT | Internet of Things |
| NRMSE | Normalised root-mean-square error |
| OS_ELM | Online-sequential extreme learning machine |
| RAM | Random-Access Memory |
| RSM | Rolling Sample Mean |
| RSS | Rolling Sample Skewness |
| RSV | Rolling Sample Variance |
Appendix A. Opening the Developed Methods
Appendix A.1. Proof of Equation (2) for Calculating Cumulative Sample Mean (CSM)
Appendix A.2. Proof of Equation System (3) for Calculating Cumulative Sample Variance (CSV)
Appendix A.3. Proof of Equation System (4) for Calculating Cumulative Sample Skewness (CSS)
Appendix A.4. Proof of Equation (5) for Calculating Rolling Sample Mean (RSM)
Appendix A.5. Proof of Equation System (6) for Calculating Rolling Sample Variance (RSV)
Appendix A.6. Proof of Equation System (7) for Calculating Rolling Sample Skewness (RSS)
Appendix A.7. Proof of Equation (8) for Calculating Exponentially Weighted Sample Mean (EWSM)
Appendix A.8. Proof of Equation (9) for Calculating Exponentially Weighted Sample Variance (EWSV)
Appendix A.9. Proof of Equation System (10) for Calculating Exponentially Weighted Sample Skewness (EWSS)
References
- Chen, D.; Liu, Y.C.; Kim, B.; Xie, J.; Hong, C.S.; Han, Z. Edge Computing Resources Reservation in Vehicular Networks: A Meta-Learning Approach. IEEE Trans. Veh. Technol. 2020, 69, 5634–5646. [Google Scholar] [CrossRef]
- Gómez-Carmona, O.; Casado-Mansilla, D.; Kraemer, F.A.; de Ipiña, D.L.; García-Zubia, J. Exploring the computational cost of machine learning at the edge for human-centric Internet of Things. Future Gener. Comput. Syst. 2020, 112, 670–683. [Google Scholar] [CrossRef]
- Li, X.; Han, Q.; Qiu, B. A clustering algorithm using skewness-based boundary detection. Neurocomputing 2018, 275, 618–626. [Google Scholar] [CrossRef]
- Radečić, D. Top 3 Methods for Handling Skewed Data. 2020. Available online: https://towardsdatascience.com/top-3-methods-for-handling-skewed-data-1334e0debf45 (accessed on 17 January 2021).
- Zhang, L.; Tang, K.; Yao, X. Log-normality and skewness of estimated state/action values in reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017); ACM Press: Long Beach, CA, USA, 2017; pp. 1802–1812. [Google Scholar]
- Vasudev, R. How to Deal with Skewed Dataset in Machine Learning? 2017. Available online: https://becominghuman.ai/how-to-deal-with-skewed-dataset-in-machine-learning-afd2928011cc (accessed on 17 January 2021).
- Sun, Y.; Todorovic, S.; Li, J. Reducing the Overfitting of AdaBoost by Controlling its Data Distribution Skewness. Int. J. Pattern Recognit. Artif. Intell. 2006, 20, 1093–1116. [Google Scholar] [CrossRef] [Green Version]
- Doane, D.P.; Seward, L.E. Measuring Skewness: A Forgotten Statistic? J. Stat. Educ. 2011, 19, 1–18. [Google Scholar] [CrossRef]
- Macroption. Skewness Formula. 2021. Available online: https://www.macroption.com/skewness-formula/ (accessed on 17 January 2021).
- Lombardi, M.; Pascale, F.; Santaniello, D. Internet of Things: A General Overview between Architectures, Protocols and Applications. Information 2021, 12, 87. [Google Scholar] [CrossRef]
- Merenda, M.; Porcaro, C.; Iero, D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef]
- Tuor, T.; Wang, S.; Salonidis, T.; Ko, B.J.; Leung, K.K. Demo Abstract: Distributed Machine Learning at Resource-Limited Edge Nodes. In Proceedings of the 2018 IEEE Conference on Computer Communications Poster and Demo (INFOCOM’18 Poster/Demo), Honolulu, HI, USA, 15–19 April 2018; pp. 1–2. [Google Scholar]
- GNU. Running Statistics. 2019. Available online: https://www.gnu.org/software/gsl/doc/html/rstat.html (accessed on 12 January 2021).
- Park, J.M.; Kim, J.H. Online recurrent extreme learning machine and its application to time-series prediction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN 2017), Anchorage, AK, USA, 14–19 May 2017; pp. 1983–1990. [Google Scholar]
- Liang, N.Y.; Huang, G.B.; Saratchandran, P.; Sundararajan, N. A Fast and Accurate Online Sequential Learning Algorithm for Feedforward Networks. IEEE Trans. Neural Netw. 2006, 17, 1411–1423. [Google Scholar] [CrossRef]
- MathWorks. Moving Skewness and Moving Kurtosis. 2018. Available online: https://www.mathworks.com/matlabcentral/answers/426189-moving-skewness-and-moving-kurtosis (accessed on 12 January 2021).
- StackExchange. Exponential Weighted Moving Skewness/Kurtosis. 2011. Available online: https://stats.stackexchange.com/questions/6874/exponential-weighted-moving-skewness-kurtosis (accessed on 12 January 2021).
- StackOverflow. Is There Any Built in Function in Numpy to Take Moving Skewness? 2019. Available online: https://stackoverflow.com/questions/57097809/is-there-any-built-in-function-in-numpy-to-take-moving-skewness (accessed on 19 January 2021).
- Choi, J.H.; Kim, J.; Won, J.; Min, O. Modelling Chlorophyll-a Concentration using Deep Neural Networks considering Extreme Data Imbalance and Skewness. In Proceedings of the 21st International Conference on Advanced Communication Technology (ICACT 2019), PyeongChang, Korea, 17–20 February 2019; pp. 631–634. [Google Scholar]
- Li, Z.; Li, X.; Li, B. In Method We Trust: Towards an Open Method Kit for Characterizing Spot Cloud Service Pricing. In Proceedings of the 12th IEEE International Conference on Cloud Computing (CLOUD 2019), Milan, Italy, 8–13 July 2019; pp. 470–474. [Google Scholar]
- Jin, H.; Jia, L.; Zhou, Z. Boosting Edge Intelligence With Collaborative Cross-Edge Analytics. IEEE Internet Things J. 2021, 8, 2444–2458. [Google Scholar] [CrossRef]
- Abelson, H.; Ledeen, K.; Lewis, H.; Seltzer, W. Blown to Bits: Your Life, Liberty, and Happiness after the Digital Explosion, 2nd ed.; Addison-Wesley Professional: Boston, MA, USA, 2020. [Google Scholar]
- Zhu, G.; Liu, D.; Du, Y.; You, C.; Zhang, J.; Huang, K. Toward an Intelligent Edge: Wireless Communication Meets Machine Learning. IEEE Commun. Mag. 2020, 58, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When Edge Meets Learning: Adaptive Control for Resource-Constrained Distributed Machine Learning. In Proceedings of the 37th IEEE Conference on Computer Communications (INFOCOM 2018), Honolulu, HI, USA, 16–19 April 2018; pp. 63–71. [Google Scholar]
- Yazici, M.T.; Basurra, S.; Gaber, M.M. Edge Machine Learning: Enabling Smart Internet of Things Applications. Big Data Cogn. Comput. 2018, 2, 26. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Liu, M.; Dong, M. A new online learning algorithm for structure-adjustable extreme learning machine. Comput. Math. Appl. 2010, 60, 377–389. [Google Scholar] [CrossRef] [Green Version]
- Aral, A.; Erol-Kantarci, M.; Brandić, I. Staleness Control for Edge Data Analytics. Proc. ACM Meas. Anal. Comput. Syst. 2020, 4, 38. [Google Scholar] [CrossRef]
- Huang, Z.; Lin, K.J.; Tsai, B.L.; Yan, S.; Shih, C.S. Building edge intelligence for online activity recognition in service-oriented IoT systems. Future Gener. Comput. Syst. 2018, 87, 557–567. [Google Scholar] [CrossRef]
- Kadirkamanathan, V.; Niranjan, M. A Function Estimation Approach to Sequential Learning with Neural Networks. Neural Comput. 1993, 5, 954–975. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Gan, X.; Jin, H.; Fu, L.; Wang, X. Learning-Aided Computation Offloading for Trusted Collaborative Mobile Edge Computing. IEEE Trans. Mob. Comput. 2020, 19, 2833–2849. [Google Scholar] [CrossRef]
- Qi, K.; Yang, C. Popularity Prediction with Federated Learning for Proactive Caching at Wireless Edge. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC 2020), Seoul, Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Scardapane, S.; Comminiello, D.; Scarpiniti, M.; Uncini, A. Online Sequential Extreme Learning Machine With Kernels. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2214–2220. [Google Scholar] [CrossRef]
- Shahadat, N.; Pal, B. An empirical analysis of attribute skewness over class imbalance on Probabilistic Neural Network and Naïve Bayes classifier. In Proceedings of the 1st International Conference on Computer and Information Engineering (ICCIE 2015), Rajshahi, Bangladesh, 26–27 November 2015; pp. 150–153. [Google Scholar]
- Pham, M.T.; Cham, T.J. Online Learning Asymmetric Boosted Classifiers for Object Detection. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2007), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Zhao, J.; Wang, Z.; Park, D.S. Online sequential extreme learning machine with forgetting mechanism. Neurocomputing 2012, 87, 79–89. [Google Scholar] [CrossRef]
- Tham, M.T. Exponentially Weighted Moving Average Filter. 2009. Available online: https://web.archive.org/web/20091212013537/http://lorien.ncl.ac.uk/ming/filter/filewma.htm (accessed on 17 January 2021).
- Serel, D.A.; Moskowitz, H. Joint economic design of EWMA control charts for mean and variance. Eur. J. Oper. Res. 2008, 184, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Knuth, D.E. Art of Computer Programming, Volume 2: Seminumerical Algorithms, 3rd ed.; Addison-Wesley Professional: Boston, MA, USA, 1997. [Google Scholar]
- Cook, J.D. Accurately Computing Running Variance. Available online: https://www.johndcook.com/blog/standard_deviation/ (accessed on 17 January 2021).
- StackExchange. Recursive Formula for Variance. 2013. Available online: https://math.stackexchange.com/questions/374881/recursive-formula-for-variance (accessed on 12 January 2021).
- Teknomo, K. Proof Recursive Variance Formula. 2006. Available online: https://people.revoledu.com/kardi/tutorial/RecursiveStatistic/ProofTime-Variance.htm (accessed on 12 January 2021).
- Weisstein, E.W. Sample Variance Computation. From MathWorld—A Wolfram Web Resource. Available online: https://mathworld.wolfram.com/SampleVarianceComputation.html (accessed on 12 January 2021).
- StackOverflow. Rolling Variance Algorithm. 2018. Available online: https://stackoverflow.com/questions/5147378/rolling-variance-algorithm (accessed on 19 January 2021).
- Taylor, M. Running Variance. 2010. Available online: http://www.taylortree.com/2010/11/running-variance.html (accessed on 19 January 2021).
- Pébay, P.; Terriberry, T.B.; Kolla, H.; Bennett, J. Numerically stable, scalable formulas for parallel and online computation of higher-order multivariate central moments with arbitrary weights. Comput. Stat. 2016, 31, 1305–1325. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; O’Brien, L.; Kihl, M. DoKnowMe: Towards a Domain Knowledge-driven Methodology for Performance Evaluation. ACM SIGMETRICS Perform. Eval. Rev. 2016, 43, 23–32. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, D.C. Design and Analysis of Experiments, 9th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019. [Google Scholar]
- Jenkins, D.G.; Quintana-Ascencio, P.F. A solution to minimum sample size for regressions. PLoS ONE 2020, 15, e0229345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pagels, M. What Is Online Machine Learning? 2018. Available online: https://medium.com/value-stream-design/online-machine-learning-515556ff72c5 (accessed on 27 February 2021).
- Strom, D.; van der Zwet, J.F. Truth and Lies about Latency in the Cloud. White Paper, Interxion. 2021. Available online: https://www.interxion.com/whitepapers/truth-and-lies-of-latency-in-the-cloud/download (accessed on 19 July 2021).
- Chen, K.C.; Jang, S.J. Motivation in online learning: Testing a model of self-determination theory. Comput. Hum. Behav. 2010, 26, 741–752. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| n | Amount of observations (samples) within a time series. |
| The most recent k items from a time series of n samples, and . | |
| Sample standard deviation of n observation values . | |
| Sample variance of n observation values . | |
| Sample variance of the most recent k out of n observation values . | |
| Exponentially weighted sample variance of a time series of n observation values. | |
| Sample skewness of n observation values . | |
| Sample skewness of the most recent k out of n observation values . | |
| Exponentially weighted sample skewness of a time series of n observation values. | |
| The ith observation value within a time series, and . | |
| Value of the oldest observation within the most recent k out of n observation values. | |
| Sample mean of a time series of n observation values . | |
| Sample mean of the most recent k out of n observation values . | |
| Sample mean of a time series of n observation values with exponentially decreasing weights. | |
| , | constant coefficients between 0 and 1 for discounting the contribution of older data. |
| Auxiliary variable that carries the crucial information of the third Central Moment. | |
| Auxiliary variable that is associated with, and is to update, . | |
| Auxiliary variable that carries the crucial information of the second Central Moment. | |
| Auxiliary variable that is associated with, and is to update, . | |
| , | Auxiliary variables (similar to and ) that are used in the Go Library. |
| , | Auxiliary variables (similar to and ) that are used in GNU Scientific Library. |
| Sample Size | GSL Method | GoL Method | This Research | Excel Skew( ) |
|---|---|---|---|---|
| 3 | −0.378753 | −1.704387 | −1.704387 | −1.704387 |
| 4 | −0.749576 | −1.998869 | −1.998869 | −1.998869 |
| 5 | −0.292042 | −0.608421 | −0.608421 | −0.608421 |
| 10 | −0.944882 | −1.312336 | −1.312336 | −1.312336 |
| 100 | 4.593622 | 4.734717 | 4.734717 | 4.734717 |
| 1000 | 6.075131 | 6.093399 | 6.093399 | 6.093399 |
| 10,000 | 5.882105 | 5.883870 | 5.883870 | 5.883870 |
| 100,000 | 44.200905 | 44.202232 | 44.202232 | 44.202232 |
| 1,000,000 | 43.528738 | 43.528869 | 43.528869 | 43.528869 |
| Number of Hidden Neurons | Original OS_ELM | Skewness-Aware OS_ELM |
|---|---|---|
| 23 | NRMSE: 70.06% | NRMSE: 53.88% |
| 50 | NRMSE: 50.85% | NRMSE: 48.14% |
| 100 | NRMSE: 41.41% | NRMSE: 38.77% |
| 200 | NRMSE: 36.33% | NRMSE: 33.11% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Galdames-Retamal, J. On IoT-Friendly Skewness Monitoring for Skewness-Aware Online Edge Learning. Appl. Sci. 2021, 11, 7461. https://doi.org/10.3390/app11167461
Li Z, Galdames-Retamal J. On IoT-Friendly Skewness Monitoring for Skewness-Aware Online Edge Learning. Applied Sciences. 2021; 11(16):7461. https://doi.org/10.3390/app11167461
Chicago/Turabian StyleLi, Zheng, and Jhon Galdames-Retamal. 2021. "On IoT-Friendly Skewness Monitoring for Skewness-Aware Online Edge Learning" Applied Sciences 11, no. 16: 7461. https://doi.org/10.3390/app11167461
APA StyleLi, Z., & Galdames-Retamal, J. (2021). On IoT-Friendly Skewness Monitoring for Skewness-Aware Online Edge Learning. Applied Sciences, 11(16), 7461. https://doi.org/10.3390/app11167461