
Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic


Abstract
:1. Introduction
2. Review of Existing Datasets
2.1. KDD99
2.2. MAWILab
2.3. CAIDA (Center of Applied Internet Data Analysis)
2.4. SimpleWeb
2.5. NSL-KDD
2.6. IMPACT
2.7. UMass
2.8. Kyoto
2.9. IRSC
2.10. UNSW-NB15
2.11. UGR’16
2.12. CICIDS-2017
3. Dataset Requirements
3.1. Requirements for IDS Evaluation Datasets
- (1)
- Most of the datasets are not anonymized, such as KDD99, SimpleWeb, NSL-KDD, Kyoto, IRSC, and UNSW-NB15. We chose to preserve privacy by anonymizing only a specific part of the background traffic based on the Crypto-Pan algorithm.
- (2)
- The majority of the datasets are impractical to generate, such as KDD99, CAIDA, NSL-KDD, IMPACT, UMass, IRSC, UNSW-NB15, and CICIDS-2017.
- (3)
- They do not have ground-truth data, such as MAWILab, CAIDA, SimpleWeb, IMPACT, UMass, Kyoto, and CICIDS-2017.
- (4)
- As for encryption information, most of the datasets contain non-encrypted traffic, except for MAWILab, UGR’16, and CICIDS-2017. These datasets neither focused on nor classified encrypted traffic. However, HIKARI-2021 is focused on encrypted traffic.
3.1.1. Content Requirements
- (1)
- Complete capture: complete capture of the network traffic, such as communication between host, broadcast message, domain lookup query, the protocol being used. The most important thing from complete capture is that both flow data and pcap should be available.
- (2)
- Payload: payload is not needed for a flow-based approach. However, having comprehensive information and extracting the most out of the data is important. HIKARI-2021 is the dataset that provides labeled encrypted traffic, while the well-known datasets do not focus on encrypted traffic. There is a possibility that a full payload captured might be useful in the future.
- (3)
- Anonymity: synthetic traffic should provide full packet capture, while real traffic must anonymize certain packets to preserve privacy.
- (4)
- Ground-truth: the datasets should provide realistic traffic from a real production network, compared with the synthetic traffic, and ensure no unlabeled attack in the ground-truth.
- (5)
- Up to date: both packet traces from flow data and pcap should be always accessible by repeating the capturing process of the network traffic. Because the data are subject to change over time, repeating the procedures guarantees that the dataset always obtains the latest information.
- (6)
- Labeled dataset: correctly labeling data as malicious or benign is important for accurate and reliable analysis. The labeling process is a manual task and determined by the flow with a combination of the source IP address, source port, destination IP address, destination port, and protocol.
- (7)
- Encryption Information: information on how to establish benign or malicious traffic must be stated. We are focused on application layer attacks, such as brute force and probing that employ HTTPS with TLS version 1.2 to deliver the attacks.
3.1.2. Process Requirement
3.2. Comparison of the Existing Datasets against the above Requirements
4. HIKARI-2021 Generation Methodology
4.1. Network Configuration for Generating Dataset
- (1)
- The attacker network with two machines is deployed with CentOS 7 and CentOS 8. There are no specific criteria of the attackers’ machines as long as they can run Bash and Python scripts. The Python version is 3.8.8 from Miniconda 3.
- (2)
- In the victim network, three machines are deployed with one Debian 8 machine running Joomla 3.4.3, and two Debian 9 machines running Drupal 8.0 and WordPress 5.0. There are no specific criteria for the OS version for the victim network, and the three different Content Management Systems (CMS) such as Drupal, WordPress, and Joomla use default themes and plugins. These three open-source CMSs were chosen based on their popularity. These machines are used for collecting the background traffic.
4.2. Background Profile
4.3. Benign Profile
4.4. Attacker Profile
- (1)
- Brute force attack: this attack is the most famous for cracking passwords. The attacker usually repeatedly tries to gain the target over and over using all possible combinations using a dictionary of possible common passwords [64]. We developed a script that mimics a brute force attack, using a browser to deliver the attack. We intentionally added a user to the three different CMSs with the role as an admin and password, which we took randomly from [64]. The purpose is to make sure that the brute force attack is delivered successfully.
- (2)
- Brute force attack with different attack vectors: while the first type of attack uses the browser as the attack vector, the second attack uses a different attack vector, XMLRPC. We developed a script that accesses XMLRPC for gaining valid credential access.
- (3)
- Probing: this is also called vulnerability probing. This script scans the web applications, such as Joomla, WordPress, and Drupal to find their vulnerability. The tools for vulnerability scanning are publicly available. For this dataset, the scripts used these probing scripts: droopescan [65] for WordPress and Drupal, and joomscan [66] for Joomla.
4.5. Scenarios
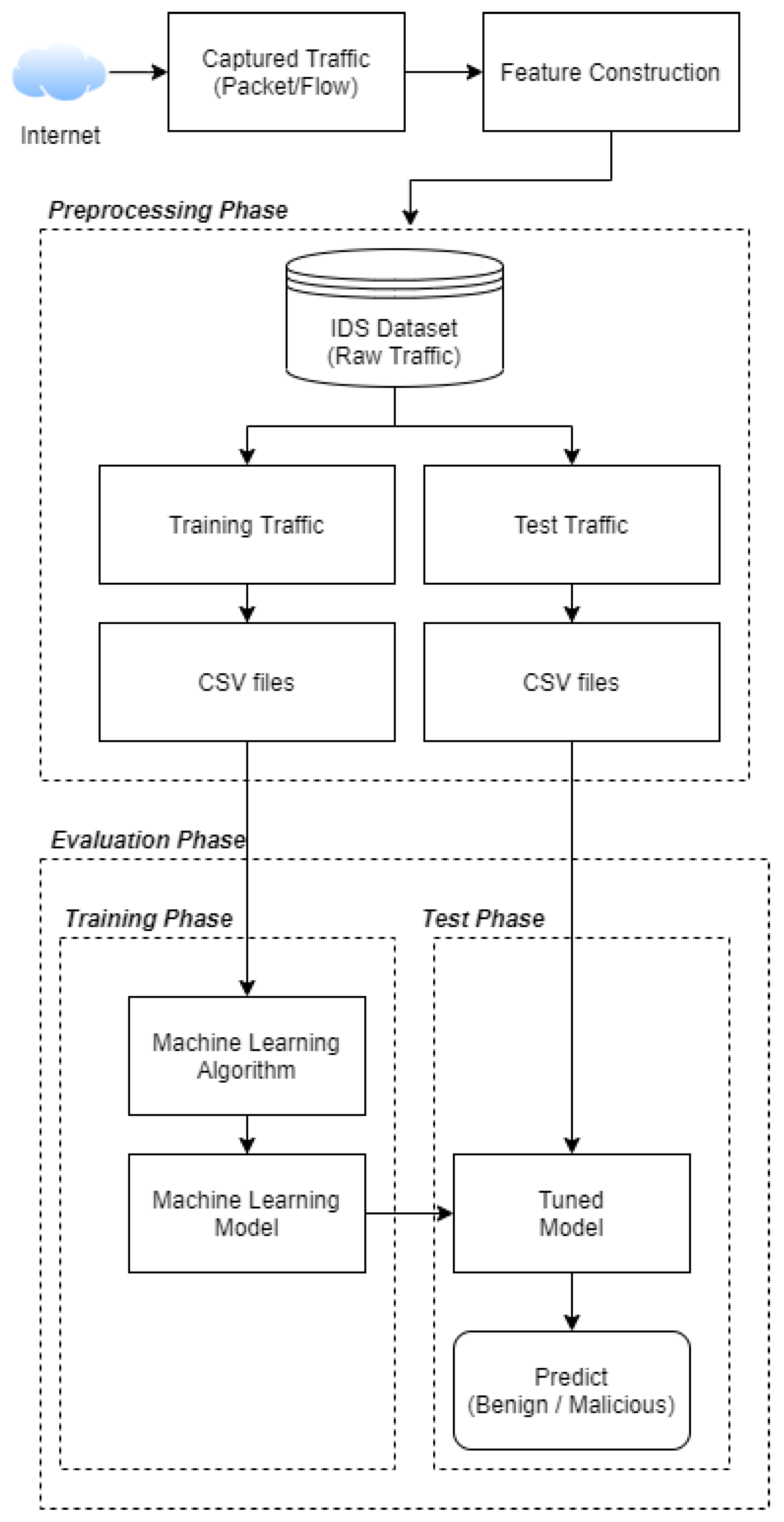
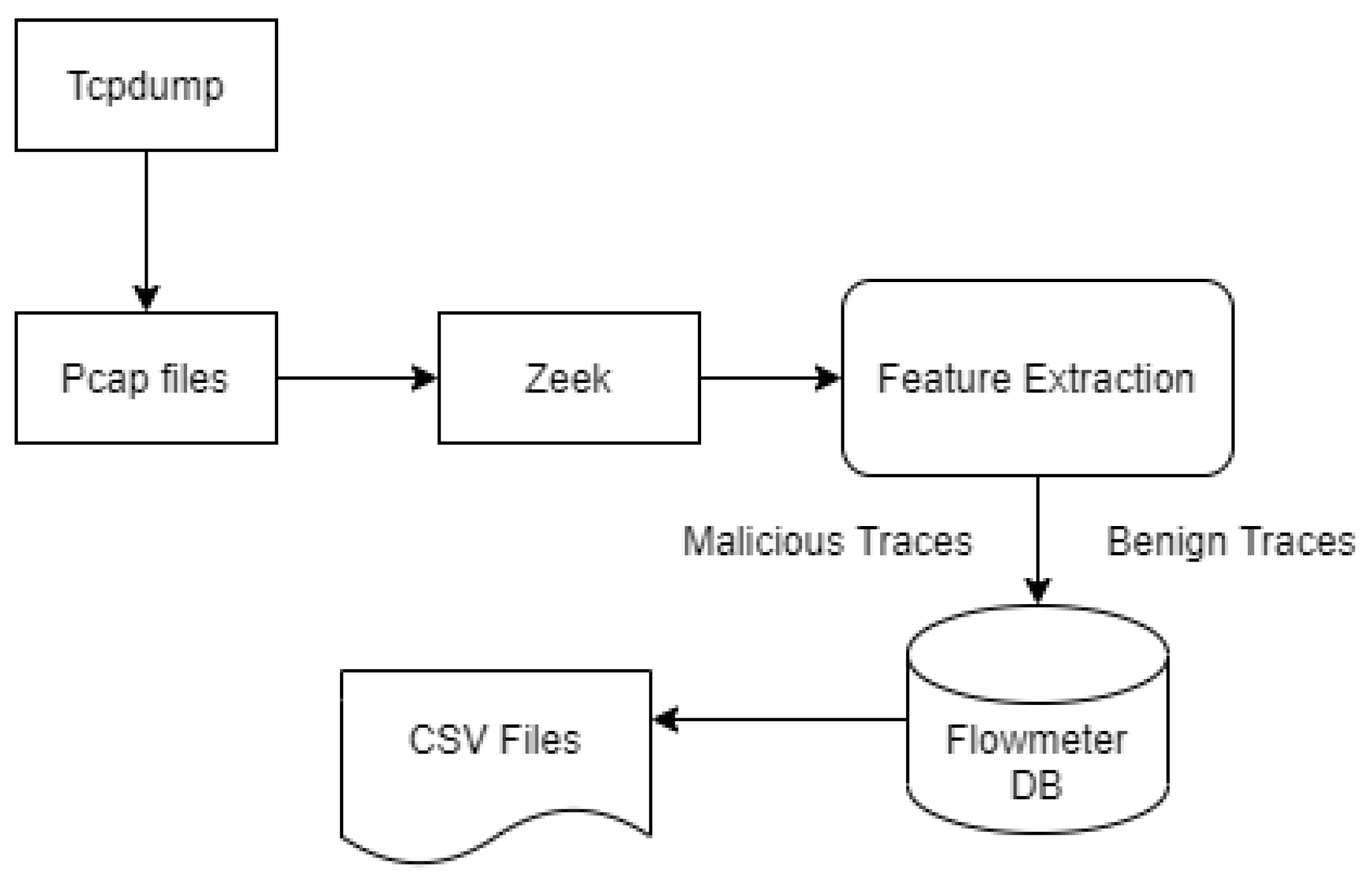
4.6. Dataset Preprocessing
4.7. Labeling Process
4.8. Feature Description
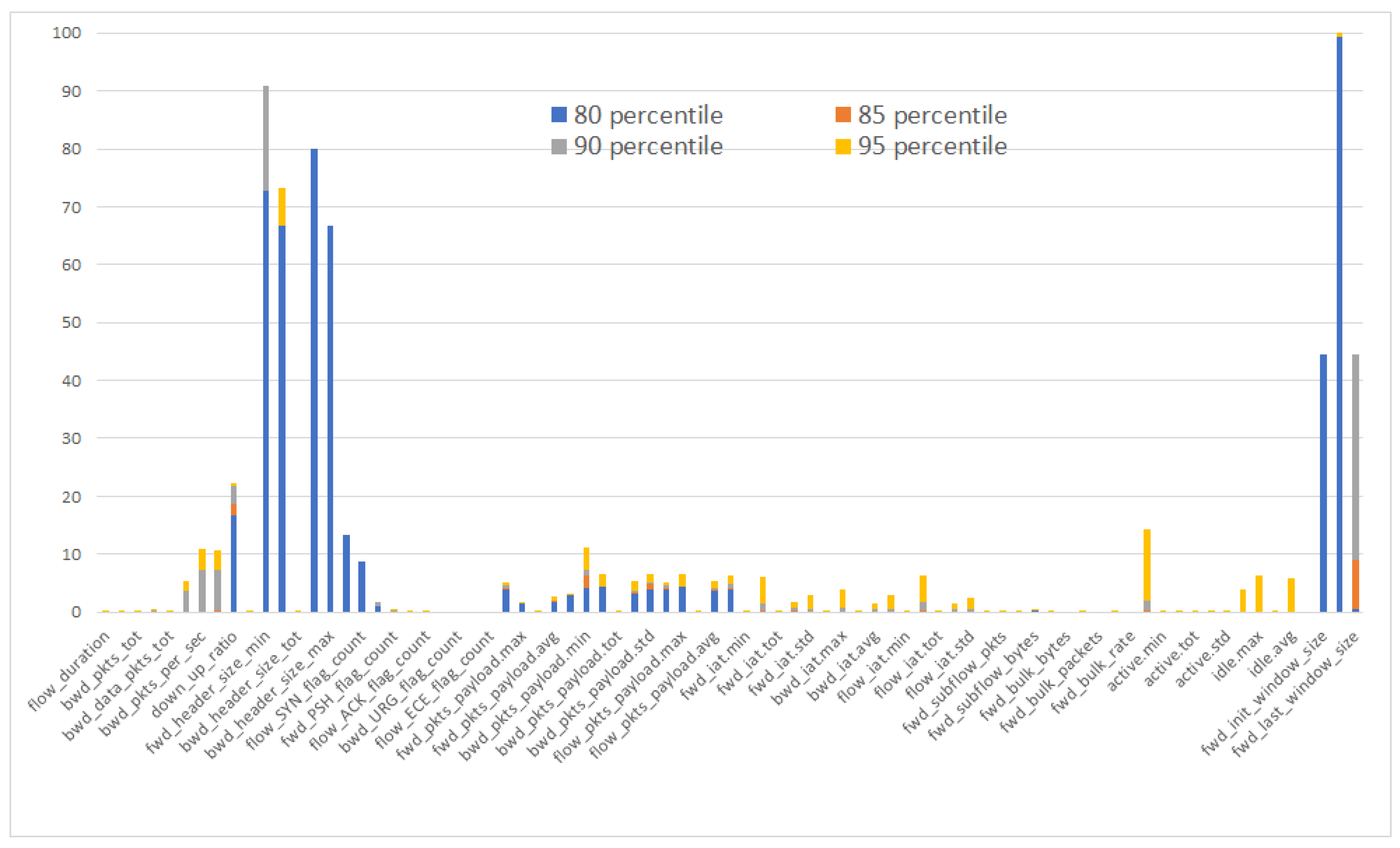
4.9. Performance Analysis
5. Comparison of KDD99, UNSW-NB15, CICIDS-2017, and HIKARI-2021
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tavallaee, M.; Stakhanova, N.; Ghorbani, A.A. Toward credible evaluation of anomaly-based intrusion-detection methods. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 516–524. [Google Scholar] [CrossRef]
- Aviv, A.J.; Haeberlen, A. Challenges in Experimenting with Botnet Detection Systems. In Proceedings of the 4th Workshop on Cyber Security Experimentation and Test (CSET 11), San Francisco, CA, USA, 8 August 2011. [Google Scholar]
- Velan, P.; Čermák, M.; Čeleda, P.; Drašar, M. A survey of methods for encrypted traffic classification and analysis. Int. J. Netw. Manag. 2015, 25, 355–374. [Google Scholar] [CrossRef]
- De Lucia, M.J.; Cotton, C. Identifying and detecting applications within TLS traffic. In Proceedings of the Cyber Sensing 2018, Orlando, FL, USA, 15–19 April 2018; Volume 10630. [Google Scholar] [CrossRef]
- Kaur, S.; Singh, M. Automatic attack signature generation systems: A review. IEEE Secur. Priv. 2013, 11, 54–61. [Google Scholar] [CrossRef]
- Ahmed, M.; Naser Mahmood, A.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Zeek IDS. 2021. Available online: https://zeek.org (accessed on 10 May 2021).
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Inf. Secur. J. Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Maciá-Fernández, G.; Camacho, J.; Magán-Carrión, R.; García-Teodoro, P.; Therón, R. UGR ‘16: A new dataset for the evaluation of cyclostationarity-based network IDSs. Comput. Secur. 2018, 73, 411–424. [Google Scholar] [CrossRef] [Green Version]
- Lippmann, R.P.; Fried, D.J.; Graf, I.; Haines, J.W.; Kendall, K.R.; McClung, D.; Weber, D.; Webster, S.E.; Wyschogrod, D.; Cunningham, R.K.; et al. Evaluating intrusion detection systems: The 1998 DARPA off-line intrusion detection evaluation. In Proceedings of the DARPA Information Survivability Conference and Exposition (DISCEX’00), Hilton Head, SC, USA, 25–27 January 2000; Volume 2, pp. 12–26. [Google Scholar] [CrossRef] [Green Version]
- Siddique, K.; Akhtar, Z.; Khan, F.A.; Kim, Y. KDD Cup 99 data sets: A perspective on the role of data sets in network intrusion detection research. Computer 2019, 52, 41–51. [Google Scholar] [CrossRef]
- Özgür, A.; Erdem, H. A review of KDD99 dataset usage in intrusion detection and machine learning between 2010 and 2015. PeerJ 2016, 4, e1954v1. [Google Scholar] [CrossRef]
- Luo, C.; Wang, L.; Lu, H. Analysis of LSTM-RNN based on attack type of kdd-99 dataset. In Proceedings of the International Conference on Cloud Computing and Security, Haikou, China, 8–10 June 2018; Springer: Cham, Switzerland, 2018; pp. 326–333. [Google Scholar] [CrossRef]
- Fukuda Lab Mawi Archive. 2021. Available online: https://fukuda-lab.org/mawilab (accessed on 10 May 2021).
- Fontugne, R.; Borgnat, P.; Abry, P.; Fukuda, K. Mawilab: Combining diverse anomaly detectors for automated anomaly labeling and performance benchmarking. In Proceedings of the Co-NEXT ’10: Conference on Emerging Networking EXperiments and Technologies, Philadelphia, PA, USA, 30 November–3 December 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Hafsa, M.; Jemili, F. Comparative study between big data analysis techniques in intrusion detection. Big Data Cogn. Comput. 2019, 3, 1. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Sim, C.; Choi, J. Generating labeled flow data from MAWILab traces for network intrusion detection. In Proceedings of the ACM Workshop on Systems and Network Telemetry and Analytics, Phoenix, AZ, USA, 25 June 2019; pp. 45–48. [Google Scholar] [CrossRef] [Green Version]
- CAIDA Datasets. 2021. Available online: https://www.caida.org/catalog/datasets/completed-datasets/ (accessed on 10 May 2021).
- Jonker, M.; King, A.; Krupp, J.; Rossow, C.; Sperotto, A.; Dainotti, A. Millions of targets under attack: A macroscopic characterization of the DoS ecosystem. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 100–113. [Google Scholar] [CrossRef]
- Lutscher, P.M.; Weidmann, N.B.; Roberts, M.E.; Jonker, M.; King, A.; Dainotti, A. At home and abroad: The use of denial-of-service attacks during elections in nondemocratic regimes. J. Confl. Resolut. 2020, 64, 373–401. [Google Scholar] [CrossRef]
- Hinze, N.; Nawrocki, M.; Jonker, M.; Dainotti, A.; Schmidt, T.C.; Wählisch, M. On the potential of BGP flowspec for DDoS mitigation at two sources: ISP and IXP. In Proceedings of the ACM SIGCOMM 2018 Conference on Posters and Demos, Budapest, Hungary, 20–25 August 2018; pp. 57–59. [Google Scholar] [CrossRef]
- Hesselman, C.; Kaeo, M.; Chapin, L.; Claffy, K.; Seiden, M.; McPherson, D.; Piscitello, D.; McConachie, A.; April, T.; Latour, J.; et al. The DNS in IoT: Opportunities, Risks, and Challenges. IEEE Internet Comput. 2020, 24, 23–32. [Google Scholar] [CrossRef]
- Barbosa, R.R.R.; Sadre, R.; Pras, A.; van de Meent, R. Simpleweb/University of Twente Traffic Traces Data Repository; Centre for Telematics and Information Technology, University of Twente: Enschede, The Netherlands, 2010. [Google Scholar]
- Haas, S. Security Monitoring and Alert Correlation for Network Intrusion Detection. Ph.D. Thesis, Staats-und Universitätsbibliothek Hamburg Carl von Ossietzky, Hamburg, Germany, 2020. [Google Scholar]
- Wang, J.; Paschalidis, I.C. Botnet detection based on anomaly and community detection. IEEE Trans. Control Netw. Syst. 2016, 4, 392–404. [Google Scholar] [CrossRef]
- Čermák, M.; Čeleda, P. Detecting Advanced Network Threats Using a Similarity Search. In Proceedings of the IFIP International Conference on Autonomous Infrastructure, Management and Security, Munich, Germany, 20–23 June 2016; Springer: Cham, Switzerland, 2016; pp. 137–141. [Google Scholar] [CrossRef] [Green Version]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Kantarci, B.; Adams, C. Machine learning-driven intrusion detection for contiki-NG-based IoT networks exposed to NSL-KDD dataset. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Linz, Austria, 13 July 2020; pp. 25–30. [Google Scholar] [CrossRef]
- Gao, Y.; Wu, H.; Song, B.; Jin, Y.; Luo, X.; Zeng, X. A distributed network intrusion detection system for distributed denial of service attacks in vehicular ad hoc network. IEEE Access 2019, 7, 154560–154571. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion detection system for NSL-KDD dataset using convolutional neural networks. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 81–85. [Google Scholar] [CrossRef]
- Zhang, C.; Ruan, F.; Yin, L.; Chen, X.; Zhai, L.; Liu, F. A deep learning approach for network intrusion detection based on NSL-KDD dataset. In Proceedings of the 2019 IEEE 13th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 25–27 October 2019; pp. 41–45. [Google Scholar] [CrossRef]
- IMPACT Cyber Trust. 2021. Available online: https://www.impactcybertrust.org/ (accessed on 10 May 2021).
- UMass Trace Repository. 2021. Available online: http://traces.cs.umass.edu/index.php/Network/Network (accessed on 10 May 2021).
- Nasr, M.; Bahramali, A.; Houmansadr, A. Deepcorr: Strong flow correlation attacks on tor using deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1962–1976. [Google Scholar] [CrossRef] [Green Version]
- Bissias, G.; Levine, B.N.; Liberatore, M.; Prusty, S. Forensic identification of anonymous sources in oneswarm. IEEE Trans. Dependable Secur. Comput. 2015, 14, 620–632. [Google Scholar] [CrossRef]
- Eagle, N.; Pentland, A.S. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]
- Kyoto Dataset. 2021. Available online: http://www.takakura.com/Kyoto_data (accessed on 10 May 2021).
- Song, J.; Takakura, H.; Okabe, Y.; Eto, M.; Inoue, D.; Nakao, K. Statistical analysis of honeypot data and building of Kyoto 2006+ dataset for NIDS evaluation. In Proceedings of the First Workshop on Building Analysis Datasets and Gathering Experience Returns for Security, Salzburg, Austria, 10 April 2011; pp. 29–36. [Google Scholar] [CrossRef]
- Singh, A.P.; Kaur, A. Flower pollination algorithm for feature analysis of kyoto 2006+ data set. J. Inf. Optim. Sci. 2019, 40, 467–478. [Google Scholar] [CrossRef]
- Salo, F.; Nassif, A.B.; Essex, A. Dimensionality reduction with IG-PCA and ensemble classifier for network intrusion detection. Comput. Netw. 2019, 148, 164–175. [Google Scholar] [CrossRef]
- Zuech, R.; Khoshgoftaar, T.; Seliya, N.; Najafabadi, M.; Kemp, C. A New Intrusion Detection Benchmarking System. 2015. Available online: https://www.aaai.org/ocs/index.php/FLAIRS/FLAIRS15/paper/view/10368 (accessed on 30 April 2021).
- Krystosek, P.; Ott, N.M.; Sanders, G.; Shimeall, T. Network Traffic Analysis with SiLK; Technical Report; Carnegie-Mellon Univeristy: Pittsburgh, PA, USA, 2019. [Google Scholar]
- Snort IDS. 2021. Available online: https://snort.org/ (accessed on 10 May 2021).
- Rajagopal, S.; Hareesha, K.S.; Kundapur, P.P. Feature Relevance Analysis and Feature Reduction of UNSW NB-15 Using Neural Networks on MAMLS. In Advanced Computing and Intelligent Engineering; Springer: Singapore, 2020; pp. 321–332. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. Performance Analysis of Intrusion Detection Systems Using a Feature Selection Method on the UNSW-NB15 Dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Kumar, V.; Das, A.K.; Sinha, D. Statistical analysis of the UNSW-NB15 dataset for intrusion detection. In Computational Intelligence in Pattern Recognition; Springer: Singapore, 2020; pp. 279–294. [Google Scholar] [CrossRef]
- Rajagopal, S.; Kundapur, P.P.; Hareesha, K.S. A stacking ensemble for network intrusion detection using heterogeneous datasets. Secur. Commun. Netw. 2020, 2020. [Google Scholar] [CrossRef] [Green Version]
- Radhakrishnan, C.; Karthick, K.; Asokan, R. Ensemble Learning based Network Anomaly Detection using Clustered Generalization of the Features. In Proceedings of the 2020 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 18–19 December 2020; pp. 157–162. [Google Scholar] [CrossRef]
- Yilmaz, I.; Masum, R.; Siraj, A. Addressing imbalanced data problem with generative adversarial network for intrusion detection. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 25–30. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Gharib, A.; Lashkari, A.H.; Ghorbani, A.A. Towards a reliable intrusion detection benchmark dataset. Softw. Netw. 2018, 2018, 177–200. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar] [CrossRef]
- Kshirsagar, D.; Kumar, S. An efficient feature reduction method for the detection of DoS attack. ICT Express 2021. [Google Scholar] [CrossRef]
- Kshirsagar, D.; Kumar, S. An ensemble feature reduction method for web-attack detection. J. Discret. Math. Sci. Cryptogr. 2020, 23, 283–291. [Google Scholar] [CrossRef]
- Tama, B.A.; Nkenyereye, L.; Islam, S.R.; Kwak, K.S. An enhanced anomaly detection in web traffic using a stack of classifier ensemble. IEEE Access 2020, 8, 24120–24134. [Google Scholar] [CrossRef]
- Yulianto, A.; Sukarno, P.; Suwastika, N.A. Improving AdaBoost-based Intrusion Detection System (IDS) Performance on CIC IDS 2017 Dataset. J. Phys. Conf. Ser. 2019, 1192, 012018. [Google Scholar] [CrossRef]
- Stiawan, D.; Idris, M.Y.B.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 dataset feature analysis with information gain for anomaly detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar] [CrossRef]
- Cordero, C.G.; Vasilomanolakis, E.; Wainakh, A.; Mühlhäuser, M.; Nadjm-Tehrani, S. On generating network traffic datasets with synthetic attacks for intrusion detection. ACM Trans. Priv. Secur. 2021, 24, 1–39. [Google Scholar] [CrossRef]
- Kenyon, A.; Deka, L.; Elizondo, D. Are public intrusion datasets fit for purpose characterising the state of the art in intrusion event datasets. Comput. Secur. 2020, 99, 102022. [Google Scholar] [CrossRef]
- Varet, A.; Larrieu, N. Realistic Network Traffic Profile Generation: Theory and Practice. Comput. Inf. Sci. 2014, 7, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Selenium Python. 2021. Available online: https://selenium-python.readthedocs.io (accessed on 14 May 2021).
- Alexa. 2021. Available online: https://www.alexa.com (accessed on 14 May 2021).
- Daniel Miessler 10k Most Common Credentials. 2021. Available online: https://github.com/danielmiessler (accessed on 14 May 2021).
- Droopescan. Available online: https://github.com/droope/droopescan (accessed on 30 April 2021).
- Joomscan. Available online: https://github.com/OWASP/joomscan/releases (accessed on 30 April 2021).
- Fan, J.; Xu, J.; Ammar, M.H.; Moon, S.B. Prefix-preserving IP address anonymization: Measurement-based security evaluation and a new cryptography-based scheme. Comput. Netw. 2004, 46, 253–272. [Google Scholar] [CrossRef]
- Ferriyan, A.; Thamrin, A.H.; Takeda, K.; Murai, J. HIKARI-2021: Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic; Zenodo: Geneva, Switzerland, 2021. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Comp. Capture | Payload | Anonymity | Ground-Truth | Up to Date Traffic | Labeled | Encryption | Practical to Generate |
|---|---|---|---|---|---|---|---|---|
| KDD99 [11] | Yes | Yes | No | Yes | No | Yes | No | No |
| MAWILab [15] | Yes | No | Yes | No | Yes | Yes | Yes | Yes |
| CAIDA [19] | Yes | No | Yes | No | Yes | No | No | No |
| SimpleWeb [24] | Yes | No | No | No | No | No | No | Yes |
| NSL-KDD [28] | Yes | Yes | No | Yes | No | Yes | No | No |
| IMPACT [34] | Yes | No | Yes 1 | No | Yes | No | No | No |
| UMass [35] | Yes | Yes | - | No | No | No | No | No |
| Kyoto [39] | Yes | Yes | No | No | No | Yes | No | Yes |
| IRSC [43] | Yes | Yes | No | Yes | No | Yes | No | No |
| UNSW-NB15 [9] | Yes | Yes | No | Yes | No | Yes | No | No |
| UGR’16 [10] | Yes | No | Yes | Yes | Yes | Yes | Yes | Yes |
| CICIDS-2017 [53] | Yes | Yes | Yes | No | No | Yes | Yes 2 | No |
| Traffic Category | Label | Total Flows (Flowmeter) | No. Encrypted Session |
|---|---|---|---|
| Background | Benign | 170,151 | 36,782 |
| Benign | Benign | 347,431 | 116,309 |
| Bruteforce | Attack | 5884 | 5884 |
| Bruteforce-XML | Attack | 5145 | 5145 |
| Probing | Attack | 23,388 | 23,388 |
| XMRIGCC CryptoMiner | Attack | 3279 | 0 |
| No | Feature | No | Feature | No | Feature |
|---|---|---|---|---|---|
| 1 | uid | 30 | flow_ECE_flag_count | 59 | flow_iat.avg |
| 2 | originh | 31 | fwd_pkts_payload.min | 60 | flow_iat.std |
| 3 | originp | 32 | fwd_pkts_payload.max | 61 | payload_bytes_per_second |
| 4 | responh | 33 | fwd_pkts_payload.tot | 62 | fwd_subflow_pkts |
| 5 | responp | 34 | fwd_pkts_payload.avg | 63 | bwd_subflow_pkts |
| 6 | flow_duration | 35 | fwd_pkts_payload.std | 64 | fwd_subflow_bytes |
| 7 | fwd_pkts_tot | 36 | bwd_pkts_payload.min | 65 | bwd_subflow_bytes |
| 8 | bwd_pkts_tot | 37 | bwd_pkts_payload.max | 66 | fwd_bulk_bytes |
| 9 | fwd_data_pkts_tot | 38 | bwd_pkts_payload.tot | 67 | bwd_bulk_bytes |
| 10 | bwd_data_pkts_tot | 39 | bwd_pkts_payload.avg | 68 | fwd_bulk_packets |
| 11 | fwd_pkts_per_sec | 40 | bwd_pkts_payload.std | 69 | bwd_bulk_packets |
| 12 | bwd_pkts_per_sec | 41 | flow_pkts_payload.min | 70 | fwd_bulk_rate |
| 13 | flow_pkts_per_sec | 42 | flow_pkts_payload.max | 71 | bwd_bulk_rate |
| 14 | down_up_ratio | 43 | flow_pkts_payload.tot | 72 | active.min |
| 15 | fwd_header_size_tot | 44 | flow_pkts_payload.avg | 73 | active.max |
| 16 | fwd_header_size_min | 45 | flow_pkts_payload.std | 74 | active.tot |
| 17 | fwd_header_size_max | 46 | fwd_iat.min | 75 | active.avg |
| 18 | bwd_header_size_tot | 47 | fwd_iat.max | 76 | active.std |
| 19 | bwd_header_size_min | 48 | fwd_iat.tot | 77 | idle.min |
| 20 | bwd_header_size_max | 49 | fwd_iat.avg | 78 | idle.max |
| 21 | flow_FIN_flag_count | 50 | fwd_iat.std | 79 | idle.tot |
| 22 | flow_SYN_flag_count | 51 | bwd_iat.min | 80 | idle.avg |
| 23 | flow_RST_flag_count | 52 | bwd_iat.max | 81 | idle.std |
| 24 | fwd_PSH_flag_count | 53 | bwd_iat.tot | 82 | fwd_init_window_size |
| 25 | bwd_PSH_flag_count | 54 | bwd_iat.avg | 83 | bwd_init_window_size |
| 26 | flow_ACK_flag_count | 55 | bwd_iat.std | 84 | fwd_last_window_size |
| 27 | fwd_URG_flag_count | 56 | flow_iat.min | 85 | traffic_category |
| 28 | bwd_URG_flag_count | 57 | flow_iat.max | 86 | Label |
| 29 | flow_CWR_flag_count | 58 | flow_iat.tot |
| Algorithm | Accuracy | Balanced Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| KNN | 0.98 | 0.94 | 0.86 | 0.90 | 0.88 |
| MLP | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| SVM | 0.99 | 0.99 | 0.99 | 0.98 | 0.99 |
| RF | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Parameters | KDD99 | UNSW-NB15 | CICIDS-2017 | HIKARI-2021 |
|---|---|---|---|---|
| Number of unique IP address | 11 | 45 | 16,960 | 7991 |
| Simulation | Yes | Yes | Partial | Partial |
| Duration of the data being captured | 5 weeks | 16 h | 65 h | 39 h |
| Format of the data collected | 3 types (tcpdump, BSM, dumpfile) | pcap files | pcap files | pcap files |
| Number of Attack categories | 4 | 9 | 7 | 4 |
| Feature extraction tools | Bro-IDS tool | Argus, Bro-IDS | CICFlowmeter | Zeek-IDS, python tools |
| Number of features | 42 | 49 | 80 | 86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferriyan, A.; Thamrin, A.H.; Takeda, K.; Murai, J. Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic. Appl. Sci. 2021, 11, 7868. https://doi.org/10.3390/app11177868
Ferriyan A, Thamrin AH, Takeda K, Murai J. Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic. Applied Sciences. 2021; 11(17):7868. https://doi.org/10.3390/app11177868
Chicago/Turabian StyleFerriyan, Andrey, Achmad Husni Thamrin, Keiji Takeda, and Jun Murai. 2021. "Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic" Applied Sciences 11, no. 17: 7868. https://doi.org/10.3390/app11177868
APA StyleFerriyan, A., Thamrin, A. H., Takeda, K., & Murai, J. (2021). Generating Network Intrusion Detection Dataset Based on Real and Encrypted Synthetic Attack Traffic. Applied Sciences, 11(17), 7868. https://doi.org/10.3390/app11177868