1. Introduction
Although it is quite a trivial task for humans to describe an image, it was for many years, until recently, a very challenging task for a machine to perform at a level close to that of humans. The major breakthrough came with the introduction of deep learning-based image-captioning systems [
1] that were inspired by the success of deep learning-based neural machine translation systems [
2], which heralded probably the most significant age in the field of visual–language research. In automatic image caption generation systems, an image is presented to a machine which is then required to produce relevant and sensible human-readable descriptions (captions) that describe it. The challenge of accomplishing the task of automatic image-captioning stems from the fact that it is a vision-to-language task that requires a machine to both understand the semantic content in an image and have language understanding as well as generation capabilities. This is further complicated by the fact that it is an ambiguous task with many equally accurate descriptions possible for each image.
Automatic image-captioning systems have been mainly implemented using LSTMs (long short-term memory) [
1,
3,
4,
5] as the language model in an encoder–decoder architecture. In this architecture, a convolutional neural network (CNN) encoder pre-trained on a large image classification dataset such as ImageNet [
6], is used to extract the image features into a fixed-length vector that is then fed to the decoder LSTM which learns to generate captions one word at a time by conditioning them over both the image features and the previously generated words. Even with the introduction of systems that employed CNN–CNN encoder–decoder models [
7,
8], the now classic method has still stood the test of time, especially with the introduction of attention-based variants [
3] which significantly improved their performance.
In spite of their undeniable successes and impressive performances, LSTMs have several shortcomings. The inability to remember long sequences was a major factor in their development and advantage over vanilla RNNs, but the problem, which is caused by vanishing gradients, still exists. Their sequential nature also makes it difficult to parallelize parts of the training process as every subsequent caption token can only be dealt with after the previous one has been processed. As a consequence, they are incapable of taking full advantage of GPUs, which would make training them much faster, significantly impacting the training time. Furthermore, most of the previously mentioned models of image-captioning suffered from the issue of exposure bias. It is because of these reasons that more researchers have recently begun to leave previous methods and adopt transformer-based architectures. Transformer architectures, introduced by Vaswani et al. [
9] for machine translation, have now achieved state-of-the-art results in many computer vision and natural language processing (NLP) tasks including visual–language tasks such as image-captioning [
10,
11,
12,
13].
Transformers for image-captioning in many of the proposed models are not without their shortcomings, though. Transformers are very data-hungry, requiring a lot of data to achieve decent results. This is because they are very unfocused at the beginning and require data to learn both where to focus, and what to focus on. Many of the transformer models in image-captioning do not adequately use the images to generate the captions, mostly relying on the training captions (which are fortunately already highly compressed and informative), thereby missing out on much of the fine-grained salient semantic information available in images that could improve the quality of generated captions. This problem was much worse in non-attention-based captaining models that would only look at the image once and still produce decent captions; thus, the practice to give little attention to the images in image-captioning persisted. Another challenge experienced in image-captioning concerns increasing the level of detail in the captions generated, specifically increasing the number of objects and attributes mentioned in captions generated. Often, captions only mention a single object, including probably its location and the action being performed. As a result, there is a need to find more ways to highlight and extract more of the latent features contained in images so that they can provide additional information which can be exploited by intra-attention mechanisms.
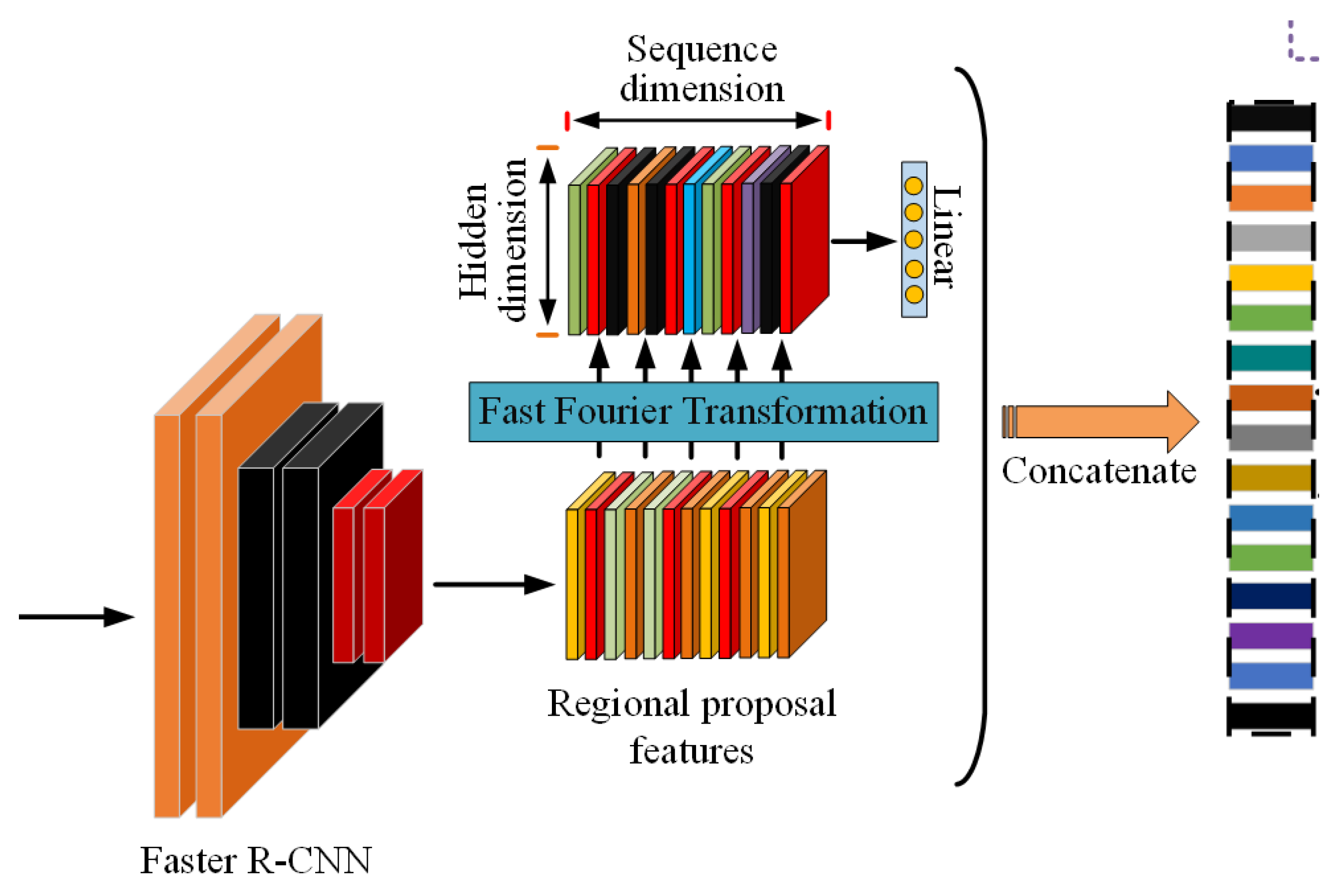
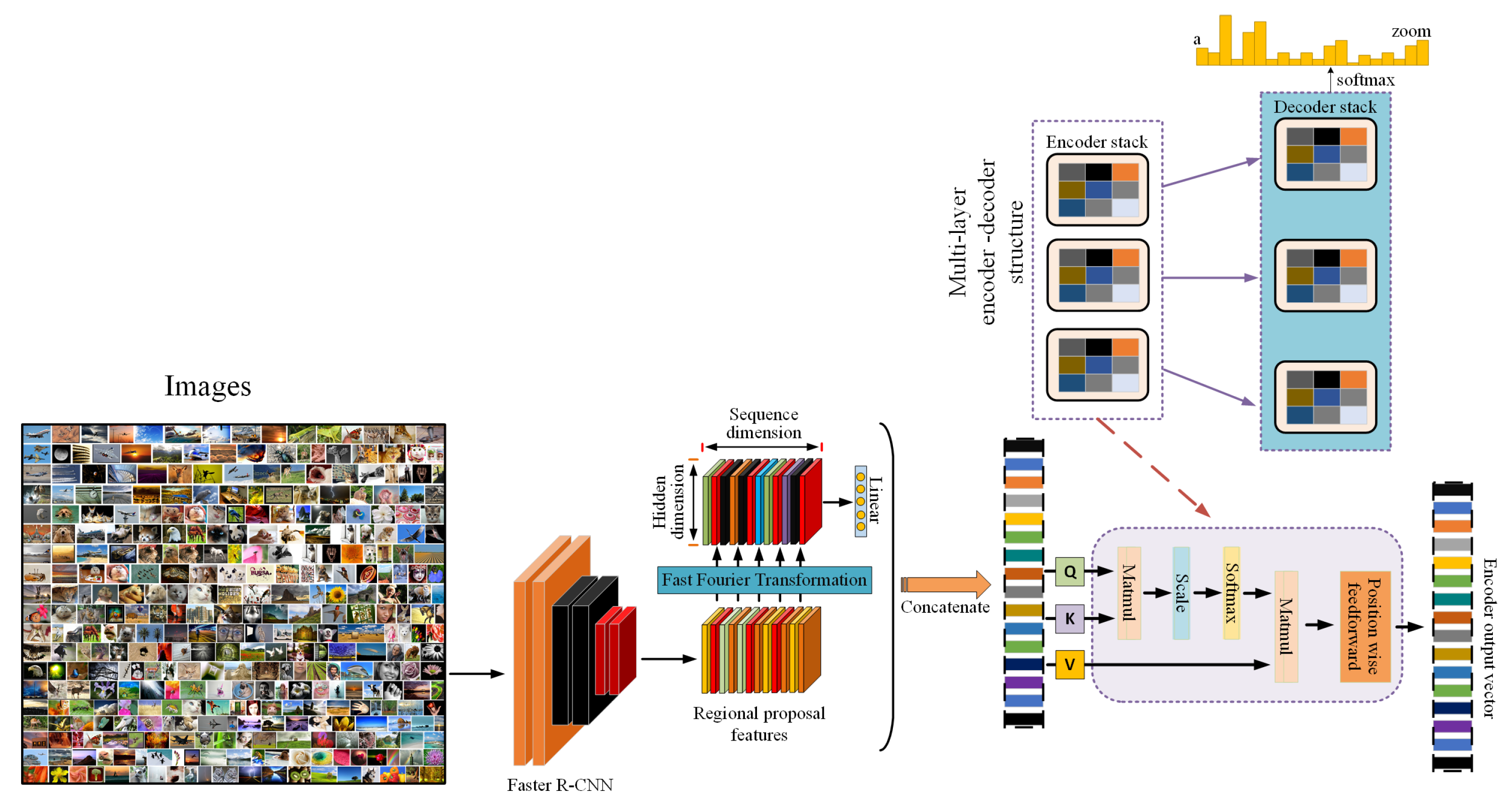
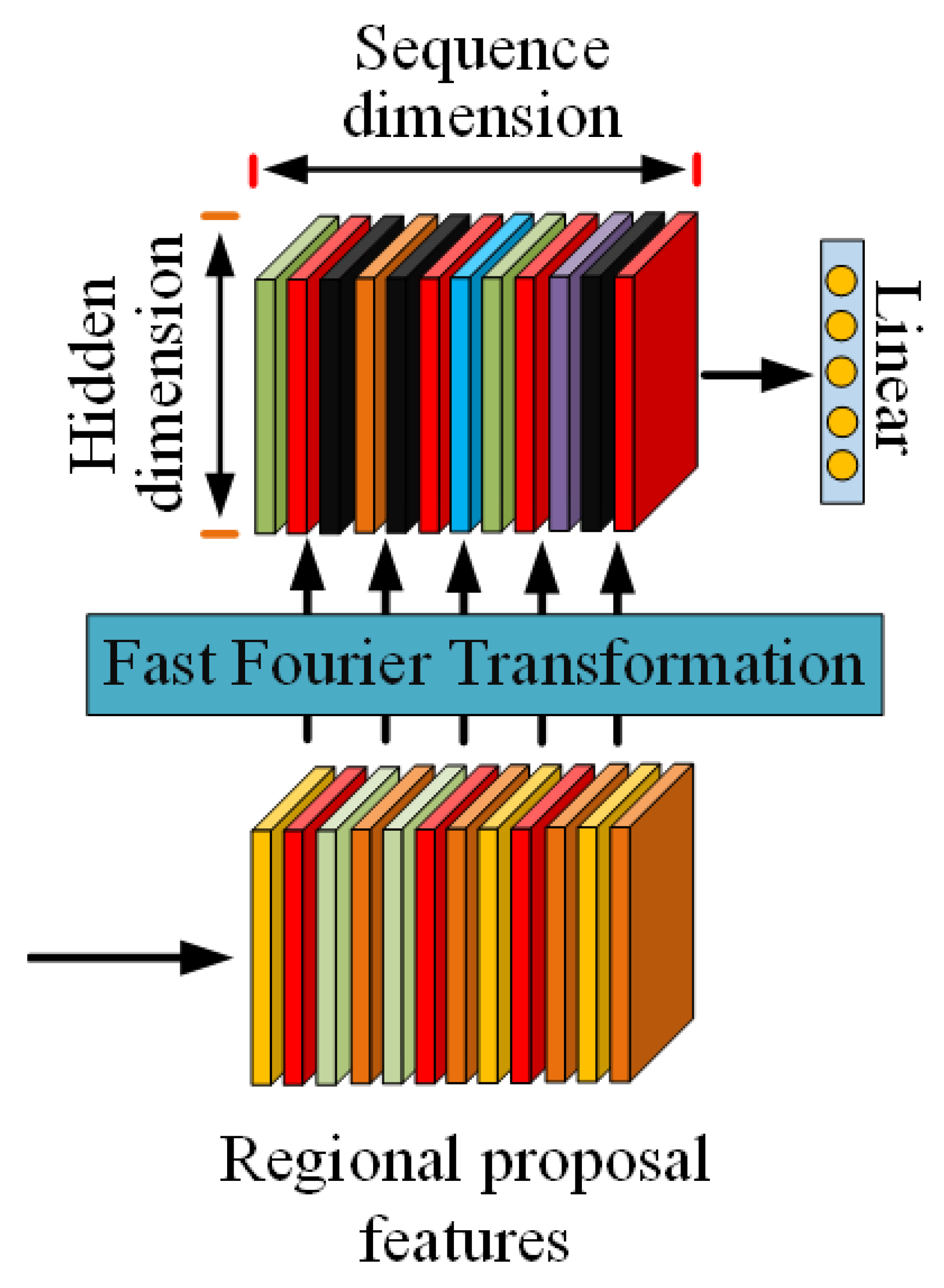
It is with the above in mind that we propose a transformer-based image-captioning method that purposefully uses fast Fourier transforms to extract additional salient information from image features in order to create a richer representation of input images and lead to the generation of more detailed representative captions, enabling the image to contribute more towards the generation of captions without specifically grounding caption objects to regions in the image, as shown summarily in
Figure 1 and in the full framework diagram in
Figure 2. The ability of Fourier transforms to break down a function into its individual frequencies, as well as the mixing mechanisms they provide [
14] without using learnable parameters, offer a way to extract and highlight some existing discriminatory image information that may remain unused if self-attention is only applied directly to the input features. We (1) leverage the power of Fourier signal decomposition and mixing to extract otherwise ignored salient image information, and (2) use a simple yet effective concatenation of features to create a richer image feature representation to foster better quality and more detailed caption generation. The additional image feature information allows for the self-attention mechanism to learn more relationships among features and the associated captions, leading to demonstratively more detailed captions. Our model was tested on the MSCOCO benchmark dataset and our contributions can be summed up as follows:
We propose AFCT, a fully attentive transformer-based captioning model that uses a multi-layer encoder–decoder architecture to extract fine-grained salient image features that are used in caption generation.
The model proposed leverages the ability of Fourier transforms to separate input signals into their constituent frequencies to extract and augment the object proposal features, creating a richer and more detailed image feature representation that learns a deeper relationship between objects and their locations in images.
We perform a thorough analysis of the effect of the use of Fourier transforms and a fully connected layer for image-captioning. Furthermore, we demonstrate why Fourier transforms work much better with image features than with captions by performing several experiments on variants of the proposed model.
We demonstrate the superior performance of the proposed method qualitatively through the quality of captions generated, as well as quantitatively through tests performed on the MSCOCO benchmark dataset, showcasing competitive scores when compared to similar and more complex models without using additional training or pre-training methods.
Figure 1.
The fast Fourier transform extracted features fused with regional proposal features.
Figure 1.
The fast Fourier transform extracted features fused with regional proposal features.
Figure 2.
Fourier-enhanced image-captioning framework diagram.
Figure 2.
Fourier-enhanced image-captioning framework diagram.
2. Related Work
Automatic image-captioning is not a new field of study and a lot of research has already gone into developing systems that tackle it. As in [
15], machine learning-based image-captioning methods can be divided into two broad categories: traditional and deep learning-based image-captioning methods. To extract image features, traditional machine learning methods [
16,
17,
18,
19,
20,
21,
22] employed tedious and cumbersome manual feature engineering, and relied on sentence templates, sentence-retrieval methods, and ranking-based techniques to create the descriptions, which inevitably were generally very rigid in nature and not novel.
The field of image-captioning remained more or less a fringe research area until, inspired by the successes of deep neural networks applied to neural machine translation [
2], deep learning-based methods thrust automatic image-captioning into the limelight. Most of these deep learning-based methods [
1,
3,
23,
24,
25] involve the use of neural networks such as, in particular, recurrent neural networks (RNNs) and, specifically, LSTMs [
26] or gated recurrent units (GRUs) [
27], in conjunction with convolutional neural networks (CNN) [
28], in an encoder–decoder architecture in which a state-of-the-art CNN architecture such as VGGNet [
29] and ResNet [
30] pre-trained on the ImageNet dataset, used as the encoder for image feature extraction. These features, together with the associated image captions, are then used to train an LSTM or GRU decoder (language model) to generate relevant captions based on the input image; this is achieved by training to generate captions using the image features and the previously generated captions to predict the next word in the sequence. Attention mechanisms that allow the decoder to focus on different parts of the image during generation boosted the performance of these methods [
3]. In an attempt to further boost performance and increase the diversity of the captions generated, some works [
7,
8] have successfully utilized CNNs as decoders, employed generative adversarial neural networks and reinforcement learning [
31,
32], and recently, more commonly, employed transformers. This was done to alleviate RNN issues including being too complex and slow to train, as well as their sequential nature in making it difficult for them to take full advantage of the parallelization advantages offered by the use of GPUs.
Transformers, first proposed in the paper “attention is all you need” [
9], have greatly changed the vision, language, and the vision–language research communities. Methods involving transformers such as ViLBERT [
33] have achieved state-of-the-art results in vision, language, and vision–language tasks. Originally proposed following encoder–decoder architectures, there are now variants that exist using only one of the modules. In image-captioning, transformers, with their attention-only architectures (without recurrent units), may follow the encoder–decoder architecture [
10,
13], wherein the encoder receives and processes image features, and sends them to the decoder module (language model) in which captions are also input and output. Pre-trained unified transformer architectures for visual–language tasks have been proposed, wherein the model is pre-trained on a large corpus and then fine-tuned for downstream tasks such as image-captioning and vision-question-answering [
11,
12]. The meshed-memory transformer [
10] uses a multilevel representation of the encoder output and a meshed cross-attention network at the decoder. AoANet [
13] proposes an alternative to the scaled dot product attention wherein the initial query is concatenated with the output of the dot product attention, the result of which is then transformed by two linear layers to produce an information signal and a sigmoid attention gate which, when multiplied together, can be used as a substitute for the normal scaled dot product attention. DLCT [
34] uses both region proposal and grid features to generate captions. This requires a specially designed complex attention mechanism they refer to as a dual-way self-attention mechanism and a locality-constrained cross-attention mechanism, alongside an alignment graph to combine the features and eliminate any resulting noise. CPTR [
35] uses a pre-trained vision transformer as the encoder, completely removing convolutional features. Due to the fact that a transformer is initially very unfocused, a lot of data is required to train it. As a result, in order to use a visual transformer on the captioning dataset, the authors had to use an encoder pre-trained on a much larger dataset than their captioning dataset.
In order to add more details to the captions, some works such as [
4] used templates which are later filled using associated external news articles. Wu et al. [
36] used an intermediate attribute prediction layer and injected external knowledge mined from a knowledge-base into the model to improve the captions generated. There is a need for methods that can make such detailed captions without resorting to external knowledge. The current language models are quite powerful and the datasets contain enough textual information that it is still possible to improve the quality of captions and generate more detailed captions without the need for external knowledge-bases. This can be done by extracting more salient information from the image features as well as learning better associations and relationships during training both between the features and with the captions that describe the images.
Inspired by the work explored above, we introduce the Attentive Fourier-Augmented Image-Captioning Transformer, AFCT, a transformer-based image-captioning model that fully explores the input image features to make the image in image-captioning matter to a greater degree. We achieve this by using a very simple yet effective fast Fourier transform algorithm to augment the regional proposal features from a faster R-CNN network. The model learns a deeper and more complex relationship between the input image features (and subsequently the associated captions) by setting a self-attention layer to create relevancy scores over the input regional proposal features supplemented by the Fourier extracted features. We demonstrate a model that makes better use of the fine-grained salient semantic information contained in the images to generate accurate, fluent, relevant, and more detailed captions that show a better understanding of the object, its location, and the surroundings when generating captions. Fourier transforms have been more commonly used in theoretical work [
14] such as for solving partial differential equations [
37], reducing the exploding and vanishing problems in RNNs [
38], speeding up CNN computations [
39,
40], and the development of Fourier convolutional neural networks [
41].
Fourier transforms have also been extensively utilized in many image-processing applications. For example, it can be used for image transformation and compression [
42,
43]. Shi et al. [
44] used 2D Fourier transforms that also employed a hash function to take advantage of the sparsity in the frequency domain to estimate the largest k coefficients. The authors expressed that their method is faster than the Fastest Fourier Transform in the West (FFTW) [
45], which is generally taken as the fastest fast Fourier transform implementation. Fast Fourier transforms have also been used to fuse satellite images as in [
46]. In the image classification domain, Fourier transforms were explored by [
47] for the extraction of useful information in the frequency domain using the Fourier transform of input images and deep neural networks. In contrast, we work with feature vectors that have been pre-processed by a faster R-CNN network because we need more fine-grained information than is required for classification. A more recent proposal and most similar to our work is the study by Lee-Thorp et al. [
14] who propose replacing the self-attention layer with a Fourier transform or fully connected layer. In contrast, we maintain the self-attention layer but use the Fourier transforms to mine more salient image information and employ it to an image-captioning task rather than a translation or text-retrieval task. Similar to [
10], we also use a multilevel encoding of image regions, but in contrast, we do not use a mesh connectivity.
5. Discussion
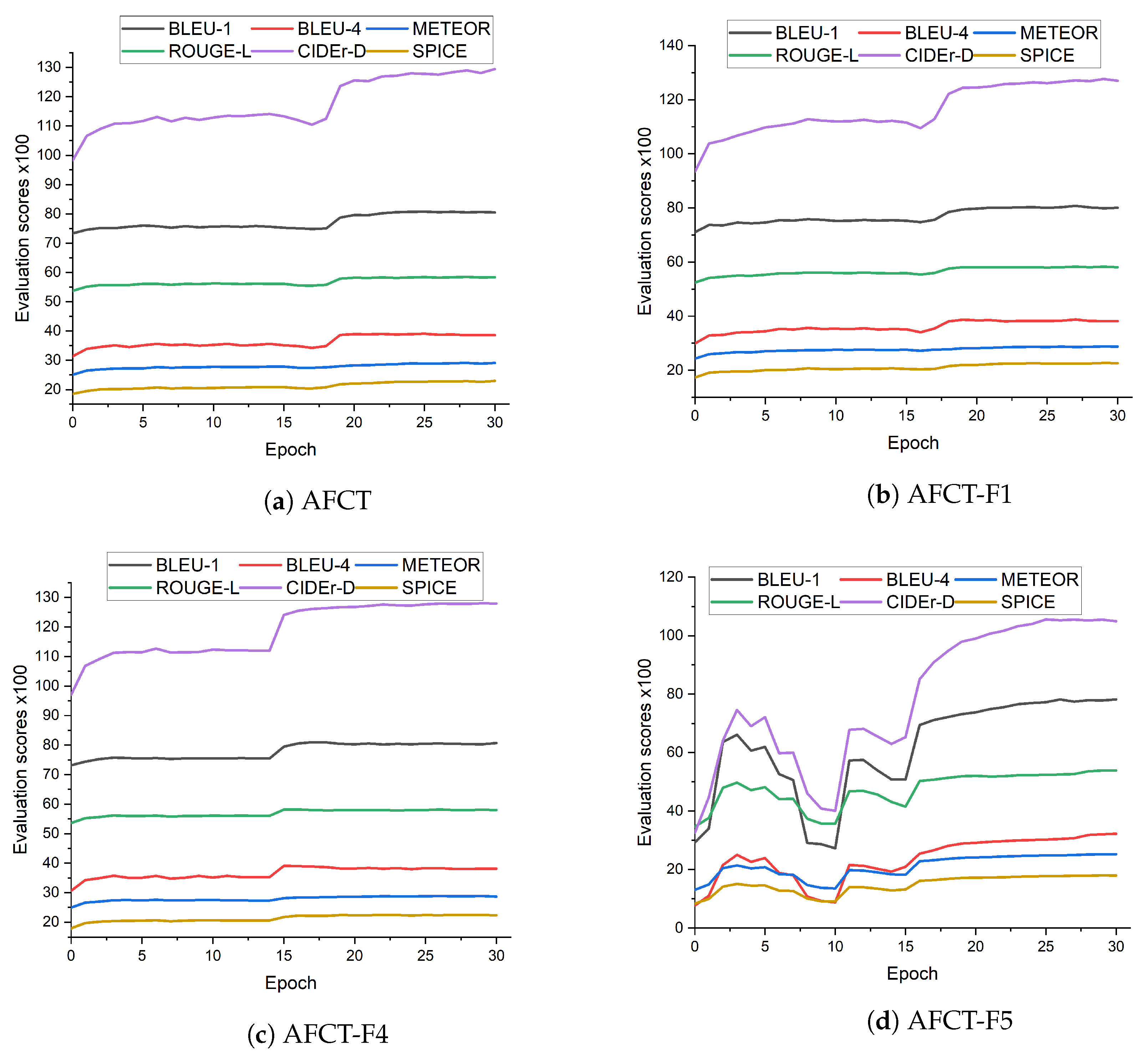
The results from our model are competitive in all evaluation categories and validated by the results of the variants used in the ablation studies to explore the effect of each of the design decisions we made. This is especially apparent regarding the CIDEr score in
Table 1 and the quality of the captions as attested to by human evaluators. Automatic evaluation of language generation results is still an ongoing area of research. No single method is good enough to adequately evaluate the generated text with respect to the ground truth but the metrics are provided nevertheless to make it possible to compare this manuscript to other papers. We used the full suite of methods, alongside human evaluators, and provide graphs that we hope together demonstrate a reasonably accurate analysis both quantitatively through the metrics and graphs (
Figure 4), and qualitatively through the sample captions shown in
Table A1,
Table A2,
Table A3 and
Table A4 in
Appendix A.1. We intentionally do not highlight any captions sections in order to not bias anyone towards what to notice so as to let reader devise their own deductions about the differences between the captions generated by the different models. The optimum number of encoders and decoders for this set up is three encoders and three decoders. This finding is not only proven by the stellar results achieved by our model but further solidified by the better performance of the AFCT-1 and AFCT-3 variants, which had three encoders and three decoders, when compared to the AFCT-2 variant, which had six layers.
The feature representation of an image contains much of the latent information that can be exploited to identify objects and their relationships to each other. Fourier transforms provide a way to accomplish such a task because they decompose input features into their constituent elements in the frequency domain. In this domain, many features that were not apparent in the original domain become highlighted as the transform improves the signal-to-noise ratio. In our image-captioning application, this additional object and relation information improved the quality of the captions generated. Alternative ways to improve the quality of the image feature information, such as using external knowledge sources or pre-training, are thus avoided. In addition, the Fourier transforms themselves are just a linear transformation and thus hardly add any new parameters that need to be learned. The advantage of this is that there will only be an insignificant increase in the training time required, while attaining a significant improvement in performance.
The AFCT-1 variant that used a Fourier transform to replace the self-attention model, which performed second best and was only beaten by the proposed model. This shows FFTs are capable of extracting and highlighting many of the underlying features, thus providing the cross-attention sub-module with highly discriminating and information-rich features on which to model the captions. The AFCT-3 variant used only one attention head instead of eight but this did not seem to affect its performance. This is because no self-attention was used, thus the outputs of the heads were usually the same and there was no measurable advantage of using one or eight heads. In the self-attention technique, every input feature receives a score of its relevance to itself and to other features. This may result in each feature giving itself a higher score than all the other features. This situation is mitigated by having multiple attention heads, which by focusing on different attention areas, reduces this bias. The result of the Fourier transformation over the features is deterministic and always the same no matter how many heads observe it. The decoder section of the network used cross-attention and masked self-attention, greatly benefiting from the additional attention heads. The main model and most of the variants (except AFCT-3) used the same number of attention heads in the encoder and decoder sections for symmetrical reasons, which we believe may have also helped with the training process. The model that contained only the fully connected layer (AFCT-4) had higher first epoch scores in all the metrics when compared to the other variants. This can be attributed to the fact that the other variants contained extra learnable parameters (courtesy of the Fourier section) that were randomly initialized and still needed to be learned. It still had lower metrics than the proposed model (AFCT) in spite of the fact that it also contained more learnable parameters (FFT linear layers and the self-attention weight matrices). This shows the agility and robustness of the proposed model as, despite containing these extra parameters, AFCT was still able to beat the baseline and variants by capturing fine-grained salient image information right from the start.
One reason why Fourier transforms worked so well on the images is because an image is organized in a grid on which every pixel is related to the pixels around it. This is a phenomenon that can be well exploited by both self-attention and Fourier transforms to produce information-rich image representations. For text, while a word may derive meaning and context from the words around it, more often than not, the prediction of a new word may depend on another word that was output several tokens before, in addition to the words around it. Self-attention, which creates a relevance score of not only the words around it but also of every other word in an input word sequence, has a much higher chance of capturing this dependence than a Fourier transform. We demonstrate this by constructing a variant (AFCT-F5) that not only uses a Fourier transform layer at the encoder but also replaces the decoder masked self-attention with a masked Fourier layer. Early epochs can be deceiving but they do provide a lot of valuable information. It takes a while for the linear layers to start converging, but as the parameters are learned, the performance of this variant also becomes competitive, especially after the commencement of the CIDER-D optimization. It still, however, exhibits the lowest score in every metric and by a wide margin. The only difference between AFCT-5 and AFCT-1 is the masked Fourier layer used in the decoder in place of the masked self-attention. It is evident, as described above, that while FFTs are capable of extracting relevant latent information in images, they perform quite poorly with long-term dependencies which are quite common in textual inputs, in contrast to image inputs which mainly depend on the features around themselves. The associated graphs are shown in
Figure 4 and the scores are presented in
Table 3.
To add to the points above, image-captioning, unlike some other tasks such as object detection and/or classification, requires exploring more fine-grained information because it not only encompasses the latter two but also requires associations and relationships to be detected in the image. This is where a Fourier transform can help by decomposing the feature vectors further to offer the self-attention mechanism more information to use when detecting relationships between each feature and other features for the purpose of determining the degree to which each feature is related to other features, i.e., the relevance of each feature to the others. This has the added advantage of detecting and learning relationships that may have been lost during the transformation from the spatial domain. The mixing of the input tokens, unlike when using convolutional kernels which limit interactions to a neighborhood, provides context for more long-term dependencies, allowing for the model, in some instances, to, e.g., generate a caption that captures more than one object, their colors, associations, and general location. Thus, alongside the intra-attention mechanism, the fast Fourier transformed tokens promote the transfer of salient information.
Another way of looking at the performance of the model and the different variants is to consider what exactly each evaluation metric takes into consideration. As described in
Section 3.3, the different evaluation metrics can help explain different aspects about the captions generated, giving a quantifiable insight into their quality. They are not perfect but they are things that can be measured and comparisons can be made. Considering CIDEr and SPICE metrics correlate best with human evaluators, they are usually considered to be the most important metrics. AFCT-F4, the variant with only fully connected layers, performed quite well in the BLEU scores but its captions are not as detailed as the ones produced by the other models. This is accurately reflected by the lower METEOR, CIDEr, and Spice score it received, which runs in contrast to its good BLEU scores. This shows that the fully connected layer was not able to capture as much fine-grained salient information as the other models that employed a combination of one or both of the Fourier and self-attention layer. In addition, the fully connected variant, based on the captions generated, had the most inconsistent performance. For instance, sometimes it generated very good captions and at other times very poor captions. The captions show a model that can identify the items in the picture but struggles with dependencies, capturing relevance and associations. These are some of the strengths of self-attention layers and, to a lower extent, FFT layers. The higher CIDEr and SPICE scores correlate well with the good captions generated by AFCT and AFCT-F1.
Another major takeaway from this experiment was the fact that even if we were able to mine more of the latent information from the image features, the language model would still be dominant and able to create meaningful sentences even with the least information provided, for example, with the fully connected layer variant. This shows that the information is discriminatory and adequate enough for the decoder language model to make a correct prediction both greedily or through a beam search. This is usually a merit considering as a captioning model, it has to output natural language, but this ability also causes it to hallucinate at times, as can be seen in the sample captions in
Table A1,
Table A2,
Table A3 and
Table A4. Considering for every input there will be a legitimate resulting output probability distribution, the model will always produce a caption no matter its level of confidence. In reality, these guesses are usually right most of the time, but this highlights the limitations of many of the current captioning systems; they are not production-ready. At the level of the current models, if a confidentiality variable is to be introduced, it can only be used to rank sentences, a task that beam search is already doing. If it is used by the model to judge whether or not to output a sentence, a large number of captions for which the model has a low confidence for, but are actually right, will not be output. This is also compounded by the fact that the current evaluation metrics used still do not correlate well enough with human judgment and, in a situation like ours in which we are comparing captions from the variants, fail to notice quality sentences.
In our case, we did not notice any significant decrease in the time required to train a model that uses self-attention when compared to one that used a Fourier transform. This could be attributed to the fact that the decoder section still contains two sets of eight attention head self-attention sub-modules each, while the Fourier transform section also contains linear layers (with weights that need to be learned) after the fast Fourier transform, as shown in Equation (
3). If there is a time difference, it probably only becomes obvious when one replaces all sections with a Fourier transform or when conducted on much larger models. Actually, the AFCT-F4 (fully connected) variant did take about 5% less time to train but this supposed time gain was too short to be independently verified due to the varying GPU and CPU loads on the shared GPU server. The model sizes do vary as expected, with the six-layer AFCT-F2 variant being the biggest one, at twice the size of the smallest one, the AFCT-F4 variant, which only contained the position-wise feed-forward layer in the encoder. That being said, the time required for each epoch varied greatly depending on the complexity and size of the model, and especially concerning the hardware used. While we used the same GPUs, data was stored on different SSDs in order to perform simultaneous tests. During cross-entropy, it required about 40 min to 90 min per epoch, and 3 to 7 h per epoch for Cider optimization, varying largely depending on the complexity or size of the variant.
A lot more can be deduced from and discussed regarding the major and subtle differences between the captions generated by the different variants of the model. This will be left up to the reader to further scrutinize the nuances. The performances of the models, in which the self-attention layer was replaced by either a Fourier or a full connected layer, performed much better than expected and warrants further research. An important question, which is not a subject of this paper’s discussion but that we encountered during our experiments, concerns determining at what point to perform the CIDEr-D optimization. Due to a finite amount of computing power, it is not possible to try all possible combinations but the decision does have a significant impact on the final results obtained. We utilized CIDEr-D optimization and thus used the model with the best validation CIDEr-D score from the cross-entropy training stage as the starting point, another hyperparameter. Regardless, how many cross-entropy epochs that have a non-improving CIDEr-D score should one wait for before making the decision to switch to CIDEr-D optimization? This does add to the difficulty in comparing the various models. One may set it at six, while another may wait for forty epochs. A helpful indicator is whether the validation score is still dropping, but at some point, one will need to make a decision based on some logic, intuition, and experience. This is some food for thought.






{kind=link}
{kind=link}
{kind=link}
{kind=link}





































