We conducted several experiments to verify the efficiency of the proposed accented speech recognition approach. The experimental setup is described first, then the experimental results are reported.
4.1. Experimental Setups
4.1.1. Speech Corpus
In this study, all experiments were conducted using the Common Voice corpus [
19], which is an open-source speech database released by Mozilla in 2019. As this corpus consists of a significant amount of well-refined speech data, it is widely used for various speech recognition tasks [
20]. In particular, this corpus can be effectively utilized in the field of accented speech recognition because speaker information such as age, gender, language, and accent type are provided. The Common Voice corpus has speech data for 60 languages ranging from widely used languages such as English and Spanish to relatively unfamiliar languages such as Basque and Welsh. This study targeted English accents, using speech data from five English accents including US (US accent), AU (Australian accent), CA (Canadian accent), EN (British English (England) accent) and IN (Indian accent). Hereafter, the accent names are denoted by their respective abbreviations for convenience. For domain adaptation, US was determined as the source domain, while the other four accents were regarded as the target domains, because the quantity of US data is much larger than that of other accents. All the speech files were pre-processed for the experiments. The downloaded speech files (.mp3) were converted into wav format and sampled at 16,000 Hz. The files were then divided into the training set (
Table 2), the validation set (
Table 3), and the test set (
Table 4).
There were no duplicated files in these three sets. The training set was used to train the ASR model. The names of the datasets in
Table 2 indicate the accent type and the number of files. For example, AU-20k indicates an Australian accent dataset with 20,000 files. The validation set was used to calibrate the hyperparameters of the ASR model. It played a role in enhancing the credibility of the experimental results. To obtain reliable experimental results, the hyperparameters needed to be calibrated in detail using the validation set. Finally, the ASR model was evaluated using the test set.
4.1.2. Hyperparameters
To obtain the best experimental results, the hyperparameters were calibrated in detail using the validation set. The hyperparameters were heuristically determined by the system developers, whereas the feature parameters were calculated within the model and they can be determined from the data. In deep learning, the representative hyperparameters include the learning rate, epoch, batch size, and dropout rate.
To find the lowest loss
L, the weights
W were updated with a learning rate
η. The weight
in the next time step was updated by subtracting the multiplication of gradient
and
η from the current weight
, as described in (3). The weights were optimized by the Adam optimizer [
21].
Setting an appropriate learning rate is very important, as the learning rate affects variations in the loss value and helps to find the global minimum loss value. After conducting several experiments by calibrating the learning rate, this study determined the most appropriate learning rate to be 0.0001.
Epoch means a count of how often the total training samples have been passed forward and backward through the model. As each epoch proceeds, the loss value is expected to gradually decrease. However, there is a period in which the model does not show any significant improvement. Thus, an appropriate number of epochs needs to be determined when investigating the improvement in performance. This study confirmed that 100 epochs were sufficient to achieve the lowest loss.
Batch size refers to the number of training samples that are sequentially entered into the training stage, and it is generally set to a power of two such as 2, 4, 8, 16, 32, etc. In general, a larger batch size makes the training faster but it requires more memory for calculation. Thus, the batch size should be determined considering the memory capacity of the computer. In this study, the batch size was empirically set to 32. Thus, 32 training samples were in a single batch.
Dropout is a type of regularization technique [
22]. It helps to prevent the overfitting problem, which arises when the network excessively fits into the training data and thus fails to correctly recognize test data. Overfitting problem often occurs when the network has a large capacity and the amount of training data is too small to meet the capacity. Hence, this issue needs to be handled in the accented speech recognition task, where a smaller amount of accented speech data have been provided. Dropout deactivates some neurons (nodes) to reduce the capacity of the network, making the network simpler. This operation is performed according to a dropout rate, which is the ratio of the deactivated nodes to all nodes. In this study, the dropout rate was empirically set to 0.1.
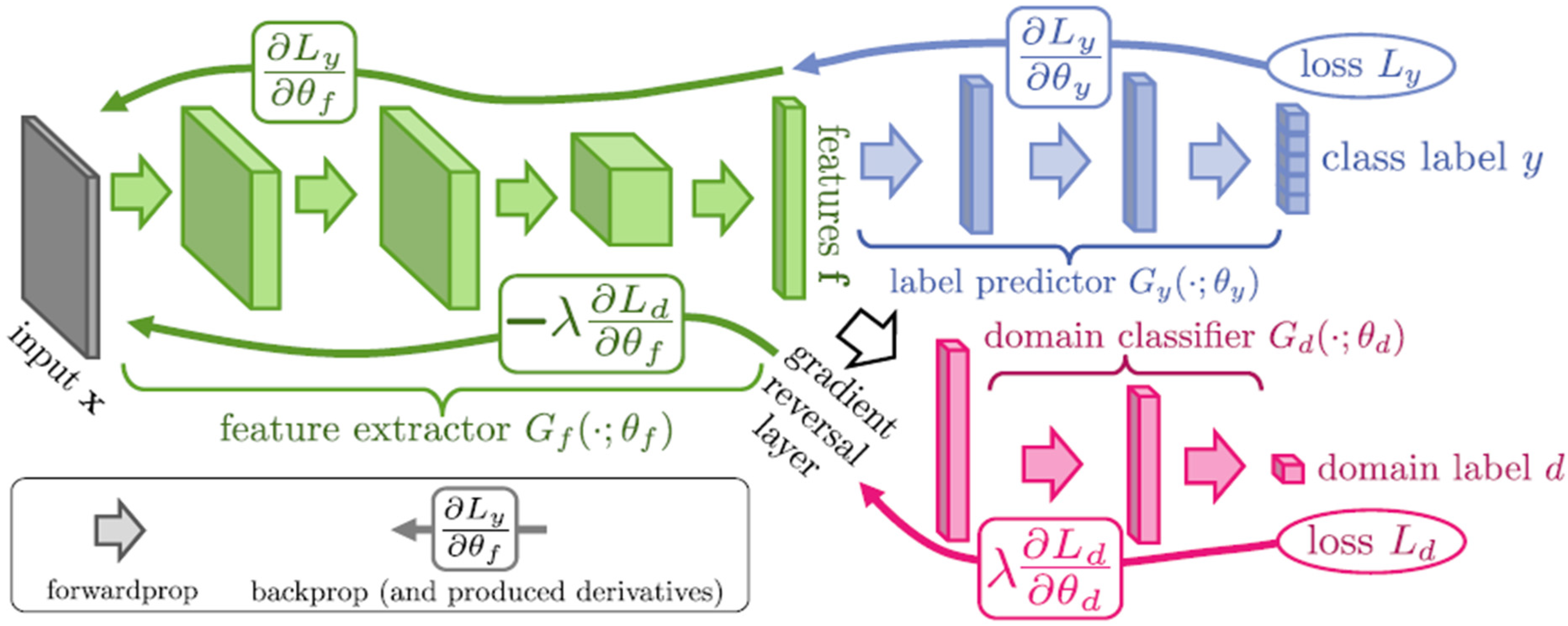
The last hyperparameter in this study was a domain adaptation parameter λ used in DANN. When the gradient of the domain classifier is backpropagated into the downstream of the ASR model, the gradient is multiplied by λ, which can be set between 0 and 1. The parameter controls the influence of domain adversarial training. A higher value makes the effect of the domain adversarial training more dominant. However, an excessive dependence on domain adversarial training may lead to performance degradation. Thus, the parameter should be set precisely via experiments. In this study, λ was empirically set to 0.01.
4.2. Experimental Results
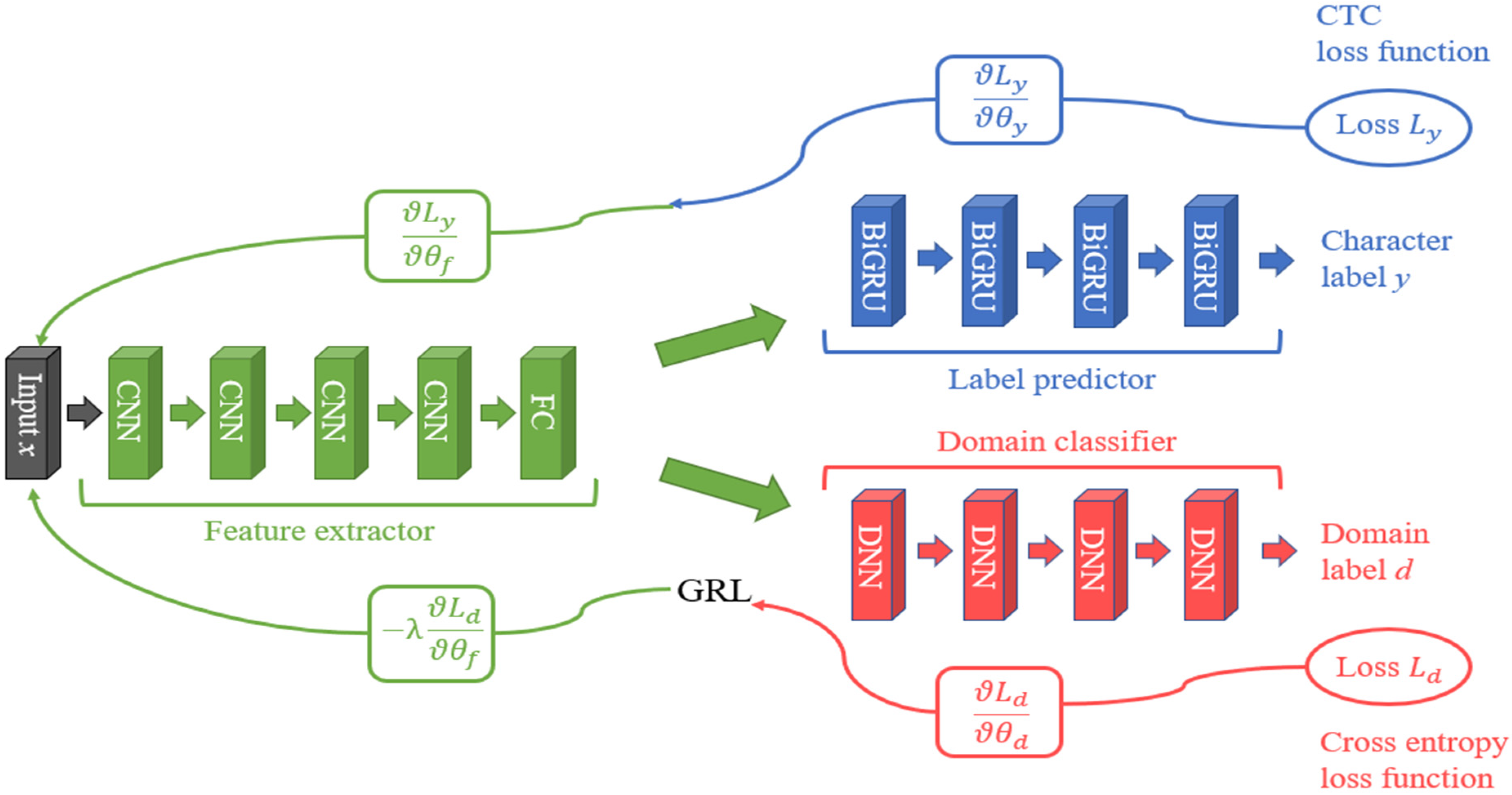
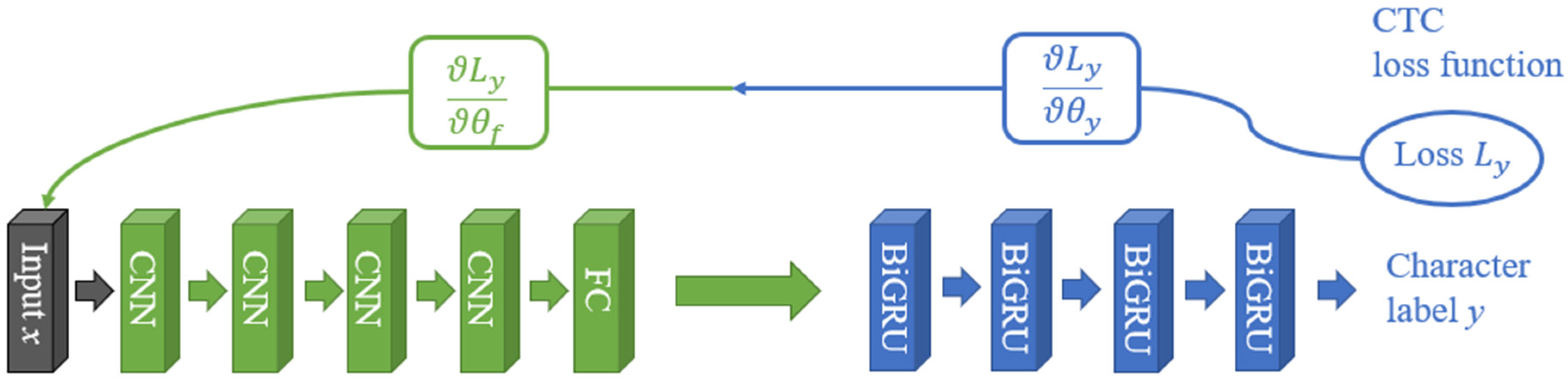
To verify the efficiency of the proposed approach, baseline and DANN models were built. The baseline model performed standard end-to-end speech recognition, and it comprised four CNN and four BiGRU layers, as shown in
Figure 6. The DANN model was constructed according to
Figure 4, illustrated in
Section 3.3.
The performance of the two model types was first investigated. As described in
Table 5, two baseline models were compared with the DANN model. Baseline-src was trained using only the dataset of the source domain (US-160k), whereas baseline-src-tgt was trained using both the datasets of the source domain (US-160k) and each target domain (AU-20k, CA-20k, EN-20k, and IN-20k). DANN was also trained using the same datasets as baseline-src-tgt. The performance of the models was assessed using two measures: the character error rate (CER) and the word error rate (WER), which were measured by the edit distance based on the Levenshtein algorithm [
23] between the predicted labels
and the original labels
.
The results are presented in pairs of CER and WER (CER/WER) in
Table 5. As shown in the table, baseline-src-tgt achieved a better performance than baseline-src for all accents. Although the amount of target domain data was much smaller than that of the source domain data, the model applying the target domain data was effective for recognizing the test data corresponding to the target domain. Moreover, compared with the two baseline model types, DANN achieved significant performance improvements for all accents. In particular, compared with baseline-src-tgt, the proposed DANN approach showed a notable performance for EN and IN accents, with WER reductions of approximately 5% and 3%, respectively. Meanwhile, it had a very slight performance improvement for the CA accent, with a WER reduction of 0.53%. These results indicated that the linguistic differences between the source and target domain accents affected the performance. The source domain accent (US) has linguistically more similar characteristics to CA than the EN and IN accents. As a result, domain adversarial training provides better conditions for recognizing target accents that are linguistically different from the source domain accents.
Although our proposed approach demonstrated superior performance compared with the baseline, it is necessary to examine whether the results are sufficiently meaningful. In particular, the CER and WER are quite high for practical purposes. In general, standard speech recognition systems providing stable performance use vast amounts of training data. The study in [
16], which was based on end-to-end speech recognition, used over 10,000 h of standard speech data to train acoustic models. However, it is a challenge to construct reliable models for different accent types, as it is difficult to collect a sufficient amount of speech data for each target accent. For this reason, most studies have concentrated on finding efficient methods under the conditions of limited amounts of accented speech data. In this study, we used approximately 200 h of source domain data and 25 h of target domain data to train the models.
Nevertheless, it is necessary to compare the performance of our approach with that of conventional studies. We investigated the results given in [
6], in which the accent embedding technique, known as the most representative approach for accented speech recognition, was adopted; the end-to-end method was applied for training acoustic models; and the Common Voice corpus was used for evaluation. We selected the Indian accent for our performance comparison as it was the only target accent for which performance was reported in both studies. In the conventional study, the WER of the Indian accent was 52%, which outperformed our approach (63.56%). However, a direct comparison may not be meaningful, as the two studies conducted experiments on different experimental setups in terms of the training dataset and hyperparameters. For this reason, we concentrated on relative improvements in the baseline system. The baseline performance of the conventional study was 55.2%, providing a relative improvement of 6.15%. On the other hand, our approach achieved a relative improvement of 14.35% compared with the baseline. These results show that our proposed approach improved the baseline system more efficiently with less computational cost compared with the conventional study.
The next experiment was conducted to investigate the effect of the amount of target domain data on performance improvement. The performance was observed when larger amounts of target domain data were applied to the DANN model. The model was called DANN-inc and it was compared with the DANN model (DANN) shown in
Table 5. The Common Voice corpus provides different amounts of speech files according to accents. For a fair evaluation, we balanced the amount of data for different accent types when constructing the DANN-inc model. As a result, the amount of data for each target accent was set to about 40k.
Table 6 summarizes the results. When more target domain data were used to train the DANN model, the model’s performance was significantly improved for most accents. Among the four accent types, the IN accent demonstrated the most significant improvement, with a WER reduction of approximately 3%.
Although
Table 6 shows that the amount of target domain data affected the accuracy of DANN, it is difficult to say that the experiments perfectly observe the tendency, due to the limited amount of data for some accents. The final experiment focused on investigating the effect of the amount of target domain data in detail. This experiment was conducted using only the speech files of EN, which is the accent with the largest amount of target domain data among the four target accents. Five models were constructed, ranging from DANN-EN1 to DANN-EN5, while varying the amount of EN accent data (20k, 40k, 60k, 80k, and 100k for EN1, EN2, EN3, EN4, and EN5, respectively). In all the DANN-EN models, the amount of source domain (US) data was 160k. For example, DANN-EN3 was trained with US-160k and EN-60k data.
Table 7 presents the performance of the five models. As the amount of target domain data increased, the accuracy of accented speech recognition consistently improved. In particular, DANN-EN5 achieved a WER reduction of about 9% in comparison with DANN-EN1. This result shows the possibility that collecting a larger amount of target accent data will improve the performance of accented speech recognition, enhancing the correctness of DANN models.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}