
End-to-End Deep Reinforcement Learning for Image-Based UAV Autonomous Control

Abstract
:1. Introduction
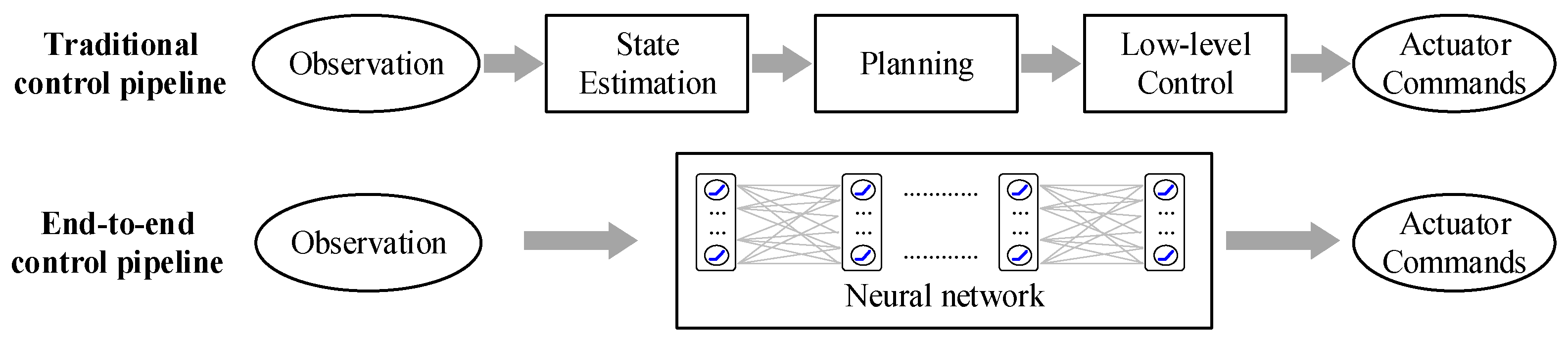
- A new solution based on end-to-end learning for the autonomous control of UAVs is proposed, which simplifies the traditional modularization paradigm by establishing an integrated neural network, directly mapping the image input of the onboard camera onto the low-level control commands of the actuators;
- An image-based reinforcement learning algorithm is implemented with the designed neural network architecture and the reward functions according to the specific scenario;
- The proposed method is validated on the basis of a UAV landing simulation under different cases with ROS and Gazebo. The results show that the end-to-end method allows the UAV to learn to land on the centerline of the runway even with large initial lateral and heading angle offsets.
2. Related Work
3. Preliminaries
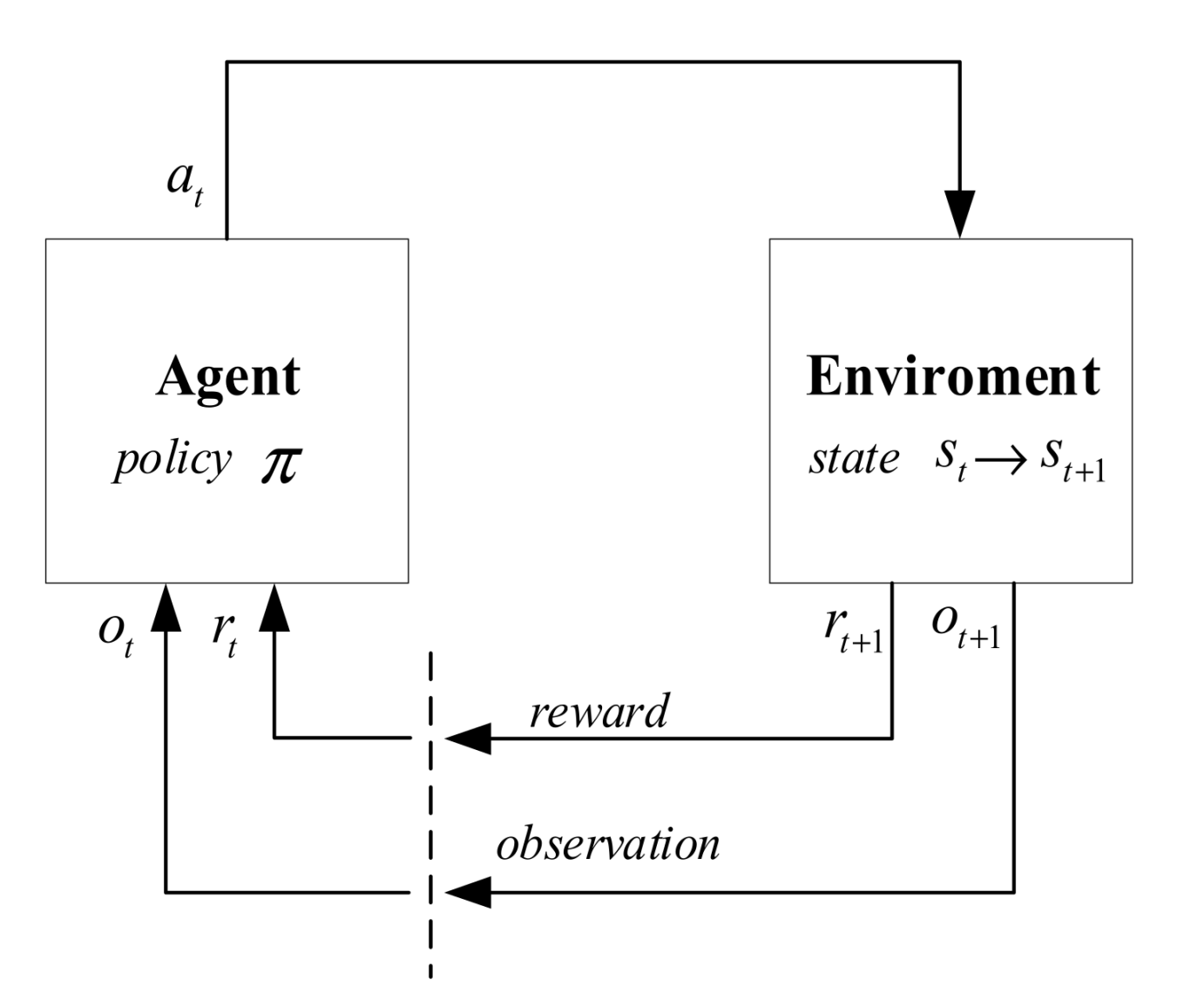
3.1. Reinforcement Learning
3.2. Problem Formulation
4. Proposed Method
4.1. Framework
4.2. Network Architecture
4.3. Reward Function
4.4. Algorithm Implementation
| Algorithm 1: DDPG-based training algorithm |
| 1. Randomly initialize the behavior network ( ); |
| 2. Initialize the target network ( ) by copying the behavior network; |
| 3. Initialize the OU process for action exploration noise; |
| 4. Initialize the replay buffer; |
| 5. For each episode: |
| (1) Reset the UAV with initial states; |
| (2) Receive initial observation of the image state ; |
| (3) For each time step t = 0,1,2……: |
| i. Select action for current observed image according to the current policy and exploration noise; |
| ii. Control the UAV with action and observe reward and observe new image state ; |
| iii. Store the piece of experience () into the replay buffer; |
| iv. Sample a random mini-batch of pieces of experience () from the replay buffer; |
| v. Calculate the TD target using target networks:
|
| vi. Update the behavior value network:
where ; |
| vii. Update the behavior policy network: where ; |
| viii. Update the target networks:
|
| ix. If the terminal condition is satisfied, start a new episode. Or, continue for next time step. The end of a time step; |
| The end of an episode; |
5. Simulation Experiments
5.1. UAV Model
5.2. Environment Setup
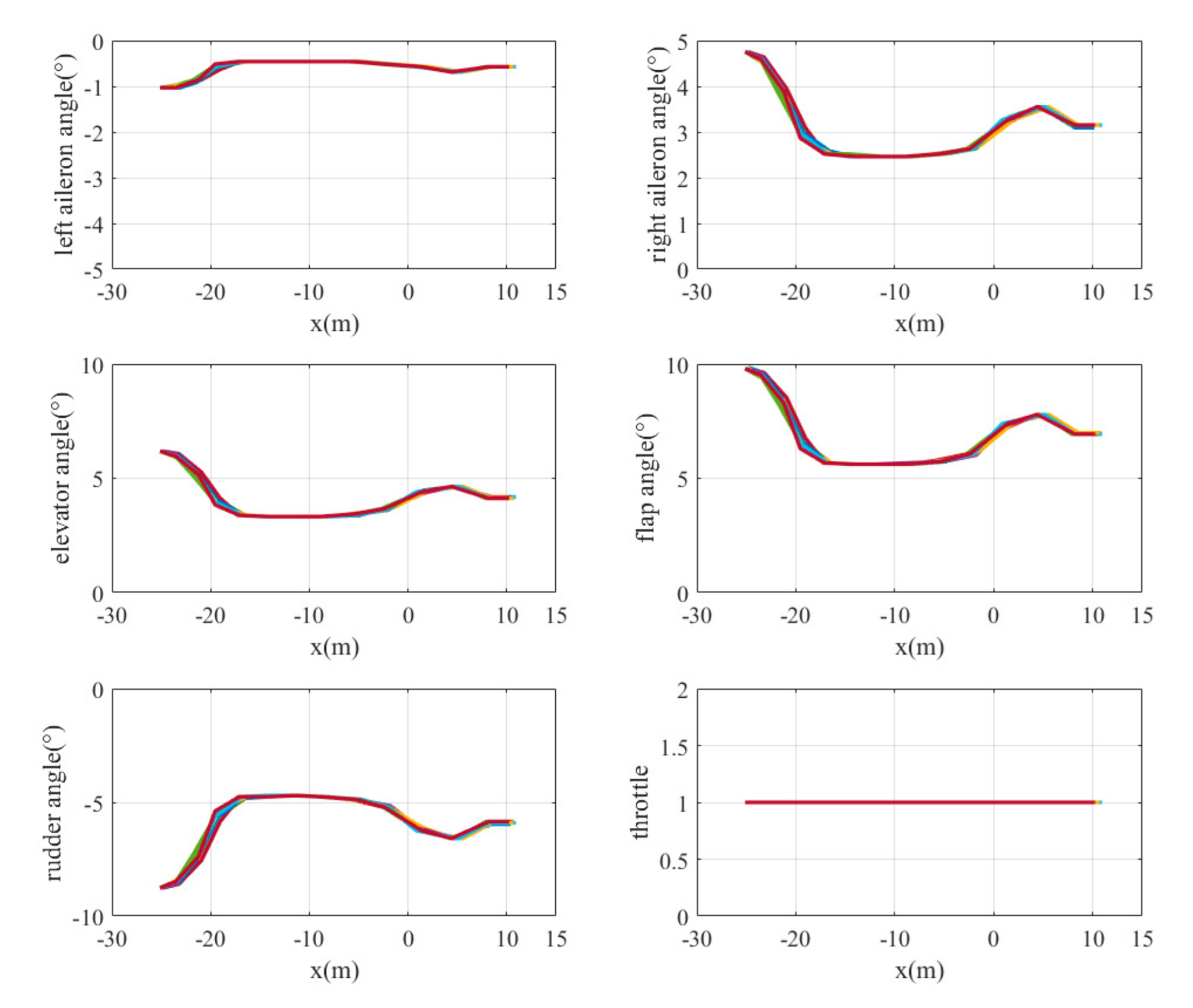
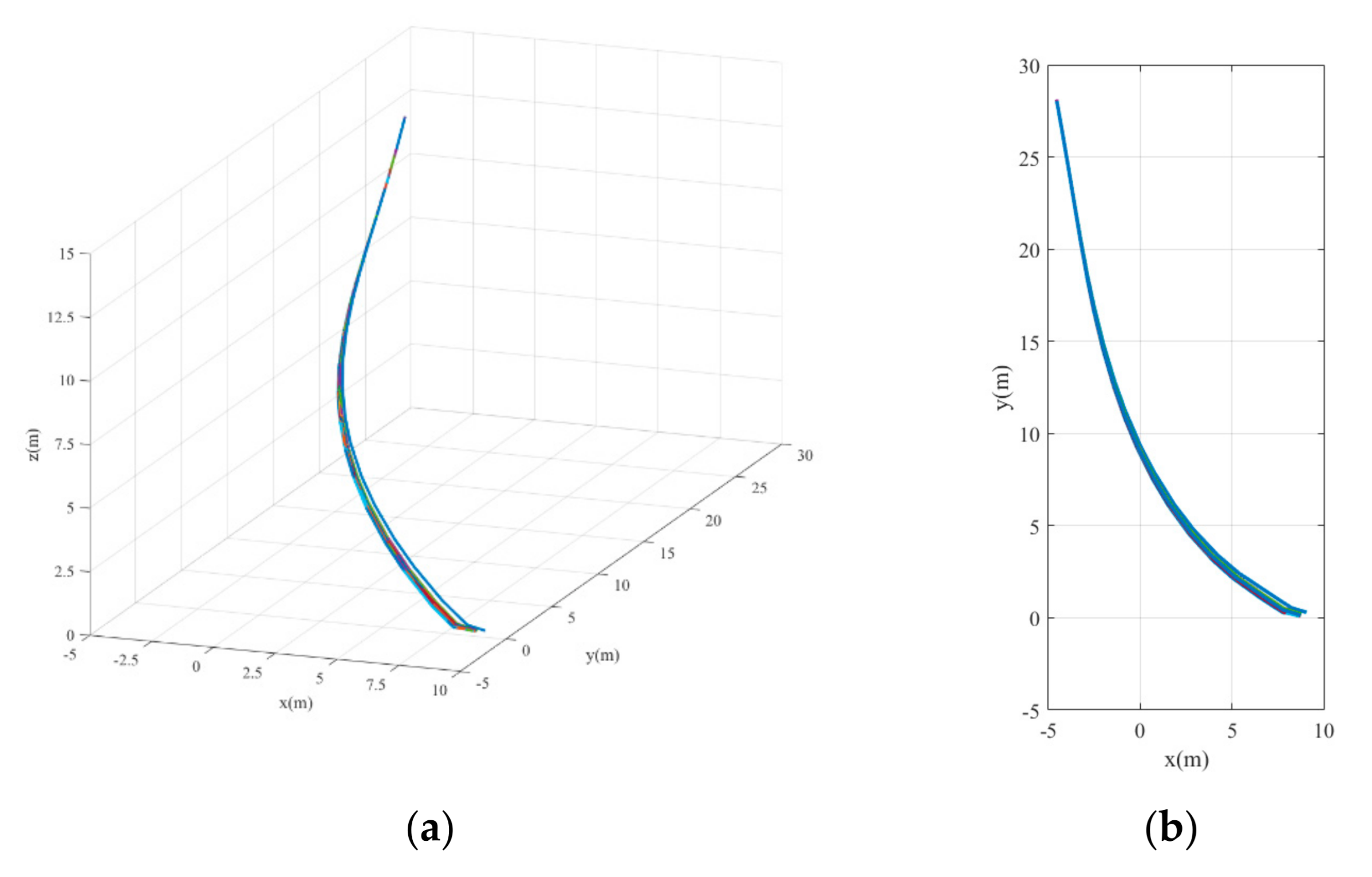
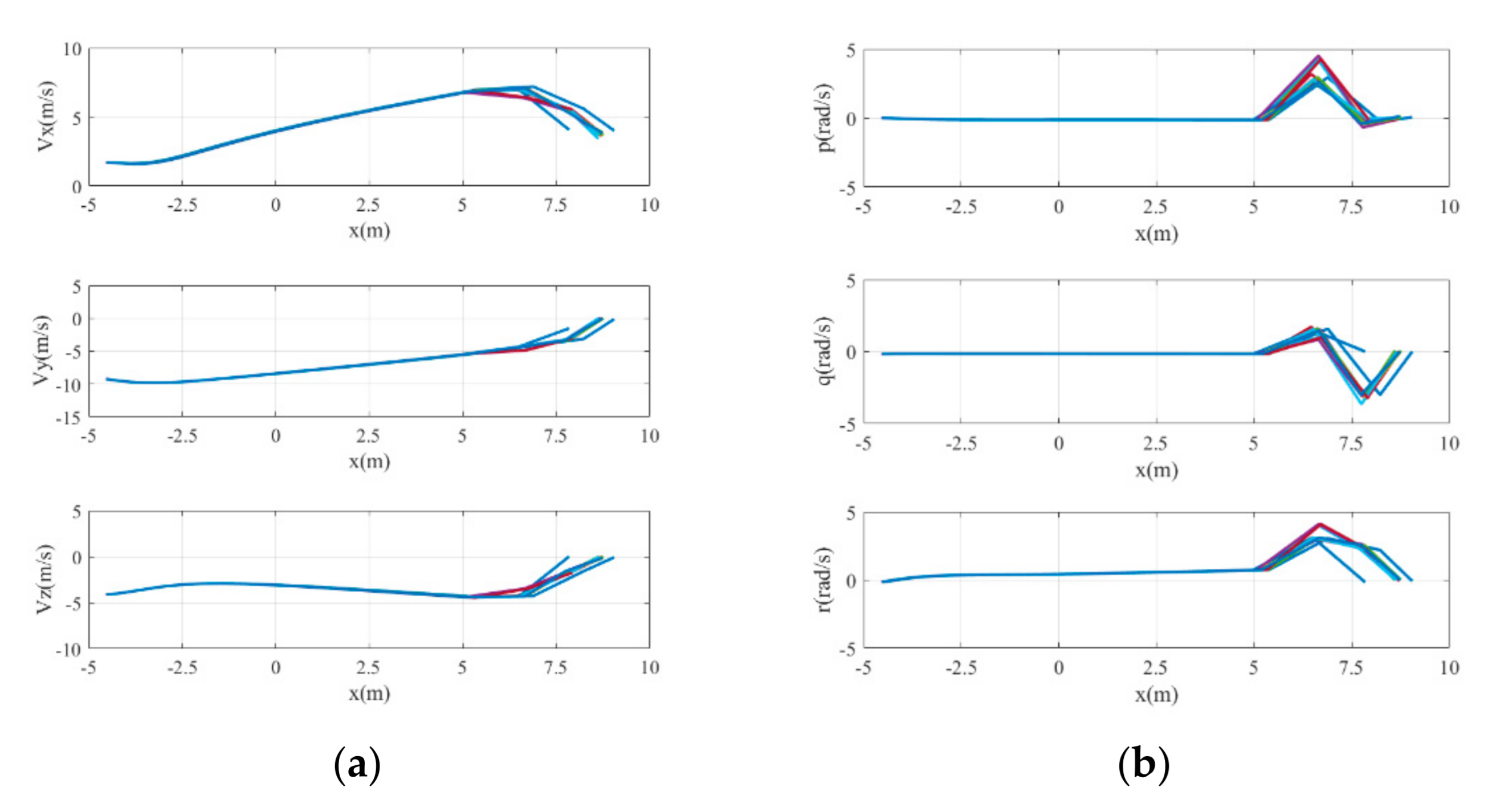
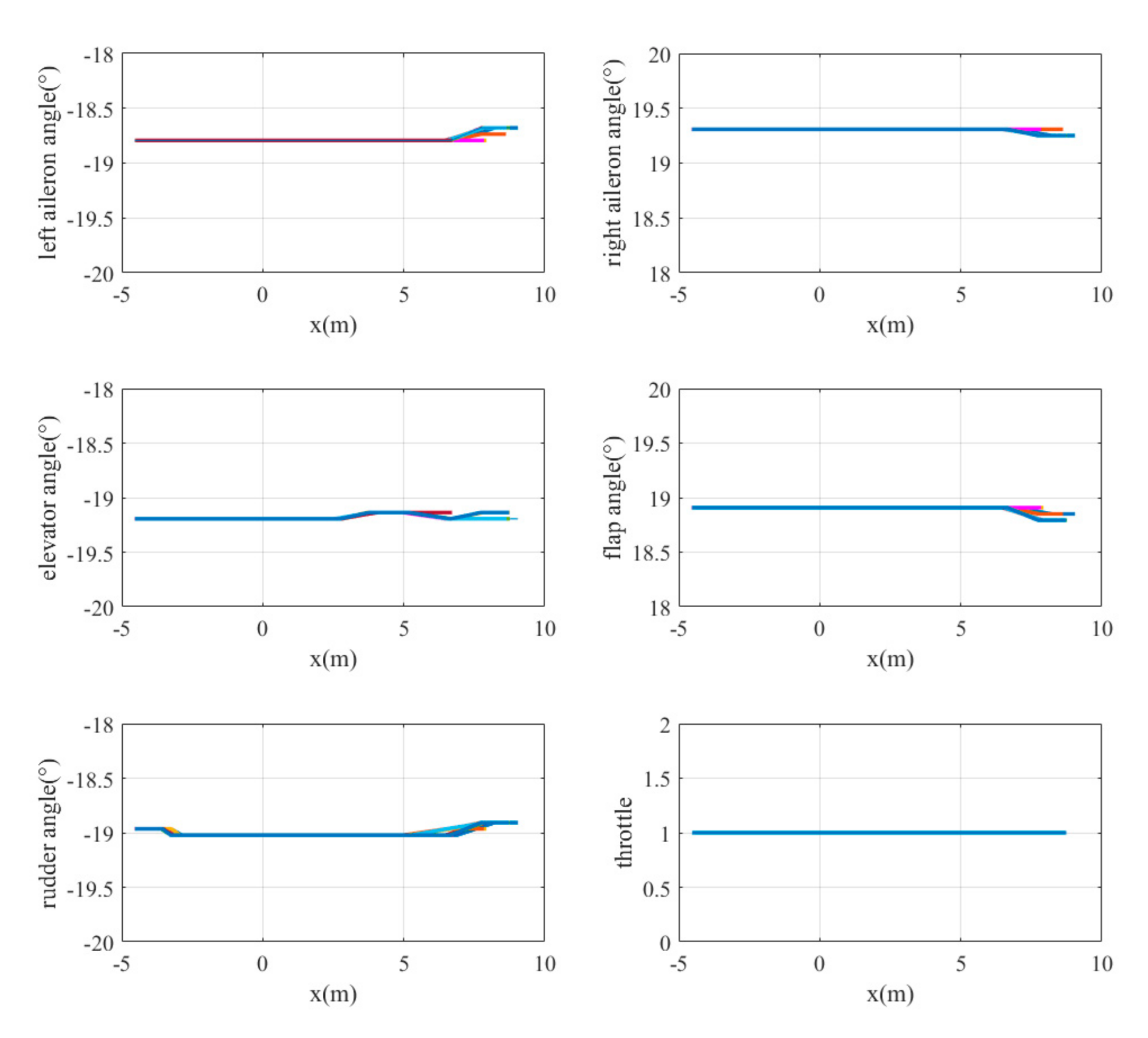
5.3. Simulation Results
- 1.
- UAV starts landing from a point exactly aligned with the center of the runway;
- 2.
- UAV starts landing from a point parallel to the center of the runway with a small lateral offset;
- 3.
- UAV starts landing from a point vertical to the runway with a large lateral offset.
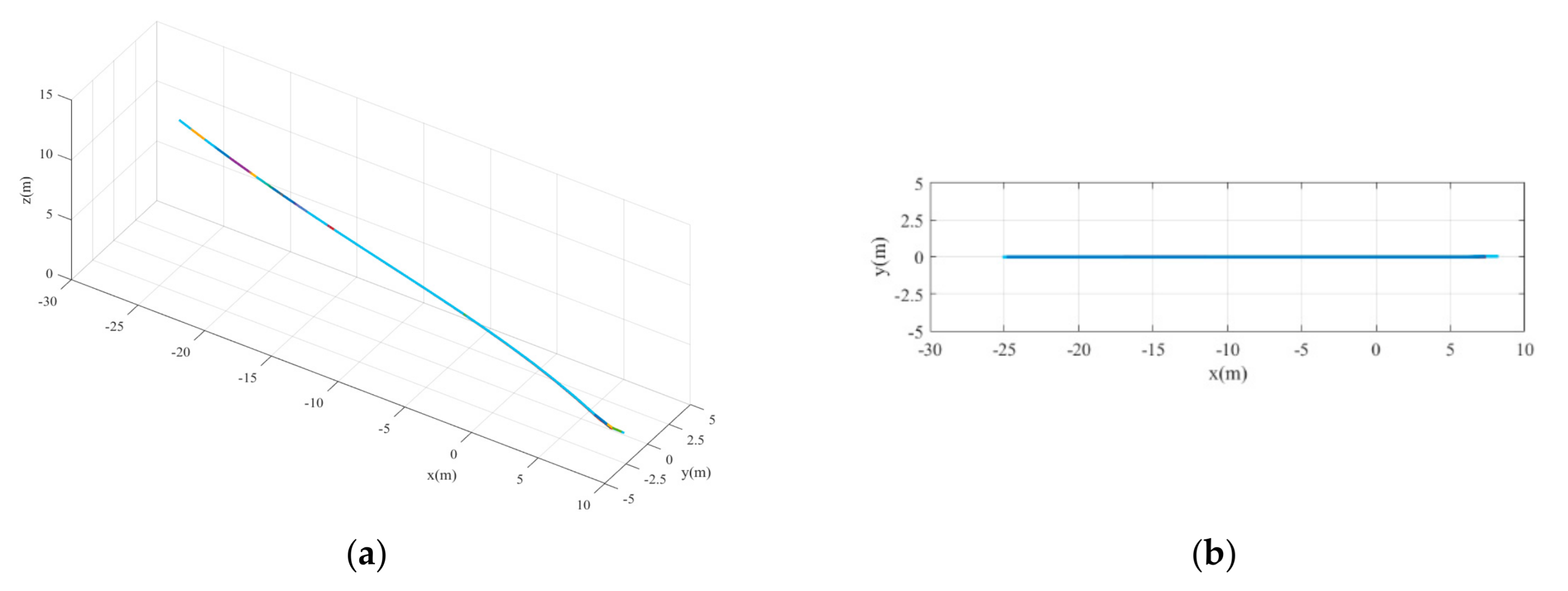
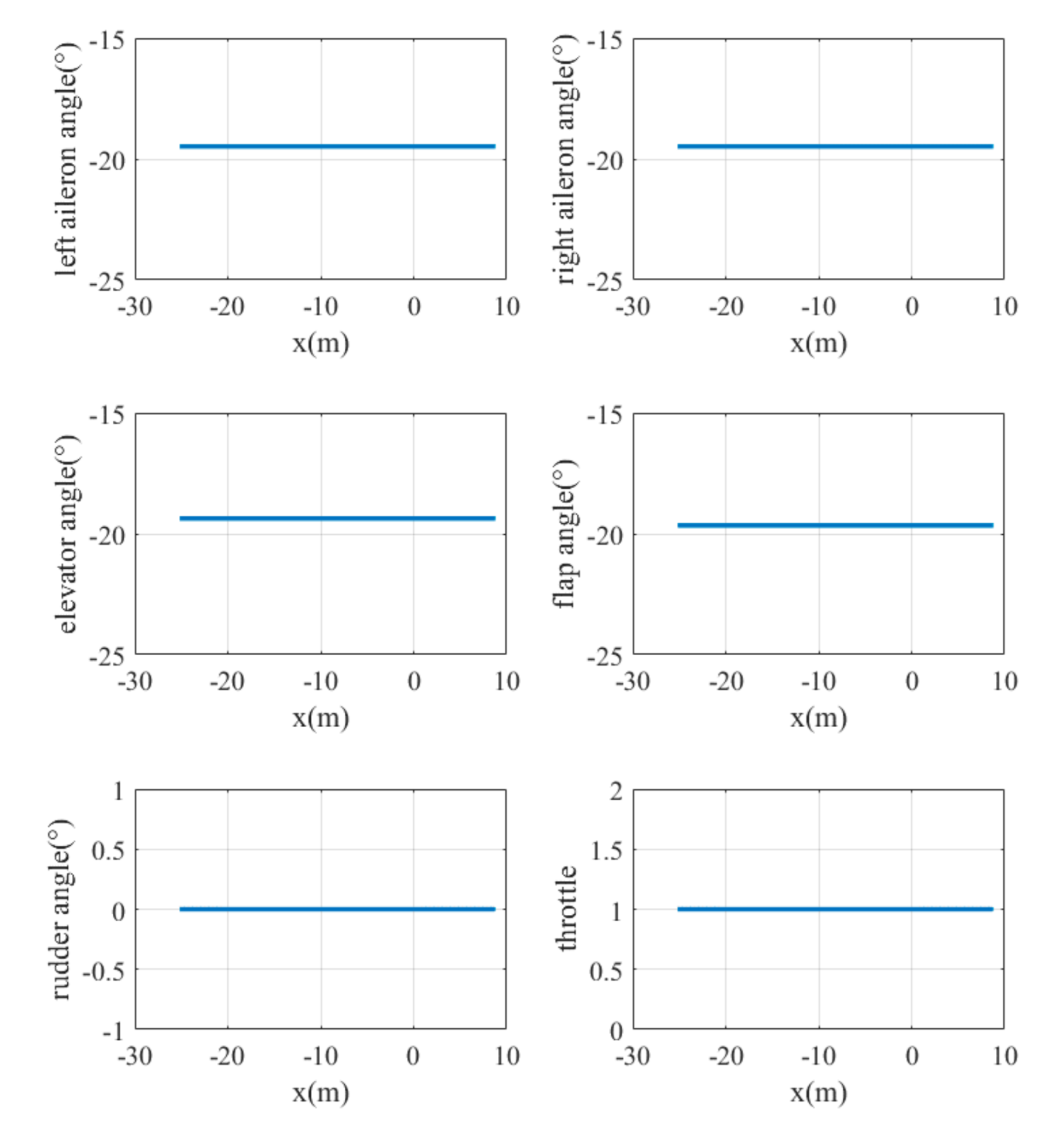
5.3.1. Case 1
5.3.2. Case 2
5.3.3. Case 3
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhen, Z.; Zhu, P.; Xue, Y.; Ji, Y. Distributed intelligent self-organized mission planning of multi-UAV for dynamic targets cooperative search-attack. Chin. J. Aeronaut. 2019, 32, 2706–2716. [Google Scholar] [CrossRef]
- Li, S.; Liu, T.; Zhang, C. Learning unmanned aerial vehicle control for autonomous target following. arXiv 2017, arXiv:1709.08233. [Google Scholar]
- Wang, C.; Wu, L.; Yan, C.; Wang, Z.; Long, H.; Yu, C. Coactive design of explainable agent-based task planning and deep reinforcement learning for human-UAVs teamwork. Chin. J. Aeronaut. 2020, 33, 2930–2945. [Google Scholar] [CrossRef]
- Tang, S.; Kumar, V. Autonomous flight. Annu. Rev. Control Robot. Auton. Syst. 2018, 1, 29–52. [Google Scholar] [CrossRef]
- Lu, Y.; Xue, Z.; Xia, G.-S.; Zhang, L. A survey on vision-based UAV navigation. Geo Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef] [Green Version]
- Gasparetto, A.; Boscariol, P.; Lanzutti, A.; Vidoni, R. Path planning and trajectory planning algorithms: A general overview. Motion Oper. Plan. Robot. Syst. 2015, 29, 3–27. [Google Scholar] [CrossRef]
- Yang, T.; Li, P.; Zhang, H.; Li, J.; Li, Z. Monocular vision SLAM-based UAV autonomous landing in emergencies and unknown environments. Electronics 2018, 7, 73. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Liu, T.; Shen, S. Online generation of collision-free trajectories for quadrotor flight in unknown cluttered environments. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE Press: Piscataway, NJ, USA, 2016; pp. 1476–1483. [Google Scholar]
- Bagnell, J.A.; Bradley, D.; Silver, D.; Silver, D.; Sofman, B.; Stentz, A. Learning for autonomous navigation. IEEE Robot. Autom. 2010, 17, 7–84. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Chrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Li, X.; Chen, Y.; Li, L. End-to-end task-completion neural dialogue systems. arXiv 2017, arXiv:1703.01008. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Perez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–18. [Google Scholar] [CrossRef]
- Guo, T.; Jiang, N.; Li, B.; Zhu, X.; Wang, Y.; Du, W. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chin. J. Aeronaut. 2020, 34, 479–489. [Google Scholar] [CrossRef]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef]
- Xiong, G.; Dong, L. Vision-based autonomous tracking of UAVs based on reinforcement learning. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November2020; IEEE Press: Piscataway, NJ, USA, 2020; pp. 2682–2686. [Google Scholar]
- Sampedro, C.; Rodriguez-Ramos, A.; Gil, I. Image-based visual servoing controller for multirotor aerial robots using deep reinforcement learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE Press: Piscataway, NJ, USA, 2018; pp. 979–986. [Google Scholar]
- Mercado-Ravell, D.A.; Castillo, P.; Lozano, R. Visual detection and tracking with UAVs, following a mobile object. Adv. Robot. 2019, 33, 388–402. [Google Scholar] [CrossRef]
- Kumar, K.S.; Venkatesan, M.; Karuppaswamy, S. Lidar-aided autonomous landing and vision-based taxiing for fixed-wing UAV. J. Indian Soc. Remote. Sens. 2021, 49, 629–640. [Google Scholar] [CrossRef]
- Falanga, D.; Zanchettin, A.; Simovic, A.; Delmerico, J.; Scaramuzza, D. Vision-based autonomous quadrotor landing on a moving platform. In Proceedings of the 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), Shanghai, China, 11–13 October 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 200–207. [Google Scholar]
- Asl, H.J.; Yoon, J. Robust image-based control of the quadrotor unmanned aerial vehicle. Nonlinear Dyn. 2016, 85, 2035–2048. [Google Scholar]
- Shuai, C.; Wang, H.; Zhang, W.; Yao, P.; Qin, Y. Binocular vision perception and obstacle avoidance of visual simulation system for power lines inspection with UAV. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 10480–10485. [Google Scholar]
- Mohta, K.; Kumar, V.; Daniilidis, K. Vision-based control of a quadrotor for perching on lines. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE Press: Piscataway, NJ, USA, 2014; pp. 3130–3136. [Google Scholar]
- Falanga, D.; Mueggler, E.; Faessler, M.; Scaramuzza, D. Aggressive quadrotor flight through narrow gaps with onboard sensing and computing using active vision. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, 2 May–3 June 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 5774–5781. [Google Scholar]
- Mohta, K.; Watterson, M.; Mulgaonkar, Y.; Liu, S.; Qu, C.; Makineni, A.; Saulnier, K.; Sun, K.; Zhu, A.; Delmerico, J.; et al. Fast, autonomous flight in GPS-denied and cluttered environments. J. Field Robot. 2017, 35, 101–120. [Google Scholar] [CrossRef]
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W.; Yang, Z.; Shen, S. Autonomous aerial navigation using monocular visual-inertial fusion. J. Field Robot. 2017, 35, 23–51. [Google Scholar] [CrossRef]
- Schmid, K.; Lutz, P.; Tomić, T.; Mair, E.; Hirschmüller, H. Autonomous vision-based micro air vehicle for indoor and outdoor navigation. J. Field Robot. 2014, 31, 537–570. [Google Scholar] [CrossRef]
- Basso, M.; de Freitas, E.P. A UAV Guidance system using crop row detection and line follower algorithms. J. Intell. Robot. Syst. 2019, 97, 605–621. [Google Scholar] [CrossRef]
- Ross, S.; Melik-Barkhudarov, N.; Shankar, K.S.; Wendel, A.; Dey, D.; Bagnell, J.A. Learning monocular reactive UAV control in cluttered natural environments. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; IEEE Press: Piscataway, NJ, USA, 2013; pp. 1765–1772. [Google Scholar]
- Loquercio, A.; Maqueda, A.I.; del-Blanco, C.R.; Scaramuzza, D. DroNet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case 1 | Exactly aligned with the centerline of the runway |
| Case 2 | Parallel to the centerline of the runway with a small lateral offset |
| Case 3 | Vertical to the runway with a large lateral offset |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Sun, J.; Cai, Z.; Wang, L.; Wang, Y. End-to-End Deep Reinforcement Learning for Image-Based UAV Autonomous Control. Appl. Sci. 2021, 11, 8419. https://doi.org/10.3390/app11188419
Zhao J, Sun J, Cai Z, Wang L, Wang Y. End-to-End Deep Reinforcement Learning for Image-Based UAV Autonomous Control. Applied Sciences. 2021; 11(18):8419. https://doi.org/10.3390/app11188419
Chicago/Turabian StyleZhao, Jiang, Jiaming Sun, Zhihao Cai, Longhong Wang, and Yingxun Wang. 2021. "End-to-End Deep Reinforcement Learning for Image-Based UAV Autonomous Control" Applied Sciences 11, no. 18: 8419. https://doi.org/10.3390/app11188419
APA StyleZhao, J., Sun, J., Cai, Z., Wang, L., & Wang, Y. (2021). End-to-End Deep Reinforcement Learning for Image-Based UAV Autonomous Control. Applied Sciences, 11(18), 8419. https://doi.org/10.3390/app11188419