
Image Splicing Location Based on Illumination Maps and Cluster Region Proposal Network


Abstract
:1. Introduction
- (1)
- The illumination maps are applied in the illumination stream to extract inconsistent lighting color features, which can prove the effectiveness of the illumination maps.
- (2)
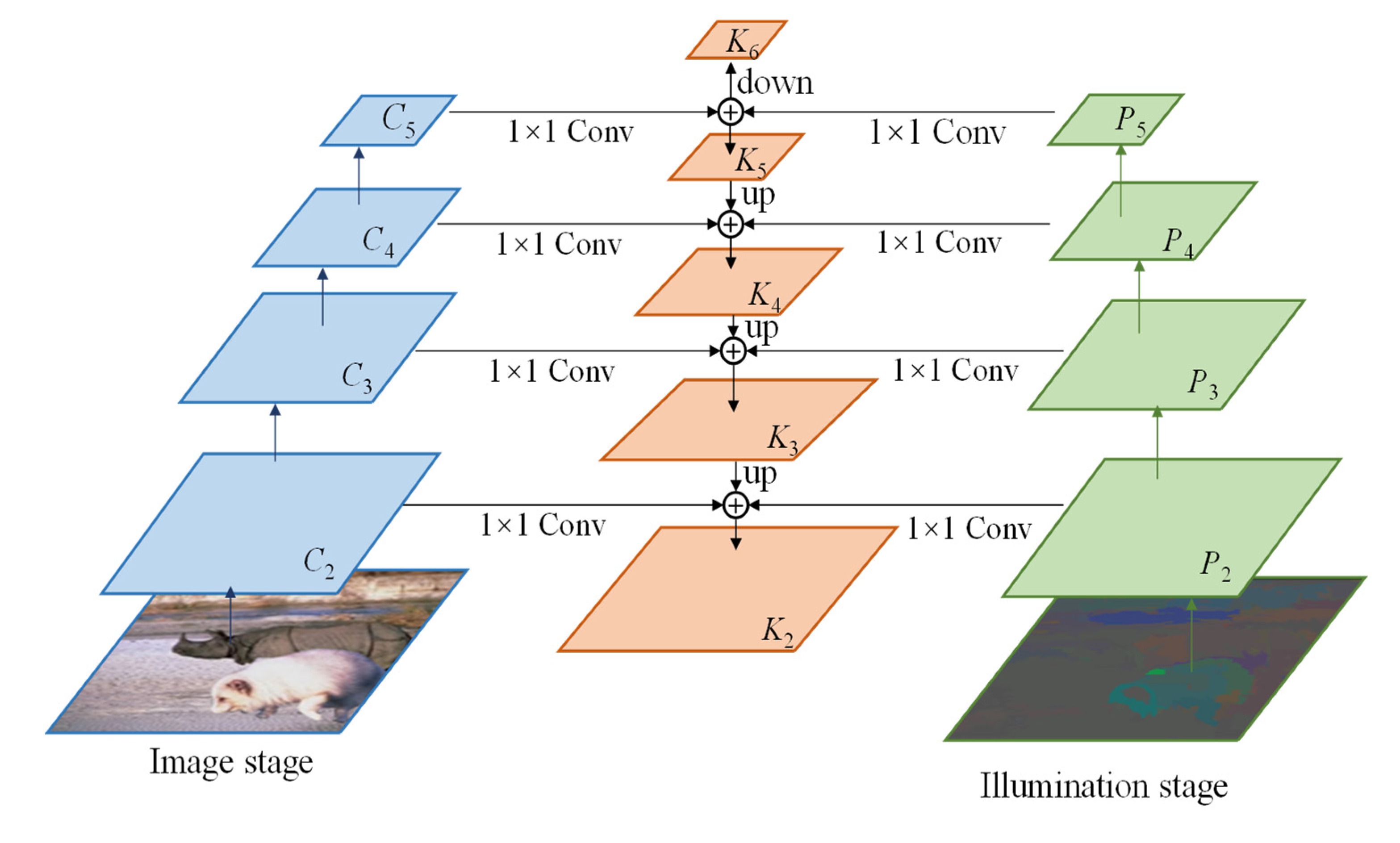
- A Multiple Feature Pyramid Network (MFPN) is proposed for deep multi-scale dual-stream features fusion, which provides sufficient tampered features for the tampered region proposal.
- (3)
- Cluster Region Proposal Network (C-RPN) is proposed, where the spatial attention mechanism retains more position information, and clusters adaptively selects the anchor size.
2. Related Works
3. The Proposed Framework
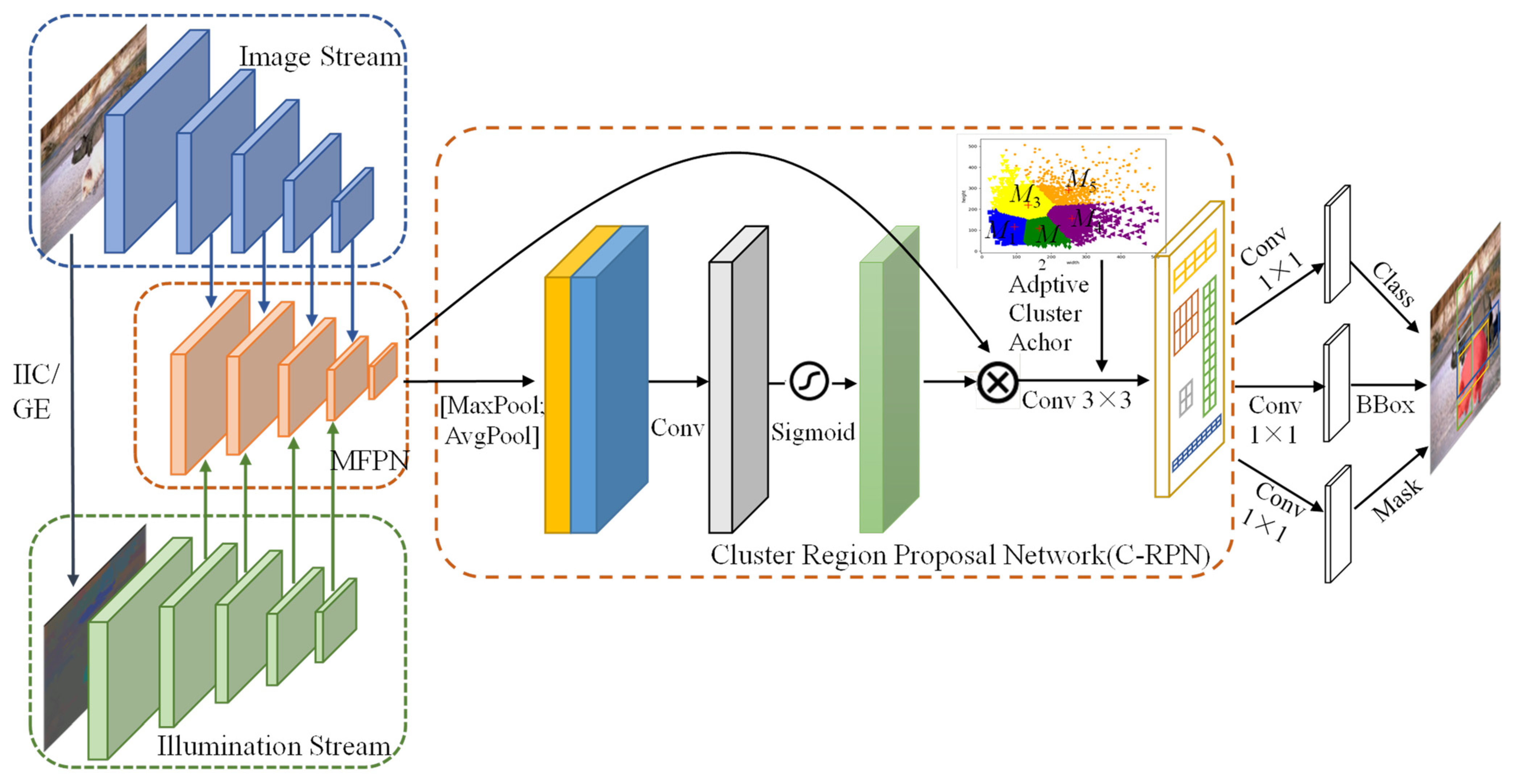
3.1. The Dual-Stream Framework
3.1.1. Illumination Maps
3.1.2. The Image and Illumination Stream
3.2. The Dual-Stream Framework
3.3. Cluster Region Proposal Network (C-RPN)
3.4. Training Loss
4. Discussion
4.1. Datasets and Evaluation Metrics
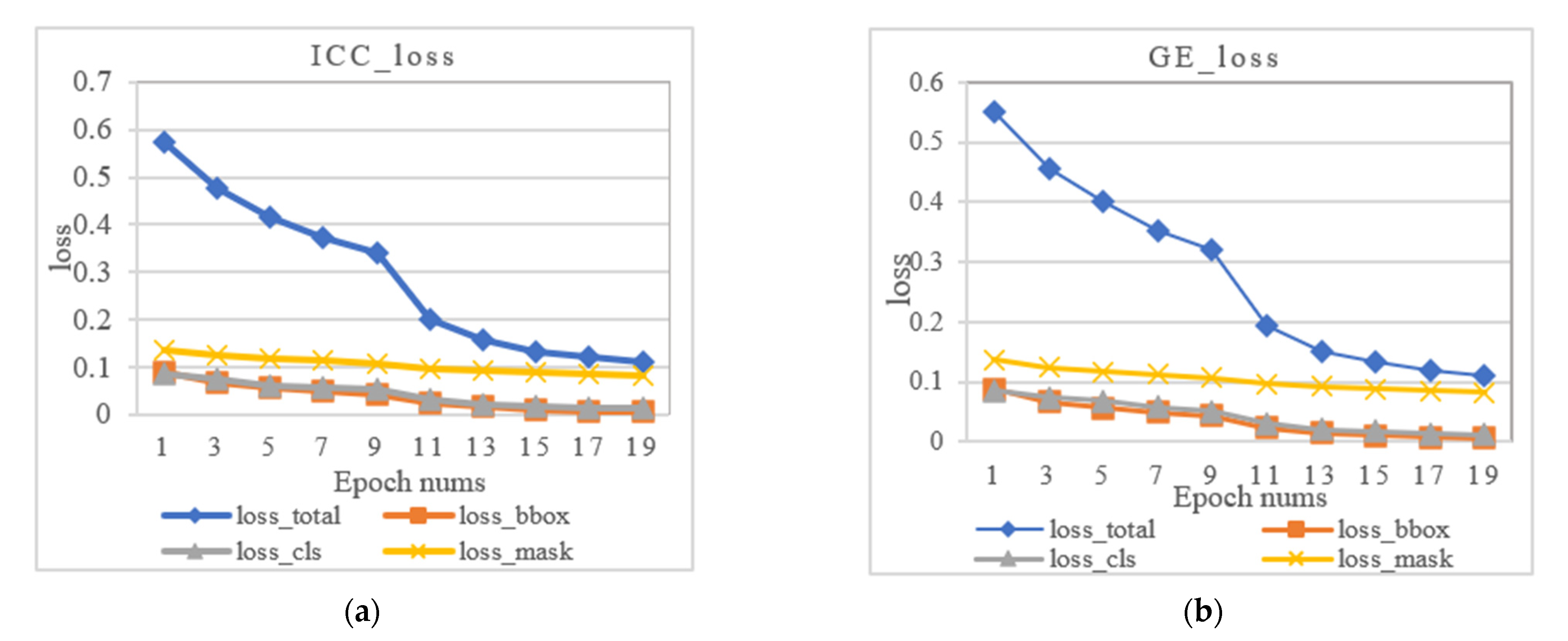
4.2. Training Setting
4.3. Experiments and Comparative Analysis
4.3.1. Ablation Experiments
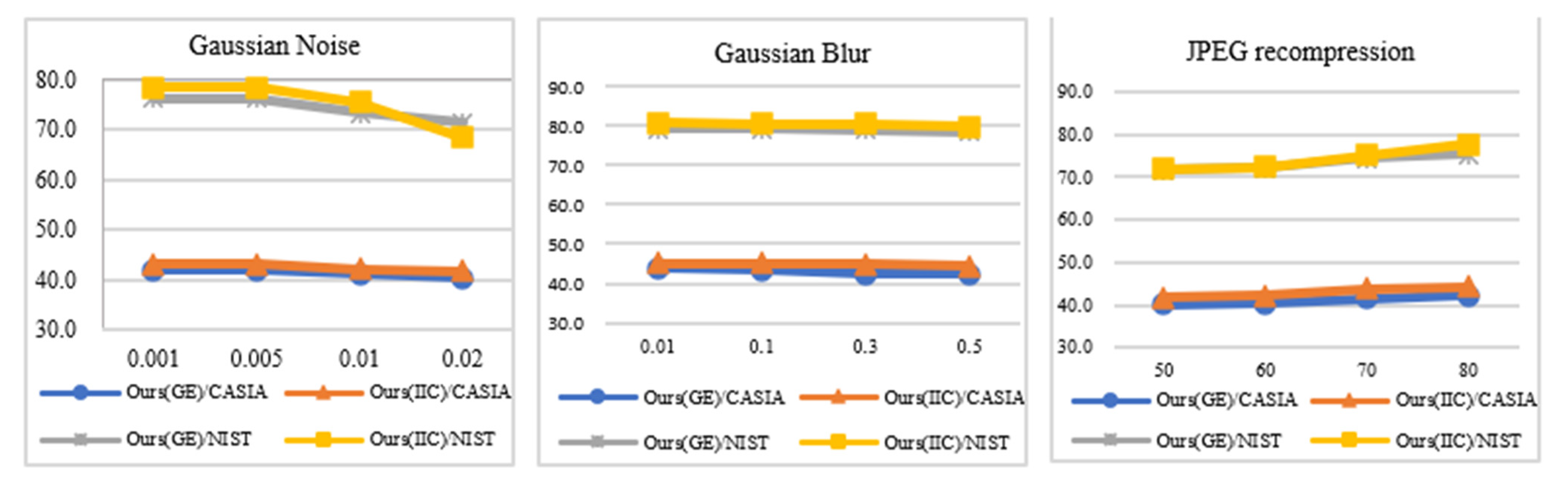
4.3.2. Robustness Analysis
4.4. Experiments and Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image Forgery Localization via Fine-Grained Analysis of CFA Artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Krawetz, N.; Solutions, H.F. A pictures worth. Hacker Factor Solut. 2007, 6, 1–31. [Google Scholar]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Youseph, S.N.; Cherian, R.R. Pixel and edge based illuminant color estimation for image forgery detection. Procedia Comput. Sci. 2015, 46, 1635–1642. [Google Scholar] [CrossRef] [Green Version]
- Kee, E.; Farid, H. Exposing digital forgeries from 3-D lighting environments. In Proceedings of the 2010 IEEE International Workshop Information Forensics and Security, Seattle, WA, USA, 12–15 December 2010; pp. 1–6. [Google Scholar]
- Francis, K.; Gholap, S.; Bora, P.K. Illuminant colour based image forensics using mismatch in human skin highlights. In Proceedings of the 2014 International Conference on Communications, Kanpur, India, 28 February–2 March 2014; pp. 1–6. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V. Image region forgery detection: A deep learning approach. SG-CRC 2016, 2016, 1–11. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 International Workshop on Information Forensics and Security, AbuDhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Bondi, L.; Lameri, S.; Guera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. Tampering detection and localization through clustering of camera-based CNN features. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1855–1864. [Google Scholar]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Deep matching and validation network: An end-to-end solution to constrained image splicing localization and detection. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1480–1502. [Google Scholar]
- Liu, Y.; Zhu, X.; Zhao, X.; Cao, Y. Adversarial Learning for Constrained Image Splicing Detection and Localization Based on Atrous Convolution. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2551–2566. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, X. Constrained Image Splicing Detection and Localization with Attention-Aware Encoder-Decoder and Atrous Convolution. IEEE Access 2020, 8, 6729–6741. [Google Scholar] [CrossRef]
- Jaiswal, A.K.; Srivastava, R. A technique for image splicing detection using hybrid feature set. Multimedia Tools Appl. 2020, 79, 11837–11860. [Google Scholar] [CrossRef]
- Bi, X.; Wei, Y.; Xiao, B.; Li, W. Rru-net: The ringed residual u-net for image splicing forgery detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1–10. [Google Scholar]
- Xiao, B.; Wei, Y.; Bi, X.; Li, W.; Ma, J. Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering. Inf. Sci. 2020, 511, 172–191. [Google Scholar] [CrossRef]
- Ahmed, B.; Gulliver, T.A.; Alzahir, S. Image splicing detection using mask-RCNN. Signal Image Video Process. 2020, 14, 1035–1042. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial Pyramid Attention Network for Image Manipulation Localization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 312–328. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image R. 2018, 51, 201–209. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Shen, X.; Kang, H.; Lv, Y. Image Manipulation Detection and Localization Based on the Dual-Domain Convolutional Neural Networks. IEEE Access 2018, 6, 76437–76453. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning rich features for image manipulation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1053–1061. [Google Scholar]
- Wu, Y.; Abd Almageed, W.; Natarajan, P. ManTra-net: Manipulation tracing net-work for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9543–9552. [Google Scholar]
- Mazaheri, G.; Mithun, N.C.; Bappy, J.H.; Roy-Chowdhury, A.K. A skip connection architecture for localization of image manipulations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 119–129. [Google Scholar]
- Bappy, J.H.; Simons, C.; Nataraj, L.; Manjunath, B.S.; Roy-Chowdhury, A.K. Hybrid LSTM and Encoder–Decoder Architecture for Detection of Image Forgeries. IEEE Trans. Image Process. 2019, 28, 3286–3300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riess, C.; Angelopoulou, E. Scene illumination as an indicator of image manipulation. In Proceedings of the International Workshop on Information Hiding, Calgary, AB, Canada, 28–30 June 2010; pp. 66–80. [Google Scholar]
- Carvalho, T.; Faria, F.A.; Pedrini, H.; Torres, R.D.S.; Rocha, A. Illuminant-Based Transformed Spaces for Image Forensics. IEEE Trans. Inf. Forensics Secur. 2015, 11, 720–733. [Google Scholar] [CrossRef]
- Pomari, T.; Ruppert, G.; Rezende, E.; Rocha, A.; Carvalho, T. Image splicing detection through illumination inconsistencies and deep learning. In Proceedings of the 2018 IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 3788–3792. [Google Scholar]
- Mazumdar, A.; Bora, P.K. Deep learning-based classification of illumination maps for exposing face splicing forgeries in images. In Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 116–120. [Google Scholar]
- Van De Weijer, J.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. 2007, 16, 2207–2214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, R.T.; Nishino, K.; Ikeuchi, K. Color constancy through inverse-intensity chromaticity space. J. Opt. Soc. Am. A 2004, 21, 321–334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Nist Nimble 2016 Datasets. Available online: https://www.nist.gov/itl/iad/mig/nimble-challenge-2017-evaluation/ (accessed on 10 September 2020).
- Dong, J.; Wang, W.; Tan, T. Casia image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 June 2013; pp. 422–426. [Google Scholar]
- Lin, T.; Maire, M.; Belonge, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Tampered Images | Most Image Size | Number of Train and Test |
|---|---|---|---|
| Synthesized | 11k | 512 × 512 | Train: 10k Test: 1k |
| NIST16 | 564 | 384 × 256 | Train: 404 Test: 160 |
| CASIA1.0 and 2.0 | 6044 | 384 × 256 | Train: 5123 Test: 921 |
| Synthetic Dataset | AP |
|---|---|
| GE stream | 81.7 |
| IIC stream | 82.1 |
| Image stream | 87.2 |
| Dual-stream(GE + Image) | 89.1 |
| Dual-stream(IIC + Image) | 89.8 |
| Ours (GE) | 92.9 |
| Ours (IIC) | 93.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Shen, X.; Liu, S.; Zhang, X.; Yan, G. Image Splicing Location Based on Illumination Maps and Cluster Region Proposal Network. Appl. Sci. 2021, 11, 8437. https://doi.org/10.3390/app11188437
Zhu Y, Shen X, Liu S, Zhang X, Yan G. Image Splicing Location Based on Illumination Maps and Cluster Region Proposal Network. Applied Sciences. 2021; 11(18):8437. https://doi.org/10.3390/app11188437
Chicago/Turabian StyleZhu, Ye, Xiaoqian Shen, Shikun Liu, Xiaoli Zhang, and Gang Yan. 2021. "Image Splicing Location Based on Illumination Maps and Cluster Region Proposal Network" Applied Sciences 11, no. 18: 8437. https://doi.org/10.3390/app11188437
APA StyleZhu, Y., Shen, X., Liu, S., Zhang, X., & Yan, G. (2021). Image Splicing Location Based on Illumination Maps and Cluster Region Proposal Network. Applied Sciences, 11(18), 8437. https://doi.org/10.3390/app11188437