2.1. Risk Management and Resilience Concepts Transferred to Manufaturing Systems
Risk management as a measure and business discipline is typically known as corporate risk management, which focuses on accounting and financial reporting (see, e.g., [
5]) or as a relevant step in project management processes (see, e.g., [
6]). In order to evaluate risk probabilities and their impacts, the identification and classification of risks are inevitable. In a survey by Fries et al. [
7], ten major challenges on future production systems were identified that can be subsumed into complexity (of supply networks and products as well as processes), changing customer behavior and expectations, market changes (globalization, volatility and increased competition) as well as impacts caused by politics, natural disasters, and unstable economics.
With reference to the aforementioned risk management, a structuring of risk categories is required. Various descriptions of system structure and meta-level representations have been developed in the context of factories (see, e.g., [
8,
9]).
A possible corresponding classification of risks refers to the depicted internal and external flows of production systems. Thus, we propose the separation of risks into the categories described in
Table 1.
In industrial practice, enterprises are possibly confronted with combined threats of several risk categories. In addition to that, it should be highlighted that each of these risk categories is translated into an economic evaluation, as corporate decision-making ultimately depends on monetary performance metrics. Thus, each risk category requires translation into specific cause–effect relationships in order to operationalize risk assessment and to elaborate measures. Moreover, the effect of one risk may even express itself in further categories. Conversely, causes may be relevant in several risk categories. Furthermore, the risk effects can be separated according to their time-related behavior. According to this,
Table 1 illustrates a typical specification of risks.
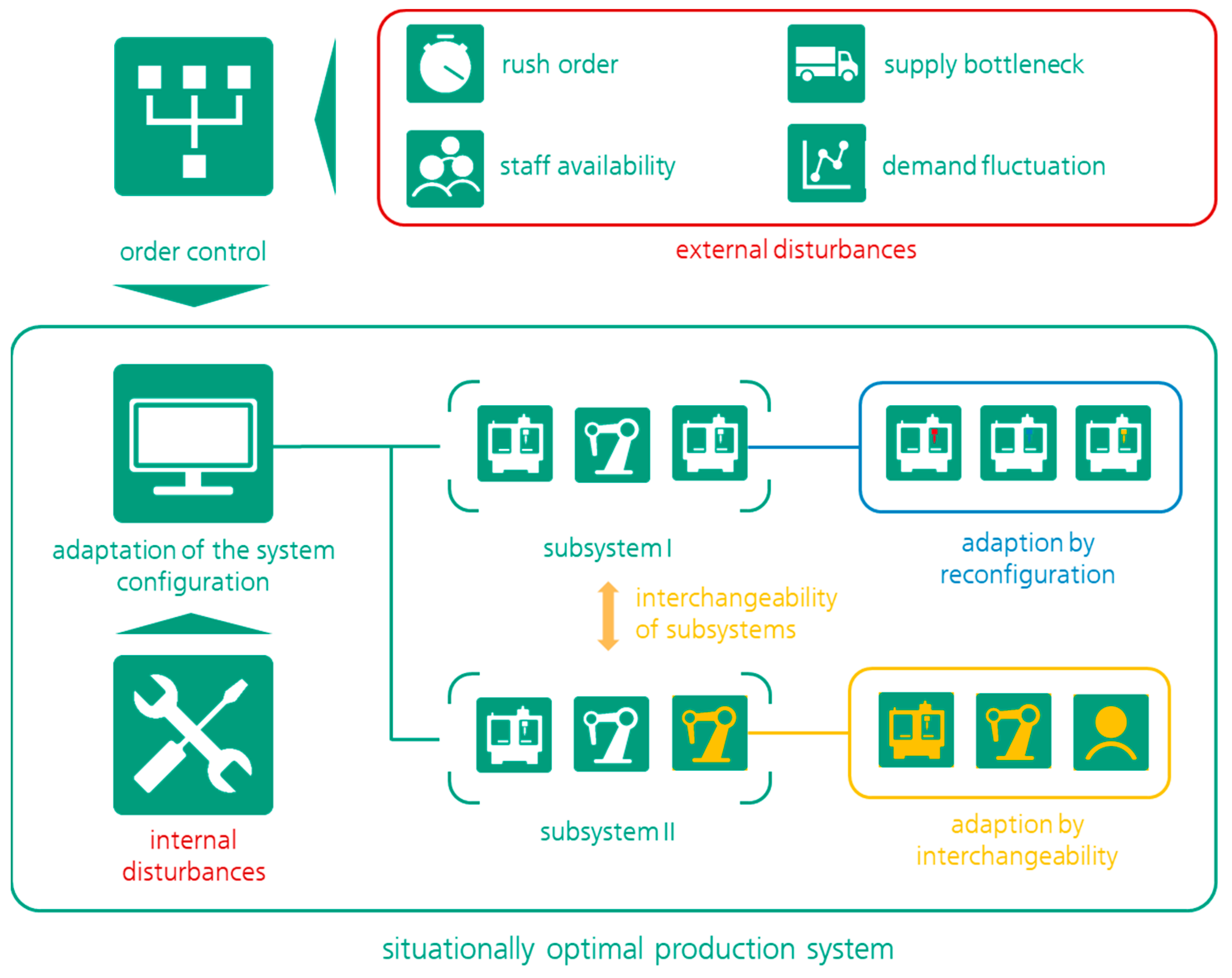
With regard to production systems, these risks may cause external and internal turbulence, increasing the necessity of short adaption and transformation times. This leads to the necessity of flexibility and the quick configurability of elements and processes in manufacturing facilities. From a system-based point of view, an overall production system may be divided into several subsystems of interchangeable and reconfigurable components based on standardized interfaces and a modular structure.
Figure 1 depicts this system concept as a framework to anticipate as well as to mitigate risk impacts and to generate a common understanding of subsequent sections.
Resilience as a feature of systems covers multiple aspects and dimensions related to the prevention and mitigation of risks. A conceptual distinction between “engineering resilience” (“efficiency of function”) and “ecosystem resilience” (“existence of function”) is traced back to Holling (1996) [
10]. The first represents stability in the sense of efficiency, continuity, and predictability in order to generate fail-safe (technical) designs and to always remain close to a targeted state of equilibrium as a given measured variable. In contrast to this, the second form describes resilience as persistence, change, and unpredictability, in which a system can flexibly adapt to new conditions. In this case, resilience is measured by the amount/extent of disturbance that can be absorbed prior to system change. Hence, ecosystem resilience often refers to the assessment of complex social and ecologic systems.
Fischer et al. (2018) [
11] mention that resilience as a term is used in many variations, depending on the scientific area. With a focus on urban environments and systems they developed a mathematical resilience framework for evaluating and comparing different prevention and reaction strategies for hazardous situations on a quantitative basis. The derived resilience cycle comprises the phases prepare, prevent, protect, respond, and recover and is based on a study published by the German Academy of Technological Sciences (acatech) [
12]. Thus, this cycle expands the formerly established social resilience cycle, which comprised the four phases of preparedness, response, recovery, and mitigation, that was described by Edwards (2009) [
13].
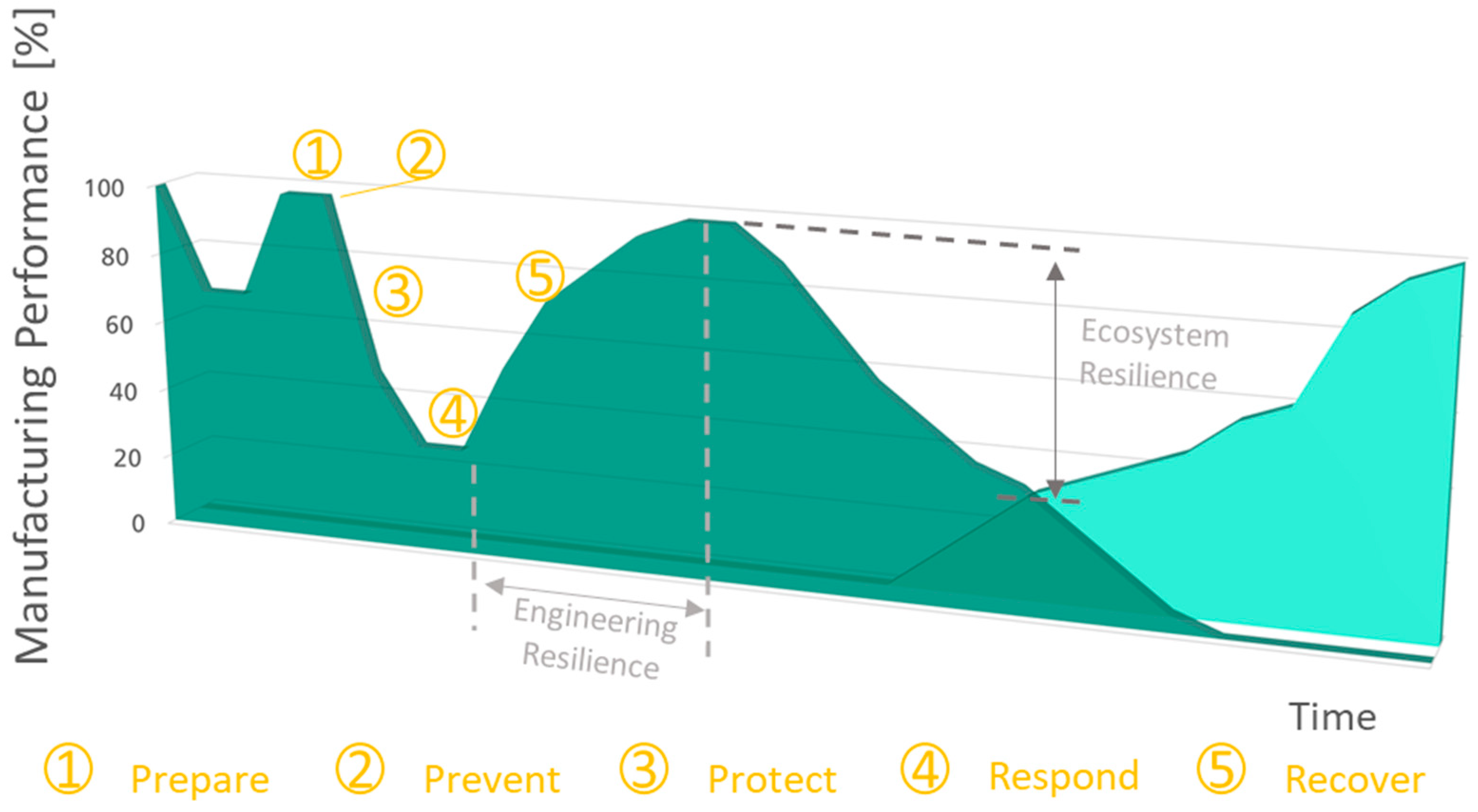
Figure 2 illustrates the described resilience types and cycle phases in a schematic manner, applied to the impact of hazards on production system performance.
The illustrated time series helps to allocate terms and methods that aim to reduce the effect of internal and external disturbances on manufacturing system performance. In an exemplary scenario, the initial performance reduction—caused, e.g., by supplier breakdown—may lead to the decision of preparation strategies such as (1) the improved synchronization among supply chain partners. In case of assumed bottlenecks, prevention methods such as (2) the increase of incoming stocks may be performed to reduce the impact of interruptions in material supply. Protection methods (3) may comprise strategies of supply chain management and production scheduling in order to mitigate performance losses due to supply failures. As a response (4), product components are substituted and lead to the necessity of system reconfiguration due to adapted production processes. The corresponding recovery phase (5) essentially affects profitability and competitiveness. However, market demand for the fictitious product may steadily decrease, caused by changing customer demands and may finally lead to the transformation of an overall production system, which is illustrated by shifting from dark to lighter green. Based on this classification, the actions and reactions during dangerous impacts can be sorted along their time-related occurrence. However, in order to develop a structured portfolio of measures, the appropriate model as a guideline is required.
The automation pyramid is a well-established model for factory automation [
14]. In accordance with the recent trend of Industry 4.0, this model was extended to a three-dimensional expression, including more aspects than the level of automation. The resulting RAMI 4.0 (
Figure 3) includes elements and IT components in a layer and life cycle model. It tries to decompose complex processes into modules and adds aspects of data privacy and IT security. RAMI 4.0 is intended to elaborate the understanding and discussions of all participants involved in Industry 4.0 [
15]. Thus, it may also serve as a base model for the definition and systematization of resilience-increasing measures.
Related to the described resilience cycle phases, the subsequent section contains simulation-based options that mainly focus on phases 1 to 3 on an enterprise- and supply chain level. Afterwards, the necessary concepts in information modeling and control for fast reconfiguration are described.
2.2. Concurrent Supply Chain and Production Planning
In order to investigate disturbances on production systems and the accompanying supply chain networks, material flow simulation provides appropriate options to study system behavior. According to Guideline 3633, Sheet 1 of the Society of German Engineers (VDI) [
16], simulation involves the recreation of a system with dynamic processes allowing the investigation with experiments to generate findings that can, in turn, be transferred to the real system. Thus, it becomes possible to investigate the temporal behavior of the respective modeled system and to derive corresponding statements. For the investigation of processes, discrete-event flow simulations are often used, in which the time-related behavior of the system is represented by successive events of a processing list and the associated state changes.
In an exemplary use case, a model was implemented in a Tecnomatix® Plant Simulation, which contains its own user interface to select production scenarios depending on the processing status of the implemented orders. A truck picks up the finished orders from the last day based on the first-in-first-out (FIFO) principle. Depending on the destination of the products, there is a separation between two different retrieval strategies. Inland locations allow partial deliveries, whereas abroad destinations require complete order fulfilment in one iteration. Disturbances can be turned on and off for the study of different scenarios with a simple button. This means that once the orders run through as planned (deterministically), there will be no delays in production. If the button is activated, disturbances with a defined mean time to repair (MTTR) are switched on, stochastic effects generate impacts on processes, and therefore, delays and unexpected events can occur.
In its standard version, the modelled factory works in a 2-shift system. A total of two hours before end of production, a message is sent to the user to make a decision on how to proceed with further production. The user can base this decision on the status of the planned orders and the orders being processed at that time.
In doing so, the user can select a scenario (e.g., start next shift) in the interface. This means that a third shift is run because the user assumes that the orders cannot be completely processed until the end of the second shift. In general, the user has three options as coping strategies for disturbance-related delays:
Option 1: Start third shift (as described above);
Option 2: Increase production speed by a certain percentage. The default value in this case is 15%. Hence, orders may be completed by 10pm after all or will continue to be processed the next day;
Option 3: Continue as planned; in this case, it could be the case that the orders become behind schedule and have to be processed within the next day.
The implementation and operationalization of the described options in a short-cycled and complex production environment necessitates the sophisticated description and modeling of system elements and their corresponding production processes. Therefore, an appropriate modeling approach and the derived process generation functionalities are described in the subsequent section.
2.3. Modelling and Execution of Resilient Production Processes
Mitigating risks and increasing resilience on the level of workflow management and process execution requires that an erroneous process can be returned to a defined state and—if possible—the defined goal of the workflow can still be reached. For example, if a single machine fails within a production process, it is in the interest of the plant operator that the error is remedied as soon as possible, reducing the loss of production and therefore reducing costs. Additionally, it might be feasible to reschedule single tasks within the production process in order to reduce downtime further. With the example of a model machine that allows for rescheduling the tasks performed by its modules, we examine how resilience can be provided on the level of process execution. On the one hand, this approach requires an amendment to the models used to describe production processes, and on the other hand, the information flow between the involved components of the Manufacturing Execution System (MES) needs to be taken into consideration.
Classic business process modelling consists of a sequence of activity nodes, which are intertwined with decision nodes, allowing for as much as flexibility as possible to be considered at compile time. In case erroneous events take place during the process execution, those events must be an explicit part of the process model. Consequently, an equally explicit mitigation strategy is required to be modelled at compile time as well, meaning that even “the unforeseen” must be foreseen. However, several approaches have been explored to allow for more flexible process execution and to provide resilience on the level of process execution in the domains of software engineering [
17], emergency management [
18], logistics [
19], and cyber-physical systems [
20]. Notably, [
18] advocate a declarative approach, annotating single activities with “preconditions and effects”, allowing for a dynamic workflow generation by utilizing these annotations as constraints between those activities.
However, the domain of cyber-physical production systems (CPPS) imposes further conditions since tasks executed by production machines or human operators usually affect artifacts existing in the real world—such as work pieces—and thus manipulate their state. Furthermore, these artifacts may be impacted by influences that are outside of the scope of the defined workflow, leading to cyber-physical deviations that need to be addressed during process execution [
21]. Therefore, we propose the generalization of the declarative approach used in [
18] by considering the condition of the artifacts and by utilizing their context for applying constraints on the tasks within the production workflow. For this matter, we use the definition of “context” provided by Dey and Abowd (2000), who define context as “any information that can be used to characterize the situation of an entity” [
22]. They further define an entity as “a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and applications themselves”, but given the nature of CPPS, interactions do not only take place between users and applications, but also in-between applications. For this reason, we suggest not limiting this definition to interactions in which a user participates.
Within the research project “RESPOND”, we evaluate the declarative approach outlined above with the aid of a model machine consisting of four modules. These modules are traversed by a work piece made of aluminum (approx. 65 mm × 20 mm × 3 mm) in a skid on a conveyor belt. The four modules and their respective tasks are as follows:
A drill that drills a hole into the work piece;
A milling machine that mills an engraving into the surface of the work piece;
A camera that measures the diameter of the drilling;
A knuckle joint press to manually press a steel ball into the drilling.
Furthermore, a human operator is responsible for loading and unloading the machine. In order to execute task 4, tasks 1 and 3 must have been executed successfully before. However, task 2 is independent of the other tasks and is only crucial for the success of the whole workflow. This means that if task 2 fails (e.g., due to a malfunction of the milling machine), the other tasks can still be executed and task 2 can be performed later, provided that the defect is remedied. Furthermore, executing the automated tasks (drilling, milling, measuring) requires that the work piece is in the skid of the conveyor belt, while the manual task requires that the work piece has been taken from the skid into the knuckle joint press.
By annotating the activities of the process with the required and returned context data, it is possible to verify whether the process is valid. For example, if an activity requires that the work piece be located inside the skid, a preceding activity must have returned “location = skid”. This standard process annotated with the required and returned context data is depicted in
Figure 4.
Furthermore, these annotations can be utilized to dynamically provide resilience on the level of process execution in case one of the modules fails to perform its designated task. The use case that we want to examine represents a temporary defect of the milling machine, which is supposed to be remedied by a human operator. This resilience can be provided in the form of a modified workflow, which is generated ad hoc upon process errors. For this matter, we propose a Process-Planning Engine (PPE), which can be accessed by the Manufacturing Execution System (MES) and that is able to obtain information from the process itself as well as a context model of the plant.
The information flow outlined above requires a suitable architecture, in which contextual information is available in real-time to the PPE. This use case is explored in [
21], where an architecture consisting of four layers allowing for real-time communication between the involved components is proposed. One of these layers (the so called “RESPOND infrastructure”) is responsible for communication via an event bus. Payloads delivered via this event bus include, e.g., sensor data, commands for actuators, or messages sent by components upon their registration. Besides the event bus, components communicate via a peer-to-peer connection. Within this architecture, the proposed PPE can be represented by the “Process Healing” node.
Based on this architecture, a sequence diagram displaying the information exchange relevant for resilient process planning is shown in
Figure 5. As soon as a fault in the current process is detected, a message containing the IDs of the faulty process, the blamable activity, and the involved agents is sent to the PPE. For this matter, the origin of this error message is considered a black box; however, it is conceivable to provide these error messages by means of a Complex Event Processing (CEP) engine. In the architecture proposed by [
21], the CEP engine is represented by the “Process Analysis” node.
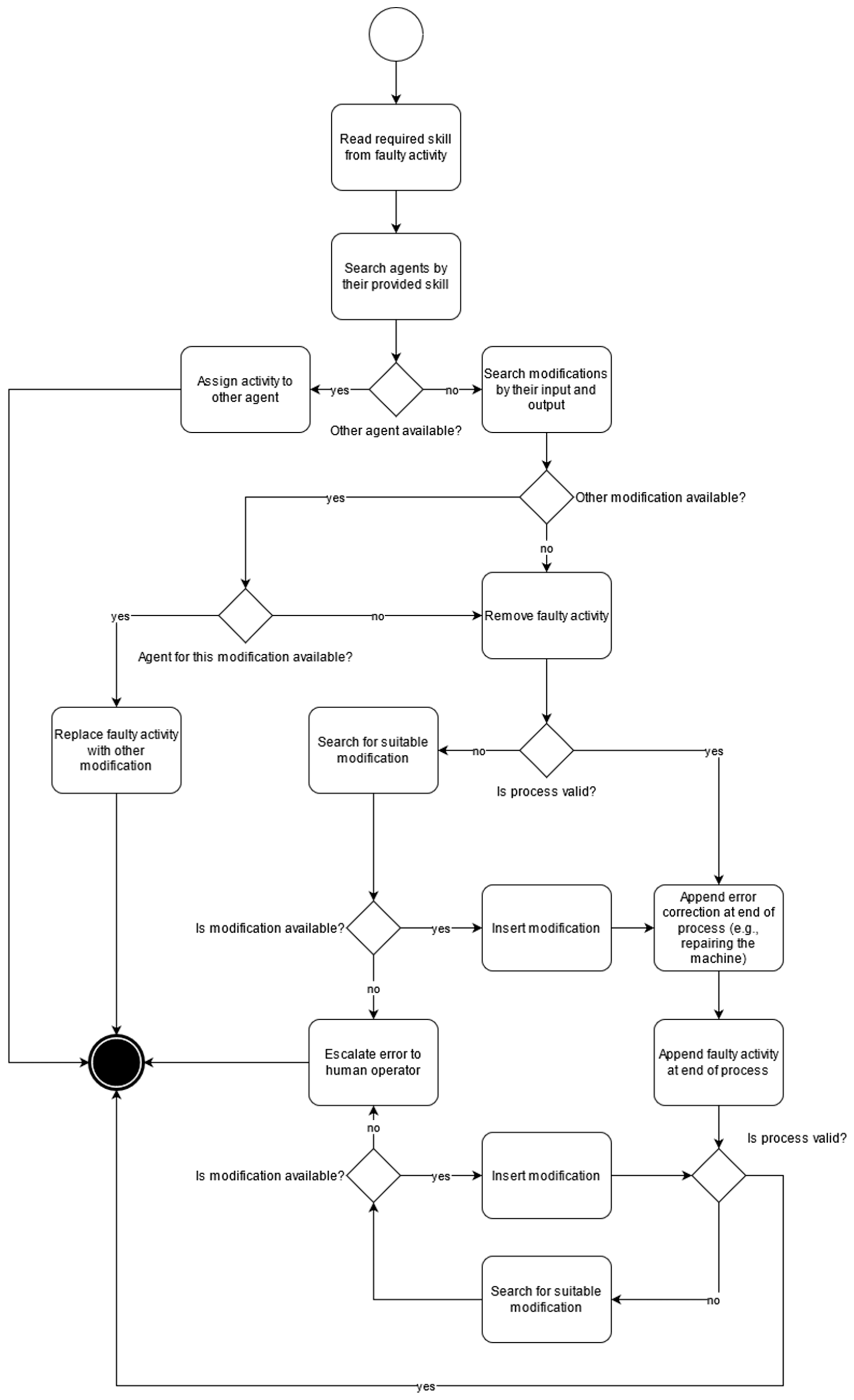
Based on these IDs (process, activity, agents, artifacts), the PPE requests the process repository for the process model and the context engine for context information about the involved agents and artifacts. Assuming that the process model is amended by semantic information about the artifact states as shown in
Figure 4, the “required” and “returned” states can be summarized as “modifications” and can be mapped to the necessary skill profile of the involved agents. Based on these modifications and skill profiles, two general approaches can be conducted (
Figure 6):
Adjust the faulty process by replacing the faulty activity with another activity (or sub-process) that yields the same outcome;
Transfer the faulty activity to another agent that corresponds to the required skill profile.
As soon as the PPE finds a solution for the faulty process, the newly generated process is pushed to the process repository and its ID is published via the event bus to be read by the workflow management system (WfMS), which, in turn, retrieves this process from the repository and then starts it.
In the example of the workflow depicted in
Figure 4, the task that should be performed by the milling machine would be rescheduled to the end of the workflow, and a human operator would be instructed to repair the machine. However, the milling machine requires the work piece to be in the skid on the conveyor belt, and at the end of the default workflow, the work piece is unloaded from the machine and put into the tray. Therefore, it is necessary that the rescheduled milling process is padded with further activities that guarantee the required artifact location, i.e., putting it into the skid before the milling and taking it from the skid to the tray afterwards. The final activity was not part of the original process model, so in order to add this activity to the rescheduled workflow, the PPE needs to query the process repository for suitable activities or sub-processes based on the required context modification. This modified workflow is depicted in
Figure 7.
2.4. Rapid Response to Changing Requirements Using Skill-Based Control Systems and Virtual Commissioning
To implement the methods of workflow management and process execution to increase the resilience of production systems, it is necessary to increase flexibility and modularity on the station level and below. This can be achieved by designing the control device, field device, and product accordingly. The modular design of the control device reduces the development time and expenses even for smaller batch sizes. In addition, this modularity enables flexible and individual adaptation of the control device to the application. The focus of this section lies on the control device and its interaction with a digital representation of the production station, represented as digital twin. This combination is a key enabler in bringing production systems towards more resilience in production and is also beneficial in the development phase. Details will be given in two subsections for the controller and digital twin.
Modular and flexible production stations require new design [
23] and new ideas of power and information supply [
24] as well as a new paradigm of PLC programming. Only if the flexibility and adaptability in hardware is transferred into flexibility in the design of automation solutions can a true and holistic flexibility in manufacturing be reached. However, state-of-the-art programmable logic controllers (PLC), which are the common solution, e.g., for robot cells, are a cyclic processing comprising the steps:
Input scan (reading all inputs and memory states);
Execution of a problem-oriented automation program (PLC-program) to generate output and memory values;
Output update (writing values to outputs and memory).
Up until today, the core of the PLC program has been defined by the automation task. Until now, this has usually been developed, implemented, tested, and maintained on a task-specific basis by an automation technician of the machine/unit manufacturer [
25]. Due to the fact that the task defines the code, necessary modification, adaptation or addition of command sequences, and positions, process sequences are usually not easily possible, even for minimal changes to the automation task. The effort required for programming, testing, and commissioning control software is growing disproportionately with the increase in the scope and complexity of control functionality [
26]. In addition, monolithic, task driven programs are mostly only changeable by specifically educated PLC programmers, which often result in long maintenance breaks. Hence, this paradigm must be changed due to the stated request for increased flexibility and modularity of production to realize an extended resilience.
An alternative is the plug-and-produce concept. Although this was originally developed for hardware and connectivity in automation systems, it enables the flexible configuration and partial self-organization of production processes at the runtime of the system. Individual functional components can be combined and/or exchanged in a flexible manner in order to adapt the production system to changing products or boundary conditions. The basic idea of plug-and-produce is that hardware components make their functions available based on a self-description, including all of the necessary information for the higher-level automation system. Thanks to a uniform interface, new components can be easily connected and used by the control device [
14]. Several solutions are already available, mainly using the OPC Unified Architecture (OPC UA) standard for data exchange [
27]. This was developed as a platform-independent, service-oriented architecture. However, most of the existing solutions are still manufacturer dependent or limited to several, specified use cases [
28].
One basis for implementing the plug-and-produce concept at the level of control devices is to structure the functional components of an automation solution into modules. This ensures that modules can be easily exchanged and arranged according to the automation task as well as to the hardware representation.
This also triggers the main disruption in the programming of control devices: the developed code is no longer task-driven, but skill-driven and modular.
The most important features of this controller programming approach are uniform interfaces and the provision of parameterizable module functions in specific skills. Afterwards, the functions can be orchestrated freely for the automation task by a higher-level system, whereby each module provides the necessary function descriptions, requirements, and boundary conditions [
13].
The strengths compared to the established architectures lie in the free reconfigurability, interchangeability, and reusability of functional components at the control level. The concept of skill-based control can be derived from a product-process-resource model (see
Figure 8).
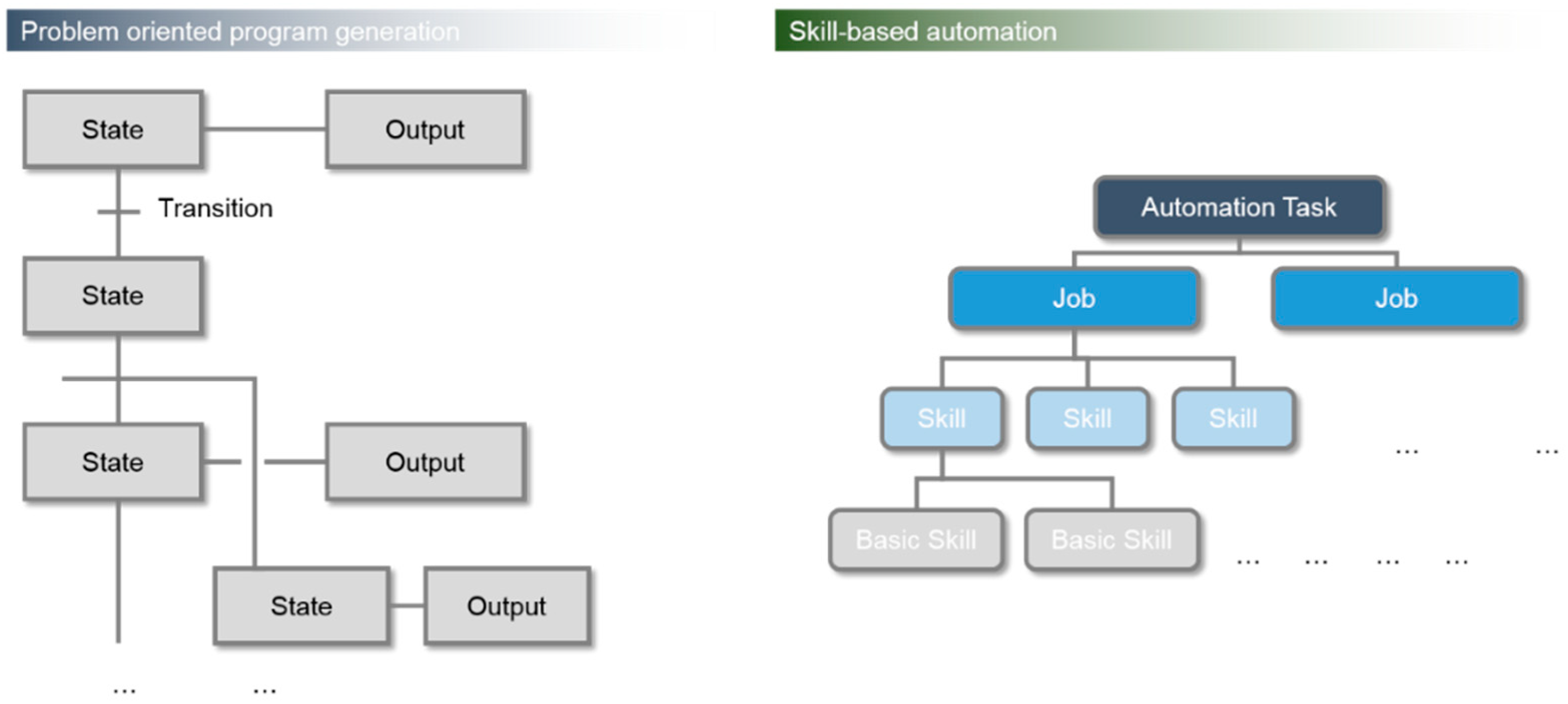
The benefit to the user is that the PLC programming is transformed from a programming effort to a combination of predefined skills and their parametrization. Hence, the controller is not only equipped with a specific program to solve one specific complex automation task (
Figure 9, left), but bases it on a large set of modular basic skills, covering all of the possible or senseful abilities of the manufacturing unit. Here, skills can be parametrized and combined to jobs, leading to the complete automation task (
Figure 9, right).
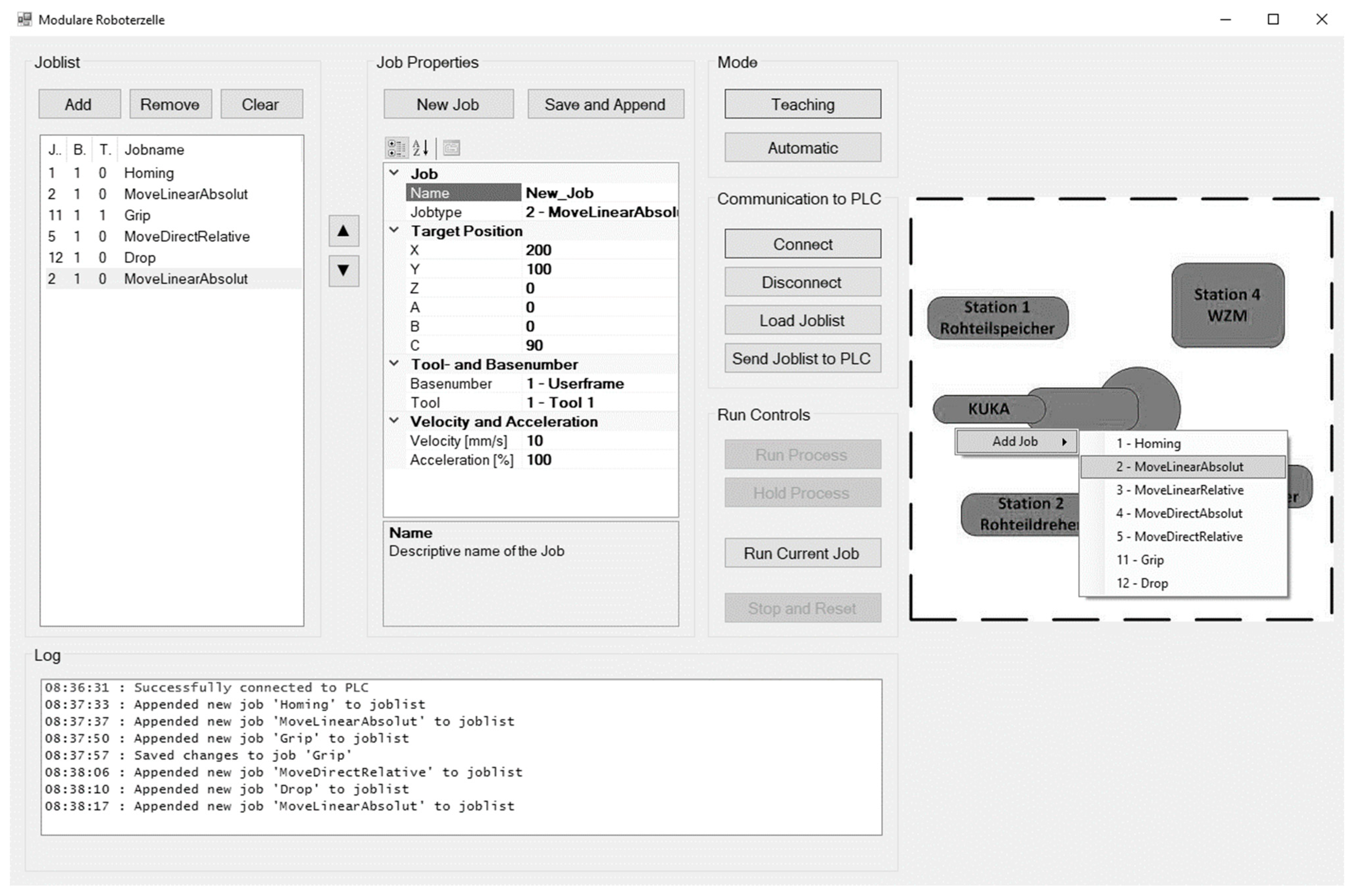
To give an example, handling, measuring, orienting, and loading/unloading are regarded as jobs. All of the jobs consist of a sequence of skills, such as movement, opening/closing a gripper, call to a camera. The skill “movement” is furthermore a combination of basic skills such a move linear or move circular (
Figure 9, right). The manufacturing cell is equipped with all hardware modules and a complete skillset. This skillset is taught and programmed by the automation technician but remains open for a variety of applications. The solution is extremely flexible in further applications and in individual utilizations. Further steps such as combining skills to jobs and programs can be conducted by skilled workers and do not require automation technicians.
After a basic commissioning and software test, the machine operator can combine the skills and jobs to an automated process sequence or adapt the given sequence to a new setting with support of a graphical user interface (GUI).
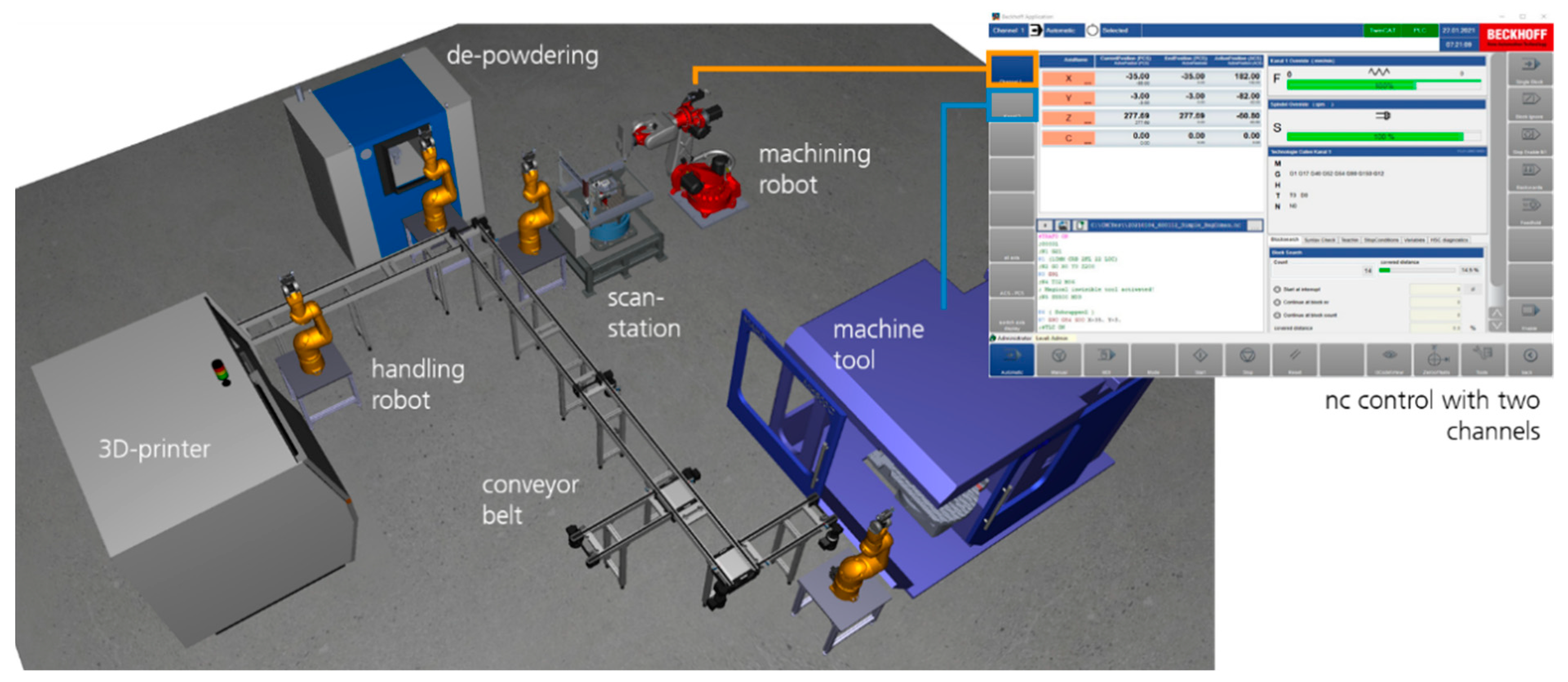
The fast commissioning as well as the software tests for the skill-based functions can be realized by virtual commissioning using a digital twin of the production system. Digital twins are already widely used by machine and plant manufacturers to virtually plan and optimize the most complex production machines and plants during their development [
30]. Along the development process, the digital twin can be used for the design of the different domain-specific subsystems and to evaluate the dependencies between them. As such, at the end of the construction phase, there is a nearly exact digital twin of the machine that can be used for the development of the control functions while the hardware is in realization [
31]. The virtual commissioning of control systems allows for a reduction of the commissioning time of the whole machine and results in a faster production start as well as reduced costs for the engineering process [
32].
Figure 10 shows the timeline for the conventional procedure for the development of a system and in comparison, the timeline for the same procedures with virtual commissioning.
For virtual commissioning, machine and plant models are developed that correspond to their real counterparts in terms of their interfaces, parameters, and operating modes. With the help of these virtual systems, realistic test and commissioning situations can be simulated, including all control functions, whereby the control system can be operated and examined on the digital twin in the same way as on the real machine. Although domain-specific behavioral models are occasionally used today in the production phase for control and regulation functions, the comprehensive system simulation models from engineering are usually not adopted in the real operating phase. In the context of the resilience of production systems, these models in combination with the possibilities of the virtual commissioning contributes to various aspects of resilience enhancement.
Increasing the resilience of production systems not only requires the early recognition of the internal and external events that lead to disruptions in production processes, but also strategies to respond to them flexibly. For example, it is necessary to evaluate a suitable alternative in the event of a production equipment failure. In addition to manufacturing products of the same quality, the objective may also involve meeting deadlines or changing input materials, which can lead to necessary changes in the production processes. The adaptation of the production system must be planned and examined for its feasibility. If the machinery of a component manufacturer, for example, is virtualized, a virtual commissioning system can be used to assemble machines and systems from a library [
33]. With this modular system, it is possible to quickly assemble new configurations for manufacturing systems, plants, or even entire factory halls in the event of changing boundary conditions and to examine them regarding defined optimization criteria. In terms of anticipation, such a configurator can be used to simulate events such as the failure of production equipment and to plan the corresponding reactions and validate them on the virtual representation. This way, it is possible to react much more quickly in the event of an occurrence and thus shorten the downtimes of production systems.
Today, up to two thirds of the control software for manufacturing systems is used for error detection and handling [
34]. The testing of the methods used for this can only take place after the hardware has been realized. Only then can the corresponding errors be provoked, and the reaction of the control system can be validated. In addition, errors that lead to the destruction of the system, impairment of the machine environment, or even injury to the machine operator cannot be checked on the real system. With the digital twin, on the other hand, it is possible to examine these error patterns in an early phase of the system development, even before its realization, and to incorporate the gained knowledge into the development of the system components and control system. In this way, the robustness of systems in the face of faults can already be increased during their development.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}