
Plant Diseases Identification through a Discount Momentum Optimizer in Deep Learning

Abstract
:1. Introduction
- Applying the discount weighted moving average to the momentum buffer , a relative result reveals the higher recognition ability and faster convergence.
- Another key contribution of this work is show that DM does provide performance gains over other non-adaptive learning rate methods on plant diseases classification task.
- It is proved that discount momentum optimizer is insensitive to deep learning architectures and hyper-parameters.
- The DM method is capable of recovering popular non-adaptive learning rate methods in an efficient and accessible manner.
2. Related Work
3. Non-Adaptive Learning Rate Methods
| Algorithm 1 Generic framework of non-adaptive optimization methods |
| Require:, initial step size (learning rate) , sequence of functions |
| for to T and endfor |
3.1. Stochastic Gradient Descent Momentum
3.2. The Proposed Method: Discount Momentum Optimizer
4. Results
4.1. The Dataset
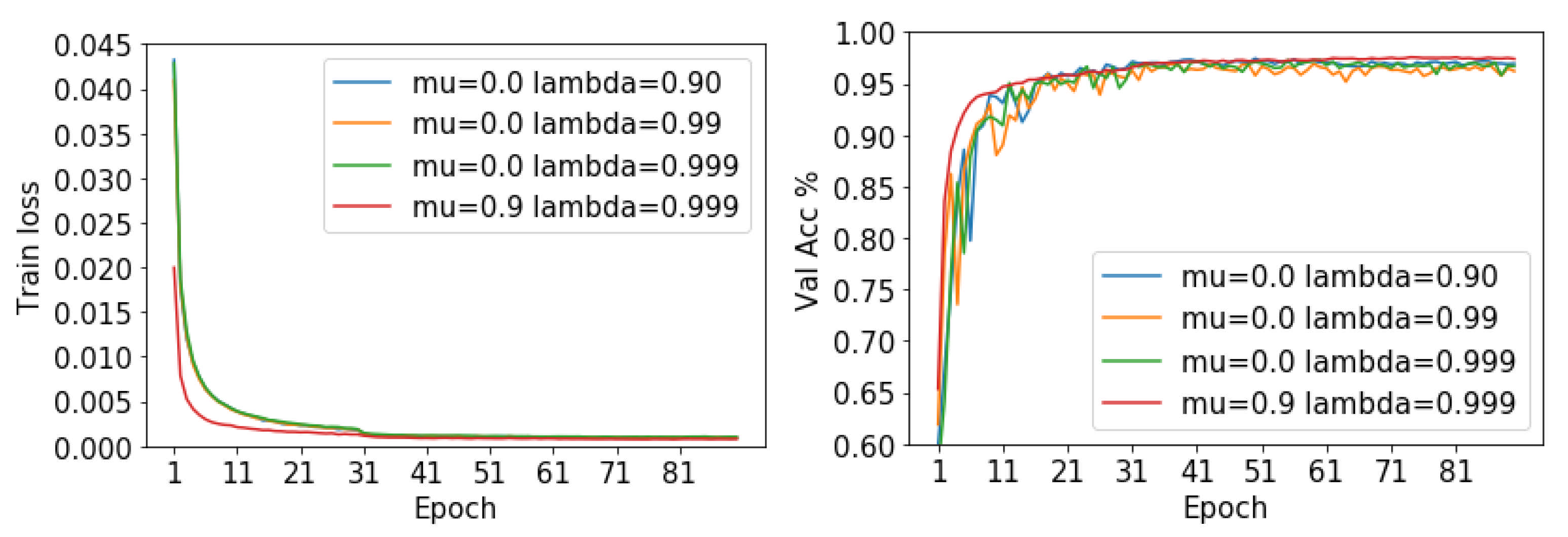
4.2. Hyper-Parameter Tuning
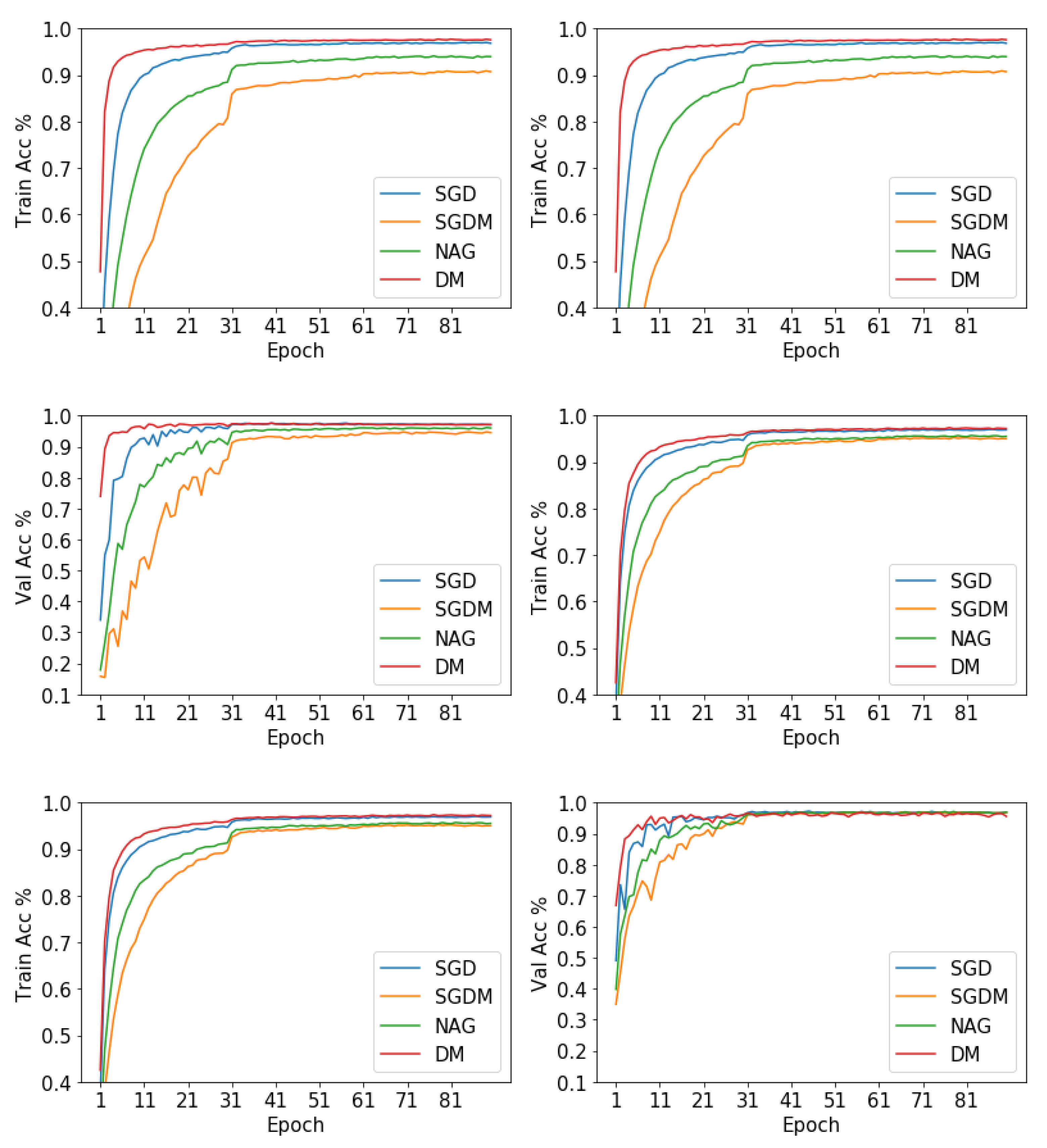
4.3. Convolutional Neural Networks
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Harvey, C.A.; Rakotobe, Z.L.; Rao, N.S.; Dave, R.; Razafimahatratra, H.; Rabarijohn, R.H.; Rajaofara, H.; MacKinnon, J.L. Extreme vulnerability of smallholder farmers to agricultural risks and climate change in Madagascar. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 1639. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gimenez-Gallego, J.; Gonzalez-Teruel, J.D.; Jimenez-Buendia, M.; Toledo-Moreo, A.B.; Soto-Valles, F.; Torres-Sanchez, R. Segmentation of Multiple Tree Leaves Pictures with Natural Backgrounds using Deep Learning for Image-Based Agriculture Applications. Appl. Sci. 2019, 10, 202. [Google Scholar] [CrossRef] [Green Version]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Wu, Y.; Xu, L. Crop Organ Segmentation and Disease Identification Based on Weakly Supervised Deep Neural Network. Agronomy 2019, 9, 737. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Han, L.; Dong, Y.; Shi, Y.; Huang, W.; Han, L.; González-Moreno, P.; Ma, H.; Ye, H.; Sobeih, T. A Deep Learning-Based Approach for Automated Yellow Rust Disease Detection from High-Resolution Hyperspectral UAV Images. Remote Sens. 2019, 11, 1554. [Google Scholar] [CrossRef] [Green Version]
- Moreno-Revelo, M.Y.; Guachi-Guachi, L.; Gómez-Mendoza, J.B.; Revelo-Fuelagán, J.; Peluffo-Ordóñez, D.H. Enhanced Convolutional-Neural-Network Architecture for Crop Classification. Appl. Sci. 2021, 11, 4292. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep neural networks with transfer learning in millet crop images. Comput. Ind. 2019, 108, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, S.P.; Hughes, D.P.; Salath, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Ghazi, M.; Yanikoglu, B.; Aptoula, E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 2017, 235, 228–235. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2018, 161, 272–279. [Google Scholar] [CrossRef]
- Sambasivam, G.; Opiyo, G.D. A predictive machine learning application in agriculture: Cassava disease detection and classification with imbalanced dataset using convolutional neural networks. Egypt. Inform. J. 2020, 22, 27–34. [Google Scholar] [CrossRef]
- Cruz, A.C.; Luvisi, A.; De Bellis, L.; Ampatzidis, Y. X-FIDO: An Effective Application for Detecting Olive Quick Decline Syndrome with Deep Learning and Data Fusion. Front. Plant Sci. 2017, 8, 1714. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, S.; Zhang, C.; Wang, X.; Shi, Y. Cucumber leaf disease identification with global pooling dilated convolutional neural network. Comput. Electron. Agric. 2019, 162, 422–430. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Zhang, X.; Qiao, Y.; Meng, F.; Fan, C.; Zhang, M. Identification of Maize Leaf Diseases Using Improved Deep Convolutional Neural Networks. IEEE Access 2018, 6, 30370–30377. [Google Scholar] [CrossRef]
- Herbert, R.; Sutton, M. A Stochastic Approximation Method; Springer: New York, NY, USA, 1985; Volume 22. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. Ussr Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Nesterov, Y.E. A method for solving the convex programming problem with convergence rate. Dokl. Akad. Nauk Sssr 1983, 269, 372376. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive Gradient Methods with Dynamic Bound of Learning Rate. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 315–323. [Google Scholar]
- Ma, J.; Yarats, D. Quasi-hyperbolic momentum and Adam for deep learning. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhou, Z.; Zhang, Q.; Lu, G.; Wang, H.; Zhang, W.; Yu, Y. AdaShift: Decorrelation and Convergence of Adaptive Learning Rate Methods. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Johnson, R.; Zhang, T. Accelerating Stochastic Gradient Descent using Predictive Variance Reduction. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems, Christopher J. C. Burges and Léon Bottou and Zoubin Ghahramani and Kilian Q. Weinberger, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 315–323. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| SGD | SGDM | NAG |
|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Liu, Y.; Zhou, H.; Hu, H. Plant Diseases Identification through a Discount Momentum Optimizer in Deep Learning. Appl. Sci. 2021, 11, 9468. https://doi.org/10.3390/app11209468
Sun Y, Liu Y, Zhou H, Hu H. Plant Diseases Identification through a Discount Momentum Optimizer in Deep Learning. Applied Sciences. 2021; 11(20):9468. https://doi.org/10.3390/app11209468
Chicago/Turabian StyleSun, Yunyun, Yutong Liu, Haocheng Zhou, and Huijuan Hu. 2021. "Plant Diseases Identification through a Discount Momentum Optimizer in Deep Learning" Applied Sciences 11, no. 20: 9468. https://doi.org/10.3390/app11209468
APA StyleSun, Y., Liu, Y., Zhou, H., & Hu, H. (2021). Plant Diseases Identification through a Discount Momentum Optimizer in Deep Learning. Applied Sciences, 11(20), 9468. https://doi.org/10.3390/app11209468