
Universal Adversarial Attack via Conditional Sampling for Text Classification

Abstract
:1. Introduction
2. Background and Related Work
2.1. Deep Neural Networks
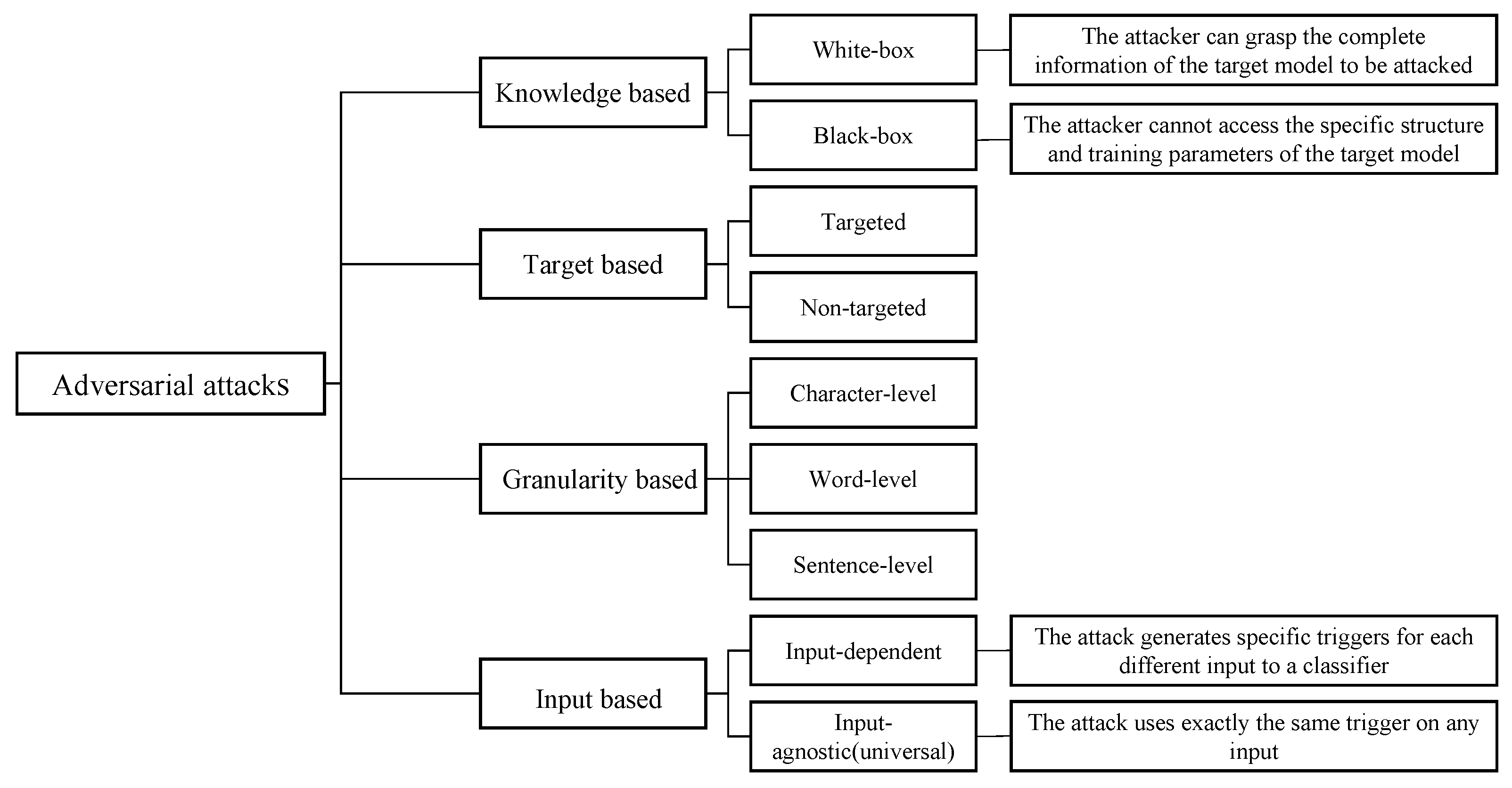
2.2. Adversarial Attacks
2.2.1. Input-Dependent Attacks
2.2.2. Universal Attacks
3. Universal Adversarial Perturbations
3.1. Universal Triggers
3.2. Problem Formulation
3.3. Attack Trigger Generation
4. Experiments
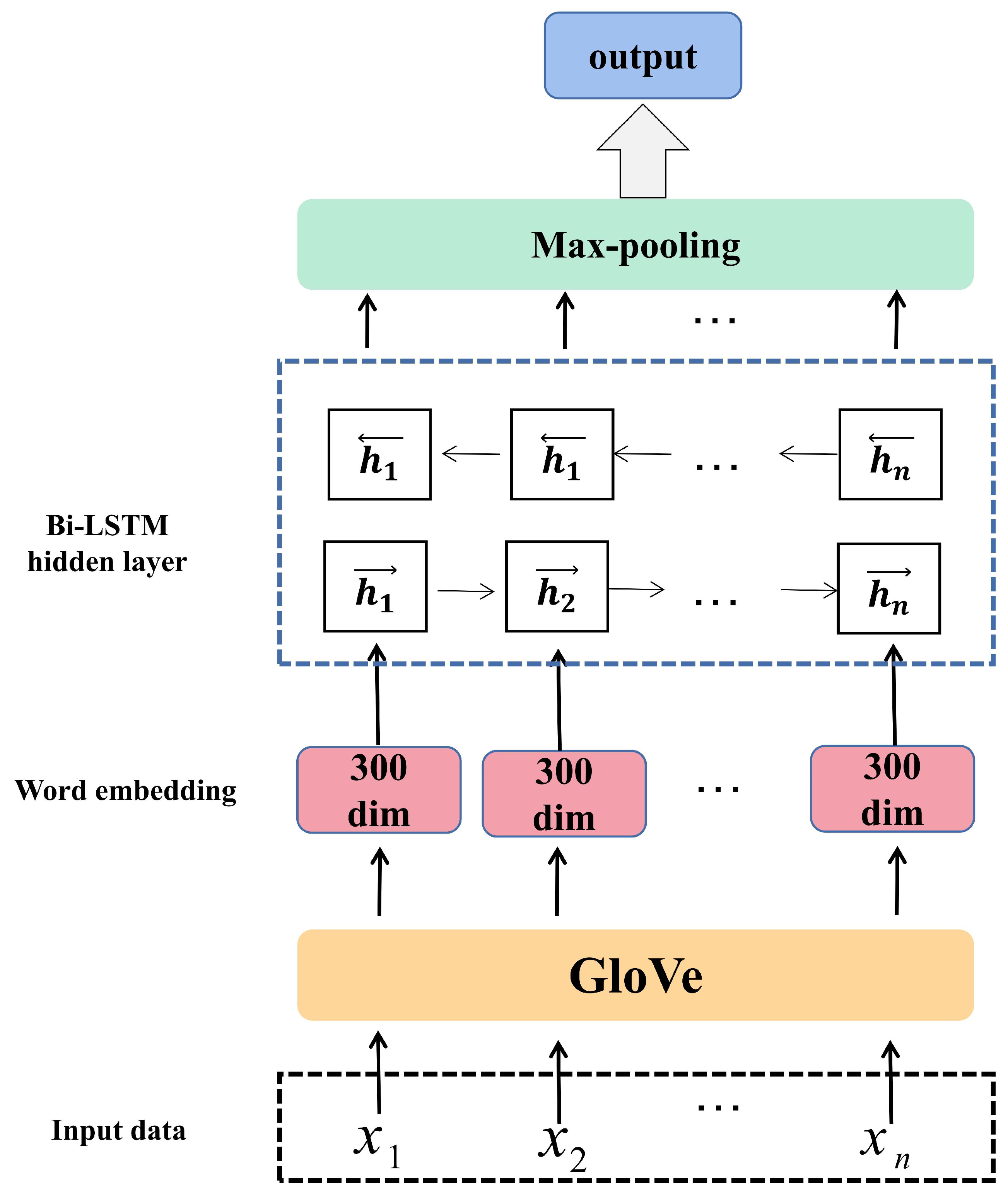
4.1. Datasets and Target Models
4.2. Baseline Methods
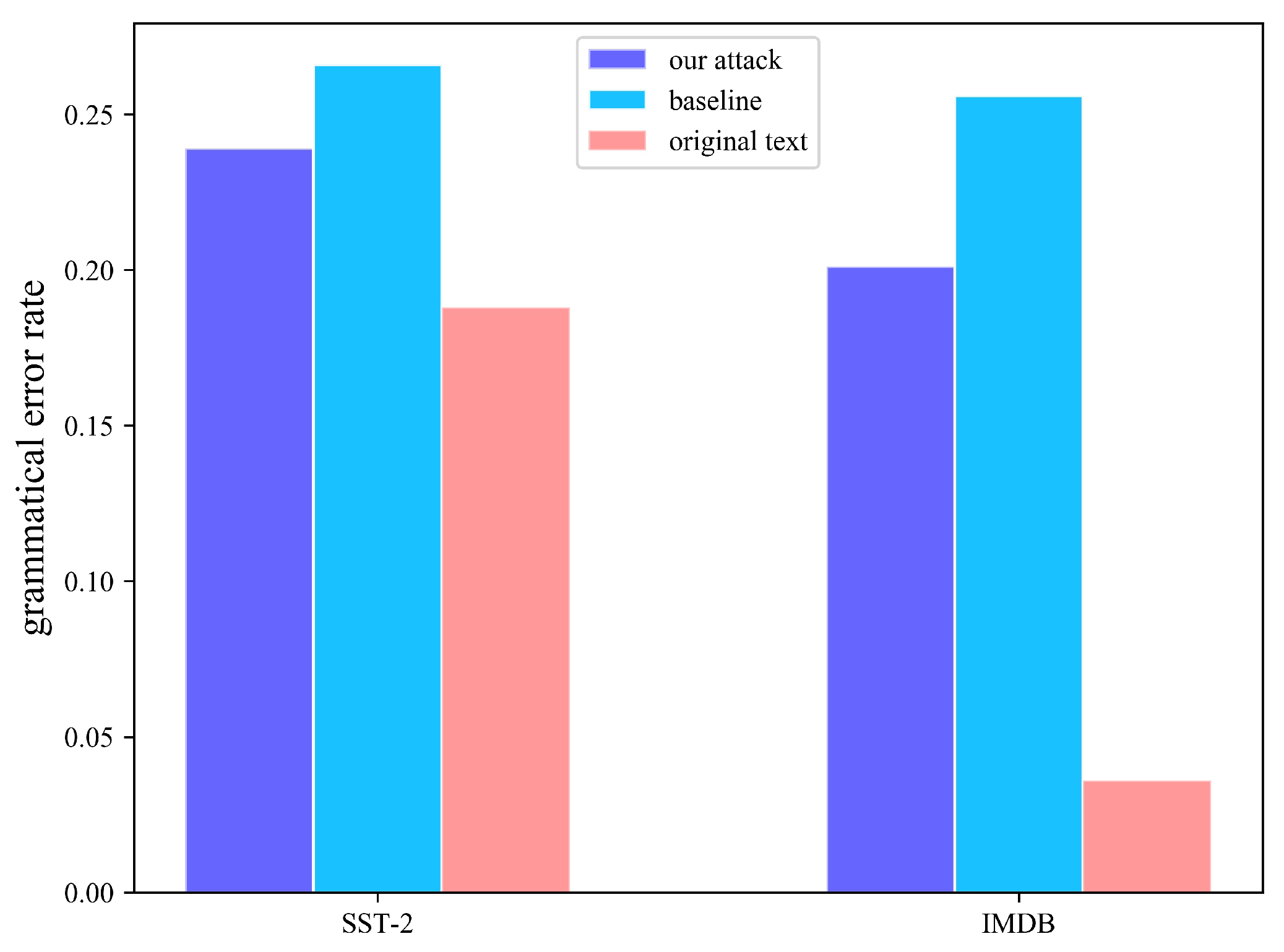
4.3. Evaluation Metrics
4.4. Attack Results
4.5. Transferability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Ye, F.; Yang, J. A Deep Neural Network Model for Speaker Identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting Adversarial Input Sequences for Recurrent Neural Networks. arXiv 2016, arXiv:1604.08275. [Google Scholar]
- Du, X.; Yu, J.; Yi, Z.; Li, S.; Ma, J.; Tan, Y.; Wu, Q. A Hybrid Adversarial Attack for Different Application Scenarios. Appl. Sci. 2020, 10, 3559. [Google Scholar] [CrossRef]
- Thys, S.; Van Ranst, W.; Goedeme, T. Fooling Automated Surveillance Cameras: Adversarial Patches to Attack Person Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Workshops 2019, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. arXiv 2015, arXiv:1511.07528. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. arXiv 2017, arXiv:1707.07328. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and Natural Noise Both Break Neural Machine Translation. arXiv 2018, arXiv:1711.02173. [Google Scholar]
- Moosavi-Dezfooli, S.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 86–94. [Google Scholar] [CrossRef] [Green Version]
- Wallace, E.; Feng, S.; Kandpal, N.; Gardner, M.; Singh, S. Universal Adversarial Triggers for Attacking and Analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2153–2162. [Google Scholar] [CrossRef] [Green Version]
- Behjati, M.; Moosavi-Dezfooli, S.; Baghshah, M.S.; Frossard, P. Universal Adversarial Attacks on Text Classifiers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; pp. 7345–7349. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 5754–5764. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 3261–3275. [Google Scholar]
- Wang, A.; Cho, K. BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model. arXiv 2019, arXiv:1902.04094. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. HotFlip: White-Box Adversarial Examples for Text Classification. arXiv 2018, arXiv:1712.06751. [Google Scholar]
- Lei, Q.; Wu, L.; Chen, P.; Dimakis, A.; Dhillon, I.S.; Witbrock, M.J. Discrete Adversarial Attacks and Submodular Optimization with Applications to Text Classification. In Proceedings of the Machine Learning and Systems 2019, MLSys 2019, Stanford, CA, USA, 31 March–April 2 March 2019. [Google Scholar]
- Alzantot, M.; Sharma, Y.; Elgohary, A.; Ho, B.J.; Srivastava, M.; Chang, K.W. Generating Natural Language Adversarial Examples. arXiv 2018, arXiv:1804.07998. [Google Scholar]
- Zang, Y.; Qi, F.; Yang, C.; Liu, Z.; Zhang, M.; Liu, Q.; Sun, M. Word-level Textual Adversarial Attacking as Combinatorial Optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies—Volume 1; Association for Computational Linguistics: Seattle, WA, USA, 2011; pp. 142–150. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; A Meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL: Seattle, WA, USA, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Wallace, E.; Feng, S.; Kandpal, N.; Gardner, M.; Singh, S. Universal Adversarial Triggers for Attacking and Analyzing NLP. arXiv 2021, arXiv:1908.07125. [Google Scholar]
- Mozes, M.; Stenetorp, P.; Kleinberg, B.; Griffin, L.D. Frequency-Guided Word Substitutions for Detecting Textual Adversarial Examples. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, 19–23 April 2021; Merlo, P., Tiedemann, J., Tsarfaty, R., Eds.; Association for Computational Linguistics: Seattle, WA, USA, 2021; pp. 171–186. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]









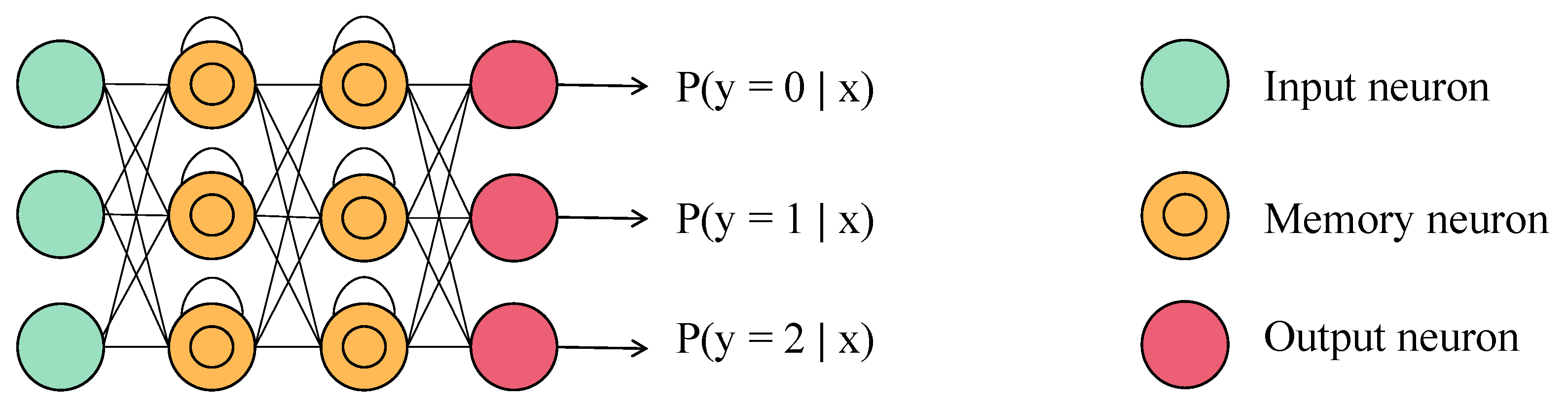{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Evaluation Method | Better? |
|---|---|---|
| Composite score | Auto | Higher |
| Success Rate | Auto | Higher |
| Word Freqency | Auto | Higher |
| Grammaticality | Auto (Error Rate) | Lower |
| Fluency | Auto (Perplexity) | Lower |
| Naturality | Human (Naturality Score) | Higher |
| Task | Test Data | Our Attack | Baseline | ||||
|---|---|---|---|---|---|---|---|
| Trigger | Success Rate (%) | Q (%) | Trigger | Success Rate (%) | Q (%) | ||
| SST-2 | negative | genius ensemble plays a variety scripts dealing with disease | 74.0 | 6.25 | death fearlessly courageous courageous terror terror sentimentalizing sentimentalizing triteness | 84.3 | 5.12 |
| positive | speedy empty constraints both on aimlessly | 80.1 | 7.78 | wannabe hip timeout timeout ill infomercial | 89.1 | 6.33 | |
| IMDB | negative | harmonica fractured absolutely amazing enjoyable fantasia suite symphony energetically | 51.3 | 0.15 | unparalleled heartwrenching heartwarming unforgettably wrenchingly movie relatable relatable heartfelt | 65.2 | −2.20 |
| positive | red martin on around a keen cherry drinks then limp unfunny sobbing from a waste entrance | 50.1 | −0.15 | miserable moron unoriginal unoriginal unengaging ineffectual delicious crappiest stale lousy | 57.6 | −4.10 | |
| Condition | Ours | Baseline | Not Sure |
|---|---|---|---|
| Trigger-only | 78.6% | 19.0% | 2.4% |
| Trigger + benign | 71.4% | 23.8% | 4.8% |
| Test Class | Model Architecture | Dataset | ||
|---|---|---|---|---|
| BiLSTM ⇓ BERT | BERT ⇓ BiLSTM | SST ⇓ IMDB | IMDB ⇓ SST | |
| positive | 52.8% | 39.8% | 10.0% | 93.9% |
| negative | 45.8% | 13.2% | 35.5% | 98.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Shao, K.; Yang, J.; Liu, H. Universal Adversarial Attack via Conditional Sampling for Text Classification. Appl. Sci. 2021, 11, 9539. https://doi.org/10.3390/app11209539
Zhang Y, Shao K, Yang J, Liu H. Universal Adversarial Attack via Conditional Sampling for Text Classification. Applied Sciences. 2021; 11(20):9539. https://doi.org/10.3390/app11209539
Chicago/Turabian StyleZhang, Yu, Kun Shao, Junan Yang, and Hui Liu. 2021. "Universal Adversarial Attack via Conditional Sampling for Text Classification" Applied Sciences 11, no. 20: 9539. https://doi.org/10.3390/app11209539
APA StyleZhang, Y., Shao, K., Yang, J., & Liu, H. (2021). Universal Adversarial Attack via Conditional Sampling for Text Classification. Applied Sciences, 11(20), 9539. https://doi.org/10.3390/app11209539