
Eliciting Auxiliary Information for Cold Start User Recommendation: A Survey


Abstract
:1. Introduction
- This study offers a novel explanation and insight into the detailed process of reaching and extracting the auxiliary information needed for cold start recommendation.
- This study categorizes and presents a taxonomy of the approaches used for eliciting auxiliary information needed for cold start recommendation.
- This study shows and identifies several challenges associated with eliciting auxiliary information for a cold start recommendation. One of the most noticeable challenges from the results is that deriving the auxiliary side information usually involves two distinct processes.
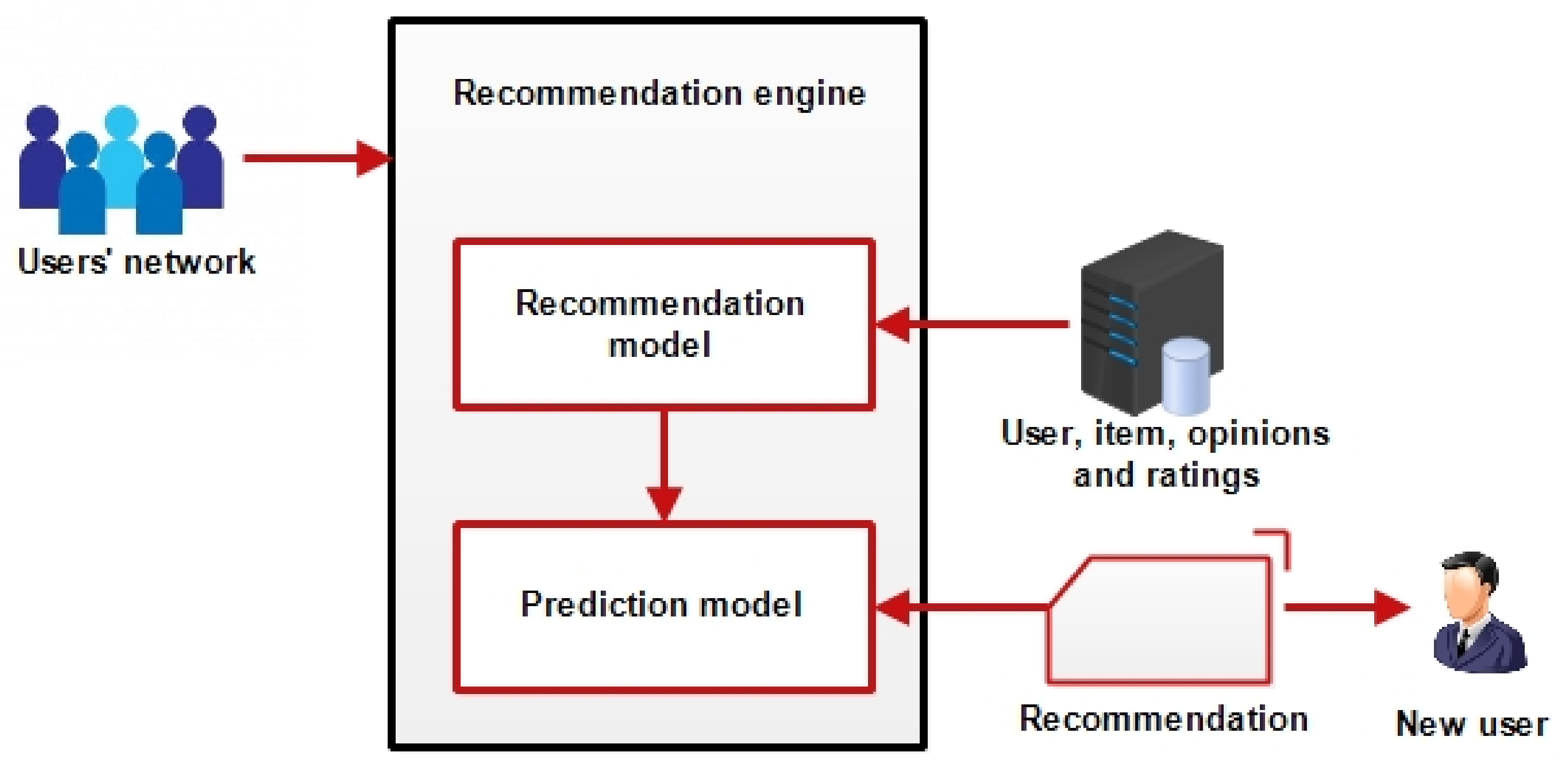
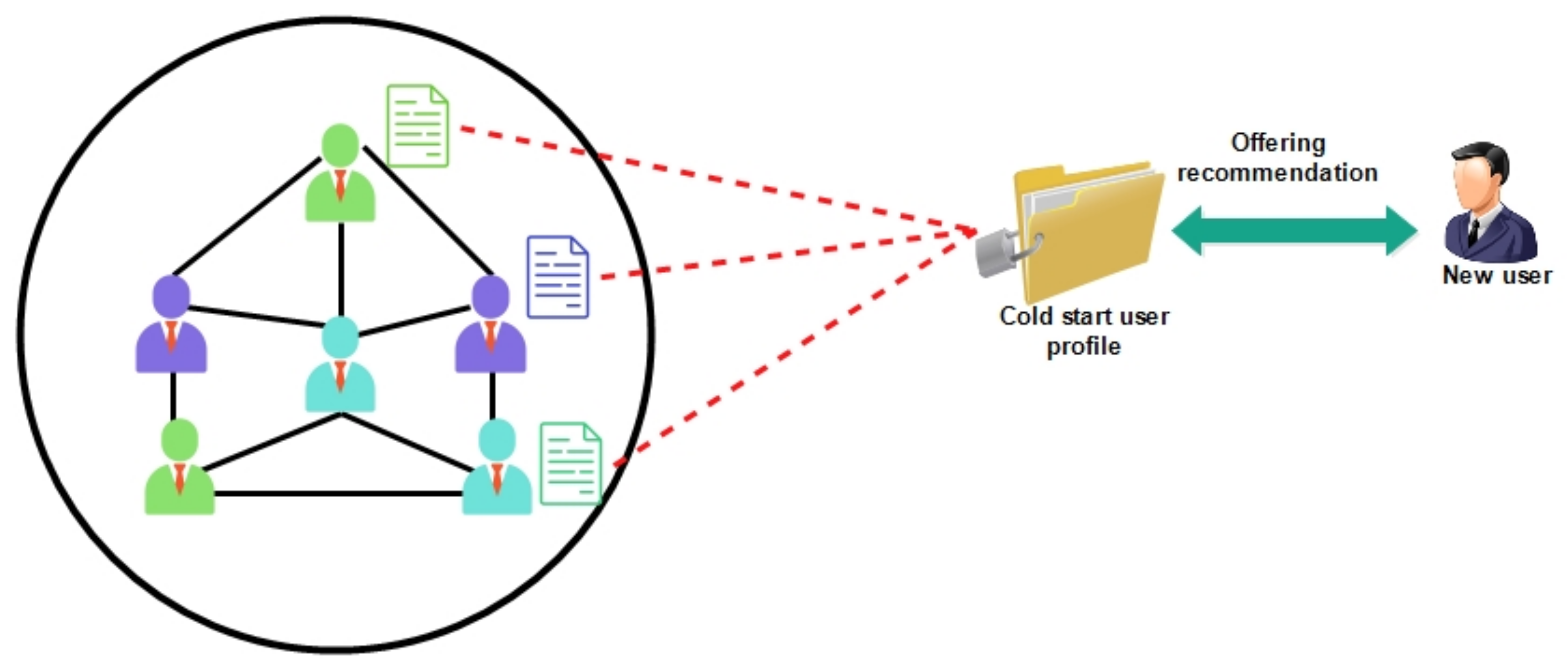
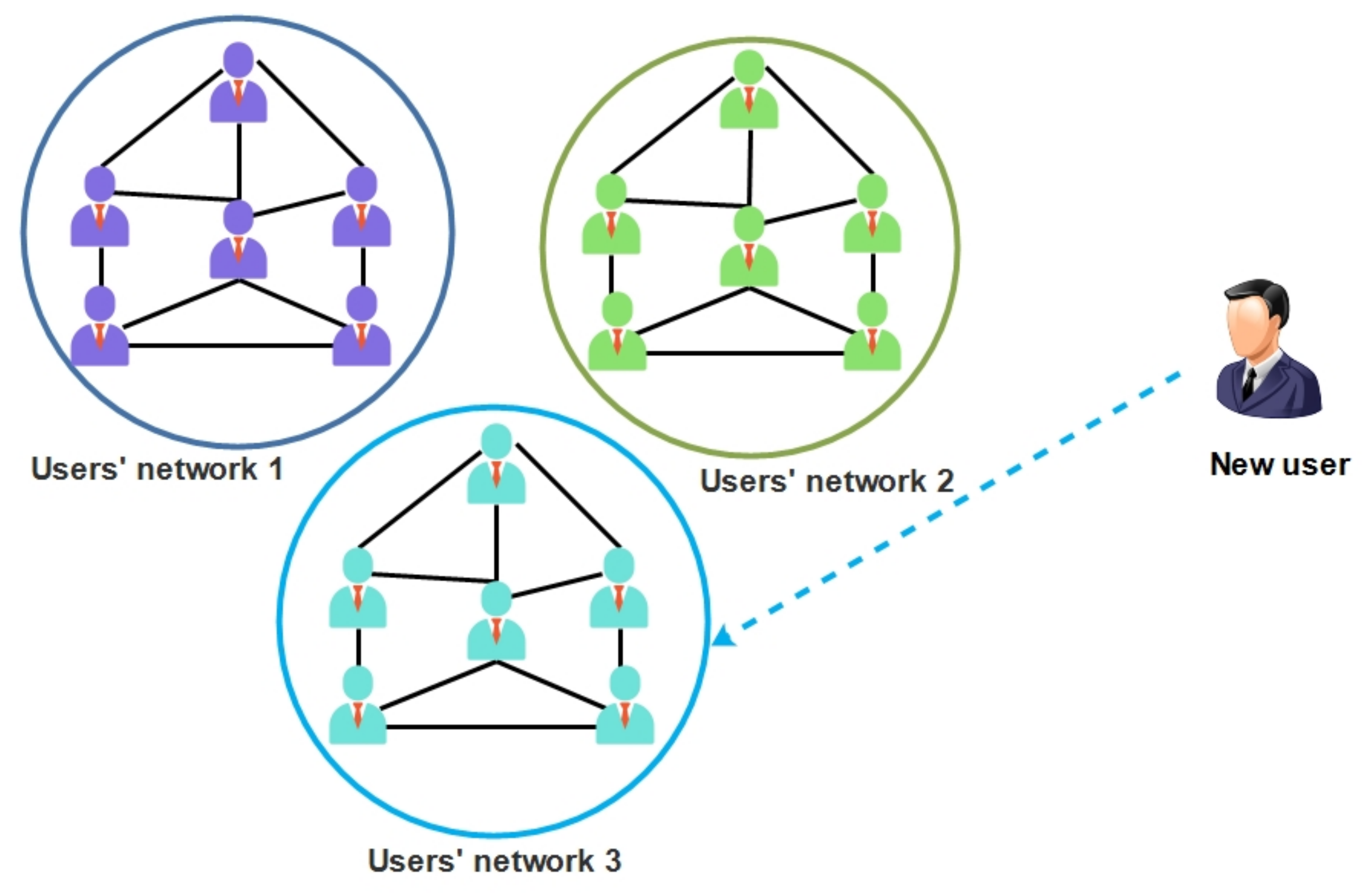
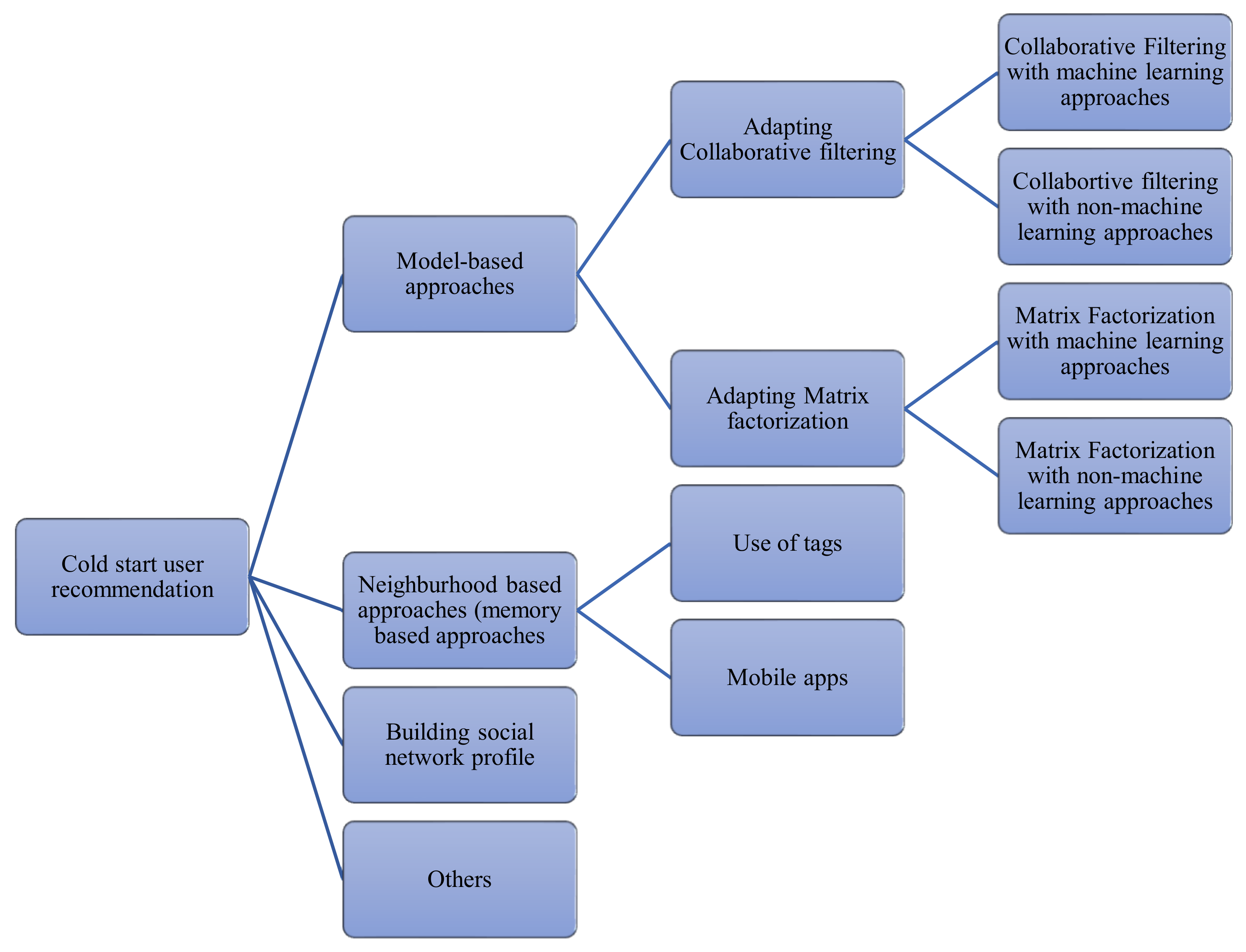
- This study illustrates the three (3) main processes or strategies used in obtaining auxiliary information by adapting traditional filtering and matrix factorization algorithms, typically with machine learning algorithms to build learning prediction models. The understanding of similar or connected user profiles can be used as auxiliary information for building cold start user profile to enable similar recommendation in social networks. Similar users are clustered into sub-groups so that a cold start user could be allocated and inferred to a sub-group having similar profiles for recommendations.
- This study presents the bigger picture of research productivity and outcomes in cold start recommender systems. This study identified the need of key areas that cold start recommendation research is yet weak especially with the use of deep learning approaches, so that researchers and recommender system practitioners could further understand the technicality of recommendation to a new user and serve as motivation in pursuing further investigations.
2. Methodology
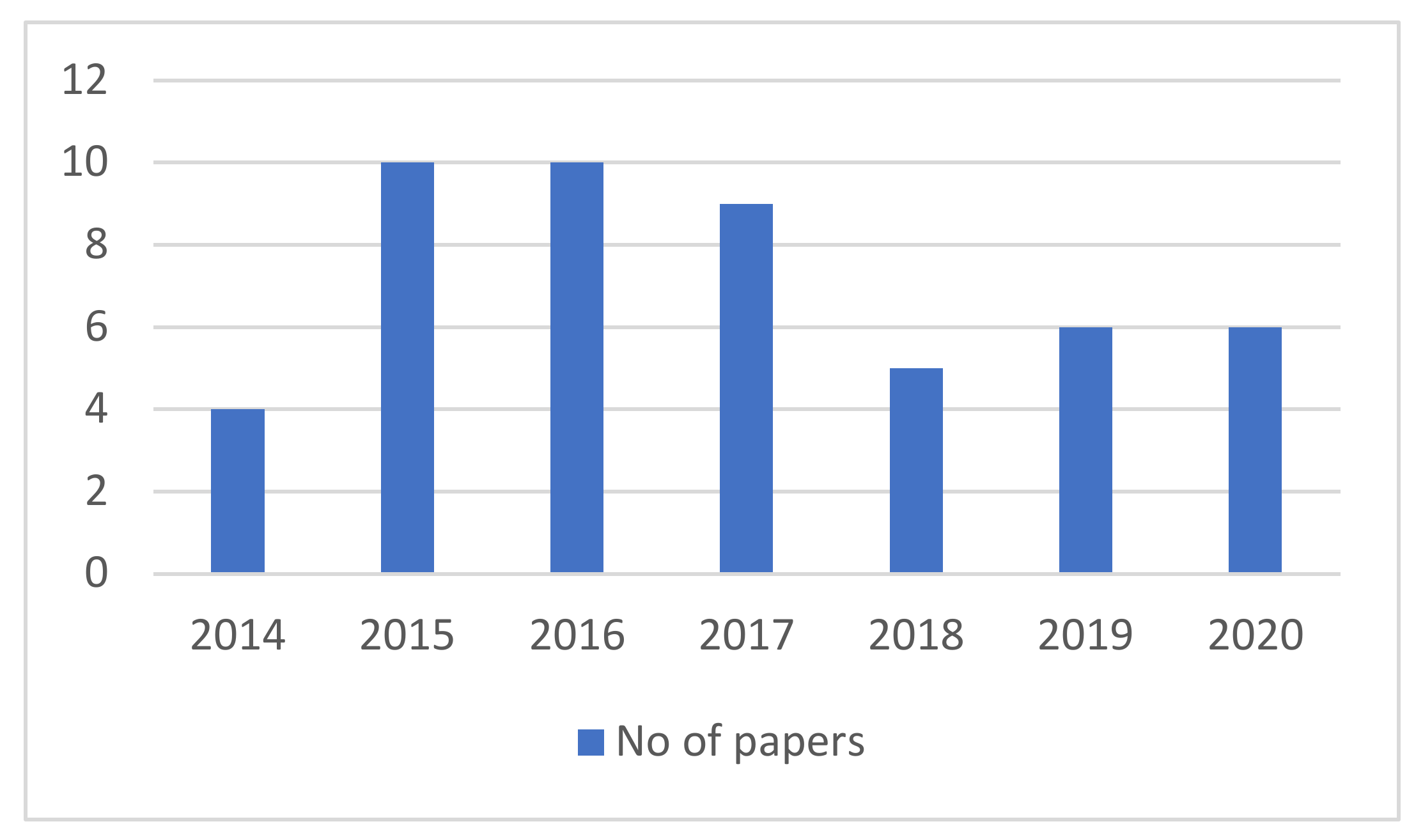
2.1. Literature Search
2.2. Categorization
3. Results
3.1. Adapting Model Based Approaches
3.1.1. Adapting Traditional Filtering Strategies
- a.
- Coupling collaborative filtering with machine learning algorithms:
- b.
- Coupling Collaborative filtering with other algorithms:
3.1.2. Adapting Matrix Factorization Model
- a.
- Coupling Matrix Factorization with machine learning algorithms:
- b.
- Coupling Matrix factorization with non-machine learning algorithms:
3.2. Adapting Memory Based Approaches
- a.
- Tags-based elicitation approach:
- b.
- Cold start recommendation in mobile environment:
3.3. Building Social Network Profile for Cold Start Users
Forming Users Social Circle
3.4. Others
3.5. Pictorial Summary of Findings
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manouselis, N.; Drachsler, H.; Verbert, K.; Duval, E. Recommender Systems for Learning; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Melville, P.; Sindhwani, V. Recommender systems. Encycl. Mach. Learn. 2010, 1, 829–838. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–35. [Google Scholar]
- Desrosiers, C.; Karypis, G. A comprehensive survey of neighborhood-based recommendation methods. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 107–144. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2015; pp. 77–118. [Google Scholar]
- Sun, M.; Li, F.; Lee, J.; Zhou, K.; Lebanon, G.; Zha, H. Learning multiple-question decision trees for cold-start recommendation. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 445–454. [Google Scholar]
- Miranda, T.; Claypool, M.; Gokhale, A.; Mir, T.; Murnikov, P.; Netes, D.; Sartin, M. Combining content-based and collaborative filters in an online newspaper. In Proceedings of the ACM SIGIR Workshop on Recommender Systems; Worchester Polytechnic Institute: Worcester, MA, USA, 1999. [Google Scholar]
- Montaner, M.; López, B.; De La Rosa, J.L. A taxonomy of recommender agents on the internet. Artif. Intell. Rev. 2003, 19, 285–330. [Google Scholar] [CrossRef]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.-H.; Bahadorpour, M. Cold-start problem in collaborative recommender systems: Efficient methods based on ask-to-rate technique. J. Comput. Inf. Technol. 2014, 22, 105–113. [Google Scholar] [CrossRef]
- He, C.; Parra, D.; Verbert, K. Interactive recommender systems: A survey of the state of the art and future research challenges and opportunities. Expert Syst. Appl. 2016, 56, 9–27. [Google Scholar] [CrossRef]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Camacho, L.A.G.; Alves-Souza, S.N. Social network data to alleviate cold-start in recommender system: A systematic review. Inf. Process. Manag. 2018, 54, 529–544. [Google Scholar] [CrossRef]
- Son, L.H. Dealing with the new user cold-start problem in recommender systems: A comparative review. Inf. Syst. 2016, 58, 87–104. [Google Scholar] [CrossRef]
- Idrissi, N.; Zellou, A. A systematic literature review of sparsity issues in recommender systems. Soc. Netw. Anal. Min. 2020, 10, 1–23. [Google Scholar] [CrossRef]
- Khan, M.M.; Ibrahim, R.; Ghani, I. Cross domain recommender systems: A systematic literature review. Acm Comput. Surv. (Csur) 2017, 50, 1–34. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. Acm Comput. Surv. (Csur) 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Haruna, K.; Akmar Ismail, M.; Suhendroyono, S.; Damiasih, D.; Pierewan, A.C.; Chiroma, H.; Herawan, T. Context-aware recommender system: A review of recent developmental process and future research direction. Appl. Sci. 2017, 7, 1211. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Bu, J.; Chen, C.; Cai, D. An exploration of improving collaborative recommender systems via user-item subgroups. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 21–30. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Kim, H.-N.; El-Saddik, A.; Jo, G.-S. Collaborative error-reflected models for cold-start recommender systems. Decis. Support Syst. 2011, 51, 519–531. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Bernal, J. A collaborative filtering approach to mitigate the new user cold start problem. Knowl. -Based Syst. 2012, 26, 225–238. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Tang, J.; Zhang, X.; Xue, X. Addressing cold start in recommender systems: A semi-supervised co-training algorithm. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, QLD, Australia, 6–11 July 2014; pp. 73–82. [Google Scholar]
- Pereira, A.L.V.; Hruschka, E.R. Simultaneous co-clustering and learning to address the cold start problem in recommender systems. Knowl. -Based Syst. 2015, 82, 11–19. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl. -Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef] [Green Version]
- Duricic, T.; Lacic, E.; Kowald, D.; Lex, E. Trust-based collaborative filtering: Tackling the cold start problem using regular equivalence. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 446–450. [Google Scholar]
- Anwaar, F.; Iltaf, N.; Afzal, H.; Nawaz, R. HRS-CE: A hybrid framework to integrate content embeddings in recommender systems for cold start items. J. Comput. Sci. 2018, 29, 9–18. [Google Scholar] [CrossRef]
- Jiang, M.; Cui, P.; Chen, X.; Wang, F.; Zhu, W.; Yang, S. Social recommendation with cross-domain transferable knowledge. IEEETrans. Knowl. Data Eng. 2015, 27, 3084–3097. [Google Scholar] [CrossRef]
- Yang, C.; Zhou, Y.; Chen, L.; Zhang, X.; Chiu, D.M. Social-group-based ranking algorithms for cold-start video recommendation. Int. J. Data Sci. Anal. 2016, 1, 165–175. [Google Scholar] [CrossRef] [Green Version]
- Hannech, A.; Adda, M.; Mcheick, H. Cold-start recommendation strategy based on social graphs. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–7. [Google Scholar]
- Chen, Z.; Shen, L.; Li, F.; You, D. Your neighbors alleviate cold-start: On geographical neighborhood influence to collaborative web service QoS prediction. Knowl. -Based Syst. 2017, 138, 188–201. [Google Scholar] [CrossRef]
- Mu, R. A survey of recommender systems based on deep learning. IEEE Access 2018, 6, 69009–69022. [Google Scholar] [CrossRef]
- Kiran, R.; Kumar, P.; Bhasker, B. DNNRec: A novel deep learning based hybrid recommender system. Expert Syst. Appl. 2020, 144, 113054. [Google Scholar]
- Bathla, G.; Aggarwal, H.; Rani, R. AutoTrustRec: Recommender system with social trust and deep learning using autoEncoder. Multimed. Tools Appl. 2020, 79, 20845–20860. [Google Scholar] [CrossRef]
- Bokde, D.; Girase, S.; Mukhopadhyay, D. Matrix factorization model in collaborative filtering algorithms: A survey. Procedia Comput. Sci. 2015, 49, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Xue, H.-J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep Matrix Factorization Models for Recommender Systems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3203–3209. [Google Scholar]
- Fernández-Tobías, I.; Cantador, I.; Tomeo, P.; Anelli, V.W.; Di Noia, T. Addressing the user cold start with cross-domain collaborative filtering: Exploiting item metadata in matrix factorization. User Modeling User-Adapt. Interact. 2019, 29, 443–486. [Google Scholar] [CrossRef]
- Bi, Y.; Song, L.; Yao, M.; Wu, Z.; Wang, J.; Xiao, J. A Heterogeneous Information Network based Cross Domain Insurance Recommendation System for Cold Start Users. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 2211–2220. [Google Scholar]
- Ocepek, U.; Rugelj, J.; Bosnić, Z. Improving matrix factorization recommendations for examples in cold start. Expert Syst. Appl. 2015, 42, 6784–6794. [Google Scholar] [CrossRef]
- Peng, F.; Lu, J.; Wang, Y.; Yi-Da Xu, R.; Ma, C.; Yang, J. N-dimensional Markov random field prior for cold-start recommendation. Neurocomputing 2016, 191, 187–199. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, Z.; Zuo, W.; Yue, L.; Liang, S.; Li, X. Joint Personalized Markov Chains with social network embedding for cold-start recommendation. Neurocomputing 2020, 386, 208–220. [Google Scholar] [CrossRef]
- Chou, S.-Y.; Yang, Y.-H.; Jang, J.-S.R.; Lin, Y.-C. Addressing cold start for next-song recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 115–118. [Google Scholar]
- Zhao, W.X.; Li, S.; He, Y.; Chang, E.Y.; Wen, J.-R.; Li, X. Connecting social media to e-commerce: Cold-start product recommendation using microblogging information. Ieee Trans. Knowl. Data Eng. 2015, 28, 1147–1159. [Google Scholar] [CrossRef] [Green Version]
- Mirbakhsh, N.; Ling, C.X. Improving top-n recommendation for cold-start users via cross-domain information. Acm Trans. Knowl. Discov. Data (Tkdd) 2015, 9, 1–19. [Google Scholar] [CrossRef]
- Li, C.-T.; Hsu, C.-T.; Shan, M.-K. A cross-domain recommendation mechanism for cold-start users based on partial least squares regression. Acm Trans. Intell. Syst. Technol. (Tist) 2018, 9, 1–26. [Google Scholar] [CrossRef]
- Zhu, F.; Wang, Y.; Chen, C.; Liu, G.; Orgun, M.; Wu, J. A deep framework for cross-domain and cross-system recommendations. arXiv, 2020; arXiv:2009.06215. [Google Scholar]
- Barjasteh, I.; Forsati, R.; Masrour, F.; Esfahanian, A.-H.; Radha, H. Cold-start item and user recommendation with decoupled completion and transduction. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 91–98. [Google Scholar]
- Rana, C.A.Q.; Salima, H.; Usama, F.; Hammam, C. From a “cold” to a “warm” start in recommender systems. In Proceedings of the 2014 IEEE 23rd International WETICE Conference, Parma, Italy, 23–25 June 2014; pp. 290–292. [Google Scholar]
- Zhu, J.; Zhang, J.; Zhang, C.; Wu, Q.; Jia, Y.; Zhou, B.; Philip, S.Y. CHRS: Cold start recommendation across multiple heterogeneous information networks. IEEE Access 2017, 5, 15283–15299. [Google Scholar] [CrossRef]
- Kumbhar, N.; Belerao, K. Microblogging Reviews Based Cross-Lingual Sentimental Classification for Cold-Start Product Recommendation. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 1–18 August 2017; pp. 1–4. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y.; Xu, J. Enabling kernel-based attribute-aware matrix factorization for rating prediction. IEEE Trans. Knowl. Data Eng. 2016, 29, 798–812. [Google Scholar] [CrossRef]
- Roy, S.; Guntuku, S.C. Latent factor representations for cold-start video recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 99–106. [Google Scholar]
- Ji, K.; Shen, H. Jointly modeling content, social network and ratings for explainable and cold-start recommendation. Neurocomputing 2016, 218, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Yuan, D. A novel matrix factorization recommendation algorithm fusing social trust and behaviors in micro-blogs. In Proceedings of the 2017 IEEE 2nd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 28–30 April 2017; pp. 283–287. [Google Scholar]
- Tomeo, P.; Fernández-Tobías, I.; Di Noia, T.; Cantador, I. Exploiting linked open data in cold-start recommendations with positive-only feedback. In Proceedings of the 4th Spanish Conference on Information Retrieval, Granada, Spain, 14–16 June 2016; pp. 1–8. [Google Scholar]
- Ostuni, V.C.; Di Noia, T.; Di Sciascio, E.; Mirizzi, R. Top-n recommendations from implicit feedback leveraging linked open data. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 85–92. [Google Scholar]
- Meymandpour, R.; Davis, J.G. Enhancing Recommender Systems Using Linked Open Data-Based Semantic Analysis of Items. In Proceedings of the 3rd Australasian Web Conference (AWC 2015), Sydney, Australia, 27–30 January 2015; pp. 11–17. [Google Scholar]
- Nazari, Z.; Charbuillet, C.; Pages, J.; Laurent, M.; Charrier, D.; Vecchione, B.; Carterette, B. Recommending Podcasts for Cold-Start Users Based on Music Listening and Taste. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Sydney, Australia, 27–30 January 2015; pp. 1041–1050. [Google Scholar]
- Kim, B.S.; Kim, H.; Lee, J.; Lee, J.-H. Improving a recommender system by collective matrix factorization with tag information. In Proceedings of the 2014 Joint 7th International Conference on Soft Computing and Intelligent Systems (SCIS) and 15th International Symposium on Advanced Intelligent Systems (ISIS), Kitakyushu, Japan, 3–6 December 2014; pp. 980–984. [Google Scholar]
- Aggarwal, C.C. Neighborhood-based collaborative filtering. In Recommender Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 29–70. [Google Scholar]
- Zhu, T.; Ren, Y.; Zhou, W.; Rong, J.; Xiong, P. An effective privacy preserving algorithm for neighborhood-based collaborative filtering. Future Gener. Comput. Syst. 2014, 36, 142–155. [Google Scholar] [CrossRef]
- Rosli, A.N.; You, T.; Ha, I.; Chung, K.-Y.; Jo, G.-S. Alleviating the cold-start problem by incorporating movies facebook pages. Clust. Comput. 2015, 18, 187–197. [Google Scholar] [CrossRef]
- Belém, F.M.; Heringer, A.G.; Almeida, J.M.; Gonçalves, M.A. Exploiting syntactic and neighbourhood attributes to address cold start in tag recommendation. Inf. Process. Manag. 2019, 56, 771–790. [Google Scholar] [CrossRef]
- Elahi, M.; Hosseini, R.; Rimaz, M.H.; Moghaddam, F.B.; Trattner, C. Visually-Aware Video Recommendation in the Cold Start. In Proceedings of the 31st ACM Conference on Hypertext and Social Media, Virtual Event, 13–15 July 2020; pp. 225–229. [Google Scholar]
- Baeza-Yates, R.; Jiang, D.; Silvestri, F.; Harrison, B. Predicting the next app that you are going to use. In Proceedings of the eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 285–294. [Google Scholar]
- Liu, J.; Shi, J.; Cai, W.; Liu, B.; Pan, W.; Yang, Q.; Ming, Z. Transfer Learning from APP Domain to News Domain for Dual Cold-Start Recommendation. In Proceedings of the RecSysKTL, Como Italy, 27 August 2017; pp. 38–41. [Google Scholar]
- Han, D.; Li, J.; Li, W.; Liu, R.; Chen, H. An app usage recommender system: Improving prediction accuracy for both warm and cold start users. Multimed. Syst. 2019, 25, 603–616. [Google Scholar] [CrossRef]
- Tu, Z.; Fan, Y.; Li, Y.; Chen, X.; Su, L.; Jin, D. From fingerprint to footprint: Cold-start location recommendation by learning user interest from app data. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–22. [Google Scholar] [CrossRef]
- Sassi, I.B.; Mellouli, S.; Yahia, S.B. Context-aware recommender systems in mobile environment: On the road of future research. Inf. Syst. 2017, 72, 27–61. [Google Scholar] [CrossRef]
- Woerndl, W.; Huebner, J.; Bader, R.; Gallego-Vico, D. A model for proactivity in mobile, context-aware recommender systems. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 273–276. [Google Scholar]
- Woerndl, W.; Brocco, M.; Eigner, R. Context-aware recommender systems in mobile scenarios. Int. J. Inf. Technol. Web Eng. (Ijitwe) 2009, 4, 67–85. [Google Scholar] [CrossRef]
- Bouneffouf, D.; Bouzeghoub, A.; Gançarski, A.L. A contextual-bandit algorithm for mobile context-aware recommender system. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; pp. 324–331. [Google Scholar]
- Bouneffouf, D.; Bouzeghoub, A.; Gançarski, A.L. Hybrid-ε-greedy for mobile context-aware recommender system. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Kuala Lumpur, Malaysia, 29 May 2012; pp. 468–479. [Google Scholar]
- Del Carmen Rodríguez-Hernández, M.; Ilarri, S. AI-based mobile context-aware recommender systems from an information management perspective: Progress and directions. Knowl. -Based Syst. 2021, 215, 106740. [Google Scholar] [CrossRef]
- Khan, A.; Ahmad, A.; Rahman, A.U.; Alkhalil, A. A mobile cloud framework for context-aware and portable recommender system for smart markets. In Smart Infrastructure and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 283–309. [Google Scholar]
- Lin, J.; Sugiyama, K.; Kan, M.-Y.; Chua, T.-S. New and improved: Modeling versions to improve app recommendation. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, QLD, Australia, 6–11 July 2014; pp. 647–656. [Google Scholar]
- Liu, B.; Kong, D.; Cen, L.; Gong, N.Z.; Jin, H.; Xiong, H. Personalized mobile app recommendation: Reconciling app functionality and user privacy preference. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 315–324. [Google Scholar]
- Cao, D.; He, X.; Nie, L.; Wei, X.; Hu, X.; Wu, S.; Chua, T.-S. Cross-platform app recommendation by jointly modeling ratings and texts. Acm Trans. Inf. Syst. (Tois) 2017, 35, 1–27. [Google Scholar] [CrossRef]
- Lin, J.; Sugiyama, K.; Kan, M.-Y.; Chua, T.-S. Addressing cold-start in app recommendation: Latent user models constructed from twitter followers. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 283–292. [Google Scholar]
- Liu, H.; Jing, L.; Wen, J.; Xu, P.; Yu, J.; Ng, M.K. Bayesian Additive Matrix Approximation for Social Recommendation. Acm Trans. Knowl. Discov. Data (Tkdd) 2021, 16, 1–34. [Google Scholar]
- Zhao, G.; Lei, X.; Qian, X.; Mei, T. Exploring users’ internal influence from reviews for social recommendation. IEEE Trans. Multimed. 2018, 21, 771–781. [Google Scholar] [CrossRef]
- Tang, J.; Hu, X.; Liu, H. Social recommendation: A review. Soc. Netw. Anal. Min. 2013, 3, 1113–1133. [Google Scholar] [CrossRef]
- Victor, P.; De Cock, M.; Cornelis, C. Trust and recommendations. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 645–675. [Google Scholar]
- Wang, X.; Lu, W.; Ester, M.; Wang, C.; Chen, C. Social recommendation with strong and weak ties. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 5–14. [Google Scholar]
- Herce-Zelaya, J.; Porcel, C.; Bernabé-Moreno, J.; Tejeda-Lorente, A.; Herrera-Viedma, E. New technique to alleviate the cold start problem in recommender systems using information from social media and random decision forests. Inf. Sci. 2020, 536, 156–170. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Liu, H. Addressing the cold-start problem in location recommendation using geo-social correlations. Data Min. Knowl. Discov. 2015, 29, 299–323. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Tobías, I.; Braunhofer, M.; Elahi, M.; Ricci, F.; Cantador, I. Alleviating the new user problem in collaborative filtering by exploiting personality information. User Modeling User-Adapt. Interact. 2016, 26, 221–255. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.-D.; Sriboonchitta, S.; Huynh, V.-N. Using community preference for overcoming sparsity and cold-start problems in collaborative filtering system offering soft ratings. Electron. Commer. Res. Appl. 2017, 26, 101–108. [Google Scholar] [CrossRef]
- Shapira, B.; Rokach, L.; Freilikhman, S. Facebook single and cross domain data for recommendation systems. User Modeling User-Adapt. Interact. 2013, 23, 211–247. [Google Scholar] [CrossRef]
- Pliakos, K.; Joo, S.-H.; Park, J.Y.; Cornillie, F.; Vens, C.; Van den Noortgate, W. Integrating machine learning into item response theory for addressing the cold start problem in adaptive learning systems. Comput. Educ. 2019, 137, 91–103. [Google Scholar] [CrossRef]
- Salem, Y.; Hong, J.; Liu, W. CSFinder: A cold-start friend finder in large-scale social networks. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 687–696. [Google Scholar]
- Ebesu, T.; Fang, Y. Neural semantic personalized ranking for item cold-start recommendation. Inf. Retr. J. 2017, 20, 109–131. [Google Scholar] [CrossRef]
- Hernando, A.; Bobadilla, J.; Ortega, F.; Gutiérrez, A. A probabilistic model for recommending to new cold-start non-registered users. Inf. Sci. 2017, 376, 216–232. [Google Scholar] [CrossRef]
- Viktoratos, I.; Tsadiras, A.; Bassiliades, N. Combining community-based knowledge with association rule mining to alleviate the cold start problem in context-aware recommender systems. Expert Syst. Appl. 2018, 101, 78–90. [Google Scholar] [CrossRef]
- Hong, D.-G.; Lee, Y.-C.; Lee, J.; Kim, S.-W. CrowdStart: Warming up cold-start items using crowdsourcing. Expert Syst. Appl. 2019, 138, 112813. [Google Scholar] [CrossRef]
- Zhang, X.; Yuan, X.; Li, Y.; Zhang, Y. Cold-Start Representation Learning: A Recommendation Approach with Bert4Movie and Movie2Vec. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2612–2616. [Google Scholar]
- Kulathilake, K.; Abdullah, N.A.; Bandara, A.; Lai, K.W. InNetGAN: Inception Network-Based Generative Adversarial Network for Denoising Low-Dose Computed Tomography. J. Healthc. Eng. 2021, 2021, 9975762. [Google Scholar] [CrossRef] [PubMed]
- Kulathilake, K.S.H.; Abdullah, N.A.; Sabri, A.Q.M.; Lai, K.W. A review on Deep Learning approaches for low-dose Computed Tomography restoration. Complex Intell. Syst. 2021, 1–33. [Google Scholar] [CrossRef]
- Villegas, N.M.; Sánchez, C.; Díaz-Cely, J.; Tamura, G. Characterizing context-aware recommender systems: A systematic literature review. Knowl. -Based Syst. 2018, 140, 173–200. [Google Scholar] [CrossRef]
- Panniello, U.; Tuzhilin, A.; Gorgoglione, M. Comparing context-aware recommender systems in terms of accuracy and diversity. User Modeling User-Adapt. Interact. 2014, 24, 35–65. [Google Scholar] [CrossRef]
- Champiri, Z.D.; Shahamiri, S.R.; Salim, S.S.B. A systematic review of scholar context-aware recommender systems. Expert Syst. Appl. 2015, 42, 1743–1758. [Google Scholar] [CrossRef]
- Zheng, Y.; Mobasher, B.; Burke, R. Emotions in context-aware recommender systems. In Emotions and Personality in Personalized Services; Springer: Berlin/Heidelberg, Germany, 2016; pp. 311–326. [Google Scholar]
- Jäschke, R.; Hotho, A.; Mitzlaff, F.; Stumme, G. Challenges in tag recommendations for collaborative tagging systems. In Recommender Systems for the Social Web; Springer: Berlin/Heidelberg, Germany, 2012; pp. 65–87. [Google Scholar]
- Martins, E.F.; Belém, F.M.; Almeida, J.M.; Gonçalves, M.A. On cold start for associative tag recommendation. J. Assoc. Inf. Sci. Technol. 2016, 67, 83–105. [Google Scholar] [CrossRef]
- Belém, F.M.; Almeida, J.M.; Gonçalves, M.A. A survey on tag recommendation methods. J. Assoc. Inf. Sci. Technol. 2017, 68, 830–844. [Google Scholar] [CrossRef]
- Ji, K.; Shen, H. Addressing cold-start: Scalable recommendation with tags and keywords. Knowl. -Based Syst. 2015, 83, 42–50. [Google Scholar] [CrossRef]
- Abdi, S.; Khosravi, H.; Sadiq, S.; Gasevic, D. Complementing educational recommender systems with open learner models. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 360–365. [Google Scholar]
- Erdt, M.; Fernandez, A.; Rensing, C. Evaluating recommender systems for technology enhanced learning: A quantitative survey. IEEE Trans. Learn. Technol. 2015, 8, 326–344. [Google Scholar] [CrossRef]
- Ghauth, K.I.; Abdullah, N.A. Learning materials recommendation using good learners’ ratings and content-based filtering. Educ. Technol. Res. Dev. 2010, 58, 711–727. [Google Scholar] [CrossRef]
- Ghauth, K.I.; Abdullah, N.A. The effect of incorporating good learners’ ratings in e-Learning content-based recommender System. J. Educ. Technol. Soc. 2011, 14, 248–257. [Google Scholar]
- Albatayneh, N.A.; Ghauth, K.I.; Chua, F.-F. Utilizing learners’ negative ratings in semantic content-based recommender system for e-learning forum. J. Educ. Technol. Soc. 2018, 21, 112–125. [Google Scholar]
- Wan, H.; Yu, S. A recommendation system based on an adaptive learning cognitive map model and its effects. Interact. Learn. Environ. 2020, 1–19. [Google Scholar] [CrossRef]
- Rahman, M.M.; Abdullah, N.A. A personalized group-based recommendation approach for Web search in E-learning. IEEE Access 2018, 6, 34166–34178. [Google Scholar] [CrossRef]
- Rasheed, R.A.; Kamsin, A.; Abdullah, N.A. An Approach for Scaffolding Students Peer-Learning Self-Regulation Strategy in the Online Component of Blended Learning. IEEE Access 2021, 9, 30721–30738. [Google Scholar] [CrossRef]
- Rasheed, R.A.; Abdullah, N.A.; Kamsin, A.; Ahmed, M.A.; Yahaya, A.S.; Umar, K. A framework for designing students peer learning self-regulation strategy system for blended courses. In Proceedings of the 2021 1st International Conference on Emerging Smart Technologies and Applications (eSmarTA), Sana’a, Yemen, 10–12 August 2021; pp. 1–5. [Google Scholar]
- Rasheed, R.A.; Kamsin, A.; Abdullah, N.A. Challenges in the online component of blended learning: A systematic review. Comput. Educ. 2020, 144, 103701. [Google Scholar] [CrossRef]
- Haruna, K.; Akmar Ismail, M.; Damiasih, D.; Sutopo, J.; Herawan, T. A collaborative approach for research paper recommender system. PLoS ONE 2017, 12, e0184516. [Google Scholar] [CrossRef] [PubMed]
- Champiri, Z.D.; Asemi, A.; Binti, S.S.S. Meta-analysis of evaluation methods and metrics used in context-aware scholarly recommender systems. Knowl. Inf. Syst. 2019, 61, 1147–1178. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, Z.; Chao, Y.; Qian, X. CAPER: Context-aware personalized emoji recommendation. IEEE Trans. Knowl. Data Eng. 2020, 33, 3160–3172. [Google Scholar] [CrossRef]
- Wu, Y.; Li, K.; Zhao, G.; Xueming, Q. Personalized long-and short-term preference learning for next POI recommendation. IEEE Trans. Knowl. Data Eng. 2020. [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S/N | Articles | Platform, Data and Domain | Summary of Approaches |
|---|---|---|---|
| Coupling collaborative filtering with machine learning algorithms | |||
| 1 | [9] | Movielens (Movies) | Collaborative filtering algorithms combined with naive bayes and C4.5 classification algorithms |
| 2 | [23] | Movielens (Movies) | Model based collaborative filtering by a context aware to elicit auxiliary data |
| 3 | [24] | Netflix, jetstar, Movielens (Movies) | User demographic information together with collaborative filtering to address cold start problem using a SCOAL (Simultaneous co-clustering and learning) algorithm |
| 4 | [25] | Not stated | Adapting collaborative filtering using explicit trusted user neighbor data |
| 5 | [26] | Netflix (Movies) | Collaborative filtering merged with machine learning algorithms-deep learning algorithm (deep neural network) SADE, timeSVD++ |
| 6 | [27] | Opinions | Collaborative filtering merged with K-nearest neighbors |
| 7 | [28] | Collaborative filtering with word2vec unsupervised machine learning algorithm | |
| Coupling collaborative filtering with other approaches | |||
| 1 | [29] | Tancent Weibo (Video) | Collaborative filtering merged with a hybrid random walk (HRW) method |
| 2 | [30] | Tancent Weibo (Video) | Collaborative filtering merged with a social group-based algorithm |
| 3 | [31] | Ontological approach | Collaborative filtering adapted with an ontological approach |
| 4 | [32] | WSDream (Web services) | A collaborative filtering web service QoS prediction approach that utilizes geographical neighborhoods knowledge |
| S/N | Articles | Platform, Data and Domain | Summary of Approaches |
|---|---|---|---|
| Coupling matrix factorization with machine learning algorithms | |||
| 1 | [40] | Not stated | Matrix factorization coupled with regression tree and linear regression supervised learning models |
| 2 | [41] | Movielens | Matrix factorization with Markov chain (Markov random field prior (mrf-MF)) |
| 3 | [42] | Social media | Matrix factorization with Markov chain |
| 4 | [43] | Music | Merging Markov chain with matrix factorization model |
| 5 | [44] | Siena weibo (e-commerce) | Cross site (cross domain). Matrix factorization with modified gradient boosting trees and recurrent neural networks |
| 6 | [45] | Not stated | Cluster-based matrix factorization model with K means clustering algorithm for cold start cross domain recommendation |
| 7 | [46] | Videos & DVDs, Books, and Music | Cross-domain recommendation mechanism based partial least squares regression analysis. PLSR coupled with matrix factorization |
| 8 | [47] | Not stated | Cross-domain and cross-system recommendations coupling deep neural network with matrix factorization models |
| Coupling matrix factorization with other approaches | |||
| 1 | [12] | DBpedia | Adapting matrix factorization with open linked data (MF-LOD) |
| 2 | [48] | Not Stated | algorithmic framework based on matrix factorization |
| 3 | [49] | Social media (Twitter) | ISoNTRE—is a framework called intelligent Social Network Transformer into Recommendation Engine is combined with matrix factorization |
| 4 | [50] | Douban movie iMDB (Movies) | CHRS uses a two-step approach to integrate the complementary in both the target and source networks for cold start recommendation utilizing the rich information from these two paths |
| 5 | [51] | Social media platforms (e-commerce) | Cross-domain cold start recommendation based on mapping user feature based matrix factorization from social media and product features from e-commerce website |
| 6 | [52] | Yelp; movielens (Movies) | Developed KAMF that use social links between users for cold start recommendation |
| 7 | [53]. | Movielens (Movies) | Matrix factorization with a content |
| 8 | [54] | Tancient Weibo (Movie) | Neighborhood and matrix factorization (hybrid—memory based and model based) |
| 9 | [55] | Tencent Weibo (microblogs) | Adapted matrix factorization adapted by coupling social behavior and social trust data |
| S/N | Articles | Platform, Data and Domain | Summary of Approaches |
|---|---|---|---|
| 1 | [63] | Facebook (movies) | Proposed a similarity metric for grouping users of the same interest for improving cold start movie recommendation through the use of KNN and K Means algorithms |
| 2 | [64] | Movielens, Elo7 (Movies) | Tag recommendation methods in a cold start scenario through syntactic and neighbourhood-based attributes. |
| 3 | [65] | Youtube (videos) | Video recommendation based on visual tags; visual description of the videos is used for the automatic annotation of the tags using K-Nearest Neighbor algorithm. |
| 4 | [66] | Mobile app | Predicting the next app to be used which involve a technique based on a set of features representing the real-time spatiotemporal contexts sensed by the home screen app for user cold start |
| 5 | [67] | Mobile app | Provides cross domain cold start recommendation for mobile apps from a mobile application domain to a news domain. |
| 6 | [68] | Mobile app | A modified incremental k-nearest neighbors (IkNN) and K-clustering algorithm for predicting next app for cold start |
| 7 | [69] | Mobile app | Location features and user interests are transferred from app usage data for cold-start location recommendation, |
| S/N | Articles | Platform, Data and Domain | Summary of Approaches |
|---|---|---|---|
| 1 | [27] | Opinions | Collaborative filtering merged with k-nearest neighbors |
| 2 | [85] | DBLP, Ciao, Douban, Opinions (Movies, books, music) | The coefficient of Jaccard is adapted as an intrinsic feature of the social network. A customized ranking model of items are formed for generating recommendation to cold start user |
| 3 | [86] | Leveraging the use of social media (Twitter) data to create a behavioral profile and classify users based on their behavior. Decision tree classifier and random forest machine learning techniques | |
| 4 | [87] | Social networks | Geographical distance and social network correlation are leveraged on location based social network LBSNs for building cold start user profile |
| 5 | [88] | Facebook (music, books) | Proposed three approaches to mitigating, which are: personality-based active learning, personality-based matrix factorization and personality-based cross-domain recommendation |
| 6 | [89] | Not stated | Social network data is used with collaborative filtering to exploit community preferences to address cold start recommendation |
| S/N | Articles | Platform, Data and Domain | Summary of Approaches |
|---|---|---|---|
| 1 | [30] | Tancient weibo (video) | Social-group-based algorithm for video recommendation |
| 2 | [59] | Music | Inter domain cross recommendation of using representation of music taste and past music listening for user cold start recommendation |
| 3 | [91] | ERS | Cold start recommendation in online learning adaptive systems using machine learning (classification and regression trees) |
| 4 | [92] | (Movies (yahoo movies)) | Probabilistic approach incorporating deep neural network (DNN) |
| 5 | [93] | Not stated | Probabilistic approach |
| 6 | [94] | Facebook (CARS). Location based) | Rule mining and community-based knowledge for user context-aware recommender systems |
| 7 | [95] | Conversational recommender system (critique-based recommendation) | |
| 8 | [96] | Movielens (Movies) | hybrid model with machine learning algorithms to provide recommendation for crowd workers |
| 9 | [97] | Movie | Movie videos representation using gradient boosting tree |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah, N.A.; Rasheed, R.A.; Nasir, M.H.N.M.; Rahman, M.M. Eliciting Auxiliary Information for Cold Start User Recommendation: A Survey. Appl. Sci. 2021, 11, 9608. https://doi.org/10.3390/app11209608
Abdullah NA, Rasheed RA, Nasir MHNM, Rahman MM. Eliciting Auxiliary Information for Cold Start User Recommendation: A Survey. Applied Sciences. 2021; 11(20):9608. https://doi.org/10.3390/app11209608
Chicago/Turabian StyleAbdullah, Nor Aniza, Rasheed Abubakar Rasheed, Mohd Hairul Nizam Md. Nasir, and Md Mujibur Rahman. 2021. "Eliciting Auxiliary Information for Cold Start User Recommendation: A Survey" Applied Sciences 11, no. 20: 9608. https://doi.org/10.3390/app11209608
APA StyleAbdullah, N. A., Rasheed, R. A., Nasir, M. H. N. M., & Rahman, M. M. (2021). Eliciting Auxiliary Information for Cold Start User Recommendation: A Survey. Applied Sciences, 11(20), 9608. https://doi.org/10.3390/app11209608