1. Introduction
Named Entity Recognition (NER), as a prerequisite for information extraction, is a study aimed at annotating characters in text sequences and finding out entity types. NER as a foundational task was first proposed by Grishman et al. at the sixth in a series of Message Understanding Conferences (MUC-6) [
1] and then expanded in MUC-7 [
2] with four types of entities: time, date, percentage, and value. In the extraction process, researchers found that extracting these valuable entities can be of great use, and NER is the basic work for tasks such as question and answer systems and building knowledge graphs.
In the medical NER task, the early approaches used are rule-based and lexicon-based approaches. That is, scholars in the related fields manually construct some rule templates to recognize entities in the text by pattern matching or string matching. In the medical field, the entities involved are mainly entity types such as drug names, disease names, drug doses, symptom names, etc. Since there are many fixed proper names in this field, researchers initially used a dictionary and rule-based approach in the medical field. As many of the rules used need to be developed by experienced experts, these efforts are quite costly and each domain has different rules that are difficult to transfer to other domains. Because of the capability to automatically learn text features of the deep learning models, deep learning based NER methods have become a hot research topic [
3].
As a classical sequence labeling task, NER is a very fundamental technology in many high level NLP applications [
4]. The deep learning based NER models mostly consist of three parts. The first one is the embedding stage. In this stage, we map words into distributed representations and a series of Pre-trained Language Models (PLMs) are proposed to learn contextual word representations. GPT [
5] selects Transformer [
6] to extract one-way text information and achieves great performance. In addition, BERT [
7] has also achieved good results under many NLP tasks which uses CBOW to train a bidirectional language model and MLM to stochastically mask entities in text input. As Chinese has its unique characteristics that differ in various fields such as syntactic relations, semantic relations, and so on [
8], scholars begin to build models that fit Chinese lingual characteristics [
9]. Even though Li et al. [
10] try to prove that tokenization in Chinese has relatively little effect, Sun et al. [
11] propose ERNIE with three masking strategies to better capture multi-granularity semantics. In 2019, Cui et al. [
12] propose BERT with whole word masking which mask all characters included in one Chinese word to adapt to the natural characteristics of Chinese.
The second part is the context encoder module to extract sequence features and then capture the contextual dependencies of the input sequence. In order to make the future state also able to predict the current output, bidirectional RNNs such as Bi-LSTM [
13] and Bi-GRU are proposed. According to the research of Liu et al. [
14], LSTM has great potential for NER for clinical texts because it does not require hand-crafted features. However, the training speed of RNNs is limited by its temporal characteristics, and the advantages of convolutional kernel weight sharing used in CNN models can reduce the computational complexity and multiple convolutional kernels that can be computed in parallel are revalued by scholars [
15,
16].
The third and the last part, namely the inference module, takes representations from the second part and generate the optimal label to finish the process of NER. The Softmax function is a generalization of the binary classification function Sigmoid for multi-classification tasks, aiming at presenting the results of multi-classification in the form of probabilities. As a linear classifier, it is a popular component of many models that treat the process of sequence labeling as a set of independent classification tasks. This leads to neglecting dependencies in nearby labels. Thus, the Conditional Random Fields (CRF) is used to learn the cross-label dependencies, which has been proved to be effective and become a competitive option in the NER task [
17].
However, the semantic information in the text still needs to be acquired via a more efficient approach to improve NER results. To address this problem, this paper proposes BIBC, an NER model that utilizes the latest breakthroughs in the NER field on the diabetes dataset, in order to improve the labeling performance on this task.
Our contributions can be summarized as follows:
We make improvements based on the BiLSTM-CRF model and achieve better performance on the NER task.
We analyze the features of the related models and Ruijin Dataset, and design a new data preprocessing method to address the long text input problem.
We design the BIBC model to better capture both local and global sequence features to further improve the model effectiveness, and experimental results verify the performance on the Ruijin Dataset.
2. Related Work
In 2015, Huang et al. [
18] proposed the classical BiLSTM-CRF sequence annotation model, which uses BiLSTM to extract the sentence distant contextual information, combined with CRF to consider tag dependencies, and obtained the best results at that time. However, since Chinese characters do not have clear separators between them and face difficulties in word separation, the performance of using the classical model directly on Chinese datasets will be deviated. Thus, many scholars in China have optimized and adjusted the model for the characteristics of Chinese datasets. Zhang et al. [
19] designed a Lattice LSTM network structure that combines information about the characters themselves and the words they belong to to mitigate the effects of incorrect word separation. To make full use of the information in the text, Qiang et al. [
20] also proposed to add lexical features to enhance the performance of the neural network model.
Other scholars proposed to use convolutional neural networks [
21] for the task of Chinese entity recognition, using CNNs to extract local features of sequences to solve the impact of semantic deficiencies caused by unseparated Chinese data. Chiu et al. [
13] proposed to use a combination of BiLSTM and CNN models, using CNNs to learn fine-grained features in characters and BiLSTMs to complete the task of sequence annotation. A combined model is proposed by combining the advantages of the models. Ding et al. [
22] used graph neural networks to model the entity recognition task and used external lexicons for feature supplementation during the training process to learn the features inside automatically using the features of the model. Chiu [
13] et al. argue that a dilated convolution network can improve the speed in training and prediction by overlaying CNNs, which can expand the perceptual field of the model. In addition, Strubell et al. [
23] propose an Iterated Dilated Convolutional Neural Network (IDCNN), which makes remarkable improvement in speed and computationally efficiency with a SOTA-level accuracy in an NER task. However, these studies do not consider in an integrated way that fusing models together can capture more complete global and local features.
In recent years, Chinese entity recognition models have been gradually applied to the biomedical field. Entities in the biomedical domain are more specialized than those in other domains for Chinese recognition tasks, and there are a large number of entities with a mixture of numbers, Chinese, English, and symbols, e.g., medication dose entity: ‘500 mg/d’; the entity of the test indicator: ‘>12.4 mmol/L’, etc. The existence of these entities makes the identification of Chinese named entities in the medical field extremely difficult.
To address these difficulties, a number of medical NER models have been investigated. In 2019, Zhang et al. [
24] pre-trained BERT and used the embedding as the input feature of BiLSTM-CRF to solve the problem of medical NER for breast cancer. Li et al. [
25] combined the attention mechanism and BiLSTM for entity extraction from Chinese electronic medical records. The method captured more contextual information about the entities through attention and further improved the model recognition performance using features such as medical lexicon and lexical properties. Ji et al. [
26] added an entity auto-correction algorithm to the attention-Bi-LSTM-CRF model to correct the recognition of entities using historical entity information. In 2020, Li et al. [
27] pre-trained the BERT model using untagged clinical text based on the clinical NER datasets of CCKS-2017 and CCKS-2018, and further improved the model performance using the introduction of dictionary features and root features of Chinese characters. In 2021, Li et al. [
28] used CRF to specify identification rules in the identification of named entities in Chinese electronic medical records, solving the problem of ambiguous classification boundaries. Zhou et al. [
29] proposed a label recalibration strategy and a knowledge distillation technique in the face of insufficient training sets. The label recalibration strategy improves the recall of the weakly labeled dataset in an iterative manner without introducing noise, obtaining two high-quality datasets. In addition, the knowledge distillation technique compresses the recognition models trained from the two datasets into one recognition model, which eventually achieved good results on the CDR and NCBI disease corpus. While the above studies have produced good results, most of them are based on processed medical corpus. In fact, few processed and open-sourced datasets are available due to privacy issues and specialization. In addition, a summary of the models in the related work is shown in
Table 1.
3. Method
3.1. Data Preprocessing
The dataset used in this paper is the diabetes-related literature provided by Ruijin Hospital, which includes textbooks, research papers, and clinical guidelines related to diabetes. This dataset is a chapter-level text, in which there are 15 medical entities, including examination methods, etiology, clinical manifestations, medication methods, and sites.
In NLP tasks, the sentences input to the model need to be of appropriate length. Too short sentence length will lose the feature information of the text, while too large sentence length is not conducive to the model training process. The diabetes-related medical literature used in this paper is chapter-level Chinese text, and an article with thousands or even tens of thousands of words cannot be directly input to the model for training, so it is necessary to divide the long diabetes text and transform it into data suitable for model input.
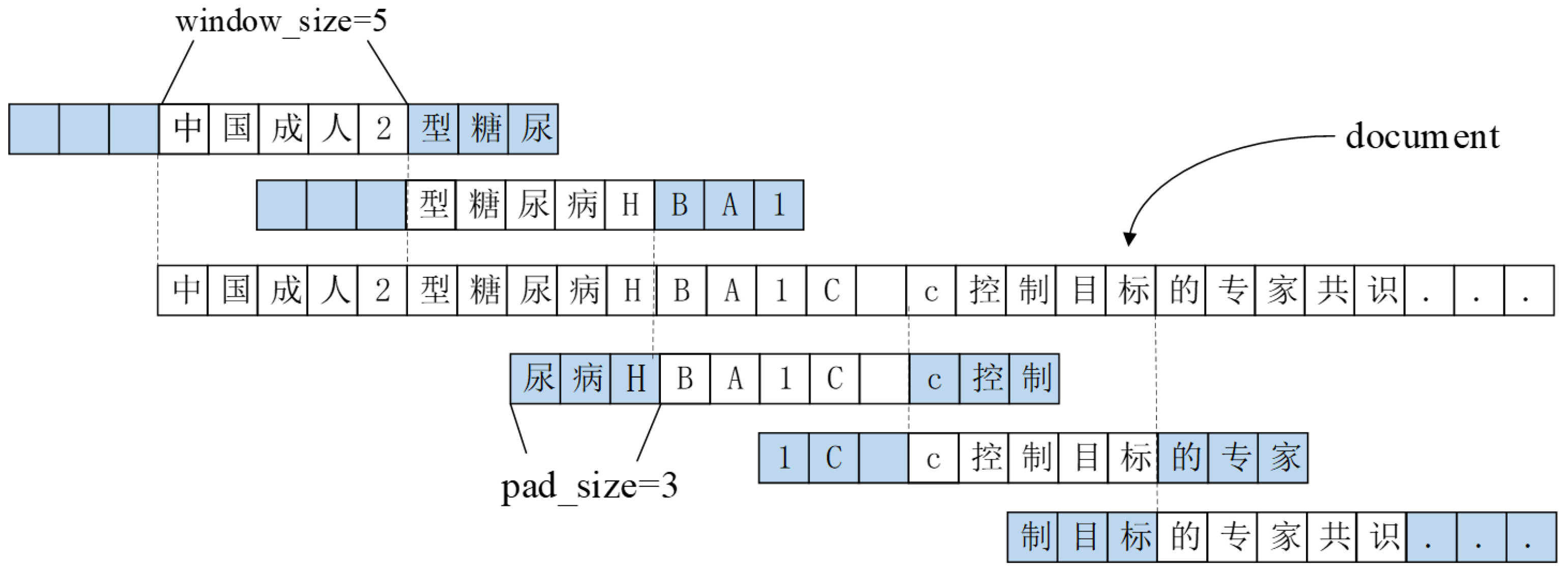
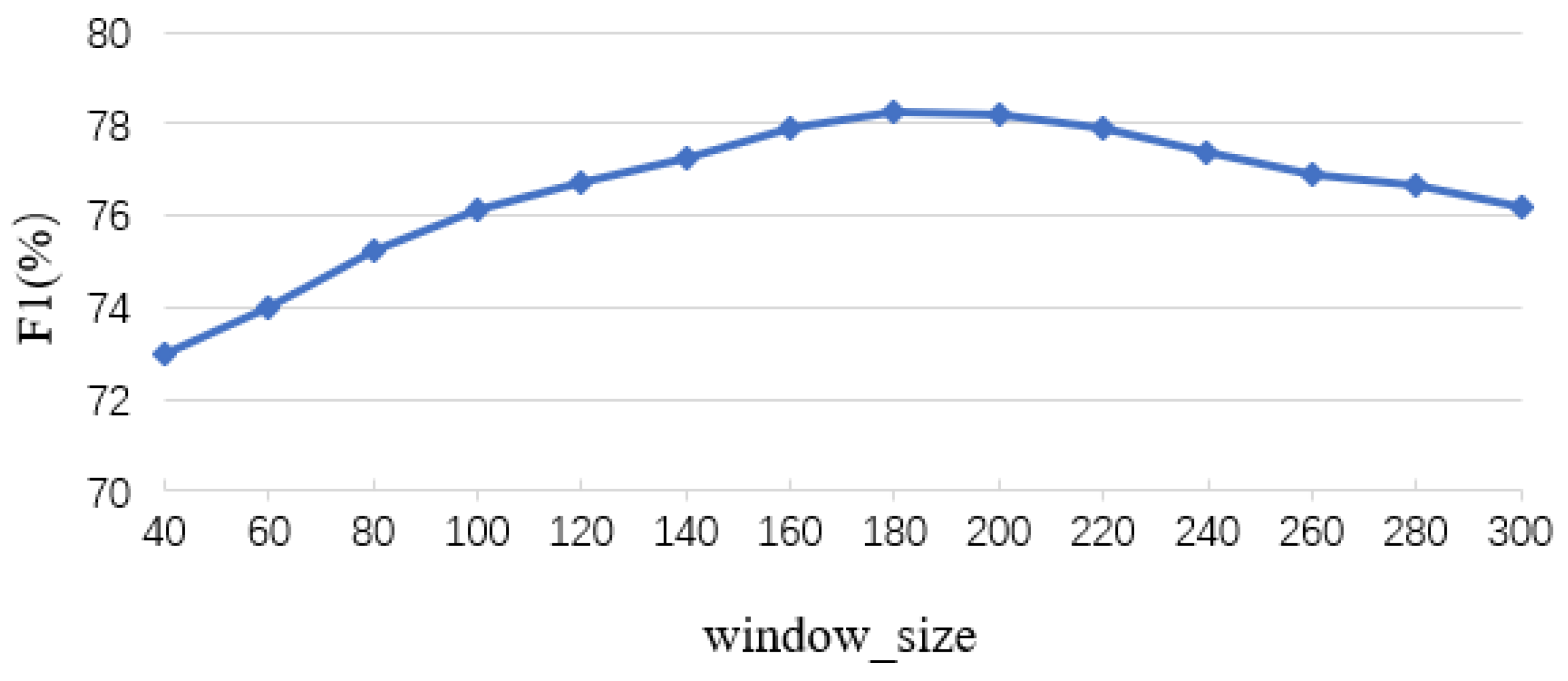
Because of formatting conversion of the original text, there will be line breaks or periods between entities in the article, which leads to a lack of good sentence boundaries. Thus, directly using punctuation to divide the sentences may have the situation of dividing one entity in two sentences, resulting in incomplete entities. To address the problem, in this paper, we propose to use a sliding window size equal to the step size to slice the sentence, and extend the window left and right by a certain length of characters. Thus, the length of the sentence can be controlled and all have certain contextual information, avoiding the case of entity segmentation. The specific division method is shown in
Figure 1, in which the size of the sliding window (
) is 5, the number of characters extended to the left and right of the sentence (
) is 3, and the final sentence length obtained is
.
The sentences obtained from the above division are labeled in BIO mode, and the characters in the sequence are labeled with “B-X”, “I-X”, or “O”. The label “B-X” means the corresponding character is at the beginning of the entity, “I-X” means the corresponding character is in the middle of the entity, and “O” means the character does not belong to any entity.
3.2. Model
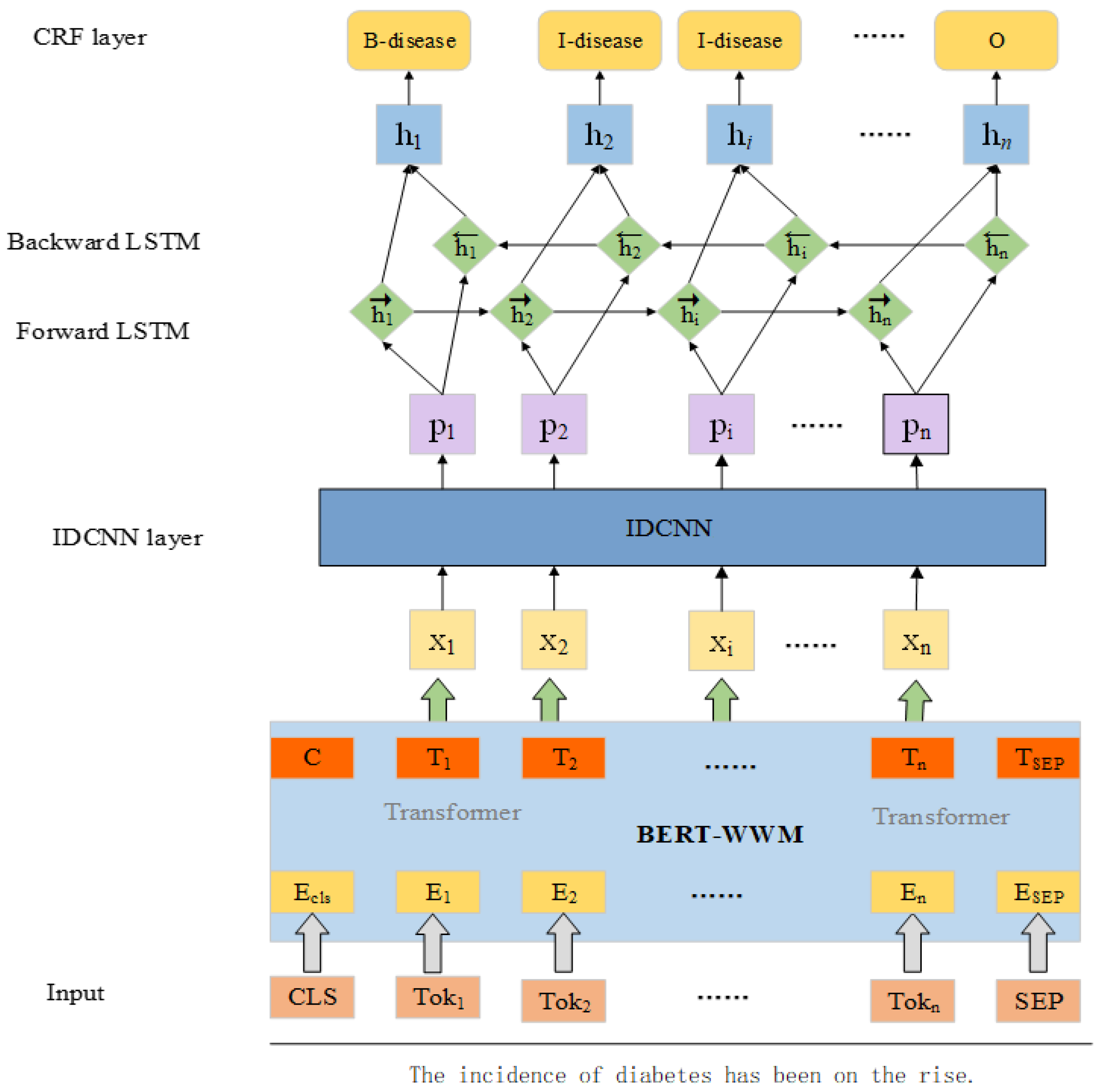
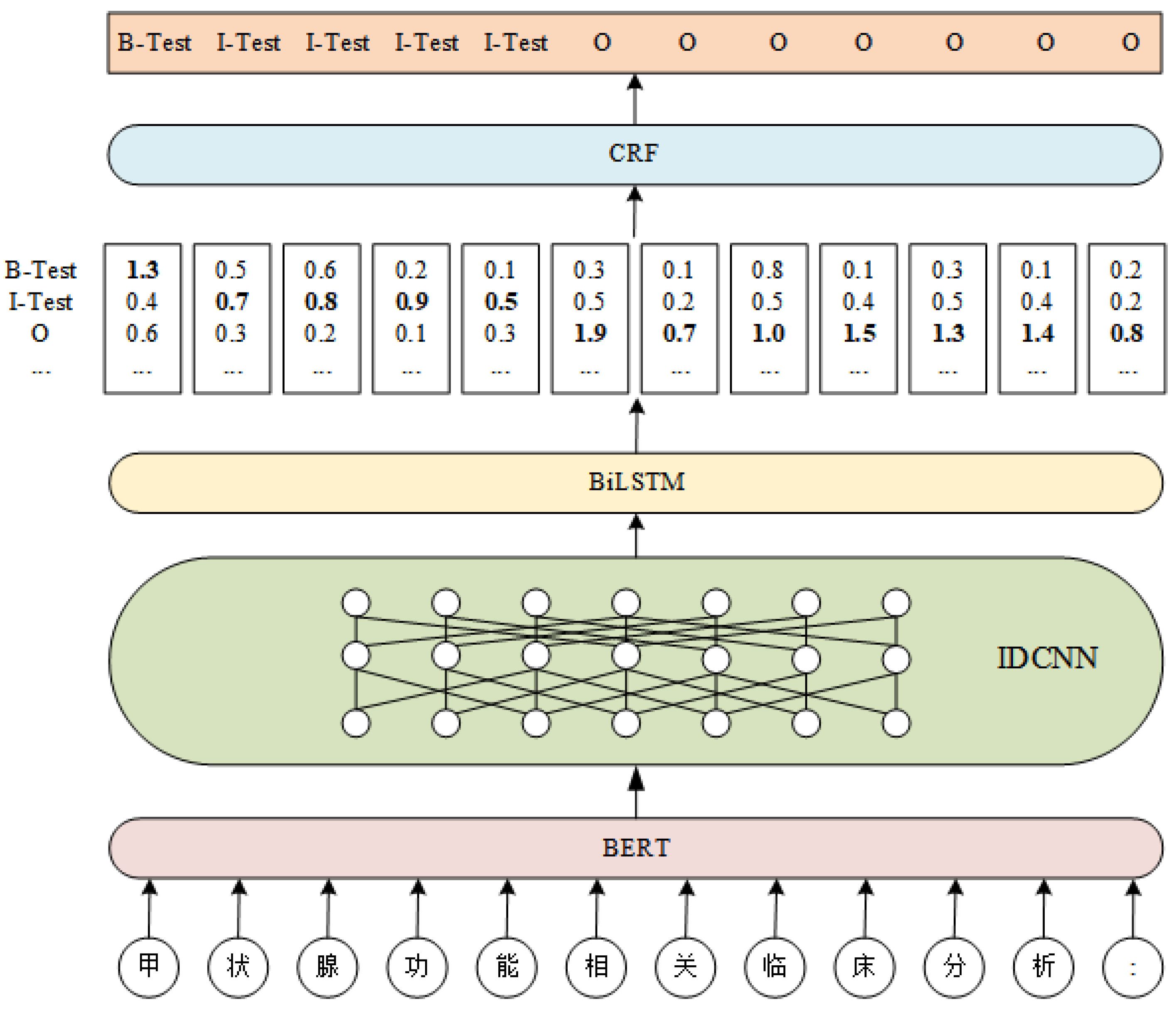
The overall architecture of the proposed model named BIBC for NER is shown in
Figure 2. As is shown by the figure, the whole model structure consists of four parts, namely BERT, IDCNN, bidirectional LSTM, and CRF. A modified BERT-WWM model is used to train on a massive unlabeled corpus for feature supplementation, which greatly enhances the semantic representation between words or phrases through deep and continuous learning. In addition, the IDCNN layer is added to make the model take into account both local and global features by IDCNN and bidirectional LSTM, thus making the whole model achieve better results on diabetes medical literature. The specific implementation process of the BIBC-based named entity recognition model consists of the following parts:
Firstly, the sentences are input to the BERT-WWM pre-trained language model based on whole-word masking for pre-training to obtain word vectors that better match the Chinese expressions.
The obtained vectors are then sent into the IDCNN layer to obtain the local information of the sentences.
The vector sequences obtained from IDCNN layer become the input to BiLSTM to further encode the global sequence features of the sentences.
Finally, the entities are labeled using the label transfer function of CRF and the feature information extracted by each network to obtain a globally optimal label sequence.
3.2.1. Pre-Trained Language Model BERT
The BERT model uses a deep bi-directional Transformer network structure. For each word in the sentence, it can well calculate the interrelationship and importance with other words, and then obtain a new feature of a word. This feature vector contains more relationships and weights, so it can represent the polysemy of words.
BERT precedes each input sentence with a [CLS] marker symbol, which is used to represent the features of the whole sequence of the input, and we use this representation in the downstream target task as well. Between two sentences is the [SEP] symbol, which is used to split the two sentences. BERT is able to obtain some temporal features through the position vector, so that features are learned for different word contexts, and finally the multisense words are represented by different vectors.
One of the tasks of BERT pre-training is Masked language model, which masks a word in a sequence and then predicts it according to the context. The smallest token in Chinese data are a word, and a word consists of many Chinese characters, which contains a lot of information, so, for Chinese data, it is often necessary to mask a word and then predict it. In this part, we follow Cui et al. [
12] using BERT-WWM, a derivative model of BERT. The model makes improvements to alleviate the shortcomings of BERT in pre-training by masking only part of the tokens, and uses a full word masking method in Chinese text.
3.2.2. IDCNN Layer
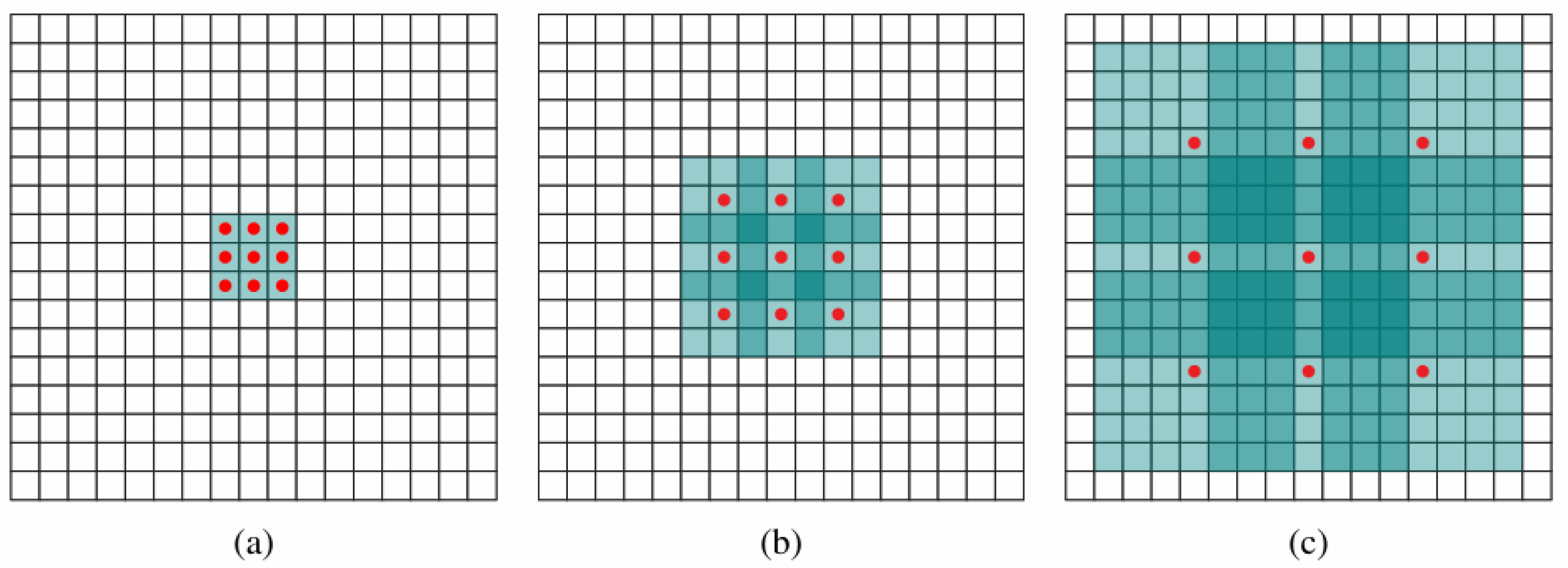
Dilated Convolutional Neural Networks (DCNN) [
30] were initially applied in the field of image segmentation, and it mainly changes the use of convolutional kernels of CNNs. The DCNN expands the perceptual field of view by adding a width to the convolutional kernel, ignoring only the information on the convolutional kernel, and no longer performs convolutional operations on the continuous region of the input matrix like the ordinary CNN’s convolutional kernel.
As is shown in
Figure 3a, it is a
1-dilated convolution, which convolves on a contiguous region of the input data like the general CNN convolution kernel;
Figure 3b corresponds to a 2-dilated convolution, where the size of the convolution kernel remains unchanged, but the width is increased, so the perceptual field of view is widened as well. The 4-dilated convolution shown in
Figure 3c increases the perceptual field of view while keeping the convolution kernel unchanged. In the three figures, only the data in the nine red dot regions are focused on, and the weight of the data in the middle part is set to 0.
From our analysis, the convolutional operation of traditional CNN, when stride is set to 1, the three layers of convolutional kernel can act in a range of , and the perceptible area and the number of layers are linearly related. However, in DCNN, the convolutional kernel with width has an exponential relationship between the perceived area and the number of layers, and the perceived field of view expands rapidly. In this way, more information can be obtained with as few layers as possible, solving the problem that ordinary CNNs can only obtain a small amount of information.
In the sequence labeling task, any word in the sentence may have an impact on the current word. CNN is to cover more information in the sequence by increasing the number of layers of convolutional layers, making the network structure more and more complex. Dropout, for example, is also used to prevent overfitting from bringing more hyperparameters, which makes the whole model training even more difficult. DCNN makes the perceptual field of view larger without increasing parameters, and solves the problem of too many parameters without information loss. Generally stacking Dilated CNNs can obtain more information, but this method leads to overfitting, so we choose IDCNN (Iterated Dilated CNN) as an alternative. IDCNN applies the same DCNN structure several times to increase the generalization ability of the model by reusing the same parameters in a cyclic manner. IDCNN structure is composed of four identical Dilated CNN blocks stitched together, where each Dilated CNN block has three convolutional layers inside with dilation widths of 1, 1, and 2, respectively.
In the NER model proposed in this paper, sentences are first pre-trained by BERT-WWM to obtain word vectors, and then input to Iterated Dilated CNN. IDCNN extracts local feature information of sentences by convolutional operations, and the entire perceptual field of view grows exponentially due to the increased width of the convolutional kernel, which reduces a large number of features without losing parameters and increases the training speed of the model. The feature vector with local information obtained by IDCNN is used as the input to BiLSTM to further extract the features of the whole sequence. In the internal IDCNN structure, the word vectors obtained from BERT training are firstly input into the first layer of DCNN, and the results of the first layer processing are output to the second layer of DCNN and other DCNN layers, respectively, and finally the output feature vectors are spliced.
3.2.3. BiLSTM Layer
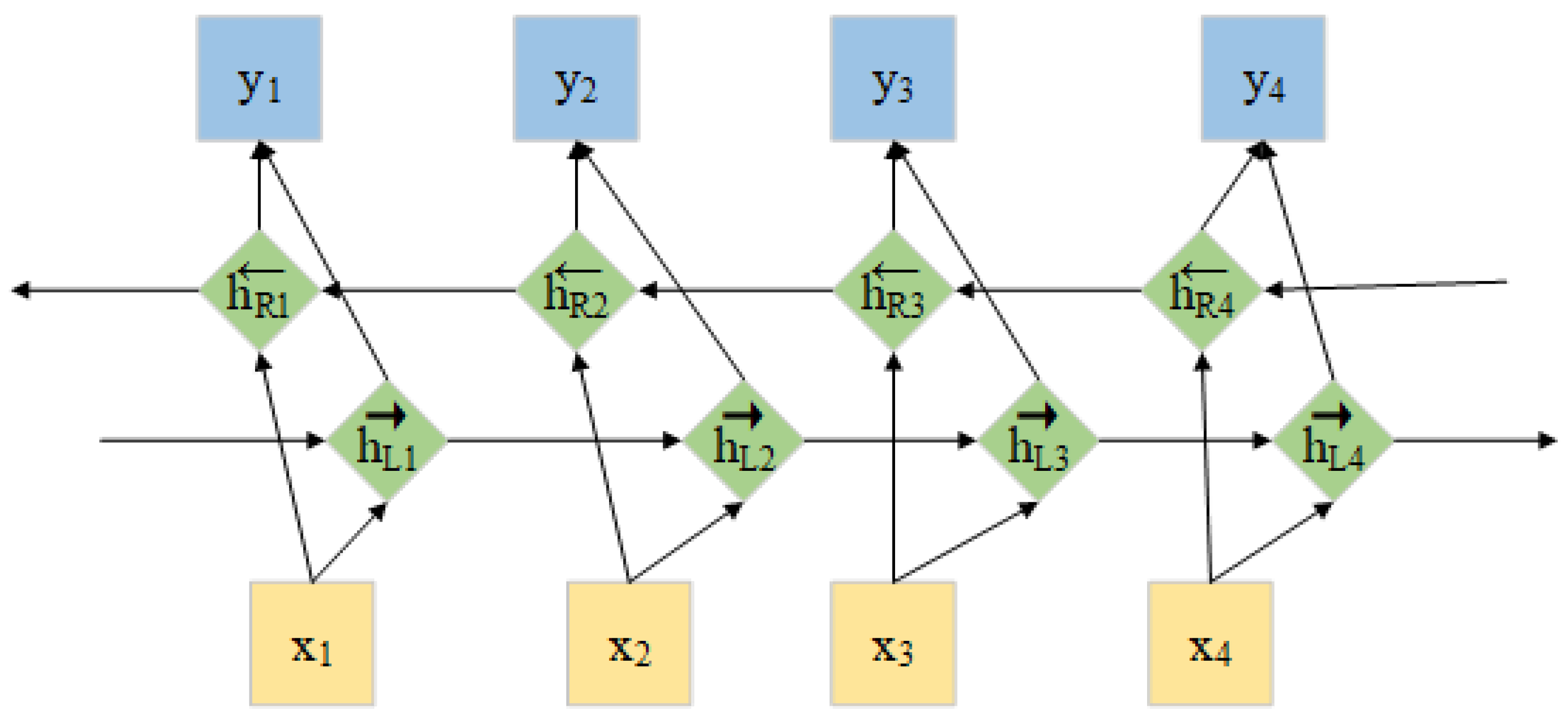
LSTM can only obtain the forward information of the sentence, but most of the time the backward dependency of the sentence also carries a lot of information, so using BiLSTM can obtain both the forward and backward information of the sentence, and each layer of it has the same structure as LSTM, only the order of calculation is different. Thus, each word can contain the complete contextual information, and the network structure of BiLSTM is shown in
Figure 4.
The input sentence sequence is sent into the forward LSTM to obtain a feature vector with sentence forward dependencies
. The feature vector with sentence backward dependencies obtained from the reverse LSTM is denoted as
. The acquired bi-directional feature vectors are stitched together to obtain the new vectors:
Vector Y in Equation (
1) carries sentence-level contextual information and then it is input to CRF to obtain the sequence of sentence labels.
3.2.4. CRF Layer
We add the CRF model to solve the dependency problem between labels by adding many mandatory constraints between the output sequence labels. For instance,
can only be the middle part of the drug entity instead of the beginning of the entity, and the label after it cannot be
,
O is used to indicate that the character does not belong to any entity, etc. For input sentence
, the probability matrix is denoted by
P, and the fractional matrix is the output of BiLSTM.
P is a matrix of
, where
k denotes the total number of the labels and
denotes the probability that the
i-th word in the sentence is labeled as the
j-th tag. For output sequence
, the score can be calculated from Equation (
2):
where
A denotes the label transfer matrix and
denotes probability of label
i transfer to label
. A is a
matrix with start flag
and end flag
added to the label set. The probability of
y is calculated by softmax for all possible tags in the sentence, as shown in Equation (
3):
In the training process, maximizing the log probability of correctly labeled sequences is used as the optimization objective which is calculated in Equation (
4):
where
denotes all possible label sequences for a given sequence
X (including labeled sequences that do not conform to the BIO format). The final output sequence obtained uses the Vibit algorithm to calculate the label sequence with the largest score following Equation (
5):
Finally, a dynamic optimization algorithm is used in the prediction phase to solve for the optimal sequence of labels .
In our proposed NER model, the input sentences are first pre-trained with BERT-WWM to generate a corresponding pre-trained word embedding from the sentences. Afterwards, this word embedding will be sent to the Iterated Dilated CNN to extract multiple local feature information through inflated convolution to obtain the local feature vector of the sentences. To further extract the global features of the whole sentence, BiLSTM is used to obtain the global features of the sentence from the sentence local feature vector combined with the context, and then obtain the classification probability of each word. Finally, it is plugged into the CRF layer containing the sequence transfer probabilities, and constraints are added to the final prediction labels to ensure the correctness of the final annotation results. The input sentence is processed as described in
Figure 5 in the proposed BIBC model.
5. Conclusions and Future Work
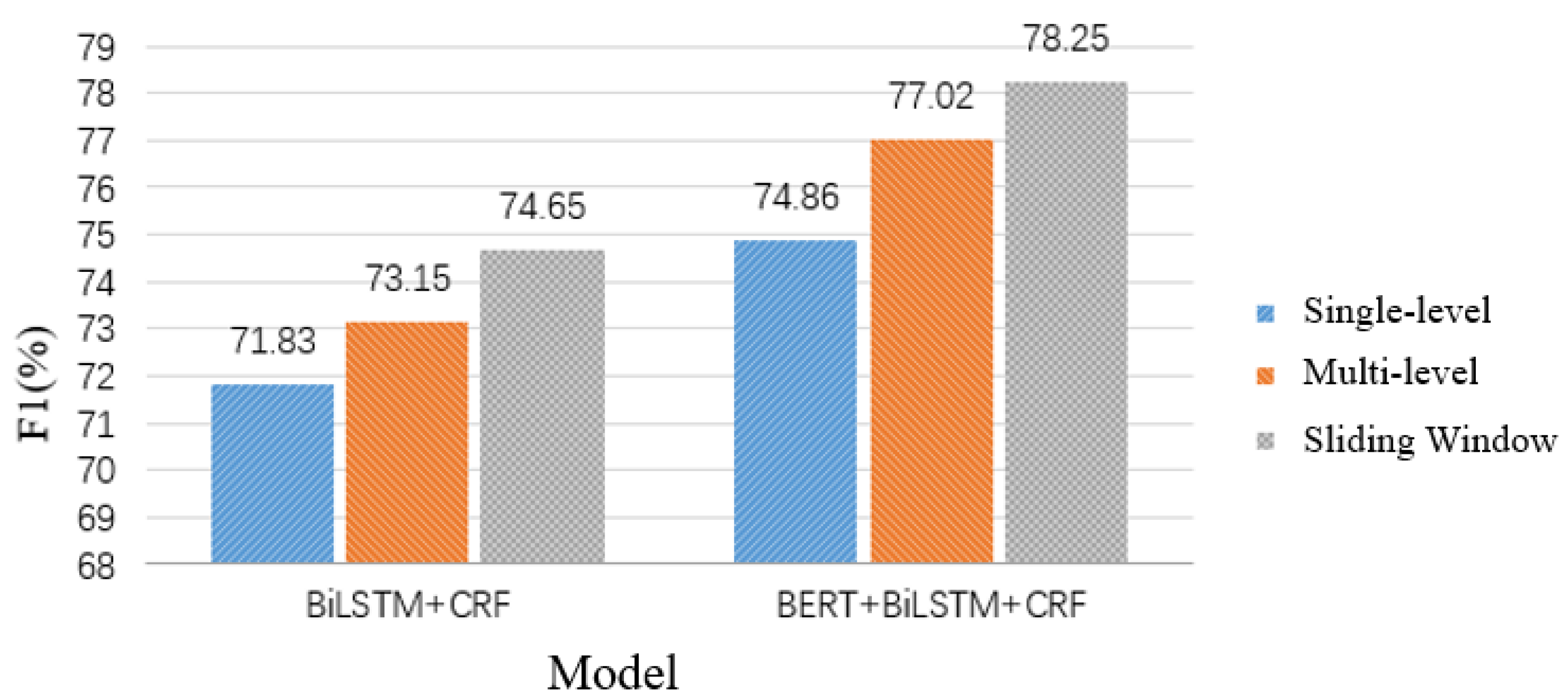
In this paper, we use the current mainstream model BiLSTM-CRF as the base model, and improve on this model to enhance the performance of NER. To address the polysemy phenomenon, we further introduce BERT to train the word vector, which alleviates this problem and also solves the lack of medical data and the non-standardized annotation problem. The performance of NER is greatly improved by using BERT combined with BiLSTM-CRF on the diabetes dataset. We proposed the BIBC model to reduce training parameters and expand the perceptual field, which ensures the combination of both local and global features.
Due to the raw format of the dataset, it took a great amount of work in data preprocessing. The imperfections in this process remain to be added to our study in the future, such as a more precise method to divide the sentences and to consider the sentence grammar, lexicality, and external description, especially medical expert knowledge, etc.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}