
A Language Model for Misogyny Detection in Latin American Spanish Driven by Multisource Feature Extraction and Transformers

 ,
,  , and
, and 
Abstract
:
1. Introduction
- (i)
- reform legal frameworks to criminalize violence against women in political and public life, both online and offline, and to end impunity;
- (o)
- set standards on what constitutes online violence against women in public life so that the media and companies running social media platforms can be held accountable for such content; and
- (p)
- increase the capacity of national statistical systems to collect data regularly and systematically (both online and offline) on violence against women in public life.
2. Related Work
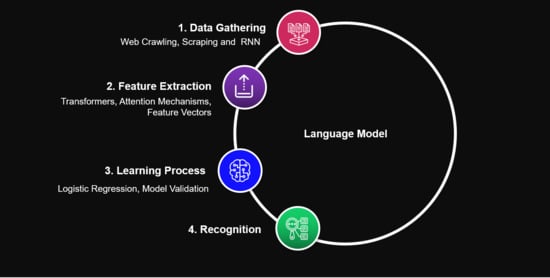
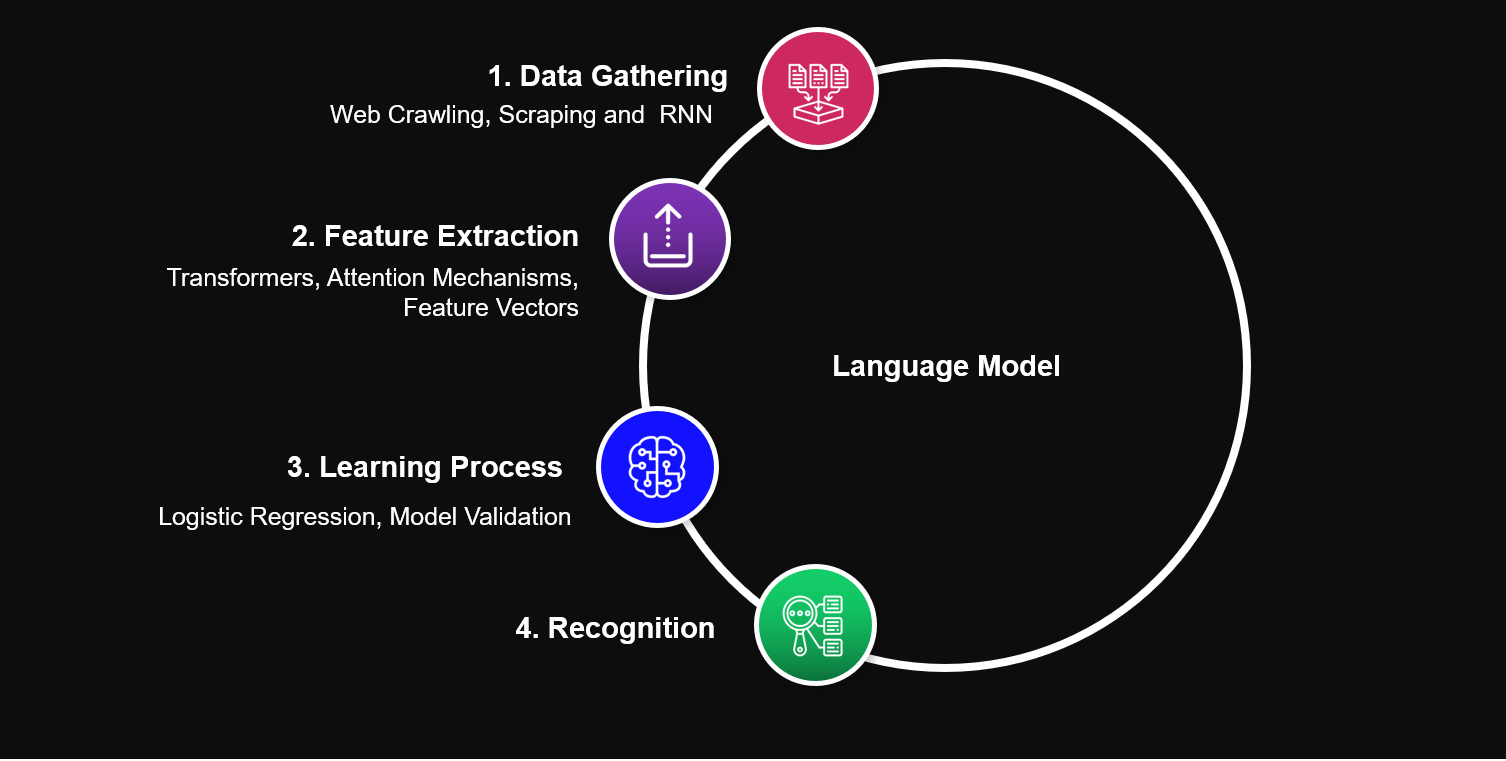
3. Misogyny Detection Approach
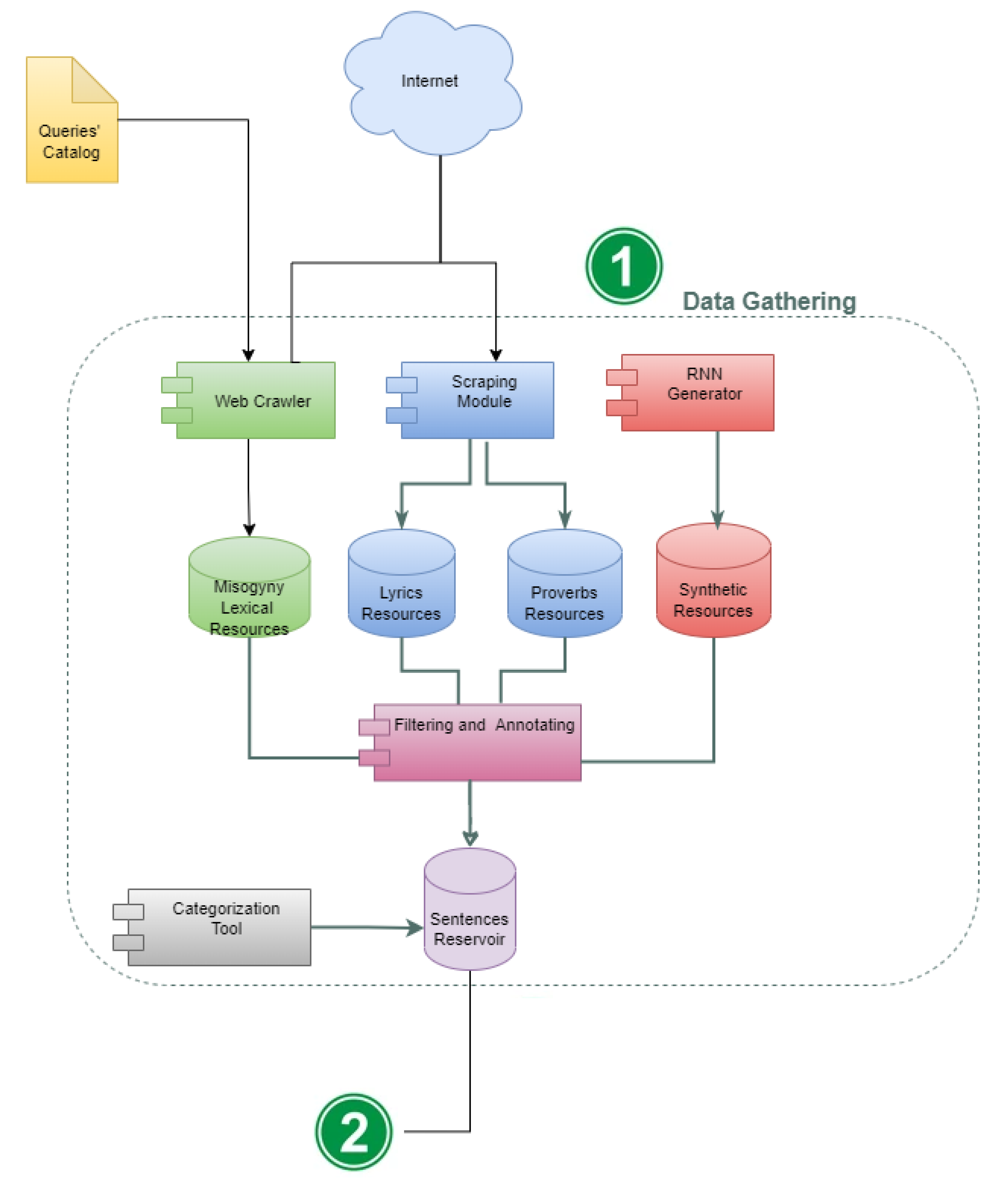
3.1. Data Gathering
- Web Crawler: It allows us to seek and obtain documents (in HTML and PDF format) containing misogynistic expressions. The search of documents is guided by a set of what we have called Queries Catalog. This catalog contains 64 sentences in Spanish made up of key words allusive to misogyny, that intend to focus the search on those documents containing misogynistic elements. For example, sentences of the form: comportamiento misógino (misogynistic behavior), discriminación y violencia contra la mujer (discrimination and violence against women), chistes misóginos (misogynistic jokes), misoginia en la política (misogyny in politics), and so on. Additionally, the catalog also contains a set of n-grams that frequently appeared in text with misogynistic bias, according to a preliminary study reported in [38]. For example, the n-gram eres una puta (you are a whore) and malditas feminazis (fucking feminazis), among others. From the described catalog, the web crawler could find an initial set of 991 documents of different length containing text in Spanish with a high probability of having misogynistic expressions.
- Scraping Module: Unlike the web crawling, scraping is a process that allows us to obtain the content of prior identified resources. Relying on the assumption that the text of several songs could be a suitable resource to find misogynistic expressions (an interesting study is reported in Reference [39]), we focus on identifying lyrics in Spanish singled out as resources with sexist content and violence against women, under the perception of some group of people. In this regard, we use a set of keywords on the search engines of Google, Facebook, Twitter, and YouTube to identify those songs that are commonly associated with misogynistic content. From the results of the searches, we build a catalog of 163 titles of songs with a high probability of including valuable sentences for our purposes; this resource is available at http://shorturl.at/lptzT (accessed on 4 November 2021). Relying on the catalog’s titles, the Scraping Module is executed in order to obtain their corresponding lyrics, from the website https://www.letras.com (accessed on 4 November 2021). We also configured this module to scrap and filter documents available at https://proverbia.net (accessed on 4 November 2021), which are short documents (proverbs) just containing expressions that people often quote for giving advice or some philosophical reflection. Those proverbs with misogynistic content were not considered. It is worth mentioning that all the texts, including the proverbs, were manually revised to avoid including misogynistic phrases.
- RNN Generator: Although the above datasets allowed us to obtain an large number of documents, it was insufficient to encompass the study phenomenon. For this reason, our proposal includes a strategy to overcome the lack of data, based on a Recurrent Neural Network (RNN) capable of learning the intrinsic semantic of misogynistic expressions contained within the collected lyrics and generating documents that contain synthetic text. The length of the generated text is determined by a parameter corresponding to the number of words desired. For purposes of our work, we set this parameter to a constant value of 300. Since the quality of the generated text is much lower than that of the lyrics text, a lot of generated documents could not contain valuable sentences to be considered in our corpus. Despite this, we achieved to obtain a valuable set of sentences by exhaustive manual inspection (see Table 1).
- Other components: At this point, we take the collected documents as input to execute the module that we have called Filtering and Annotating: Filtering is the process by which expressions and sentences (in general) are extracted from the text of each document; this process was manual and did depend on the criteria from who executes it to define what is a sentence. From this, a set of 7191 “raw sentences” was obtained. Relying on these sentences, we executed an annotation process in which each sentence was annotated by 2 independent annotators judging the presence or absence of misogynistic content (binary decision). Of the 7191 sentences, we obtained 6747 agreements (93.84%) and 3624.8 agreements expected by chance (50.41% of observations) resulting in a kappa value of 0.87 indicating a suitable agreement. For those sentences where the annotators did not agree, there was a third annotator to judge and make a final decision based on the mode of the three annotations. We try to keep the annotation guideline as simple as possible, so that annotators could easily make a decision. The guideline included only three rules regarding a misogynistic sentence:
- –
- Unigrams sentences containing rudeness that could be directed at a woman. For instance, puta (whore), fea (ugly), gorda (fat), tonta (silly).
- –
- Any sentence containing one or more rudeness and violent language explicitly directed at a woman or a group of them. For example, me engañaste pinche alcohólica (you cheated on me, fucking alcoholic), te odio pinche zorra (I hate you fucking bitch), etc.
- –
- Any phrase that, in the judgment of the annotator, indicates explicitly or implicitly submission, inferiority or violence, but it does not necessarily include rudeness. For example, ellas también tiene que respetarse, se visten así y luego se quejan cuando les pasa algo (they have to respect themselves, they dress that way and then complain when something happens to them), vete a la cocina y prepararme un sándwich (go to the kitchen and make me a sandwich).
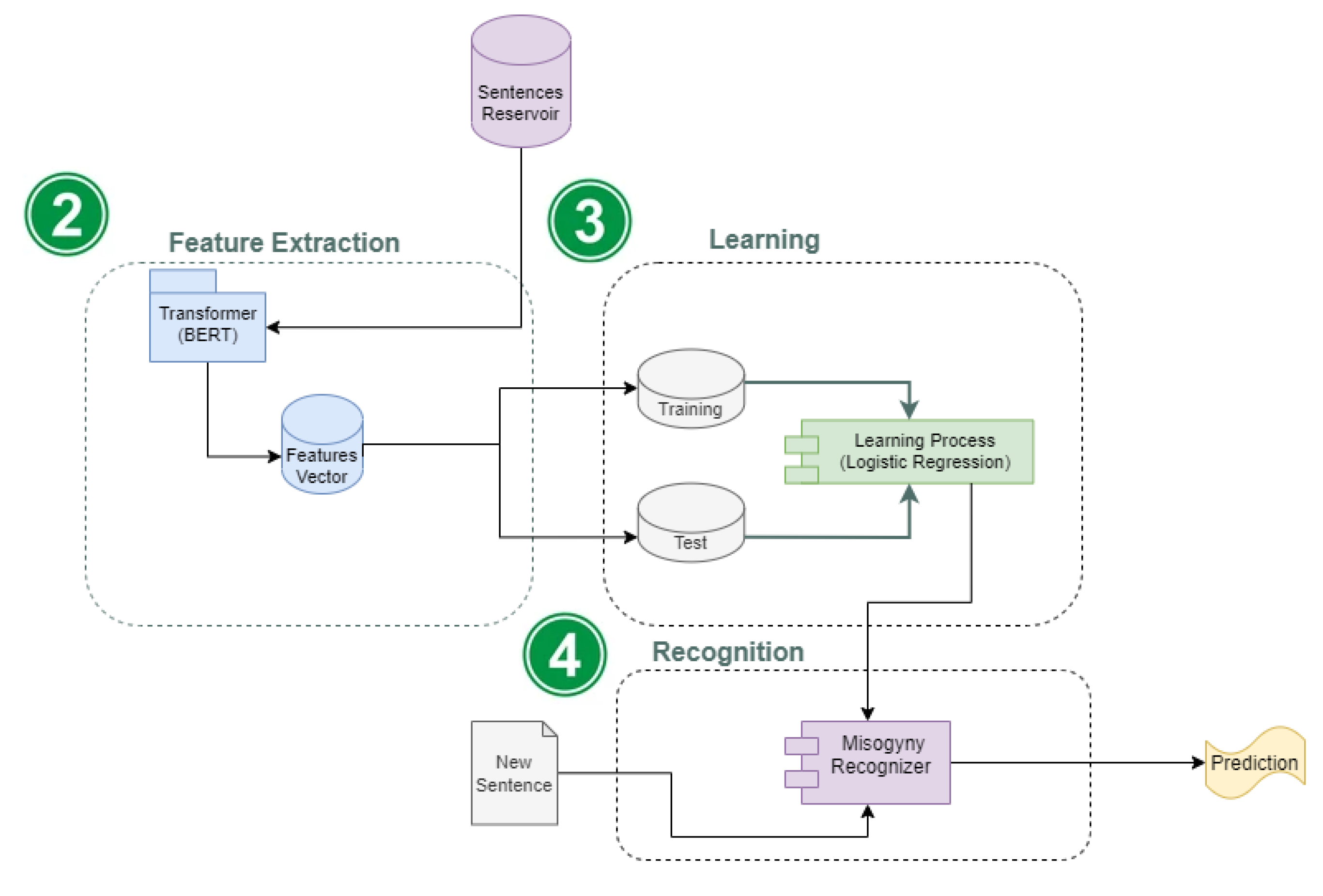
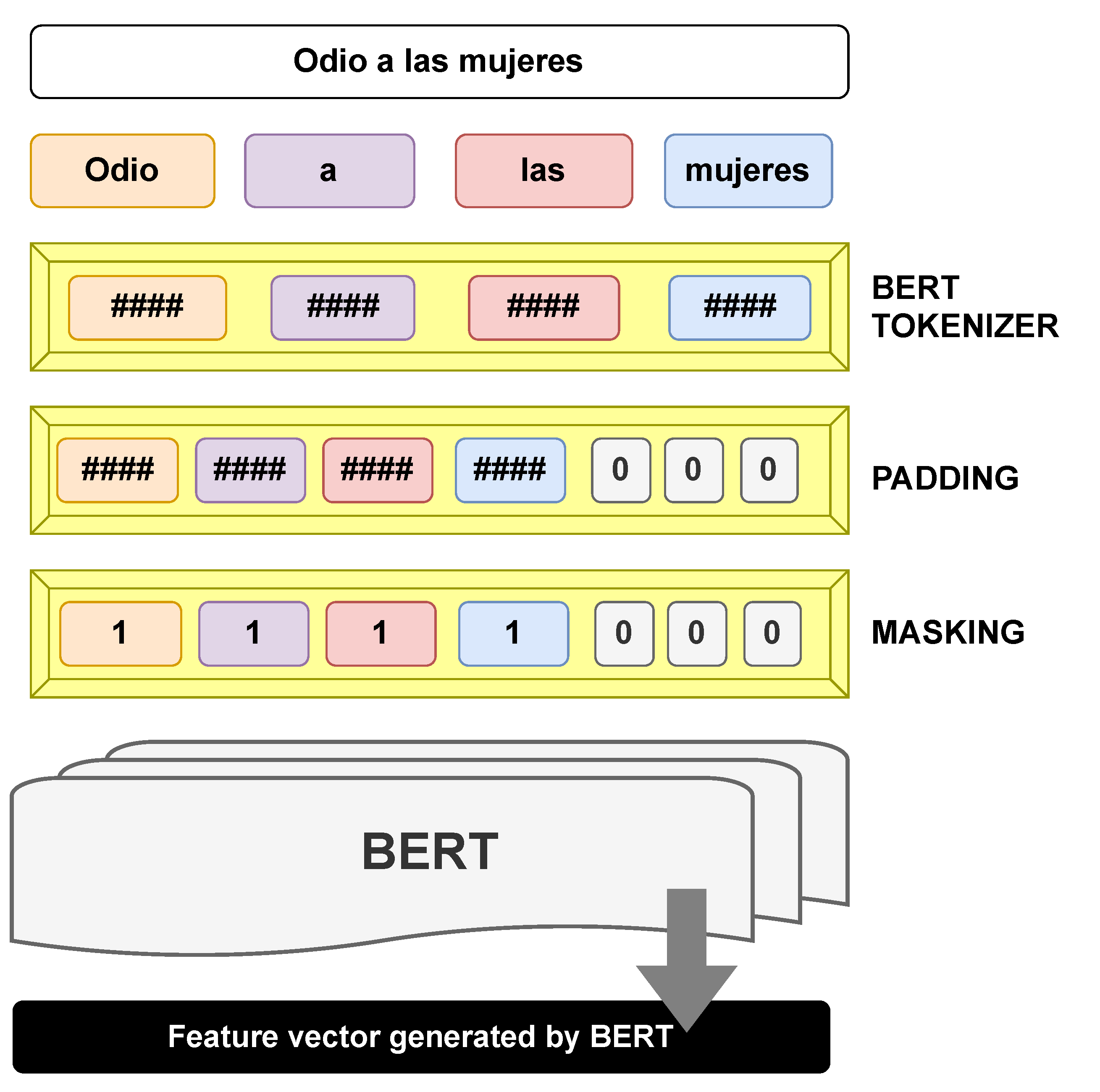
3.2. Feature Extraction
- 1
- Obtaining of an instance of a BERT model pre-trained on a large unlabeled dataset in Spanish.
- 2
- Fine-tuning [45], where the model is initialized with the pre-trained parameters and all of them are fine-tuned using a labeled data regarding sentences previously categorized as misogynistic and non-misogynistic.
| Algorithm 1: Feature Extraction |
 |
3.3. Learning Process
| Algorithm 2: Learning Process |
 |
3.4. Recognition Process
| Algorithm 3: Misogyny Recognition |
|
Data: s: Sentence to be analyzed, Result: Prediction vector /* Loading previous models */ /* Tokenizing sentence to be analyzed */ /* Padding Sentences and Attention Mask */ 10 Return p |
4. Experiments and Results
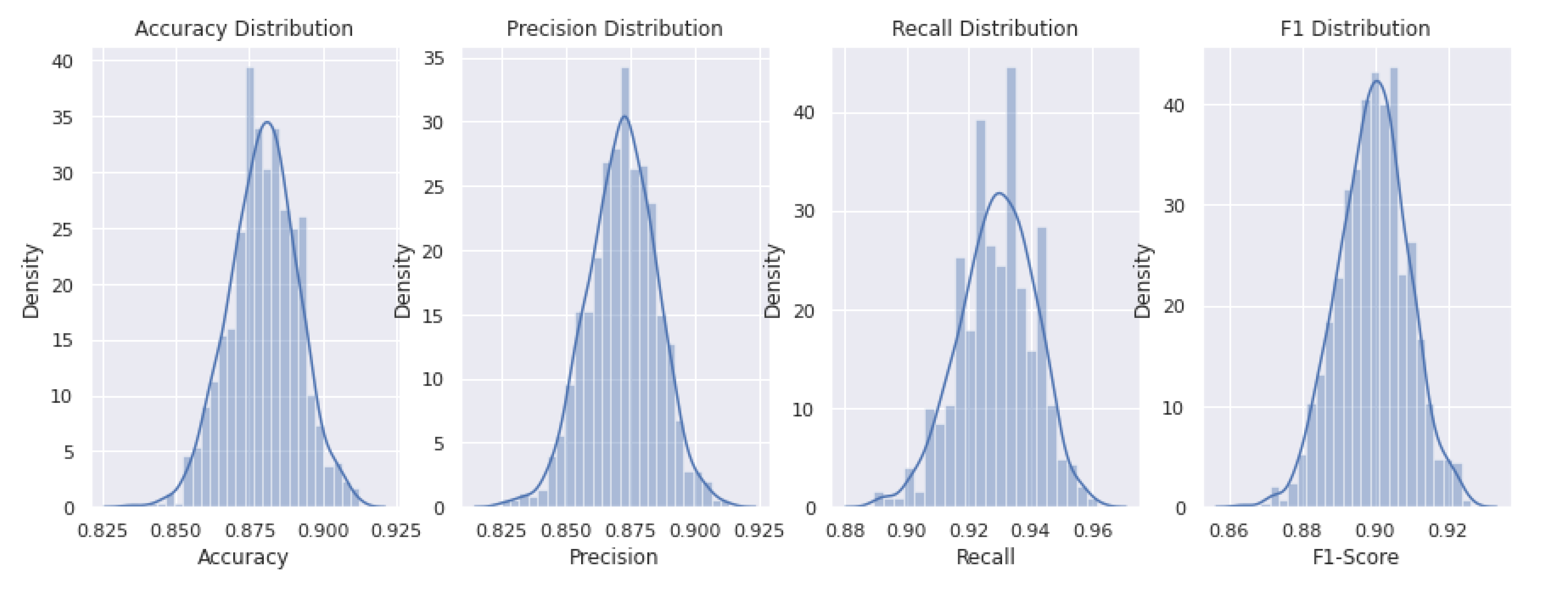
4.1. Learning Ability Assessment
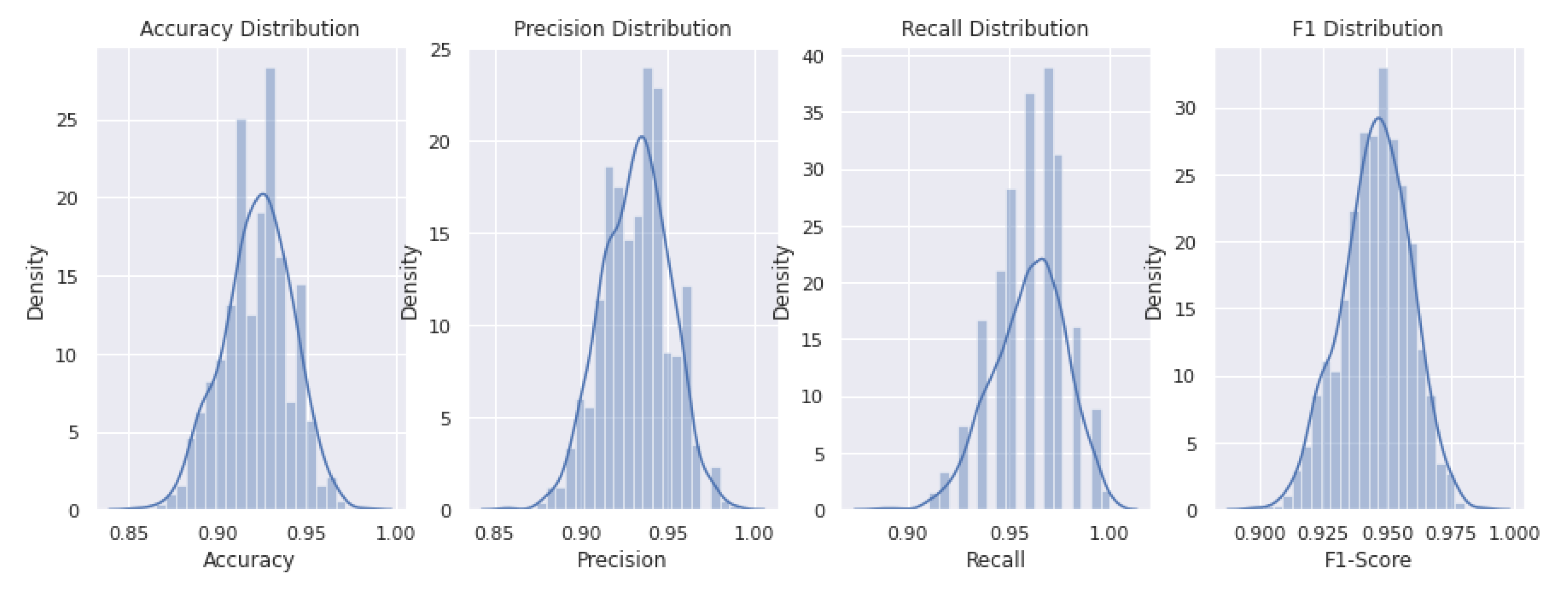
4.2. Assessment for Real World Data
- HS—a binary value indicating the presence or absence of hate speech against one of the given target people (women or immigrants).
- TR—a binary value indicating if the target of the hate speech is a generic group of people (0) or a specific individual (1).
- AG—a binary value indicating if the hate speech present in the tweet is aggressive (1) or not (0).
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. Violence against women: A global health problem of epidemic proportions. In WHO News Release; WHO: Geneva, Switzerland, 2013. [Google Scholar]
- WHO. Global and Regional Estimates of Violence against Women: Prevalence and Health Effects of Intimate Partner Violence and Non-Partner Sexual Violence; World Health Organization: Geneva, Switzerland, 2013. [Google Scholar]
- CSW. Report of the Secretary-General of the Commission on the Status of Women, United Nations, Sixty-Fifth Session. 2021. Available online: https://undocs.org/E/CN.6/2021/3 (accessed on 5 August 2021).
- Galtung, J. Cultural violence. J. Peace Res. 1990, 27, 291–305. [Google Scholar] [CrossRef]
- Foucault, M. The Order of Discourse (L’ordre du Discours); Galimart: Paris, France, 1971. (In French) [Google Scholar]
- Hewitt, S.; Tiropanis, T.; Bokhove, C. The problem of identifying misogynist language on Twitter (and other online social spaces). In Proceedings of the 8th ACM Conference on Web Science, Hannover, Germany, 22–25 May 2016; pp. 333–335. [Google Scholar]
- Hardaker, C.; McGlashan, M. “Real men don’t hate women”: Twitter rape threats and group identity. J. Pragmat. 2016, 91, 80–93. [Google Scholar] [CrossRef] [Green Version]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 88–93. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montréal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Yao, M.; Chelmis, C.; Zois, D.S. Cyberbullying ends here: Towards robust detection of cyberbullying in social media. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3427–3433. [Google Scholar]
- Ridenhour, M.; Bagavathi, A.; Raisi, E.; Krishnan, S. Detecting Online Hate Speech: Approaches Using Weak Supervision and Network Embedding Models. In International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation; Springer: Berlin, Germany, 2020; pp. 202–212. [Google Scholar]
- Lynn, T.; Endo, P.T.; Rosati, P.; Silva, I.; Santos, G.L.; Ging, D. A comparison of machine learning approaches for detecting misogynistic speech in urban dictionary. In Proceedings of the 2019 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (Cyber SA), Oxford, UK, 3–4 June 2019; pp. 1–8. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Rangel Pardo, F.; Rosso, P.; Sanguinetti, M. SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Ojha, A.K.; Lahiri, B.; Zampieri, M.; Malmasi, S.; Murdock, V.; Kadar, D. Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 11–16 May 2020. [Google Scholar]
- Mandl, T.; Modha, S.; Majumder, P.; Patel, D.; Dave, M.; Mandlia, C.; Patel, A. Overview of the hasoc track at fire 2019: Hate speech and offensive content identification in indo-european languages. In Proceedings of the 11th Forum for Information Retrieval Evaluation, Kolkata, India, 12–15 December 2019; pp. 14–17. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the type and target of offensive posts in social media. arXiv 2019, arXiv:1902.09666. [Google Scholar]
- Aragon, M.; Carmona, M.A.; Montes, M.; Escalante, H.J.; Villaseñor-Pineda, L.; Moctezuma, D. Overview of MEX-A3T at IberLEF 2019: Authorship and aggressiveness analysis in Mexican Spanish tweets. In Proceedings of the 1st SEPLN Workshop on Iberian Languages Evaluation Forum (IberLEF), Bilbao, Spain, 24 September 2019. [Google Scholar]
- Fersini, E.; Rosso, P.; Anzovino, M. Overview of the Task on Automatic Misogyny Identification at IberEval 2018. IberEval@ SEPLN 2018, 2150, 214–228. [Google Scholar]
- Bretschneider, U.; Peters, R. Detecting offensive statements towards foreigners in social media. In Proceedings of the 50th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 4–7 January 2017. [Google Scholar]
- Kovács, G.; Alonso, P.; Saini, R. Challenges of Hate Speech Detection in Social Media. SN Comput. Sci. 2021, 2, 9. [Google Scholar] [CrossRef]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and multi-aspect hate speech analysis. arXiv 2019, arXiv:1908.11049. [Google Scholar]
- Sigurbergsson, G.I.; Derczynski, L. Offensive language and hate speech detection for Danish. arXiv 2019, arXiv:1908.04531. [Google Scholar]
- Pitenis, Z.; Zampieri, M.; Ranasinghe, T. Offensive language identification in Greek. arXiv 2020, arXiv:2003.07459. [Google Scholar]
- Bosco, C.; Felice, D.; Poletto, F.; Sanguinetti, M.; Maurizio, T. Overview of the evalita 2018 hate speech detection task. In Proceedings of the EVALITA 2018 Sixth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian, Turin, Italy, 12–13 December 2018; Volume 2263, pp. 1–9. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are they our brothers? analysis and detection of religious hate speech in the arabic twittersphere. In In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 69–76. [Google Scholar]
- Ibrohim, M.O.; Budi, I. Multi-label hate speech and abusive language detection in Indonesian twitter. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1–2 August 2019; pp. 46–57. [Google Scholar]
- Ptaszynski, M.; Pieciukiewicz, A.; Dybała, P. Results of the Poleval 2019 Shared Task 6: First Dataset and Open Shared Task for Automatic Cyberbullying Detection in Polish Twitter. 2019. Available online: https://ruj.uj.edu.pl/xmlui/bitstream/handle/item/152265/ptaszynski_pieciukiewicz_dybala_results_of_the_poleval_2019.pdf?sequence=1&isAllowed=y (accessed on 4 November 2021).
- Hussein, O.; Sfar, H.; Mitrović, J.; Granitzer, M. NLP_Passau at SemEval-2020 Task 12: Multilingual Neural Network for Offensive Language Detection in English, Danish and Turkish. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 13–14 September 2020; pp. 2090–2097. [Google Scholar]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and monitoring hate speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corazza, M.; Menini, S.; Cabrio, E.; Tonelli, S.; Villata, S. A multilingual evaluation for online hate speech detection. ACM Trans. Internet Technol. TOIT 2020, 20, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Ranasinghe, T.; Zampieri, M. Multilingual offensive language identification with cross-lingual embeddings. arXiv 2020, arXiv:2010.05324. [Google Scholar]
- Pamungkas, E.W.; Basile, V.; Patti, V. Misogyny detection in twitter: A multilingual and cross-domain study. Inf. Process. Manag. 2020, 57, 102360. [Google Scholar] [CrossRef]
- Anzovino, M.; Fersini, E.; Rosso, P. Automatic Identification and Classification of Misogynistic Language on Twitter. In Natural Language Processing and Information Systems; Silberztein, M., Atigui, F., Kornyshova, E., Métais, E., Meziane, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 57–64. [Google Scholar]
- Bashar, M.A.; Nayak, R.; Suzor, N. Regularising LSTM classifier by transfer learning for detecting misogynistic tweets with small training set. Knowl. Inf. Syst. 2020, 62, 4029–4054. [Google Scholar] [CrossRef]
- Frenda, S.; Bilal, G. Exploration of Misogyny in Spanish and English tweets. In Proceedings of the Third Workshop on Evaluation of Human Language Technologies for Iberian Languages (IberEval 2018), Sevilla, Spain, 18 September 2018; Volume 2150, pp. 260–267. [Google Scholar]
- García-Díaz, J.A.; Cánovas-García, M.; Colomo-Palacios, R.; Valencia-García, R. Detecting misogyny in Spanish tweets. An approach based on linguistics features and word embeddings. Future Gener. Comput. Syst. 2021, 114, 506–518. [Google Scholar] [CrossRef]
- Fulper, R.; Ciampaglia, G.L.; Ferrara, E.; Ahn, Y.; Flammini, A.; Menczer, F.; Lewis, B.; Rowe, K. Misogynistic language on Twitter and sexual violence. In Proceedings of the ACM Web Science Workshop on Computational Approaches to Social Modeling (ChASM), Bloomington, IN, USA, 23–26 June 2014; pp. 57–64. [Google Scholar]
- Molina-Villegas, A. La incidencia de las voces misóginas sobre el espacio digital en México. In Jóvenes, Plataformas Digitales y Lenguajes: Diversidad Lingüística, Discursos e Identidades; Pérez-Barajas, A.E., Arellano-Ceballos, A.C., Eds.; Elementum: Pachuca, Mexico, 2021; in press. [Google Scholar]
- Cundiff, G. The influence of rap and hip-hop music: An analysis on audience perceptions of misogynistic lyrics. Elon J. Undergrad. Res. Commun. 2013, 4. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in Translation: Contextualized Word Vectors. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Cambridge, MA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Documents | Sentences |
|---|---|---|
| Web Crawler | 991 | 3310 |
| Scraping (Lyrics) | 200 | 733 |
| Scraping (Proverbia) | 2196 | 2196 |
| RNN Generator | 1000 | 952 |
| Total sentences | 7191 |
| Statistic | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Q | 0.87 | 0.86 | 0.92 | 0.89 |
| Q | 0.88 | 0.87 | 0.93 | 0.89 |
| Q | 0.88 | 0.88 | 0.93 | 0.90 |
| IQR | 0.01 | 0.01 | 0.01 | 0.01 |
| CI | [0.84, 0.91] | [0.83, 0.90] | [0.89, 0.96] | [0.87, 0.92] |
| Statistic | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Q | 0.90 | 0.91 | 0.93 | 0.93 |
| Q | 0.92 | 0.93 | 0.94 | 0.94 |
| Q | 0.93 | 0.94 | 0.95 | 0.95 |
| IQR | 0.02 | 0.02 | 0.01 | 0.01 |
| CI | [0.86, 0.98] | [0.87, 0.98] | [0.90, 0.98] | [0.90, 0.98] |
| Original Tag | Not Misogyny | Misogyny | |
|---|---|---|---|
| Y tu eres mi esposa ve a la cocina zorra | 1 | 0.0886 | 0.9113 |
| Solo sirves para lavar los trastes | 0 | 0.8533 | 0.1466 |
| Me encanta mi novia porque hace las tareas domésticas | 1 | 0.3099 | 0.6900 |
| Ella también tiene que respetarse, se visten así y luego se quejan cuando les pasa algo | 1 | 0.0167 | 0.9832 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldana-Bobadilla, E.; Molina-Villegas, A.; Montelongo-Padilla, Y.; Lopez-Arevalo, I.; S. Sordia, O. A Language Model for Misogyny Detection in Latin American Spanish Driven by Multisource Feature Extraction and Transformers. Appl. Sci. 2021, 11, 10467. https://doi.org/10.3390/app112110467
Aldana-Bobadilla E, Molina-Villegas A, Montelongo-Padilla Y, Lopez-Arevalo I, S. Sordia O. A Language Model for Misogyny Detection in Latin American Spanish Driven by Multisource Feature Extraction and Transformers. Applied Sciences. 2021; 11(21):10467. https://doi.org/10.3390/app112110467
Chicago/Turabian StyleAldana-Bobadilla, Edwin, Alejandro Molina-Villegas, Yuridia Montelongo-Padilla, Ivan Lopez-Arevalo, and Oscar S. Sordia. 2021. "A Language Model for Misogyny Detection in Latin American Spanish Driven by Multisource Feature Extraction and Transformers" Applied Sciences 11, no. 21: 10467. https://doi.org/10.3390/app112110467
APA StyleAldana-Bobadilla, E., Molina-Villegas, A., Montelongo-Padilla, Y., Lopez-Arevalo, I., & S. Sordia, O. (2021). A Language Model for Misogyny Detection in Latin American Spanish Driven by Multisource Feature Extraction and Transformers. Applied Sciences, 11(21), 10467. https://doi.org/10.3390/app112110467