
Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents


Abstract
:1. Introduction
2. Related Works
2.1. Agent Initiative Strategies for Helping Users
2.2. Adapting the Scaffolding Method into the Subsequential Process of Information Exploration
3. Context-Based Database and Recommendation Strategies for QA Agents
3.1. Context-Based Database Construction
3.2. Show Me the Way: Topic-Recommendation Strategies
3.2.1. Depth-Oriented Strategy
3.2.2. Various Subjects Strategy
3.2.3. Random
4. Methodology
5. Result
5.1. Questionnaire Analysis
5.2. Search Behavior Analysis
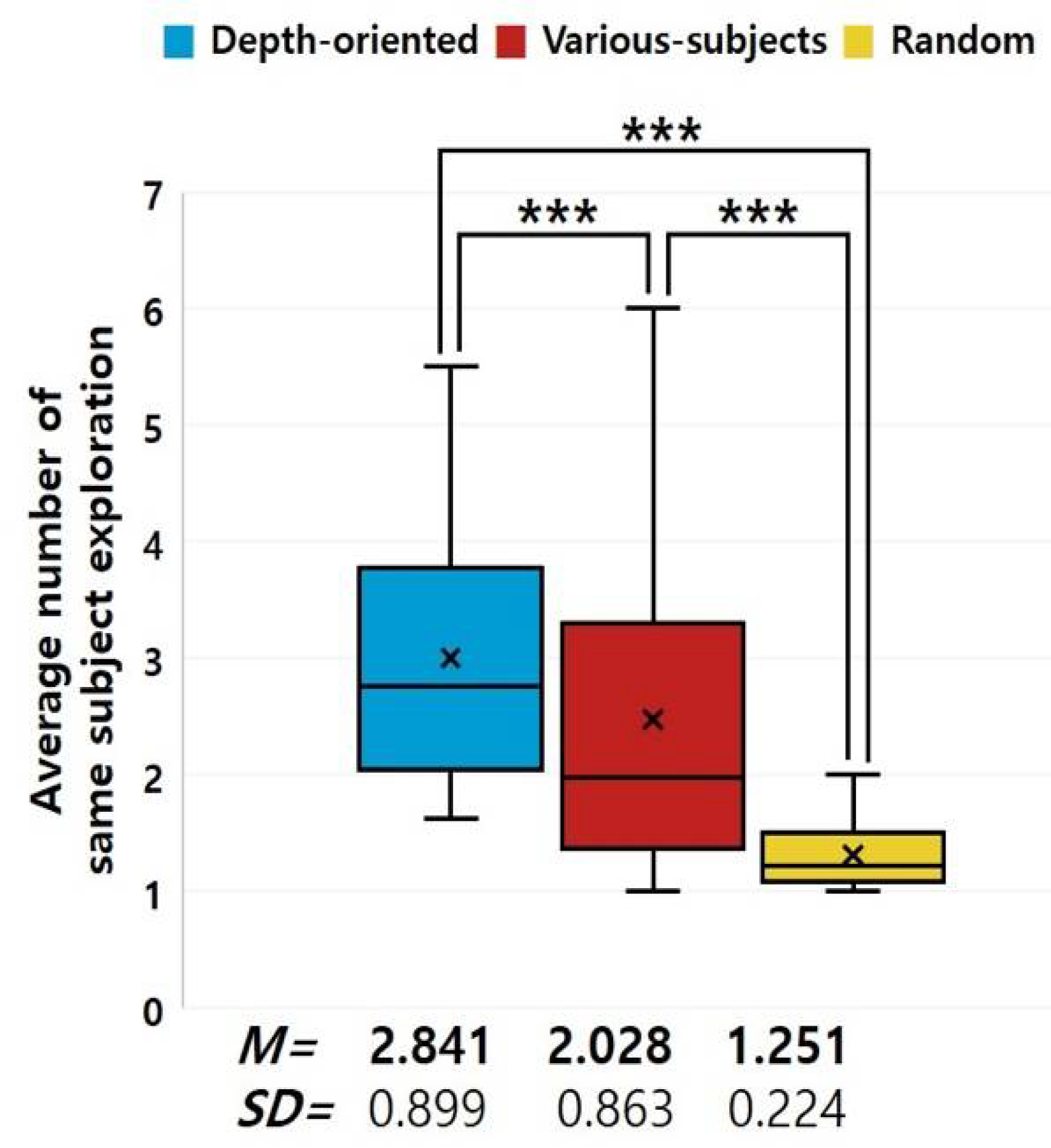
5.2.1. Exploration on the Same Subject
5.2.2. Analysis of Topic Precision
5.2.3. Analysis of Topic Exploration
“Unlike other agents, in this case (using random), most of the questions that gave selections were not related to subjects that I have explored. And some questions were from subjects that I explored already. It made it difficult to choose questions for the next-turn.”—a ‘What else’ user.
5.2.4. Analysis of Topic Introduction
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Mendonça, V.; Melo, F.S.; Coheur, L.; Sardinha, A. A Conversational Agent Powered by Online Learning. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, Richland, SC, USA, 8–12 May 2017; pp. 1637–1639. [Google Scholar]
- Li, C.-H.; Yeh, S.-F.; Chang, T.-J.; Tsai, M.-H.; Chen, K.; Chang, Y.-J. A Conversation Analysis of Non-Progress and Coping Strategies with a Banking Task-Oriented Chatbot. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Hu, T.; Xu, A.; Liu, Z.; You, Q.; Guo, Y.; Sinha, V.; Luo, J.; Akkiraju, R. Touch Your Heart: A Tone-aware Chatbot for Customer Care on Social Media. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Kopp, S.; Gesellensetter, L.; Krämer, N.C.; Wachsmuth, I. A conversational agent as museum guide: Design and evaluation of a real-world application. In Proceedings of the Advances in Autonomous Robotics, Kos, Greece, 12–14 September 2005; pp. 329–343. [Google Scholar]
- Schaffer, S.; Gustke, O.; Oldemeier, J.; Reithinger, N. Toward chatbot in the museum. In Proceedings of the 2nd Workshop on Mobile Access to Cultural Heritage, Barcelona, Spain, 3 September 2018; pp. 1–10. [Google Scholar]
- Machidon, O.-M.; Tavčar, A.; Gams, M.; Duguleană, M. CulturalERICA: A conversational agent improving the exploration of European cultural heritage. J. Cult. Herit. 2020, 41, 152–165. [Google Scholar] [CrossRef]
- Grinder, A.L.; McCoy, E.S. The Good Guide: A Sourcebook for Interpreters, Docents, and Tour Guides; Ironwood Press: Schottsdale, AZ, USA, 1985. [Google Scholar]
- Ronbinson, S.; Traum, D.R.; Ittycheriah, M.; Henderer, J. What would you Ask a conversational Agent? Observations of Human-Agent Dialogues in a Museum Setting. In Proceedings of the Sixth International Conference on Language Resources and Evaluation, Marrakech, Morocco, 28–30 May 2008; pp. 1125–1131. [Google Scholar]
- Liao, Q.V.; Mas-ud Hussain, M.; Chandar, P.; Davis, M.; Khazaeni, Y.; Crasso, M.P.; Wang, D.; Muller, M.; Shami, N.S.; Geyer, W. All Work and No Play? In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Gregory, D.; Anind, A.; Dey, K.; Peter, J.; Nigel Davies, B.; Smith, M.; Steggles, P. Towards a Better Understanding of Context and Context-Awareness. In Proceedings of the 1st international symposium on Handheld and Ubiquitous Computing, Karlsruhe, Germany, 27–29 September 1999; pp. 304–307. [Google Scholar]
- Francisco, A.M.; Tatiane, V.; Guimarães, G.; Prates, R.O.; Candello, H. Here’s What I Can Do: Chatbots’ Strategies to Convey Their Features to Users. In Proceedings of the XVI Brazilian Symposium on Human Factors in Computing Systems, Joinville, Brazil, 23–27 October 2017; pp. 1–10. [Google Scholar]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for Human-AI Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Walker, J.P.; Walker, M.I. Centering Theory in Discourse; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Ashktorab, Z.; Jain, M.; Liao, Q.V.; Weisz, J.D. Resilient Chatbots: Repair Strategy Preferences for Conversational Breakdowns. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and Informing the Design of Chatbots. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 8 June 2018; pp. 895–906. [Google Scholar]
- Lee, M.K.; Kielser, S.; Forlizzi, J.; Srinivasa, S.; Rybski, P. Gracefully mitigating breakdowns in robotic services. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Osaka, Japan, 22 April 2010; pp. 203–210. [Google Scholar]
- Thies, I.M.; Menon, N.; Magapu, S.; Subramony, M.; O’Neill, J. How do you want your chatbot? An exploratory Wizard-of-Oz study with young, urban Indians. In Proceedings of the Advances in Autonomous Robotics, Mumbai, India, 20 September 2017; pp. 441–459. [Google Scholar]
- Vygotsky, L.S. Mind in Society: The Development of Higher Psychological Processes; Harvard University Press: Cambridge, MA, USA, 1980. [Google Scholar]
- van de Pol, J.; Volman, M.; Oort, F.; Beishuizen, J. Teacher scaffolding in small-group work: An intervention study. J. Learn. Sci. 2014, 23, 600–650. [Google Scholar] [CrossRef]
- Winkler, R.; Hobert, S.; Salovaara, A.; Söllner, M.; Leimeister, J.M. Sara, the Lecturer: Improving Learning in Online Education with a Scaffolding-Based Conversational Agent. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 21 April 2020; pp. 1–14. [Google Scholar]
- Griol, D.; Callejas, Z. An Architecture to Develop Multimodal Educative Applications with Chatbots. Int. J. Adv. Robot. Syst. 2013, 10, 175. [Google Scholar] [CrossRef] [Green Version]
- van de Pol, J.; Elbers, E. Scaffolding student learning: A micro-analysis of teacher–student interaction. Learn. Cult. Soc. Interact. 2013, 2, 32–41. [Google Scholar] [CrossRef]
- Gonda, D.E.; Luo, J.; Wong, Y.-L.; Lei, C.-U. Evaluation of Developing Educational Chatbots Based on the Seven Principles for Good Teaching. In Proceedings of the 2018 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Wollongon, Australia, 4–7 December 2018; pp. 446–453. [Google Scholar]
- Delen, E.; Liew, J.; Willson, V. Effects of interactivity and instructional scaffolding on learning: Self-regulation in online video-based environments. Comput. Educ. 2014, 78, 312–320. [Google Scholar] [CrossRef]
- Azevedo, R.; Hadwin, A.F. Scaffolding Self-regulated Learning and Metacognition—Implications for the Design of Computer-based Scaffolds. Instr. Sci. 2005, 33, 367–379. [Google Scholar] [CrossRef]
- Graves, M.F. Scaffolded Reading Experiences for Inclusive Classes. Educ. Leadersh. 1996, 53, 14–16. [Google Scholar]
- Wood, D.; Bruner, J.S.; Ross, G. The Role of Tutoring in Problem Solving. J. Child Psychol. Psychiatry 1976, 17, 89–100. [Google Scholar] [CrossRef] [PubMed]
- Bloom, B.S. Taxonomy of Educational Objectives, Handbook 1: Cognitive Domain, 2nd ed.; David McKay Company: New York, NY, USA, 1956. [Google Scholar]
- Asia Culture Archive of Asia Culture Center. Available online: http://archive.acc.go.kr/ (accessed on 8 November 2021).
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Percentage | ||
|---|---|---|---|
| Gender | |||
| Male | 25 | 50 | |
| Female | 25 | 50 | |
| Visit Experience of Anonymised Museum | |||
| Never visited | 39 | 78 | |
| 1 to 3 times | 7 | 14 | |
| Above 4 times | 4 | 8 | |
| The Frequency of Visiting Museum | |||
| Once a month | 0 | 0 | |
| Once every 2–3 months. | 8 | 16 | |
| Once every 6 months. | 9 | 18 | |
| Once a year | 17 | 34 | |
| Less than once a year. | 16 | 32 | |
| The Purpose of Visiting Museum | (Duplicate check allowed) | ||
| To consume exciting content | 38 | 76 | |
| To share own feelings with company | 27 | 54 | |
| To acquire knowledge | 13 | 26 | |
| To get some ideas from museum | 20 | 40 | |
| To appreciate the exhibits and relax | 36 | 72 |
| TAM Sections | No. | Questionnaires | All Participants (n = 50) | Keep Going (n = 25) | What Else (n = 31) | Whatever (n = 23) |
|---|---|---|---|---|---|---|
| Perceived Usefulness | 1 | Selections help the subsequential information exploration with themes I focused on |  |  |  | A>C>B |
| 2 | Selections help to explore topics with various subjects | B>A>C | A=B>C | B>A=C | B=C>A | |
| 3 | Suggested selections make me want to explore more turns |  |  |  | C>A>B | |
| 4 | By using the agent, I explored subjects profoundly |  |  |  | B>C>A | |
| Perceived Easy of Use | 5 | Questions in suggested selections reflected well what I want to ask |  |  | B>A>C | C>B=A |
| 6 | Questions in suggested selections were difficult than what I wanted to ask | B>C>A | A>B>C | C>B>A | A>B>C | |
| 7 | Questions in suggested selections were easier than what I wanted to ask | A>B>C |  |  | A>B=C | |
| 8 | There were times that I wanted to ask other questions than that of suggested selections | C>B>A |  |  | C>A>B | |
| 9 | It was easy to choose questions for the next turns |  |  |  | C>A>B | |
| Intention to Use | 10 | Want to use the QA agent when I visit the museum | B>A>C |  |  |  |
| 11 | Want to recommend the QA agent to acquaintances who will visit the exhibition | B>A>C |  |  |  | |
| 12 | Want to visit the exhibition related with subjects I explored with the QA agent |  |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, A.D.-Y.; Noh, Y.-G.; Hong, J.-H. Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents. Appl. Sci. 2021, 11, 10600. https://doi.org/10.3390/app112210600
Yang AD-Y, Noh Y-G, Hong J-H. Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents. Applied Sciences. 2021; 11(22):10600. https://doi.org/10.3390/app112210600
Chicago/Turabian StyleYang, Albert Deok-Young, Yeo-Gyeong Noh, and Jin-Hyuk Hong. 2021. "Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents" Applied Sciences 11, no. 22: 10600. https://doi.org/10.3390/app112210600
APA StyleYang, A. D. -Y., Noh, Y. -G., & Hong, J. -H. (2021). Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents. Applied Sciences, 11(22), 10600. https://doi.org/10.3390/app112210600