
Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks



Abstract
:Featured Application
Abstract
1. Introduction
- The feasibility of collecting and building a CSE attack corpus to address the lack of training data composed of realized CSE attacks.
- The feasibility of annotating the linguistic characteristics of social engineers’ language in order to constitute an adjuvant factor for the ML algorithms’ training.
- The usage of the produced CSE corpus towards an early-stage automated CSE attack recognition by training a NER system that is able to identify critical in-context terms.
2. Related Work
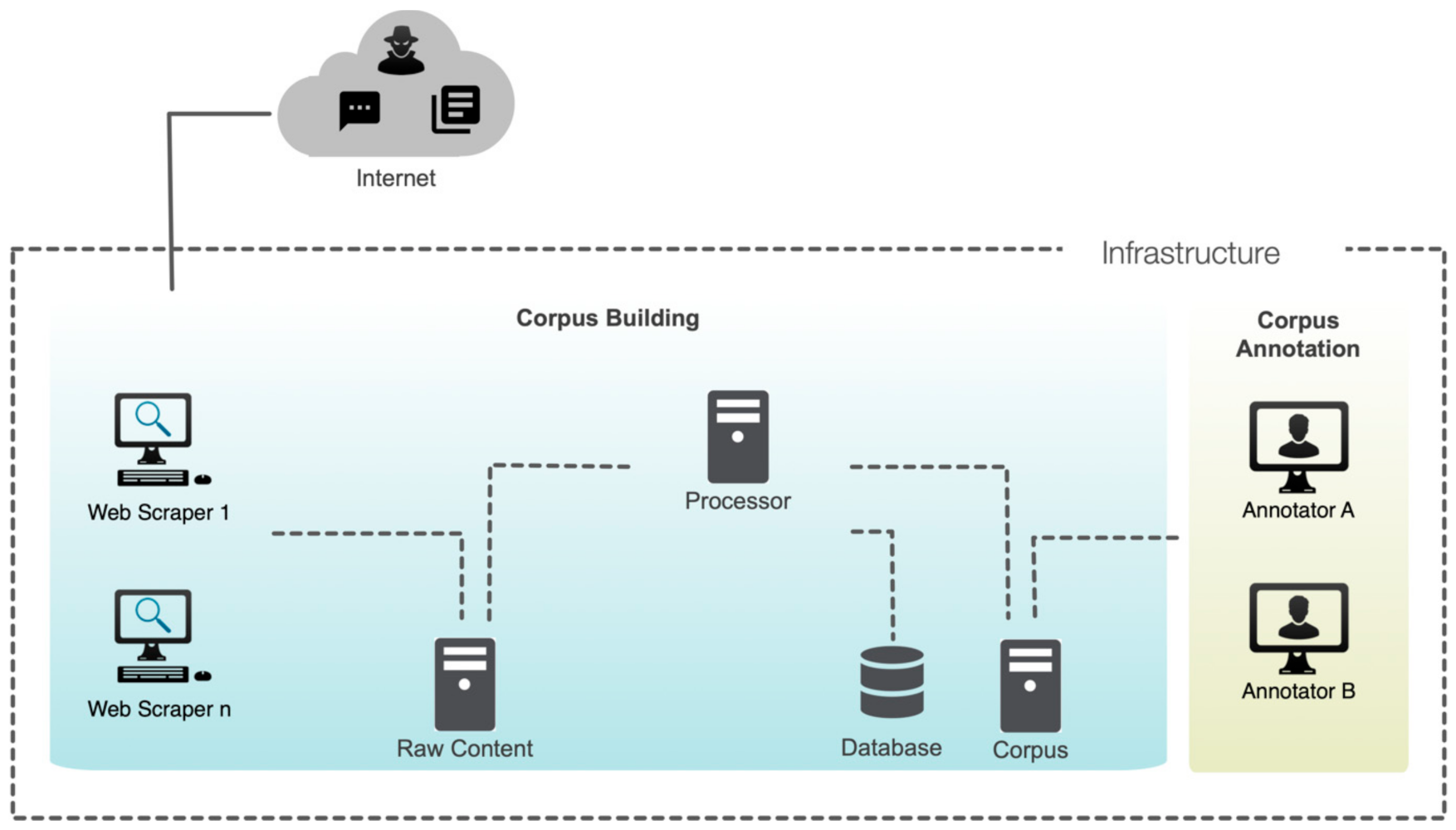
3. The Proposed Approach
3.1. Conceptual Framework
- Personal: Details related to the employee, e.g., first or last name, telephone number etc.
- IT: Details related to the Information Technology ecosystem, e.g., Network-share names, hardware/software characteristics, etc.
- Enterprise: Details related to the SME ecosystem, e.g., Department names, Office numbers, etc.
3.2. Methodology
- PHASE 1: CSE Corpus Building
- ◦
- STEP1-Sources Selection: the CSE attack dialogue sources are identified.
- ◦
- STEP2-Dialogues Collection: the CSE attack dialogues are collected through manual and automated web scraping methods.
- ◦
- STEP3-Dialogues Enrichment: Dialogues enrichment techniques are selected and applied.
- ◦
- STEP4-Linguistic Analysis: Dialogues are analyzed from a linguistic perspective.
- ◦
- STEP5-Dialogues Processing: the dialogues are processed using NLP techniques to form the CSE corpus
- PHASE 2: CSE Corpus Annotation, based on the steps described in [24].
- ◦
- STEP1-Goal Declaration: the goal of the annotation task is declared.
- ◦
- STEP2-Model and CSE Ontology Creation: the phenomenon in study is represented in abstract terms and an ontology is created to be used as the base for the annotation task.
- ◦
- STEP3-Specifications Definition: a concrete representation of the model is created based on the CSE ontology.
- ◦
- STEP4-Annotator Guidelines: a blueprint is produced to help annotators in element identification and element association with the appropriate tag.
- ◦
- STEP5-Annotation Task: the annotation process is performed. In case of changes in the CSE ontology the process returns recursively to STEP2.
- ◦
- STEP6-Inter-Annotator Agreement: the inter-annotator agreement is validated.
- ◦
- STEP7-Adjudication Task: the final version (gold standard) of the annotated CSE corpus is finally formed.
4. Application and Results
4.1. CSE Corpus Building
4.1.1. Source Selection
- Social engineering dark websites (tutorials, guides, and others)
- Social engineering dark forums (text dialogues)
- Social engineering books
- Instant Messaging logs
- Telephone conversations
4.1.2. Dialogues Collection
4.1.3. Dialogues Enrichment
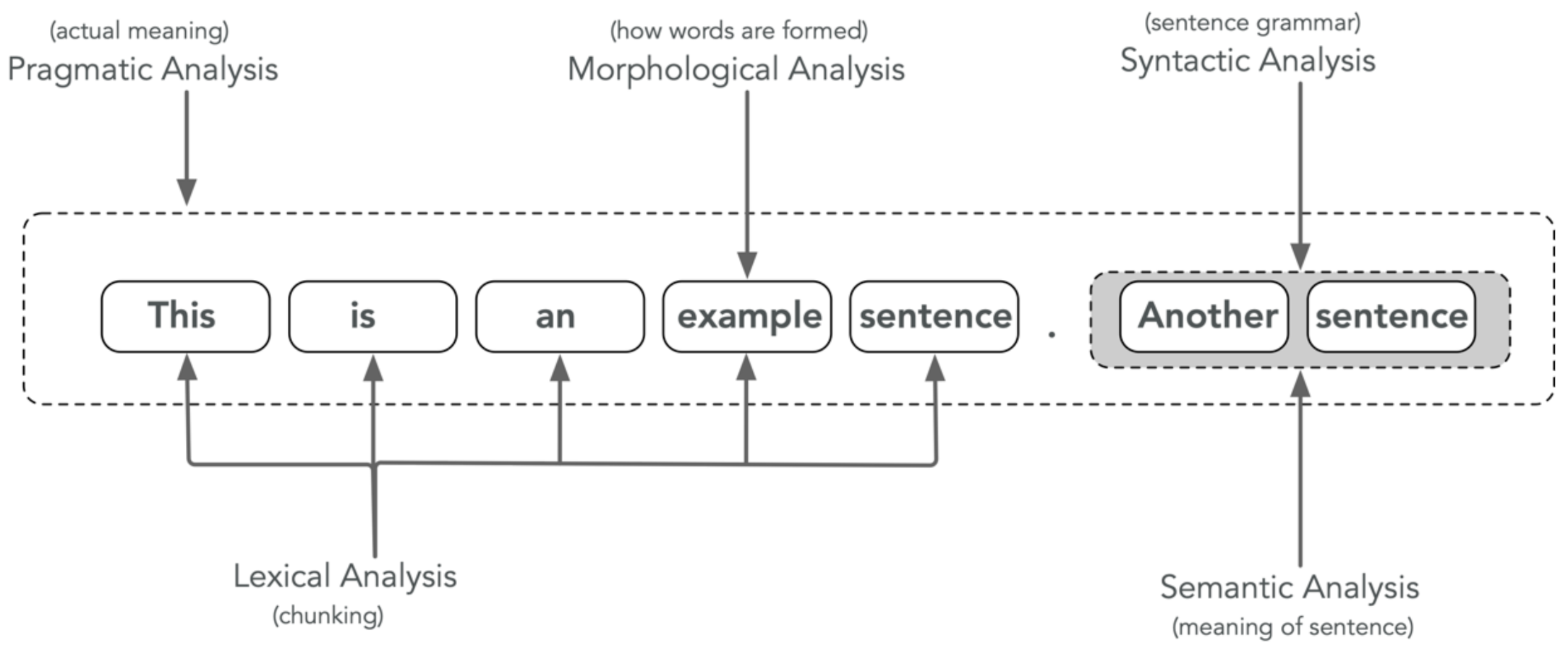
4.1.4. Linguistic Analysis
4.1.5. Dialogues Processing
4.2. CSE Corpus Annotation
4.2.1. Goal Declaration
- Identify keywords, syntax, and semantic characteristics to detect Personal data leakage. If found, label with appropriate tag.
- Use keywords, syntax, and semantic characteristics to detect IT data leakage. If found, label with appropriate tag.
- Identify keywords, syntax, and semantic characteristics to detect Enterprise data leakage. If found, label with appropriate tag.
- Identify noun-verb combinations and verb repetitions based on blacklists.
4.2.2. Model and CSE Ontology Creation
- T = {CSE_Ontology_term, Personal, Enterprise, IT}
- R = {CSE_Ontology_term:: = Personal |Enterprise| IT}
- I = {Personal= “list of personal terms in vocabulary”, IT = “list of Information Technology terms in vocabulary”, Enterprise = “list of enterprise/corporate terms in vocabulary”}
- The ontology should focus on assets (sensitive data) that could leak from an SME employee.
- The ontology should include only the necessary concepts in-context.
- The ontology should not exceed three levels of depth because that would lead to difficulties for algorithms and annotators to recognise the concepts.
4.2.3. Specifications Definition
4.2.4. Annotator Guidelines
- prefer IT category over (Enterprise category or Personal category)
- prefer Enterprise category over Personal category
- Each text span may be tagged with Personal, IT or Enterprise main tags
- If a sentence has entities that can fit in two or more tags, then follow the following priority IT > Enterprise > Personal
- Prefer individual words to word combinations
- The tag Personal is assigned to whatever information is related to a person. e.g., first name, Last Name. Consult CSE ontology
- The tag IT is assigned to whatever information is related to Information Technology, e.g., USB stick, computer, software and others. Consult Ontology
- The tag Enterprise is assigned to whatever information is related to enterprises and enterprise environment, e.g., Department, office, positions, resumes and others. Consult CSE ontology
- A sentence can have no important words. This sentence is call Neutral
- Noun-verb combinations and verb repetitions will be identified automatically based on blacklists
4.2.5. Annotation Task
4.2.6. Inter-Annotator Agreement
4.2.7. Adjudication Task
4.3. CSE Corpus Presentation
5. CSE Corpus Evaluation
- Preprocessing: The CSE corpus has already been annotated in IOB format and thus each line of the corpus can easily be read and stored as a list of token-tag pairs. Then, each token was represented by a word embedding using a pre-trained English language model of the spaCy NLP library.
- Building: Using Keras, a bi-LSTM model was constructed, which is comprised of two compound layers:
- ◦
- Bi-directional LSTM layer, where the forward and backward pass were encapsulated and the input and output sequences returned were stacked.
- ◦
- Classification layer, where classification was performed to every position of the sequences in the stack. The SoftMax activation function was used to scale the output and obtain sequences of probability distributions.
- Training: To train the model in Keras, a loss function for the model was specified to measure the distance between prediction and truth, and a batch-wise gradient descent algorithm was specified for optimization.
- Assessing: The performance assessment of the model was conducted by applying the model to the preprocessed validation data. For each sample dialogue sentence and each token in a sentence, a tensor was obtained that contained a predicted probability distribution over the tags. The tag with highest probability was chosen, and for each sentence and each token the true and predicted tags were returned.
- 1.
- Each dialogue sentence was split into a sequence of token-tag pairs.
- 2.
- Each token-tag pair was represented by a word embedding vector.
- 3.
- The word embeddings were provided by spaCy NLP library and pretrained to encode semantic information. This approach is known as Transfer Learning [46].
- 4.
- Going forward the bi-LSTM model at each step:
- a.
- the input vector was read and combined with the internal memory
- b.
- the output vector was produced and the internal memory was updated
- 5.
- This sequence of actions was performed by the bi-LSTM model to the input sequence and produced an output sequence of the same length.
- 6.
- Going backwards, the model read the input sequence again and produced another output sequence.
- 7.
- At each position, the outputs of steps 4 and 5 were combined and fed into a classifier which outputted the probability for the input word, at this position, that should be annotated with the Personal, IT or Enterprise tag.
- True Positives (TP): CSE ontology entities where the true tag is positive and whose category is correctly predicted to be positive.
- False Positives (FP): CSE ontology entities where the true tag is negative and whose category is incorrectly predicted to be positive.
- True Negatives (TN): CSE ontology entities where the true tag is negative and whose category is correctly predicted to be negative.
- False Negatives (FN): CSE ontology entities where the true tag is positive and whose class is incorrectly predicted to be negative.
- Accuracy, which is the number of CSE ontology entities correctly identified as either truly positive or truly negative out of the total number of entities
- Recall, which identifies how many tags from the positive class are correctly detected
- Precision, which identifies the frequency with which a model was correct when predicting the positive class.
- F1 Score, which is the harmonic average of the precision and recall, and measures the effectiveness of identification when just as much importance is given to recall as to precision
- Enriching the CSE Corpus, i.e., adding sentences where more critical nouns belonging to one of the three sensitive data categories are substituted by similar words.
- Replacing the last feed-forward layer by a conditional random field (CRF) model,
- Reducing the imbalance of the tag distribution, e.g., by using a different loss function,
- Providing more input by tagging newcoming CSE dialogues and thus training more data.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- What Is “Social Engineering”? Available online: https://www.enisa.europa.eu/topics/csirts-in-europe/glossary/what-is-social-engineering (accessed on 29 October 2021).
- Kumar, A.; Chaudhary, M.; Kumar, N. Social Engineering Threats and Awareness: A Survey. Eur. J. Adv. Eng. Technol. 2015, 2, 15–19. [Google Scholar]
- Heartfield, R.; Loukas, G. A Taxonomy of Attacks and a Survey of Defence Mechanisms for Semantic Social Engineering Attacks. ACM Comput. Surv. 2016, 48, 1–39. [Google Scholar] [CrossRef]
- Salahdine, F.; Kaabouch, N. Social Engineering Attacks: A Survey. Future Internet 2019, 11, 89. [Google Scholar] [CrossRef] [Green Version]
- 2020 Data Breach Investigations Report. Available online: https://enterprise.verizon.com/resources/reports/dbir/ (accessed on 12 April 2021).
- Adamopoulou, E.; Moussiades, L. An Overview of Chatbot Technology. In Artificial Intelligence Applications and Innovations; Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; IFIP Advances in Information and Communication Technology; Springer International Publishing: Cham, Switzerland, 2020; Volume 584, pp. 373–383. ISBN 978-3-030-49185-7. [Google Scholar]
- Cialdini, R.B.; Cialdini, R.B. Influence: The Psychology of Persuasion; Collins: New York, NY, USA, 2007; Volume 55. [Google Scholar]
- Pogrebna, G.; Skilton, M. Navigating New Cyber Risks: How Businesses Can Plan, Build and Manage Safe Spaces in the Digital Age; Springer International Publishing: Cham, Switzerland, 2019; ISBN 978-3-030-13526-3. [Google Scholar]
- Li, D.-C.; Lin, W.-K.; Chen, C.-C.; Chen, H.-Y.; Lin, L.-S. Rebuilding sample distributions for small dataset learning. Decis. Support Syst. 2018, 105, 66–76. [Google Scholar] [CrossRef]
- Lateh, M.A.; Muda, A.K.; Yusof, Z.I.M.; Muda, N.A.; Azmi, M.S. Handling a small dataset problem in prediction model by employ artificial data generation approach: A review. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Langkawi, Malaysia, 2017; Volume 892, p. 012016. [Google Scholar]
- Wilcock, G. Introduction to Linguistic Annotation and Text Analytics. Synth. Lect. Hum. Lang. Technol. 2009, 2, 1–159. [Google Scholar] [CrossRef]
- Lansley, M.; Polatidis, N.; Kapetanakis, S. SEADer: A Social Engineering Attack Detection Method Based on Natural Language Processing and Artificial Neural Networks. In Computational Collective Intelligence; Nguyen, N.T., Chbeir, R., Exposito, E., Aniorté, P., Trawiński, B., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11683, pp. 686–696. ISBN 978-3-030-28376-6. [Google Scholar]
- Lansley, M.; Mouton, F.; Kapetanakis, S.; Polatidis, N. SEADer++: Social engineering attack detection in online environments using machine learning. J. Inf. Telecommun. 2020, 4, 346–362. [Google Scholar] [CrossRef] [Green Version]
- Lansley, M.; Kapetanakis, S.; Polatidis, N. SEADer++ v2: Detecting Social Engineering Attacks using Natural Language Processing and Machine Learning. In Proceedings of the 2020 International Conference on INnovations in Intelligent SysTems and Applications (INISTA); IEEE: Novi Sad, Serbia, 2020; pp. 1–6. [Google Scholar]
- Catak, F.O.; Sahinbas, K.; Dörtkardeş, V. Malicious URL Detection Using Machine Learning. Available online: www.igi-global.com/chapter/malicious-url-detection-using-machine-learning/266138 (accessed on 12 April 2021).
- Peng, T.; Harris, I.; Sawa, Y. Detecting Phishing Attacks Using Natural Language Processing and Machine Learning. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 300–301. [Google Scholar]
- Lee, Y.; Saxe, J.; Harang, R. CATBERT: Context-Aware Tiny BERT for Detecting Social Engineering Emails. arXiv 2020, arXiv:2010.03484. [Google Scholar]
- Lan, Y. Chat-Oriented Social Engineering Attack Detection Using Attention-based Bi-LSTM and CNN. In Proceedings of the 2021 2nd International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 28–29 January 2021; pp. 483–487. [Google Scholar]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference; Association for Computing Machinery: New York, NY, USA, 2012; pp. 239–248. [Google Scholar]
- Dalton, A.; Aghaei, E.; Al-Shaer, E.; Bhatia, A.; Castillo, E.; Cheng, Z.; Dhaduvai, S.; Duan, Q.; Hebenstreit, B.; Islam, M.; et al. Active Defense Against Social Engineering: The Case for Human Language Technology. In Proceedings of the First International Workshop on Social Threats in Online Conversations, Understanding and Management, Marseille, France, 11–16 May 2020. [Google Scholar]
- Saleilles, J.; Aïmeur, E. SecuBot, a Teacher in Appearance: How Social Chatbots Can Influence People. In Proceedings of the 1st Workshop on Adverse Impacts and Collateral Effects of Artificial Intelligence Technologies—AIofAI 2021; Aïmeur, E., Ferreyra, N.E.D., Hage, H., Eds.; CEUR: Montréal, Canada, 2021; Volume 2942, pp. 31–49. [Google Scholar]
- ISO/IEC Standard 15408. Available online: https://www.enisa.europa.eu/topics/threat-risk-management/risk-management/current-risk/laws-regulation/rm-ra-standards/iso-iec-standard-15408 (accessed on 13 July 2021).
- Evaluation criteria for IT Security—Part 1: Introduction and General Model—ISO/IEC 15408-1:2009. Available online: https://standards.iso.org/ittf/PubliclyAvailableStandards/c050341_ISO_IEC_15408-1_2009.zip (accessed on 13 July 2021).
- Pustejovsky, J.; Stubbs, A. Natural Language Annotation for Machine Learning; O’Reilly Media: Sebastopol, CA, USA, 2013; ISBN 978-1-4493-0666-3. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Tsinganos, N. Tsinik/Applsci-1445637: Applsci-1445637 v1.0.0. Zenodo. 2021. Available online: http://doi.org/10.5281/zenodo.5635627 (accessed on 15 November 2021).
- TextBlob: Simplified Text Processing—TextBlob 0.16.0 Documentation. Available online: https://textblob.readthedocs.io/en/dev/index.html (accessed on 11 May 2021).
- NLTK: Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 13 October 2021).
- spaCy Industrial-strength Natural Language Processing in Python. Available online: https://spacy.io/ (accessed on 13 October 2021).
- Taylor, A.; Marcus, M.; Santorini, B. The Penn Treebank: An Overview. In Treebanks: Building and Using Parsed Corpora; Abeillé, A., Ed.; Text, Speech and Language Technology; Springer: Dordrecht, The Netherlands, 2003; pp. 5–22. ISBN 978-94-010-0201-1. [Google Scholar]
- Souag, A.; Salinesi, C.; Comyn-Wattiau, I. Ontologies for Security Requirements: A Literature Survey and Classification. In Proceedings of the International Conference on Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2012; pp. 61–69. [Google Scholar]
- Li, T.; Ni, Y. Paving Ontological Foundation for Social Engineering Analysis. In Proceedings of the Advanced Information Systems Engineering; Giorgini, P., Weber, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 246–260. [Google Scholar]
- Protégé. Available online: https://protege.stanford.edu/ (accessed on 11 May 2021).
- Murata, M.; Laurent, S.S.; Kohn, D. XML Media Types. Available online: https://www.rfc-editor.org/rfc/rfc3023.html (accessed on 16 April 2021).
- GATE.Ac.Uk—Index.Html. Available online: https://gate.ac.uk/ (accessed on 11 March 2021).
- Prodigy An Annotation Tool for AI, Machine Learning & NLP. Available online: https://prodi.gy (accessed on 23 September 2021).
- WordNet | A Lexical Database for English. Available online: https://wordnet.princeton.edu/ (accessed on 14 October 2021).
- LIWC—WP Engine. Available online: https://liwc.wpengine.com/ (accessed on 15 November 2021).
- Ramshaw, L.A.; Marcus, M.P. Text chunking using transformation-based learning. In Natural Language Processing Using Very Large Corpora; Springer: Berlin/Heidelberg, Germany, 1999; pp. 157–176. [Google Scholar]
- Craig, R.T. Generalization of Scott’s index of intercoder agreement. Public Opin. Q. 1981, 45, 260–264. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Shelar, H.; Kaur, G.; Heda, N.; Agrawal, P. Named Entity Recognition Approaches and Their Comparison for Custom NER Model. Sci. Technol. Libr. 2020, 39, 324–337. [Google Scholar] [CrossRef]
- Keras: The Python deep learning API. Available online: https://keras.io/ (accessed on 9 October 2021).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 9 October 2021).
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Tsinganos, N.; Sakellariou, G.; Fouliras, P.; Mavridis, I. Towards an Automated Recognition System for Chat-based Social Engineering Attacks in Enterprise Environments. In Proceedings of the 13th International Conference on Availability, Reliability and Security; ACM: Hamburg, Germany, 2018; pp. 1–10. [Google Scholar]
- Iyer, R.R.; Sycara, K.; Li, Y. Detecting Type of Persuasion: Is there Structure in Persuasion Tactics? In Proceedings of the CMNA@ICAIL, London, UK, 16 July 2017. [Google Scholar]
- Edwards, M.J.; Peersman, C.; Rashid, A. Scamming the Scammers: Towards Automatic Detection of Persuasion in Advance Fee Frauds. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 1291–1299. [Google Scholar] [CrossRef] [Green Version]
- Hidey, C.; McKeown, K. Persuasive influence detection: The role of argument sequencing. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Stajner, S.; Yenikent, S. A Survey of Automatic Personality Detection from Texts. In Proceedings of the 28th International Conference on Computational Linguistics, International Committee on Computational Linguistics, Barcelona, Spain, 13–18 September 2020; pp. 6284–6295. [Google Scholar]
- Kang, S.; Ko, Y.; Seo, J. Hierarchical speech-act classification for discourse analysis. Pattern Recognit. Lett. 2013, 34, 1119–1124. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No# | Web Sites/Forums |
|---|---|
| 1 | ‘What is the bloody point?’ https://www.whatsthebloodypoint.com/ (accessed on 15 November 2021) |
| 2 | ‘Social Engineering’, Nulled. https://www.nulled.to/forum/69-social-engineering/ (accessed on 15 November 2021) |
| 3 | ‘Sinisterly-Social Engineering’ https://sinister.ly/Forum-Social-Engineering (accessed on 15 November 2021) |
| 4 | ‘Ripoff Scams Report | Consumer Complaints & Reviews | Ripandscam.com’https://www.ripandscam.com/ (accessed on 15 November 2021) |
| 5 | MPGH-MultiPlayer Game Hacking & Cheats https://www.mpgh.net/forum/forumdisplay.php?f=670 (accessed on 15 November 2021) |
| 6 | ‘Home’, BlackHatWorld. https://www.blackhatworld.com/ (accessed on 15 November 2021) |
| 7 | ‘Hack Forums’ https://hackforums.net/index.php (accessed on 15 November 2021) |
| 8 | ‘Demonforums.net’, demonforums.net. https://demonforums.net/ (accessed on 15 November 2021) |
| 9 | 419 Eater-The largest scambaiting community on the planet! https://www.419eater.com/ (accessed on 15 November 2021) |
| 10 | Socialengineered Forum https://web.archive.org/web/20200119025819/https://socialengineered.net/ (accessed on 15 November 2021) |
| 11 | SE Forums https://web.archive.org/web/20180401044855/https://seforums.se/ (accessed on 15 November 2021) |
| 12 | Leak Forums Net https://web.archive.org/web/20190123070424/https://leakforums.net/ (accessed on 15 November 2021) |
| Books | |
| 13 | Advanced Persistent Threat Hacking: The Art and Science of Hacking-Tyler Wrightson |
| 14 | G. Watson, A. Mason, and R. Ackroyd, Social Engineering Penetration Testing: Executing Social Engineering Pen Tests, Assessments and Defense. Syngress, 2014 |
| 15 | C. Hadnagy, Unmasking the Social Engineer: The Human Element of Security. John Wiley & Sons, 2014 |
| 16 | M. I. Mann, Hacking the Human: Social Engineering Techniques and Security Countermeasures. Gower Publishing, Ltd., 2012. |
| 17 | K. D. Mitnick and W. L. Simon, The Art of Deception: Controlling the Human Element of Security. John Wiley & Sons, 2011. |
| 18 | K. Mitnick, Ghost in the Wires: My Adventures as the World’s Most Wanted Hacker. Hachette UK, 2011. |
| 19 | J. Long, No Tech Hacking: A Guide to Social Engineering, Dumpster Diving, and Shoulder Surfing. Syngress, 2011. |
| 20 | C. Hadnagy, Social Engineering: The Art of Human Hacking. John Wiley & Sons, 2010. |
| Corpus Name | CSE Corpus |
|---|---|
| Collection methods | Web scraping, pattern-matching text extraction |
| Corpus size | (N) 56 text dialogues/3380 sentences |
| Vocabulary size | (V) 4500 terms |
| Content | chat-based dialogues |
| Collection date | June 2018–December 2020 |
| Creation date | June 2021 |
| No# | Sentence | Tag |
|---|---|---|
| 1 | You will find contact numbers on the Intranet | IT |
| 2 | Let me get that name again and give me your employee number | Enterprise |
| 3 | Our project leader is Jerry Mendel | Enterprise |
| 4 | I can cut some corners and save some time, but I’ll need your username and password | IT |
| 5 | Okay, can you tell me again your employee ID number. | Enterprise |
| 6 | I’ll just hit reset and the old one will be wiped out | IT |
| 7 | For account identification may you please provide your account number | IT |
| 8 | Tom, Its Eddie… go ahead and try your network connection | IT |
| 9 | May I have your full name and email address please | Personal |
| 10 | Rest assured that they will be able to read the chat transcript as well as the documentation in your case | - |
| Syntactic | Semantic |
|---|---|
| What Part-of Speech (POS) type is it? | Is it a CSE ontology entity? |
| Is it a bi-gram? | What role does it play in the CSE ontology? |
| Chunk | Encoding |
|---|---|
| Mr | B-EMP-NAME |
| Robinson | I-EMP-NAME |
| is | O |
| the | O |
| head | I-POS |
| of | O |
| Financial | B-DEPT-NAME |
| Department | I-DEPT-NAME |
| and | O |
| his | O |
| office | I-DEPT |
| is | O |
| on | O |
| the | O |
| second | I-OFF-NUM |
| floor | I-OFF-NUM |
| Annotator | B | B | B | Total | |
| Category | personal | enterprise | IT | ||
| A | personal | 1665 | 63 | 13 | 1741 |
| A | enterprise | 59 | 1442 | 31 | 1532 |
| A | IT | 14 | 19 | 1194 | 1227 |
| Total | 1738 | 1524 | 1238 | 4500 |
| No # | Utterance |
|---|---|
| 1 | which computer servers does your group use |
| 2 | do you sign in under the username Rosemary |
| 3 | ok i am trying to logon now |
| 4 | trace it back to where its plugged |
| 5 | it could save us both big headaches the next time this network problem happens |
| 6 | did you turn your computer off |
| 7 | thanks a lot please wait for my email |
| 8 | take care and bye for now |
| 9 | my flex 2 is charged but wont turn on is it normal |
| 10 | are you experiencing any computer issues presently |
| Tag | F1 | Precision | Recall | Support |
|---|---|---|---|---|
| PERSONAL | 0.67 | 0.63 | 0.51 | 65 |
| IT | 0.86 | 0.93 | 0.64 | 122 |
| ENTERPRISE | 0.71 | 0.84 | 0.56 | 89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsinganos, N.; Mavridis, I. Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks. Appl. Sci. 2021, 11, 10871. https://doi.org/10.3390/app112210871
Tsinganos N, Mavridis I. Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks. Applied Sciences. 2021; 11(22):10871. https://doi.org/10.3390/app112210871
Chicago/Turabian StyleTsinganos, Nikolaos, and Ioannis Mavridis. 2021. "Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks" Applied Sciences 11, no. 22: 10871. https://doi.org/10.3390/app112210871
APA StyleTsinganos, N., & Mavridis, I. (2021). Building and Evaluating an Annotated Corpus for Automated Recognition of Chat-Based Social Engineering Attacks. Applied Sciences, 11(22), 10871. https://doi.org/10.3390/app112210871