EnCaps: Clothing Image Classification Based on Enhanced Capsule Network

 , and
, and
Abstract
:1. Introduction
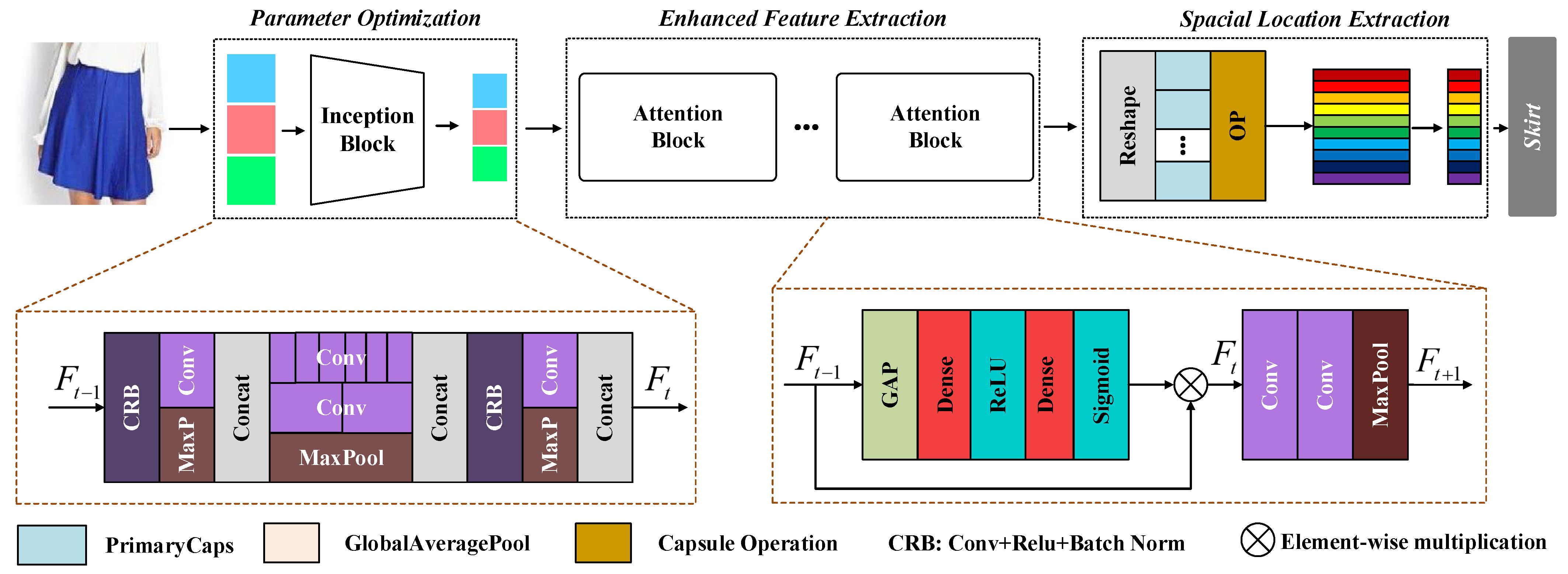
2. Materials and Methods
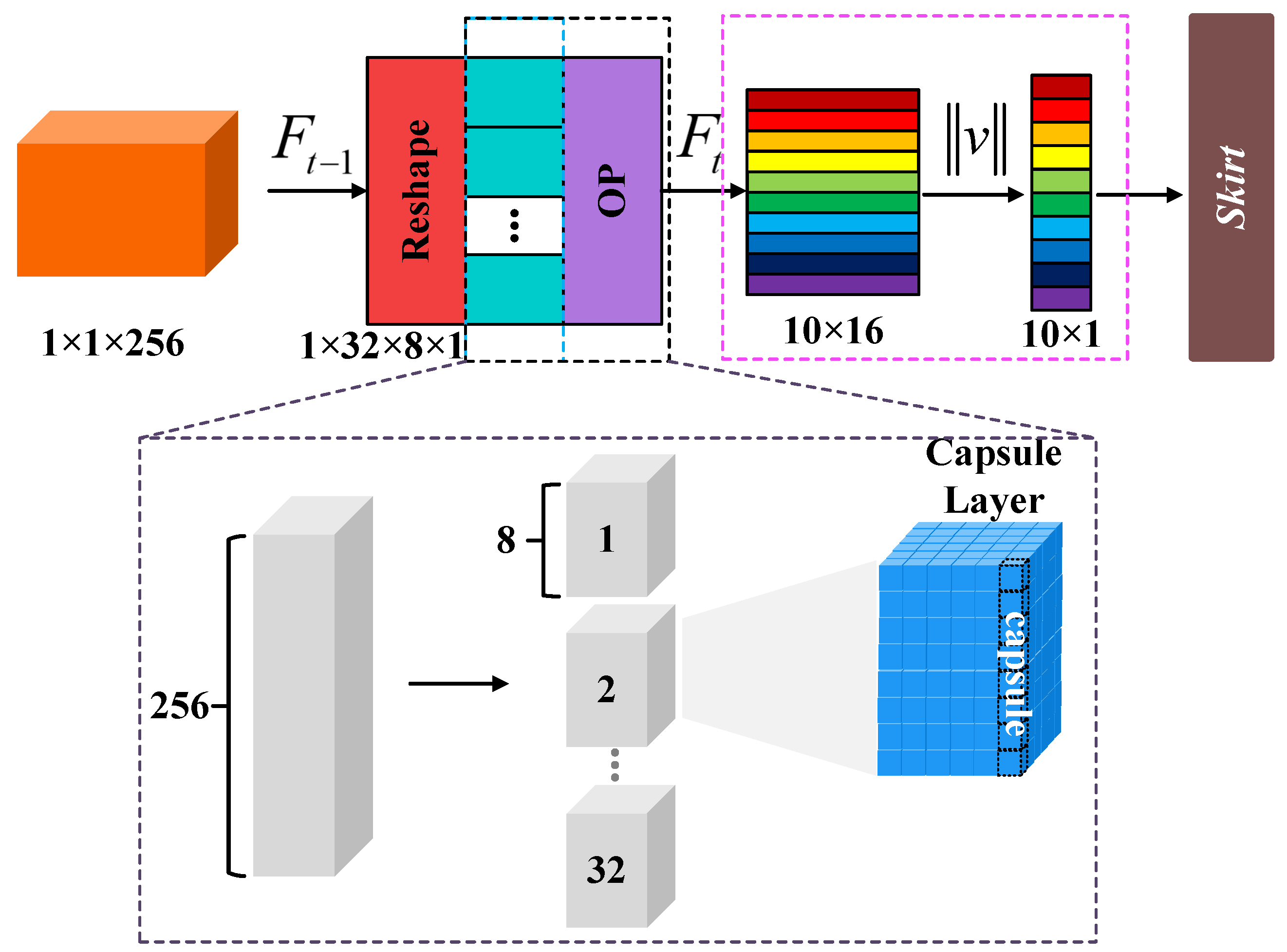
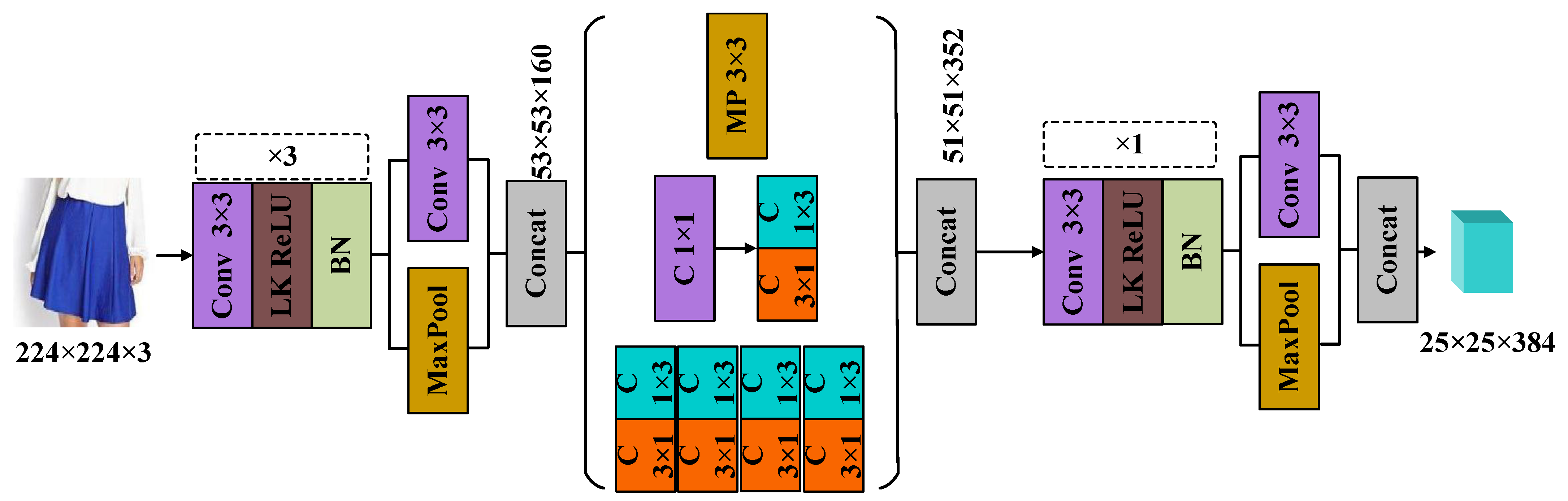
2.1. Spatial Structure Extraction
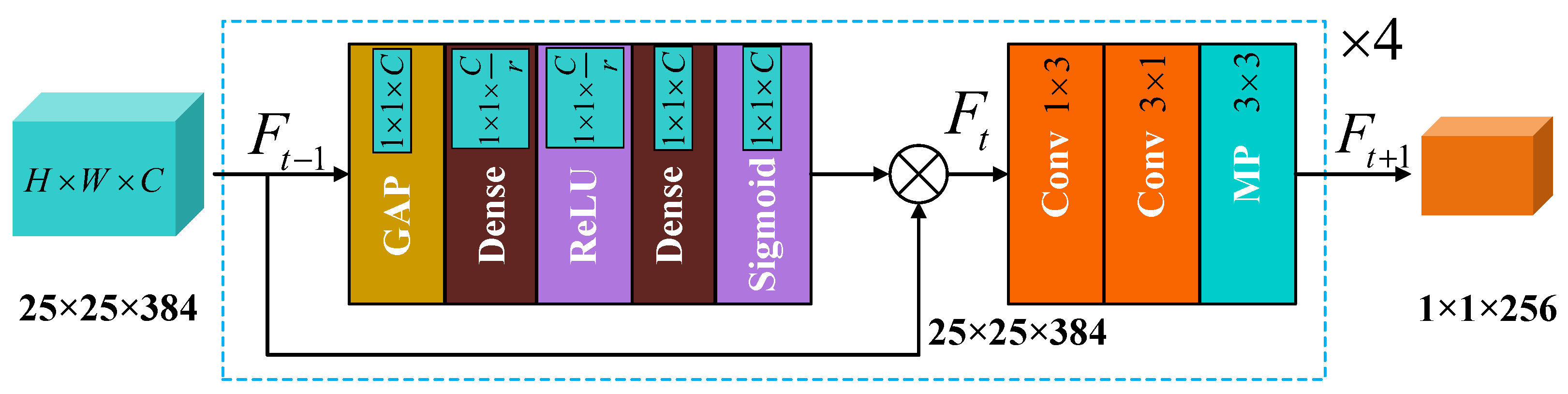
2.2. Enhanced Feature Extraction
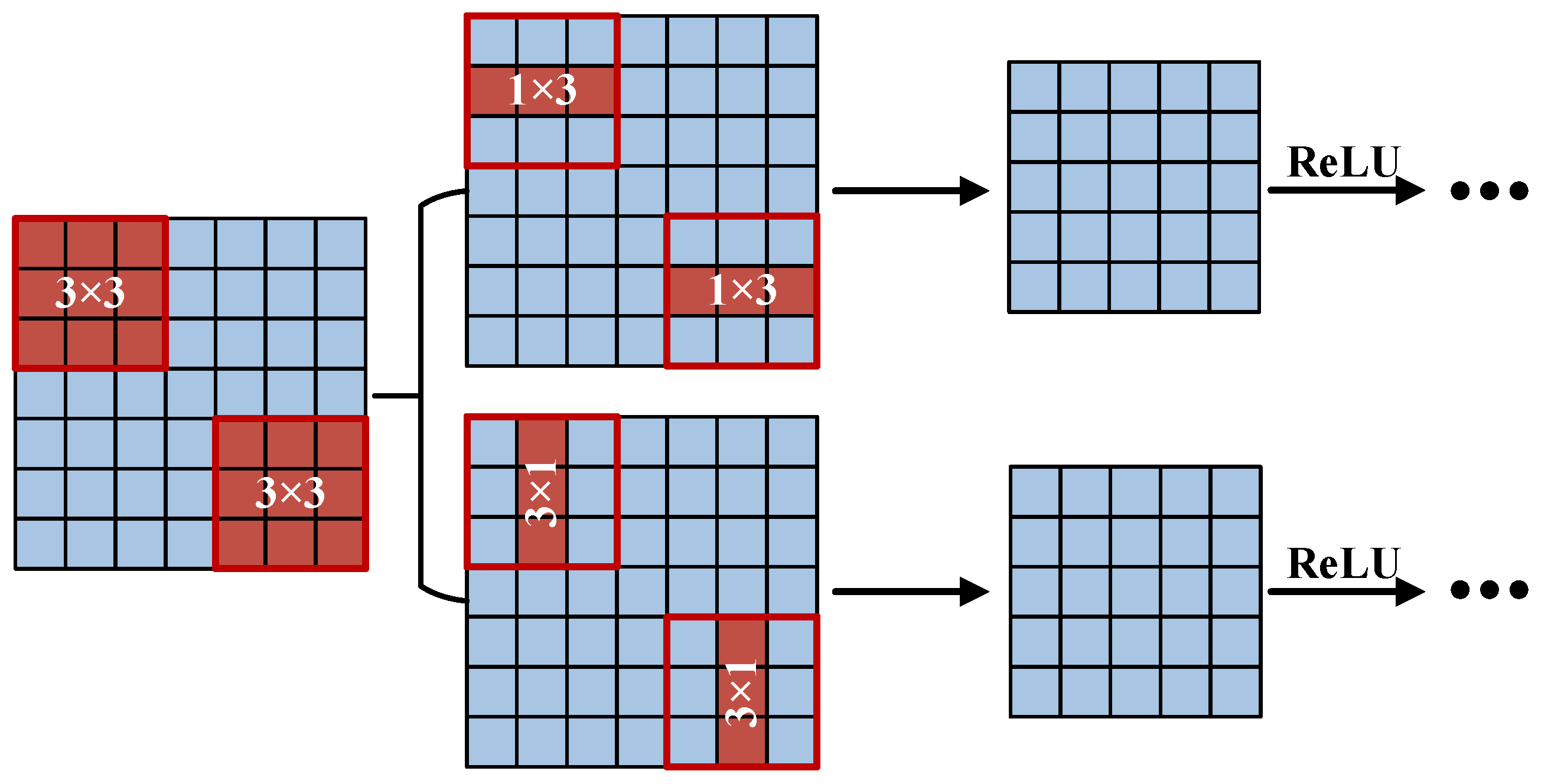
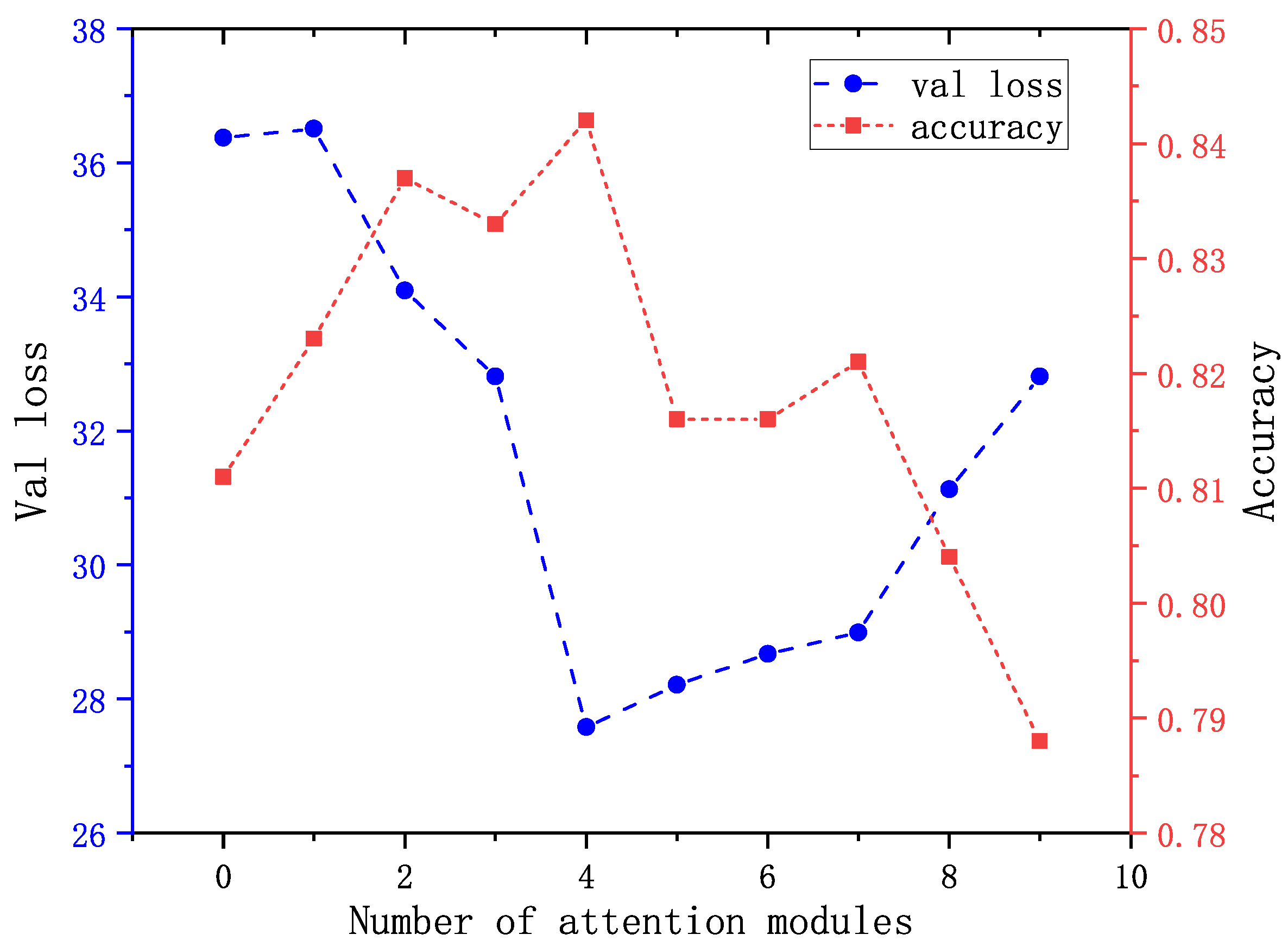
2.3. Parameter Optimization
3. Experiments and Results
3.1. Dataset
3.2. Evaluation Criterion
3.3. Experiment Platform Setting
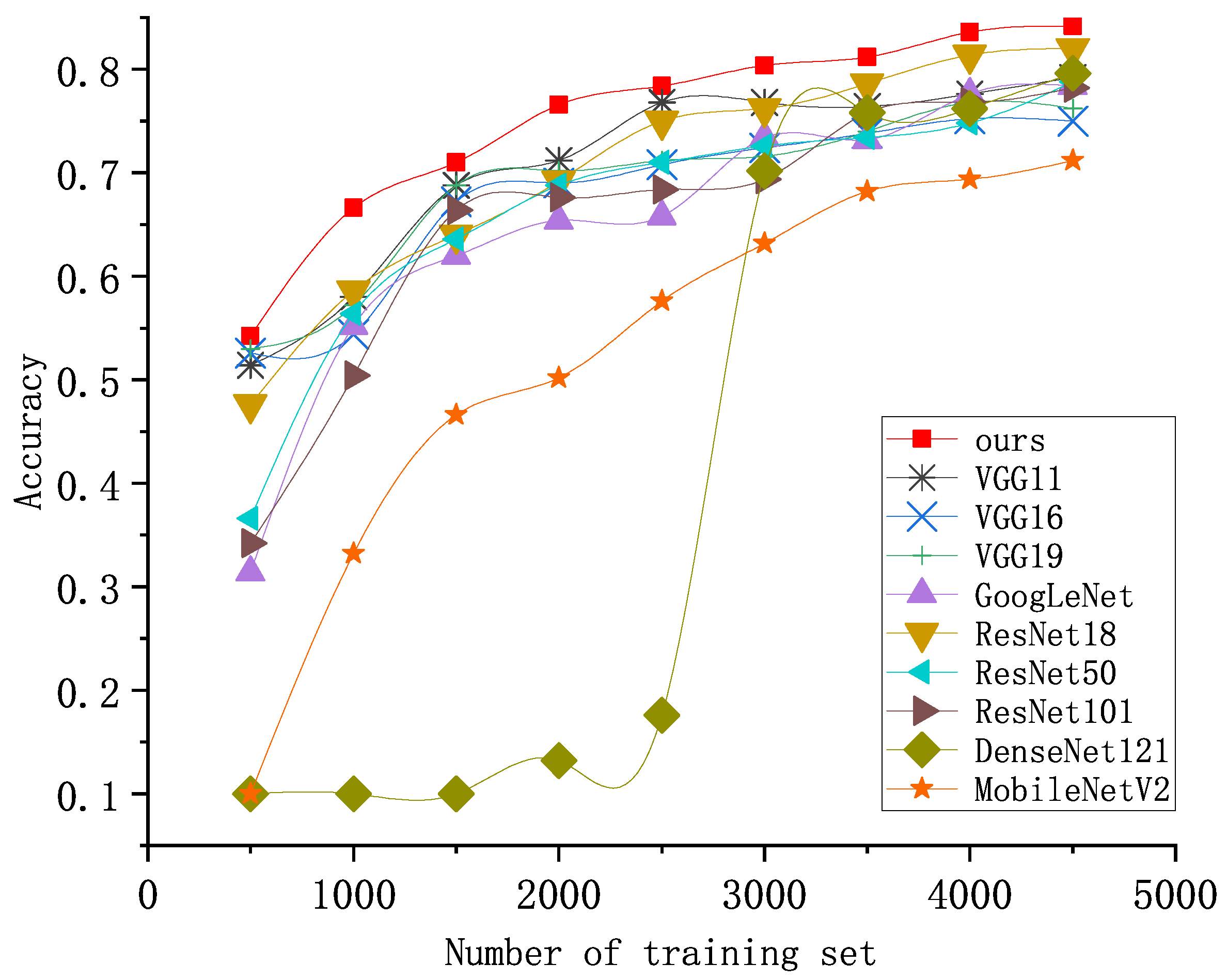
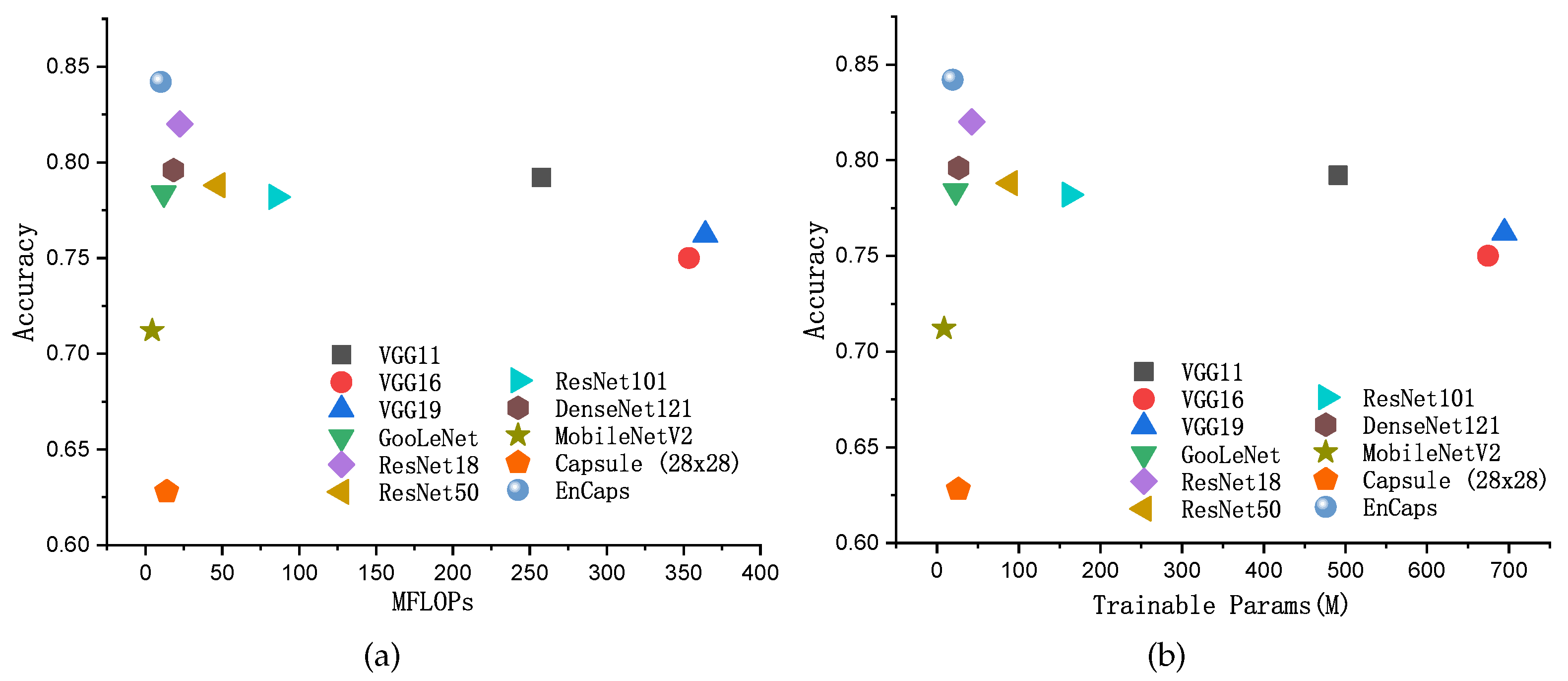
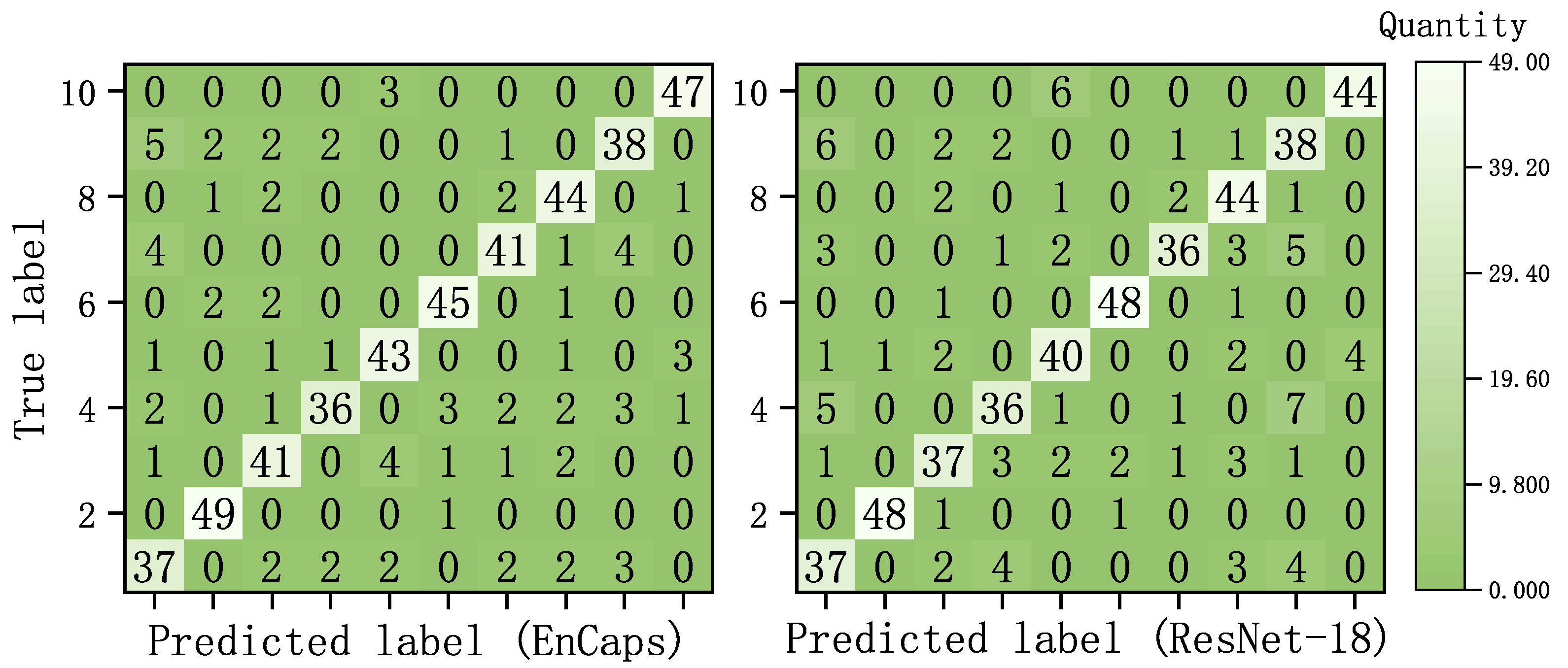
3.4. The Comparison with Other Methods
4. Discussion and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, S.; Wu, Y.; Fu, Y. Deep bidirectional cross-triplet embedding for online clothing shopping. Acm Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–22. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Z.; Zhang, Y.; Gu, X. Query-free clothing retrieval via implicit relevance feedback. IEEE Trans. Multimed. 2017, 20, 2126–2137. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Sun, Y.; Liu, L.; Wang, X.; Li, L.; Liu, W. ClothingOut: A category-supervised GAN model for clothing segmentation and retrieval. Neural Comput. Appl. 2020, 32, 4519–4530. [Google Scholar] [CrossRef]
- Hidayati, S.C.; You, C.W.; Cheng, W.H.; Hua, K.L. Learning and recognition of clothing genres from full-body images. IEEE Trans. Cybern. 2017, 48, 1647–1659. [Google Scholar] [CrossRef]
- Wang, W.; Xu, Y.; Shen, J.; Zhu, S.C. Attentive fashion grammar network for fashion landmark detection and clothing category classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4271–4280. [Google Scholar]
- Zhang, S.; Song, Z.; Cao, X.; Zhang, H.; Zhou, J. Task-aware attention model for clothing attribute prediction. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1051–1064. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, P.; Yuan, C.; Wang, Z. Texture and shape biased two-stream networks for clothing classification and attribute recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13538–13547. [Google Scholar]
- An, L.; Li, W. An integrated approach to fashion flat sketches classification. Int. J. Cloth. Sci. Technol. 2014, 26, 346–366. [Google Scholar] [CrossRef]
- Berg, T.L.; Ortiz, L.E.; Kiapour, M.H.; Yamaguchi, K. Parsing clothing in fashion photographs. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Yang, X.; Yuan, S.; Tian, Y. Assistive clothing pattern recognition for visually impaired people. IEEE Trans. Hum. Mach. Syst. 2014, 44, 234–243. [Google Scholar] [CrossRef]
- Chen, H.; Gallagher, A.; Girod, B. Describing clothing by semantic attributes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 609–623. [Google Scholar]
- Zhan, H.; Yi, C.; Shi, B.; Lin, J.; Duan, L.Y.; Kot, A.C. Pose-normalized and appearance-preserved street-to-shop clothing image generation and feature learning. IEEE Trans. Multimed. 2020, 23, 133–144. [Google Scholar] [CrossRef]
- Gao, Y.; Kuang, Z.; Li, G.; Luo, P.; Chen, Y.; Lin, L.; Zhang, W. Fashion Retrieval via Graph Reasoning Networks on a Similarity Pyramid. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1–15. [Google Scholar] [CrossRef]
- Donati, L.; Iotti, E.; Mordonini, G.; Prati, A. Fashion Product Classification through Deep Learning and Computer Vision. Appl. Sci. 2019, 9, 1385. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.J.; Lee, D.H.; Niaz, A.; Kim, C.Y.; Memon, A.A.; Choi, K.N. Multiple-Clothing Detection and Fashion Landmark Estimation Using a Single-Stage Detector. IEEE Access 2021, 9, 11694–11704. [Google Scholar] [CrossRef]
- Chen, W.; Huang, P.; Xu, J.; Guo, X.; Guo, C.; Sun, F.; Li, C.; Pfadler, A.; Zhao, H.; Zhao, B. POG: Personalized outfit generation for fashion recommendation at Alibaba iFashion. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2662–2670. [Google Scholar]
- Zhang, S.; Liu, S.; Cao, X.; Song, Z.; Zhou, J. Watch fashion shows to tell clothing attributes. Neurocomputing 2018, 282, 98–110. [Google Scholar] [CrossRef]
- Yang, Q.; Wu, A.; Zheng, W.S. Person re-identification by contour sketch under moderate clothing change. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, L.; Zhang, H.; Ji, Y.; Wu, Q.J. Toward AI fashion design: An Attribute-GAN model for clothing match. Neurocomputing 2019, 341, 156–167. [Google Scholar] [CrossRef]
- Huang, C.Q.; Chen, J.K.; Pan, Y.; Lai, H.J.; Yin, J.; Huang, Q.H. Clothing landmark detection using deep networks with prior of key point associations. IEEE Trans. Cybern. 2018, 49, 3744–3754. [Google Scholar] [CrossRef] [PubMed]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jia, B.; Huang, Q. DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing. Appl. Sci. 2020, 10, 884. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Ye, S.; Liao, P.; Liu, Y.; Su, G.; Sun, Y. Enhanced Capsule Network for Medical image classification. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 1544–1547. [Google Scholar] [CrossRef]
- Xiang, C.; Zhang, L.; Tang, Y.; Zou, W.; Xu, C. MS-CapsNet: A novel multi-scale capsule network. IEEE Signal Process. Lett. 2018, 25, 1850–1854. [Google Scholar] [CrossRef]
- Edraki, M.; Rahnavard, N.; Shah, M. Subspace capsule network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10745–10753. [Google Scholar]
- Do Rosario, V.M.; Borin, E.; Breternitz, M. The multi-lane capsule network. IEEE Signal Process. Lett. 2019, 26, 1006–1010. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1804–2767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | EnCaps-Reduce | Shape |
|---|---|---|
| Input | / | N × 384 × 25 × 25 |
| SE_layer | N × 384 × 25 × 25 | |
| Conv_5 + ReLU + BN | Conv-384(k:1,3;s:1,1;p:0,0) | N × 384 × 25 × 25 |
| Conv-384(k:3,1;s:1,1;p:0,0) | N × 384 × 25 × 25 | |
| Max(k:2,2;s:2,2;p:1,1) | N × 384 × 12 × 12 | |
| SE_layer | N × 384 × 12 × 12 | |
| Conv_6 + ReLU + BN | Conv-512(k:1,3;s:1,1;p:1,1) | N × 512 × 12 × 12 |
| Conv-512(k:3,1;s:1,1;p:1,1) | N × 512 × 12 × 12 | |
| Max(k:2,2;s:2,2;p:1,1) | N × 512 × 6 × 6 | |
| SE_layer | N × 512 × 6 × 6 | |
| Conv_7 + ReLU + BN | Conv-512(k:1,3;s:1,1;p:1,1) | N × 512 × 4 × 4 |
| Conv-512(k:3,1;s:1,1;p:1,1) | N × 512 × 4 × 4 | |
| Max(k:2,2;s:2,2;p:1,1) | N × 512 × 2 × 2 | |
| SE_layer | N × 512 × 2 × 2 | |
| Conv_8 + ReLU + BN | Conv-256(k:1,2;s:1,1;p:1,1) | N × 256 × 1 × 1 |
| Conv-256(k:2,1;s:1,1;p:1,1) | N × 256 × 1 × 1 | |
| output | N × 256 |
| Layer | EnCaps-Stem | Shape | ||
|---|---|---|---|---|
| Input | / | N × 3 × 224 × 224 | ||
| Conv_1 + ReLU + BN | Conv-32(k:3,3;s:2,2;p:1,1) | N × 32 × 111 × 111 | ||
| Conv_2 + ReLU + BN | Conv-32(k:3,3;s:1,1;p:1,1) | N × 32 × 109 × 109 | ||
| Conv_3 + ReLU + BN | Conv-64(k:3,3;s:1,1;p:1,1) | N × 64 × 107 × 107 | ||
| Conv-96(k:3,3;s:2,2;p:1,1) | Max(k:3,3;s:2,2;p:1,1) | \ | ||
| Concatenate | N × 160 × 53 × 53 | |||
| Conv-64(k:1,3;s:1,1;p:0,0) | \ | |||
| Conv-64(k:3,1;s:1,1;p:0,0) | ||||
| Conv-64(k:1,3;s:1,1;p:0,0) | ||||
| Conv-64(k:3,1;s:1,1;p:0,0) | Conv-64(k:1,1;s:1,1;p:0,0) | |||
| Conv-64(k:1,3;s:1,1;p:0,0) | Conv-96(k:3,1;s:1,1;p:1,1) | Max(k:3,3;s:1,1;p:1,1) | ||
| Conv-64(k:3,1;s:1,1;p:0,0) | Conv-96(k:1,3;s:1,1;p:1,1) | |||
| Conv-96(k:1,3;s:1,1;p:1,1) | ||||
| Conv-96(k:3,1;s:1,1;p:1,1) | ||||
| Concatenate | N × 352 × 51 × 51 | |||
| Conv_4 + ReLU + BN | Conv-192(k:1,1;s:1,1;p:1,1) | N × 352 × 51 × 51 | ||
| Conv-96(k:3,3;s:2,2;p:1,1) | Max(k:3,3;s:2,2;p:1,1) | \ | ||
| output | Concatenate | N × 384 × 25 × 25 | ||
| Validation Accuracy | Validation Loss | |
|---|---|---|
| stem module | 0.682 | 47.42 |
| reduced module | 0.778 | 43.10 |
| stem & reduced module | 0.628 | 52.76 |
| EnCaps | 0.842 | 27.58 |
| Real | 1 | 0 |
| MFLOPs | Trainable Params (M) | Top-1 Acc. | |
|---|---|---|---|
| VGG11 | 257.592715 | 491.36 | 0.792 |
| VGG16 | 353.619785 | 674.52 | 0.75 |
| VGG19 | 364.23662 | 694.78 | 0.762 |
| GoogLeNet | 11.953082 | 22.83 | 0.784 |
| ResNet18 | 22.363325 | 42.65 | 0.82 |
| ResNet50 | 47.057184 | 89.75 | 0.788 |
| ResNet101 | 85.041593 | 162.2 | 0.782 |
| DenseNet121 | 18.396804 | 26.57 | 0.796 |
| MobileNetV2 | 4.468249 | 8.53 | 0.712 |
| Capsule (28 × 28) | 13.863176 | 26.11 | 0.628 |
| EnCaps | 10.019512 | 19.13 | 0.842 |
| Real | N/A | N/A | 1 |
| Accuracy | Precision | Recall | Specificity | Sensitivity | ||
|---|---|---|---|---|---|---|
| Blouse | 0.928 | 0.652 | 0.6 | 0.964 | 0.6 | 0.625 |
| Jeans | 0.991 | 0.925 | 0.98 | 0.991 | 0.98 | 0.951 |
| Skirt | 0.956 | 0.781 | 0.78 | 0.976 | 0.78 | 0.78 |
| Cardigan | 0.952 | 0.842 | 0.64 | 0.987 | 0.64 | 0.727 |
| Dress | 0.962 | 0.782 | 0.86 | 0.973 | 0.86 | 0.819 |
| Short | 0.978 | 0.882 | 0.9 | 0.987 | 0.9 | 0.891 |
| Tee | 0.962 | 0.816 | 0.8 | 0.98 | 0.8 | 0.808 |
| Tank | 0.968 | 0.815 | 0.88 | 0.978 | 0.88 | 0.846 |
| Hoodie | 0.948 | 0.731 | 0.76 | 0.969 | 0.76 | 0.745 |
| Romper | 0.984 | 0.904 | 0.94 | 0.989 | 0.94 | 0.922 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, F.; Du, C.; Hua, A.; Jiang, M.; Wei, X.; Peng, T.; Hu, X. EnCaps: Clothing Image Classification Based on Enhanced Capsule Network. Appl. Sci. 2021, 11, 11024. https://doi.org/10.3390/app112211024
Yu F, Du C, Hua A, Jiang M, Wei X, Peng T, Hu X. EnCaps: Clothing Image Classification Based on Enhanced Capsule Network. Applied Sciences. 2021; 11(22):11024. https://doi.org/10.3390/app112211024
Chicago/Turabian StyleYu, Feng, Chenghu Du, Ailing Hua, Minghua Jiang, Xiong Wei, Tao Peng, and Xinrong Hu. 2021. "EnCaps: Clothing Image Classification Based on Enhanced Capsule Network" Applied Sciences 11, no. 22: 11024. https://doi.org/10.3390/app112211024
APA StyleYu, F., Du, C., Hua, A., Jiang, M., Wei, X., Peng, T., & Hu, X. (2021). EnCaps: Clothing Image Classification Based on Enhanced Capsule Network. Applied Sciences, 11(22), 11024. https://doi.org/10.3390/app112211024