
AI Model for Predicting Legal Judgments to Improve Accuracy and Explainability of Online Privacy Invasion Cases


Abstract
:1. Introduction
2. Related Works
2.1. Prediction of Legal Judgments
2.2. Algorithms for Protecting Online Privacy
3. Research Method
3.1. Data Preparation
3.2. Classification Techniques in Machine Learning
3.2.1. Linear Discriminant Analysis (LDA)
3.2.2. Classification and Regression Tree (CART)
3.2.3. Neural Networks (NNET)
3.2.4. Support Vector Machines (SVM)
3.2.5. Random Forests
3.3. Network Text Analysis (NTA)
4. Performance Comparison of Machine Learning
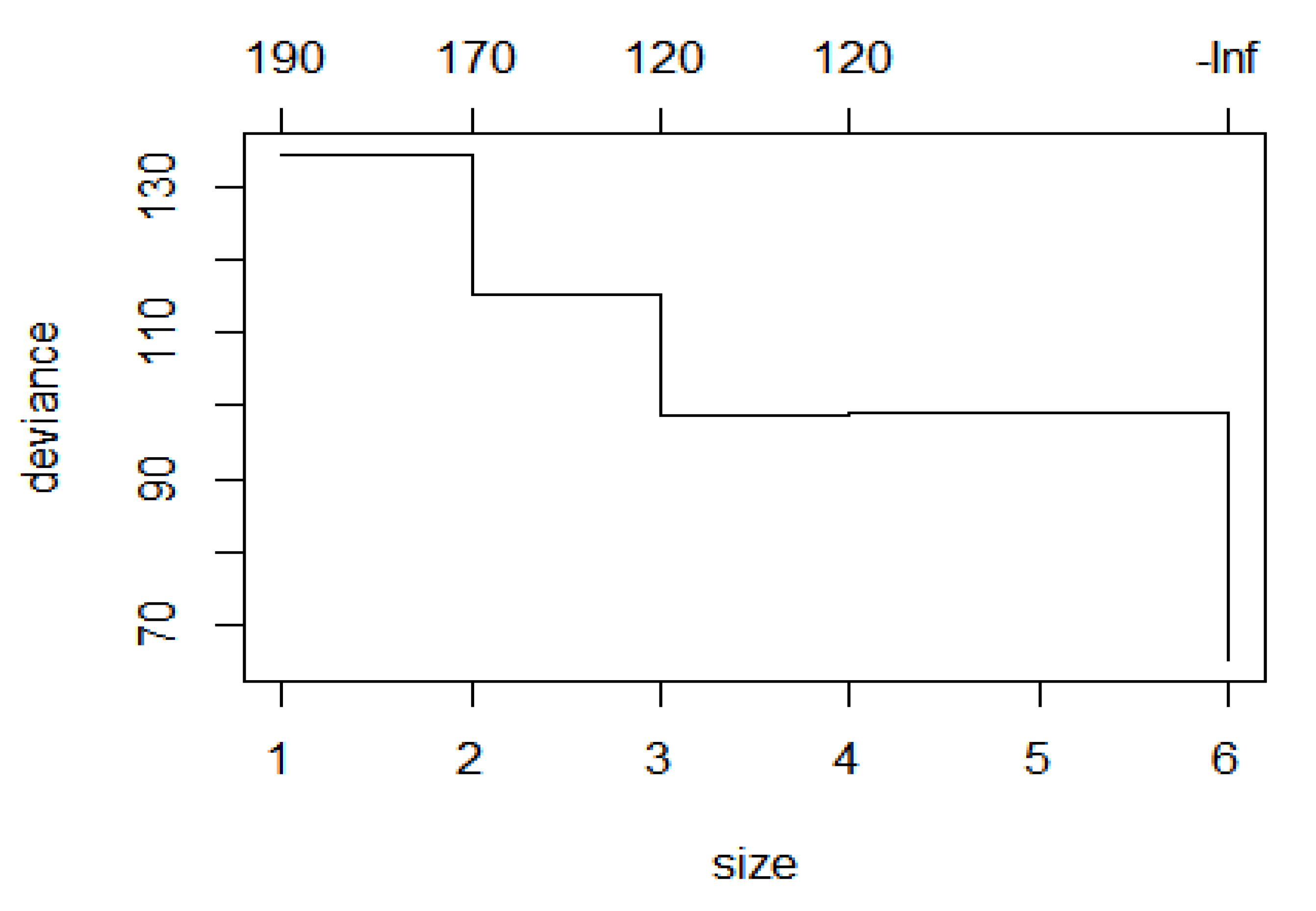
4.1. Classification Model Construction
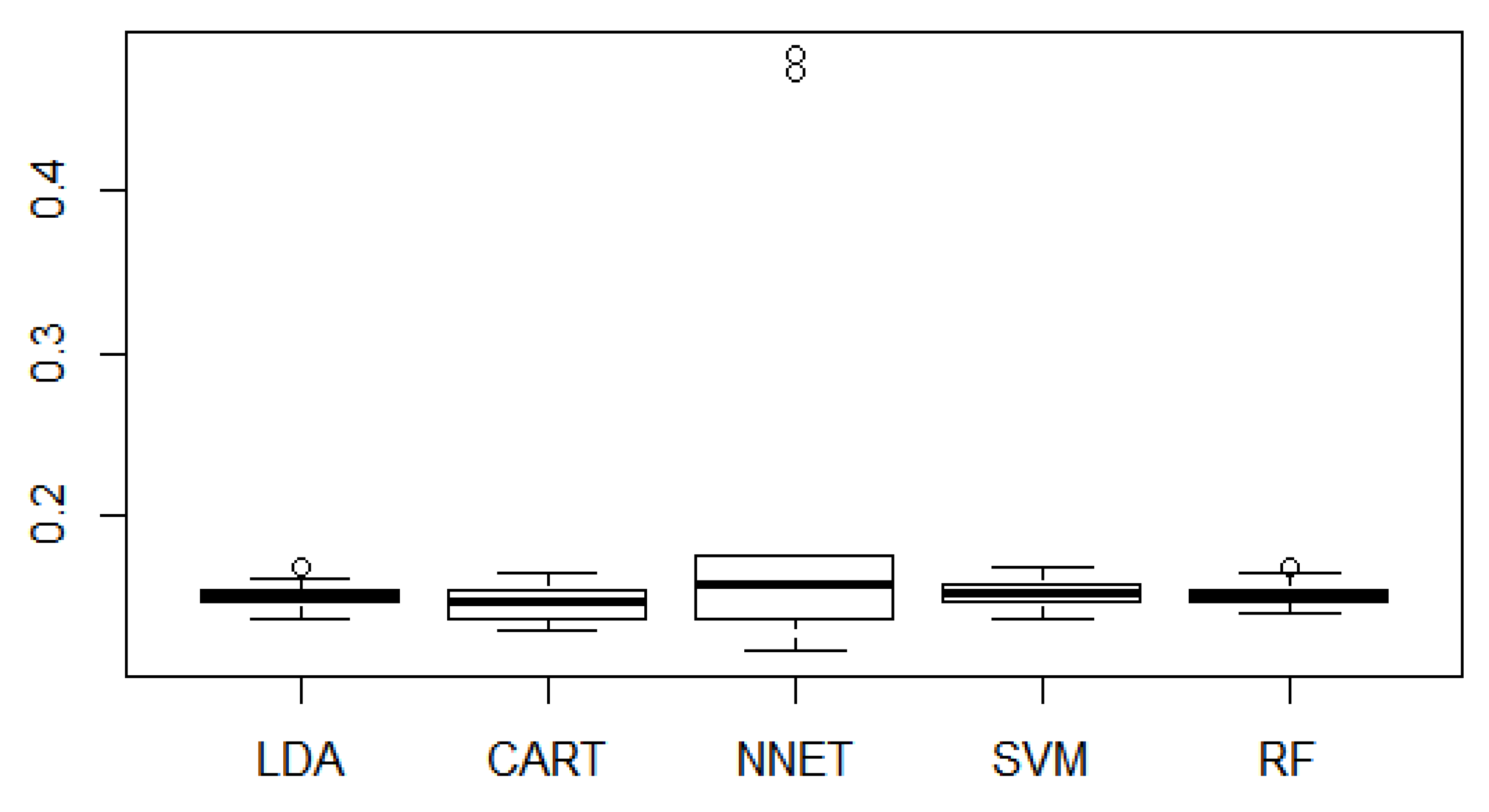
4.2. Model Validation and Performance Comparison
5. Constructing Networks of Legal Judgments
5.1. Analysis of the Possibility of Judgment According to Types of Privacy Invasion
5.1.1. Possibility of Conviction and Innocence in Terms of Criminal Law
5.1.2. Possibility of Judgment of Civil Compensation by Invasion Type
6. Conclusions
7. Contributions and Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Kim, Y.-H.; Hong, J.-S.; Cha, H.-J.; Kook, K.-H. A Study of Personal Information Handler Based on Social Network Analysis. J. Secur. Eng. 2016, 13, 143–154. [Google Scholar] [CrossRef]
- Kelbert, F.; Shirazi, F.; Simo, H.; Wüchner, T.; Buchmann, J.; Pretschner, A.; Waidner, M. State of online privacy: A technical perspective. In Internet Privacy; Springer: Berlin/Heidelberg, Germany, 2012; pp. 189–279. [Google Scholar]
- Popping, R. Knowledge graphs and network text analysis. Soc. Sci. Inf. 2003, 42, 91–106. [Google Scholar] [CrossRef] [Green Version]
- Ashley, K.D.; Brüninghaus, S. Computer models for legal prediction. Jurimetrics 2006, 46, 309–352. [Google Scholar]
- Ashley, K.D.; Brüninghaus, S. Automatically classifying case texts and predicting outcomes. Artif. Intell. Law 2009, 17, 125–165. [Google Scholar] [CrossRef]
- Bruninghaus, S.; Ashley, K.D. Predicting Outcomes of Case Based Legal Arguments. In Proceedings of the 9th International Conference on Artificial Intelligence and Law, Scotland, UK, 24–28 June 2003; pp. 233–242. [Google Scholar]
- Branting, L.K.; Pfeifer, C.; Brown, B.; Ferro, L.; Aberdeen, J.; Weiss, B.; Pfaff, M.; Liao, B. Scalable and explainable legal prediction. Artif. Intell. Law 2021, 29, 213–238. [Google Scholar] [CrossRef]
- Archer, K.J.; Kimes, R.V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Lame, G. Using NLP techniques to identify legal ontology components: Concepts and relations. Artif. Intell. Law 2004, 12, 379–396. [Google Scholar] [CrossRef]
- Lax, G.; Russo, A.; Fascì, L.S. A Blockchain-based approach for matching desired and real privacy settings of social network users. Inf. Sci. 2021, 557, 220–235. [Google Scholar] [CrossRef]
- Hanguang, L.; Yu, N. Intrusion detection technology research based on apriori algorithm. Phys. Procedia 2012, 24, 1615–1620. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, T.; Lucchi, A.; Lacoste-Julien, S.; McWilliams, B. Variance reduced stochastic gradient descent with neighbors. arXiv 2015, arXiv:1506.03662. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Amiri, F.; Yazdani, N.; Shakery, A.; Chinaei, A.H. Hierarchical anonymization algorithms against background knowledge attack in data releasing. Knowl.-Based Syst. 2016, 101, 71–89. [Google Scholar] [CrossRef]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Megías, D. Individual differential privacy: A utility-preserving formulation of differential privacy guarantees. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Kotsogiannis, I.; Machanavajjhala, A.; Hay, M.; Miklau, G. Pythia: Data Dependent Differentially Private Algorithm Selection. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1323–1337. [Google Scholar]
- Lundmark, M.; Dahlman, C.-J. Differential privacy and machine learning: Calculating sensitivity with generated data sets. Comput. Sci. 2017. Available online: https://kth.diva-portal.org/smash/get/diva2:1112478/FULLTEXT01.pdf (accessed on 16 November 2021).
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Philip, S.Y. A general survey of privacy-preserving data mining models and algorithms. In Privacy-Preserving Data Mining; Springer: Berlin/Heidelberg, Germany, 2008; pp. 11–52. [Google Scholar]
- Dong, B.; Liu, R.; Wang, W.H. Prada: Privacy-Preserving Data-Deduplication-as-a-Service. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1559–1568. [Google Scholar]
- Yi, X.; Rao, F.-Y.; Bertino, E.; Bouguettaya, A. Privacy-Preserving Association Rule Mining in Cloud Computing. In Proceedings of the 10th ACM Symposium on Information, Computer and Communications Security, Singapore, 17 March–14 April 2015; pp. 439–450. [Google Scholar]
- Arewa, O.B. Open access in a closed universe: Lexis, Westlaw, law schools, and the legal information market. Lewis Clark Law Rev. 2006, 10, 797. [Google Scholar]
- Takasugi, N. E-Commerce Law and the Prospects for Uniform E-Commerce Rules on the Privacy and Security of Electronic Communications. Ariz. J. Int. Comp. Law 2016, 33, 257. [Google Scholar]
- Valdes, A.; Skinner, K. Adaptive, Model-Based Monitoring for Cyber Attack Detection. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2000; pp. 80–93. [Google Scholar]
- Argaw, S.T.; Bempong, N.-E.; Eshaya-Chauvin, B.; Flahault, A. The state of research on cyberattacks against hospitals and available best practice recommendations: A scoping review. BMC Med Inform. Decis. Mak. 2019, 19, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.-S. A content analysis of journal articles using the language network analysis methods. J. Korean Soc. Inf. Manag. 2014, 31, 49–68. [Google Scholar]
- Maroco, J.; Silva, D.; Rodrigues, A.; Guerreiro, M.; Santana, I.; de Mendonça, A. Data mining methods in the prediction of Dementia: A real-data comparison of the accuracy, sensitivity and specificity of linear discriminant analysis, logistic regression, neural networks, support vector machines, classification trees and random forests. BMC Res. Notes 2011, 4, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Mood, C. Logistic regression: Why we cannot do what we think we can do, and what we can do about it. Eur. Sociol. Rev. 2010, 26, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Tan, Q. Dynamical behavior of computer virus on Internet. Appl. Math. Comput. 2010, 217, 2520–2526. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Haupt, S.E.; Cowie, J.; Linden, S.; McCandless, T.; Kosovic, B.; Alessandrini, S. Machine learning for applied weather prediction. In Proceedings of the 2018 IEEE 14th International Conference on e-Science (e-Science), IEEE, Amsterdam, The Netherlands, 29 October–1 November 2018; pp. 276–277. [Google Scholar]
- Wu, J.; Cai, Z. A naive Bayes probability estimation model based on self-adaptive differential evolution. J. Intell. Inf. Syst. 2014, 42, 671–694. [Google Scholar] [CrossRef]
- Bengio, Y.; Grandvalet, Y. No unbiased estimator of the variance of k-fold cross-validation. J. Mach. Learn. Res. 2004, 5, 1089–1105. [Google Scholar]
- Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S. An efficient hybrid multilayer perceptron neural network with grasshopper optimization. Soft Comput. 2019, 23, 7941–7958. [Google Scholar] [CrossRef]
- Anderson, J. An Introduction to Neural Networks; MIT Press: Cambridge, MA, USA, 1995; ISBN 026-201-144-1. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Padmanabhan, B.; Zheng, Z.; Kimbrough, S.O. An empirical analysis of the value of complete information for eCRM models. Mis Q. 2006, 247–267. [Google Scholar] [CrossRef] [Green Version]
- Padmanabhan, B.; Zheng, Z.; Kimbrough, S.O. Personalization from incomplete data: What you don’t know can hurt. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 154–163. [Google Scholar]
- Lawrence, R.L.; Wright, A. Rule-based classification systems using classification and regression tree (CART) analysis. Photogramm. Eng. Remote Sens. 2001, 67, 1137–1142. [Google Scholar]
- Razi, M.A.; Athappilly, K. A comparative predictive analysis of neural networks (NNs), nonlinear regression and classification and regression tree (CART) models. Expert Syst. Appl. 2005, 29, 65–74. [Google Scholar] [CrossRef]
- Tsoi, A.C.; Pearson, R. Comparison of Three Classification Techniques: CART, C4. 5 and Multi-Layer Perceptrons. In Advances in Neural Information Processing Systems; Kaufmann: San Mateo, CA, USA, 1991; pp. 963–969. [Google Scholar]
- Markham, I.S.; Mathieu, R.G.; Wray, B.A. A rule induction approach for determining the number of kanbans in a just-in-time production system. Comput. Ind. Eng. 1998, 34, 717–727. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pal, S.K.; Wang, P.P. Genetic Algorithms for Pattern Recognition; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Wang, C.; Jin, X. Study on Prediction of Legal Judgments Based on the CNN-BiGRU Model. In Proceedings of the 2020 6th International Conference on Computing and Artificial Intelligence, Tianjin, China, 23–26 April 2020; pp. 63–68. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Díaz-Uriarte, R.; De Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef] [Green Version]
- Hua, J.; Xiong, Z.; Lowey, J.; Suh, E.; Dougherty, E.R. Optimal number of features as a function of sample size for various classification rules. Bioinformatics 2005, 21, 1509–1515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shmueli, G.; Yahav, I. The forest or the trees? Tackling Simpson’s paradox with classification trees. Prod. Oper. Manag. 2018, 27, 696–716. [Google Scholar] [CrossRef]
- Caballé-Cervigón, N.; Castillo-Sequera, J.L.; Gómez-Pulido, J.A.; Gómez-Pulido, J.M.; Polo-Luque, M.L. Machine learning applied to diagnosis of human diseases: A systematic review. Appl. Sci. 2020, 10, 5135. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Sowa, J.F. Conceptual Structures: Information Processing in Mind and Machine; Addison-Wesley Longman Publishing Co. Inc.: Boston, MA, USA, 1984. [Google Scholar]
- Wellman, B.; Berkowitz, S.D. Social Structures: A Network Approach; CUP Archive: Cambridge, UK, 1988; Volume 2. [Google Scholar]
- Bhat, S.S.; Milne, S. Network effects on cooperation in destination website development. Tour. Manag. 2008, 29, 1131–1140. [Google Scholar] [CrossRef]
- Christley, R.M.; Pinchbeck, G.; Bowers, R.G.; Clancy, D.; French, N.P.; Bennett, R.; Turner, J. Infection in social networks: Using network analysis to identify high-risk individuals. Am. J. Epidemiol. 2005, 162, 1024–1031. [Google Scholar] [CrossRef] [PubMed]
- Gunning, D. Broad Agency Announcement Explainable Artificial Intelligence (XAI); Technical Report; Defense Advanced Research Projects Agency: Arlington, VA, USA, 2016. [Google Scholar]



{kind=link}
{kind=link}
| Year | Precedents | Year | Precedents | Year | Precedents | Year | Precedents |
|---|---|---|---|---|---|---|---|
| 2000 | 42 | 2005 | 41 | 2010 | 51 | 2015 | 51 |
| 2001 | 53 | 2006 | 54 | 2011 | 53 | 2016 | 56 |
| 2002 | 62 | 2007 | 44 | 2012 | 87 | 2017 | 77 |
| 2003 | 61 | 2008 | 74 | 2013 | 56 | 2018 | 83 |
| 2004 | 52 | 2009 | 49 | 2014 | 62 |
| Type of Privacy Invasion | Definition and Characteristics | Frequency |
|---|---|---|
| Adware | Refers to software that randomly shows advertisements to users but can also be used to collect personal data [23] | 124 |
| Cyberattack | An action causing damage to the other party’s company by invading the user’s PC through the internet. It is used as a general term for illegal access behaviors [24] | 79 |
| A type of cyber terrorism such as leaking personal data or crashing websites for political or social purposes [25] | ||
| Malware | A program that causes failures in system operation, acquires unauthorized access to data collection or system resources, or is used for other acts of invasion [3] | 195 |
| Spam | Refers to for-profit advertising data that are sent in unsolicited bulk, without consent, to devices such as email or cell phones of users of information and communication services [26] | 212 |
| Spyware | Software that collects personal data after being installed without the user’s consent by deceiving the user [27] | 137 |
| Vandalism | Acts of destroying order in cyberspace that threaten personal data by posting another person’s data with misuse of anonymity or through defamation of a specific person [28] | 45 |
| Virus | An illegal program that destroys important data or software by invading the user’s system or expanding damages through self-replication, using a network [29] | 184 |
| Classification | Innocence | Conviction | Prediction Rate (%) | |
|---|---|---|---|---|
| LDA | Innocence | 451 | 85 | 82.33 |
| Conviction | 109 | 453 | ||
| CART | Innocence | 460 | 76 | 83.16 |
| Conviction | 109 | 453 | ||
| Neural Network | Innocence | 466 | 70 | 81.79 |
| Conviction | 130 | 432 | ||
| SVM | Innocence | 448 | 102 | 82.69 |
| Conviction | 88 | 460 | ||
| Random Forest | Innocence | 463 | 73 | 83.06 |
| Conviction | 113 | 449 |
| Methods | Misclassification Rate (%) |
|---|---|
| LDA | 11.82 |
| CART | 11.52 |
| Neural Network | 12.04 |
| Support Vector Machine | 11.90 |
| Random Forest | 11.72 |
| Main Keyword | Degree Centrality | Network of Privacy Invasion with Conviction |
|---|---|---|
| Adware | 0.155 |  |
| Cyberattack | 0.018 | |
| Malware | 0.278 | |
| Spam | 0.266 | |
| Spyware | 0.230 | |
| Vandalism | 0.034 | |
| Virus | 0.191 |
| Main Keyword | Degree Centrality | Network of Privacy Invasion with Innocence |
|---|---|---|
| Adware | 0.143 |  |
| Cyberattack | 0.085 | |
| Malware | 0.221 | |
| Spam | 0.142 | |
| Spyware | 0.429 | |
| Vandalism | 0.222 | |
| Virus | 0.102 |
| Main Keyword | Degree Centrality | Network of Privacy Invasion with Compensation |
|---|---|---|
| Adware | 0.173 |  |
| Cyberattack | 0.198 | |
| Malware | 0.231 | |
| Vandalism | 0.098 | |
| Virus | 0.102 | |
| Spam | 0.200 | |
| Spyware | 0.211 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, M.; Chai, S. AI Model for Predicting Legal Judgments to Improve Accuracy and Explainability of Online Privacy Invasion Cases. Appl. Sci. 2021, 11, 11080. https://doi.org/10.3390/app112311080
Park M, Chai S. AI Model for Predicting Legal Judgments to Improve Accuracy and Explainability of Online Privacy Invasion Cases. Applied Sciences. 2021; 11(23):11080. https://doi.org/10.3390/app112311080
Chicago/Turabian StylePark, Minjung, and Sangmi Chai. 2021. "AI Model for Predicting Legal Judgments to Improve Accuracy and Explainability of Online Privacy Invasion Cases" Applied Sciences 11, no. 23: 11080. https://doi.org/10.3390/app112311080
APA StylePark, M., & Chai, S. (2021). AI Model for Predicting Legal Judgments to Improve Accuracy and Explainability of Online Privacy Invasion Cases. Applied Sciences, 11(23), 11080. https://doi.org/10.3390/app112311080