
LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model



Abstract
:1. Introduction
- Increasing automatic discovery of topics from data or corpus by a joining proposed method with LDA approach.
- Providing more precise sentiment representation over topics, documents and words by integrating accurate topic and document discovery.
2. Related Works
2.1. Computer Vision and Image Processing Approaches for Sentiment Analysis
2.2. Artificaial Intelligence Approaches for Sentiment Analysis
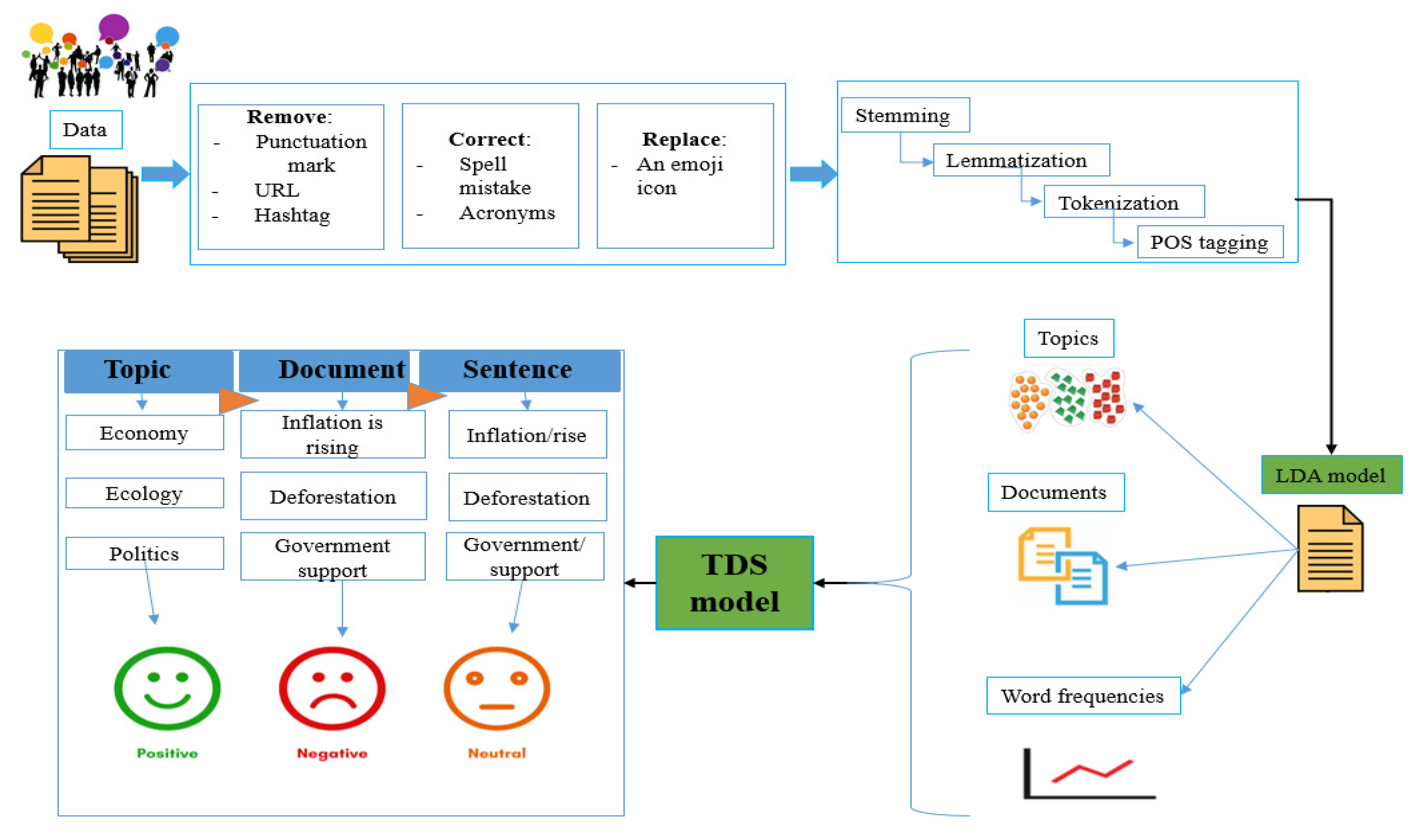
3. Proposed Method
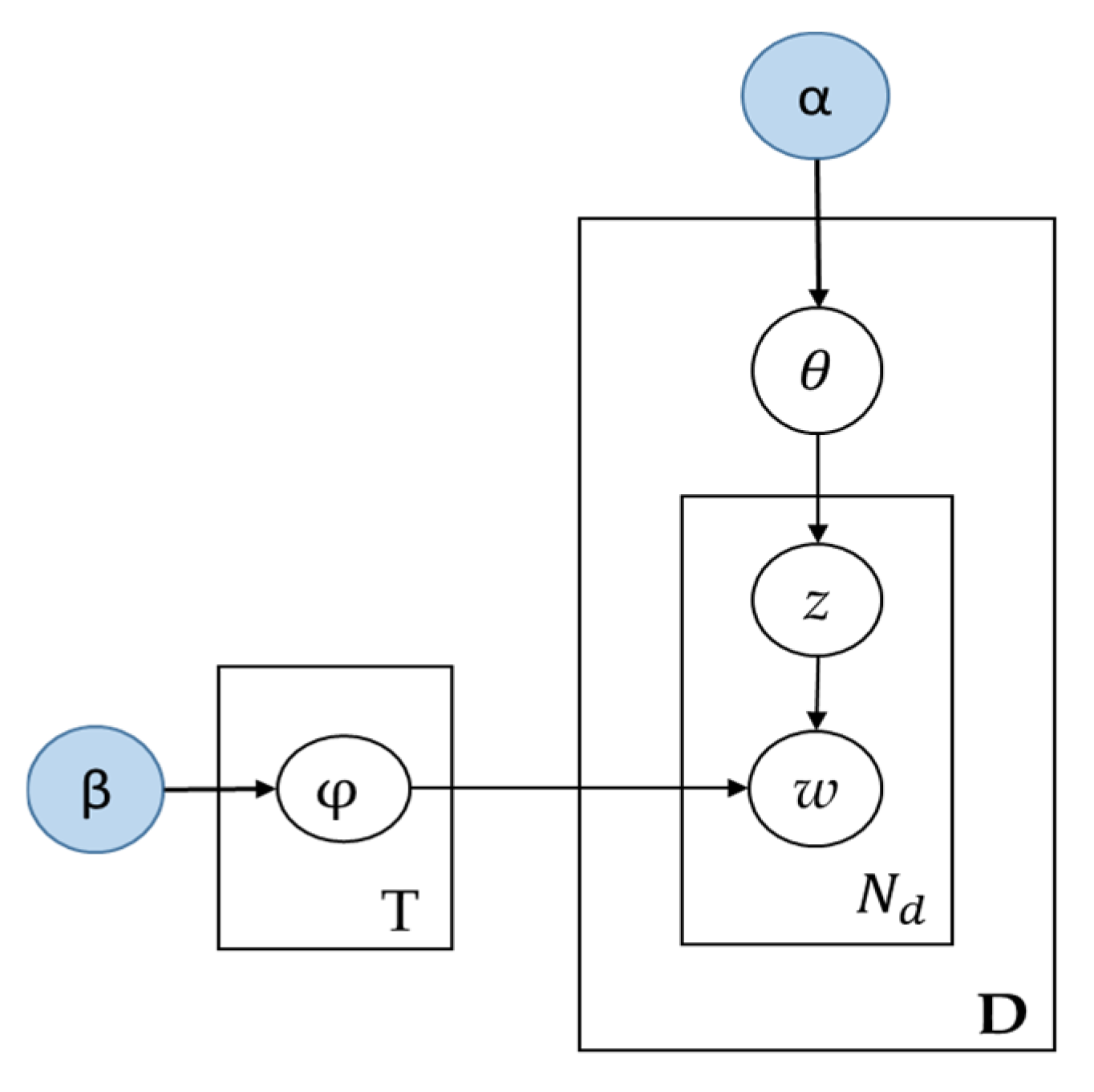
3.1. Introduction to LDA
- (a).
- Choose a multinomial distribution φt for topic t (t ∈{1,…, T}) from a Dirichlet distribution with parameter β.
- (b).
- Choose a multinomial distribution θd for document d (d ∈ {1,…,M}) from a Dirichlet distribution with parameter .
- (c).
- For a word wn (n ∈{1,…, Nd}) in document d,
- selection of a topic zn from θd,
- selection of a word wn from φzn.
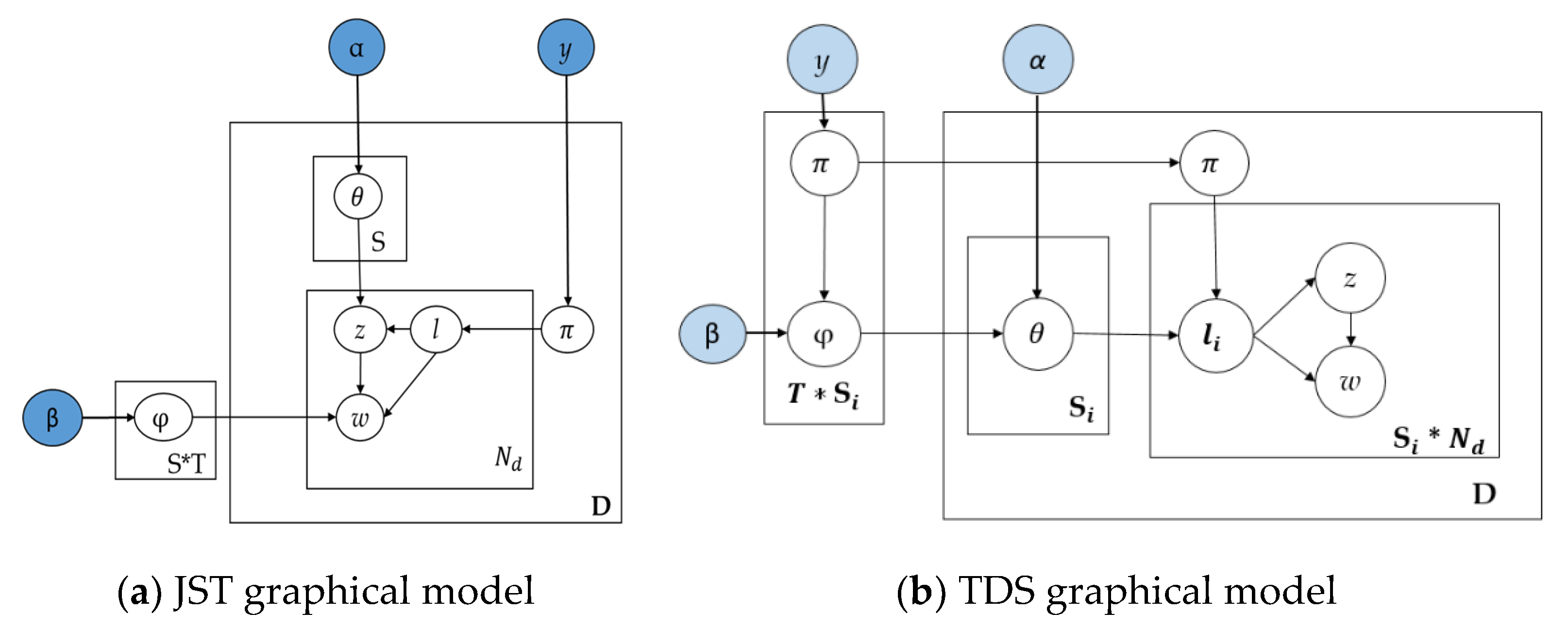
3.2. Topic Document Sentence (TDS) Model
- -
- choose a sentiment label ,
- -
- choose a topic ,
- -
- choose a word from the distribution over words defined by the topic and sentiment label .
- -
- JST with document distribution—,
- -
- JST with word distribution—,
- -
- Sentiment document distribution—
4. Experimental Results and Analysis
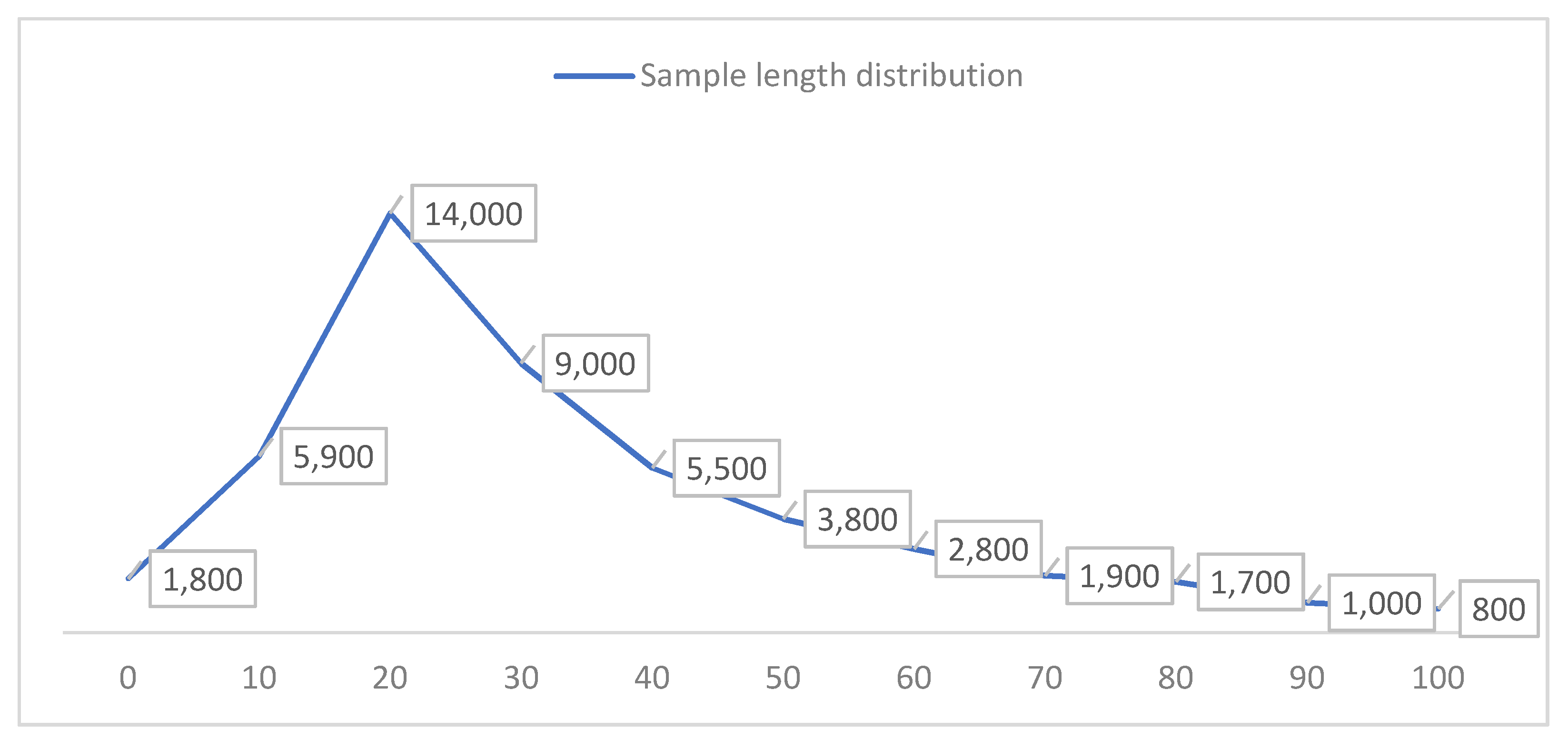
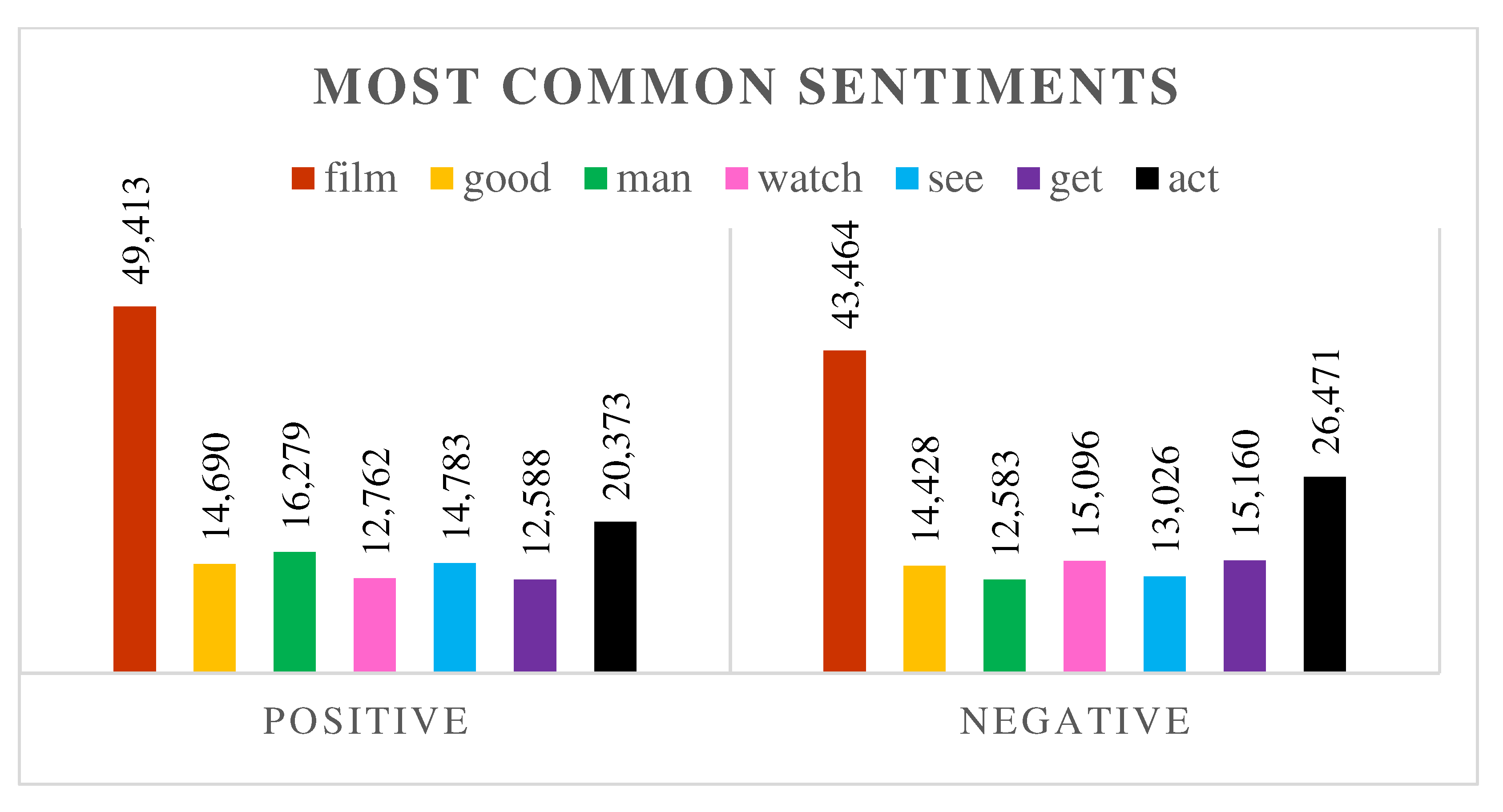
4.1. Preprocessing the Dataset
4.2. Performance Measurement
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Bing, L. Sentiment Analysis and Subjectivity. In Handbook of Natural Language Processing, 2nd ed.; Indurkhya, N., Damerau, F.J., Eds.; MIT Press: Cambridge, MA, USA, 2010; pp. 4–10. [Google Scholar]
- Martínez Cámara, E.; Almeida-Cruz, Y.; Díaz Galiano, M.C.; Estévez-Velarde, S.; García Cumbreras, M.Á.; García Vega, M.; Gutiérrez, Y.; Montejo Ráez, A.; Montoyo, A.; Munoz, R.; et al. Overview of TASS: Opinions, Health and Emotions. In TASS 2018 Workshop on Sentiment Analysis as SEPLN; CEUR Workshop: Sevilla, Spain, 2018. [Google Scholar]
- Martínez-Cámara, E.; Martín-Valdivia, M.T.; Urena-López, L.A.; Montejo-Ráez, A.R. Sentiment analysis in Twitter. Nat. Lang. Eng. 2014, 20, 1–28. [Google Scholar] [CrossRef]
- Ho, V.A.; Nguyen, D.H.-C.; Nguyen, D.H.; Pham, L.T.-V.; Nguyen, D.-V.; van Nguyen, K.; Nguyen, N.L.-T. Emotion Recognition for Vietnamese Social Media Text. In Proceedings of the 2019 International Conference of the Pacific Association for Computational Linguistics (PACLING 2019), Hanoi, Vietnam, 11–13 October 2019. [Google Scholar]
- Liu, B.; Indurkhya, N.; Damerau, F.J. (Eds.) Handbook of Natural Language Processing, 2nd ed; Chapman & Hall: Cambridge, MA, USA, 2010. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found Trends Inf. Retrieve 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Maynard, D.; Funk, A. Automatic detection of political opinions in tweets. In Proceedings of the 8th International Conference on the Semantic Web, ESWC’11, Heraklion, Greece, 29–30 May 2011; pp. 88–99. [Google Scholar]
- Tsytsarau, M.; Palpanas, T. Survey on the mining subjective data on the web. Data Min. Knowl. Discov. 2012, 24, 478–514. [Google Scholar] [CrossRef]
- Yousif, A.; Niu, Z.; Tarus, J.K.; Ahmad, A. A survey on sentiment analysis of scientific citations. Artif. Intell. Rev. 2019, 52, 1805–1838. [Google Scholar] [CrossRef]
- Ortis, A.; Farinella, G.M.; Battiato, S. An Overview on Image Sentiment Analysis: Methods, Datasets and Current Challenges. In Proceedings of the 16th International Joint Conference on e-Business and Telecommunications, ICETE 2019, Prague, Czech Republic, 26–28 July 2019. [Google Scholar]
- Siersdorfer, S.; Minack, E.; Deng, F.; Hare, J. Analyzing and predicting sentiment of images on the social web. In Proceedings of the 18th ACM International Conference on Multimedia, ACM, Firenze, Italy, 25–29 October 2010; pp. 715–718. [Google Scholar]
- Doshi, U.; Barot, V.; Gavhane, S. Emotion Detection and Sentiment Analysis of Static Images. In Proceedings of the 2020 International Conference on Convergence to Digital World—Quo Vadis (ICCDW), Mumbai, India, 18–20 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Noh, Y.; Park, S.; Park, S.-B. Aspect-Based Sentiment Analysis Using Aspect Map. Appl. Sci. 2019, 9, 3239. [Google Scholar] [CrossRef] [Green Version]
- Tao, J.; Fang, X. Toward multi-label sentiment analysis: A transfer learning based approach. J. Big Data 2020, 7, 1. [Google Scholar] [CrossRef] [Green Version]
- Abdelgwad, M.M.; Soliman, T.H.A.; Taloba, A.I.; Farghaly, M.F. Arabic aspect based sentiment analysis using bidirectional gru based models. arXiv 2021, arXiv:2101.10539. [Google Scholar]
- Martín-Valdivia, M.T.; Martínez-Cámara, E.; Perea-Ortega, J.M.; Ureña-López, L.A. Sentiment polarity detection in Spanish reviews combining supervised and unsupervised approaches. Expert Syst. Appl. 2013, 40, 3934–3942. [Google Scholar] [CrossRef]
- Jeong, H.; Ko, Y.; Seo, J. How to Improve Text Summarization and Classification by Mutual Cooperation on an Integrated Framework. Expert Syst. Appl. 2016, 60, 222–233. [Google Scholar] [CrossRef]
- Turney, P.D.; Littman, M.L. Unsupervised learning of semantic orientation from a hundred-billion-word corpus. arXiv 2002, arXiv:cs/0212012. [Google Scholar]
- Lin, C.; He, Y. Joint Sentiment/Topic Model for Sentiment Analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 375–384. [Google Scholar]
- Duric, A.; Song, F. Feature selection for sentiment analysis based on content and syntax models. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis (WASSA ’11), Portland, OR, USA, 24 June 2011; pp. 96–103. [Google Scholar]
- Hercig, T.; Brychcín, T.; Svoboda, L.; Konkol, M.; Steinberger, J. Unsupervised Methods to Improve Aspect-Based Sentiment Analysis in Czech. Comput. Sist. 2016, 20, 365–375. [Google Scholar] [CrossRef] [Green Version]
- Matsuno, I.P.; Rossi, R.G.; Marcacini, R.M.; Rezende, S.O. Aspect-Based Sentiment Analysis Using Semi-Supervised Learning in Bipartite Heterogeneous Networks. Inf. Data Manag. 2016, 7, 141–154. [Google Scholar]
- Pannala, N.U.; Nawarathna, C.P.; Jayakody, J.T.K.; Rupasinghe, L.; Krishnadeva, K. Supervised Learning Based Approach to Aspect Based Sentiment Analysis. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 662–666. [Google Scholar] [CrossRef]
- Chakraborti, S.; Lothian, R.; Wiratunga, N.; Watt, S. Sprinkling: Supervised Latent Semantic Indexing. In Proceedings of the 28th European Conference on Advances in Information Retrieval, London, UK, 10–12 April 2006; pp. 510–514. [Google Scholar] [CrossRef]
- IMDB Dataset. Available online: https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews (accessed on 10 August 2021).
- Sievert, C.; Shirley, K.E. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, application, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment Analysis of Twitter Data. In Proceedings of the Workshop on Language in Social Media (LSM 2011), Portland, Oregon, 23 June 2011. [Google Scholar]
- Bauer, S.; Noulas, A.; Séaghdha, D.O.; Clark, S.; Mascolo, C. Talking places: Modelling and analyzing linguistic content in foursquare. In Proceedings of the 2012 International Conference on Social Computing (SocialCom), Amsterdam, The Netherlands, 3–5 September 2012. [Google Scholar]
- Eidelman, V.; Boyd-Graber, J.; Resnik, P. Topic models for dynamic translation model adaption. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jeju Island, Korea, 8–14 July 2012. [Google Scholar]
- Godin, F.; Slavkovikj, V.; De Neve, W.; Schrauwen, B.; Van de Walle, R. Using topic models for twitter hashtag recommendation. In Proceedings of the 22nd International Conference on World Wide Web, ACM, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Mukherjee, S.; Basu, G.; Joshi, S. Joint Author Sentiment Topic Model. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014. [Google Scholar] [CrossRef] [Green Version]
- Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar] [CrossRef]
- Phan, H.T.; Tran, V.C.; Nguyen, N.T.; Hwang, D. Improving the Performance of Sentiment Analysis of tweets containing fuzzy sentiment using the feature ensemble model. IEEE Access 2020, 8, 14630–14641. [Google Scholar] [CrossRef]
- Yan-Yan, Z.; Bing, Q.; Ting, L. Integrating Intra-and Inter-document Evidences for Improving Sentence Sentiment Classification. Acta Autom. Sin. 2010, 36, 1417–1425. [Google Scholar]
- Sahlgren, M.; Cöster, R. Using bag-of-concepts to improve the performance of support vector machines in text categorization. In Proceedings of the 20th International Conference on Computational Linguistics (COLING ’04), Geneva, Switzerland, 23–27 August 2004; Association for Computational Linguistics: USA; p. 487-es. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of unique words in initial documents | 163,721 |
| Number of unique words after removing rare and common words | 24,960 |
| Number of documents | 50,000 |
| Number of unique tokens | 24,960 |
| Predicted | ||
|---|---|---|
| Actual | Positive Documents | Negative Documents |
| Positive documents | # True Positive samples (TP) | # False Negative samples (FN) |
| Negative documents | # False Positive samples (FP) | # True Negative samples (TN) |
| Intra similarity: Cosine similarity for corresponding parts of a document | 0.9997066 |
| Inter similarity: Cosine similarity between random parts of a document | 0.9992671 |
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | ||||
|---|---|---|---|---|---|---|---|
| Term | Frequency | Term | Frequency | Term | Frequency | Term | Frequency |
| rol | 0.008 | lif | 0.005 | look-lik | 0.007 | kil | 0.006 |
| perform | 0.008 | world | 0.004 | bet | 0.006 | girl | 0.005 |
| hi_wif | 0.007 | view | 0.004 | im | 0.006 | wom | 0.004 |
| cast | 0.006 | feel | 0.003 | didnt | 0.005 | old | 0.004 |
| best | 0.006 | cannot | 0.003 | laugh | 0.005 | sex | 0.004 |
| New_york | 0.005 | tru | 0.003 | funn | 0.005 | car | 0.004 |
| star | 0.005 | year | 0.003 | whi | 0.004 | guy | 0.004 |
| john | 0.004 | liv | 0.003 | spec_effect | 0.004 | back | 0.004 |
| comed | 0.004 | war | 0.003 | dont_know | 0.004 | little | 0.004 |
| wif | 0.004 | two | 0.003 | iv | 0.004 | find | 0.004 |
| Model Classification | ||||
|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | |
| Positive | 0.94 | 0.18 | 0.30 | 4993 |
| Negative | 0.55 | 0.99 | 0.70 | 5009 |
| Accuracy | 0.58 | 1000 | ||
| Marco avg | 0.74 | 0.58 | 0.50 | 1000 |
| Weighted avg | 0.74 | 0.58 | 0.50 | 1000 |
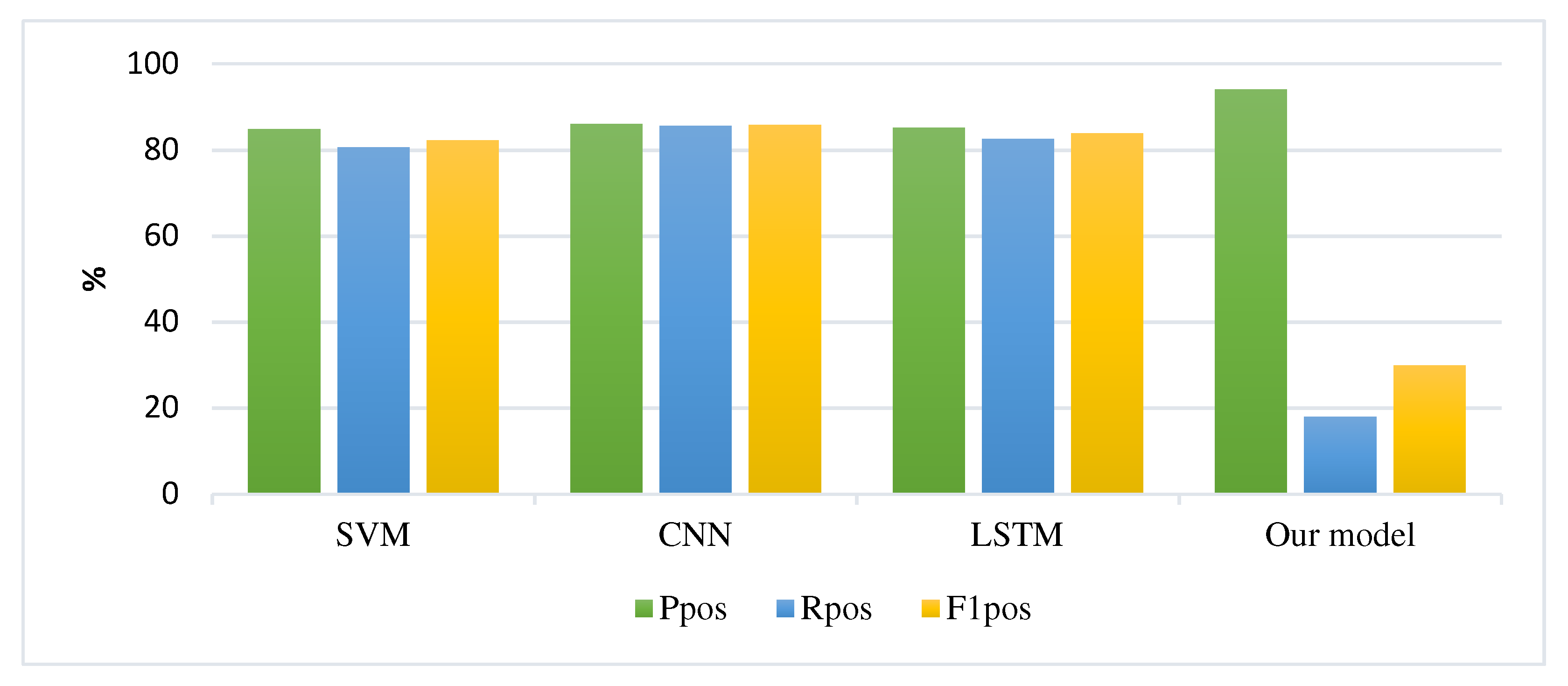
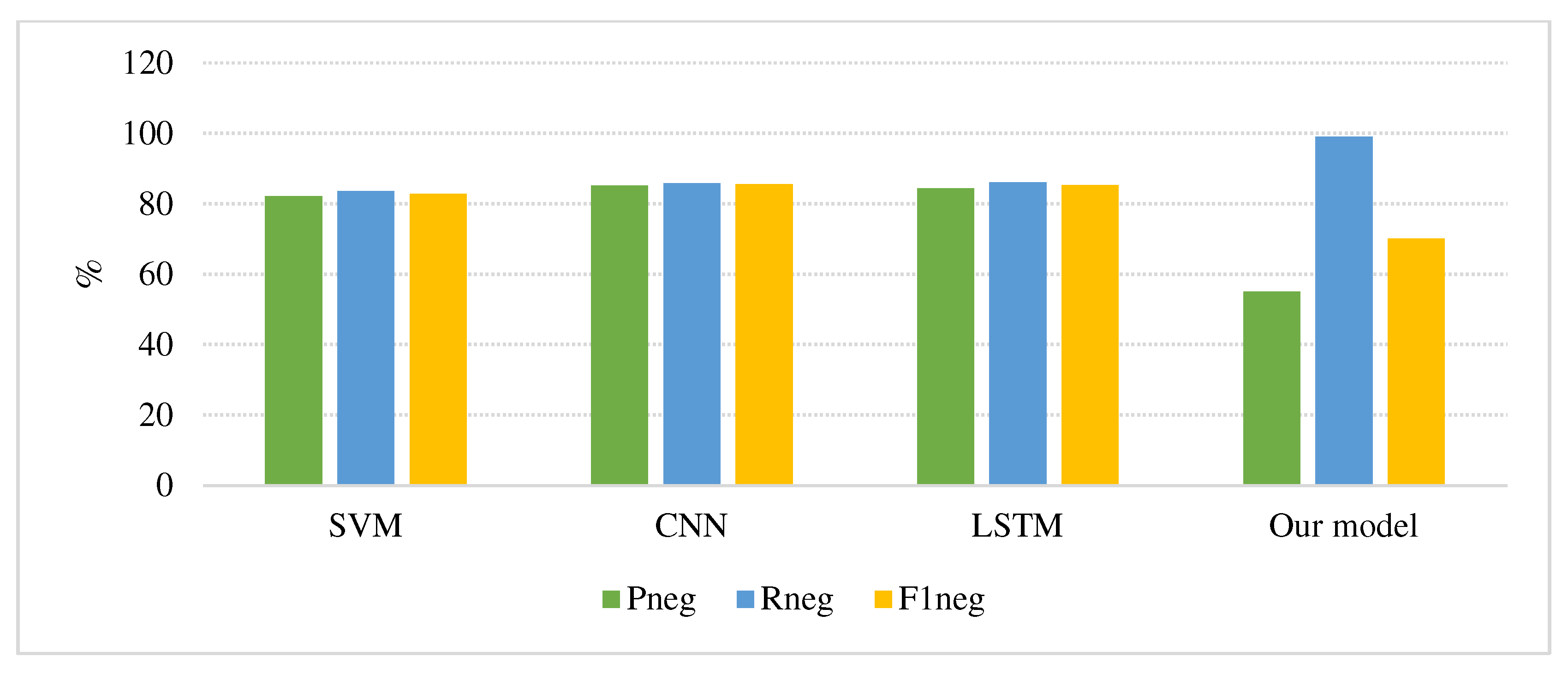
| Model | Positive | Negative | Marco_F1 | ||||
|---|---|---|---|---|---|---|---|
| Ppos | Rpos | F1pos | Pneg | Rneg | F1neg | ||
| SVM | 84.80 | 80.70 | 82.22 | 82.10 | 83.50 | 82.79 | 82.51 |
| CNN | 86.00 | 85.60 | 85.80 | 85.17 | 85.82 | 85.49 | 85.65 |
| LSTM | 85.10 | 82.50 | 83.78 | 84.30 | 86.10 | 85.19 | 84.49 |
| Our model | 94.0 | 18.0 | 30.0 | 55.0 | 99.0 | 70.0 | 58.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Appl. Sci. 2021, 11, 11091. https://doi.org/10.3390/app112311091
Farkhod A, Abdusalomov A, Makhmudov F, Cho YI. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Applied Sciences. 2021; 11(23):11091. https://doi.org/10.3390/app112311091
Chicago/Turabian StyleFarkhod, Akhmedov, Akmalbek Abdusalomov, Fazliddin Makhmudov, and Young Im Cho. 2021. "LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model" Applied Sciences 11, no. 23: 11091. https://doi.org/10.3390/app112311091
APA StyleFarkhod, A., Abdusalomov, A., Makhmudov, F., & Cho, Y. I. (2021). LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Applied Sciences, 11(23), 11091. https://doi.org/10.3390/app112311091