
A Systematic Review of Federated Learning in the Healthcare Area: From the Perspective of Data Properties and Applications

 ,
,  ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
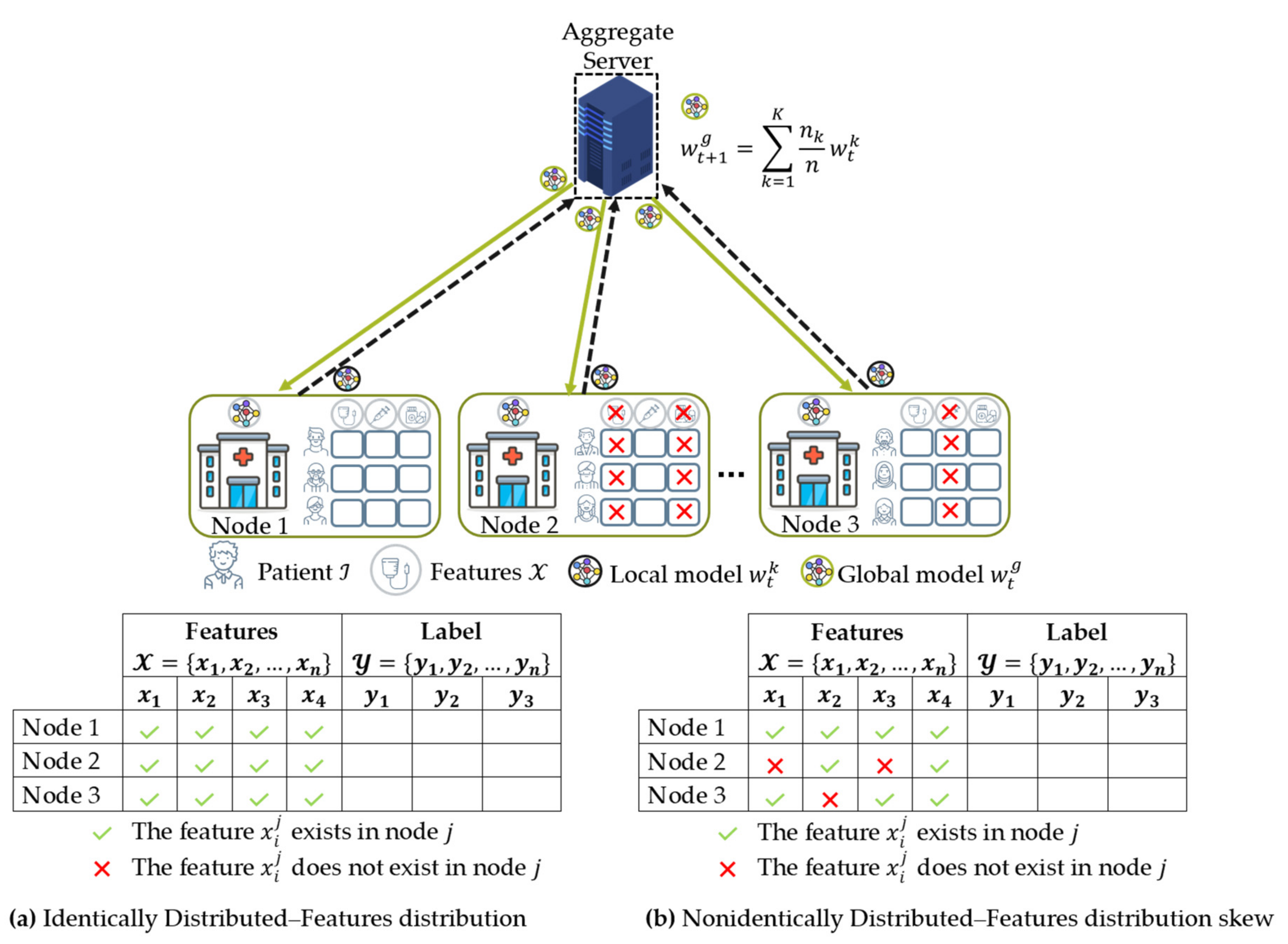
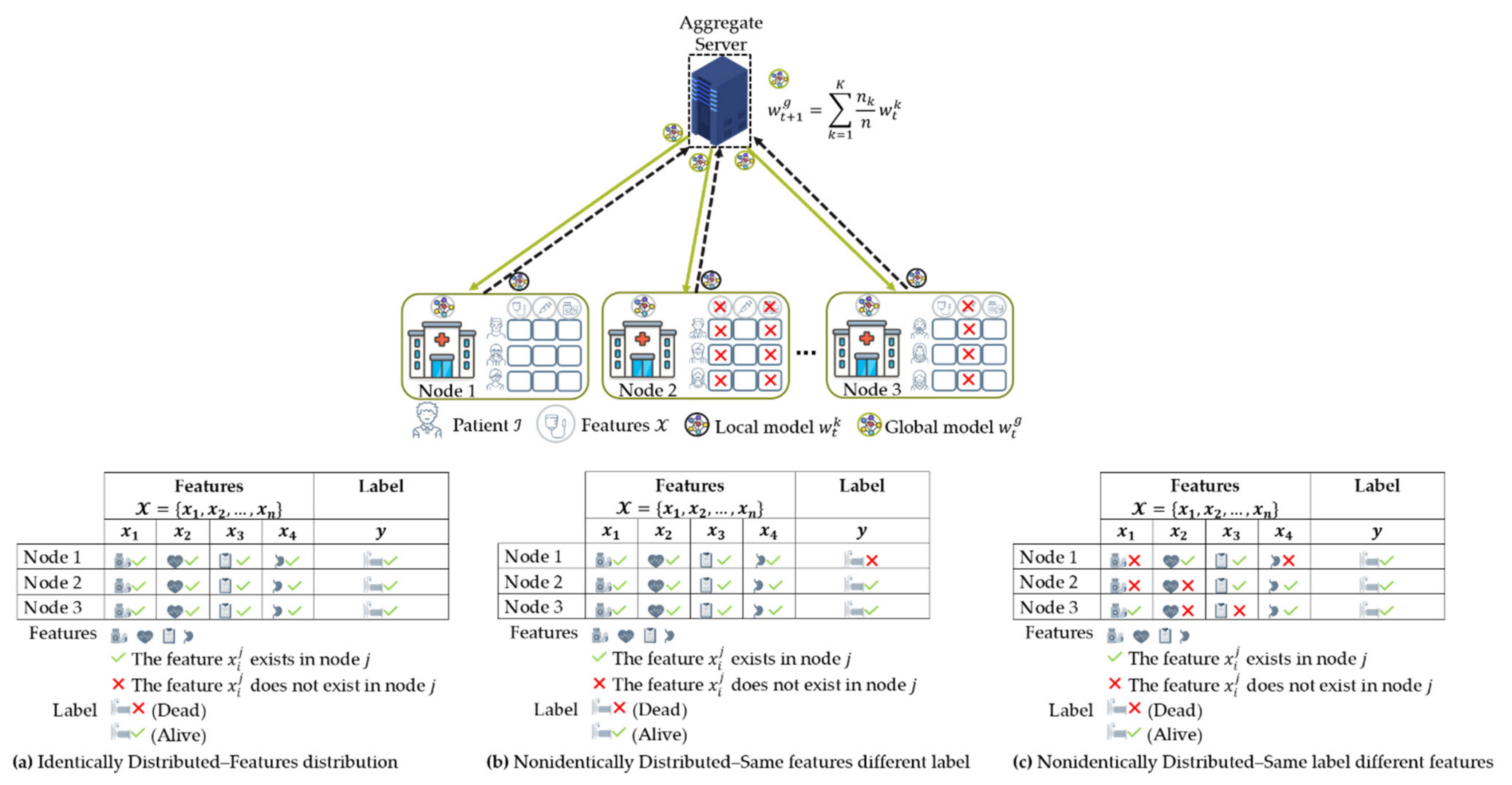
- Data partitions: FL technique aims to solve the limited sample size problem for training a secure collaborative machine learning model by aggregating a group of clients’ data. However, choosing a data partition (horizontal or vertical) for FL is essential to solve the limited sample size, limited sample features, or both.
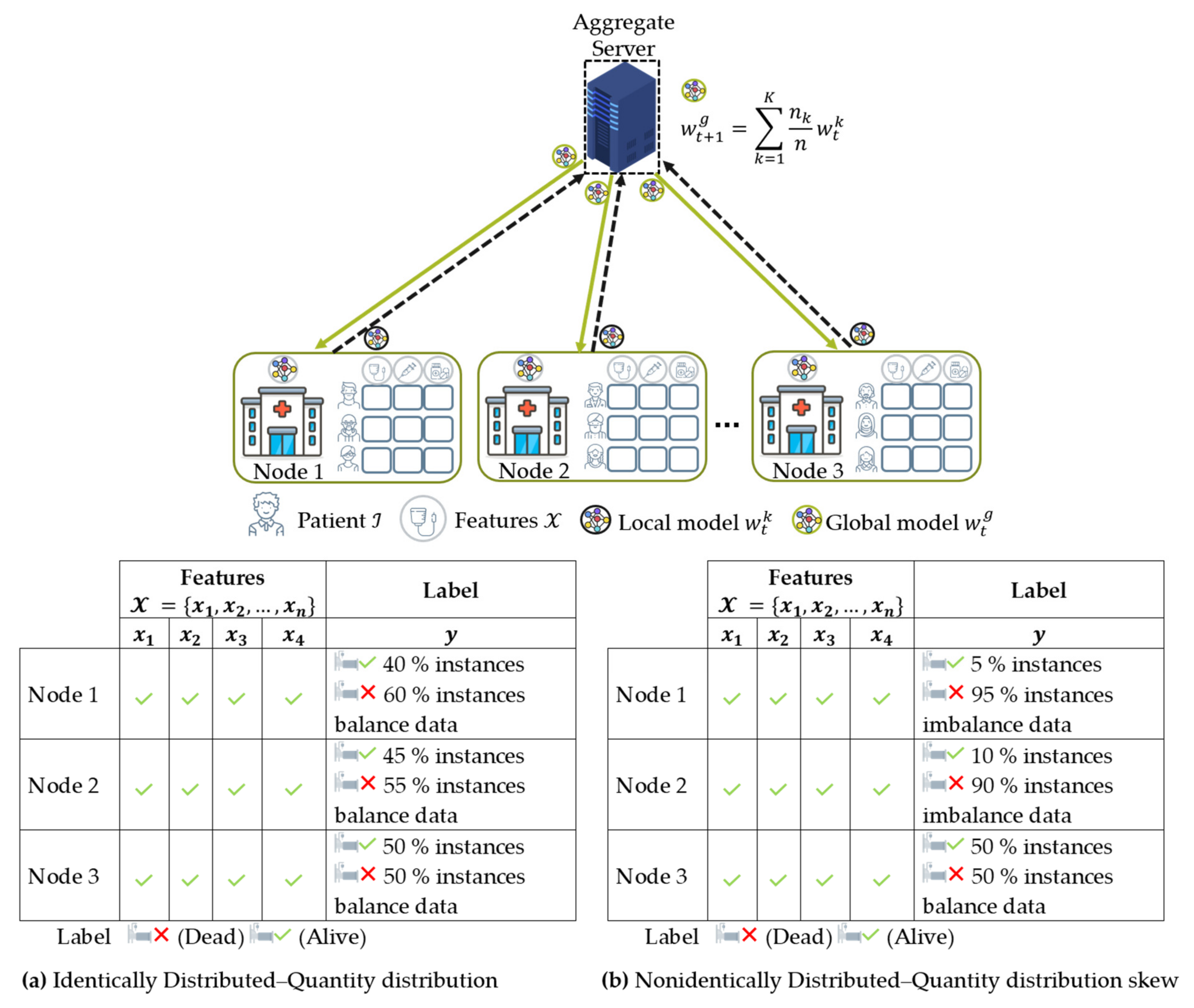
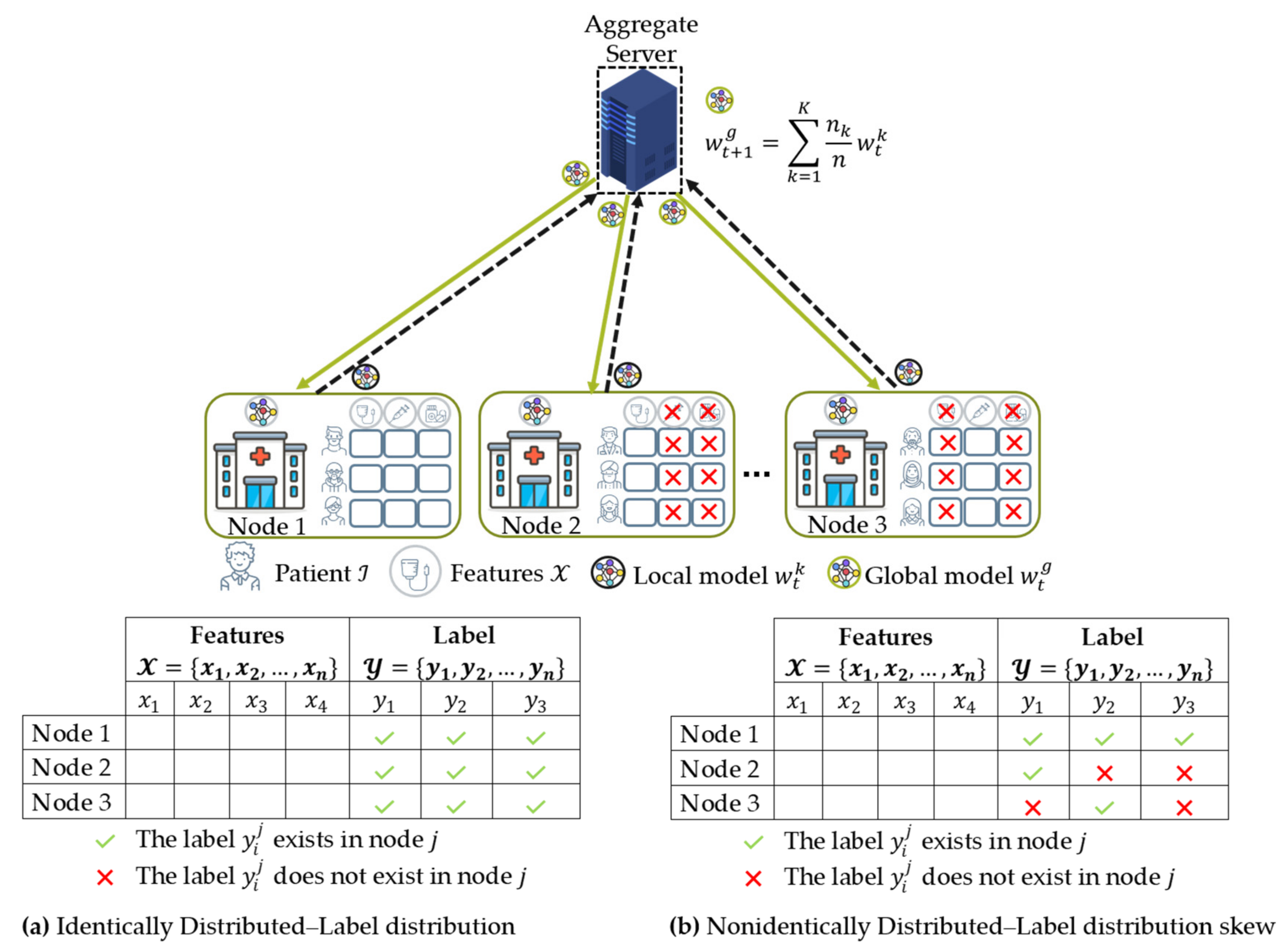
- Data distribution (statistical challenge): In developing a machine learning model in a centralized manner, the training data are centrally stored and balanced during training. However, with federated learning, each client generated the training data locally, remained decentralized, and cannot access the other clients’ data. Thus, data distribution at one client can differ significantly from others, i.e., nonindependent and identically distributed (non-IID), impacting the performance of the federated learning model [23,24].
- Privacy and security: Data privacy and security are critical issues in medical applications. It is impossible to assume all of the clients in FL are reliable because the number of clients expected to participate is potentially thousands or millions. Thus, privacy-preserving mechanisms are needed to protect medical data from untrusted clients or third-party attackers.
- Benchmark medical dataset: Medical dataset quantity and quality have often limited the development of a robust solution to the FL algorithm. For various research purposes, the dataset used in FL experiments could vary significantly. For instance, some datasets focus on medical image classification and segmentation performance while others focus on network communication performance. However, the benchmark datasets have not already been compiled, specifically for medical datasets. Thus, a trusted benchmark is necessary to evaluate the performance of the FL that uses multiple medical data sources. Finally, we provide a comprehensive list of relevant medical datasets for future research on this topic.
2. Research Method
2.1. Formulate Research Questions
- -
- RQ1: What are the state-of-the-art FL methods in the healthcare area?
- -
- RQ2: What are the FL methods proposed by scholars to solve challenging medical applications from a data properties perspective?
- -
- RQ3: What are the research gaps and potential future research directions of FL related to medical applications?
2.2. Data Eligibility and Analysis of the Literature
3. Results
4. Discussion
- RQ1: What are the state-of-the-art FL methods in the healthcare area?
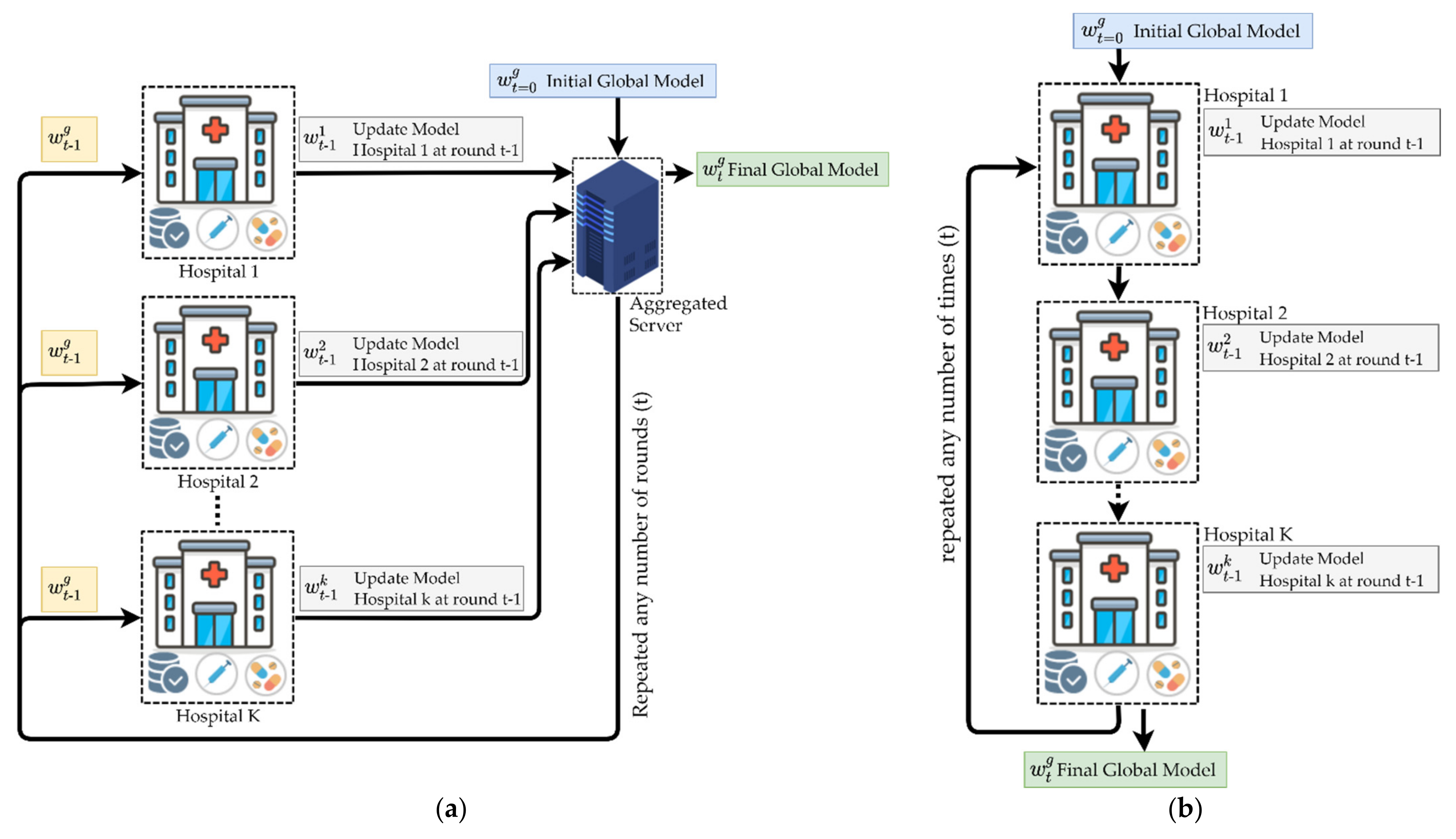
4.1. Federated Learning Overview
| Algorithm 1 FL with Federated Averaging (FedAvg) algorithm [16] | |
| Input: global round, number of fractions for each training round, number of clients, learning rate at a local client, number of epochs at a local client, local minibatch at a local client. | |
| 01: | Initialize global model |
| 02: | for do |
| 03: | |
| 04: | |
| 05: | for do |
| 06: | |
| 07: | |
| 08: | |
| 09: | ClientUpdate: |
| 10: | |
| 11: | for do |
| 12: | for do |
| 13: | |
| 14: | |
| Output: | |
- RQ2: What are the FL methods proposed by scholars to solve challenging medical applications from a data properties perspective?
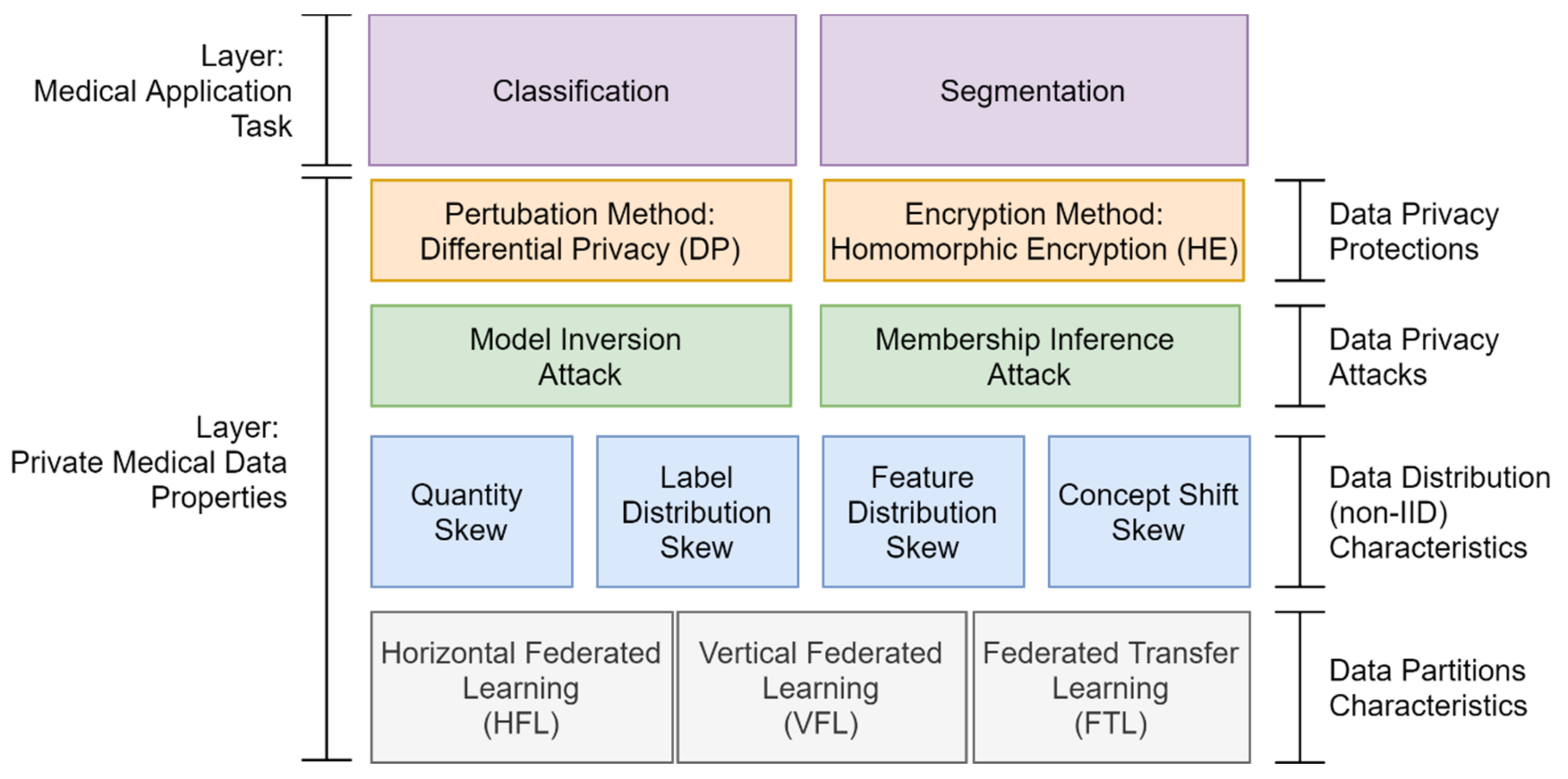
4.2. Data Partition Characteristics
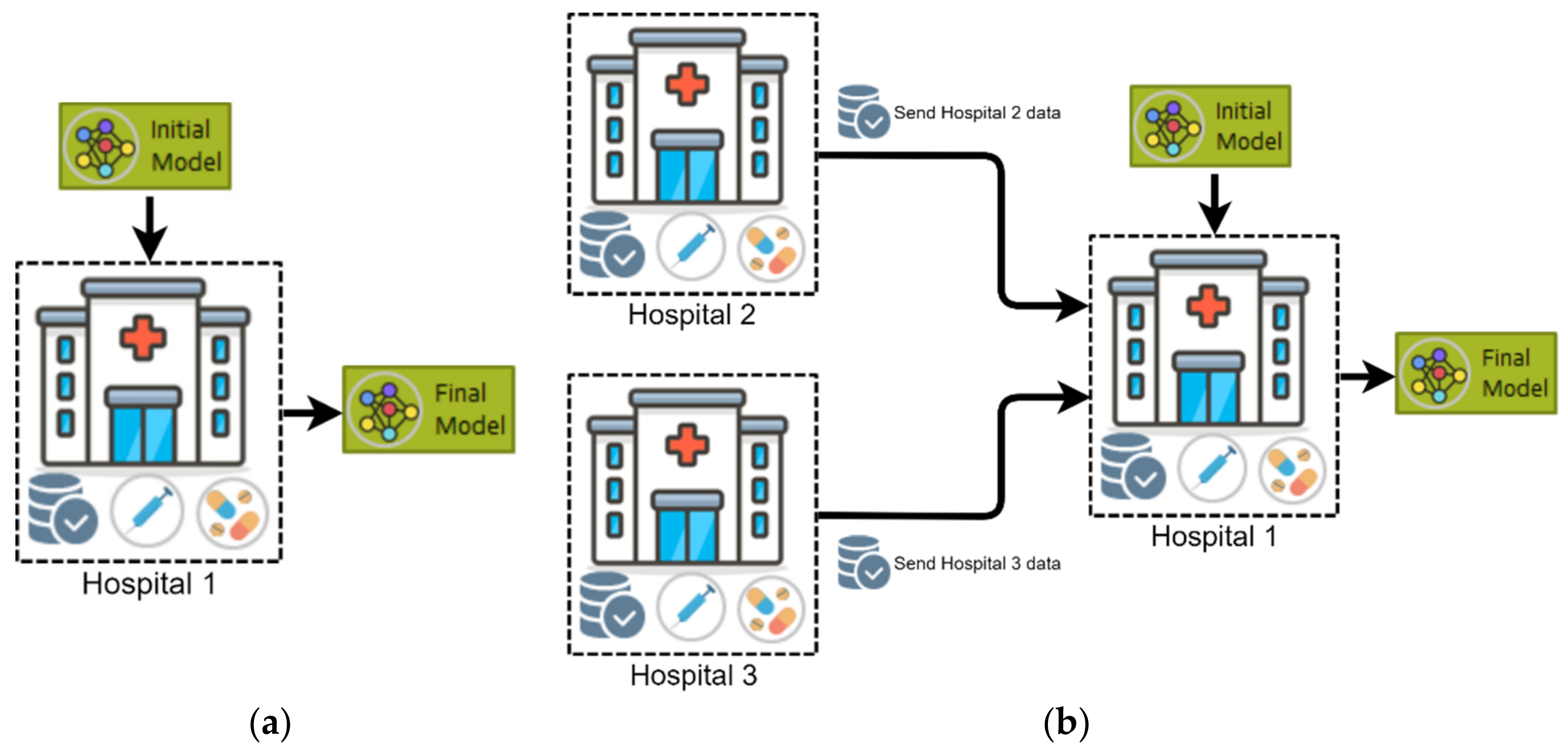
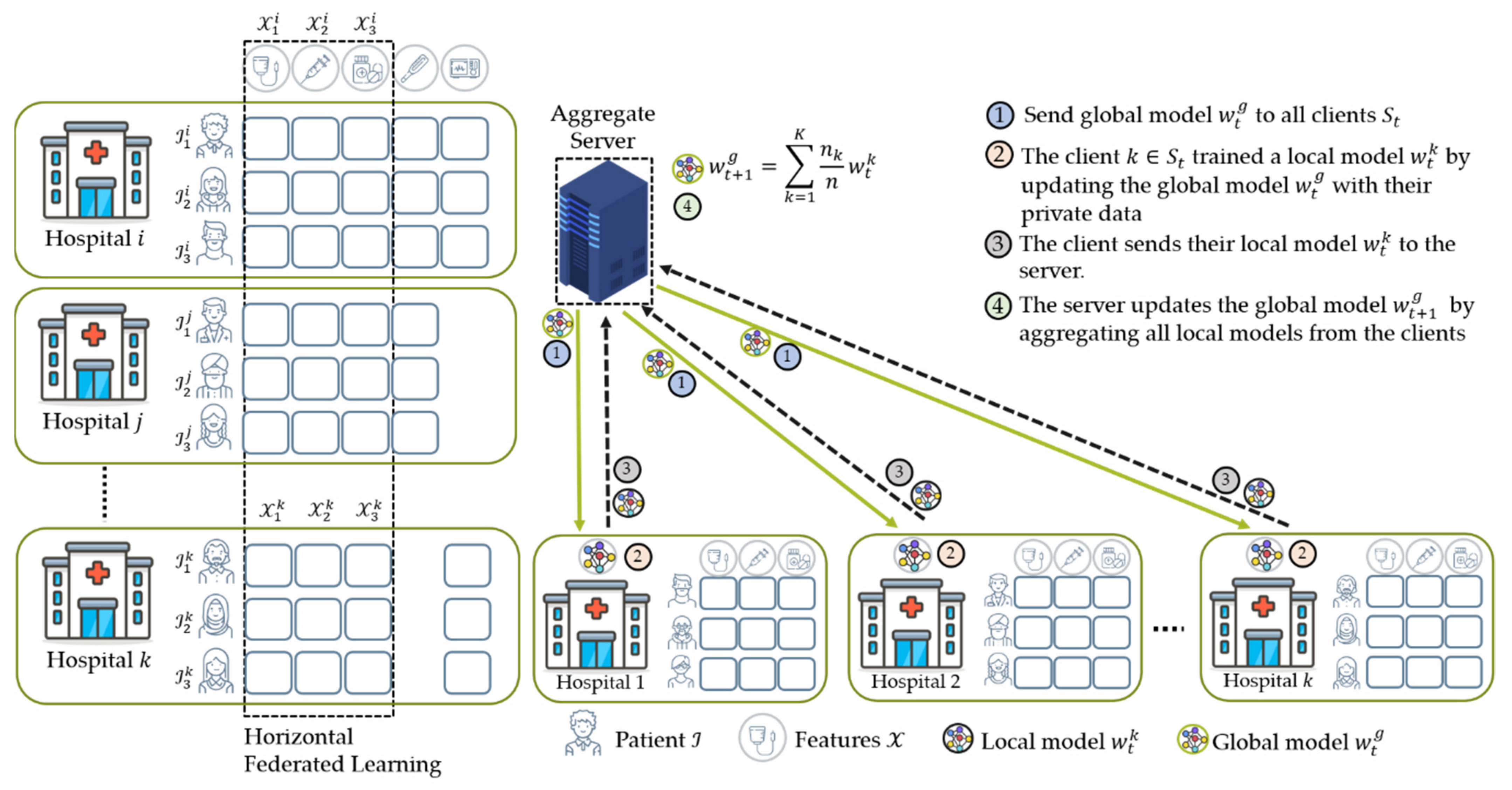
4.2.1. Horizontal Federated Learning (HFL)
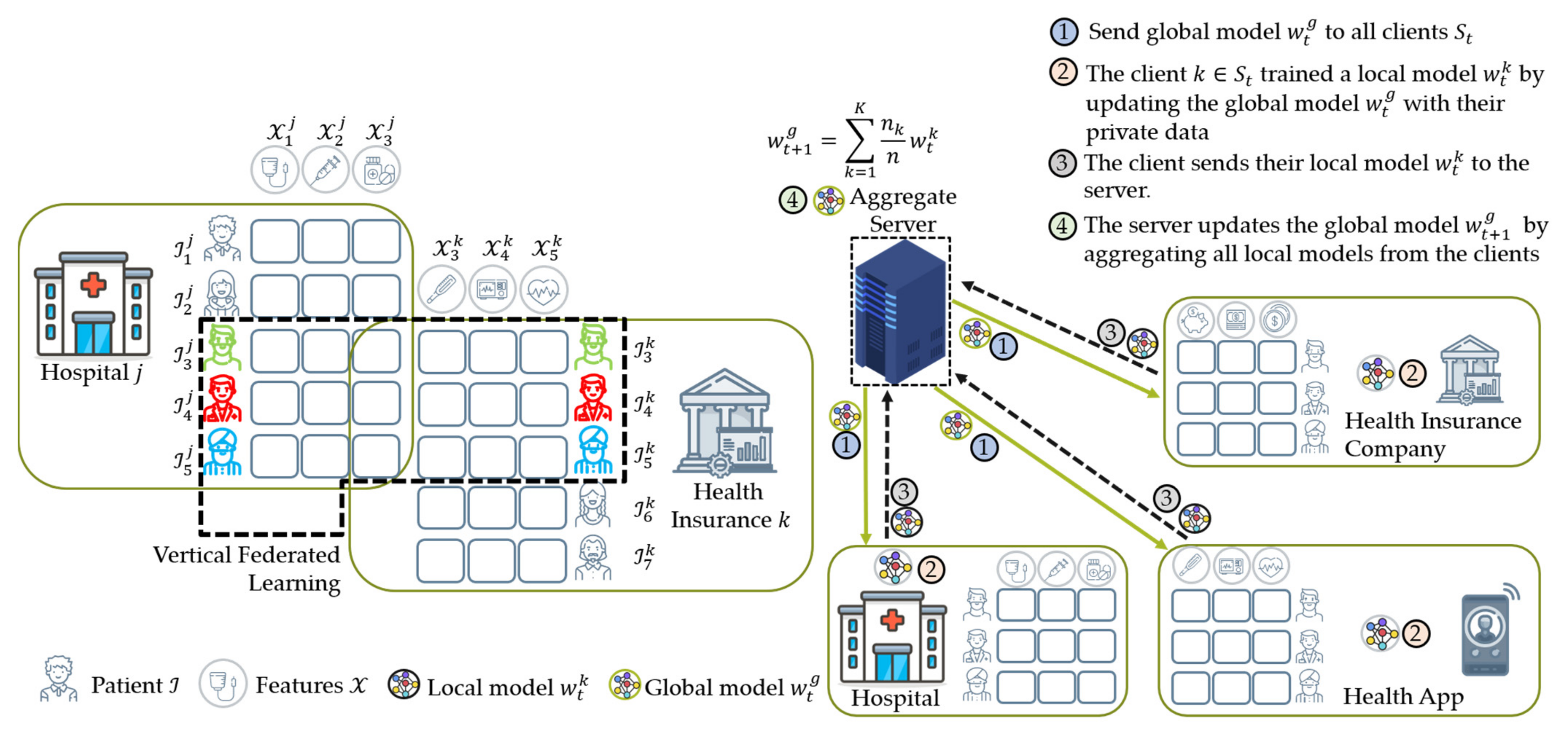
4.2.2. Vertical Federated Learning (VFL)
4.2.3. Federated Transfer Learning (FTL)
4.3. Data Distribution (Statistical Data Heterogeneity) Challenge
4.3.1. Non-IID Characteristics
4.3.2. Non-IID Mitigation Methods
- (1)
- The healthcare node generates a synthetic sample to balance the training dataset in the local data augmentation method. The synthetic minority oversampling technique (SMOTE) [21,49], generative adversarial method (GAN) [44], or geometric transformation [40,48,53] is employed to generate a synthetic sample in an FL environment. The SMOTE algorithm is an oversampling technique where the synthetic data are generated for the minority class. For instance, Wu et al. [21] and Rajendran et al. [49] employ SMOTE to balance the heavy imbalance in a fall detection and lung cancer training dataset, respectively. Zhang et al. [44] proposed secure synthetic COVID-19 data by combining the GAN and differential privacy method. Feki et al. [40], Duo et al. [48], and Yang et al. [53] applied geometric transformations such as random flipping, random rotation, and random translation to balance the quantity of minority class in their training dataset for the data augmentation method.
- (2)
- The aggregate server securely shares a small portion of data to the healthcare node in the server data sharing method. For instance, Zhao et al. [23] proposed a global shared dataset partition to train non-IID data. The author demonstrated that by simply sharing 5% of data, they could get a 30% boost accuracy score. However, it raises model communication costs and is prone to data privacy attacks during the data sharing process.
- (1)
- The weighting coefficient is a variable that indicates the relative influence of each node k on the aggregation equation in Equation (2) to update the global model. Initially, McMahan et al. [16] proposed FedAvg that the weighting coefficient is as shown in Equation (6), where and are the private data points hold by node and the total data from all nodes that participated during training, respectively. In this case, a node with significant data points has a considerable effect on the global model. This method worked well when dealing with label distribution skew characteristics experimented in their studies [16,20].
- (2)
- In addition, the adaptive loss function has the ability to change conditions based on the loss score function. The loss function was used to measure the model performance. The lower the loss score, the better a model was trained. Specifically, Huang et al. [46] proposed the LoAdaBoost method based on loss function in the FL environment for patient mortality prediction. In their proposed method, the adaptive loss function boosts the training process adaptively from the weak learners node. On each training step, the local node will send both the local model and training loss. If the training loss score is more than the loss threshold, it will be retraining again. Otherwise, it will send to the aggregate server.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
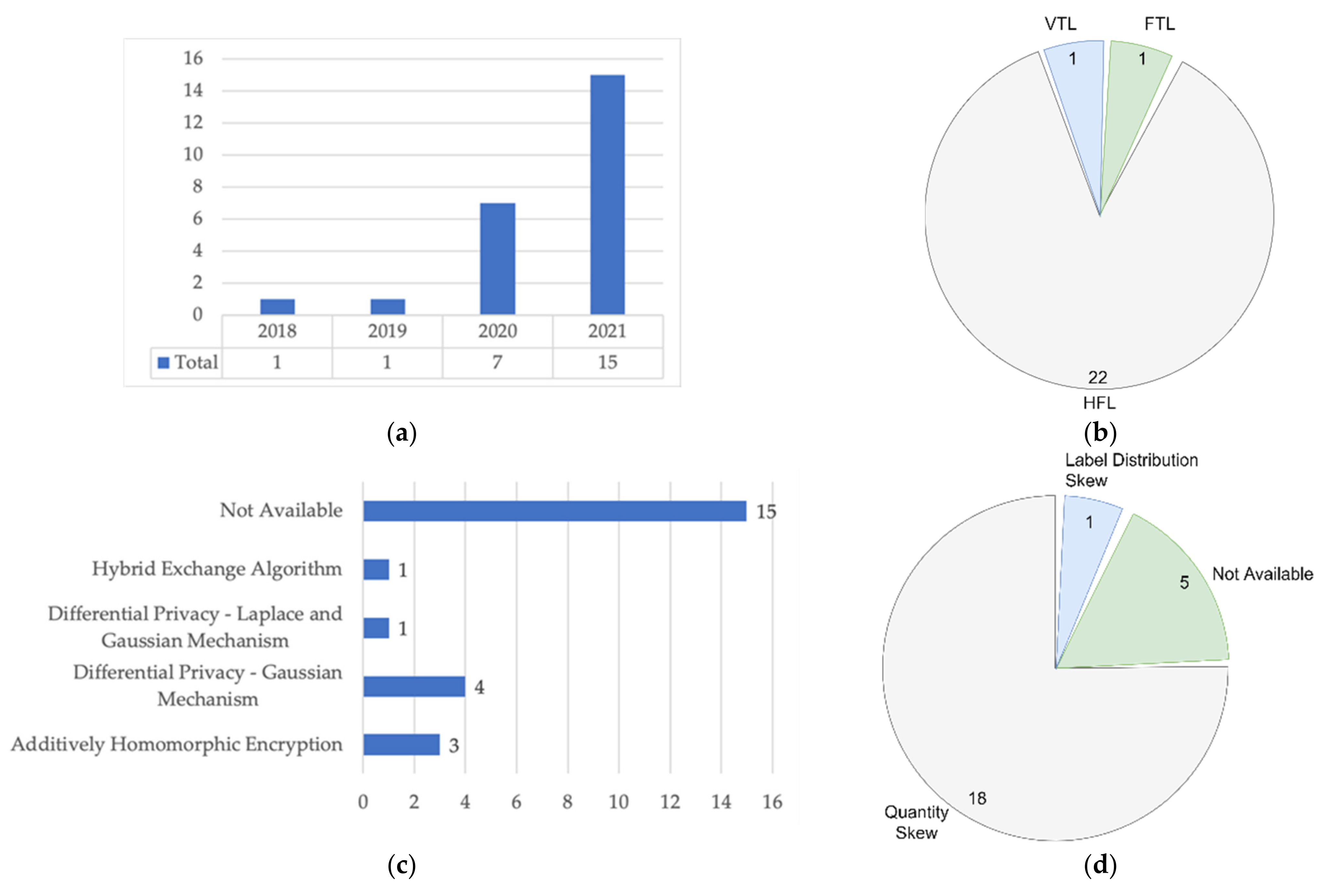
| Data Partition | Purpose | Number of Nodes | Non-IID Characteristics | Non-IID Mitigation | Studies/Year |
|---|---|---|---|---|---|
| HFL | Combining all samples from a group of selected nodes to increase the sample size | 10 | Quantity Skew | Balancing the training dataset | Brismi et al., 2018 [52] |
| 50 | Quantity Skew | Not Available | Huang et al., 2019 [19] | ||
| 20 | Quantity Skew | Balancing the training dataset | Chen et al., 2020 [45] | ||
| 90 | Quantity Skew | Adaptive Hyperparameters: Adaptive Loss Function | Huang et al., 2020 [46] | ||
| 4 | Quantity Skew | Domain Adaptation: Mixture of Expert and Domain Adversarial | Li et al., 2020 [18] | ||
| 5 | Quantity Skew | Not Available | Shao et al., 2020 [47] | ||
| 10 | Quantity Skew | Not Available | Sheller et al. [38] | ||
| 5 | Quantity Skew | Balancing the training dataset: SMOTE Algorithm | Wu et al., 2020 [21] | ||
| 10 | Not Available | Not Available | Abdul Salam et al., 2021 [54] | ||
| 4 | Quantity Skew | Balancing the training dataset: Geometric Transformation | Chhikara et al., 2021 [37] | ||
| 8 | Quantity Skew | Not Available | Cui et al., 2021 [39] | ||
| 3 | Quantity Skew | Balancing the training dataset: Geometric Transformation | Dou et al., 2021 [48] | ||
| 4 | Quantity Skew | Balancing the training dataset: Geometric Transformation | Feki et al., 2021 [40] | ||
| 6 | Quantity Skew | Not Available | Lee et al., 2021 [41] | ||
| 10 | Quantity Skew | Balancing the training dataset | Liu et al., 2021 [42] | ||
| 2 | Quantity Skew | Balancing the training dataset: SMOTE Algorithm | Rajendran et al. [49] | ||
| 3 | Not Available | Not Available | Sarma et al. [50] | ||
| 5 | Quantity Skew | Not Available | Vaid et al., 2021 [55] | ||
| 8 | Not Available | Not Available | Xue et al., 2021 [51] | ||
| 8 | Not Available | Not Available | Yan et al., 2021 [43] | ||
| 3 | Quantity Skew | Balancing the training dataset: Geometric Transformation | Yang et al., 2021 [53] | ||
| 100 | Label Distribution Skew | Balancing the training dataset: Generative Adversarial Network (GAN) | Zhang et al., 2021 [44] | ||
| VFL | Combining all features from a group of selected nodes to increase features dimension | 7 | Not Available | Not Available | Cha et al., 2021 [56] |
| FTL | Improve the model performance with small data size and unlabeled samples | 7 | Quantity Skew | Balancing the training dataset | Chen et al., 2020 [20] |
4.4. Data Privacy Attacks and Protections
4.4.1. Data Privacy Attacks on Federated Learning
4.4.2. Data Privacy Protections for Federated Learning
4.5. Benchmark Medical Dataset for Federated Learning
4.6. FL Studies for Healthcare Applications
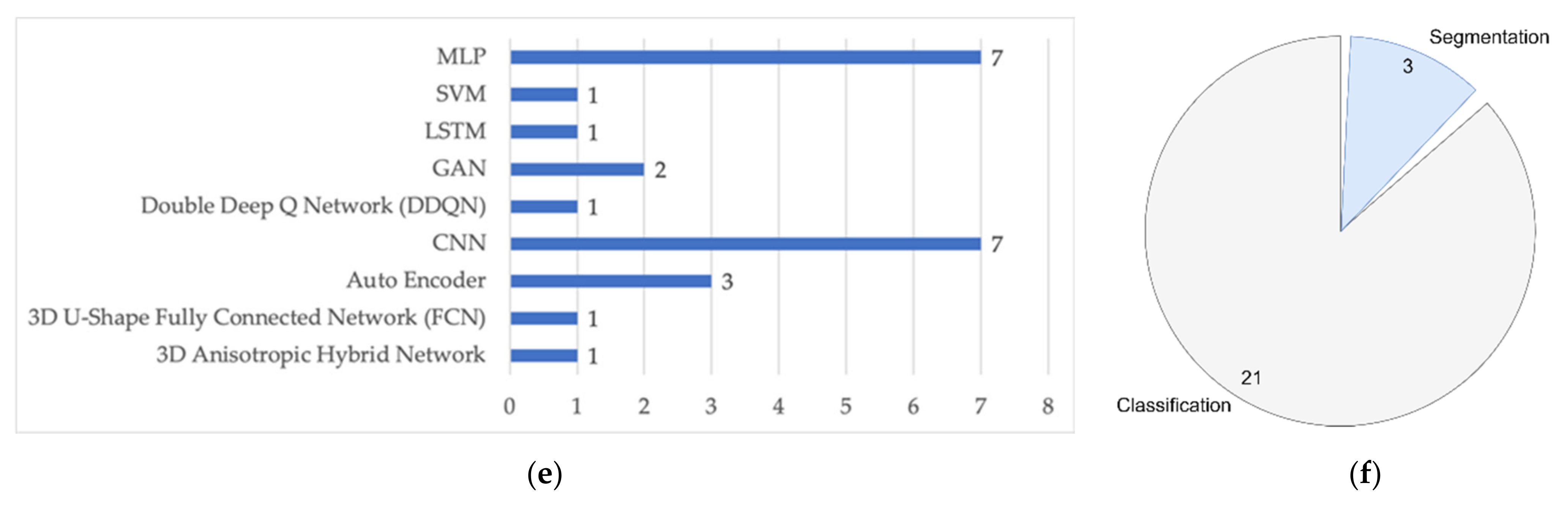
4.6.1. Classification Task in FL for Healthcare Applications
| ML Task | Clinical Tasks | Medical Input Data | Model Architecture | FL Study |
|---|---|---|---|---|
| Classification | Autism spectrum disorders (ASD) or Healthy control (HC) | fMRI | CNN | [18] |
| Cancer diagnosis: | ||||
|
|
| [43] [41] [49] | |
| COVID-19 detection | X-ray images | CNN | [40,44,48,54] | |
| Human activity | Wearable device | LSTM | [20,21,45] | |
| Human emotion | Wearable device | CNN | [37,42] | |
| Patient hospitalization | Patient EHR | SVM | [52] | |
| Patient mortality | Critical care data | MLP | [19,39,46,47,55,56] | |
| Sepsis disease | Patient EHR | Double Deep Q Network | [51] | |
| Segmentation | Brain tumor | MRI | U-Net | [38] |
| COVID-19 region | 3D Chest CT | 3D U-Net | [53] | |
| Prostate cancer | MRI | 3D Anisotropic Hybrid Network | [50] |
4.6.2. Segmentation Task in FL for Healthcare Applications
- RQ3: What are the research gaps and potential future research directions of FL related to medical data?
4.7. Open Challenges
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| AMCA | American medical collection agency |
| AUROC | Area under the receiver operating characteristic curve |
| CNN | Convolutional neural network |
| CT | Computerized tomography image |
| DNN | Deep neural network |
| FCN | Fully connected network |
| FL | Federated learning |
| fMRI | Functional magnetic resonance image |
| GDPR | General data protection right |
| HIPAA | Health insurance portability and accountability act |
| IID | Independent and identical data distribution |
| LSTM | Long short-term memory |
| ML | Machine learning |
| MLP | Multilayer perceptron |
| MRI | Magnetic resonance image |
| PDPA | Personal data protection act |
| PHI | Protected health information |
Appendix A
| Scientific Database | Query | Studies Results # |
|---|---|---|
| PubMed | ((federated learning AND ((fft[Filter]) AND (english[Filter]) AND (2018:2021[pdat]))) AND (healthcare OR hospital OR clinic AND ((fft[Filter]) AND (english[Filter]) AND (2018:2021[pdat])))) AND (“data quality” OR privacy protection OR non iid AND ((fft[Filter]) AND (english[Filter]) AND (2018:2021[pdat]))) AND ((fft[Filter]) AND (english[Filter])) AND ((fft[Filter]) AND (english[Filter])) | 21 |
| IEEE Xplore | (“All Metadata”:federated learning) AND (“All Metadata”:healthcare OR “All Metadata”:hospital OR “All Metadata”:clinic) AND (“All Metadata”:data quality OR “All Metadata”:privacy protection OR “All Metadata”:non iid) | 14 |
| Web of Science | ”Healthcare OR Hospital OR Clinic” AND ”federated learning” AND ”Data Quality OR Privacy Protection OR non iid’’ | 17 |
| Science Direct | (“federated learning”) AND (healthcare OR hospital OR clinic) AND (“data quality” OR “privacy protection” OR “non iid”) | 105 |
| ACM Digital Library | [All: “federated learning”] AND [[All: healthcare] OR [All: clinic] OR [All: hospital]] AND [[All: “data quality”] OR [All: “privacy protection”] OR [All: “non iid”]] AND [Publication Date: (1 January 2018 TO 30 June 2021)] | 40 |
| Authors | Year | Title | Journal | FL Studies |
|---|---|---|---|---|
| Brismi et al. | 2018 | Federated learning of predictive models from federated electronic health records | International Journal of Medical Informatics | [52] |
| Huang et al. | 2019 | Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records | Journal of Biomedical Informatics | [19] |
| Chen et al. | 2020 | FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare | IEEE Intelligent Systems | [20] |
| Chen et al. | 2020 | Communication-Efficient Federated Deep Learning With Layerwise Asynchronous Model Update and Temporally Weighted Aggregation | IEEE Transactions on Neural Networks and Learning Systems | [45] |
| Huang et al. | 2020 | LoAdaBoost: Loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data | PLOS ONE | [46] |
| Li et al. | 2020 | Multi-site fMRI analysis using privacy-preserving federated learning and domain adaptation: ABIDE results | Medical Image Analysis | [18] |
| Shao et al. | 2020 | Stochastic Channel-Based Federated Learning With Neural Network Pruning for Medical Data Privacy Preservation: Model Development and Experimental Validation | JMIR Formative Research | [47] |
| Sheller et al. | 2020 | Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data | Scientific Reports | [38] |
| Wu et al. | 2020 | FedHome: Cloud-Edge based Personalized Federated Learning for In-Home Health Monitoring | IEEE Transactions on Mobile Computing | [21] |
| Abdul Salam et al. | 2021 | COVID-19 detection using federated machine learning | PLOS ONE | [54] |
| Cha et al. | 2021 | Implementing Vertical Federated Learning Using Autoencoders: Practical Application, Generalizability, and Utility Study | JMIR Medical Informatics | [56] |
| Chhikara et al. | 2021 | Federated Learning Meets Human Emotions: A Decentralized Framework for Human–Computer Interaction for IoT Applications | IEEE Internet of Things Journal | [37] |
| Cui et al. | 2021 | FeARH: Federated machine learning with anonymous random hybridization on electronic medical records | Journal of Biomedical Informatics | [39] |
| Dou et al. | 2021 | Federated deep learning for detecting COVID-19 lung abnormalities in CT: a privacy-preserving multinational validation study | npj Digital Medicine | [48] |
| Feki et al. | 2021 | Federated learning for COVID-19 screening from chest X-ray images | Applied Soft Computing | [40] |
| Lee et al. | 2021 | Federated Learning for Thyroid Ultrasound Image Analysis to Protect Personal Information: Validation Study in a Real Health Care Environment | JMIR Medical Informatics | [41] |
| Liu et al. | 2021 | Learning From Others Without Sacrificing Privacy: Simulation Comparing Centralized and Federated Machine Learning on Mobile Health Data | JMIR mHealth and uHealth | [42] |
| Rajendran et al. | 2021 | Cloud-Based Federated Learning Implementation Across Medical Centers | JCO Clinical Cancer Informatics | [49] |
| Sarma et al. | 2021 | Federated learning improves site performance in multicenter deep learning without data sharing | Journal of the American Medical Informatics Association | [50] |
| Vaid et al. | 2021 | Federated Learning of Electronic Health Records to Improve Mortality Prediction in Hospitalized Patients With COVID-19: Machine Learning Approach | JMIR Medical Informatics | [55] |
| Xue et al. | 2021 | A Resource-Constrained and Privacy-Preserving Edge-Computing-Enabled Clinical Decision System: A Federated Reinforcement Learning Approach | IEEE Internet of Things Journal | [51] |
| Yan et al. | 2021 | Variation-Aware Federated Learning with Multi-Source Decentralized Medical Image Data | IEEE Journal of Biomedical and Health Informatics | [43] |
| Yang et al. | 2021 | Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan | Medical Image Analysis | [53] |
| Zhang et al. | 2021 | FedDPGAN: Federated Differentially Private Generative Adversarial Networks Framework for the Detection of COVID-19 Pneumonia | Information Systems Frontiers | [44] |
References
- Feng, Y.; Zhang, L.; Mo, J. Deep manifold preserving autoencoder for classifying breast cancer histopathological images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 91–101. [Google Scholar] [CrossRef] [PubMed]
- McWilliams, A.; Beigi, P.; Srinidhi, A.; Lam, S.; MacAulay, C.E. Sex and smoking status effects on the early detection of early lung cancer in high-risk smokers using an electronic nose. IEEE Trans. Biomed. Eng. 2015, 62, 2044–2054. [Google Scholar] [CrossRef]
- Chen, S.; Yang, H.; Fu, J.; Mei, W.; Ren, S.; Liu, Y.; Zhu, Z.; Liu, L.; Li, H.; Chen, H. U-Net Plus: Deep semantic segmentation for esophagus and esophageal cancer in computed tomography images. IEEE Access 2019, 7, 82867–82877. [Google Scholar] [CrossRef]
- Ge, C.; Gu, I.Y.; Jakola, A.S.; Yang, J. Enlarged training dataset by pairwise GANs for molecular-based brain tumor classification. IEEE Access 2020, 8, 22560–22570. [Google Scholar] [CrossRef]
- Sultan, H.H.; Salem, N.M.; Al-Atabany, W. Multi-classification of brain tumor images using deep neural network. IEEE Access 2019, 7, 69215–69225. [Google Scholar] [CrossRef]
- Noreen, N.; Palaniappan, S.; Qayyum, A.; Ahmad, I.; Imran, M.; Shoaib, M. A deep learning model based on concatenation approach for the diagnosis of brain tumor. IEEE Access 2020, 8, 55135–55144. [Google Scholar] [CrossRef]
- Xue, W.; Li, Q.; Xue, Q. Text detection and recognition for images of medical laboratory reports with a deep learning approach. IEEE Access 2020, 8, 407–416. [Google Scholar] [CrossRef]
- Harerimana, G.; Kim, J.W.; Yoo, H.; Jang, B. Deep learning for electronic health records analytics. IEEE Access 2019, 7, 101245–101259. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Zech, J.R.; Badgeley, M.A.; Liu, M.; Costa, A.B.; Titano, J.J.; Oermann, E.K. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. PLoS Med. 2018, 15, e1002683. [Google Scholar] [CrossRef] [Green Version]
- O’Leary, D.E. Embedding AI and crowdsourcing in the big data lake. IEEE Intell. Syst. 2014, 29, 70–73. [Google Scholar] [CrossRef]
- Moore, W.; Frye, S. Review of HIPAA, part 1: History, protected health information, and privacy and security rules. J. Nucl. Med. Technol. 2019, 47, 269–272. [Google Scholar] [CrossRef]
- Mark Allen Group, Data breach at major healthcare firms. Comput. Fraud. Secur. 2019, 2019, 3–19. [CrossRef]
- Voigt, P.; von dem Bussche, A. The EU General Data Protection Regulation (GDPR); Springer: Cham, Switzerland, 2017. [Google Scholar]
- Laws and Regulations Database of the Republic of China. Personal Data Protection Act. 2015. Available online: https://law.moj.gov.tw/ENG/LawClass/LawAll.aspx?pcode=I0050021 (accessed on 7 July 2021).
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics Conference, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2019, arXiv:1811.03604. [Google Scholar]
- Li, X.; Gu, Y.; Dvornek, N.; Staib, L.H.; Ventola, P.; Duncan, J.S. Multi-site FMRI analysis using privacy-preserving federated learning and domain adaptation: ABIDE results. Med. Image Anal. 2020, 65, 101765. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Shea, A.L.; Qian, H.; Masurkar, A.; Deng, H.; Liu, D. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J. Biomed. Inform. 2019, 99, 103291. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. FedHealth: A federated transfer learning framework for wearable healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Chen, X.; Zhou, Z.; Zhang, J. FedHome: Cloud-edge based personalized federated learning for in-home health monitoring. IEEE Trans. Mobile Comput. 2020. [Google Scholar] [CrossRef]
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J.; et al. Privacy-preserving federated brain tumour segmentation. In Machine Learning in Medical Imaging; Suk, H.-I., Liu, M., Yan, P., Lian, C., Eds.; Springer: Cham, Switzerland, 2019; Volume 11861, pp. 133–141. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-IID data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Hsieh, K.; Phanishayee, A.; Mutlu, O.; Gibbons, P.B. The non-IID data quagmire of decentralized machine learning. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Virtual Event, 13–18 July 2020. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Wu, Q.; He, K.; Chen, X. Personalized federated learning for intelligent IoT applications: A cloud-edge based framework. IEEE Open J. Comput. Soc. 2020, 1, 35–44. [Google Scholar] [CrossRef] [PubMed]
- Du, Z.; Wu, C.; Yoshinaga, T.; Yau, K.-L.A.; Ji, Y.; Li, J. Federated learning for vehicular internet of things: Recent advances and open issues. IEEE Open J. Comput. Soc. 2020, 1, 45–61. [Google Scholar] [CrossRef]
- Putra, K.T.; Chen, H.-C.; Prayitno; Ogiela, M.R.; Chou, C.-L.; Weng, C.-E.; Shae, Z.-Y. Federated compressed learning edge computing framework with ensuring data privacy for PM2.5 prediction in smart city sensing applications. Sensors 2021, 21, 4586. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2020, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Pfitzner, B.; Steckhan, N.; Arnrich, B. Federated learning in a medical context: A systematic literature review. ACM Trans. Internet Technol. 2021, 21, 1–31. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- PRISMA. PRISMA Endorsers. Available online: http://www.prisma-statement.org/Endorsement/PRISMAEndorsers (accessed on 21 November 2021).
- McDonagh, M.; Peterson, K.; Raina, P.; Chang, S.; Shekelle, P. Avoiding bias in selecting studies. In Methods Guide for Effectiveness and Comparative Effectiveness Reviews; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2008. [Google Scholar]
- Scherer, R.W.; Saldanha, I.J. How should systematic reviewers handle conference abstracts? A view from the trenches. Syst. Rev. 2019, 8, 264. [Google Scholar] [CrossRef] [Green Version]
- Chhikara, P.; Singh, P.; Tekchandani, R.; Kumar, N.; Guizani, M. Federated learning meets human emotions: A decentralized framework for human–computer interaction for IoT applications. IEEE Internet Things J. 2021, 8, 6949–6962. [Google Scholar] [CrossRef]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Colen, R.R.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 12598. [Google Scholar] [CrossRef]
- Cui, J.; Zhu, H.; Deng, H.; Chen, Z.; Liu, D. FeARH: Federated machine learning with anonymous random hybridization on electronic medical records. J. Biomed. Inform. 2021, 117, 103735. [Google Scholar] [CrossRef] [PubMed]
- Feki, I.; Ammar, S.; Kessentini, Y.; Muhammad, K. Federated learning for COVID-19 screening from chest X-ray images. Appl. Soft Comput. 2021, 106, 107330. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Chai, Y.J.; Joo, H.; Lee, K.; Hwang, J.Y.; Kim, S.-M.; Kim, K.; Nam, I.-C.; Choi, J.Y.; Yu, H.W.; et al. Federated learning for thyroid ultrasound image analysis to protect personal information: Validation study in a real health care environment. JMIR Med. Inform. 2021, 9, e25869. [Google Scholar] [CrossRef]
- Liu, J.C.; Goetz, J.; Sen, S.; Tewari, A. Learning from others without sacrificing privacy: Simulation comparing centralized and federated machine learning on mobile health data. JMIR mHealth uHealth 2021, 9, e23728. [Google Scholar] [CrossRef]
- Yan, Z.; Wicaksana, J.; Wang, Z.; Yang, X.; Cheng, K.-T. Variation-aware federated learning with multi-source decentralized medical image data. IEEE J. Biomed. Health Inform. 2021, 25, 2615–2628. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, B.; Barnawi, A.; Xi, S.; Kumar, N.; Wu, Y. FedDPGAN: Federated differentially private generative adversarial networks framework for the detection of COVID-19 pneumonia. Inf. Syst. Front. 2021. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, X.; Jin, Y. Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4229–4238. [Google Scholar] [CrossRef]
- Huang, L.; Yin, Y.; Fu, Z.; Zhang, S.; Deng, H.; Liu, D. LoAdaBoost: Loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data. PLoS ONE 2020, 15, e0230706. [Google Scholar] [CrossRef] [Green Version]
- Shao, R.; He, H.; Chen, Z.; Liu, H.; Liu, D. Stochastic channel-based federated learning with neural network pruning for medical data privacy preservation: Model development and experimental validation. JMIR Form. Res. 2020, 4, e17265. [Google Scholar] [CrossRef] [PubMed]
- Dou, Q.; So, T.Y.; Jiang, M.; Liu, Q.; Vardhanabhuti, V.; Kaissis, G.; Li, Z.; Si, W.; Lee, H.H.C.; Yu, K.; et al. Federated deep learning for detecting COVID-19 lung abnormalities in CT: A privacy-preserving multinational validation study. NPJ Digit. Med. 2021, 4, 60. [Google Scholar] [CrossRef]
- Rajendran, S.; Obeid, J.S.; Binol, H.; D’Agostino, R.; Foley, K.; Zhang, W.; Austin, P.; Brakefield, J.; Gurcan, M.N.; Topaloglu, U. Cloud-based federated learning implementation across medical centers. JCO Clin. Cancer Inform. 2021, 5, 1–11. [Google Scholar] [CrossRef]
- Sarma, K.V.; Harmon, S.; Sanford, T.; Roth, H.R.; Xu, Z.; Tetreault, J.; Xu, D.; Flores, M.G.; Raman, A.G.; Kulkarni, R.; et al. Federated learning improves site performance in multicenter deep learning without data sharing. J. Am. Med. Inform. Assoc. 2021, 28, 1259–1264. [Google Scholar] [CrossRef]
- Xue, Z.; Zhou, P.; Xu, Z.; Wang, X.; Xie, Y.; Ding, X.; Wen, S. A resource-constrained and privacy-preserving edge-computing-enabled clinical decision system: A federated reinforcement learning approach. IEEE Internet Things J. 2021, 8, 9122–9138. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Xu, Z.; Li, W.; Myronenko, A.; Roth, H.R.; Harmon, S.; Xu, S.; Turkbey, B.; Turkbey, E.; Wang, X.; et al. Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan. Med. Image Anal. 2021, 70, 101992. [Google Scholar] [CrossRef]
- Abdul Salam, M.; Taha, S.; Ramadan, M. COVID-19 detection using federated machine learning. PLoS ONE 2021, 16, e0252573. [Google Scholar] [CrossRef]
- Vaid, A.; Jaladanki, S.K.; Xu, J.; Teng, S.; Kumar, A.; Lee, S.; Somani, S.; Paranjpe, I.; De Freitas, J.K.; Wanyan, T.; et al. Federated learning of electronic health records to improve mortality prediction in hospitalized patients with COVID-19: Machine learning approach. JMIR Med. Inform. 2021, 9, e24207. [Google Scholar] [CrossRef]
- Cha, D.; Sung, M.; Park, Y.-R. Implementing vertical federated learning using autoencoders: Practical application, generalizability, and utility study. JMIR Med. Inform. 2021, 9, e26598. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Hegde, H.; Shimpi, N.; Panny, A.; Glurich, I.; Christie, P.; Acharya, A. MICE vs. PPCA: Missing data imputation in healthcare. Inform. Med. Unlocked 2019, 17, 100275. [Google Scholar] [CrossRef]
- Tran, K.; Bøtker, J.P.; Aframian, A.; Memarzadeh, K. Artificial intelligence for medical imaging. In Artificial Intelligence in Healthcare; Elsevier: Amsterdam, The Netherlands, 2020; pp. 143–162. [Google Scholar]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. Proc. USENIX Secur. Symp. 2014, 2014, 17–32. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Almadhoun, N.; Ayday, E.; Ulusoy, Ö. Inference attacks against differentially private query results from genomic datasets including dependent tuples. Bioinformatics 2020, 36, i136–i145. [Google Scholar] [CrossRef] [PubMed]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying membership inference attacks in machine learning as a service. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography; Springer: Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Caldas, S.; Meher Karthik Duddu, S.; Wu, P.; Li, T.; Konečný, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. LEAF: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Luo, J.; Wu, X.; Luo, Y.; Huang, A.; Huang, Y.; Liu, Y.; Yang, Q. Real-world image datasets for federated learning. arXiv 2021, arXiv:1910.11089. [Google Scholar]
- Di Martino, A.; Yan, C.-G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. In Neural Information Processing; Springer: Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Litjens, G.; Debats, O.; Barentsz, J.; Karssemeijer, N.; Huisman, H. SPIE-AAPM PROSTATEx challenge data. Cancer Imaging Arch. 2017. [Google Scholar] [CrossRef]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct dataset: Recognition of activities of daily living using smartphones. In Proceedings of the International Conference on Information and Communication Technologies for Ageing Well and e-Health, Rome, Italy, 21–22 April 2016; pp. 143–151. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing WESAD, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 400–408. [Google Scholar]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pollard, T.J.; Johnson, A.E.W.; Raffa, J.D.; Celi, L.A.; Mark, R.G.; Badawi, O. The EICU collaborative research database, a freely available multi-center database for critical care research. Sci. Data 2018, 5, 180178. [Google Scholar] [CrossRef] [PubMed]













| ML Algorithms | Strength | Weakness | FL Study |
|---|---|---|---|
| AE | AE is mainly designed for dimensional feature reduction and denoising medical datasets via an unsupervised learning method. AE aims to recreate effective compact and effective feature representation. | An autoencoder may exclude essential information from a medical dataset’s characteristics. | [19,21,37] |
| CNN | Performs well on medical image classification tasks such as prediction of COVID-19 using X-ray images | The training process of CNN that contains multiple layers will be time-consuming if the client in the FL environment does not have powerful computation resources. | [18,20,38,39,40,41,42] |
| GAN | Generate a synthetic sample of medical data for limited quantity in experiments datasets. | Training GAN is challenging due to the unstable training process, no standard metric evaluation, and numerous trial-and-error experiments required for effective outcomes. | [43,44] |
| LSTM | Performs well on time series or sequential medical datasets, for instance, detection of human activity recognition. | Due to the vanishing and exploding gradient challenges, training LSTM is difficult. | [45] |
| MLP | Good generalization performance on tabular medical datasets such as mortality prediction based on drug data | MLP is limited to learning elementary problems. Additionally, it is feature-scaling sensitive and involves setting numerous hyperparameters such as the number of hidden neurons and layers. | [46,47,48,49,50,51] |
| SVM | SVM is capable of modeling nonlinear decision boundaries and a variety of kernels are available. Additionally, it is highly resistant to overfitting, particularly in high-dimensional space. | SVM is memory-consuming, more difficult to modify because of critically selecting the appropriate kernel, and does not scale well to more extensive datasets. | [52] |
| U-Net | Achieve accurate results when performing segmentation tasks on medical image datasets, for example, when segmenting brain tumors disease using brain magnetic resonance medical images. | U-Net model development is time-consuming because the network must be operated independently for each patch, and redundancy due to overlapping patches. Additionally, a tradeoff exists between the precision of localization and the utilization of context. | [38,53] |
| Dataset Type | Dataset Name | Description | FL Study | |
|---|---|---|---|---|
| Healthcare dataset | Medical Image Classification | Autism Brain Imaging Data Exchange (ABIDE) I [68] | The ABIDE I is a consortium dataset openly sharing 1112 functional magnetic resonance imaging (fMRI) dataset from 539 patients with autism spectrum disorders. | [18] |
| Public COVID-19 Image Data Collection [69] | The dataset consists of 108 healthy chest X-ray images and 108 confirmed with COVID-19 chest X-ray images taken from 76 patients. | [40,44,54] | ||
| Facial Emotion Recognition (FER) 2013 [70] | The FER2013 dataset consists of 35,887 human facial emotion images. The dataset is labeled into seven emotions: neutral, anger, disgust, sadness, happiness, surprise, and fear. | [37] | ||
| Medical Image Segmentation | Brain Tumor Image Segmentation Benchmark (BraTS) 2017 and 2018 [71] | The BraTs 2017 were collected from 13 institutions and consisted of 359 patients’ brain tumor scans. | [38] | |
| SPIE-AAPM PROSTATEx dataset [72] | The PROSTATEx dataset consists of 343 MRI prostate image cancer from Siemens 3T MR scanners, the MAGNETOM Trio, and Skyra. | [43,50] | ||
| Electronic Health Record | MobiAct [73] | The MobiAct dataset is human activity dataset taken from 57 volunteers (42 men and 15 women). | [21] | |
| Human Activity Recognition (HAR) [74] | The HAR dataset was collected from 30 volunteers. Each subject performed different activities such as walking, sitting, standing, and laying. There are 10,299 with 561 time-series features. | [20,45] | ||
| WESAD (Wearable Stress and Affect Detection) [75] | The WESAD is a dataset for wearable effect and stress detection. Taken from 15 participants, the WESAD consists of 12 features with 63,000,000 time-series samples. | [42] | ||
| Medical Information Mart for Intensive Care (MIMIC) III [76] | The MIMIC III dataset was collected from 40,000 patients during stayed in the ICU at Beth Israel Deaconess Medical Center between 2001 and 2012. | [46] | ||
| The eICU collaborative research database. [77] | Critical care datasets consist of 200,859 patients data from 208 hospitals in the United States. | [19,39,56] | ||
| Nonhealthcare dataset | Image classification, sentiment analysis | LEAF Dataset [66] | The LEAF Dataset Benchmarking framework consists of images and text datasets such as EMNIST, Celeba, Shakespeare, and Synthetic datasets. | [66] |
| Image Classification | FedVision—Real World image dataset for FL [67] | The FedVision dataset contains more than 900 real-world images generated from 26 street cameras. Precisely, it consists of 7 classes with a detailed bounding box. This dataset has non-IID properties reflecting a real-world data distribution. | [67] |
| Framework Name | Creator | Supported Techniques | URL | |||
|---|---|---|---|---|---|---|
| Data Partition | Data Distribution | Data Privacy Attack Simulation | Data Privacy Protection Methods | |||
| PySyft | Open Mined | ✓ HFL, VTL | ✓ IID, non-IID | ✕ | ✓ DP, HE | https://github.com/OpenMined/PySyft (accessed on 7 July 2021) |
| TFF | ✓ HFL | ✕ | ✕ | ✕ | https://www.tensorflow.org/federated (accessed on 7 July 2021) | |
| FATE | Tencent | ✓ HFL, VFL, FTL | ✕ | ✕ | ✓ HE | https://github.com/FederatedAI/FATE (accessed on 21 July 2021) |
| Sherpa.ai | Sherpa.ai | ✓ HFL | ✓ IID, non-IID | ✓ Data Poison | ✓ DP | https://developers.sherpa.ai/privacy-technology/ (accessed on 27 August 2021) |
| LEAF | Sebastian Caldas | ✓ HFL | ✕ | ✕ | ✕ | https://leaf.cmu.edu/ (accessed on 21 July 2021) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prayitno; Shyu, C.-R.; Putra, K.T.; Chen, H.-C.; Tsai, Y.-Y.; Hossain, K.S.M.T.; Jiang, W.; Shae, Z.-Y. A Systematic Review of Federated Learning in the Healthcare Area: From the Perspective of Data Properties and Applications. Appl. Sci. 2021, 11, 11191. https://doi.org/10.3390/app112311191
Prayitno, Shyu C-R, Putra KT, Chen H-C, Tsai Y-Y, Hossain KSMT, Jiang W, Shae Z-Y. A Systematic Review of Federated Learning in the Healthcare Area: From the Perspective of Data Properties and Applications. Applied Sciences. 2021; 11(23):11191. https://doi.org/10.3390/app112311191
Chicago/Turabian StylePrayitno, Chi-Ren Shyu, Karisma Trinanda Putra, Hsing-Chung Chen, Yuan-Yu Tsai, K. S. M. Tozammel Hossain, Wei Jiang, and Zon-Yin Shae. 2021. "A Systematic Review of Federated Learning in the Healthcare Area: From the Perspective of Data Properties and Applications" Applied Sciences 11, no. 23: 11191. https://doi.org/10.3390/app112311191
APA StylePrayitno, Shyu, C. -R., Putra, K. T., Chen, H. -C., Tsai, Y. -Y., Hossain, K. S. M. T., Jiang, W., & Shae, Z. -Y. (2021). A Systematic Review of Federated Learning in the Healthcare Area: From the Perspective of Data Properties and Applications. Applied Sciences, 11(23), 11191. https://doi.org/10.3390/app112311191