This section covers relevant work relating to maintenance of industrial machinery connected to fault detection and condition monitoring, and describes related deep learning methods in the section below.
2.1. Maintenance
The usage of machinery is essential in industrial applications. Failure of these machines due to wear of the underlying elements is one of the most prevalent concerns in industry; therefore, equipment maintenance is critical in preventing malfunctions and, as a result, minimizing downtime. According to [
12], maintenance expenses range from 15% to 60% of the total cost of the manufactured goods. Around 33% of maintenance expenses are directly connected to redundant and incorrect equipment maintenance within these margins. As a result, lowering the expenses of costly maintenance might substantially reduce overall production costs by improving equipment productivity [
13].
According to [
14,
15] there are three distinct techniques for maintaining equipment: (1) modificative maintenance, in which components are upgraded to improve machine productivity and performance, (2) preventive maintenance, in which a component is replaced just before it fails and (3) break-down corrective maintenance, in which a part is replaced after it fails, leading to downtime of the machine. In this paper, we concentrate on (2) preventive maintenance, which itself is separated into two types: usage-based maintenance (UBM) and condition-based maintenance (CBM).
The UBM method relies entirely on arranging maintenance visits by the engineer when a specific threshold of consumption is achieved. In practice, this implies that visits are scheduled with a certain interval between them, comparable to a yearly automobile inspection. This technique results in relatively little equipment downtime, which is good for production. However, this method has two major disadvantages; the high expenses of maintenance visits and the replacement of parts that are still usable. As a result, in many industrial applications, CBM is the recommended maintenance approach, making use of data-driven methods and approaches, e.g., cf. [
14,
16,
17].
CBM assesses the current state of equipment to identify if maintenance is required. The concept behind CBM is to only execute maintenance when specific parameters, e.g., deviating behavior in the data, indicate a reduction in performance or a predicted rise in failures. This means fewer maintenance visits and more efficient usage of the underlying components, which in turn leads to lower overall maintenance costs.
2.2. Fault Detection and Condition Monitoring
Within CBM, fault detection and condition monitoring are common approaches for rotating industrial equipment where faults regularly occur [
18]. In the past, this was achieved using physics-based models, which require background knowledge on the underlying processes. These models hardly adapt to changing circumstances and increments in the amount of data and variables [
19]. Innovations in data-driven analytics and the advances in Industrial Internet of Things (IOT) have altered the area of fault detection and condition monitoring towards a more intelligent approach [
4,
20]. These methods allow for automated data processing without prior understanding of technical elements of industrial machinery, while easily adaptable to changing operation conditions.
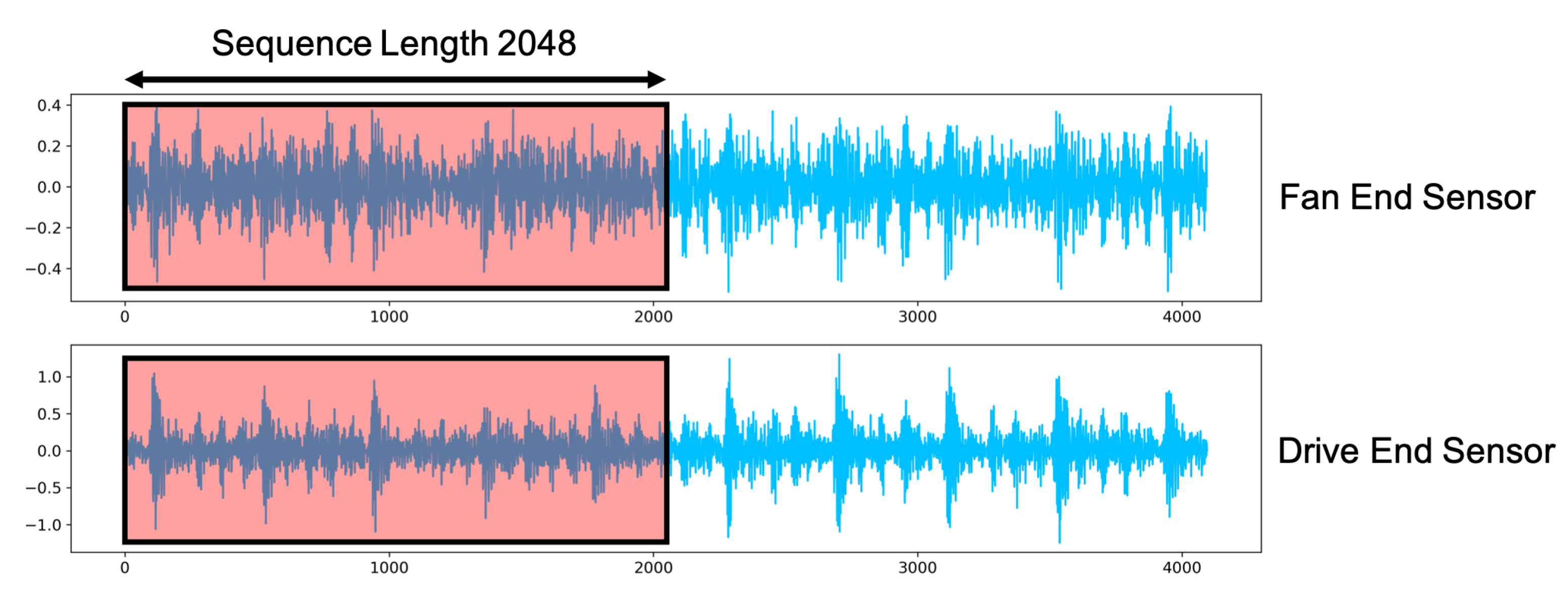
Because of the increased availability of large-scale time series datasets and better processing capacity, the usage of deep learning applications has grown in popularity. These time series are recorded by sensors, which are increasingly being used for fault detection and condition monitoring. When elements of equipment decay over time, for example, the analog metrics of the machine will not immediately reflect this; however, increased power usage (motor current), vibrations or temperature of machine elements monitored with internal and external technologies, such as sensors, might indicate that the underlying parts need to be replaced [
4,
9,
10]. These signals derived from sensors can be converted into numerical time series data for subsequent study. However, for reliable fault detection, considerable efforts in feature extraction is typically required.
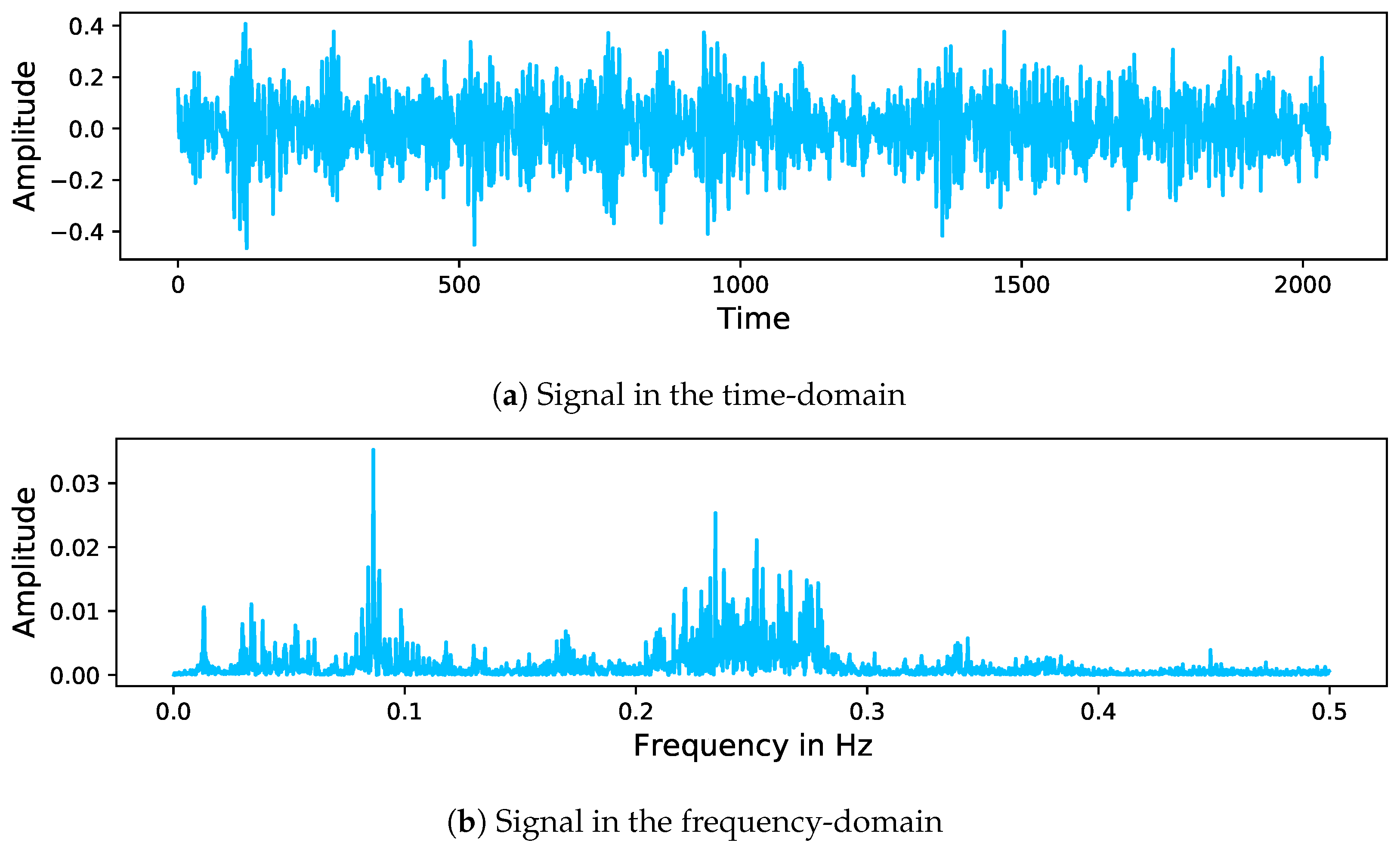
Traditional methods for extracting representative features to classify signals include time-domain analysis (e.g., statistical measures such as mean and standard deviation), frequency-domain analysis (e.g., Fourier transformations [
7], see
Figure 1) and time-frequency domain analysis, (e.g., wavelet transformations [
21,
22]). As one could expect, the quantity of features derived from the different domains results in a high-dimensional dataset. Therefore, features are picked [
23] and techniques are frequently used to decrease the dimensionality of these features, such as principal component analysis (PCA) [
24,
25] or linear discriminant analysis (LDA) [
26]. Furthermore, [
27], for example, utilized information entropy to preprocess the original time series data.
Before the final dataset can be supplied to a classifier, the essential preprocessing steps typically take a substantial amount of time and high-level knowledge in signal processing and data processing—regarding standard (non-deep learning) machine learning approaches. Additionally, the feature extraction process is influenced by the type of data gathered from a particular machine or sensor, for instance, vibration sensors require different preprocessing steps than analog sensors.
Within fault detection and condition monitoring, many different classifiers are researched, including k-nearest neighbors (K-NN) [
28,
29], support vector machines (SVM) [
21,
30,
31,
32], artificial neural networks [
33,
34] and interpretable machine learning methods such as random forests (RF) [
35]. The performance of these techniques varies a lot depending on the data quality, thoroughness of the feature extraction process and complexity of the classification task; therefore, it is often difficult to find the right classifier for the task at hand. In other words, there is not one particular machine learning classifier that is most capable of distinguishing different fault conditions. As a result, a comparison between classifiers is deemed necessary for every fault detection task to find the most optimal model.
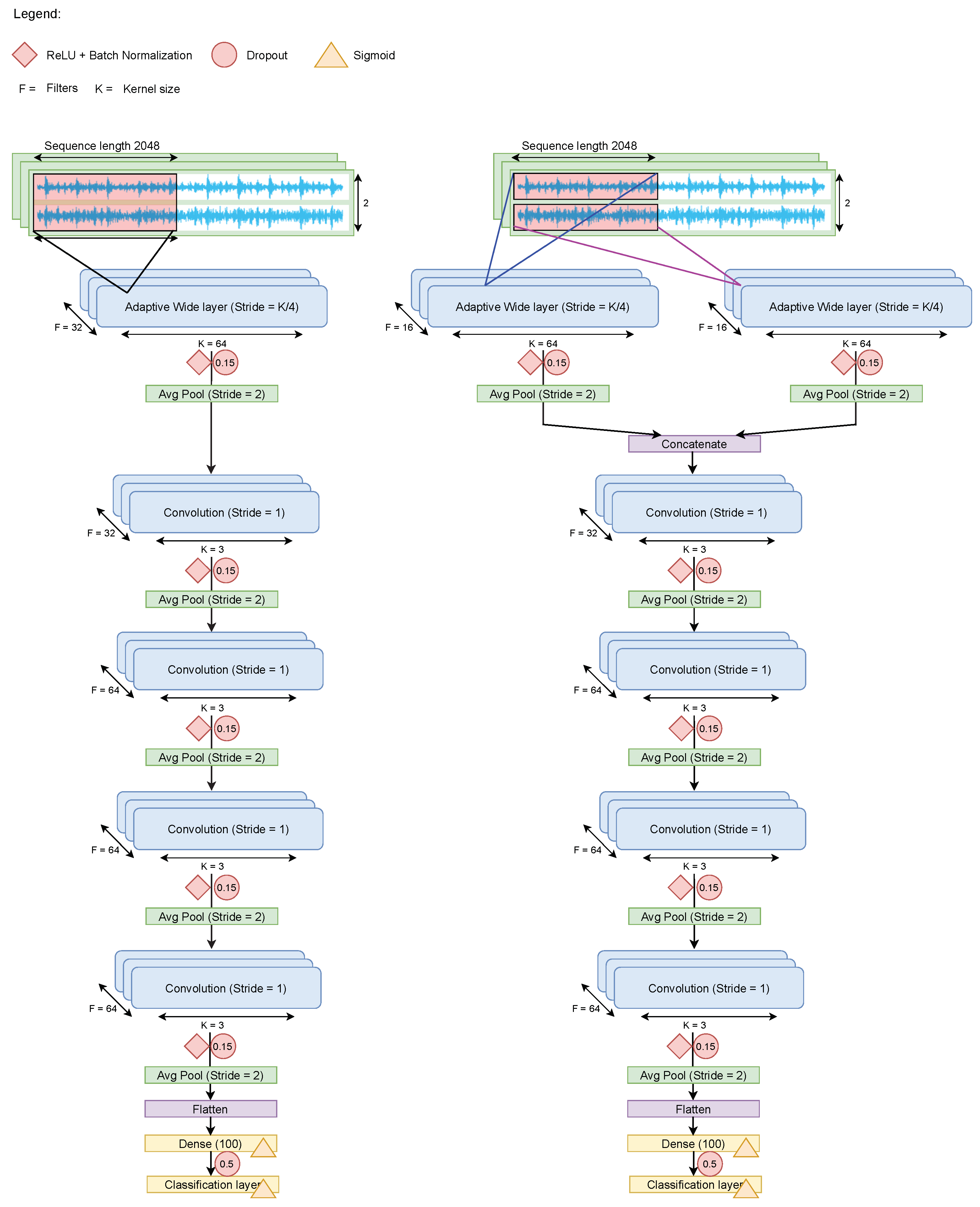
This work concentrates on deep learning applications, and more specifically on the use of one-dimensional CNNs in the context of fault detection utilizing time series data, i.e., multivariate signal data. To evaluate our proposed deep learning techniques, we used renowned benchmark datasets for fault detection and condition monitoring in various settings. We look at the generalizability of these techniques, their performance with limited training data and compare them to traditional machine learning approaches such as k-nearest neighbors, random forests and support vector machines.
2.3. Deep Learning
In general, deep learning methods offer strong processing and learning on complicated data. For instance, automatic feature generation and refinement techniques, such as for complicated classification problems, may typically leverage connections in the data in order to retrieve valuable information from the data into redefined structures. Using complicated multivariate signal data for fault detection and condition monitoring is an example of utilizing these complex data structures. Overall, there has been a lot of interest in utilizing neural networks for such complicated classification problems during the previous decade.
Initially, the multi-layer perceptron (MLP) was used, in which all network layers are fully linked [
36]; however, because of the significant increase in calculation time, the depth of these networks is restricted. Thus, in the past years, more advanced neural network architectures were developed to accommodate for this.
The creation of recurrent neural networks (RNN), such as long short-term memory (LSTM) networks, has yielded promising results since they are able to account for time dependencies and therefore can handle time series data and signals very well [
37,
38]. However, because of memorizing long-term time dependencies, RNNs use vast amounts of memory (RAM). So, these models are less suited for long sequence data due to increased training times. This is especially the case for signal data from sensors, which is often sampled at a high frequency consisting of many data points. To tackle the training issue of RNNs, combined models utilizing autoencoders as feature extractors were created [
39]. These models enhance computation but also increase the model’s complexity and decrease its interpretability.
Deep learning algorithms have been used to detect faults and monitor machine conditions many times. The MLP [
40] was one of the earliest deep learning applications in fault detection and condition monitoring. Later, RNNs [
37] and CNNs [
4,
20,
41,
42] became more common in fault detection, where they have exhibited significant performance increases. Further, CNN approaches combined with data transformations, e.g., spectrograms, have been proposed several times [
3,
43]. Ref. [
44] was successful in the creation of a 1D CNN that is able to handle raw signals by integrating automated feature extraction with time series classification. These 1D CNNs can also withstand noise effectively and can be trained with small amounts of data [
45].
Overview—Convolutional Neural Networks
A convolutional neural network (CNN), in general, is a regularized MLP that specializes in processing two-dimensional inputs such as picture pixels and color channels. CNNs have previously proven to be effective in computer vision tasks including image classification and video identification [
46,
47].
The main advantages of a CNN, compared with a traditional neural network, such as an MLP, is the use of local receptive fields, weight-sharing and sub-sampling. Especially, the weight-sharing significantly reduces memory requirements and therefore improves algorithmic efficiency [
48]. Commonly, a convolutional layer consists of three phases. The first layer performs a number of convolutions, followed by the second phase that consists of an activation function. Afterwards, a pooling function is applied [
48].
Before employing a CNN on one-dimensional data, e.g., time series, the data has to be converted using signal processing techniques into a two-dimensional representation in the time-frequency spectrum or using wavelet transforms [
22,
49,
50]. For example, one-dimensional signals can be transformed in two-dimensional spectrograms, which in turn can be fed as an image to the CNN. This approach is not able to process raw signals directly, thus contradicting the advantages of employing deep learning applications over standard machine learning approaches. The one-dimensional (1D) CNN was created to tackle this challenge by integrating automated feature extraction for time series classification tasks [
44]. These models are good at handling noise in time series and can be trained with different data sizes, while being less computationally heavy compared to RNNs or MLPs. As a result, 1D CNNs are becoming more and more applied in time series classification tasks such as fault detection and condition monitoring [
45].
Convolutional Layer
A convolutional layer convolves the input with filter kernels followed by the activation unit to generate output features. Each of these filters uses the same kernel to extract local features from the input local region, called weight-sharing. Results of the convolutional operations across the input are fed to the activation function that leads to the output features. The convolution operation is described as:
Here,
denotes the bias and
denotes the weights of the
i-th filter kernel in layer
l.
describes the
j-th local region in layer
l.
represents the convolution operation that computes the dot product of the kernel and the local regions.
denotes the input of the
j-th neuron in feature map
i of layer
l + 1.
Activation Function
The activation function is embedded in every convolutional layer to acquire nonlinear features from the input after the convolutional operation. Depending on the input and the task at hand, there are several different activation functions available; however, in recent years, the rectified linear unit (ReLU) has proven to be efficient in its computations and is therefore the most common used activation function. In this study, the ReLU activation function was used in the convolutional layers and can be described as follows:
Here,
x represents the outputs of the convolutional operation
and
represents Gaussian distributed noise with mean 0 and variance
, which has proven to make optimization easier [
51].
Pooling Layer
The output of the convolutional layer and activation function are usually fed to a pooling layer (also known as sub-sampling layer). This layer reduces the spatial size of the input features by a down-sampling operation and decreases the number of parameters and computations in the network. There are different pooling functions such as max-pooling and average-pooling. The pooling function performs a local operation over the input features resulting in a representation that becomes invariant to small translations of the input. In general, the pooling function can be denoted as:
denotes the pooling operation where values of the convolved features are computed on different locations. For every layer
l, the
i-th weight matrix is denoted as
.
represents the outputs of the convolutional layer (feature map) and
denotes the bias. These calculations then result in the compressed feature representation
given above.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}