1. Introduction
Proper management of inputs, that is, the application of fertilizer in accordance with the nutritional needs of each plant, is necessary to achieve a healthy crop and optimal yield, which is a new concept in the so-called field of precision agriculture [
1]. Among the nutrients needed by plants, nitrogen is one of the most important because it is a main component of chlorophyll. However, nitrogen deficiency/overdose in plants is one of the major nutritional problems that is affecting current agricultural practices. The first sign of nitrogen deficiency is the paleness of old leaves, because this element can move from the lower old leaves to the upper young leaves. The leaves are usually yellowish green and light yellow due to the lack of chlorophyll formation. Late red and reddish-purple growth is observed as a result of anthocyanin dye formation; also, the leaves, stems and branches become thin in nitrogen deficiency status [
2,
3,
4].
Unfortunately, in order to increase yield, farmers have resorted to excessive use of nitrogen fertilizers and are not very willing to use biological, organic and micronutrient fertilizers [
5]. However, studies indicate that nitrate accumulation in agricultural products does not play a very positive role in sustainable production and public health [
6,
7].
Excessive consumption of nitrogen makes the plant susceptible to diseases and pests. In fruit crops, it causes damage to flowers and blossoms, and reduces the quality of the product. If the main source of nitrogen supply is ammonium, it can poison the plant, as a result of which the vascular tissues are damaged and the leaves appear as cups. Therefore, at the present stage, scientific management of production and consumption of fertilizers is inevitable to improve the structure of production and the level of public health by improving the optimal use of fertilizers.
Many farmers perform leaf analysis when they observe signs of food disturbance or unknown symptoms on the leaves. Leaf analysis helps growers better manage nutrient inputs by determining the type and amount of fertilizer needed and identifying problems that may lead to poor crop performance; but, at that time, it is evident that the plant has been damaged. Therefore, in order to get a better result, disorders must be identified before the onset of symptoms. Leaf analysis is time consuming and requires special methods to interpret the data correctly [
8,
9]. On the other hand, this method is destructive. Thus, the application of non-destructive and fast methods is very important.
In recent years, spectroscopy and hyperspectral imaging have been recognized as useful tools for classifying the internal and external properties of biological products. For example, Sabzi et al. [
10] detected early the nitrogen in cucumber plants using hyperspectral images. They captured hyperspectral images of the leaves with excess and standard amount of nitrogen for several consecutive days in laboratory. The results showed that the visible and near-infrared (Vis/NIR) hyperspectral imaging technique was able to early detect plants with excess of nitrogen at a rate of 96.11%. Wang et al. [
11] analyzed hyperspectral data from mature leaves of tea plants by partial least squares-discriminant analysis (PLS-DA) and least squares-support vector machines (LS-SVM) to classify different nitrogen status. The results showed that the LS-SVM model was more able to predict different rates of nitrogen with an accuracy of 82%.
Currently, deep learning (DL) models are an extremely active area of research and they are applied in many domains, such as is in this study. They are taught using large labeled datasets and neural network structures that directly characterize features. So, they are trained without the need to extract the features manually. One of the most popular types of DL models are convolutional neural networks (CNN or ConvNet). Automatic feature extraction in CNNs makes them practical and attractive for computer vision tasks such as object detection and segmentation. A CNN learns to recognize different features of an image using up to hundreds of hidden layers. They were introduced in 1990, inspired by experiments performed by Hubel and Wiesel [
12] on the visual cortex. The uses of CNN have grown so rapidly that, in a short time, they have revolutionized many areas of computer vision, such as human action detection, object detection, face detection and tracking. In this regard, Zhu et al. [
13] conducted a review of traditional machine learning and deep learning methods, including AlexNet, VGG Net and fully convolutional networks (FCN). According to their declaration, despite the success of the machine vision methods, they will have low accuracy if the background is too noisy, or the lighting conditions are poor, since they will not be able to detect small changes in the food.
Watchareeruetai et al. [
14] used a CNN for studying deficiencies on plants considering different nutrients, such as Ca, Fe, K, Mg and N. A dataset consisting of 3000 leaf images was analyzed. The results indicated that the proposed method is superior to trained humans in the detection of nutrient deficiency. The CNN classifier had an accuracy of 94%. Espejo-García et al. [
15] aimed to use fine-tuning, instead of ImageNet, in pre-trained CNN in order to improve the obtained performance. Experimental results showed that the overall performance can be increased by the proposed method. Some structures, such as Xception and Inception-Resnet, improved it by 0.51% and 1.89%, respectively. Comparing machine learning with DL, Sharma et al. [
16] stated that DL has been analyzed and implemented in various applications and has shown remarkable results, thus they need to be explored more broadly, since they can also be useful in most fields. Liu et al. [
17] categorized hyperspectral images using long short-term memory (LSTM). Specifically, for each pixel, they fed spectral values one by one in different LSTM channels to train spectral properties. Principal component analysis (PCA) was used first to extract the first components of a hyperspectral image, and then local patches were selected. The row vectors of each patch are then transferred to the LSTM to determine the spatial properties of the central pixel. Then, in the classifier step, the spectral and spatial properties of the pixels are fed into soft-max classifiers, to obtain two different results. A strategy for decision fusion was used to obtain more spatial-spectral results. Tian et al. [
18] estimated soluble solids in apples using spectral data and DL. In their proposed model, the spectral data of apples were investigated and determined using a random frog algorithm; and DL was used to train and test the detection of geographical origin with spectral data as input. Partial least squares (PLS) were used to create individual calibration models, and then to estimate soluble solids. Competitive adaptive reweighted sampling (CARS) was used to select the optimal wavelengths. Compared to the individual source model, the proposed multi-source model obtained more accurate results for predicting soluble solid content of apples from multiple geographical origins, obtain an RP of 990 and RMSEP 0.274. Cai et al. [
19] estimated soil nutrients also using spectroscopy and DL. The simulation results indicated that the proposed model was able to improve the efficiency of obtaining the features with high reliability. This solves the problem of traditional models.
Cucumber is a fruit that is rich in useful nutrients, containing some compounds and antioxidants, which may help improve, and even prevent, some diseases in humans [
20]. Reliable diagnosis of the nutritional status of agricultural products is an important aspect of farm production, since both excess and deficiencies of nutrients can lead to damages and reduced yields. According to the literature, most of the previous research works used statistical methods, simple perceptron neural networks and DL neural networks with predefined structures, such as ImageNet and LSTM [
21]. Although all these methods were successful on their own, more accurate methods are needed for everyday use.
Consequently, the present paper describes a new one-dimensional (1D) convolutional neural network to estimate the nitrogen content of cucumber leaves. The innovation of this paper resides in the application of nitrogen overdose at 3 different levels, in order to investigate whether it is possible to detect nitrogen-rich cucumber on site and in real-time. Hyperspectral analysis of fruits and plants has been a very active area of research in the literature, and particularly in our research group, as previously seen. The main novelty of the present work resides in the proposal of a new 1D-CNN architecture with 12 layers. It contains six convolutional layers and three max-pooling layers, finishing with a dense layer, which produces the final estimation of nitrogen content. Another important element is the addition of a dropout layer that, by randomly removing some weights of the previous layer, avoids problems of overfitting.
4. Discussion
In general, the results presented in the previous section prove that the nitrogen content of cucumber leaves can be estimated with a high accuracy using hyperspectral information in the Vis-NIR range and the proposed 1D-CNN regression models. The obtained mean errors are always below 1% with respect to the expected values for all the treatments. For example, in the N30% class, the mean absolute error (MAE) is only 0.017 mg/g, while the nitrogen content ranges from 3–3.4 mg/g; this would represent a 0.56% relative error. The relative MAE for the N60% and N90% classes are 0.35% and 0.45%, respectively. This means that the proposed approach can be effectively used for the estimation of nitrogen in the leaves from the early stages, since the error is very small even for the 30% class.
This positive result can also be argued even for the worst cases of error, i.e., considering the maximum errors, MaxE. This error is 0.086 mg/g for N30% class and 0.091 mg/g for N60% class, which represent relative errors below 3%. In the N90% class, this worst case has a very low error of 0.054 mg/g. Therefore, we can conclude that the method does not present cases of extremely high error. This is evidence of the robustness of the proposed approach against the most difficult cases.
Regarding the preprocessing techniques applied in the paper, MSC and SG, both steps prove to have positive effects on the obtained results. Observe that MSC is a scatter correction filter of the spectra, while SG is a smoothing operator. In all the treatments, the worst results are given by not applying any filter, which is evident for all the performance measures. For example, in the 60% class, the MSE is 0.0003 mg/g with the proposed filters, MSC + SG, while it rises to 0.0012 mg/g with no preprocessing filter. If we should select only one filter, the smoothing step, SG, is the method that offers the best results by itself in terms of the error. For example, in the 90% class, the MAE without any filter is 0.028 mg/g; with SG it descends to 0.025, but with MSG it is 0.027. This indicates that smoothing is more beneficial than scatter correction. This is also repeated for the determination coefficient, R2, which is consistently higher for SG. Moreover, the improvement from applying MSC + SG with respect to applying only SG is very reduced in most cases, with a small positive effect in the error measures.
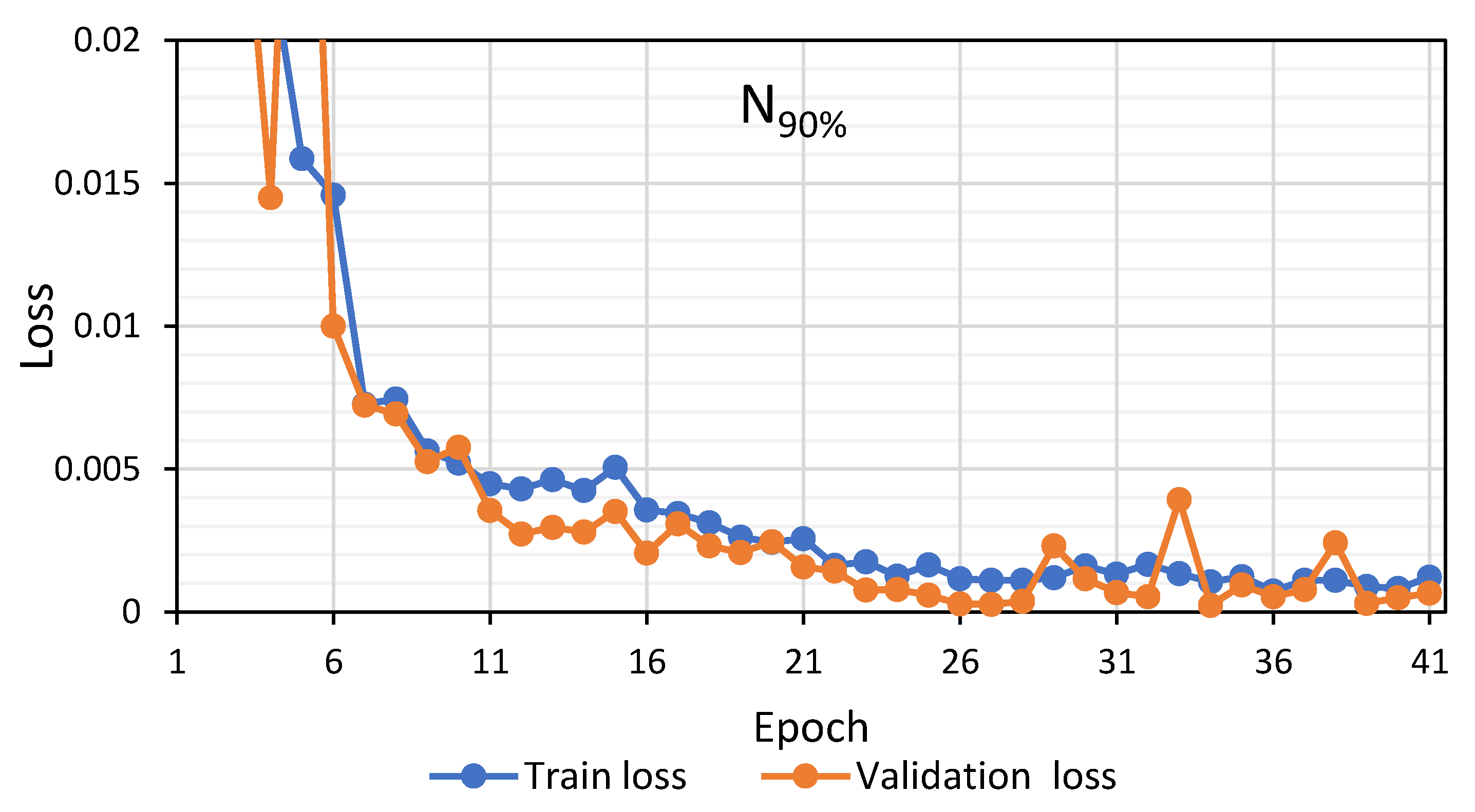
Analyzing the evolution of the loss curves in
Figure 6,
Figure 8 and
Figure 10, it can be seen that the proposed 1D-CNN has a very fast convergence for all the treatments. A fast reduction of the loss values is produced in the first five epochs. Then, the system enters in a gradual convergence phase, which is stopped before it could incur in over-fitting. No model required more than 43 epochs, making them relatively fast to be trained. The loss curves also indicate that the training process does not incur in over-fitting, which would appear as a reduction of the train loss and an increment in the validation loss.
Finally,
Table 7 presents a comparison of the results achieved by the proposed 1D-CNN models, compared with the results of other researchers for the non-destructive estimation of different properties of fruits, using R
2 criterion. Although these works have been selected among the most similar to our proposed method, this comparison has to be considered in context, since they refer to different types of fruits, different datasets, and distinct types of regression models. We have also included the results of a previous study from our group that deals with the estimation of nitrogen in tomato leaves, using different types of classifiers [
35]. Overall, the results of the present study showed that using 1D-CNN based on spectral data, it is possible to estimate the excess nitrogen more accurately, achieving results that are in the state of the art.
Comparing the obtained results with the accuracy reported in [
35], it can be seen that the R
2 are significantly better. These methods include partial least squares regression (PLSR) which is a statistical-based method, and hybrid approach of classical neural networks and the differential evolution algorithm (ANN-DE), and a method similar to the proposed in this paper using convolutional neural networks (CNN). In all of them, a unique model is trained for all the nitrogen categories, producing poor regression results always below 0.8 in R
2. Instead, the approach of creating separate models for each class is able to produce better results above 0.96. In fact, the approach of training different models for the classes was also analyzed in [
35], although the R
2 achieved ranged from 0.925 to 0.968.
On the other hand, a weak point of the proposed method is that it requires a previous classification of the leaf samples in the corresponding treatment class. Given a new unknown sample, there are three different models that could be applied on it. Thus, a classifier would be required to obtain the class before applying the regression network. This classification problem has been previously studied in our group, finding that it is possible to achieve it with a classification accuracy above 96% [
10]. This would complete a system based on two steps: first, classification of the sample; and then, regression of the nitrogen content using the specific model. The results discussed in this section indicate that this approach is able to produce better results than training a single regression model for all the classes.
5. Conclusions
Scientific management of production and consumption of fertilizers is necessary to achieve sustainable agriculture, and to improve food health by improving the optimal use of them, especially nitrogen-based fertilizers. In this paper, we have presented a new methodology for fast and accurate estimation of nitrogen content in cucumber leaves using spectroscopy analysis and convolutional neural networks (CNN).
Currently, CNNs are one of the most popular methods of machine learning, since they do not require manual feature extraction. Instead, automatic feature extraction makes deep learning models very accurate for computer vision tasks, such as regression models. Therefore, we have presented a new structure of one-dimensional CNN (1D-CNN) to estimate nitrogen content. Different levels of nitrogen fertilizer overdose by 30%, 60% and 90% were added to the cucumbers, and then prediction models were trained for each treatment. The experimental results have shown that the proposed 1D-CNN is able to estimate very accurately the nitrogen content even in the early stages, achieving, for example, for the 30% treatment, a maximum error of 0.086 mg/g and an R2 of 0.962. For the 60% and 90% classes, the R2 are 0.968 and 0.967, respectively. The experiments also showed that the applied preprocessing filters, multiplicative scatter correction, Savitzky–Golay, had a positive effect on the accuracy. Thus, this approach can be used to create a fast and non-destructive method to prevent excessive use of fertilizers.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}