1. Introduction
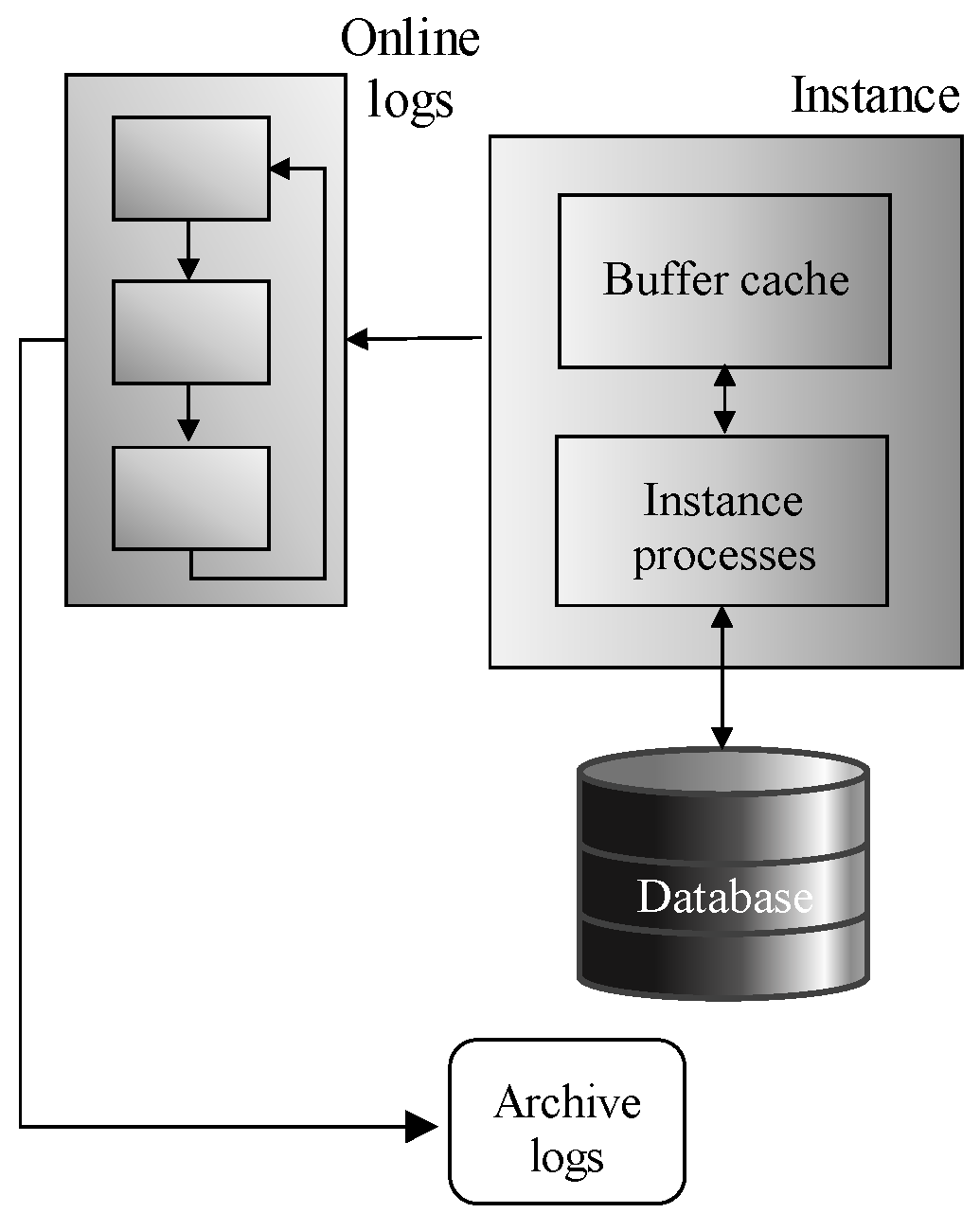
Data management is a core element of almost any information system. The robustness and intelligence of the information system are mostly covered by the data reliability provided in the suitable form and time. To get the relevant decision, it is inevitable to get not only the current data image, as it is stored in the database, but also the data correctness must be ensured, supervised by the transaction integrity. Historical data, as well as future valid object states, play an important role in creating prognoses and getting robust outputs. Input data to the system can originate from various sources with various sensitivity and quality. The main advantage of the relational systems is defined by the transaction processing defined by ACID (Atomicity, Consistency, Isolation and Durability) factors, ensuring atomicity, consistency, isolation, and data durability. Log files are crucial for the security to get the data image after the instance failure and to construct the database image dealing with the isolation factor. Thanks to that, the durability aspect of the transaction can be always reached by getting the opportunity to reconstruct transactions by executing restore and recovery. Transaction log files can be used in data evolution monitoring, as well. Active logs cannot be rewritten, otherwise the consistency aspect would be compromised.
Log files play an important role during the data retrieval, as well. Isolation of the transaction should ensure that the consistent data image is always obtained, thus any data change, even approved, cannot influence already running operation. To provide relevant data, the current state is obtained, followed by the transaction log analysis to get the undo image of the defined timepoint or system change identifier respectively. Shifting the processing into the temporal layout brings additional demands. The data amount is rising, forcing the system to get fast and reliable results as soon as possible.
This paper deals with the efficiency of temporal data processing. In each section, state of the art is discussed, highlighting the performance limitations, followed by introducing our own proposed improvements or new architecture. Namely,
Section 2 deals with the temporal database architecture with emphasis on the granularity levels. Core solutions are delimited by the object, and attribute oriented approaches. Group synchronization brings additional benefits, if multiple data changes are always done in the same time. Proposed improvement is done by using spatio-temporal grouping levels.
Section 3 deals with the transaction support and integrity. Contribution of the section is covered by the data reflection model, by which the transaction reflects multiple data models, which evolve over time in the temporality sphere. Existing conventional log rules are extended to cover the four-phase architecture model forming Extended Temporal Log Ahead Rule.
Section 4 deals with the existing approaches for the indexing in the first part. Then, the undefined values are discussed by proposing NULL_representation module. Proposed architecture deals with the Index module, Management handler, and Data change module located in the instance memory. Thanks to that, undefined values can be part of the currently often used B+tree index structure. Secondly, Master indexing and partitioning is discussed. The provided Master indexing technique can locate relevant data blocks in case of data fragmentation limiting the necessity to scan all data blocks associated with the table object sequentially. Finally, that section proposes a complex solution of the autoindexing technology available in the Oracle autonomous database cloud, by which the available index set is supervised, new indexes are added dynamically based on the current queries [
1,
2]. In this section, we also extend the technology of the post-indexing introduced in [
3,
4].
To cover the efficiency of the whole temporal environment, it is necessary to not only provide additional methods located internally in the database system itself. Therefore, we propose various clauses extending the temporal Select statement definition (
Section 5). The defined result set is delimited by the timeframe covered by the Event_definition clause. The Spatial_poistions clause defines relevant positional data regions Whereas the data model can evolve over time, the Model_reflection clause is available to reference. The Consistency_model clause similarly analyzes multiple time spectrum, covering the whole transaction processing by using timestamps. The Epsilon_definition can limit the result set by removing non-relevant data changes or changes, which do not reflect defined importance, respectively. Finally, the structure of the result set can be delimited by using Monitored_data_set, Type_of_granularity, and NULL_category denotation.
Section 6 deals with the performance analysis of all proposed solutions with regards to the existing solutions to declare the relevance and reached improvements. The limitations are discussed there, as well.
4. Indexing
A database index is an optional structure extending the table and data definition offering direct data location, whereas the data address locators (ROWID) are sorted based on the indexed attribute set. By using the suitable index, data can be located by examining the index first followed by the data location using ROWIDs. It is the most suitable and fast method, in comparison with the whole data block set scanning (Table Access Full (TAF) method), block by block sequentially until reaching the High Water Mark (HWM) symbol. It denotes the last associated block of the table. Generally, data blocks are not deallocated, even if they become empty, due to the management requirements, performance, and resource demands [
30,
31]. It does not have negative aspects in the terms of the storage and overall estimation, whereas there is an assumption, that the blocks will be used soon in the future, so they are already prepared. When dealing with Table Access Full, the empty block cannot be located directly, whereas the fullfillness is nowadays stored directly in the block itself. In the past, data blocks were divided based on the available size and split into particular lists, which were stored in the data dictionary. The limitation was just the necessity to get the data from the system table, which created the bottleneck of the system [
9,
32]. If the system was dynamic with frequent data changes and inserts, the problem was even deeper.
When dealing with the index, only relevant data blocks are accessed. They must be loaded into the memory using the block granularity and data are located, again by using ROWID values, which consist of the data file, particular block, and position of the row inside the data block. Thanks to that, data are obtained directly, however, one performance problem can be present, as well. In principle, data after the Update operation are usually placed into the original position in the database. Thus, the data ROWID pointer is not changed and remains still valid. If the data row after the operation does not fit the original block, the newly available block is searched for or even allocated forming a migrated row. It means, that the ROWID value remains the same, but inside the block, an additional reference to another block is present. As a result, in the first part, the data block, to which the ROWID points is memory loaded followed by getting another block, where the data resist. Thus, two blocks are loaded, instead of just one. Generally, data can be migrated multiple times, resulting in the performance drop caused by the huge amount of I/O operations. Although the index can be rebuilt even online, it does not provide sufficient power due to the problem of dynamic changes across the data themselves [
33].
In the relational database systems, various types of indexes can be present, like B+tree, bitmap, function-based, reserved, hash, etc. [
1,
34]. The specific category covers string indexing and full-text options. Temporal and spatial indexes have the common index types, however, almost all of them are based on the B+tree indexing, which is also the default option, as well. B+tree index structure is a balanced tree consisting of the root and internal nodes sorting data in a balanced manner. In the leaf layer, there are values of indexed data themselves, as well as ROWID pointers. Individual nodes are interconnected, thus the data are sorted in the leaf layer across the index set. To locate the data, index traversing is done using the indexed set resulting in either obtaining all data portions needed or by obtaining ROWID values, by which the other data attributes can be loaded easily (executing Table Access by Index ROWID (TaIR) method. Reflecting the data integrity, it is always ensured, that any data change is present in the index after the transaction approval. There is, however, one extra limitation associated with the undefined values. They are commonly modeled by using NULL notation, which does not require additional disc storage capacity. Whereas NULL values cannot be mathematically compared and sorted, NULL values are not indexed, at all [
24,
35,
36]. Although the database statistics cover the amount of the undefined values for the attribute, they do not reflect the current situation, just the situation during the statistics were obtained, thus they cover mostly background for the decision making in terms of the estimation. Management of the undefined values inside the index is currently solved by the three streams. The first solution is based on the default values, which replace the values, which are not specified [
4,
26]. The problem causes just the situation when the NULL value is specified explicitly. In that case, the default value cannot be used. The complex solution can be provided by the triggers [
6], replacing undefined values. From the performance point of view, there are two limitations, first of all, it is associated with the trigger firing necessary, which must occur for each operation. In the temporal environment, where a huge data stream is present, it can cause significant delays and reliability issues. Second, default values are physically stored in the database, thus it has additional storage capacity demands. Finally, undefined values can origin from various circumstances, thus undefined values can be represented by the numerous default values expressing e.g., undefined value, delayed value, inconsistent value, non-reliable value, the value of the data type range, etc.
Function-based index removes the impact of the additional storage demands, on the other hand, there is still the necessity to transform the value regarding the reasoning resulting in non-reliable data if the categorization cannot be done. Therefore, the solution extends the attribute specification defining the reason and representation of undefined value. From the point of view of the physical solution, we finally come to the interpretation of default values [
6] with no benefit.
Regarding the limitation of the existing solution, we propose another representation in this paper. Our proposed solution is based on the model of undefined value management covered in the index. The core solution is defined by our research covered in the MDPI
Sensors journal [
28]. It deals with various circumstances and models for dealing with undefined values. Several experiments are present, dealing with temporal, as well as spatial databases. Principles are based on adding a pre-indexing layer used as the filter. If the undefined value is located, its pointer is added to the NULL module connected to the root element of the index. Thus, the original index dealing just with valid defined data is still present, but undefined values can be located from the root, as well. The data structure for the NULL module representation was first defined as a linear linked list with no sorting, which brought the performance improvements in the Insert operation, whereas there was no balancing necessity, on the other hand, such data would be necessary to totally scan. In the next step, therefore, the module representation was replaced by the B+tree, in which the data were sorted in an either temporal or spatial manner. The final solution was based on the spatio-temporal dimensions formed by two-pointer stitched indexes, the first is temporally based, the second reflects the associated region, thus not the data positions are indexed, just the reference to the particular region. Another solution was based on the region of temporal dimension partitioning.
4.1. The Proposed Solution—NULL Value Origin Representation
The limitation of the already proposed definitions is just based on the NULL value notation. It is clear, that there are no additional size demands, however, there is a strict limitation of the representation. We, therefore, developed another solution proposed in this paper as an extension of the current solutions. As stated, the undefined value can be physically associated with the various circumstances, like delayed value, improper value, the value provided by the compromised network, etc. There is therefore inevitable to distinguish the reason, undefined value itself is not feasible. The architectural solution reflecting the model is the same in comparison with [
28], thus the second level indexing for the temporality (first dimension) and spatiality (second dimension) is used. For this solution, undefined values are also categorized based on origin. Categories can be user-defined, or automatic segmentation can be used. To create a new category for the undefinition, the following command can be used. The name of the database object must be unique among the users. It is associated with the treating condition specified similarly as the Where clause of the Select statement is defined. Multiple conditions can be present for the representation, delimited by the AND and OR connections. Moreover, the same condition can be used in multiple definitions, as well. In that case, the undefined value is categorized by multiple types and present in the index not only once. Physically, it is modeled by using ROWID pointers, thus the object itself is used only once, but several addresses (similar to the standard indexing) can point to that:
For dealing with the delayed data caused by the network, the following notation can be used:
For dealing with the delayed data caused by the database system interpretation, the following notation can be used:
The definitions are stored in the data dictionary—null_representation prefixed by the user (only objects created by the current user), all (created by the user or granted to him), or dba (covering all definitions across the database instance). They can be granted to multiple users via grant command:
After the NULL representation creation, the definition is put to the data dictionary, so they can be associated with the defined tables, respectively, attributes or the whole database can be used. The whole representation model unioning the set is used, thus, if the representation is defined for the whole table, it is automatically granted to each attribute, which can hold undefined value. Moreover, the definitions can be extended by the attribute reflection, as well. It is done by the following syntax:
-- for dealing with the table
-- for dealing with the attribute
-- for dealing with the user
Note, that if the username is not defined in the last command, the current user executing the code is used, by default.
Figure 9 shows the proposed architecture consisting of three core internal elements. The Management handler is responsible for associating NULL representation, to interconnect undefined value categories (NULL_representation) stored in the data dictionary with table data by the definition. Any used category is created as the separate elements in the memory, (NULL_representation memory pointer layer) to which individual data can be directed. The second internal element is just the Index module storing the whole data set (even NULL values are there, in the separate storage segment in B+tree index stitching by the three layers—spatial, temporal, categorical). The categorical definition is based on the pointers to the NULL_representation memory pointer layer, by which the type and origin of the undefined value are present. If any change on the NULL_representation, either in the data dictionary or the table association is done, the Management handler becomes responsible for the change to apply it to the whole structure. Data input stream layer (Data change module) is the input gate for the data changes, it is modeled by the separate module, where the pre-processing, filtering, and other reliability and consistency operations can be executed. Data retrieval is done straightforwardly from the Index module, as well as the database itself. The architecture of the solution is in
Figure 9. Core internal elements are gray colored. External modules are either represented by the database itself or by the data dictionary object. Green part represents database and external systems, to which the result set is provided. Dotted arrow separates the data dictionary from the instance itself.
4.2. Proposed Solution—Master Index Extension & Partitioning
When dealing with index structures, various access methods can be used to locate data. Index Unique scan (IUS) is used if the condition reflects the unique constraint by using an equality sign. If the multiple values can be produced, either as the result of the range condition or by using the non-unique index, the Index Range scan (IRS) method is used, naturally, if the order of the attributes in the index and reflecting the query is suitable. There are also many other methods, like Full Scan based on the fact that the data are already sorted in the leaf layer, so the ordering is not necessary to be performed, Fast Full scan, where all suitable data are in the index, however, the attribute order forming index is not suitable, thus the index is scanned fully. The specific access path is defined by the Skip Scan, which can be preferred if the query lacks the leading attribute of the index. It is based on the index in index architecture for the composite definition [
16]. As stated, if the index is not suitable or even if there is no index covering the conditions, at all (e.g., supervised by the function call), the whole data block set associated with the table must be searched by executing the Table Access Full method. It can have many severe limitations and constraints, mostly if there is a fragmentation present if the associated block amount is higher in comparison with current real demands. All of these factors have significant performance limitations. The Master index was firstly defined in [
24]. It uses the index just as the data locators. Generally, any index structure can be used, holding any data. By using the proposed techniques covering NULL values inside the index, any index type can be used. The spirit of the Master index is to locate data by extracting the block identifier from the ROWID values in the leaf layer. Thanks to that, just relevant data blocks are accessed. Migrated rows are secured, as well, although the ROWID pointers are not used to address them, however, there is a pointer inside the block, which is associated with the index itself, thus the security and whole data frame can be accessed forming a reliability layer. If at least one record is pointed to the block, it is completely loaded and the whole block is scanned for either data themselves or for locating migrated rows. It removes the limitation of the memory Buffer cache problem covered in [
9]. Specific index structure can be used, as well, based on the B+tree data structure, however, it points only to the data block, not the direct row position. Leaf layer automatically removes the duplicate pointers by sorting the data based on the index set, as well as pointers. A proposed solution dealing with NULL can be used, as well, individual categories are used in the separate module, in which the block definition pointers can be used, as well. The architecture of the Master indexing extended by the NULL pointer module categorization is in
Figure 10. Communication interconnection of the modules is black colored, data flow in individual phases is shown green. The processing consists of several phases. The first phase represents the query definition and its representation in the database system. Server process of the instance memory is contacted (first phase), where the syntactic and semantic check is done. In the second phase, the existing index set is processed to identify a suitable index to access the data. The third phase represents the decision. If the suitable index to cover the query exists, processing is shifted to the fourth phase, the particular index is used and result set is created. Vice versa, if there is no suitable index to serve the query, the Master index module is contacted to select the most suitable index. Such index is used for the relevant blocks holding data extraction in the fifth phase.
Partitioning enhances the performance, manageability, and availability of a wide variety of applications. It is useful in reducing the total costs of the ownerships and storage demands if a large amount of data across the temporal and spatial sphere is present. It allows you to divide tables, indexes, and index-organized tables respectively into smaller pieces, enabling you to manage these objects at a finer level of the accessing and granularity itself. When dealing with the data access using the proposed stitching architecture leveling data to the temporality, spatial dimension, and undefined value categorization, partitioning can provide a significant performance benefit. Generally, data reflecting the continuous time frame is required, thus particular data are either in the same partition fragment, or the neighborhood is contacted. Similarly, positional data are obtained by the same region. The partitioned model differentiates individual values into the partitions based on the data indexes, the supervising background process Partition_manager is launched, which is responsible for the changes and overall architecture. Note, that each data portion can be part of just one partition in the same level, except the undefined values themselves. As stated, by using the null_representation object, the undefined value can be categorized into several types, resulting in placing the object into multiple partitions. For ensuring performance, the undefined value is determined just by one state represented to the memory module, thus it does not impact performance, at all.
4.3. Complex Solution—Autoindexing and Post-Indexing
In [
37], the concept of autoindexing is proposed. It is based on the autonomous evaluation of the individual queries, by analyzing statistics, impacts, with emphasis on the current index set. The principle is based on the invisible and virtual indexes analyzing benefits and costs, if dropped [
38]. The aim is to balance the existing index set to provide robust and fast access to the data during the retrieval process, but it takes emphasis on the destructive DML operations (Insert, Update, and Delete) as well. Our defined solution covering undefined values, a master index, and partitioning can form the core part of the autoindexing, as well, mostly in cases of dynamic queries and dynamic data changes over time. By extending autoindexing with the proposed methods, just peaks during the evaluation can be dropped, whereas the Table Access Full method can be replaced by the Master index, undefined values are part of the index in the separate layer interconnected with the root element. Thanks to that, a complex environment can be created. A complete overview of the architecture is in
Figure 11. The current index list is present for the optimizer evaluation. Indexes are enhanced by the modules representing undefined values by the categories, which can evolve. The Master index is responsible for limiting the TAF method, thus the data fragmentation does not bring any limitation, at all, whereas empty blocks are automatically cut from the processing by using block identifiers (BLOCKID) extraction. As present in the experiment section, all the modules can bring additional performance power, creating a complex environment covering data access to the physical location. In
Figure 11, there is also a module dealing with post-indexing. The purple part of the figure expresses the database statistics obtained from the database and index set. It is the crucial part, whereas without non-current statistics, reliable performance cannot be ensured. The green part shows the autoindexing module. The autoindexing process is interconnected with the optimizer and DB statistics. It uses internal Query evaluation costs/benefit module responsible for creating and removing existing indexes (black arrow between index set and Query evaluation costs/benefit module. Blue part represents the post-indexing process modeled by the Notice list structure and the Post-indexing process itself. The dotted arrows represent the data flow and interconnection. Post-indexing process regularly (or based on the trigger) checks the Notice list and applies the changes by the balancing. It is connected to the optimizer.
Transactions must deal with the logging to ensure ACID properties ensuring durability after the failure, but the aspect of the consistency and ability to rollback transaction is inevitable for the processing, as well. Data themselves are operated in the second phase, which covers the index management, as well. If any indexed object state is modified, change must be reflected in the index. Otherwise, the index set would be non-reliable and unusable in the result. Post-indexing is another architecture improving the performance of the destructive DML. B+tree index is namely always balanced, thus any change requires balancing operations, which can be remanding and form a performance bottleneck. In the post-indexing architecture layer, index balancing is extracted into the separate transaction supervised by the Index_balancer background process. In that case, individual changes are placed into the Index Notice list. Thanks to that, the transaction itself can be confirmed sooner. Although the balancing operation is extracted, it is done almost immediately. Moreover, it benefits from the fact, that changes done by the same objects can be grouped and operated together, although they originate from multiple transactions. Thanks to that, in total, performance benefits, multiple operations are applied to the index during one operation, followed by the balancing. Thus, balancing is not done for each change, they are bulked. Vice versa, data retrieval operations must deal not only with the index itself, but the Notice list must also be scanned, as well, to create a consistent valid object.
Figure 12 shows the process of data retrieval. Note, that it can be done in parallel.
5. Data Retrieval
The Select statement is considered to be the most important and most frequently used SQL statement, which is used to select records from the database, either from just one or more tables or views, respectively. The basic conventional syntax of the Select command consists of six parts—Select, From, Where, Group by, Having, and Order by [
1,
4]:
| [CREATE TABLE table_name AS] |
| SELECT [ALL|DISTINCT|UNIQUE] |
| {*|attribute_name|function_name[(parameters)]} [,...] |
| FROM table_name [table_alias] [...] |
| [WHERE condition_definition] |
| [GROUP BY column_list [function_list]] |
| [HAVING agg_function_conditions] |
| [ORDER BY column_list [function_list] [ASC|DESC] [,...]] |
Proposed Select Statement Definition
The temporal extension of the Select statement brings an important aspect of performance. It is a cross-cutting solution of all temporal models and is based on the temporal database paradigm, which requires that user perspective and result approaches to be the same, regardless of the physical internal architecture. The proposed solution extends the definition by the following clauses:
This definition extends the Where clause of the Select statement, specifying the time range of data processed and retrieved, either in the form of a precise time instant (defined_timepoint) or a time interval (defined_interval), the definition of which contains two-time values—the start (BD) and end point (ED) of the interval. In the session or instance respectively, it is possible to set the type of interval (closed-closed, closed-open representation), but the user can also redefine the set access directly for a specific Select command. The second (optional) parameter is therefore the interval type used (CC—closed-closed, CO—closed-open). Note, that current database systems offer period definition by the name notation, it can be used, as well. It that case, the clause uses only one parameter, whereas the period data type always reflects CC representation:
defined_timepoint (t)
defined_interval (t1, t2, [CC|CO])
defined_interval (period_def)
The output manages individual validity intervals, if at least one timepoint is part of the defined time frame, particular state is present in the result set.
Figure 13 shows the representation and usage of the CC input validity interval (expressed by the period data type physically). Note, that the database states do not need to pass the CC interval definition, thus they are automatically transformed, by using Allen relationships and transformation principles [
6].
Figure 14 shows the similar solution dealing with CO validity time frame. Specific type of the interval is denoted just by one timepoint. The following code shows the transformation of principles to the existing syntax, BD, ED express the inner database values, t1 and t2 represent validity intervals inside the Select statement definition:
| defined_timepoint(t) | where BD ≤ t AND t ≤ ED | CC internally |
| defined_timepoint(t) | where BD ≤ t AND t < ED | CO internally |
| defined_interval(t1,t2, CC) | where BD ≤ t2 AND ED ≥ t1 | CC internally |
| defined_interval(t1,t2, CC) | where BD ≤ t2 AND ED > t1 | CO internally |
| defined_interval(t1,t2, CO) | where BD < t2 AND ED ≥ t1 | CC internally |
| defined_interval(t1,t2, CO) | where BD < t2 AND ED > t1 | CO internally |
| defined_interval(period_def) | where BD ≤ t2 AND ED ≥ t1 | CC internally |
| defined_interval(periof_def) | where BD ≤ t2 AND ED > t1 | CO internally |
When dealing with the spatio-temporal model, it is inevitable to cover the positional data and categorize them into the defined bucket set. When dealing with data retrieval, it is important to emphasize data correctness, relevance, and measurement precision. Missing data can be usually calculated by the neighborhood data positions, however, it is always necessary to mark such values and distinguish the measured data set from the assumed or calculated, respectively. Spatial_positions clause allows you to define an either polygon, which will delimit the data positions or radius. In this case, the data measurement frequency and precision are significant, whereas the data stream is not continuous, thus the object can be placed in the defined region just in a small term, however, such data should be placed in the result set, as well, to compose complex and reliable output. As stated in the previous chapter, the whole data map can be divided into several non-overlapping regions, which definition can be part of the proposed clause, as well.
Spatial_positions (polymon_def)
Spatial_positions (latitude_val, longitude_val, radius_val)
Spatial_positions (region_def)
Definition of the region can be done for the whole database, user, or table association.
For the evaluation, the precision level can be specified holding the following options:
Precision_level:
only measured data,
measured and calculated (estimated) data,
fuzzy classification of the assignment defined by the function.
Another relevant factor is delimited by the time duration (time_assignment), during which the object was part of the defined region, polygon, or point with radius delimitation, respectively. This clause can be extended by the optional parameter dealing with the time duration using Interval data type—Interval Day to Second (syntax is shown in
Figure 15) or Interval Year to Month (syntax shown in
Figure 16) [
39]:
The complex definition of the Spatial_positions clause is defined by the following structure. Note, that the data assignment to the defined region is different from the event_definition clause, in principle. In this case, namely, assignment granularity is used with the reflection to the spatial positions, whereas the event_definition deals with the whole time range of the data to be obtained:
The purpose of the Transaction_reliability clause is to manage and retrieve individual versions of object states over time. The required architecture is bi-temporal, resp. a multi-temporal system that allows you to define, modify, and correct existing states using transactional validity. So it is not only the validity itself that is monitored, the emphasis is also on the versions and later data corrections. In principle, any change to an existing situation must result in the termination of its transactional validity. The new transaction validity is expressed by the transaction itself, its beginning is identical with the beginning of the transaction, the end of validity is unlimited because it is assumed that the inserted state is correct—we do not consider its correction at the time.
The transaction validity uses the so-called historical temporal system, from the point of view of transactions, it is possible to work only with the current validity and validity in the past (historical versions of states that were later changed). From a logical point of view, it is not important to define a change in the reliability of the state in the future (detected changes and version corrections must be applied immediately). Because states can be corrected, the Select command must have the option to delimit the specific version that the user wants to obtain. The proposed Transaction_reliability clause addresses the issue of versions concerning transaction time. Either a time point, time interval, or period can be defined.
Transaction_rel_timepoint(t)
Transaction_rel_interval(t1, t2, [CC|CO])
Transaction_rel_interval(period_def)
Time frame principles remain the same as defined for event_definition clause, however, the processed time frame is not valid, but the transaction reliability or transaction definition perspective, respectively.
When dealing with the data modeling over time, the particular data model can be changed, individual constraints can be added, edited, or terminated, as well as the data structure and individual attribute set can evolve. To cover the data model definition, based on the problem specification and solution proposal in this paper, we introduce the following options. Model_reflection clause can hold either value AS-WAS, which forces the data result set to cover the conditions, as they existed in the time of the particular object state validity, which can be, however, later changed. AS-IS option looks at the data structure as it is currently expressed with the reflection on the validity of the given state of the object. AS-WILL-BE is specific and can be associated only with the future valid state. Model transformation by the constraint evolution can be defined sooner before its real usability. If the AS-WILL-BE option is used, future valid states are reflected by the model valid in the future. If there is no model for the specified time frame, either exception is raised or the AS-IS model is used. The behavior depends on the future_strictness parameter, which can hold either TRUE value (forcing the system to cover only future valid data model) or FALSE, which replaces undefined future data model by the current definition (AS-IS). Note, that the FALSE option is used, by default.
During the data monitoring and evaluation, the efficiency of the processing must be taken into emphasis, as well. Mostly in highly dynamic systems, input values can be delayed in a temporal manner, which can impact the complexity, decision making, and overall reliability reflection of the system. In general, three temporal timestamp signatures are used for the evaluation. Sent_time reflects the time of data production, either by the different system, sensor layer, etc. Received_time is a specification of the timestamp signature when the data were placed in the input queue for processing. The time costs of the data transfer are then reported as the difference between the Received_time and Sent_time. Finally, Processed_time delimits the time of the data processing directly by the database system. The difference between the Processed_time and Sent_time is crucial for the database system itself, whereas it reflects the adequacy of architecture, approaches, and robustness of database processing. The aim is to minimize such value so that the received data are ideally processed immediately. The time difference is important for efficiency, reliability with emphasis on the frequency of changes.
Optional time aspect definition can be covered by the signature of the transaction approval, which is relevant mostly in the systems containing long transactions. Just after reaching transaction commit (approval), processed data are widespread and can be used by any other session, respectively transaction. The time point of the transaction approval is denoted by the Transaction_approve_time.
The specification is based on adding additional flags for each row in the data output set reflecting the consistency_model and processing or transferring delays.
For monitoring developments and changes over time, it is possible to define rules that affect the size of the result set. Epsilon_definition is a determination of how insignificant changes can be filtered out, especially in sensory data. Each monitored temporal attribute can have a defined minimum value of the extent of a significant change—the value of Epsilon (ɛ). If the difference between two consecutive values of a given attribute is less than the value of the parameter defined for the corresponding temporal attribute, then this change will not appear in the resulting set returned by the Select statement. If this clause is not user-defined, the default value of the minimum change (ɛ = 0) will be used, in which case any change will be processed. To use this extension functionality, it is necessary to define a function that will map the values of non-numeric data types to numeric so that changes can be quantified. It is, therefore, necessary to define a mapping function for each data type (or use an implicit one), the input parameter of which is the value of the respective data type, the result is a numerical value (integer, float, longint, …). It can be managed on the temporal and spatial spheres. Note, that not only direct predecessor can be evaluated, the defined window can be used, as well. Epsilon_definition can be used for both the time and positional data:
Extending the Select statement with the Monitored_data_set clause allows you to define columns or synchronization groups in which changes need to be monitored and are relevant for further processing. The defined list does not have to be identical with the first part of the Select statement; in principle, it is possible to name any number of temporal attributes or groups of the given table, joined tables, or views, respectively. This part, unlike the first part of the Select statement definition, cannot contain non-temporal columns or function calls. Any change on the defined element forces the system to point state to the result set. Such property can be, however, too strict, resulting in providing a huge amount of data. Therefore, it is possible to extend the definition of the access approach for each element determined by the column itself, or composed from the group definition. As stated, by default, any change detection fires a new state to the output. Optional parameter extending each element determines the firing principles. The second parameter specifies the minimum number of attributes in the associated set that must change their values for such a changed state to be considered significant. This variable is specified for each element separately, if the value is not defined, the default used value representation is 1. The parameter can take any positive value, even greater than the number of attributes in the element. In this case, the entire set must be changed for the state to be considered important and directed to the output set of the Select statement. The syntax of the proposed solution is following. It is not necessary to differentiate the group and attribute itself, whereas each attribute can be considered as one element group set.
The magnitude of the change may not always be an appropriate tool for representing the importance of change, relevance, or suitability. In the spatio-temporal environment, it may be appropriate to define a “trigger” by which the resulting change will be assessed. In the Monitored_data_set clause, we propose a clause extension, allowing you to specify a condition that must result in a bivalent value representing the status. Multiple conditions can be presently interconnected by the AND and OR evaluation.
The Type_of_granularity clause is placed in the proposed syntax extension after the Having clause, it is a way of formatting the result set. It defines the sensitivity and detail of displaying changes. It can take four values: OBJECT—defines granularity at the object level, it displays objects that have been changed in a defined time period. Thus, a projection of the times in which the complex state of the object has been changed is obtained—the value of at least one temporal attribute was changed. The changed values of temporal attributes of objects are obtained by setting the processing level to the type COLUMN, respectively GROUP. The difference is that the GROUP option allows you to aggregate multiple attributes into a common evaluation. In principle, the solution using the COLUMN option is a subset of the GROUP type—each attribute is a one-element set of the GROUP type. The CHANGES_MONITORING access mode displays comprehensive information about the change—a specific attribute (A
1) as well as the original value (HA
11) and the new value (HA
12)—
Figure 17.
Previous section deals with the undefined value categorization present in the index structure. It is modeled by the memory structure, to which individual segments of the index point. During the data retrieval, these values can be robustly obtained from the defined index. The NULL value itself does not have specific meaning and origin expression, therefore in the NULL_category can clause, you can specify the undefined value representation and categorization. You can enable or disable managing individual undefined value types in the result set by calling NULL_category clause parametrized by the name of the category, to which the index segment points. Note, that the name of the NULL_category is present in the null_representation data dictionary.
Syntax extension and clauses availability in a complex manner is the following:
| [CREATE TABLE table_name AS] |
| SELECT [ALL|DISTINCT|UNIQUE] |
| {*|attribute_name| function_name[(parameters)]} [,...] |
| FROM table_name [table_alias] [,...] |
| [WHERE condition_definition] |
| [EVENT_DEFINITION] |
| [SPATIAL_POSITIONS] |
| [TRANSACTION_RELIABILITY] |
| [MODEL_REFLECTION] |
| [CONSISTENCY_MODEL] |
| [EPSILON_DEFINITION] |
| [MONITORED_DATA_SET] |
| [GROUP BY column_list [function_list]] |
| [HAVING agg_function_conditions] |
| [TYPE_OF_GRANULARITY] |
| [NULL_CATEGORY] |
| [ORDER BY column_list [function_list,ASC|DESC] [,...]] |
6. Performance Evaluation
Performance characteristics have been obtained by using the Oracle 19c database system based on the relational platform. For the evaluation, a table monitoring 100 drivers was used, each row was delimited by the composite primary key—identification of the driver (driver_id) and spatio-temporal spheres (location_def, time_def). In the first phase, just data based on the smartphone sensors were used (5 sensors we used monitoring speed of the vehicle, eye-blinking, concentration, noise, and the number of people in the car). Data (5 sensors (s)) were obtained three times per minute (f) for 100 drivers (d) during three hours a day (t) (covering the transport to the office and back + going to the standard daily shops) monitored during one month—twenty working days (m). Thus, the total data amount in the table was (value of the t is expressed in minutes):
The total amount of the data in the table was 5.4 million. The main index was defined just for the driver and time-positional data definition, 10% of rows were delimited by at least partial undefinition (three categories were used for the undefinition). No other indexes were developed, therefore this main index was used for the Flower index approach as the Master index.
Experiment results were provided using Oracle Database 19c Enterprise Edition Release 19.3.0.0.0—64bit Production. Parameters of the used computer are:
Processor: Intel Xeon E5620; 2.4 GHz (8 cores),
Operation memory: 48 GB DDR 1333 MHz
Disk storage capacity: 1000 GB (SSD).
To evaluate the performance, two approaches were used as the referencing. Model TAF does not deal with undefined values in the index definition, thus sequential scanning is necessary to be executed during the data retrieval. The second referential model can be named Model DEF, by which undefined values are transformed into the default values in the preprocessing layer outside the database. Thus, it is always ensured, that real data are present in the database, undefined values are modeled by using default value transformation. As evident from the results, it has additional demands on the disc storage. Data evaluation is more complicated, as well, whereas the default value has to be replaced during the result set composition and transport to the client.
A computational study dealing with the performance reflects processing costs delimited by the time demand aspect.
As stated, the environment deals with data 5 sensors providing data for 100 drivers during three hours. In this evaluation experiment, 2 sensors were time-synchronized. In case of any Update operation, the random number of sensor values is changed, ranging from 2 to 4. This part deals with the temporal architecture with an emphasis on the processed granularity. Model Model_obj is delimited by the object architecture capturing the whole sensor image occurring during any Update statement. Model_column manages just separate sensors regardless of the synchronization of the 2 sensors. As evident, in this case, each changed attribute forces the system to load one extra row into the temporal layer. Model_group benefits from the synchronization group, which is defined and maintained automatically, based on the structure of the changes. If the group is changed, instead of managing individual sensors separately, data_val definition is used consisting of 2 physical sensor data, however, only one row for the whole group was inserted into the main temporal level. As evident, it proposes significant benefit during the Insert or Update statements, as well as during the data retrieval, whereas the result set should contain only actually changed values. Finally, model Model_group_ext is evaluated, which is based on synchronization based on the temporal data, as well as the positional data. In our case, we divide GPS data into 8 regions characterizing the map of our country. Note, that 10% of data portions are undefined, categorized into the 3 types randomly. Temporal, as well as spatial positions, can be undefined, thus such data are not indexed, by default.
Figure 18 shows the results of dealing with the data structure. To cover the complexity and reflection of the architecture, individual results are expressed in percentage. Based on the reached results, the most demanding architecture from the database structure point of view is the object architecture, which consists of several duplicates, if the attribute value is not changed. Therefore, we propose an additional model called Model_obj_imp, which does not store the original values multiple times, just the undefined value is used to handle it. In that case, the NULL categorization is extended by one element expressing data change. The limitation is just the necessity to evaluate the direct predecessor of the state to identify real change, which is not, however, size demanding. Column level architecture uses a preprocessing layer dividing the state into individual attributes. In that case, processing size demands are lowered to 46%. Attributes, which are not changed, are not stored in the new state, at all. Processing uses attribute granularity. Group solution separates individual attributes into the synchronization group, which is managed always as one module defined by the data_val value. Thanks to that, the number of requests to the temporal table is lowered. The total size demands are lowered to the value 38. In comparison with Model_obj, it reflects improvement using 62%. Comparing to the column architecture, it provides an 8% benefit in size demands. Model_group is based on temporality. Extending the model by the spatial positions is introduced in the model Model_group_ext. Individual data are categorized into 8 regions, which can be managed separately. In that case, processing demands in terms of the size are lowered to the value 34%, lowering the demands from 38 to 34% dealing with the group architecture. The benefit is based on the spatio-temporal categorization, thus the data can be obtained from the spatial, as well as temporal perspective. If internal partitioning is used, demands are almost the same, however, data retrieval is more straightforward, processing itself can be parallelized done on the internal partitions.
Figure 18 shows the size demands.
Data retrieval process demands are based on the identification of the real change of the values. Thus, the most demanding architecture is Model_obj, in which individual rows must be sorted and compared to identify the change. If the data precision is not defined correctly, multiple phantoms can be present, which do not cover the changes, or vice versa, data values are considered as changed, which is not, however, true. Therefore, the reliability aspect is significantly inevitable in that solution. Column level architecture is optimal from the change identification requirement. Individual states are composed of the temporal layer directly. Group architecture is optimal regarding storage capacity. During data retrieval (changes monitoring), each group must be expanded into the individual column list, which requires additional 4% demands in comparison with column architecture. A slight benefit can be obtained by using spatio-temporality dealing with two layers grouping data separately. Thanks to that, the processing itself can be divided into the defined ranges formed by internal partitioning. Processing time demands are 40%. In comparison with object architecture, it lowers the demands using 60%, reflecting temporal group definition and spatio-temporal determination, it lowers the demands using 2%.
Figure 19 shows the results in the graphical form.
Different order of efficiency is obtained, if the whole data image should be provided, regardless of the changes themselves. During the defined time frame or spatial regions, respectively, the whole data image should be part of the result set. In object-level architecture, the whole data image is present there, so it can be directly provided. Thus, from the size demands, requirements are significantly high, however, when dealing with the whole data image, particular data are directly in the database with no necessity for state composition and calculation. On the other hand, there is a relevant demand for the data loading from the database into the instance memory Buffer cache.
Figure 20 shows the results. Reference model is Model_obj (100%). Improved model using object architecture dealing with the real change identification brings additional demands ranging 2%. The reason is based on the transformation necessary to the original form during the retrieval. It requires 10%, however, the demands are lowered using 8%, whereas the size of the structure is less, thus the number of blocks to be loaded is smaller. Attribute-oriented architecture, in comparison with object architecture, requires an additional 33%. The processing itself can be divided into two parts—object state composition from the individual attribute set—41% lowered by the block loading necessity—8%. Similar solutions are obtained by the group architecture, as well, additional necessity to decompose group is identified. Based on the results, it requires an additional 4 or 5%, respectively, in comparison with column granularity.
Figure 20 shows the results.
In conventional systems, individual changes are defined by the Update statement replacing the original state with the newer one. The new object is created by invoking the Insert statement. In a spatial environment, each object is delimited by the temporal scheme expressing validity, respectively of the period of occurrence. Thus, any change is physically modeled by the Insert statement, either in the case of adding a new state or the whole object definition, as well. This experiment aims to evaluate the demands of adding a new state into the database in terms of processing time. As defined, 5.4 million rows are present in the database after the operation by using various granularity levels. We compare the processing time to load the whole data set into the database with emphasis on the real change identification for the column level or synchronization detection used in group-level granularity. Each change is delimited by the separate transaction, data are logged and afterward stored in the database. No temporal consistency and model management is done, at all. Reference model is Model_obj (100%). If the same values are not stored physically, just the specific NULL category pointer is used, demands are 99% (Model_obj_imp). Physically, it requires additional demands in 7%, which is, however, lowered by the fewer size demands, whereas physically, the only pointer is used. By using column architecture, only real change is stored. In comparison with object architecture, a new row into the temporal layer is added only in the case of the real change. Object-level structure stores data values for each attribute. Column level architecture Insert statement demands are 64% in comparison with object architecture. When dealing with group management, demands can be lowered, slightly. Processing time value of the group architecture dealing with only time representation reflects 58%, spatial categorization into the regions 60%. It is the result of another processing layer and region management segmentation.
Figure 21 shows the results.
In the previous experiment, only a standardized conventional LAR approach was used. Particular data were logged and stored in the database based on the defined granularity. Data integrity, collisions, and model reflection were, however, not taken into emphasis. This section deals with the proposed rules TLAR and ETLAR referencing the current state of the art solution defined by the Log Ahead Rule. TLAR extends the definition by identifying and solving transaction rules to limit the overlapping states on the one object. Several rules can be applied to ensure consistency—a new valid state is either refused (REFUSE) or the validity of either the existing or new state is shortened (SHORTEN) or the states are moved in time (REPOSITION). This experiment evaluates the processing time demands or those three rules. The used architecture is group-oriented used as a reference model (100%). 20% of states to be added cause anomaly collision. If the REFUSE rule is used, the demands are even lowered, whereas the data themselves are not loaded into the database, only information about the temporal attempt to insert a new state is noticed. The SHORTEN rule is the most demanding, whereas the data themselves must be changed by locating existing and newly added rows. If the existing row must be updated, the total demands have risen to 109% reflecting the 9% of additional demands in comparison with the reference model LAR. In the newly inserted row, validity is changed, additional demands are 5%, whereas either begin point or end point of the validity must be shifted (shortened). In this criterion, defined states do not force the system to refuse the state completely, so there is only partial overlapping of the existing state. In this case, based on the data, we assume, that only one valid state is influenced. If multiple states are necessary to be evaluated, in general, approximately 0.5% for each state is added to the processing time demands. REPOSITION criterion influences the time positions, validity interval in terms of its length is not influenced, at all, however, the period placement into the timeline is enhanced. In that case, 3% of additional processing time costs are present, as the result of the placement identification. Similarly, we assume, that there is a collision with one state only. The ETLAR rule extends the previously defined criteria by covering the model relevance. If the particular model is not present, the newly added state can be either refused (ETLAR strict) or the current data model can be reflected (ETLAR ignore). Management of the integrity of the time-evolving data model and constraints require an additional 4% of the processing time, however, the consistency can be always ensured, no integrity constraint lacks can be later detected. In the case of using the Ignore option, additional demands are 6%, whereas the new state is always inserted with the specific flag regarding the particular model availability. Note, that by using the Strict rule, the state to be loaded can be refused completely, forcing the system not to insert data into the database, which has namely benefits in the disc operations.
Figure 22 shows the reached results for the 100 driver data sensor evaluation.
Undefined value management forms a crucial aspect limiting the performance and evaluation process. As stated, NULL values are not part of the B+index structure. Furthermore, it does not have a specific meaning. We cannot state in the temporal sphere, whether such event will be in the future or not, even whether such events have not occurred yet, particular states cannot be sorted, mathematically treated, and evaluated by the origin of a given undefined value. Therefore, this experiment covers the performance definition protected by undefined value management. The core architecture uses the group granularity evaluated in experiment 1 (Model_group). The environment solution deals with the three models. The reference model (
Model_no_null) is delimited by the pure spatio-temporal architecture, which cannot cover undefined values in the index structure, at all.
Model_null covers only undefined values in one category with no origin reflection. It does not have any storage demands, whereas such NULL values are not treated physically. By adding an external module associated with the index root node, NULL values can be placed in the structure and located by the index itself. The demands, in comparison with Model_no_null, are lowered to the value 72%, as the result of the undefined value accessibility by the index by replacing Table Access scanning necessity by the index approach managing data range. Thus, it uses the Index Range Scan method or Unique Scan, respectively, if the condition is based on a unique value set.
Model_null_cat reflects the memory structure NULL_representation as the pointer layer delimiting the meaning and origin of the undefined values. In this case, 3 categories for treating NULLs are used, however, based on the evaluation, it can be stated, that the number of categories has minimal impact on the performance. The difference is just the pointer destination, however, the size and principle reflection remains still the same. When dealing with the NULL categorization, reached performance results are 73% in comparison with Model_no_null. Comparing index structures dealing with undefined values inside the system (Model_null and Model_null_cat), there is only a slight performance difference, which is, however, fulfilled by obtaining more complex information regarding the undefined value origin and reliability of the data. If the Model_null is referential (treated as 100%), then the Model_null_cat requires additional power ranging 1.38%.
Figure 23 shows the results reflecting group granularity with various NULL management definition principles.
A specific feature of the spatio-temporal system is just the requirement for extremely fast and efficient processing. Input data are often obtained from sensory networks or systems themselves, where the emphasis is on the almost immediate processing with no delays. Data retrieval efficiency covered by the speed is a critical factor as the states of objects change dynamically. Experiment 6 focuses on the efficiency of obtaining data from the database, comprehensively monitors the process of identification and localization of individual object state records. It uses the modules defined in this paper, the benefits of which are evaluated in the retrieval process depending on their presence in the system. The first used module reflects the Epsilon definition covering just relevant data changes. We used the 0.1% threshold for shifting data into the database or reuse the original value, respectively. In principle, data are provided in the defined time frames, however, the input does not need to be stored in the database, if the significant change is not detected. In that case, the amount of data in the database is lowered with no impact on the data quality. Each data value is then extended by the 0.1% precision interval. The second module presence reference the Master indexing, which removes the impact of the whole table scanning, if no suitable index is used. In that case, block values are extracted from any suitable B+tree by scanning the leaf layer of the index. Master index selection used in this experiment was dynamic meaning, that the optimizer autonomously selects the best suitable index with minimal estimated costs reflected by the memory loading (I/O operations from the database), whole size, and costs of the scanning. Note, that the index must cover all data rows, otherwise it cannot be marked as Master. The third accessible module reflects NULL management directly in the index set. Thanks to the presence of this module, any index can be selected as Master. In this case, the existing index set does not been to be enhanced, but if the condition is based on the undefined or untrusted value, the existing index can be used, as well. By using the NULL management module, many times, the original index can be directly used with no necessity to block identification (BLOCKID) extraction. The fourth module uses range spatial partitioning using the defined regions. It follows the temporal data partitioning, as well, thus the data image valid at the defined timepoint or interval is placed in the same data partition, thus the evaluation is easier and significantly less demanding, whereas the number of searched data is minimized. Moreover, if the data interval is spread across multiple partitions, the background process launches more workers to process the data in parallel. Afterward, the result set is created by the unification of the sets (UNION ALL operation). The fifth module expresses the autoindexing option, by which the existing index set is dynamically analyzed, new indexes are created and removed autonomously with regards to the whole performance of the current states. By using the Master indexing module, peaks created by the autoindexing can be flattened. The reason is, that the autoindexing is just the reactive module based on the changed query types. Moreover, the index must be built to be usable, which demands additional processing time and system sources. If the system is so dynamic with really various query types evolving rapidly over the time, the autoindexing module does not even provide benefits, whereas the costs of the index set handling can be higher in comparison with the total contribution. In this case, based on the number of uses of the given index (provided by the statistics), the system evaluates that the benefit of the autoindexing module is minimal and is automatically deallocated. At the same time, however, the system is monitored and, if the benefits exceed the costs, it switches on automatically. The last module is post-indexing, which extracts the index balancing operation into a separate transaction. Thanks to that, a particular Insert operation can be ended sooner by reaching the transaction Commit earlier. Thus, the data are produced for the environment by lowering the processing delays.
Figure 24 shows the architecture with the relevance of the individual modules. The experiment uses the assumption, that all preceding modules are present in the system. Thus, by introducing NULL management, Epsilon, and Master index modules are already there. Note, that index set consists of the spatial and temporal reflection only. There is no additional index present unless created by the autoindexing.
The reference model does not use any already defined modules (reference 100%). Reflecting the sensor-based data about the drivers defined in [
28] reflecting principles covered in [
40,
41,
42], Epsilon definition lowers the processing time demands to 87%. Evaluation is done in the preprocessing layer of the database system, individual background processes are contacted only if it reflects the relevant change. Master index extension requires only 81%. Its benefit is based on the fragmentation, which is present at 10%, of which 3% of the blocks are empty. Migrated row problem is not present, whereas there are not physical updates. NULL management module significantly improves the performance, first of all, the index can be always used, whereas pointers to the whole relevant data are there, secondly, the Master index portfolio set can be extended, as well, any index can be marked as Master. NULL module extension limits the demands to the value of 69% if there is no specific categorization of the NULL values. If the 3-type categorization is present, the demands are 73%. One way or another, there is always a 10% demand drop. Spatio-temporal partitioning, as stated, allows the process of data in parallel. Spatiality is covered by 8 regions. It requires 55%, which is mostly caused by parallel processing followed by the result set unification. Autoindexing module covers only 4% benefit in comparison with the already defined modules. Based on the analysis, there is no significant space for improvement. Master index and NULL management modules ensure, that the whole table scanning, block by block, is not executed at all. Vice versa, adding a new index dynamically benefits only if the query type set is relatively static, otherwise, the whole module is disabled, it cannot predict the future queries to handle indexes. The main advantage of the post-indexing is the extraction of the B+tree index balancing directly during the main processing. Thus, when dealing with data changes, the solution benefits. Vice versa, during the data retrieval process, it cannot be ensured, that all changes are already applied to the indexes, thus the evaluation must be two-phase—the index itself is evaluated and scanned to find relevant data directly or ROWID or BLOCKID, respectively. As stated, it does not need to cover all changed data, therefore the Notice list must be checked and relevant changes extracted. The total demands are 54% if the autoindexing is enabled. If it is disabled, it requires 57%.
Figure 25 shows the results in the graphical form.
Data retrieval is a complex staged process, each stage influences the performance. In principle, any incorrect decision done on any layer cannot be corrected later. The first level covers architecture. In this paper, we deal with sensor data management operated to monitor driver activity, over time forming temporal architecture. Based on the defined environment and 5.4 million rows, it is evident, that the data changes are not always present for each attribute synchronously. If the heterogeneity of the specification is present, the problem can be even deeper, whereas some data portions do not change their values at all forming the code list principles. Another problem is correlated with the data, which do not need to be monitored over time. Thus, in any environment, where such prerequisites are present, the proposed solution is relevant. Based on the results, the size of the whole structure can be reduced up to 66% for the group extension architecture. The data retrieval process can significantly benefit, as well, whereas the change identification is directly evident for the attribute (column) or group granularity. Reflecting the performance and environment, demands are lowered using 63% for attribute and 61% for the group, which is reflected by the group decomposition necessity.
Undefined values form another complex problem, whereas they are not located in the index structures. For data retrieval, therefore, sequential data block scanning is necessary to be done. By using proposed NULL modules and categorization, processing demands in terms of time can be lowered up to 27% or 28%, respectively. Finally, complex architecture is evaluated covering all the proposed segments summarized in
Figure 24. The usage of the proposed solutions can be found in almost any environment necessary to monitor sensor data over time. In the industry environment, the individual manufacturing process needs to be monitored by the sensors, which produce relevant data with various granularity and precision. If the measured data value is provided with delay and the sensor is broken or the communication channel fails, even temporarily, undefined values are produced, which must be handled with care. The proposed solution can be, similarly, used for traffic monitoring, for the positional data processing of the vehicles, or flight efficiency and position monitoring. Area of patient monitoring can benefit by using the proposed architecture, as well. In this paper, moreover, data retrieval extension clauses are proposed, by which the user experience benefits. The process of the data to be obtained is significantly simplified. The following paragraph shows the benefit of the proposed solutions. The first example deals with the Epsilon management, only rows, that express the change above 1% that will be part of the result set. In the existing syntax, it is necessary to use the flowing window frame to obtain the previous value of the sensor particular for the object. Note, that it cannot be done directly, thus the nested Select statement needs to be used. Moreover, if the window does not reflect only the direct predecessor, a more complex solution must be specified. The second code shows the usage of the Epsilon clause definition, which simplifies the specification, however, the performance is the same:
| Select object, BD, value |
| From |
| (Select object, BD, value, |
| lag(value, 1<=offset, null<=default) |
| over(partition by object order by BD) as predecessor |
| From data_tab) |
| Where abs(value, predecessor)>1; |
By using proposed Select statement definition, the same results are obtained:
| Select object, BD, value |
| From data_tab |
| Where Epsilon_definition(value, 1); |
The following code shows the statement to monitor the vehicle in the Slovakia region during the year 2020 by monitoring delays. Whereas several new road segments were opened, as well as some existing are closed due to the reconstruction, current Model_reflection is used. Monitoring is specified by the Monitored_data_set clause, namely, driver and road properties are monitored.
| Select driver_data, road_parameters |
| From data_tab |
| Where Defined_interval(year(2020)) |
| And Epsilon_definition(road_parameters, 1%) |
| And Monitored_data_set(road_parameters) |
| And Model_reflection(AS-IS) |
| And Type_of_granularity(group(driver) as driver_data, |
| group(road) as road_parameters); |
Note, that without such clauses, really complicated script should be written.
Finally, there is an definition of driver route planning, thus the AS_WILL_BE model is reflected. Note, that without such clause, multiple tables across models should be necessary to be joined together, forming the complex environment. The planned journey is for 1 June 2021, reflecting the current environment pointing to the undefined limitations—traffic jams, closures, and fog.
| Select driver_data, road_parameters |
| From data_tab |
| Where Defined_interval(1-june 2021) |
| And Epsilon_definition(road_parameters, 1%) |
| And Monitored_data_set(road_parameters) |
| And Model_reflection(AS-WILL-BE) |
| And Type_of_granularity(group(driver) as driver_data, |
| group(road) as road_parameters) |
| And NULL_category(traffic_jams, closures, fog); |
7. Conclusions and Future Work
The core element influencing the quality and usability of any information system is associated with the data, their correctness, reliability, and accessibility in an effective manner. Currently, it is inevitable to store not only current valid data, but the emphasis should be taken to the whole evolution over time. The temporal database approach forms a robust solution, treating the time delimited states of the objects. In this paper, we summarize existing approaches dealing with the data granularity—the object-level temporal system extending the definition by the validity time frame. Column level architecture deals with data monitoring using the attribute level. The interlayer between object and column architecture is covered by the synchronization groups. In this paper, we propose the extension of the group solution in a spatial manner categorizing data into the regions.
When dealing with the data, whole integrity aspects must be cared for. Data models and integrity rules can evolve over time, as well. Therefore, we propose an extended conventional Log Ahead Rule dealing with either data state collisions in a temporal manner (TLAR), whereas each object can be defined just by one valid state anytime or extended version (ETLAR) covering temporal collisions, as well as data model relevance. Thanks to that, complex integrity can be ensured. Such rules are performance evaluated, as well.
Undefined values originating from various circumstances can be present in the input data stream, as well. If the untrusted ad-hoc network is present, the problem can be even deeper. In this paper, we discuss the costs and benefits of undefined values. NULL representation is not physically placed in the database, thus it does not additional store demands. On the other hand, dealing with NULL proposes a significant performance problem by locating data. Generally, data are obtained by the indexes, which cover logarithmic complexity instead of linear by using the Table Access Full method scanning block by block sequentially. The most often index used in the relational platform is B+tree, which cannot, however, cover undefined values inside it. As the consequence, when dealing with undefined values, which are most likely present in the systems, the whole block set associated with the table must be scanned, resulting in poor performance. Note, that the data fragmentation can be present there, forcing the system to load the particular block with no relevant data into the memory for the evaluation. In this paper, a complex solution for managing undefined values directly inside the index is present. It is based on an additional structure connected to the root index element. NULL values can have several representations and meanings, therefore we propose undefined data value type categorization. In this paper, we propose the NULL_represenation data dictionary object and memory pointer layer interconnected with the index module. Thanks to that, the index can be always used, whereas all references are present there.
The benefit of this paper is covered in
Section 5, as well, covering the data retrieval process. No additional clauses dealing with the spatio-temporality are present, therefore we propose transformation clauses Event_definitions, Spatial_positions, Transaction_reliability, Model_reflection, Consistency_model, Epsilon_definition, and Monitored_data set operated in the Where condition of the Select statement. Type_of_granualarity and Null_category clause domains can be present in the Having clause, by which the output format can be treated. Evaluation of the proposed methods is divided into multiple experiments—impact granularity, transaction rules definition, indexing managing NULLs. The whole architecture is covered by experiment 6, which deals with the various modules, which are evaluated to emphasize the performance impacts. Namely, we are dealing with the Epsilon definition, Master indexing, NULL management, partitioning, autoindexing, and post-indexing, which extracts the index balancing method into the separate transaction supervised by the Index Balancer background process operated on the Notice list by applying individual changes into the index itself. Whereas multiple references to the index can be grouped and operated in a single balancing method, performance benefits. Whereas the changes to the index set are applied almost immediately, it does not have a significant impact on the data retrieval performance. Moreover, index and Notice lists can be treated in parallel followed by the unification.
In the future, we would like to extend the techniques to the data distributed environment, treating various index block size structures and tablespace locations. Data balancing over the networks, as well as data fragmentation and replication techniques in the spatio-temporal environment, will be covered by future research, as well.


{kind=link}
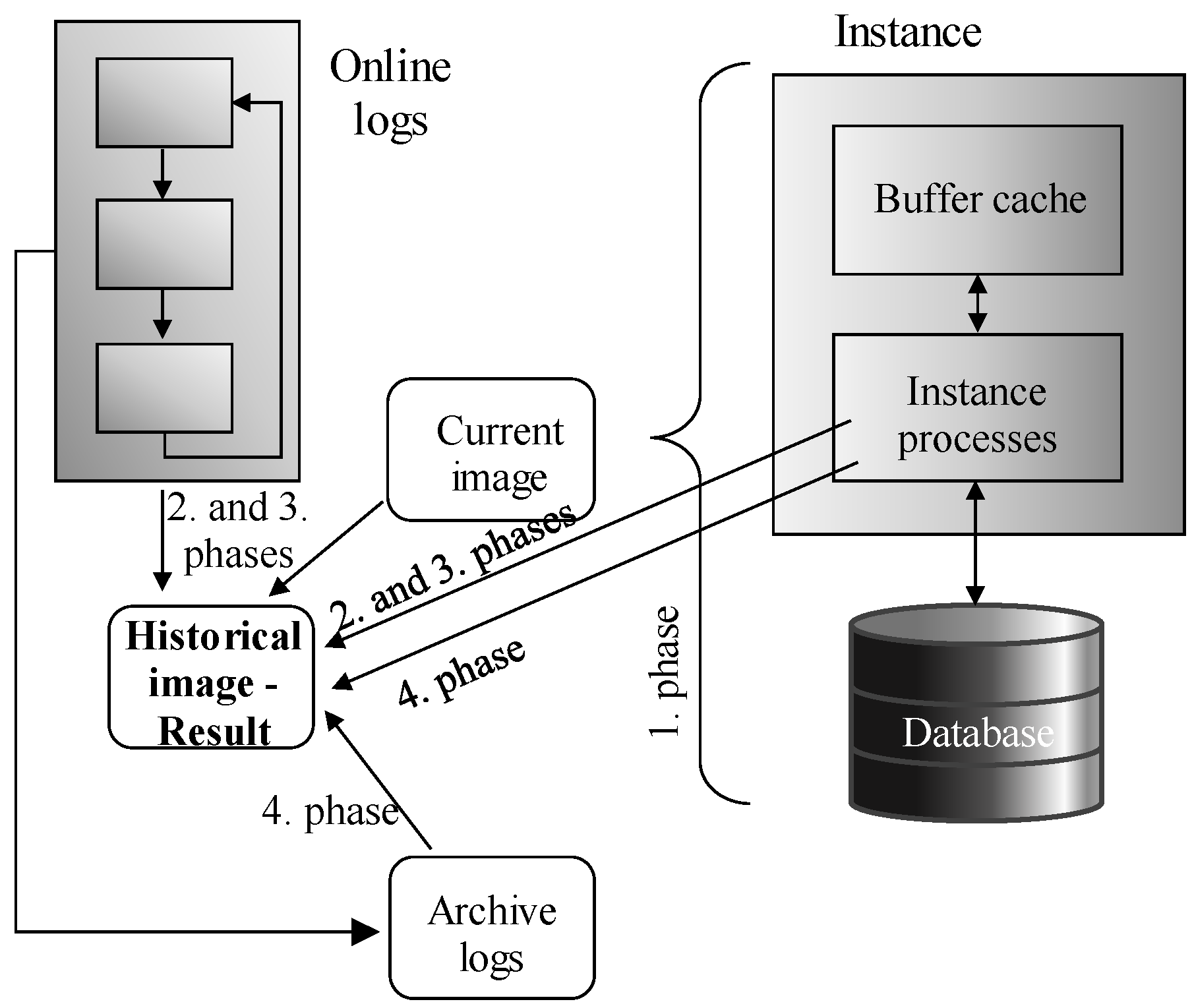{kind=link}
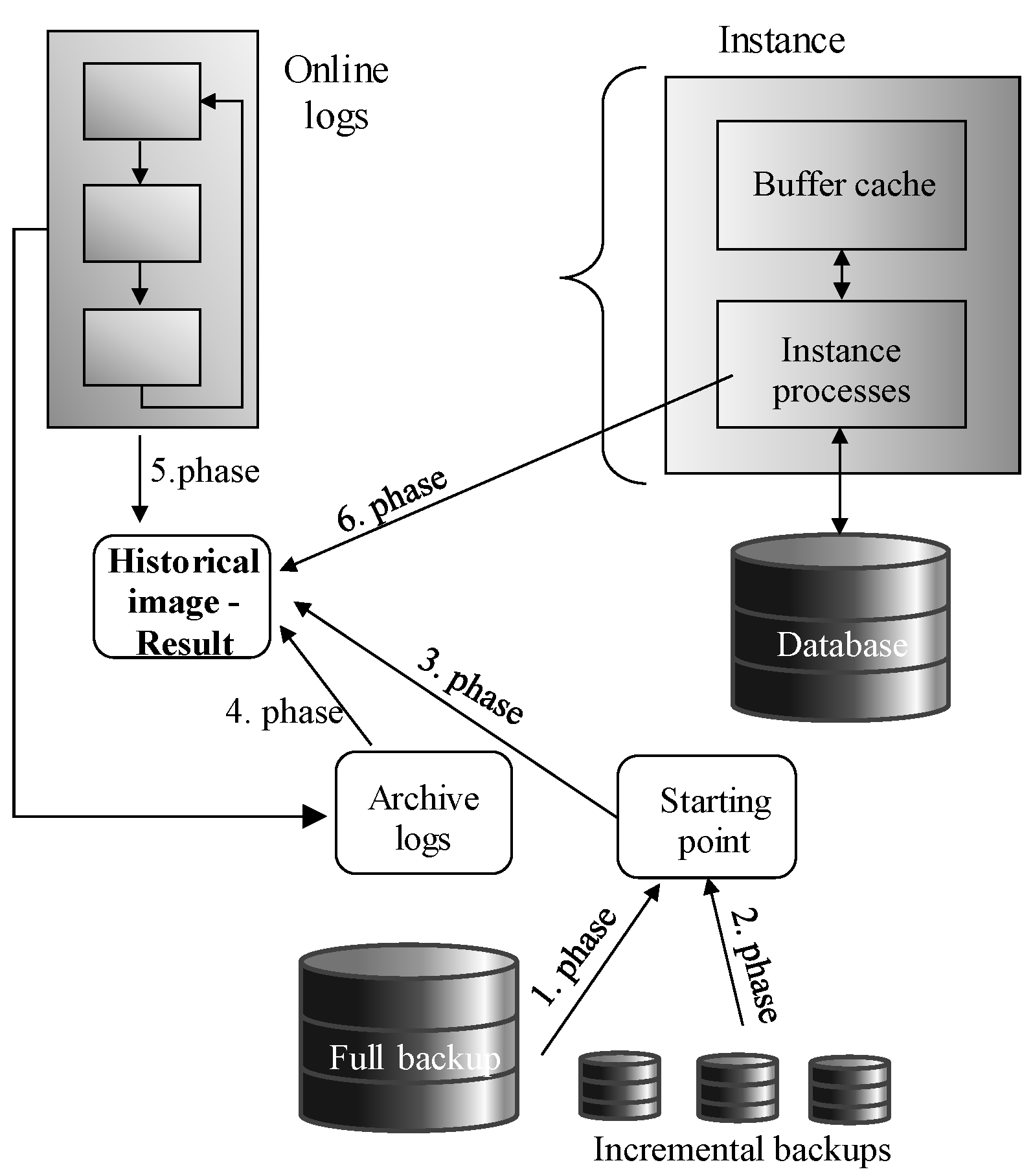{kind=link}
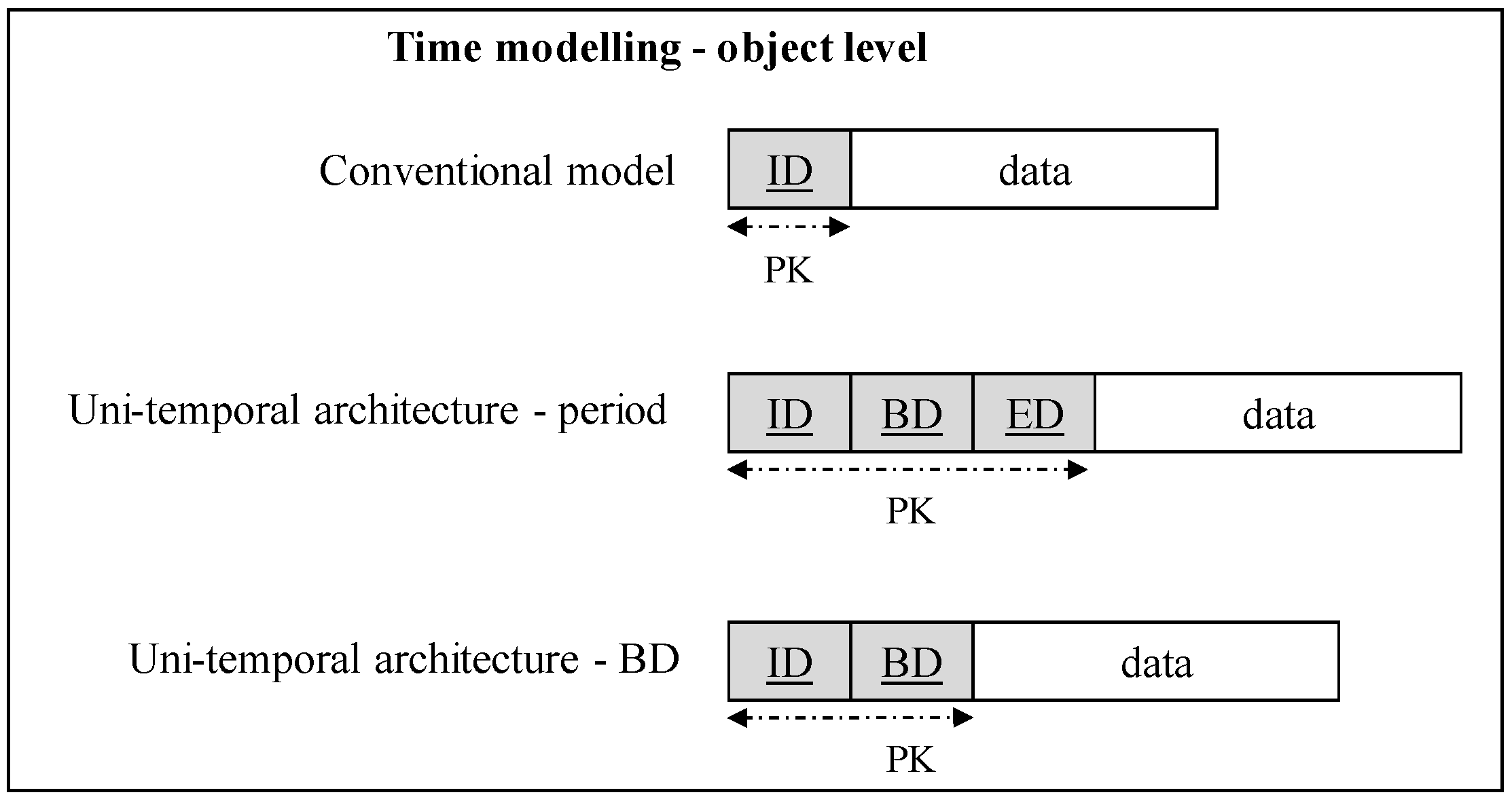{kind=link}
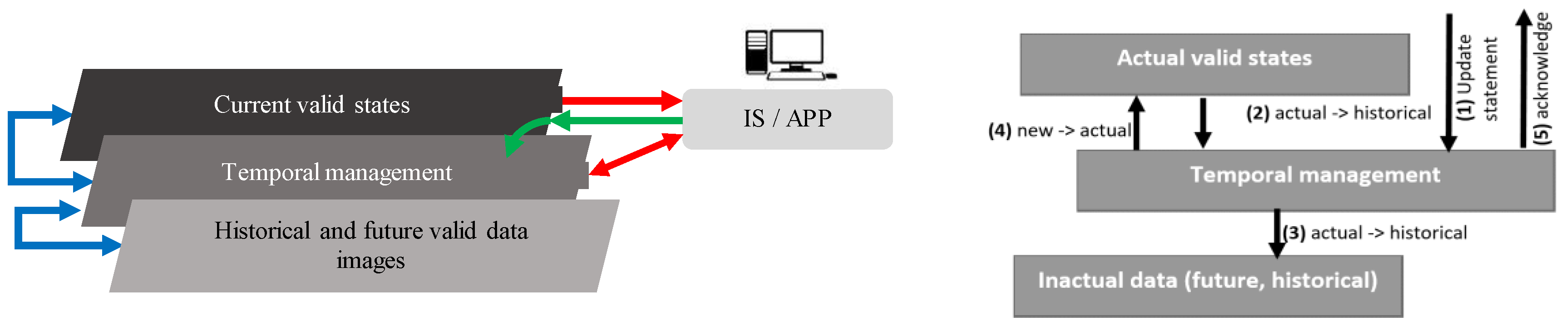{kind=link}
{kind=link}
{kind=link}
{kind=link}
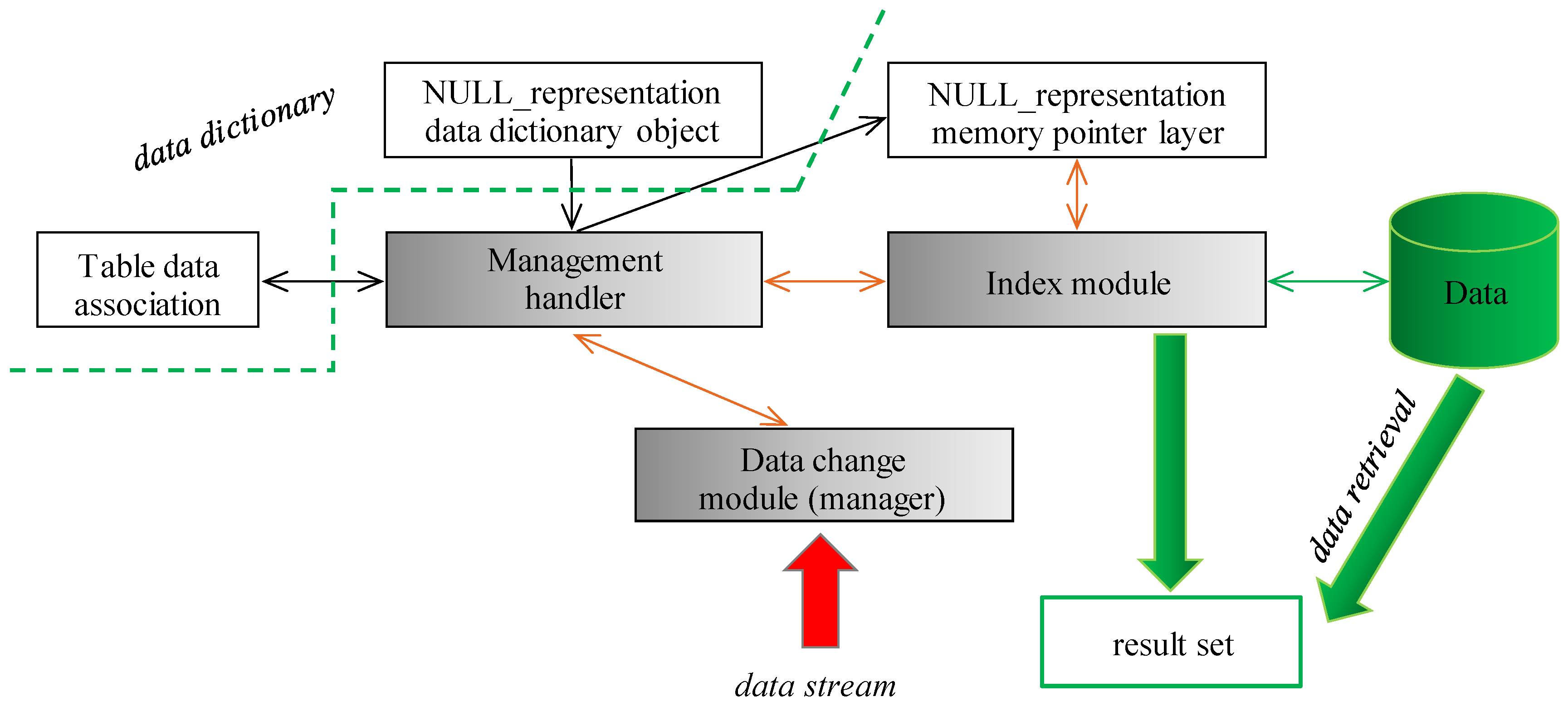{kind=link}
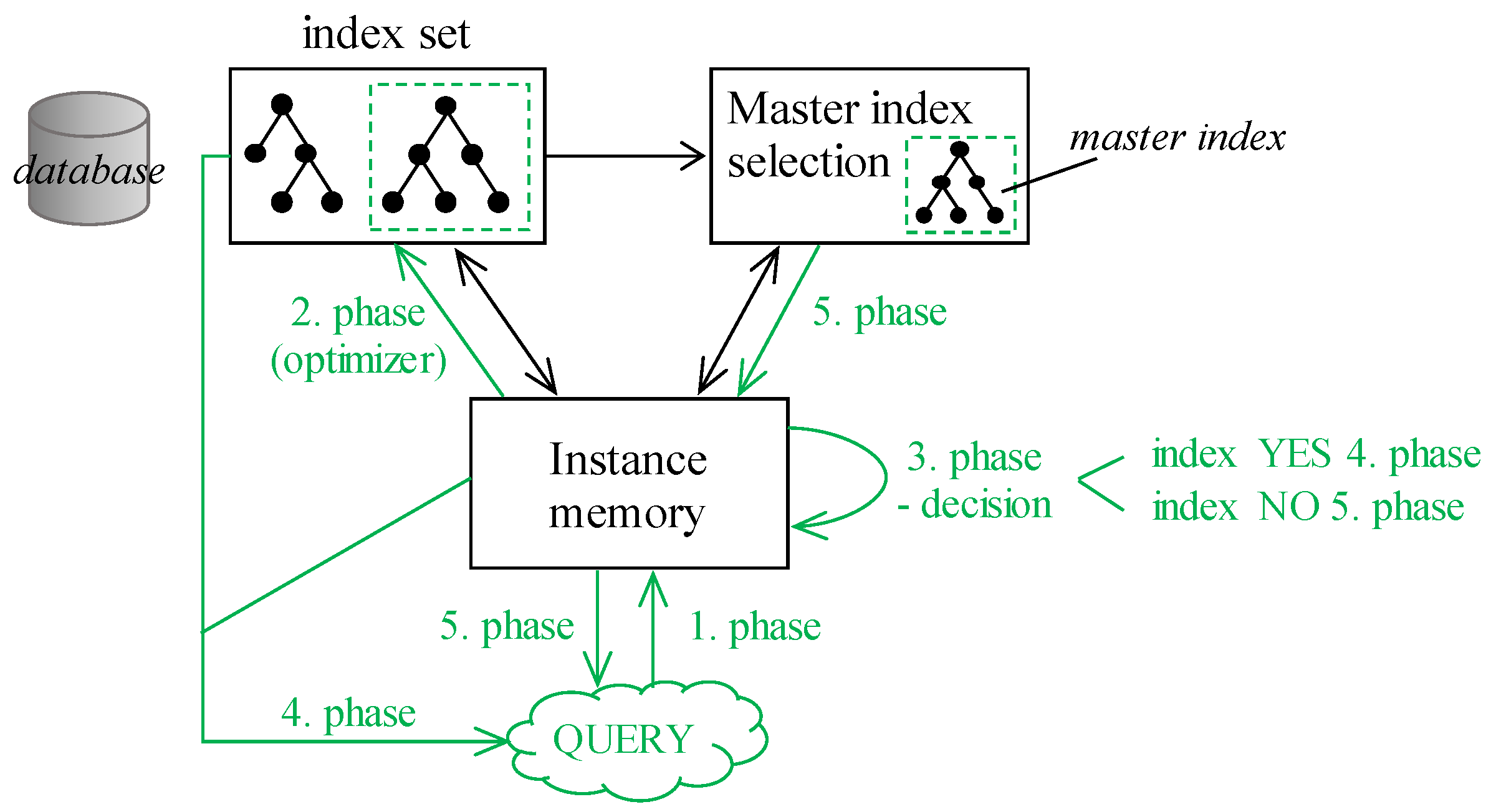{kind=link}
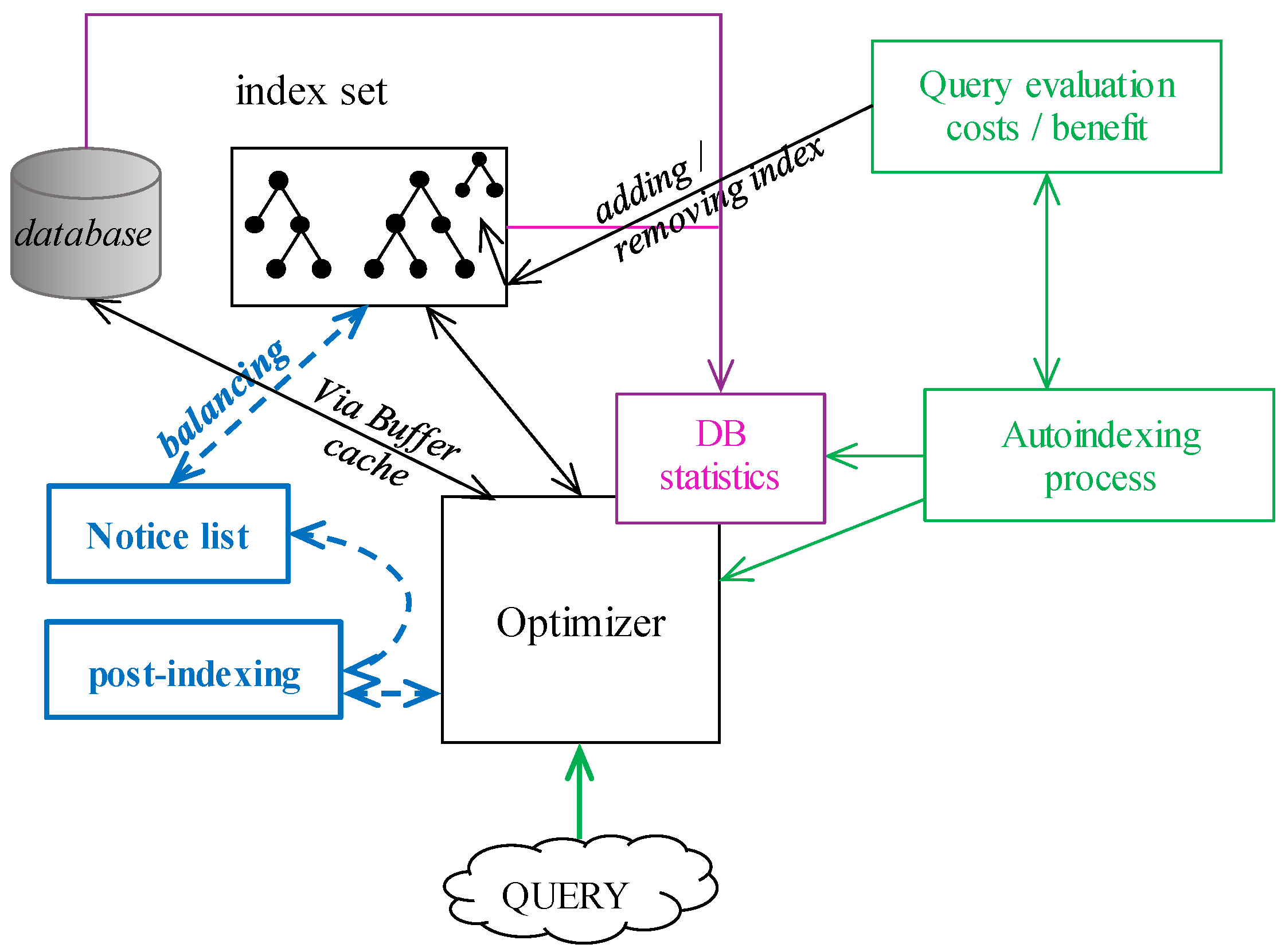{kind=link}
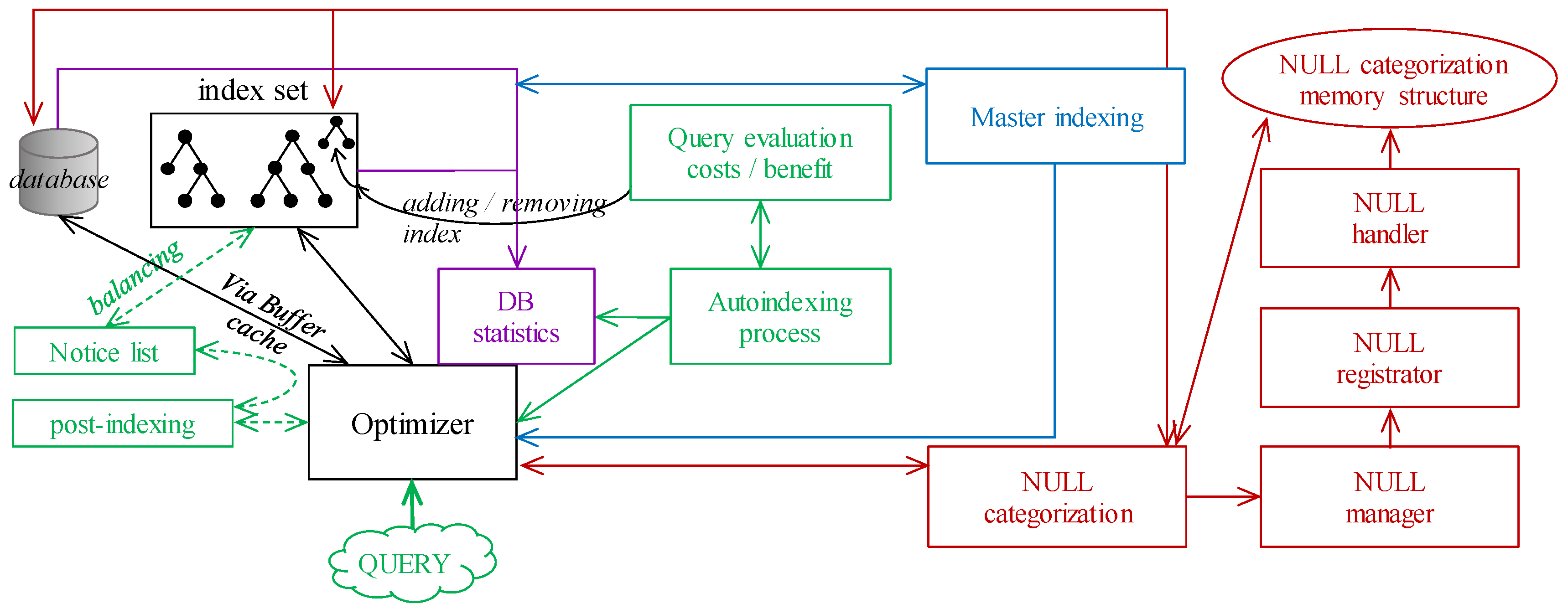{kind=link}
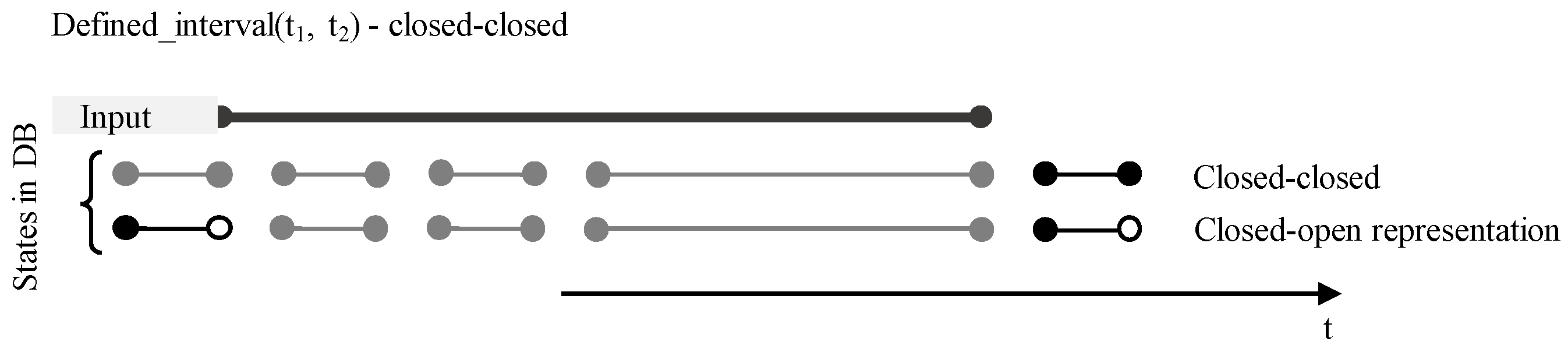{kind=link}
{kind=link}
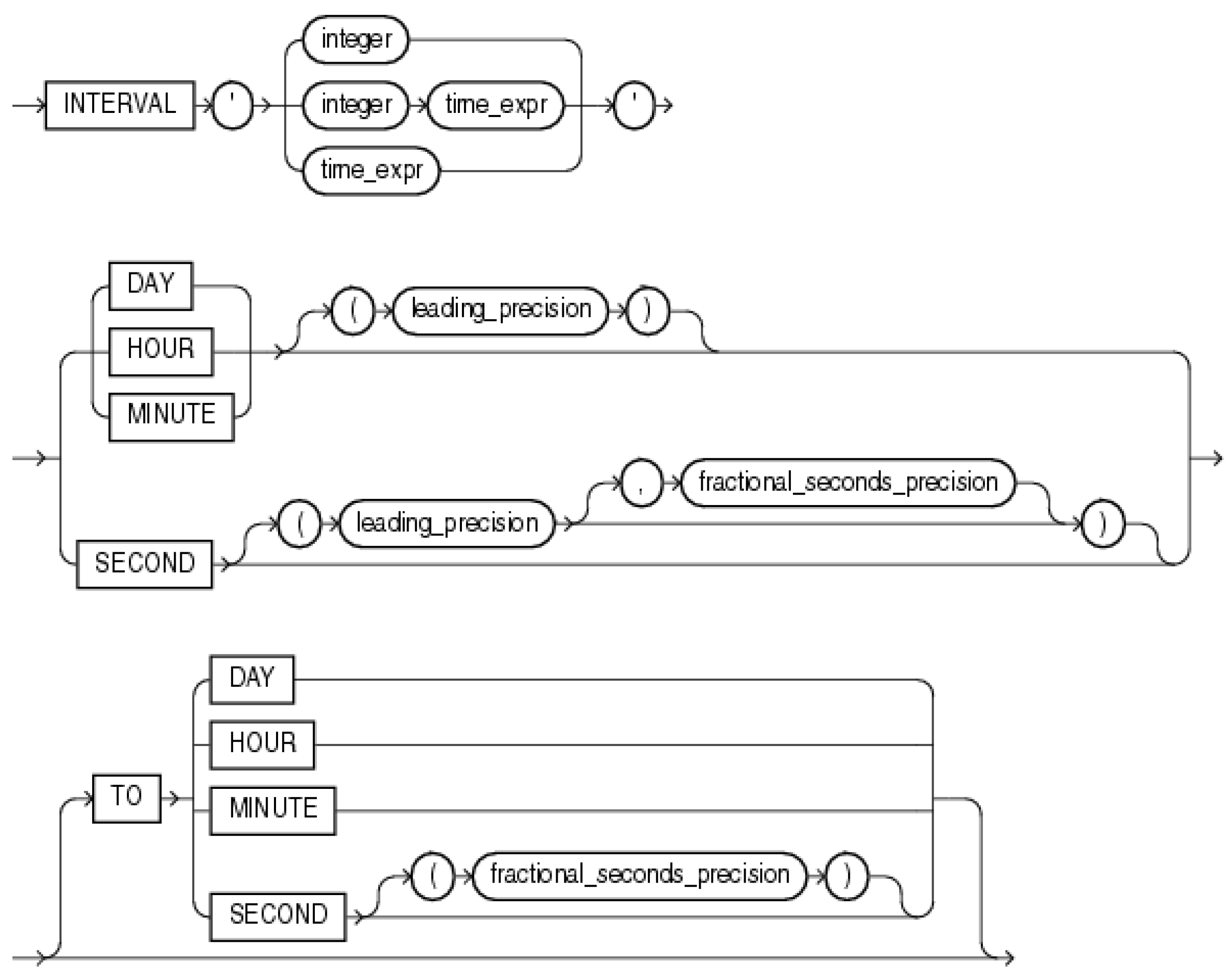{kind=link}
{kind=link}
{kind=link}
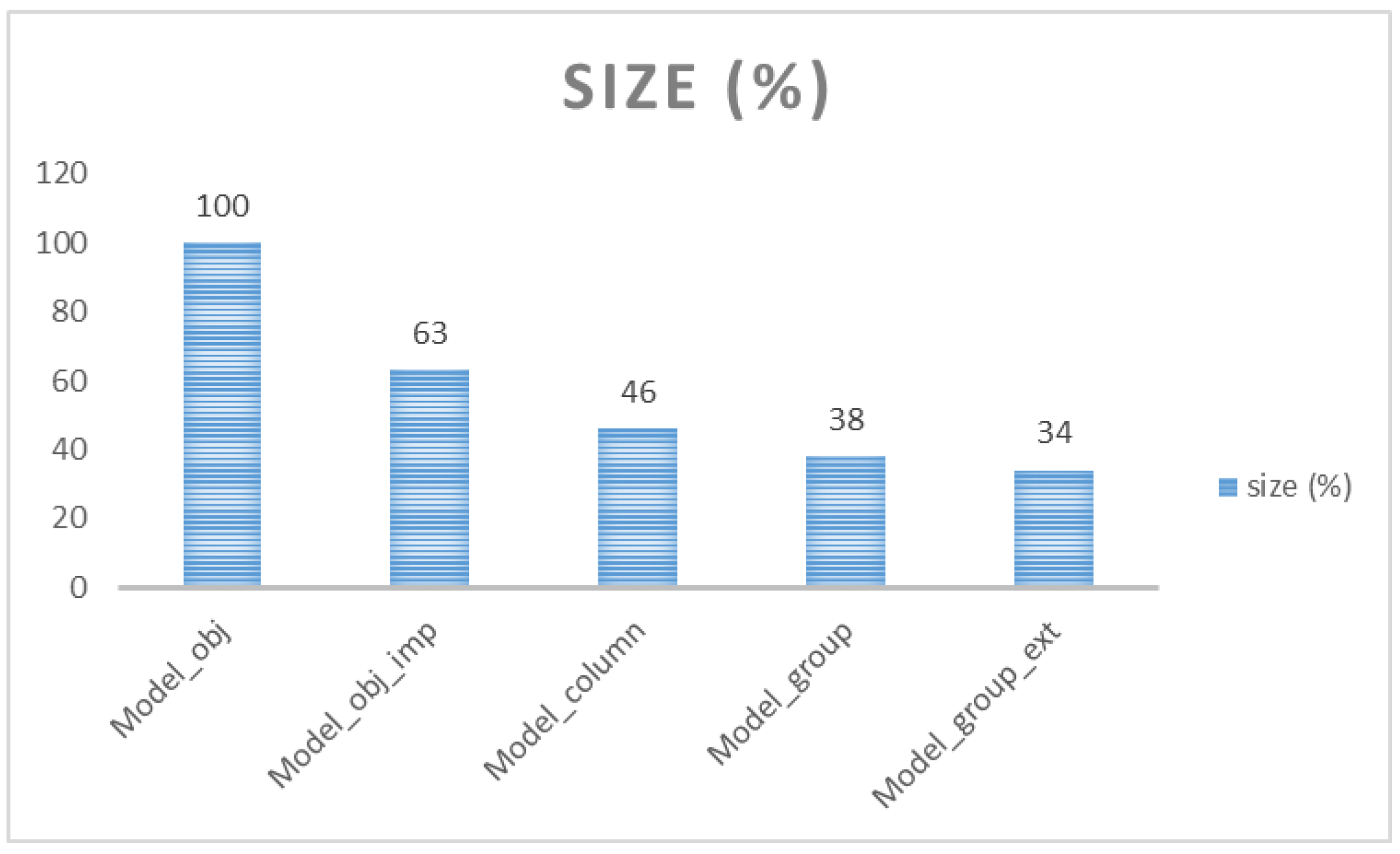{kind=link}
{kind=link}
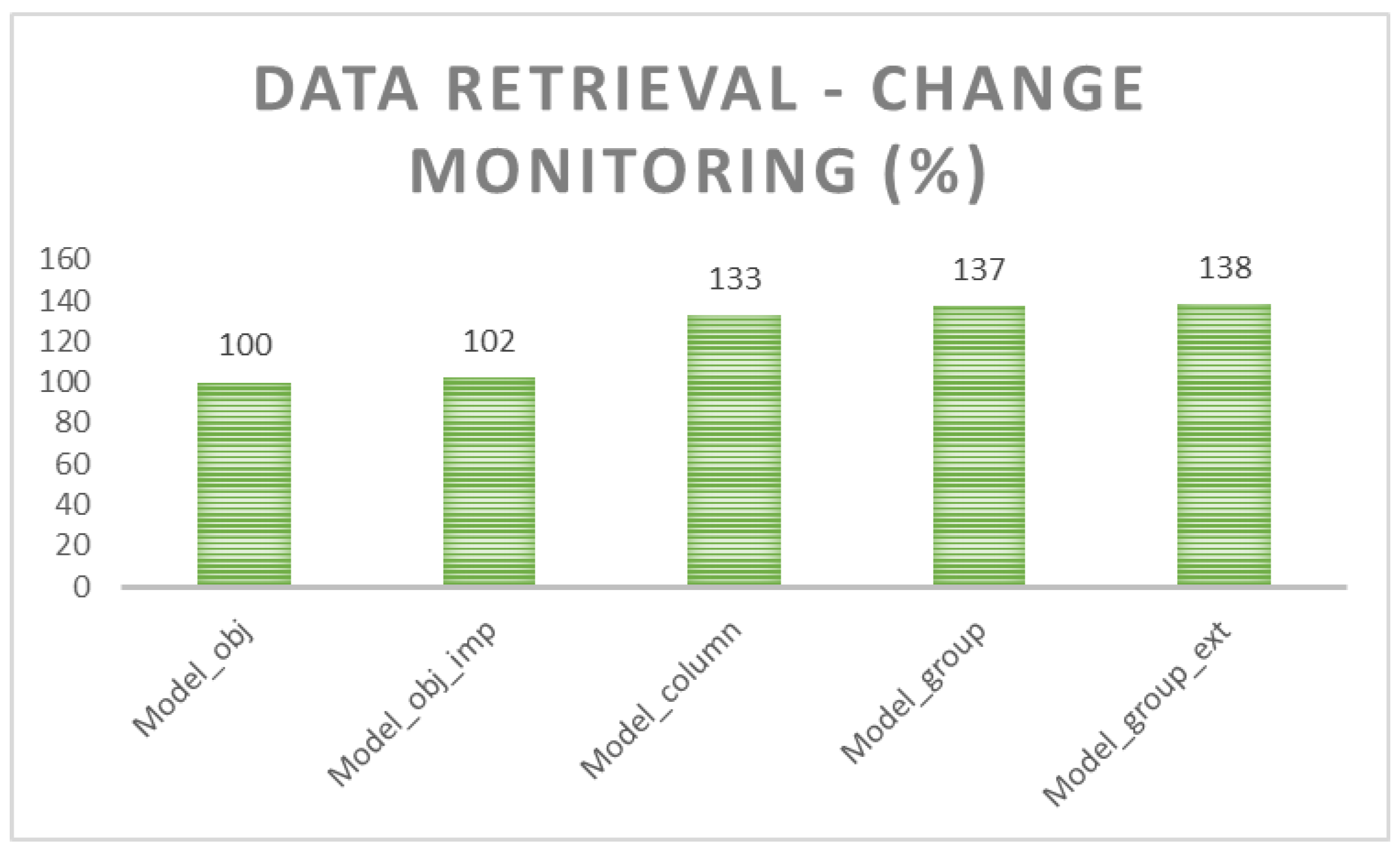{kind=link}
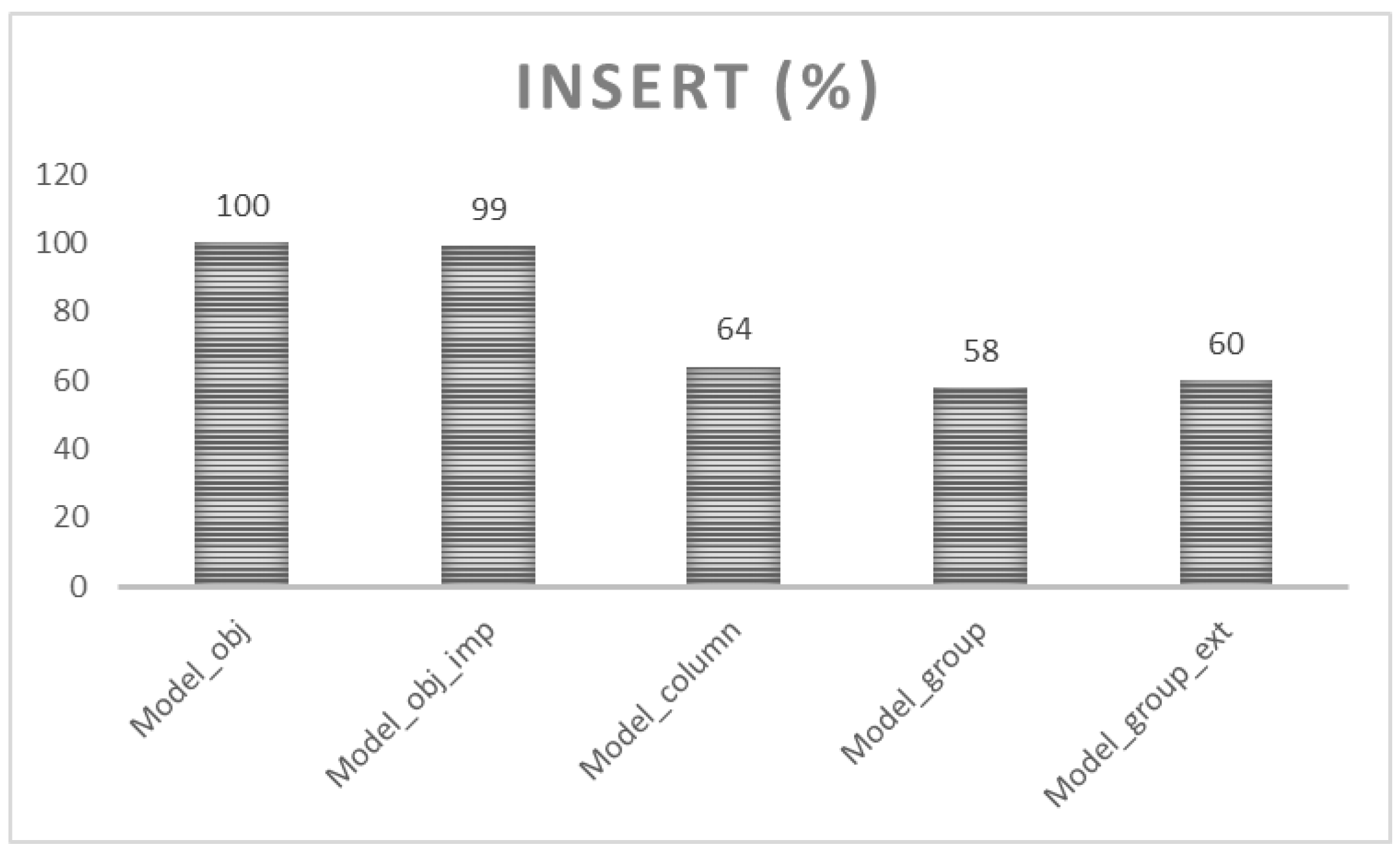{kind=link}
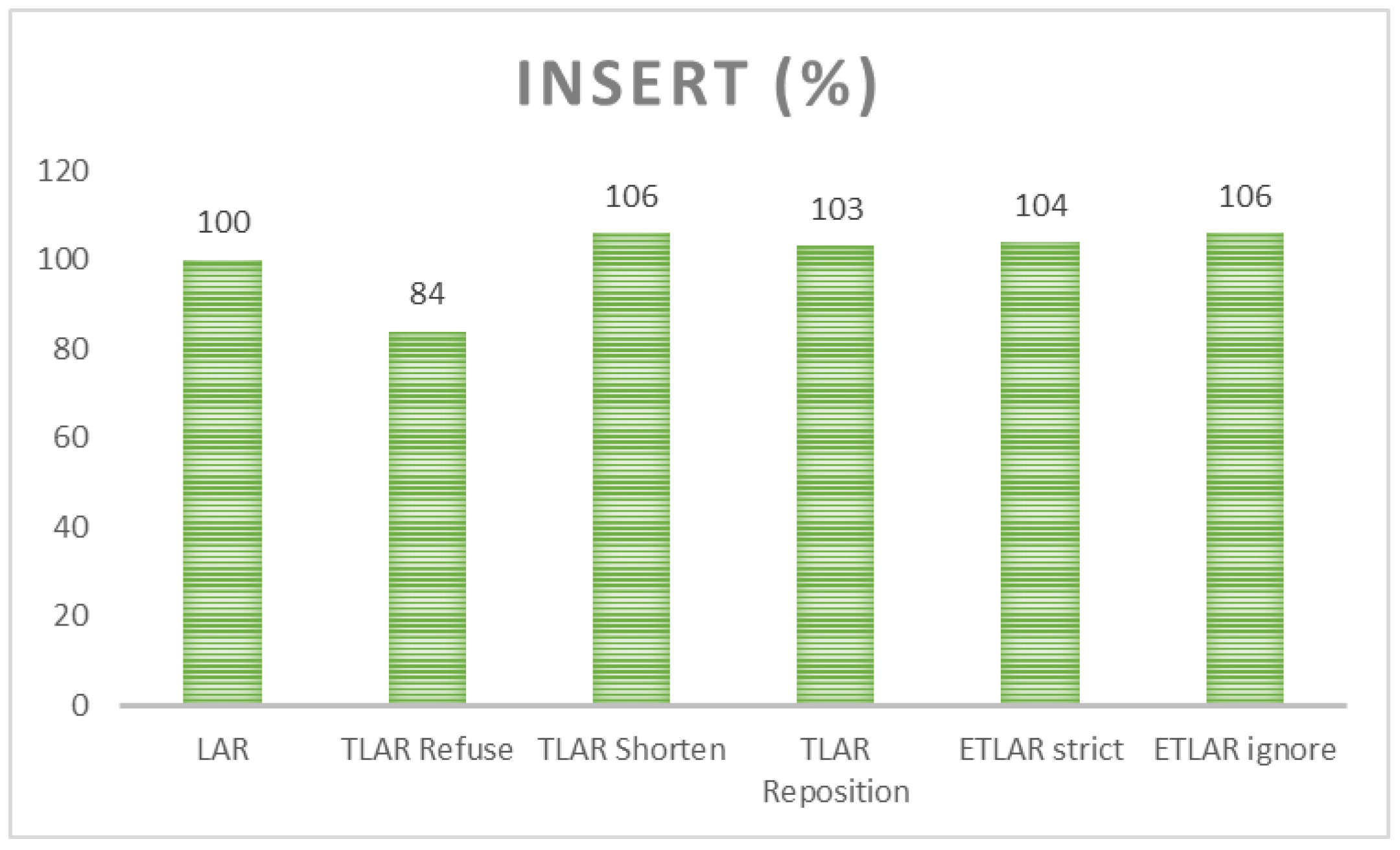{kind=link}
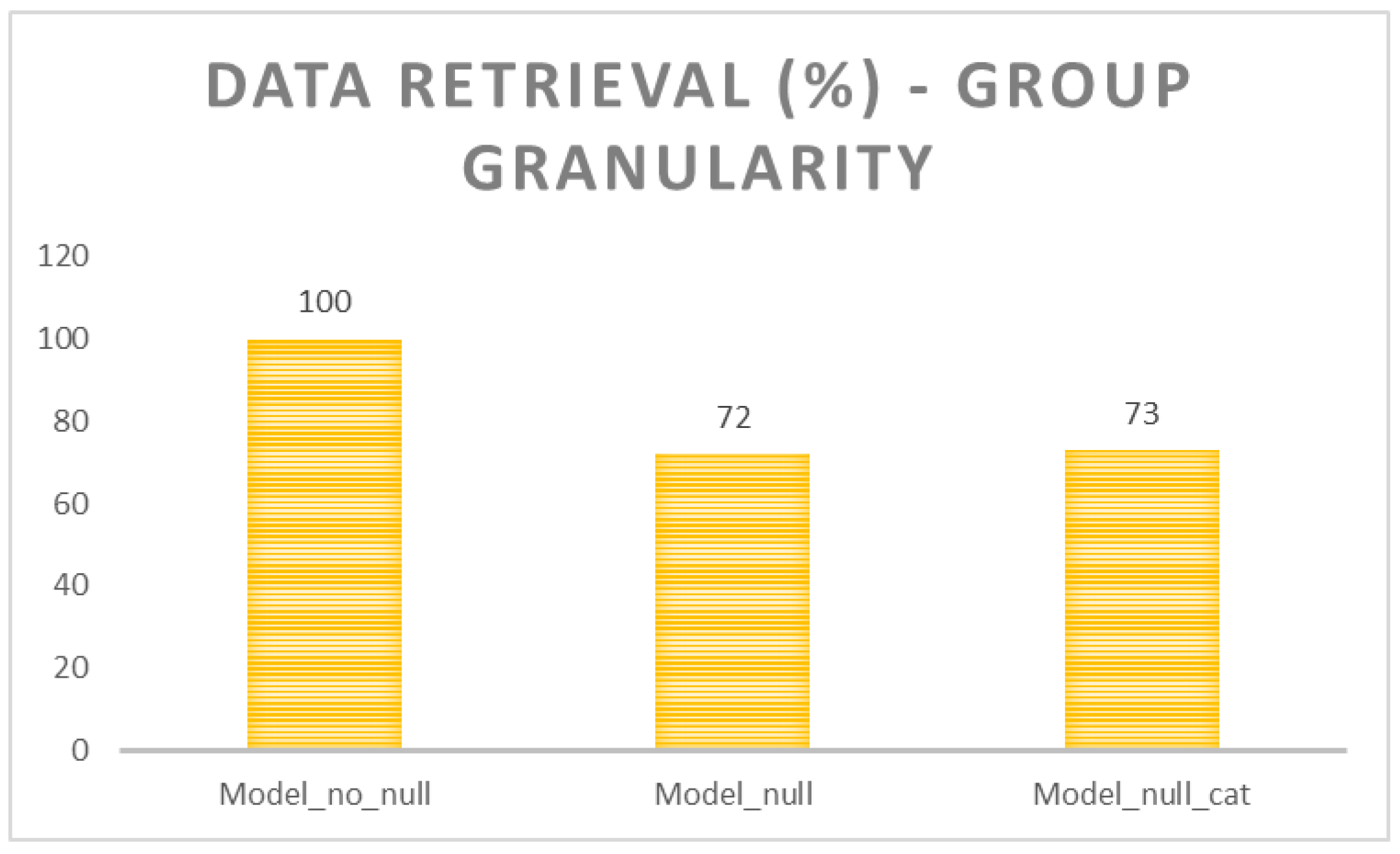{kind=link}
{kind=link}
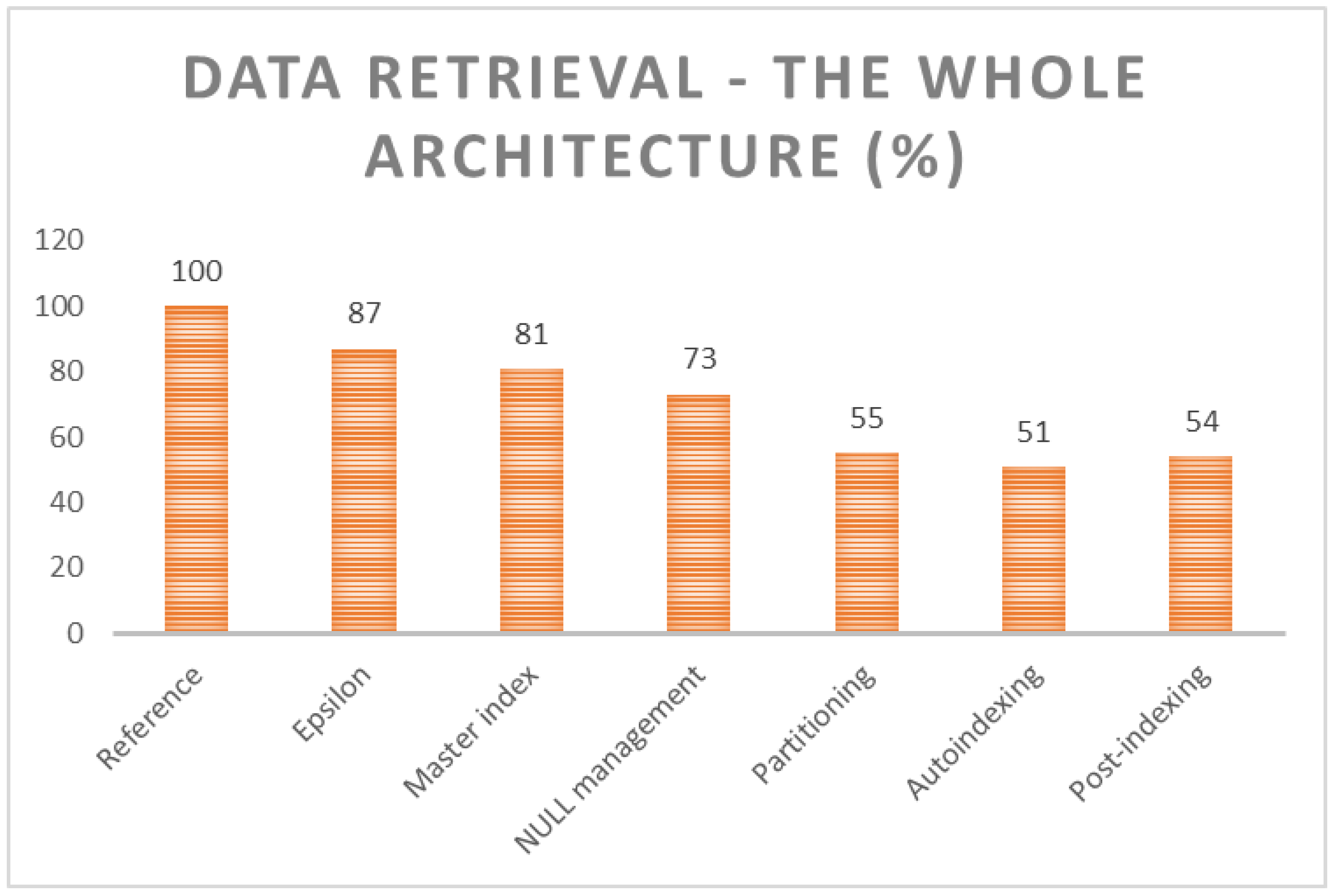{kind=link}
























