EDC-Net: Edge Detection Capsule Network for 3D Point Clouds


Abstract
:1. Introduction
- We introduce EDC-Net: the edge detection capsule network for 3D point clouds, a novel architecture of capsule networks which is designed for the purpose of edge detection from 3D point clouds.
- We design a weakly-supervised transfer learning approach for edge detection of point clouds in order to tackle the challenge of lack of the diversity of annotated data.
- We formulate a loss function assigned to the edge detection problem by combining two formats of ground-truths as edge extraction and segmentation. This combination in the loss function emphasizes the prediction of edge points and boosts the training process.
- Our model is able to improve incrementally the proposed weakly-supervised transfer learning for edge detection from 3D point clouds. This aspect of our proposed method brings the capability of applying EDC-Net to any target data. This attribute of EDC-Net is remarkable for industrial applications and is currently lacking in other edge detection techniques.
2. Related Work
2.1. Point Clouds
2.2. Edge Detection
2.3. Capsule Network
3. Proposed Method
3.1. Network Architecture
3.1.1. Input Data
3.1.2. Features Graph
3.1.3. Primary Capsules
3.1.4. Attention Module
3.1.5. Routing Mechanism
3.1.6. EdgeCaps
3.2. Loss Function
3.2.1. Edge Loss
3.2.2. Segmentation Loss
3.2.3. Total Loss
3.3. Training Process
3.3.1. Weakly-Supervised Transfer Learning
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
4.3. Edge Detection Results
4.4. Robustness to Noise
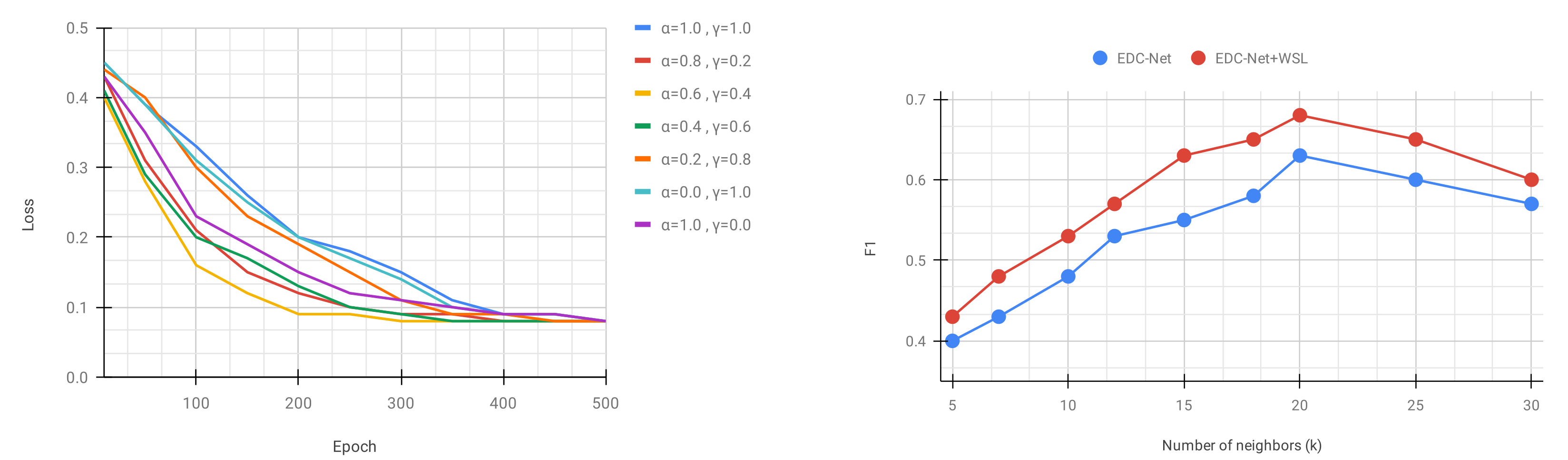
4.5. Ablation Study
4.6. Complexity Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmed, S.; Tan, Y.; Chew, C.; Mamun, A.; Wong, F. Edge and Corner Detection for Unorganized 3D Point Clouds with Application to Robotic Welding. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7350–7355. [Google Scholar]
- Hackel, T.; Dirk, J.; Schindler, K. Contour Detection in Unstructured 3D Point Clouds. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1610–1618. [Google Scholar]
- Ni, H.; Lin, X.; Ning, X.; Zhang, J. Edge Detection and Feature Line Tracing in 3D-Point Clouds by Analyzing Geometric Properties of Neighborhoods. Remote. Sens. 2016, 8, 710. [Google Scholar] [CrossRef] [Green Version]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Ho, E. 3D Object Reconstruction from Imperfect Depth Data Using Extended YOLOv3 Network. Sensors 2020, 20, 2025. [Google Scholar] [CrossRef] [Green Version]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Misra, S. Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset. Sensors 2019, 19, 1553. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.; Su, H.; Mo, K.; Guibas, L. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 652–666. [Google Scholar]
- Qi, C.; Yi, L.; Su, H.; Guibas, L. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2569–2578. [Google Scholar]
- Jaritz, M.; Gu, J.; Su, H. Multi-view PointNet for 3D Scene Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3995–4003. [Google Scholar]
- Mo, K.; Zhu, S.; Chang, A.; Yi, L.; Tripathi, S.; Guibas, L.; Su, H. PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 909–918. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3D point clouds: A survey. arXiv 2019, arXiv:1912.12033. [Google Scholar]
- Bazazian, D.; Casas, J.R.; Ruiz-Hidalgo, J. Fast and Robust Edge Extraction in Unorganized Point Clouds. In Proceedings of the 2015 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Adelaide, Australia, 23–25 November 2015; pp. 1–8. [Google Scholar]
- Weber, C.; Hahmann, S.; Hagen, H. Sharp Feature Detection in Point Clouds. In Proceedings of the Shape Modeling International Conference, Aix en Provence, France, 21–23 June 2010; pp. 175–186. [Google Scholar]
- Mineo, C.; Gareth, S.; Summan, R. Novel algorithms for 3D surface point cloud boundary detection and edge reconstruction. Comput. Des. Eng. 2018, 6, 81–89. [Google Scholar] [CrossRef]
- Demarsin, K.; Vanderstraeten, D.; Volodine, T.; Roose, D. Detection of closed sharp edges in point clouds using normal estimation and graph theory. Comput. Aided Des. 2007, 39, 276–283. [Google Scholar] [CrossRef]
- Bazazian, D.; Casas, J.R.; Ruiz-Hidalgo, J. Segmentation-based Multi-scale Edge Extraction to Measure the Persistence of Features in Unorganized Point Clouds. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), Porto, Portugal, 27 February–1 March 2017; pp. 317–325. [Google Scholar]
- Wang, X.; Xu, Y.; Xu, K.; Tagliasacchi, A.; Zhou, B.; Mahdavi-Amiri, A.; Zhang, H. PIE-NET: Parametric Inference of Point Cloud Edges. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33. [Google Scholar]
- Himeur, C.; Lejemble, T.; Pellegrini, T.; Paulin, M.; Barthe, L.; Mellado, N. PCEDNet: A Neural Network for Fast and Efficient Edge Detection in 3D Point Clouds. arXiv 2020, arXiv:2011.01630. [Google Scholar]
- Matveev, A.; Artemov, A.; Burnaev, E. Geometric Attention for Prediction of Differential Properties in 3D Point Clouds. arXiv 2020, arXiv:2007.02571. [Google Scholar]
- Raina, P.; Mudur, S.; Popa, T. Sharpness Fields in Point Clouds using Deep Learning. Comput. Graph. 2019, 78, 37–53. [Google Scholar] [CrossRef]
- Yu, L.; Li, X.; Fu, C.; Cohen-or, D.; Heng, P. EC-Net: An Edge-aware Point set Consolidation Network. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Raina, P.; Mudur, S.; Popa, T. MLS2: Sharpness Field Extraction Using CNN for Surface Reconstruction. In Proceedings of the 44th Graphics Interface Conference, Toronto, ON, Canada, 8–11 May 2018; pp. 57–66. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G. Dynamic Routing Between Capsules. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Patrick, M.; Adekoya, A.; Mighty, A.; Edward, B. Capsule networks—A survey. J. King Saud Univ. Comput. Inf. Sci 2019, 1319–1578. [Google Scholar] [CrossRef]
- Zhao, Y.; Birdal, T.; Deng, H.; Tombari, F. 3D Point-Capsule Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–21 June 2019; pp. 1009–1018. [Google Scholar]
- Srivastava, N.; Goh, H.; Salakhutdinov, R. Geometric Capsule Autoencoders for 3D Point Clouds. arXiv 2019, arXiv:1912.03310. [Google Scholar]
- Bazazian, D.; Nahata, D. DCG-Net: Dynamic Capsule Graph Convolutional Network for Point Clouds. IEEE Access 2020, 8, 188056–188067. [Google Scholar] [CrossRef]
- Zhao, Y.; Birdal, T.; Lenssen, J.; Menegatti, E.; Guibas, L.; Tombari, F. Quaternion equivariant capsule networks for 3D point clouds. arXiv 2019, arXiv:1912.12098. [Google Scholar]
- Cheraghian, A.; Petersson, L. 3DCapsule: Extending the capsule architecture to classify 3D point clouds. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1194–1202. [Google Scholar]
- Chan, L.; Hosseini, M.S.; Plataniotis, K.N. A comprehensive analysis of weakly-supervised semantic segmentation in different image domains. Int. J. Comput. Vis. 2020, 1–24. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. arXiv 2020, arXiv:1911.02685. [Google Scholar] [CrossRef]
- Hwang, S.; Kim, H.E. Self-transfer learning for fully weakly supervised object localization. arXiv 2016, arXiv:1602.01625. [Google Scholar]
- Fang, F.; Xie, Z. Weak Supervision in the Age of Transfer Learning for Natural Language Processing; cs229 Stanford: Stanford, CA, USA, 2019. [Google Scholar]
- Chang, A.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Koch, S.; Matveev, A.; Jiang, Z.; Williams, F.; Artemov, A.; Burnaev, E.; Alexa, M.; Zorin, D.; Panozzo, D. ABC: A Big CAD Model Dataset for Geometric Deep Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 19–21 June 2019; pp. 9593–9603. [Google Scholar]
- Qi, C.; Liu, W.; Wu, C.; Su, H.; Guibas, L. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Qi, C.; Litany, O.; He, K.; Guibas, L. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection from Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Li, J.; Chen, B.; Lee, G. SO-Net: Self-Organizing Network for Point Cloud Analysis. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 90–105. [Google Scholar]
- Zhang, Z.; Hua, B.; Yeung, S. ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statistics. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1607–1616. [Google Scholar]
- Hinton, G.; Krizhevsky, A.; Wang, S. Transforming auto-encoders. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS), Granada, Spain, 12–17 December 2011; pp. 44–51. [Google Scholar]
- Bonheur, S.; Štern, D.; Payer, C.; Pienn, M.; Olschewski, H.; Urschler, M. Matwo-capsnet: A multi-label semantic segmentation capsules network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 664–672. [Google Scholar]
- Survarachakan, S.; Johansen, J.S.; Aarseth, M.; Pedersen, M.A.; Lindseth, F. Capsule Nets for Complex Medical Image Segmentation Tasks. Online Colour and Visual Computing Symposium. 2020. Available online: http://ceur-ws.org/Vol-2688/paper13.pdf (accessed on 23 December 2020).
- Sun, T.; Wang, Z.; Smith, C.D.; Liu, J. Trace-back along capsules and its application on semantic segmentation. arXiv 2019, arXiv:1901.02920. [Google Scholar]
- LaLonde, R.; Bagci, U. Capsules for object segmentation. arXiv 2018, arXiv:1804.04241. [Google Scholar]
- LaLonde, R.; Xu, Z.; Irmakci, I.; Jain, S.; Bagci, U. Capsules for biomedical image segmentation. Med Image Anal. 2020, 68, 101889. [Google Scholar] [CrossRef]
- Xu, M.; Zhou, Z.; Qiao, Y. Geometry sharing network for 3D point cloud classification and segmentation. arXiv 2019, arXiv:1912.10644. [Google Scholar] [CrossRef]
- Xinyi, Z.; Chen, L. Capsule graph neural network. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Veeraraghavan, A.; Chellappa, R. Fast directional chamfer matching. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1696–1703. [Google Scholar]
- Bazazian, D. Edge_Extraction: GitHub Repository. 2015. Available online: https://github.com/denabazazian/Edge_Extraction (accessed on 23 December 2020).
- Kingma, D.; Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Loshchilov, I.; Frank, H. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]
- Rutzinger, M.; Rottensteiner, F.; Pfeifer, N. A comparison of evaluation techniques for building extraction from airborne laser scanning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 11–20. [Google Scholar] [CrossRef]
- Yu, L. EC-Net: GitHub Repository. 2018. Available online: https://github.com/yulequan/EC-Net (accessed on 23 December 2020).
- Kosiorek, A.; Sabour, S.; Teh, Y.W.; Hinton, G.E. Stacked capsule autoencoders. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019; pp. 15512–15522. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EC-Net [21] | EDC-Net (Ours) | EC-Net [21] + WSL | EDC-Net + WSL (Ours) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| ABC | N = 1024 | 0.6780 | 0.7427 | 0.7089 | 0.8475 | 0.9310 | 0.8873 | 0.6652 | 0.7278 | 0.6951 | 0.8371 | 0.9051 | 0.8698 |
| N = 2048 | 0.6782 | 0.7451 | 0.7101 | 0.8485 | 0.9561 | 0.8991 | 0.6727 | 0.7322 | 0.7012 | 0.8407 | 0.9322 | 0.8841 | |
| ShapeNet | N = 1024 | 0.5718 | 0.6845 | 0.6231 | 0.5879 | 0.6991 | 0.6387 | 0.5906 | 0.7034 | 0.6421 | 0.6357 | 0.7532 | 0.6895 |
| N = 2048 | 0.6069 | 0.6823 | 0.6424 | 0.6658 | 0.7532 | 0.7068 | 0.6469 | 0.7021 | 0.6734 | 0.7537 | 0.7843 | 0.7687 | |
| Noise Level () | ||||||
|---|---|---|---|---|---|---|
| = 0.0 | = 0.02 | = 0.05 | = 0.08 | = 0.12 | ||
| N = 1024 | P | 0.8475 | 0.8310 | 0.8179 | 0.7865 | 0.7321 |
| R | 0.9310 | 0.8986 | 0.8849 | 0.8402 | 0.8443 | |
| F1 | 0.8873 | 0.8635 | 0.8501 | 0.8125 | 0.7842 | |
| N = 2048 | P | 0.8458 | 0.8267 | 0.8268 | 0.8023 | 0.7684 |
| R | 0.9561 | 0.9385 | 0.9027 | 0.8424 | 0.8306 | |
| F1 | 0.8991 | 0.8791 | 0.8631 | 0.8219 | 0.7983 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazazian, D.; Parés, M.E. EDC-Net: Edge Detection Capsule Network for 3D Point Clouds. Appl. Sci. 2021, 11, 1833. https://doi.org/10.3390/app11041833
Bazazian D, Parés ME. EDC-Net: Edge Detection Capsule Network for 3D Point Clouds. Applied Sciences. 2021; 11(4):1833. https://doi.org/10.3390/app11041833
Chicago/Turabian StyleBazazian, Dena, and M. Eulàlia Parés. 2021. "EDC-Net: Edge Detection Capsule Network for 3D Point Clouds" Applied Sciences 11, no. 4: 1833. https://doi.org/10.3390/app11041833
APA StyleBazazian, D., & Parés, M. E. (2021). EDC-Net: Edge Detection Capsule Network for 3D Point Clouds. Applied Sciences, 11(4), 1833. https://doi.org/10.3390/app11041833