
Improving Distant Supervised Relation Extraction with Noise Detection Strategy

Abstract
:1. Introduction
2. Related Work
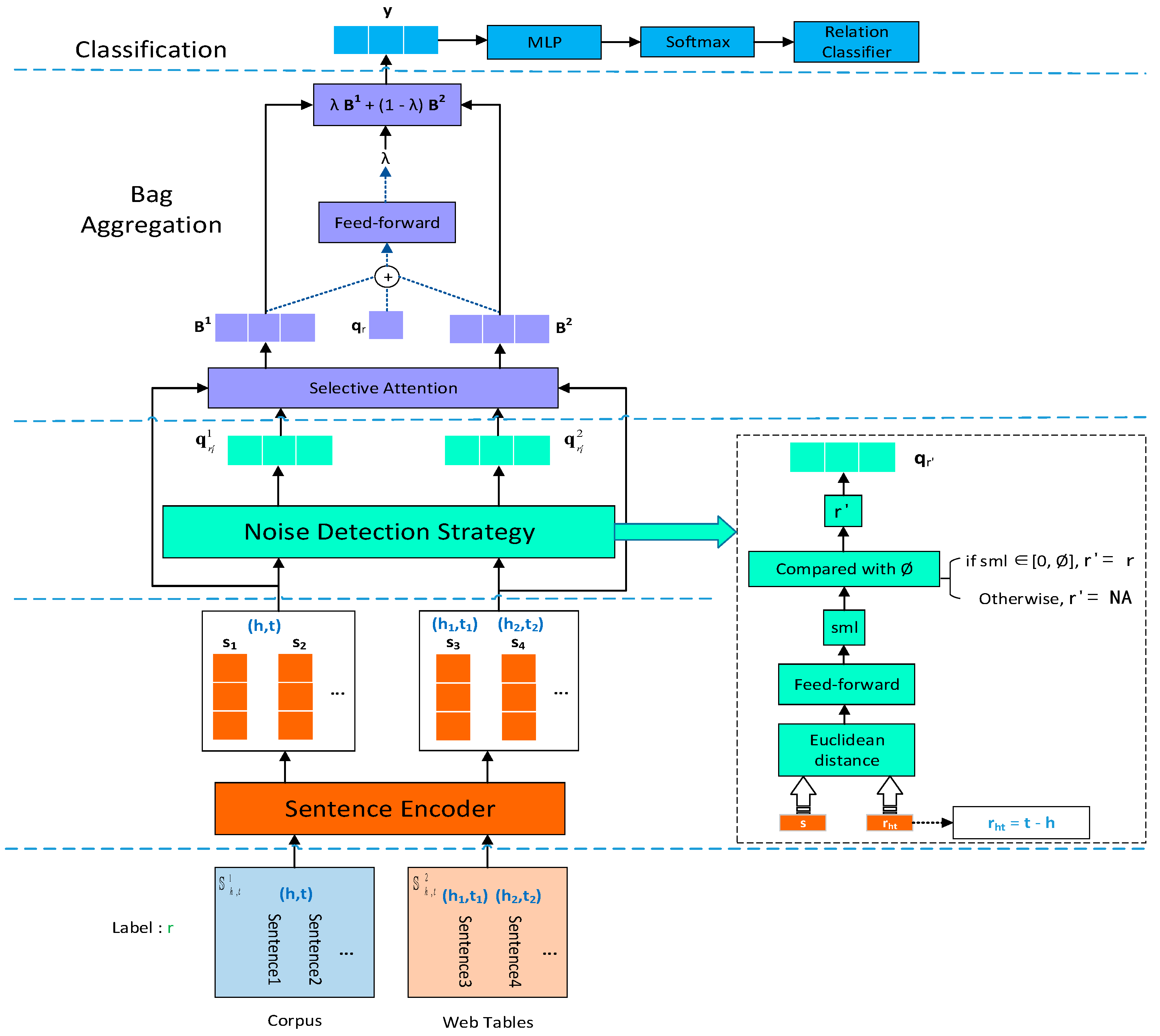
3. Proposed Method
3.1. Task Definition and Notation
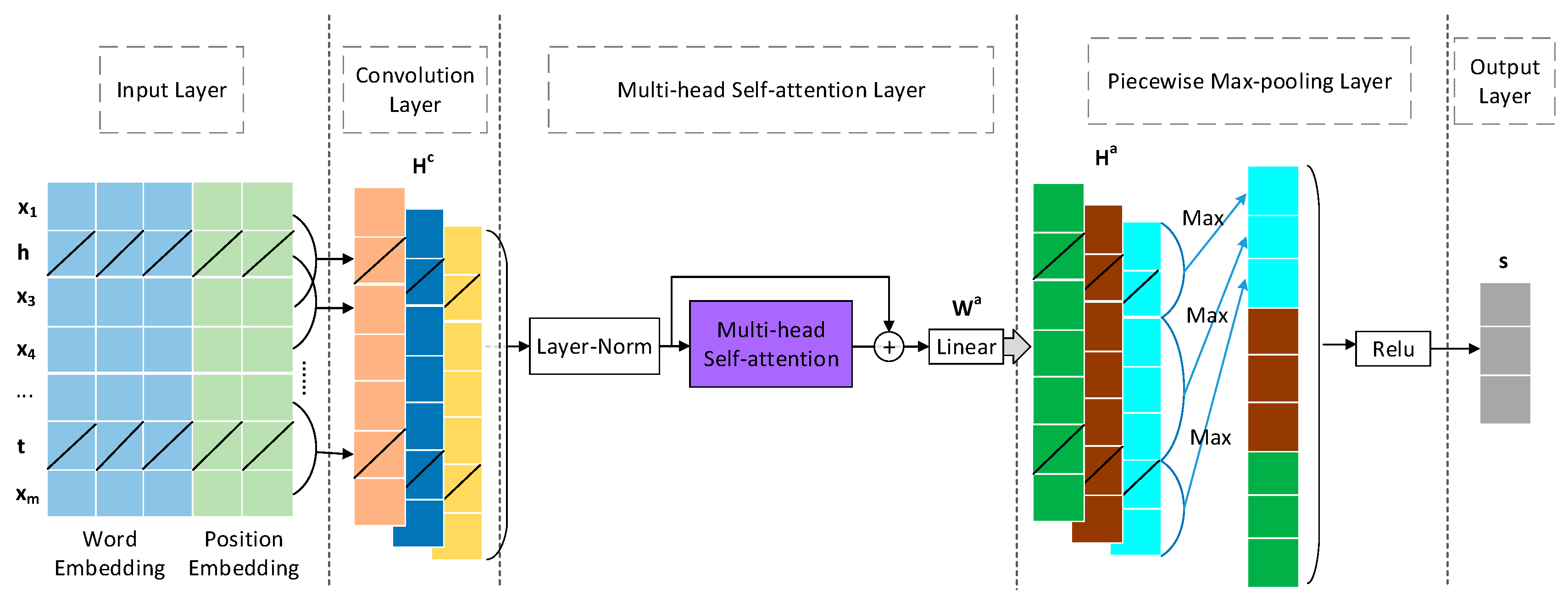
3.2. Sentence Encoder
3.2.1. Input Representation
3.2.2. Encoding Layer
3.3. Noise Detection Strategy
3.4. Bag Aggregation
3.5. Classification and Objective Function
4. Experiments and Results
4.1. Dataset
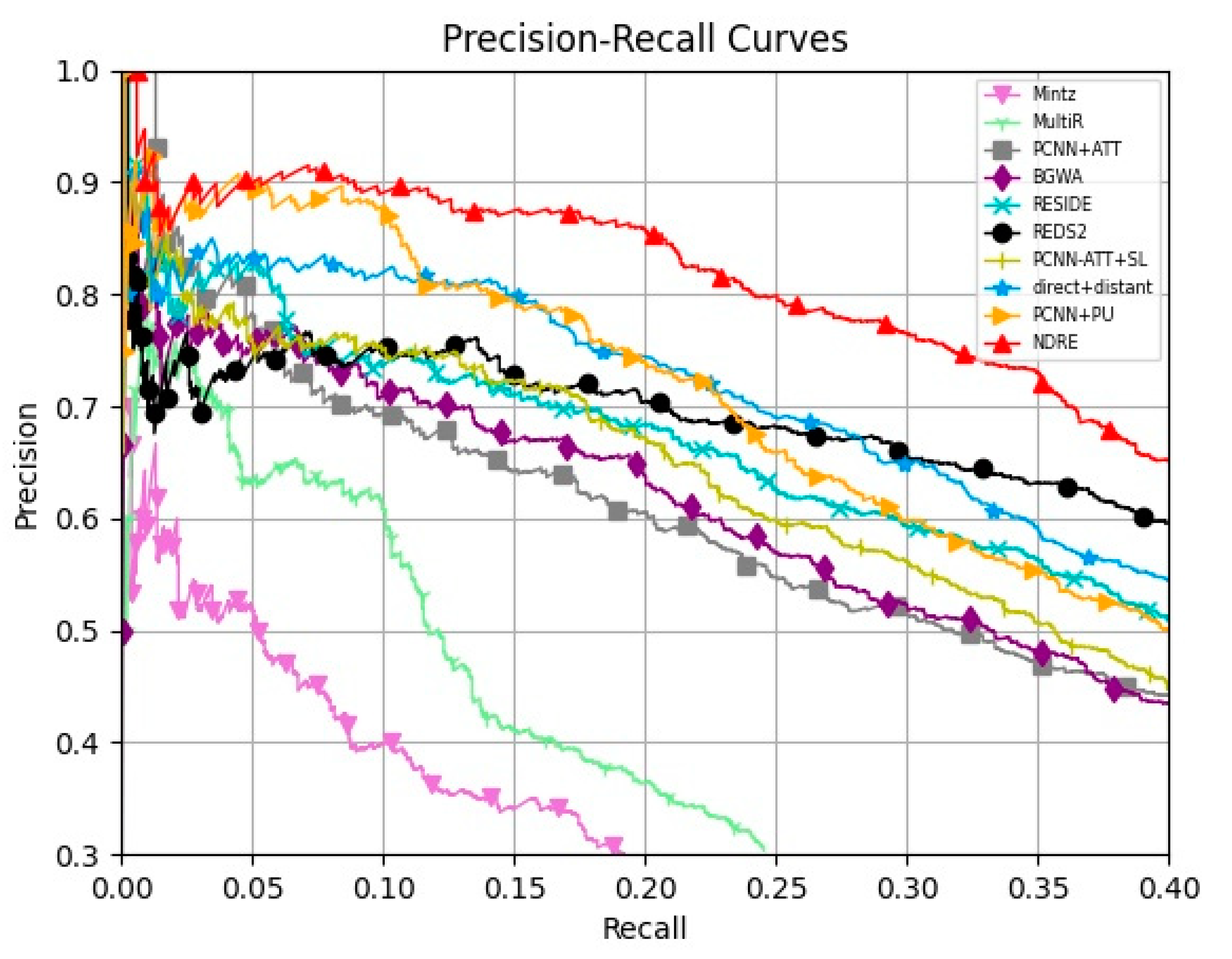
4.2. Comparison with Baselines
- Mintz: A multi-class logistic regression model based on text syntactic and lexical features proposed by Mintz et al. [3];
- MultiR: A probabilistic graphical model in a multi-instance learning framework proposed by Hoffmann et al. [12];
- PCNN+ATT: A CNN-based model combined with piecewise max pooling and selective attention over sentences proposed by Lin et al. [6];
- PCNN+ATT+SL: An entity-pair level model with soft labels that exploits semantic/syntactic information from correctly labeled instances, proposed by Liu et al. [15];
- BGWA: A BiGRU-based model with word-level attention proposed by Jat et al. [16];
- RESIDE: A GCN model based on Graph Convolutional Network (GCN) with utilizing syntactic dependency, entity type, and relation alias information, proposed by Vashishth et al. [8];
- Direct+Dis: This model, by (Beltagy et al., employs directly supervised data as supervision for the attention weights of DS data [9];
- REDS2: A two-hop distant supervision model fusing data from NYT and web tables proposed by Deng et al. [10];
- PCNN+PU: A bag-level reinforcement-learning-based method utilizing relation embedding and unlabeled instances proposed by He et al. [18];
4.3. Experimental Settings
4.3.1. Word and Position Embeddings
4.3.2. Hyper-Parameter Settings
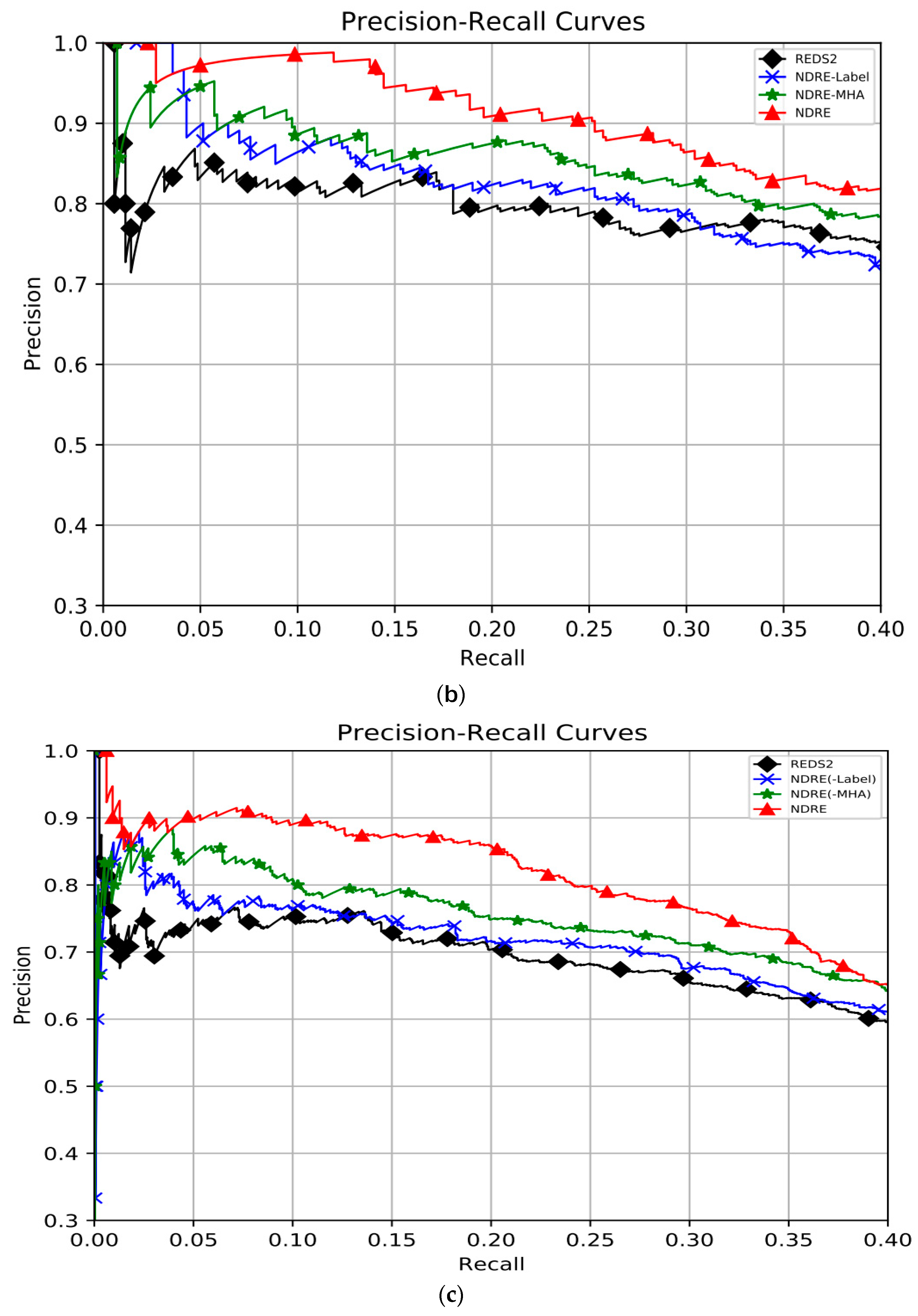
4.4. Overall Evaluation Results
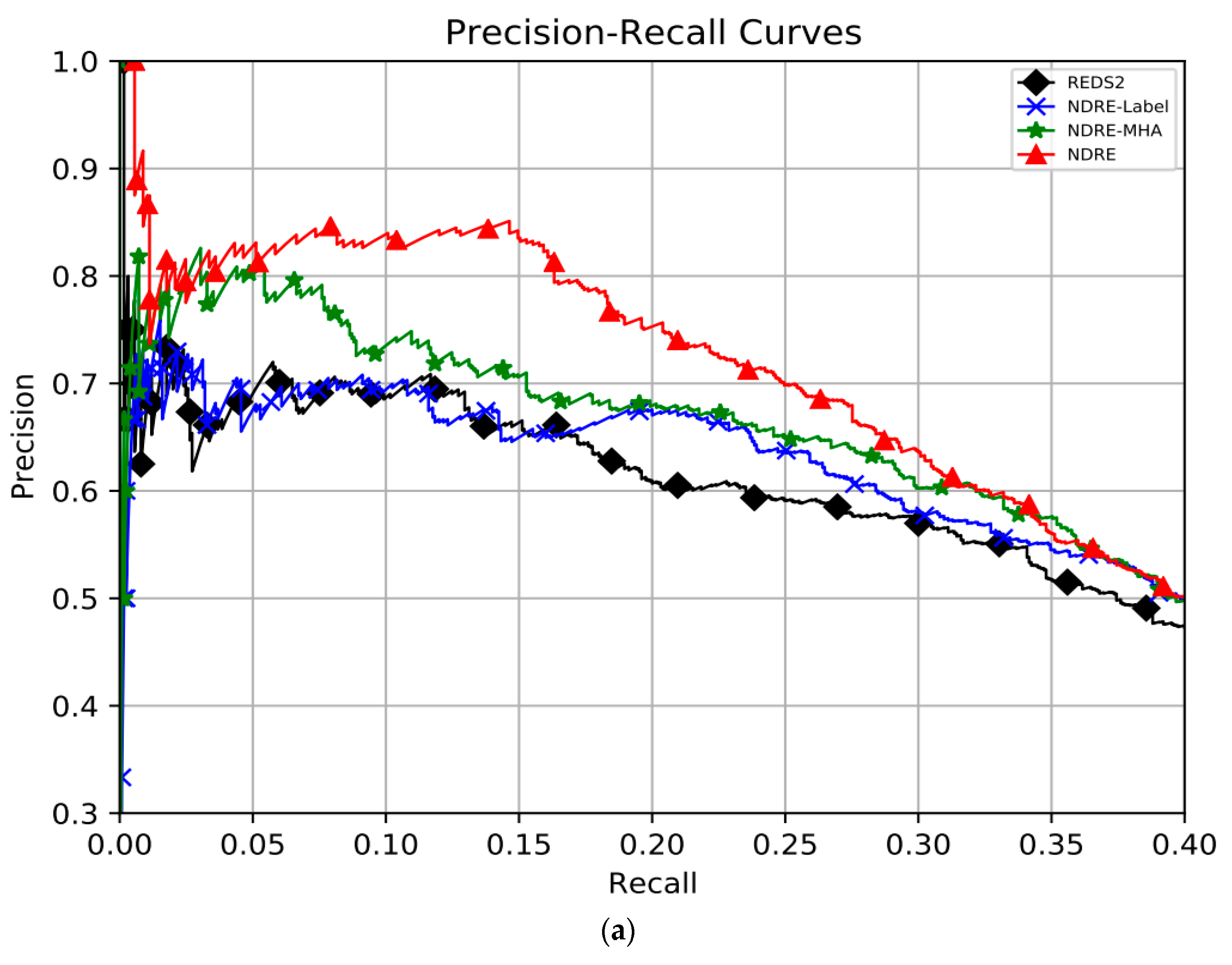
4.5. Ablation Results
- Single: Only bags composed of single instance were selected for relation extraction.
- Multiple: Only bags composed of more than one instance were selected for relation extraction.
- Whole: The whole dataset was used for relation extraction.
4.6. Case Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; Association for Computing Machinery: New York, NY, USA; pp. 1247–1250. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction Without Labeled Data. In Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–8 August 2009; pp. 1003–1011. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic Compositionality Through Recursive Matrix-Vector Spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 1201–1211. [Google Scholar]
- Daojian, Z.; Kang, L.; Siwei, L.; Guangyou, Z.; Jun, Z. Relation classifification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th international conference on computational linguistics: technical papers, Dublin, Ireland, 23–29 August 2014; 2014; pp. 2335–2344. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zaho, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–22 September 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1753–1762. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3060–3066. [Google Scholar]
- Vashishth, S.; Joshi, R.; Prayaga, S.S.; Bhattacharyya, C.; Talukdar, P. Reside: Improving distantly-supervised neural relation extraction using side information. arXiv 2018, arXiv:1812.04361. [Google Scholar]
- Beltagy, I.; Lo, K.; Ammar, W. Combining distant and direct supervision for neural relation extraction. arXiv 2018, arXiv:1810.12956. [Google Scholar]
- Deng, X.; Sun, H. Leveraging 2-hop Distant Supervision from Table Entity Pairs for Relation Extraction. arXiv 2019, arXiv:1909.06007, 2019. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling Relations and Their Mentions Without Labeled Text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Proceedings of the Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 541–550. [Google Scholar]
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multi-Instance Multi-Label Learning for Relation Extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 13–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 455–465. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural Relation Extraction with Selective Attention over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; Volume 1, pp. 2124–2133. [Google Scholar]
- Liu, T.; Wang, K.; Chang, B.; Sui, Z. A Soft-Label Method for Noise-Tolerant Distantly Supervised Relation Extraction. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1790–1795. [Google Scholar]
- Jat, S.; Khandelwal, S.; Talukdar, P. Improving distantly supervised relation extraction using word and entity based attention. arXiv 2018, arXiv:1804.06987. [Google Scholar]
- Xiao, Y.; Jina, Y.; Cheng, R.; Hao, K. Hybrid Attention-Based Transformer Block Model for Distant Supervision Relation Extraction. arXiv 2020, arXiv:2003.11518. [Google Scholar]
- He, Z.; Chen, W.; Wang, Y.; Zhang, W.; Wang, G.; Zhang, M. Improving Neural Relation Extraction with Positive and Unlabeled Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 7927–7934. [Google Scholar]
- Li, Y.; Long, G.; Shen, T.; Zhou, T.; Yao, L.; Huo, H.; Jiang, J. Self-Attention Enhanced Selective Gate with Entity-Aware Embedding for Distantly Supervised Relation Extraction. In In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; 2020; volume 34, pp. 8269–8276. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Advances in Neural Information, Processing Systems 26 (NIPS 2013), Proceedings of the Neural Information Processing Systems 2013 Conference, Lake Tahoe, NV, USA, 5–10 December 2013; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Advances in Neural Information, Processing Systems 30 (NIPS 2017), Proceedings of the Neural Information Processing Systems 2017 Conference, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishanathan, S., Garnett, R., Eds.; Neural Information Processing Systems: San Diego, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Neural Information Processing, Proceedings of the 26th International Conference on Neural Information Processing Systems, NIPS’13, Sydey, NSW, Australia, 12–15 December 2019; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the 28th AAAI Conference on Artifificial Intelligence, Quebec, ON, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bag | Instance | Correct | Weight | Noise |
|---|---|---|---|---|
| B1 (play) | Kristen Stewart is set to play Princess Diana in an upcoming movie. | True | 0.9 | Instance-level |
| Kristen Stewart can be mysterious and fragile and ultimately strong as well, which is similar to Princess Diana. | False | 0.1 | ||
| B2 (famous_in) | Will Smith was born in Philadelphia, Pennsylvania on September 25, 1968. | False | 1 | Bag-level |
| MODE | Single | Multiple | Whole | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | [email protected] | [email protected] | [email protected] | AUC | [email protected] | [email protected] | [email protected] | AUC | [email protected] | [email protected] | [email protected] | AUC |
| REDS2 | 69.1 | 61.1 | 57.4 | 37.5 | 82.4 | 79.6 | 76.6 | 57.59 | 75.3 | 70.4 | 65.5 | 44.65 |
| NDRE(-Label) | 69.4 | 67.6 | 58.1 | 38.2 | 86.4 | 82.4 | 78.7 | 61.40 | 76.5 | 71.7 | 67.6 | 46.72 |
| NDRE(-MHA) | 73.5 | 68.0 | 60.3 | 39.3 | 88.6 | 87.5 | 82.4 | 62.90 | 80.9 | 74.9 | 71.3 | 47.89 |
| NDRE | 83.9 | 75.3 | 63.8 | 42.0 | 98.6 | 90.9 | 86.4 | 66.06 | 89.0 | 85.9 | 76.6 | 50.94 |
| Instances | sml | r | Noise | Correct | |
|---|---|---|---|---|---|
| Buffon, one of the world ’s top goalkeepers, and [Fabio_Cannavaro], [Italy]’s captain, were interviewed by the authorities. | 0.04 | people/person/nationality | people/person/nationality | No | Yes |
| The director, [Bennett_miller], had made the unflinching documentary “The cruise” in 1998, which followed the gradual descent of a near-homeless [New_York city] tour guide. | 0.68 | people/person/place_lived | NA | Yes | Yes |
| Then he needs to be able to relate to the poor when he goes to places like [Brazil] or Morocco or [Burkina Faso]. | 0.83 | NA | NA | No | Yes |
| [Peggy] was born in Miami, Florida and lived in [New_York city] for 52 years. | 0.12 | people/person/place_of_birth | people/person/nationality | Yes | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, X.; Jiang, T.; Zhou, X.; Ma, B.; Wang, Y.; Zhao, F. Improving Distant Supervised Relation Extraction with Noise Detection Strategy. Appl. Sci. 2021, 11, 2046. https://doi.org/10.3390/app11052046
Meng X, Jiang T, Zhou X, Ma B, Wang Y, Zhao F. Improving Distant Supervised Relation Extraction with Noise Detection Strategy. Applied Sciences. 2021; 11(5):2046. https://doi.org/10.3390/app11052046
Chicago/Turabian StyleMeng, Xiaoyan, Tonghai Jiang, Xi Zhou, Bo Ma, Yi Wang, and Fan Zhao. 2021. "Improving Distant Supervised Relation Extraction with Noise Detection Strategy" Applied Sciences 11, no. 5: 2046. https://doi.org/10.3390/app11052046
APA StyleMeng, X., Jiang, T., Zhou, X., Ma, B., Wang, Y., & Zhao, F. (2021). Improving Distant Supervised Relation Extraction with Noise Detection Strategy. Applied Sciences, 11(5), 2046. https://doi.org/10.3390/app11052046