
Capsule Network Improved Multi-Head Attention for Word Sense Disambiguation

Abstract
:1. Introduction
2. Related Work
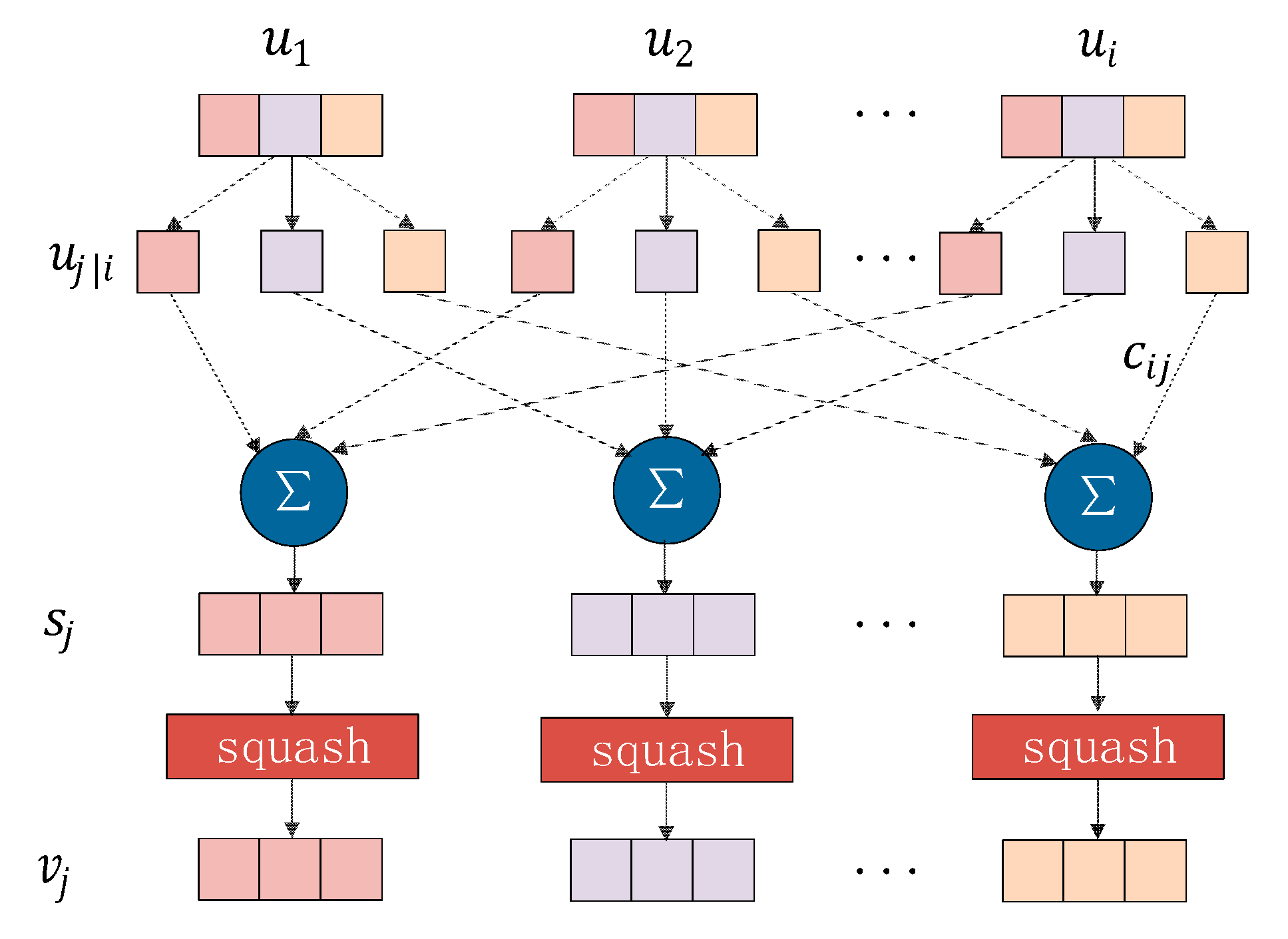
2.1. Capsule Network
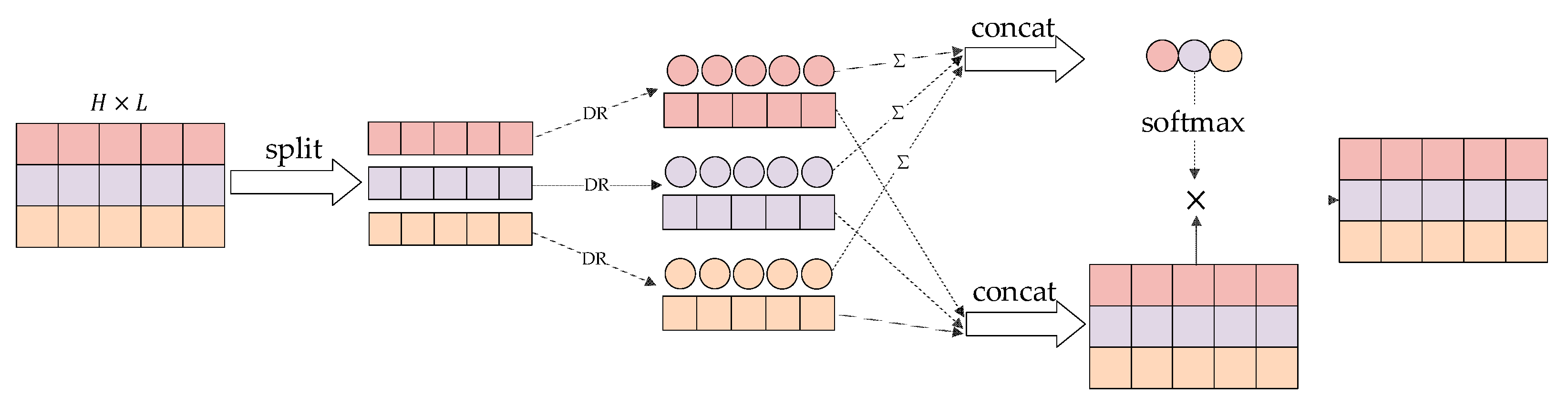
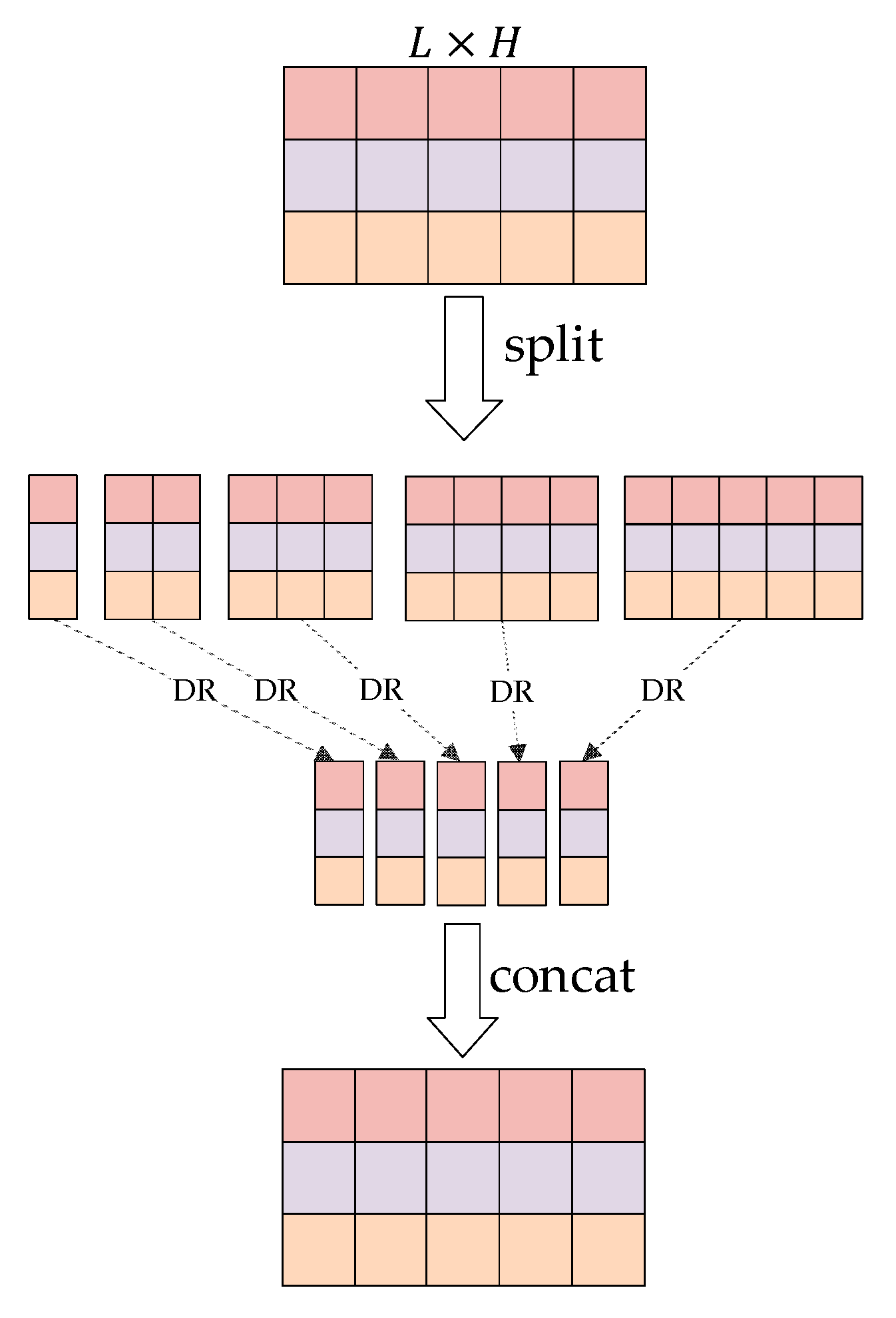
2.2. Multi-Head Attention
3. Methodology
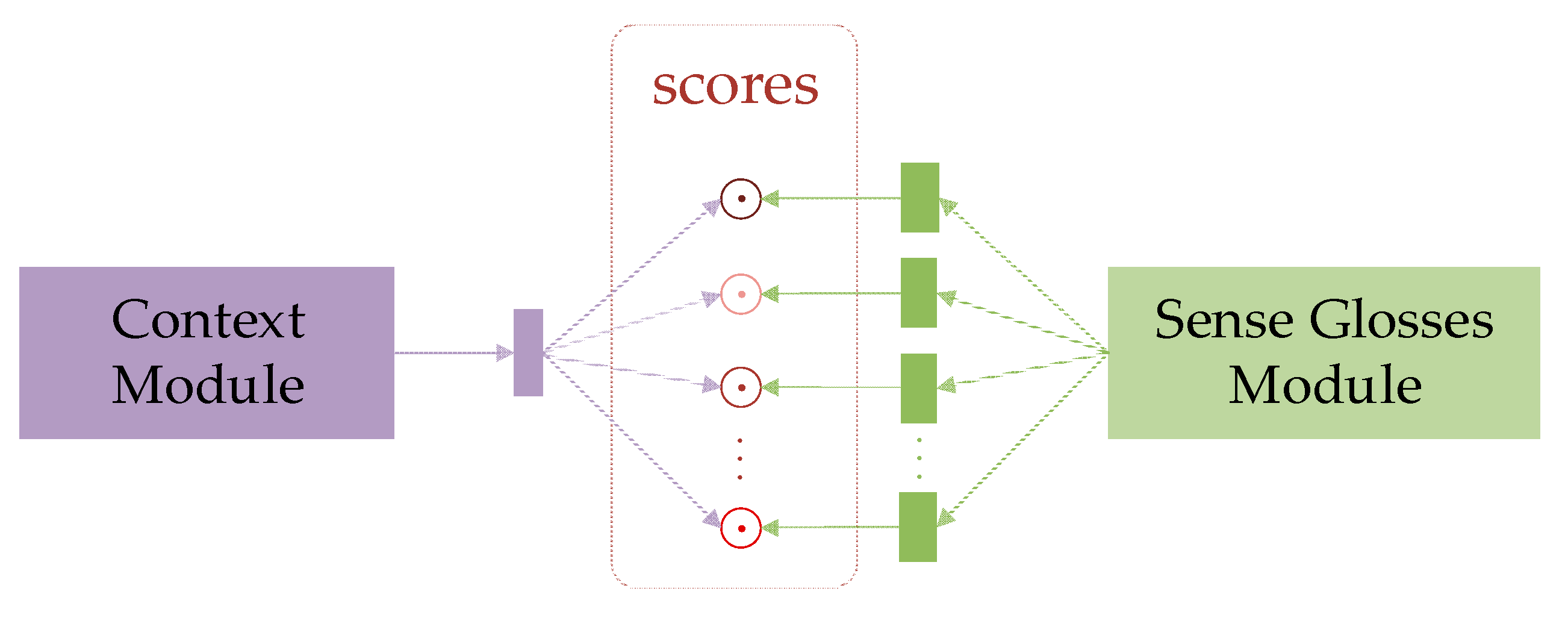
3.1. All-Words Task Definition
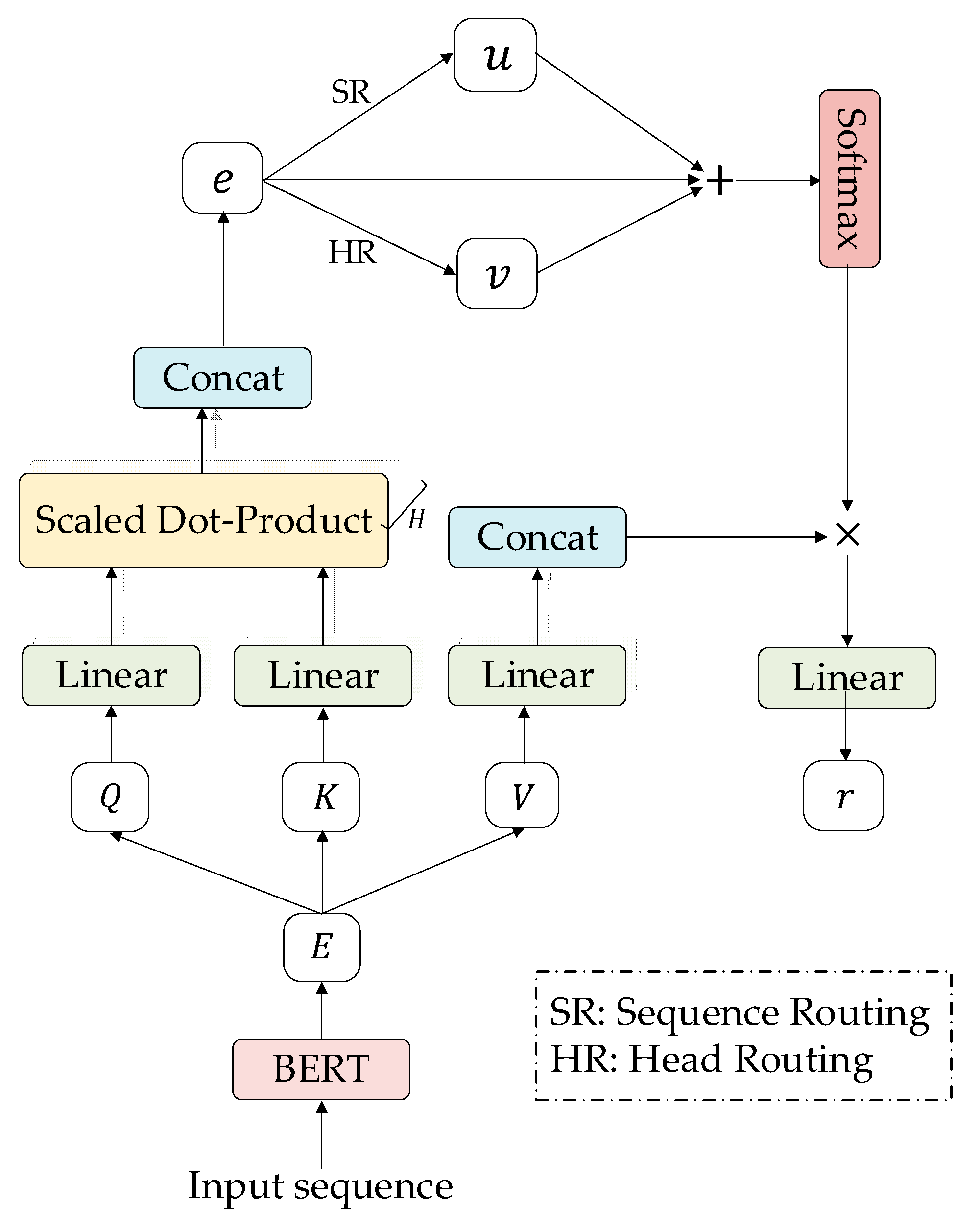
3.2. Model Details
| Algorithm 1 Dynamic Routing (DR). |
| Input: vectors , iteration times Process: 1. 2. for do 3. softmax computes Equation (3) 4. 5. squash computes Equation (4) 6. 7. end for Output: output vectors , weights |
4. Experiments
4.1. Datasets
4.2. Experimental Setup
4.3. Results
4.3.1. Overall Results
- Knowledge-based systems: The first four systems are knowledge-based methods, among which, MFS and WordNet S1 are two strong knowledge-based baselines. They select the most frequent sense (MFS) in the training dataset and in WordNet, respectively. Lesk+ext,emb [8] is an extended version of Lesk algorithm, which calculates the definition-context overlap to measure semantic similarity. Babelfy [42] builds a unified graph-based architecture that exploits BabelNet as the semantic network. WSD-TM [43] leverage the formalism of topic model to design a WSD system.
- Traditional supervised systems: IMS [10] and IMS+emb [11] are two traditional word expert supervised methods training an SVM classifier for WSD. The latter explores different approaches to incorporate word embeddings as features on the basis of the former using local features. The results show that word embeddings provide significant improvement.
- Neural-based systems: We list several recent neural-based methods. Bi-LSTM+att,LEX,POS [17] converts WSD to a sequence learning task. GASext (concatenation) [19] jointly encodes the context and glosses of the target word and extending gloss knowledge. EWISE [20] uses BiLSTM to train the context encoder and knowledge graph embedding to train the definition encoder. LMMS2348 (BERT) [21] focuses on making full use of WordNet knowledge to create sense-level embeddings. GlossBERT [16] constructs context-gloss pairs, thus treating WSD task as a sentence-pair classification problem to fine-tune the pre-trained BERT model. All the neural-based systems perform better than the traditional supervised and knowledge-based systems. It shows the ability of contextual representation and effectiveness of incorporating gloss knowledge. CapsDecE2S [26] utilizes capsule network to decompose the unsupervised word embedding into multiple morpheme-like vectors and merges them by contextual attention to generate context specific sense embedding. The CapsDecE2S and GlossBERT enable two strong baselines hard to beat.
4.3.2. WSD on Rare Words and Rare Senses
4.4. Abaltion Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Zhong, Z.; Ng, H.T. Word sense disambiguation improves information retrieval. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; pp. 273–282. [Google Scholar]
- Chan, Y.S.; Ng, H.T.; Chiang, D. Word sense disambiguation improves statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 33–40. [Google Scholar]
- Pu, X.; Pappas, N.; Henderson, J.; Popescu-Belis, A. Integrating Weakly Supervised Word Sense Disambiguation into Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2018, 6, 635–649. [Google Scholar] [CrossRef] [Green Version]
- Hung, C.; Chen, S.J. Word sense disambiguation based sentiment lexicons for sentiment classification. Knowl. Based Syst. 2016, 110, 224–232. [Google Scholar] [CrossRef]
- Lesk, M. Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone. In Proceedings of the 5th Annual International Conference on Systems Documentation, Toronto, ON, Canada, January 1986; pp. 24–26. [Google Scholar]
- Banerjee, S.; Pedersen, T. An Adapted Lesk Algorithm for Word Sense Disambiguation Using WordNet. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Mexico City, Mexico, 17–23 February 2002; pp. 136–145. [Google Scholar]
- Basile, P.; Caputo, A.; Semeraro, G. An Enhanced Lesk Word Sense Disambiguation Algorithm through a Distributional Semantic Model. In Proceedings of the COLING 2014, 25th International Conference on Computational Linguistics, Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 1591–1600. [Google Scholar]
- Sinha, R.; Mihalcea, R. Unsupervised graph-based word sense disambiguation using measures of word semantic similarity. In Proceedings of the International Conference on Semantic Computing, Irvine, CA, USA, 17–19 September 2007; pp. 363–369. [Google Scholar]
- Zhong, Z.; Ng, H.T. It Makes Sense: A Wide-Coverage Word Sense Disambiguation System for Free Text. In Proceedings of the ACL 2010 System Demonstrations, Uppsala, Sweden, 13 July 2010; pp. 78–83. [Google Scholar]
- Iacobacci, I.; Pilehvar, M.T.; Navigli, R. Embeddings for Word Sense Disambiguation: An Evaluation Study. In Proceedings of the 54rd Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 897–907. [Google Scholar]
- Melamud, O.; Goldberger, J.; Dagan, I. context2vec: Learning Generic Context Embedding with Bidirectional LSTM. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 51–61. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Hadiwinoto, C.; Ng, H.T.; Gan, W.C. Improved Word Sense Disambiguation Using Pre-Trained Contextualized Word Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5297–5306. [Google Scholar]
- Huang, L.; Sun, C.; Qiu, X.; Huang, X. Glossbert: Bert for word sense disambiguation with gloss knowledge. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3500–3505. [Google Scholar]
- Raganato, A.; Bovi, C.D.; Navigli, R. Neural sequence learning models for word sense disambiguation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1156–1167. [Google Scholar]
- Luo, F.; Liu, T.; He, Z.; Xia, Q.; Sui, Z.; Chang, B. Leveraging gloss knowledge in neural word sense disambiguation by hierarchical co-attention. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1402–1411. [Google Scholar]
- Luo, F.; Liu, T.; Xia, Q.; Chang, B.; Sui, Z. Incorporating glosses into neural word sense disambiguation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 June 2018; pp. 2473–2482. [Google Scholar]
- Kumar, S.; Jat, S.; Saxena, K.; Talukdar, P. Zero-shot word sense disambiguation using sense definition embeddings. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5670–5681. [Google Scholar]
- Loureiro, D.; Jorge, A. Language modelling makes sense: Propagating representations through WordNet for full-coverage word sense disambiguation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5682–5691. [Google Scholar] [CrossRef] [Green Version]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31th Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Yuan, D.; Richardson, J.; Doherty, R.; Evans, C.; Altendorf, E. Semi-supervised word sense disambiguation with neural models. In Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016), Osaka, Japan, 11–16 December 2016; pp. 1374–1385. [Google Scholar]
- Kageback, M.; Salomonsson, H. Word sense disambiguation using a bidirectional lstm. arXiv 2016, arXiv:1606.03568. [Google Scholar]
- Raganato, A.; Camacho-Collados, J.; Navigli, R. Word Sense Disambiguation: A Unified Evaluation Framework and Empirical Comparison. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers (EACL), Valencia, Spain, 3–7 April 2017; pp. 99–110. [Google Scholar]
- Liu, X.; Chen, Q.; Liu, Y.; Hu, B.; Siebert, J.; Wu, X.; Tang, B. Decomposing Word Embedding with the Capsule Network. Knowl. Based Syst. 2021, 212, 106611. [Google Scholar] [CrossRef]
- Miller, G. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Yang, M.; Zhao, W.; Ye, J.; Lei, Z.; Zhao, Z.; Zhang, S. Investigating Capsule Networks with Dynamic Routing for Text Classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3110–3119. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Chen, X.; Zhang, W.; Chen, H. Attention-Based Capsule Networks with Dynamic Routing for Relation Extraction. arXiv 2018, arXiv:1812.11321. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Li, J.; Yang, B.; Dou, Z.; Wang, X.; Lyu, M.R.; Tu, Z. Information Aggregation for Multi-Head Attention with Routing-by Agreement. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), New Orleans, LA, USA, 1–6 June 2019; pp. 3566–3575. [Google Scholar]
- Duan, S.; Cao, J.; Zhao, H. Capsule-Transformer for Neural Machine Translation. arXiv 2019, arXiv:2004.14649. [Google Scholar]
- Gu, S.; Feng, Y. Improving Multi-Head Attention with Capsule Networks. In Proceedings of the 8th Conferernce of Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; pp. 314–326. [Google Scholar]
- Miller, G.A.; Chodorow, M.; Landes, S.; Leacock, C.; Thomas, R.G. Using a semantic concordance for sense identification. In Proceedings of the workshop on Human Language Technology, Plainsboro, NJ, USA, 8–11 March 1994; pp. 240–243. [Google Scholar]
- Edmonds, P.; Cotton, S. SENSEVAL-2: Overview. In Proceedings of the Second International Workshop on Evaluating Word Sense Disambiguation Systems, SENSEVAL ’01, Toulouse, France, 5–6 July 2001; pp. 1–5. [Google Scholar]
- Snyder, B.; Palmer, M. The english all-words task. Proceedings of SENSEVAL-3, the Third International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 41–43. [Google Scholar]
- Pradhan, S.; Loper, E.; Dligach, D.; Palmer, M. Semeval-2007 task-17: English lexical sample, srl and all words. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Prague, Czech Republic, 23–24 June 2007; pp. 87–92. [Google Scholar]
- Navigli, R.; Jurgens, D.; Vannella, D. Semeval-2013 Task 12: Multilingual Word Sense Disambiguation. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2 and the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; pp. 222–231. [Google Scholar]
- Moro, A.; Navigli, R. Semeval2015 task 13: Multilingual all-words sense disambiguation and entity linking. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 288–297. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Moro, A.; Raganato, A.; Navigli, R. Entity linking meets word sense disambiguation: A unified approach. Trans. Assoc. Comput. Linguist. 2014, 2, 231–244. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Salakhutdinov, R. Knowledge-based Word Sense Disambiguation using Topic Models. Proceedings of 30th Innovative Applications of Artificial Intelligence Conference, New Orleans, LA, USA, 2–7 February 2018; pp. 5062–5069. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Docs | Sents | Noun | Verb | Adj | Adv | Total | Ambiguity |
|---|---|---|---|---|---|---|---|---|
| SemCor | 352 | 37,176 | 87,002 | 88,334 | 31,753 | 18,947 | 226,036 | 6.8 |
| SE2 | 3 | 242 | 1066 | 517 | 445 | 254 | 2282 | 5.4 |
| SE3 | 3 | 352 | 900 | 588 | 350 | 12 | 1850 | 6.8 |
| SE07 | 3 | 135 | 159 | 296 | 0 | 0 | 455 | 8.5 |
| SE13 | 13 | 306 | 1644 | 0 | 0 | 0 | 1644 | 4.9 |
| SE15 | 4 | 138 | 531 | 251 | 160 | 80 | 1022 | 5.5 |
| Dev | Test | Concatenation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| System | SE07 | SE2 | SE3 | SE13 | SE15 | Noun | Verb | Adj | Adv | All |
| Knowledge-based | ||||||||||
| MFS baseline | 54.5 | 65.6 | 66.0 | 63.8 | 67.1 | 67.7 | 49.8 | 73.1 | 80.5 | 65.5 |
| WordNet S1 | 55.2 | 66.8 | 66.2 | 63.0 | 67.8 | 67.6 | 50.3 | 74.3 | 80.9 | 65.2 |
| Lesk+ext,emb | 56.7 | 63.0 | 63.7 | 66.2 | 64.6 | 70.0 | 51.1 | 51.7 | 80.6 | 64.2 |
| Babelfy | 51.6 | 67.0 | 63.5 | 66.4 | 70.3 | 68.9 | 50.7 | 73.2 | 80.5 | 65.5 |
| WSD-TM | 55.6 | 69.0 | 66.9 | 65.3 | 69.6 | 69.7 | 51.2 | 76.0 | 80.9 | 66.9 |
| Traditional Supervised | ||||||||||
| IMS | 61.3 | 70.9 | 69.3 | 65.3 | 69.5 | 70.5 | 55.8 | 75.6 | 82.9 | 68.9 |
| IMS+emb | 62.6 | 72.2 | 70.4 | 65.9 | 71.5 | 71.9 | 56.6 | 75.9 | 84.7 | 70.1 |
| Neural-based | ||||||||||
| Bi-LSTM+att,LEX,POS | 64.8 | 72.0 | 69.1 | 66.9 | 71.5 | 71.5 | 57.5 | 75.0 | 83.8 | 69.9 |
| GASext(concatenation) | - | 72.2 | 70.5 | 67.2 | 72.6 | 72.2 | 57.7 | 76.6 | 85.0 | 70.6 |
| EWISE | 67.3 | 73.8 | 71.1 | 69.4 | 74.5 | 74.0 | 60.2 | 78.0 | 82.1 | 71.8 |
| LMMS2348(BERT) | 68.1 | 76.3 | 75.6 | 75.1 | 77.0 | - | - | - | - | 75.4 |
| GlossBERT | 72.5 | 77.7 | 75.2 | 76.1 | 80.4 | 79.8 | 67.1 | 79.6 | 87.4 | 77.0 |
| CapsDecE2Slarge | 68.7 | 78.9 | 77.4 | 75.6 | 77.1 | - | - | - | - | 76.9 |
| CapsDecE2Slarge+LMMS | 73.8 | 78.8 | 80.7 | 76.6 | 79.4 | - | - | - | - | 78.6 |
| Ours | 75.2 | 79.6 | 78.4 | 79.9 | 81.9 | 81.7 | 69.5 | 83.7 | 88.2 | 79.5 |
| Word Frequency | 0 | 1–10 | 11–50 | >50 |
|---|---|---|---|---|
| WordNet S1 | 84.9 | 70.6 | 65.4 | 58.0 |
| Lesk+ext,emb | 88.2 | 68.6 | 64.6 | 55.2 |
| Babelfy | 89 | 71.4 | 67.3 | 56.0 |
| EWISE | 91.0 | 73.4 | 72.5 | 66.3 |
| ours | 93.0 | 80.8 | 76.9 | 70.3 |
| System | MFS | LFS |
|---|---|---|
| WordNet S1 | 100.0 | 0.0 |
| Lesk+ext,emb | 92.7 | 9.4 |
| Babelfy | 93.9 | 12.2 |
| EWISE | 93.5 | 31.2 |
| ours | 94.0 | 60.2 |
| Model Ablation | Total | MFS | LFS |
|---|---|---|---|
| BERT-base | 68.4 | 94.7 | 36.9 |
| BERT-base+gloss | 78.9 | 94.1 | 51.7 |
| BERT-base+gloss,SR | 79.2 | 93.5 | 57.2 |
| BERT-base+gloss,HR | 79.1 | 93.4 | 57.3 |
| BiCapAtt | 79.5 | 94.0 | 60.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, J.; Tong, W.; Yan, W. Capsule Network Improved Multi-Head Attention for Word Sense Disambiguation. Appl. Sci. 2021, 11, 2488. https://doi.org/10.3390/app11062488
Cheng J, Tong W, Yan W. Capsule Network Improved Multi-Head Attention for Word Sense Disambiguation. Applied Sciences. 2021; 11(6):2488. https://doi.org/10.3390/app11062488
Chicago/Turabian StyleCheng, Jinfeng, Weiqin Tong, and Weian Yan. 2021. "Capsule Network Improved Multi-Head Attention for Word Sense Disambiguation" Applied Sciences 11, no. 6: 2488. https://doi.org/10.3390/app11062488
APA StyleCheng, J., Tong, W., & Yan, W. (2021). Capsule Network Improved Multi-Head Attention for Word Sense Disambiguation. Applied Sciences, 11(6), 2488. https://doi.org/10.3390/app11062488