
Classification of Full Text Biomedical Documents: Sections Importance Assessment

 ,
,  ,
,  and
and
Abstract
:1. Introduction
1.1. Related Work
2. Theory
2.1. The Vector Space Model
2.2. Assigning Weight to Sections
3. Material and Methods
3.1. Dataset Characterization
3.2. Document Pre-Processing
- Special characters removal: punctuation, digits and some special characters such as etc.) are removed. Characters such as “+” and “−” are not removed because they might be important in some biology domains (for example: “blood-lead”).
- Tokenization, which splits the document sections into tokens, e.g., terms.
- Stopwords removal, which removes words that are meaningless such as articles, conjunctions and prepositions (e.g., “a”, “the”, “at”, etc.). We have used a list of 659 stopwords to be identified and removed from the documents.
- Dictionary Validation: A term is considered valid if it appears in a dictionary. We have gathered several dictionaries for common English terms (such as ISPELL (http://www.lasr.cs.ucla.edu/geoff/ispell.html, accessed on 7 March 2021) and WordNet (http://wordnet.princeton.edu/, accessed on 7 March 2021) [21]), and for biological and medical terms: BioLexicon [22], The Hosford Medical Terms Dictionary and Gene Ontology (http://www.geneontology.org/, accessed on 7 March 2021) (GO). We decided to accept a term if and only if it appears in one of the mentioned dictionaries.
- Synonyms handling, using the WordNet (an English lexical database) for regular English (“non technical” words) and Gene Ontology for technical terms. Handling synonyms makes it possible to significantly reduce the number of attributes in the datasets without changing the semantic of words.
- Stemming, this process removes inflectional affixes of words, thus reducing the words to their root. We have implemented the Porter Stemmer algorithm [23].
- Feature Selection: Feature selection is the process of identifying the relevant features (strong and weak attributes), e.g., the set of features that best represent the data [24]. Information Gain was used to determine which attribute in a given set of training feature vectors is most useful for discriminating between the classes to be learned [25,26]. In document classification, Information Gain measures the number of bits of information gained, with respect to deciding the class to which a document belongs, by using each word frequency of occurrence in the document [27]. We used the WEKA (Waikato Environment for Knowledge Analysis) implementation of the Information Gain attribute selector (called Info Gain Attribute Eval) [28,29], in order to determine the effectiveness of the attributes with a threshold cut greater than 0. It is important to note that this final step is applied with the proposed term-section weighing as input.
4. Results
4.1. Experimental Data
4.2. Experiments
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Salton, G. The SMART Retrieval System—Experiments in Automatic Document Processing; Prentice-Hall Inc.: Upper Saddle River, NJ, USA, 1971. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Machine Learning: ECML-98; Nédellec, C., Rouveirol, C., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Sun, Z.; Errami, M.; Long, T.; Renard, C.; Choradia, N.; Garner, H. Systematic characterizations of text similarity in full text biomedical publications. PLoS ONE 2010, 5, e12704. [Google Scholar] [CrossRef] [PubMed]
- Westergaard, D.; Stærfeldt, H.H.; Tønsberg, C.; Jensen, L.J.; Brunak, S. A comprehensive and quantitative comparison of text-mining in 15 million full-text articles versus their corresponding abstracts. PLoS Comput. Biol. 2018, 14, e1005962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J. Is searching full text more effective than searching abstracts? BMC Bioinform. 2009, 10, 46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pérez-Agüera, J.R.; Arroyo, J.; Greenberg, J.; Iglesias, J.P.; Fresno, V. Using BM25F for Semantic Search. In Proceedings of the 3rd International Semantic Search Workshop (SEMSEARCH’10), Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Guo, Y.; Chen, D.; Le, J. An Extended Vector Space Model for XML Information Retrieval. In Proceedings of the Second International Workshop on Knowledge Discovery and Data Mining, Moscow, Russia, 23–25 January 2009. [Google Scholar]
- Ai, Q.; Yang, L.; Guo, J.; Croft, W.B. Analysis of the Paragraph Vector Model for Information Retrieval. In Proceedings of the 2016 ACM International Conference on the Theory of Information Retrieval, Newark, DE, USA, 12–16 September 2016. [Google Scholar]
- Sinclair, G.; Webber, B.L. Classification from full text: A comparison of canonical sections of scientific papers. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP), Geneva, Switzerland, 28–29 August 2004. [Google Scholar]
- Mullen, T.; Mizuta, Y.; Collier, N. A baseline feature set for learning rhetorical zones using full articles in the biomedical domain. SIGKDD Explor. Newsl. 2005, 7, 52–58. [Google Scholar] [CrossRef]
- Habib, R.; Afzal, M.T. Sections-based bibliographic coupling for research paper recommendation. Scientometrics 2019, 119, 643–656. [Google Scholar] [CrossRef]
- Collins, E.; Augenstein, I.; Riedel, S. A supervised approach to extractive summarisation of scientific papers. In Proceedings of the CoNLL 2017—21st Conference on Computational Natural Language Learning, Vancouver, BC, Canada, 3–4 August 2017; pp. 195–205. [Google Scholar]
- Li, T.; Lepage, Y. Informative sections and relevant words for the generation of NLP article abstracts. In Proceedings of the 25th Annual Meeting of the Japanese Association for Natural Language Processing, Nagoya, Japan, 12–15 March 2019; pp. 1281–1284. [Google Scholar]
- Thijs, B. Using neural-network based paragraph embeddings for the calculation of within and between document similarities. Scientometrics 2020, 155, 835–849. [Google Scholar] [CrossRef]
- Hebler, N.; Rottmann, M.; Ziegler, A. Empirical analysis of the text structure of original research articles in medical journals. PLoS ONE 2020, 15, e0240288. [Google Scholar]
- Zhou, W.; Smalheiser, N.R.; Clement, Y. A tutorial on information retrieval: Basic terms and concepts. J. Biomed. Discov. Collab. 2006, 1, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inform. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Hersh, W.; Buckley, C.; Leone, T.J.; Hickam, D. Ohsumed: An Interactive Retrieval Evaluation and New Large Test Collection for Research; Croft, B.W., van Rijsbergen, C.J., Eds.; Springer: London, UK, 1994; pp. 192–201. [Google Scholar]
- Gonçalves, C.A.; Gonçalves, C.T.; Camacho, R.; Oliveira, E.C. The impact of pre-processing on the classification of MEDLINE documents. In Proceedings of the 10th International Workshop on Pattern Recognition in Information Systems, Porto, Portugal, 8–9 June 2010; pp. 53–61. [Google Scholar]
- Fellbaum, C. (Ed.) WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Rebholz-Schuhmann, D.; Pezik, P.; Lee, V.; Kim, J.-J.; del Gratta, R.; Sasaki, Y.; McNaught, J.; Montemagni, S.; Monachini, M.; Calzolari, N.; et al. Biolexicon: Towards a reference terminological resource in the biomedical domain. In Proceedings of the 16th Annual International Conference on Intelligent Systems for Molecular Biology (ISMB-2008), Toronto, ON, Canada, 19–23 July 2008. [Google Scholar]
- Porter, M.F. An Algorithm for Suffix Stripping. In Readings in Information Retrieval; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 313–316. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, Department Of Computer Science, Waikato University, Waikato, New Zealand, 1999. [Google Scholar]
- Borase, P.N.; Kinariwala, S.A.; Rustagi, J.S. Image Re-Ranking Using Information Gain and Relative Consistency through Multi-Graph Learning; Foundation of Computer Science (FCS): New York, NY, USA, 2016; Volume 147, pp. 29–32. [Google Scholar]
- Seara Vieira, A.; Iglesias, E.L.; Borrajo, L. An hmm-based text classifier less sensitive to document management problems. Curr. Bioinform. 2016, 11, 503–514. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T.M. Machine Learning, 1st ed.; McGraw-Hill Inc.: New York, NY, USA, 1997. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The weka data mining software: An update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Trigg, L.; Hall, M.; Holmes, G.; Cunningham, S.J. Weka: Practical Machine Learning Tools and Techniques with Java Implementations. 1999. Available online: https://researchcommons.waikato.ac.nz/handle/10289/1040 (accessed on 7 March 2021).
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementation; Morgan Kaufmann: San Francisco, CA, USA, 2000. [Google Scholar]
- Carletta, S. Assessing Agreement on Classification Tasks: The Kappa Statistic. Comput. Ling. 1996, 22, 249–254. [Google Scholar]
- Gonçalves, C.A.; Iglesias, E.L.; Borrajo, L.; Camacho, R.; Seara Vieira, A.; Gonçalves, C.T. Learnsec: A framework for full text analysis. In Proceedings of the 13th International Conference on Hybrid Artificial Intelligence Systems HAIS, Oviedo, Spain, 20–22 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10870, pp. 502–513. [Google Scholar]


{kind=link}
| Corpus | Definition | Relevant# | Non-Relevant# |
|---|---|---|---|
| c01 | Bacterial Infections & Mycoses | 423 | 14,141 |
| c02 | Virus Diseases | 1184 | 13,467 |
| c03 | Parasitic Diseases | 64 | 14,208 |
| c04 | Neoplasms | 5594 | 9072 |
| c05 | Musculoskeletal Diseases | 338 | 13,978 |
| c06 | Digestive System Diseases | 1688 | 12,909 |
| c07 | Stomatognathic Diseases | 146 | 13,961 |
| c08 | Respiratory Tract Diseases | 864 | 13,656 |
| c09 | Otorhinolaryngologic Diseases | 215 | 14,280 |
| c10 | Nervous System Diseases | 2826 | 11,809 |
| c11 | Eye Diseases | 394 | 14,149 |
| c12 | Urologic & Male Genital Diseases | 1206 | 13,369 |
| c13 | Female Genital Diseases & Pregnancy Compl. | 1117 | 13,397 |
| c14 | Cardiovascular Diseases | 2607 | 12,044 |
| c15 | Hemic & Lymphatic Diseases | 459 | 14,102 |
| c16 | Neonatal Diseases & Abnormalities | 475 | 14,056 |
| c17 | Skin & Connective Tissue Diseases | 1236 | 13,437 |
| c18 | Nutritional & Metabolic Diseases | 1067 | 13,606 |
| c19 | Endocrine Diseases | 780 | 13,760 |
| c20 | Immunologic Diseases | 1744 | 12,929 |
| c21 | Disorders of Environmental Origin | 1 | 14,672 |
| c22 | Animal Diseases | 79 | 14,594 |
| c23 | Pathological Conditions, Signs & Symptoms | 7350 | 7271 |
| c24 | Occupational Diseases | 17 | 12,676 |
| c25 | Chemically-Induced Disorders | 176 | 14,336 |
| c26 | Wounds & Injuries | 253 | 14,230 |
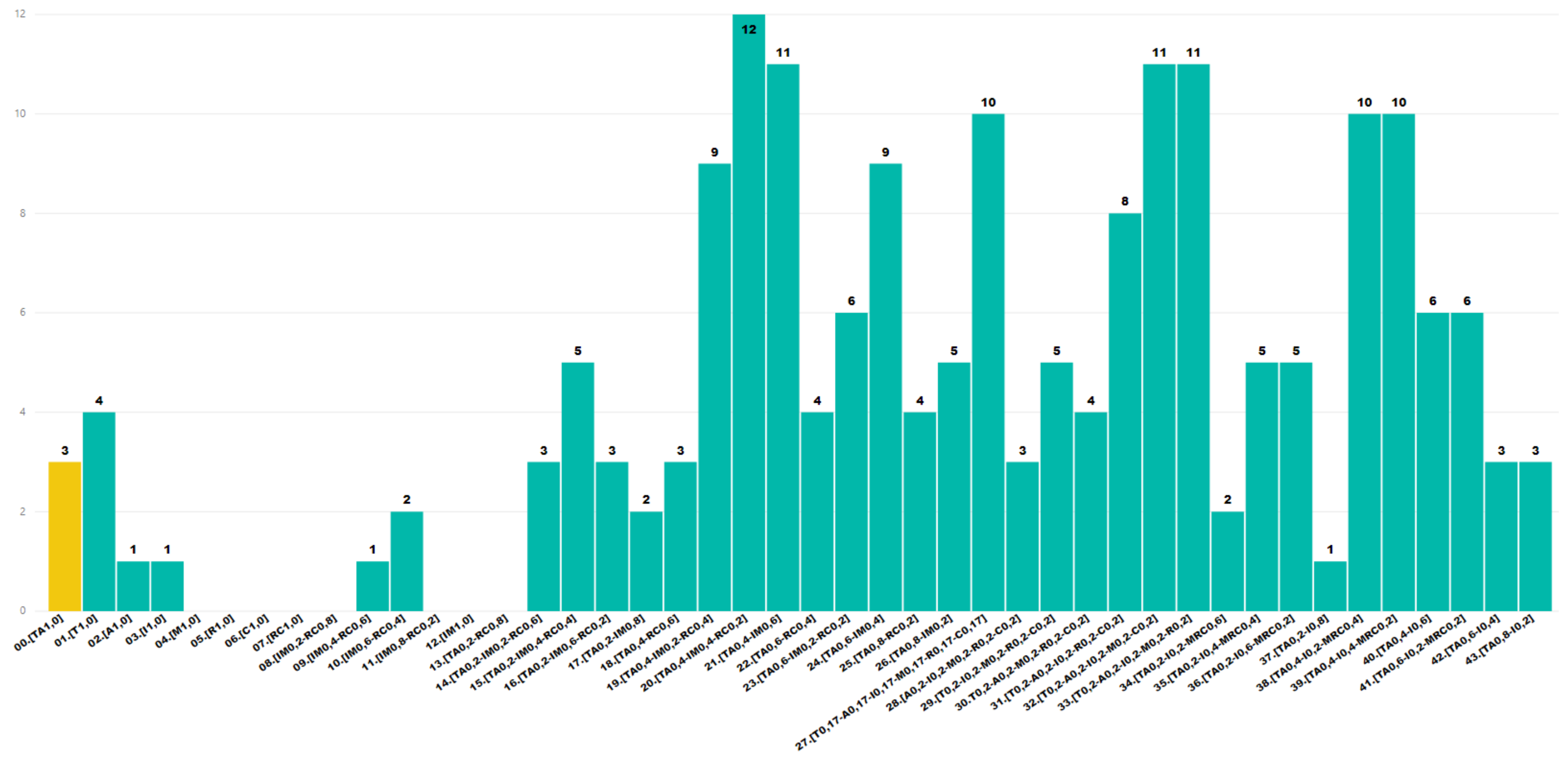
| WEIGHING COMBINATION | (T) | (A) | (I) | (M) | (R) | (C) |
|---|---|---|---|---|---|---|
| 00. [TA1,0] | 1.0 | 0 | 0 | 0 | 0 | |
| 01. [T1,0] | 1.0 | 0 | 0 | 0 | 0 | 0 |
| 02. [A1,0] | 0 | 1.0 | 0 | 0 | 0 | 0 |
| 03. [I1,0] | 0 | 0 | 1.0 | 0 | 0 | 0 |
| 04. [M1,0] | 0 | 0 | 0 | 1.0 | 0 | 0 |
| 05. [R1,0] | 0 | 0 | 0 | 0 | 1.0 | 0 |
| 06. [C1,0] | 0 | 0 | 0 | 0 | 0 | 1.0 |
| 07. [RC1,0] | 0 | 0 | 0 | 0 | 1.0 | |
| 08. [IM0,2-RC0,8] | 0 | 0 | 0.2 | 0.8 | ||
| 09. [IM0,4-RC0,6] | 0 | 0 | 0.4 | 0.6 | ||
| 10. [IM0,6-RC0,4] | 0 | 0 | 0.6 | 0.4 | ||
| 11. [IM0,8-RC0,2] | 0 | 0 | 0.8 | 0.2 | ||
| 12. [IM1,0] | 0 | 0 | 1.0 | 0 | 0 | |
| 13. [TA0,2-RC0,8] | 0.2 | 0 | 0 | 0.8 | ||
| 14. [TA0,2-IM0,2-RC0,6] | 0.2 | 0.2 | 0.6 | |||
| 15. [TA0,2-IM0,4-RC0,4] | 0.2 | 0.4 | 0.4 | |||
| 16. [TA0,2-IM0,6-RC0,2] | 0.2 | 0.6 | 0.2 | |||
| 17. [TA0,2-IM0,8] | 0.2 | 0.8 | 0 | 0 | ||
| 18. [TA0,4-RC0,6] | 0.4 | 0 | 0 | 0.6 | ||
| 19. [TA0,4-IM0,2-RC0,4] | 0.4 | 0.2 | 0.4 | |||
| 20. [TA0,4-IM0,4-RC0,2] | 0.4 | 0.4 | 0.2 | |||
| 21. [TA0,4-IM0,6] | 0.4 | 0.6 | 0 | 0 | ||
| 22. [TA0,6-RC0,4] | 0.6 | 0 | 0 | 0.4 | ||
| 23. [TA0,6-IM0,2-RC0,2] | 0.6 | 0.2 | 0.2 | |||
| 24. [TA0,6-IM0,4] | 0.6 | 0.4 | 0 | 0 | ||
| 25. [TA0,8-RC0,2] | 0.8 | 0 | 0 | 0.2 | ||
| 26. [TA0,8-IM0,2] | 0.8 | 0.2 | 0 | 0 | ||
| 27. [T0,17-A0,17-I0,17-M0,17-R0,17-C0,17] | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 |
| 28. [A0,2-I0,2-M0,2-R0,2-C0,2] | 0 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 |
| 29. [T0,2-I0,2-M0,2-R0,2-C0,2] | 0.2 | 0 | 0.2 | 0.2 | 0.2 | 0.2 |
| 30. [T0,2-A0,2-M0,2-R0,2-C0,2] | 0.2 | 0.2 | 0 | 0.2 | 0.2 | 0.2 |
| 31. [T0,2-A0,2-I0,2-R0,2-C0,2] | 0.2 | 0.2 | 0.2 | 0 | 0.2 | 0.2 |
| 32. [T0,2-A0,2-I0,2-M0,2-C0,2] | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0.2 |
| 33. [T0,2-A0,2-I0,2-M0,2-R0,2] | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0 |
| 34. [TA0,2-I0,2-MRC0,6] | 0.2 | 0.2 | 0.6 | |||
| 35. [TA0,2-I0,4-MRC0,4] | 0.2 | 0.4 | 0.4 | |||
| 36. [TA0,2-I0,6-MRC0,2] | 0.2 | 0.6 | 0.2 | |||
| 37. [TA0,2-I0,8] | 0.2 | 0.8 | 0 | 0 | 0 | |
| 38. [TA0,4-I0,2-MRC0,4] | 0.4 | 0.2 | 0.4 | |||
| 39. [TA0,4-I0,4-MRC0,2] | 0.4 | 0.4 | 0.2 | |||
| 40. [TA0,4-I0,6] | 0.4 | 0.6 | 0 | 0 | 0 | |
| 41. [TA0,6-I0,2-MRC0,2] | 0.6 | 0.2 | 0.2 | |||
| 42. [TA0,6-I0,4] | 0.6 | 0.4 | 0 | 0 | 0 | |
| 43. [TA0,8-I0,2] | 0.8 | 0.2 | 0 | 0 | 0 | |
| Nº | c02 | c04 | c06 | c08 | c10 | c11 | c12 | c13 | c14 | c17 | c19 | c20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | 0.730 | 0.683 | 0.720 | |||||||||
| 01 | 0.755 | 0.686 | 0.743 | 0.750 | ||||||||
| 02 | 0.746 | |||||||||||
| 03 | 0.810 | |||||||||||
| 09 | 0.809 | |||||||||||
| 10 | 0.702 | 0.684 | ||||||||||
| 14 | 0.812 | 0.745 | 0.778 | |||||||||
| 15 | 0.816 | 0.892 | 0.708 | 0.753 | 0.782 | |||||||
| 16 | 0.815 | 0.707 | 0.755 | |||||||||
| 17 | 0.811 | 0.743 | ||||||||||
| 18 | 0.715 | 0.681 | 0.696 | |||||||||
| 19 | 0.745 | 0.723 | 0.711 | 0.705 | 0.792 | 0.690 | 0.744 | 0.702 | 0.782 | |||
| 20 | 0.808 | 0.894 | 0.746 | 0.725 | 0.716 | 0.715 | 0.794 | 0.696 | 0.770 | 0.750 | 0.712 | 0.777 |
| 21 | 0.814 | 0.895 | 0.747 | 0.728 | 0.711 | 0.718 | 0.792 | 0.691 | 0.768 | 0.748 | 0.714 | |
| 22 | 0.726 | 0.788 | 0.687 | 0.713 | ||||||||
| 23 | 0.736 | 0.708 | 0.707 | 0.794 | 0.697 | 0.718 | ||||||
| 24 | 0.893 | 0.742 | 0.734 | 0.712 | 0.708 | 0.793 | 0.698 | 0.747 | 0.719 | |||
| 25 | 0.732 | 0.782 | 0.685 | 0.715 | ||||||||
| 26 | 0.738 | 0.711 | 0.786 | 0.696 | 0.719 | |||||||
| 27 | 0.813 | 0.894 | 0.747 | 0.724 | 0.713 | 0.713 | 0.789 | 0.771 | 0.750 | 0.703 | ||
| 28 | 0.813 | 0.707 | 0.700 | |||||||||
| 29 | 0.716 | 0.717 | 0.788 | 0.695 | 0.694 | |||||||
| 30 | 0.742 | 0.787 | 0.695 | 0.698 | ||||||||
| 31 | 0.894 | 0.726 | 0.708 | 0.785 | 0.693 | 0.747 | 0.705 | 0.779 | ||||
| 32 | 0.895 | 0.745 | 0.726 | 0.711 | 0.714 | 0.796 | 0.700 | 0.768 | 0.749 | 0.711 | 0.778 | |
| 33 | 0.811 | 0.893 | 0.748 | 0.730 | 0.717 | 0.707 | 0.790 | 0.688 | 0.749 | 0.708 | 0.782 | |
| 34 | 0.815 | 0.750 | ||||||||||
| 35 | 0.816 | 0.892 | 0.708 | 0.753 | 0.782 | |||||||
| 36 | 0.810 | 0.710 | 0.785 | 0.683 | 0.748 | |||||||
| 37 | 0.697 | |||||||||||
| 38 | 0.809 | 0.746 | 0.719 | 0.713 | 0.708 | 0.792 | 0.697 | 0.749 | 0.704 | 0.783 | ||
| 39 | 0.894 | 0.742 | 0.731 | 0.711 | 0.719 | 0.794 | 0.694 | 0.769 | 0.748 | 0.712 | ||
| 40 | 0.893 | 0.732 | 0.784 | 0.693 | 0.745 | 0.721 | ||||||
| 41 | 0.736 | 0.708 | 0.707 | 0.794 | 0.695 | 0.718 | ||||||
| 42 | 0.740 | 0.700 | 0.724 | |||||||||
| 43 | 0.741 | 0.695 | 0.722 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oliveira Gonçalves, C.A.; Camacho, R.; Gonçalves, C.T.; Seara Vieira, A.; Borrajo Diz, L.; Lorenzo Iglesias, E. Classification of Full Text Biomedical Documents: Sections Importance Assessment. Appl. Sci. 2021, 11, 2674. https://doi.org/10.3390/app11062674
Oliveira Gonçalves CA, Camacho R, Gonçalves CT, Seara Vieira A, Borrajo Diz L, Lorenzo Iglesias E. Classification of Full Text Biomedical Documents: Sections Importance Assessment. Applied Sciences. 2021; 11(6):2674. https://doi.org/10.3390/app11062674
Chicago/Turabian StyleOliveira Gonçalves, Carlos Adriano, Rui Camacho, Célia Talma Gonçalves, Adrián Seara Vieira, Lourdes Borrajo Diz, and Eva Lorenzo Iglesias. 2021. "Classification of Full Text Biomedical Documents: Sections Importance Assessment" Applied Sciences 11, no. 6: 2674. https://doi.org/10.3390/app11062674
APA StyleOliveira Gonçalves, C. A., Camacho, R., Gonçalves, C. T., Seara Vieira, A., Borrajo Diz, L., & Lorenzo Iglesias, E. (2021). Classification of Full Text Biomedical Documents: Sections Importance Assessment. Applied Sciences, 11(6), 2674. https://doi.org/10.3390/app11062674