
Dual-Mic Speech Enhancement Based on TF-GSC with Leakage Suppression and Signal Recovery


Abstract
:1. Introduction
2. Summary of TF-GSC and Postfiltering
3. Proposed TF-GSC with Leakage Suppression and Signal Recovery
3.1. Leakage Suppression
3.2. Signal Recovery
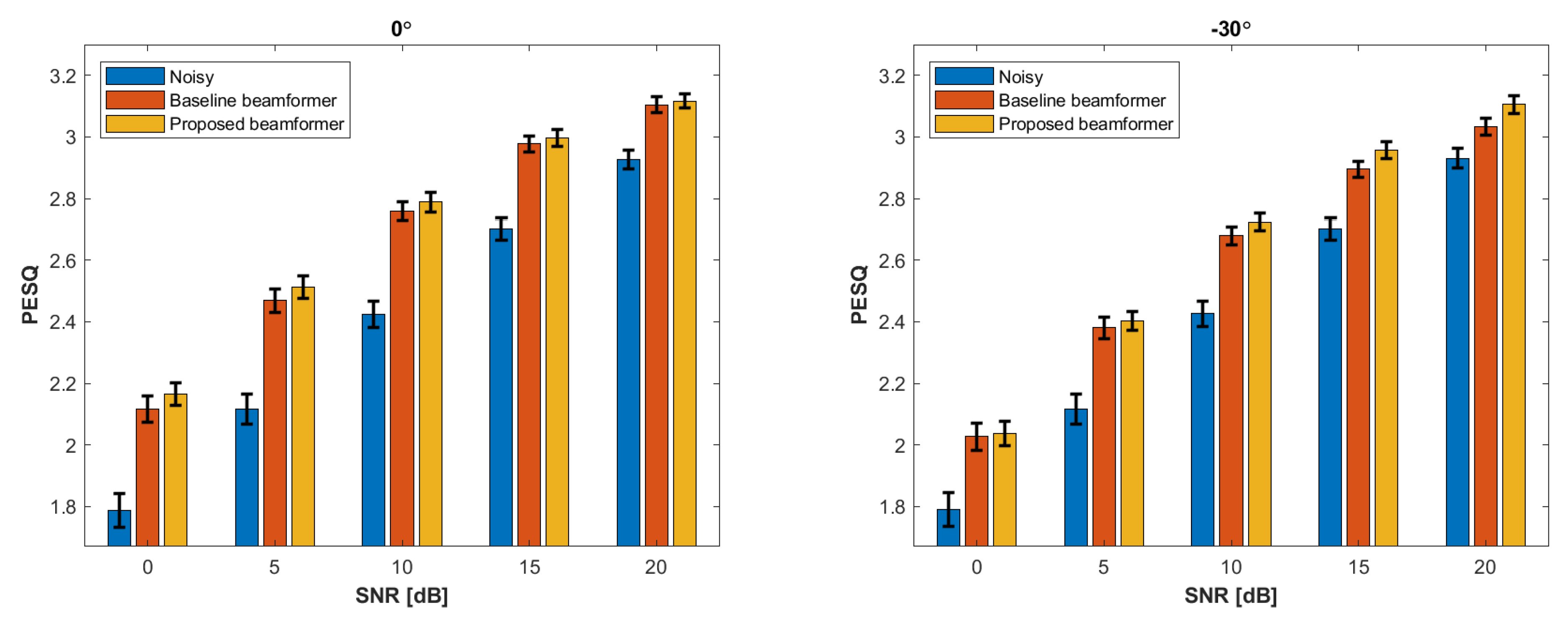
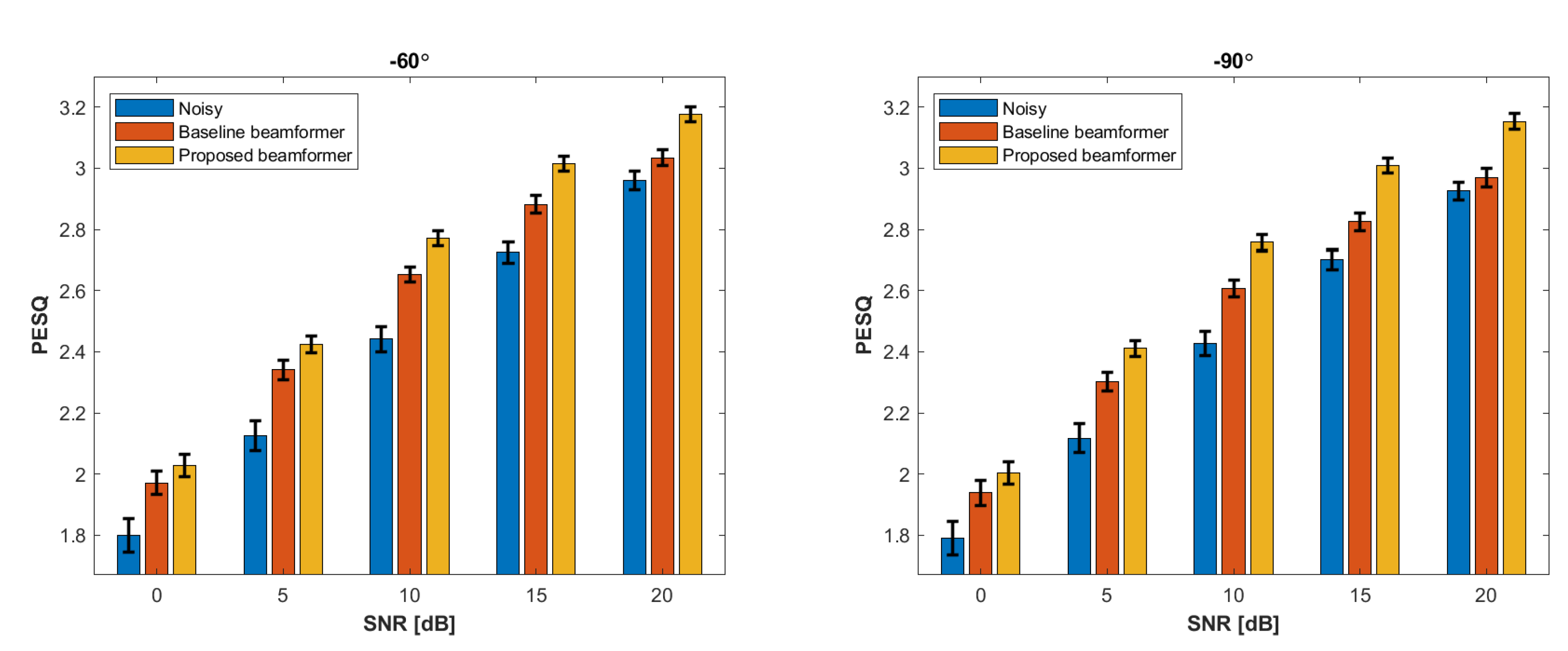
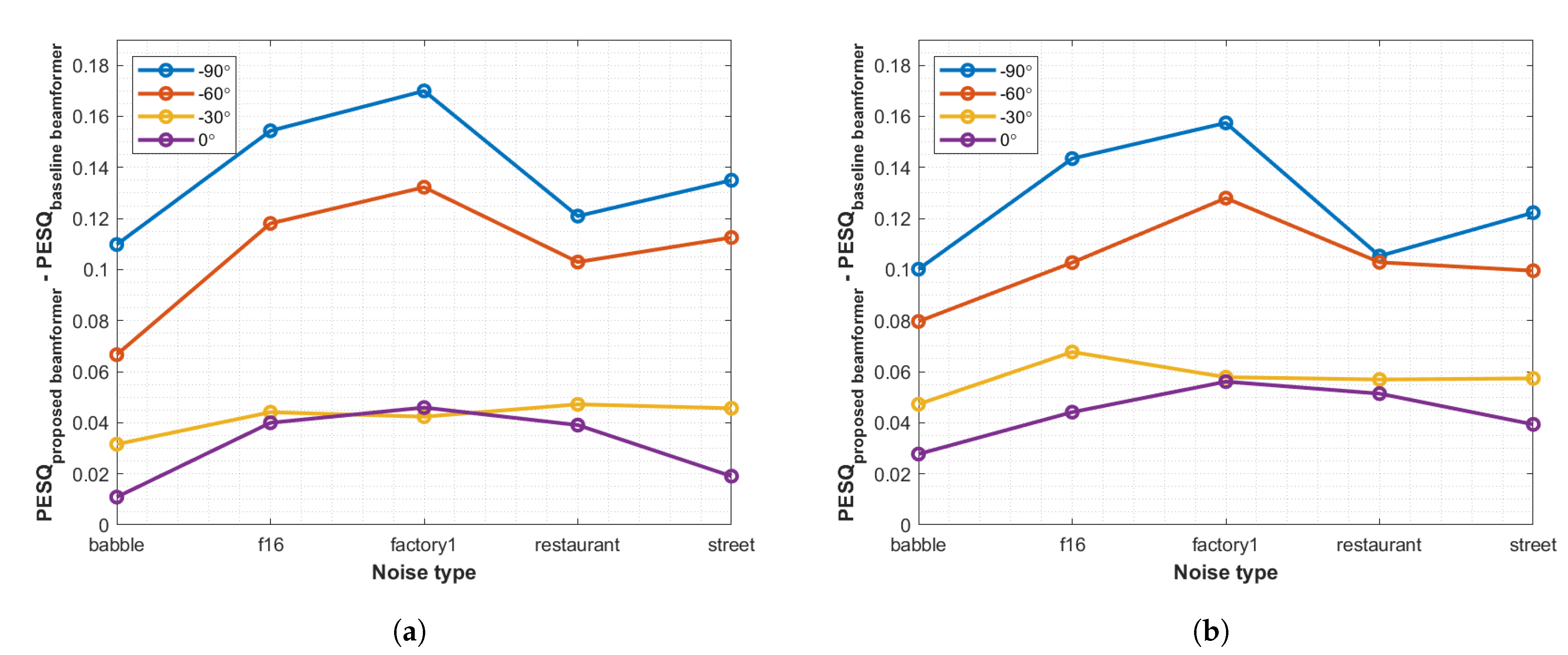
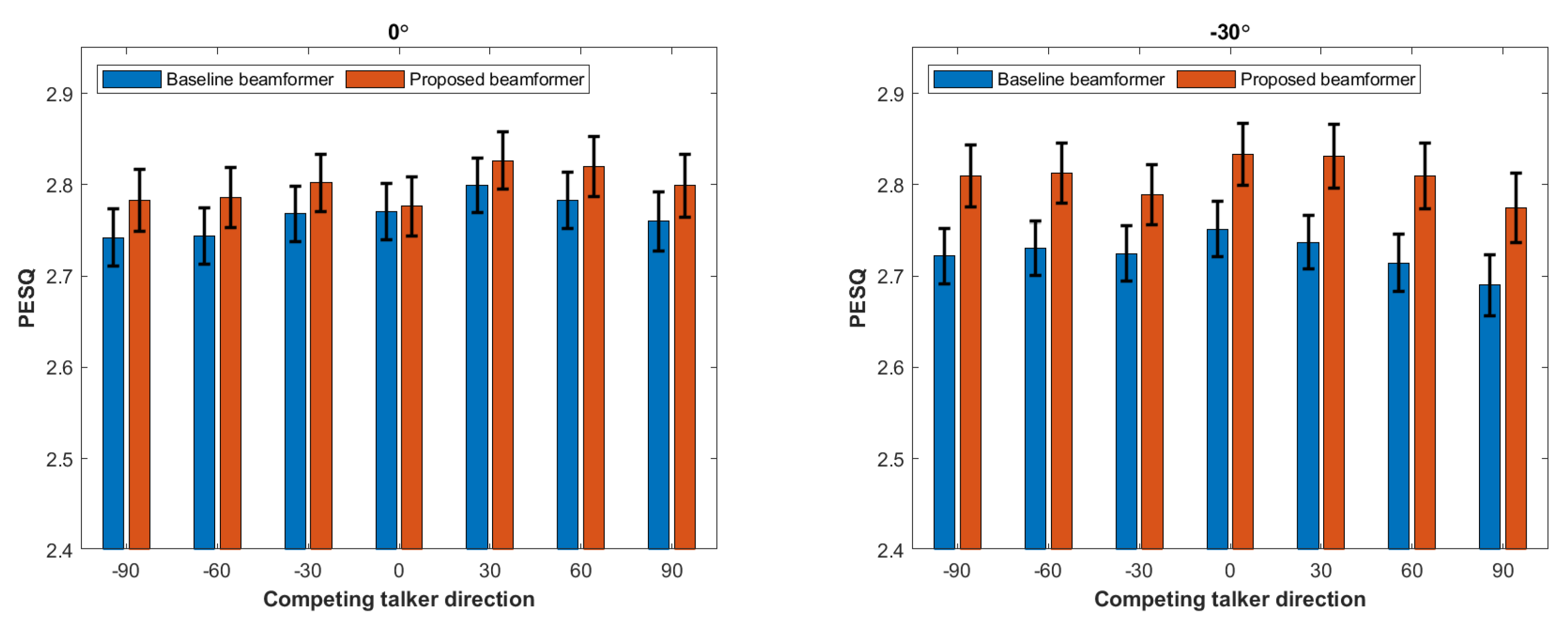
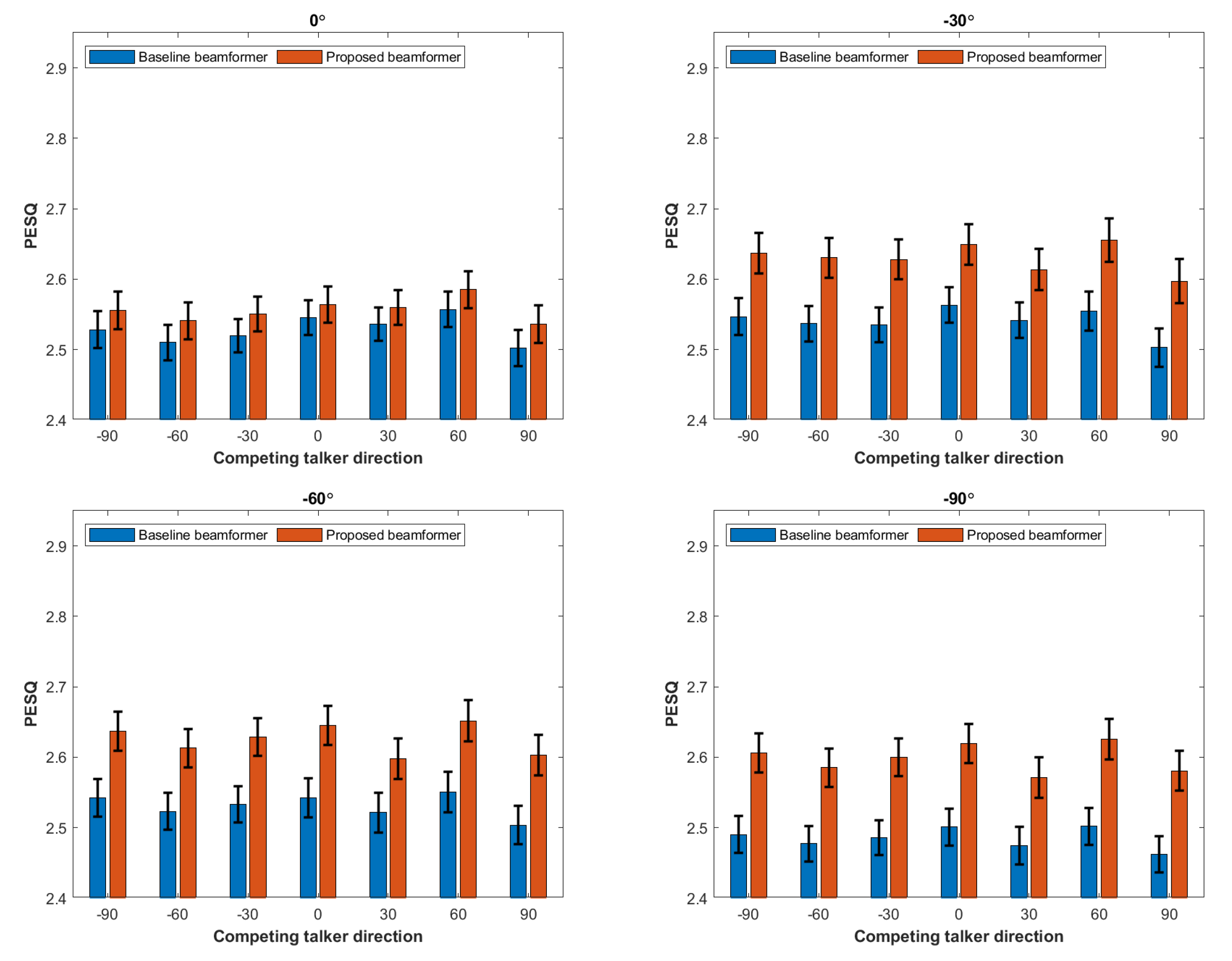
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Benesty, J.; Chen, J.; Huang, Y. Microphone Array Signal Processing; Springer-Verlag: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Gannot, S.; Vincent, E.; Markovich-Golan, S.; Ozerov, A. A Consolidated Perspective on Multimicrophone Speech Enhancement and Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 692–730. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Benesty, J.; Huang, Y.; Doclo, S. New insights into the noise reduction wiener filter. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1218–1234. [Google Scholar] [CrossRef] [Green Version]
- Bogaert, T.V.; Doclo, S.; Wouters, J.; Moonen, M. Speech enhancement with multichannel Wiener filter techniques in multimicrophone binaural hearing aids. J. Acoust. Soc. Am. 2009, 125, 360–371. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.G.; Shin, J.W.; Kim, N.S. Spectro-temporal filtering for multichannel speech enhancement in short-time Fourier transform domain. IEEE Signal Process. Lett. 2014, 21, 352–355. [Google Scholar] [CrossRef]
- Jin, Y.G.; Shin, J.W.; Kim, N.S. Decision-directed speech power spectral density matrix estimation for multichannel speech enhancement. JASA Express Lett. 2017, 141, EL228–EL233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doclo, S.; Gannot, S.; Moonen, M.; Spriet, A.; Haykin, S.; Liu, K.R. Acoustic beamforming for hearing aid applications. In Handbook on Array Processing and Sensor Networks; Haykin, S., Liu, K., Eds.; Wiley: Hoboken, NJ, USA, 2010; pp. 269–302. [Google Scholar]
- Doclo, S.; Kellermann, W.; Makino, S.; Nordholm, S.E. Multichannel signal enhancement algorithms for assisted listening devices: Exploiting spatial diversity using multiple microphones. IEEE Signal Process. Mag. 2015, 32, 18–30. [Google Scholar] [CrossRef] [Green Version]
- Benesty, J.; Sondhi, M.M.; Huang, Y. Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Dashtbozorg, B.; Abutalebi, H.R. Joint Noise Reduction and Dereverberation of Speech Using Hybrid TF-GSC and Adaptive MMSE Estimator. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 1355–1358. [Google Scholar]
- Zhang, M.; Wu, S.; Guo, W.; Ji, J. A microphone array dereverberation algorithm based on TF-GSC and postfiltering. In Proceedings of the 2016 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Nara, Japan, 1–3 June 2016. [Google Scholar]
- Cohen, I.; Berdugo, B. Microphone array post-filtering for non-stationary noise suppression. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002. [Google Scholar]
- Gannot, S.; Cohen, I. Speech enhancement based on the general transfer function GSC and postfiltering. IEEE Trans. Speech Audio Process. 2004, 12, 561–571. [Google Scholar] [CrossRef]
- Cohen, I. Multichannel post-filtering in nonstationary noise environments. IEEE Trans. Signal Process. 2004, 52, 1149–1160. [Google Scholar] [CrossRef]
- Cohen, I.; Gannot, S.; Berdugo, B. Real-Time TF-GSC in Nonstationary Noise Environments. Available online: https://israelcohen.com/wp-content/uploads/2018/05/iwaenc03.pdf (accessed on 22 March 2021).
- Cohen, I.; Gannot, S.; Berdugo, B. An integrated real-time beamforming and postfiltering system for nonstationary noise environments. EURASIP J. Adv. Signal Process. 2003, 2003, 1064–1073. [Google Scholar] [CrossRef] [Green Version]
- Van Trees, H.L. Optimum Array Processing: Part IV of Detection, Estimation, and Modulation Theory; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Gannot, S.; Burshtein, D.; Weinstein, E. Signal enhancement using beamforming and nonstationarity with applications to speech. IEEE Trans. Signal Process. 2001, 49, 1614–1626. [Google Scholar] [CrossRef] [Green Version]
- Reuven, G.; Gannot, S.; Cohen, I. Multichannel acoustic echo cancellation and noise reduction in reverberant environments using the transfer-function GSC. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007. [Google Scholar]
- Reuven, G.; Gannot, S.; Cohen, I. Joint noise reduction and acoustic echo cancellation using the transfer-function generalized sidelobe canceller. Speech Commun. 2007, 49, 623–635. [Google Scholar] [CrossRef]
- Reuven, G.; Gannot, S.; Cohen, I. Dual-source transfer-function generalized sidelobe canceller. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 711–727. [Google Scholar] [CrossRef]
- Kim, K.; Baran, R.H.; Ko, H. Extension of two-channel transfer function based generalized sidelobe canceller for dealing with both background and point-source noiser. Speech Commun. 2009, 51, 521–533. [Google Scholar] [CrossRef]
- Talmon, R.; Cohen, I.; Gannot, S. Convolutive transfer function generalized sidelobe canceler. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1420–1434. [Google Scholar] [CrossRef]
- Talmon, R.; Cohen, I.; Gannot, S. Multichannel speech enhancement using convolutive transfer function approximation in reverberant environments. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3885–3888. [Google Scholar]
- Lee, I.; Yoon, J.; Lee, Y.; Ko, H. Reinforced blocking matrix with cross channel projection for speech enhancement. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 957–960. [Google Scholar]
- Nogueira, W.; Lopez, M.; Rode, T.; Doclo, S.; Buechner, A. Individualizing a monaural beamformer for cochlear implant users. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5738–5742. [Google Scholar]
- Barnov, A.; Cohen, A.; Agmon, M.; Bracha, V.B.; Markovich-Golan, S.; Gannot, S. A dynamic TF-GSC beamformer for distributed arrays with dual-resolution speech-presence-probability estimators. In Proceedings of the 2016 IEEE International Conference on the Science of Electrical Engineering (ICSEE), Eilat, Israel, 16–18 November 2016. [Google Scholar]
- Ephraim, Y.; Van Trees, H.L. A signal subspace approach for speech enhancement. IEEE Trans. Speech Audio Process. 1995, 3, 251–266. [Google Scholar] [CrossRef]
- Wax, M.; Anu, Y. Performance analysis of the minimum variance beamformer in the presence of steering vector errors. IEEE Trans. Signal Process. 1996, 44, 938–947. [Google Scholar] [CrossRef]
- Cohen, I.; Berdugo, B. Speech enhancement for non-stationary noise environments. Signal Process. 2001, 81, 2403–2418. [Google Scholar] [CrossRef]
- Cohen, I.; Berdugo, B. Multichannel signal detection based on the transient beam-to-reference ratio. IEEE Signal Process. Lett. 2003, 10, 259–262. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing; Prentice Hall PTRs: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Scharnhorst, K. Angles in Complex Vector Spaces. Acta Appl. Math. 2001, 69, 95–103. [Google Scholar] [CrossRef]
- Mandolesi, A.L. Grassmann angles between real or complex subspaces. arXiv 2019, arXiv:1910.00147. [Google Scholar]
- Habets, E.A. Room Impulse Response Generator. 2010. Available online: https://www.audiolabs-erlangen.de/fau/professor/habets/software/rir-generator (accessed on 22 March 2021).
- Garofolo, J.S. Getting Started with the DARPA TIMIT CD-ROM: An Acoustic Phonetic Continuous Speech Database; National Institute of Standards and Technology (NIST): Gaithersburgh, MD, USA, 1988; Volume 107, p. 16.
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Hirsch, H.G.; Pearce, D. The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In Proceedings of the ASR2000-Automatic Speech Recognition: Challenges for the new Millenium ISCA Tutorial and Research Workshop (ITRW), Paris, France, 18–20 September 2000. [Google Scholar]
- Habets, E.A.; Cohen, I.; Gannot, S. Generating nonstationary multisensor signals under a spatial coherence constraint. J. Acoust. Soc. Am. 2008, 124, 2911–2917. [Google Scholar] [CrossRef] [PubMed]
- ITU-T Recommendation P.862, Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs. 2008. Available online: https://www.itu.int/rec/T-REC-P.862-200102-I/en (accessed on 22 March 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ANC update | |||
| TF ratio identification | |||
| Leakage suppression | |||
| Signal recovery |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Shin, J.W. Dual-Mic Speech Enhancement Based on TF-GSC with Leakage Suppression and Signal Recovery. Appl. Sci. 2021, 11, 2816. https://doi.org/10.3390/app11062816
Kim H, Shin JW. Dual-Mic Speech Enhancement Based on TF-GSC with Leakage Suppression and Signal Recovery. Applied Sciences. 2021; 11(6):2816. https://doi.org/10.3390/app11062816
Chicago/Turabian StyleKim, Hansol, and Jong Won Shin. 2021. "Dual-Mic Speech Enhancement Based on TF-GSC with Leakage Suppression and Signal Recovery" Applied Sciences 11, no. 6: 2816. https://doi.org/10.3390/app11062816
APA StyleKim, H., & Shin, J. W. (2021). Dual-Mic Speech Enhancement Based on TF-GSC with Leakage Suppression and Signal Recovery. Applied Sciences, 11(6), 2816. https://doi.org/10.3390/app11062816