
Acoustic Identification of the Voicing Boundary during Intervocalic Offsets and Onsets Based on Vocal Fold Vibratory Measures

 ,
,  ,
,  ,
,
Abstract
:
1. Introduction
1.1. Relative Fundamental Frequency (RFF) as an Estimate of Laryngeal Muscle Tension
1.2. Voiced/Unvoiced Boundary Detection
1.3. Current Investigation
2. Materials and Methods
2.1. Participants
2.2. Procedure
2.2.1. Participant Training
2.2.2. Experimental Setup
2.2.3. Experimental Recording
2.3. Data Analysis
2.3.1. High-Speed Video Processing
Technician Training
Experimental Data Processing
2.3.2. Manual RFF Estimation
2.3.3. Semi-Automated RFF Estimation
Acoustic Feature Selection
Feature Set Reduction
Algorithmic Modifications
2.3.4. Performance of Manual and Semi-Automated RFF Estimation Methods
2.4. Statistical Analysis
3. Results
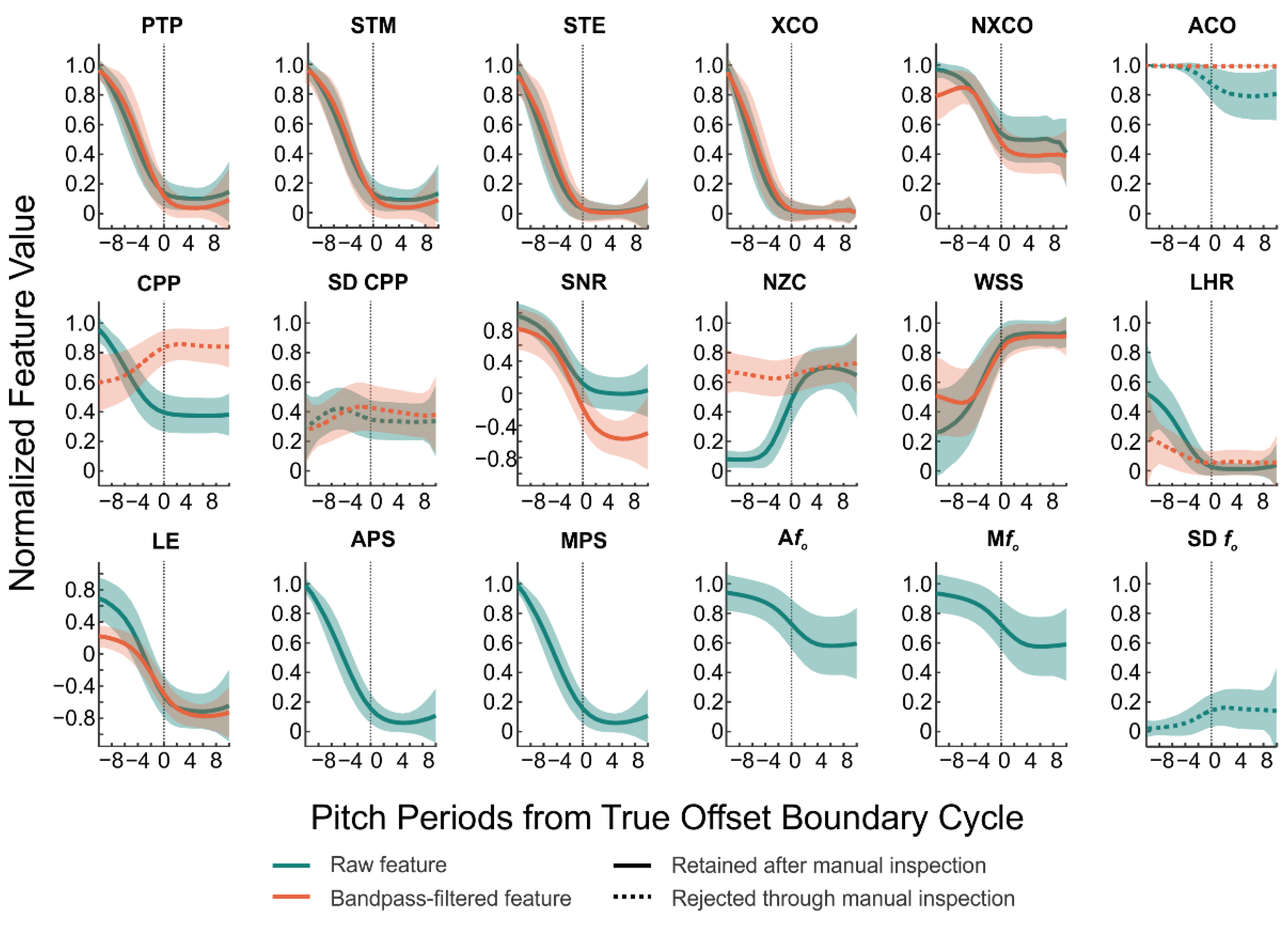
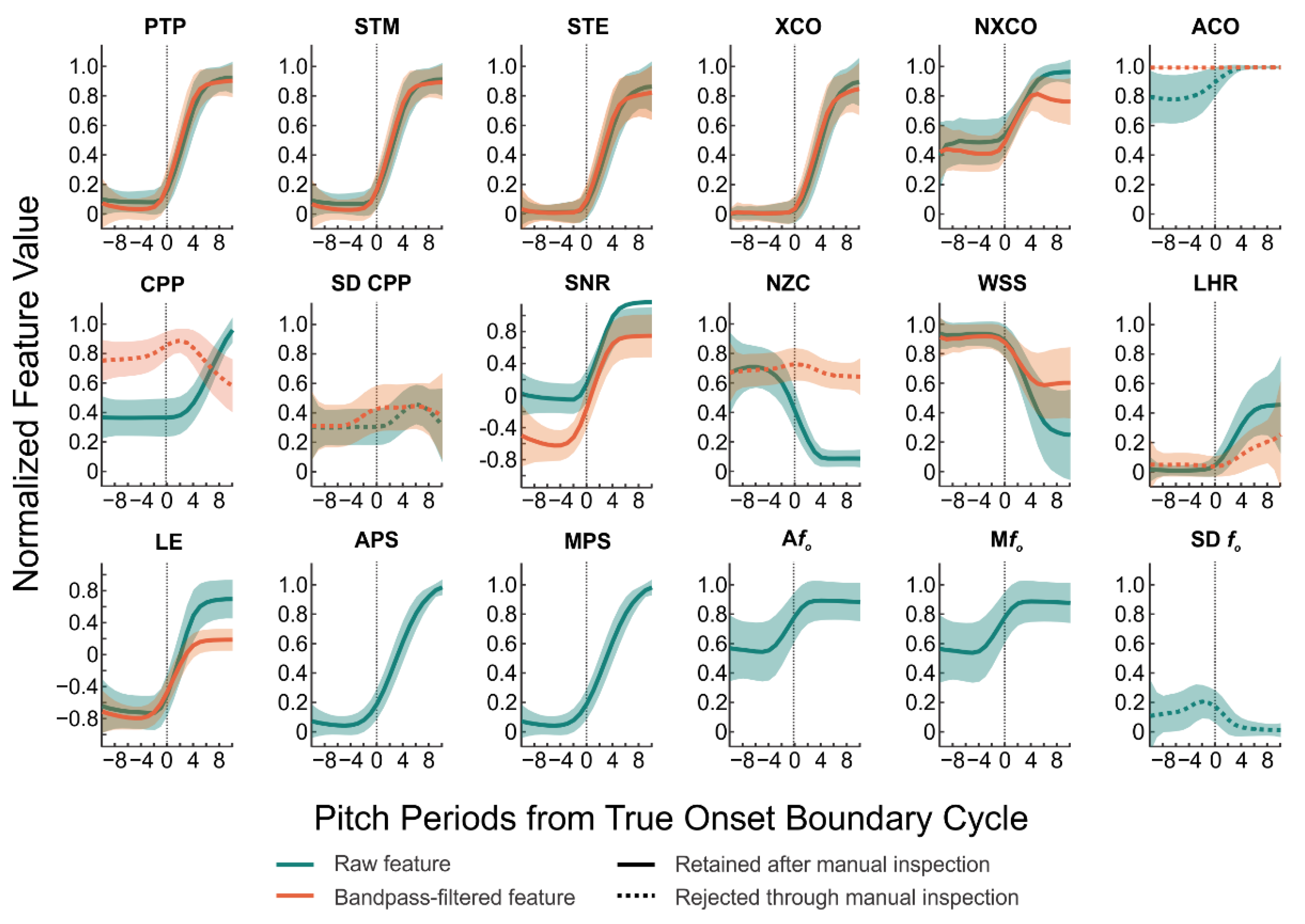
3.1. Acoustic Feature Trend Analysis
3.2. Acoustic Feature Set Reduction
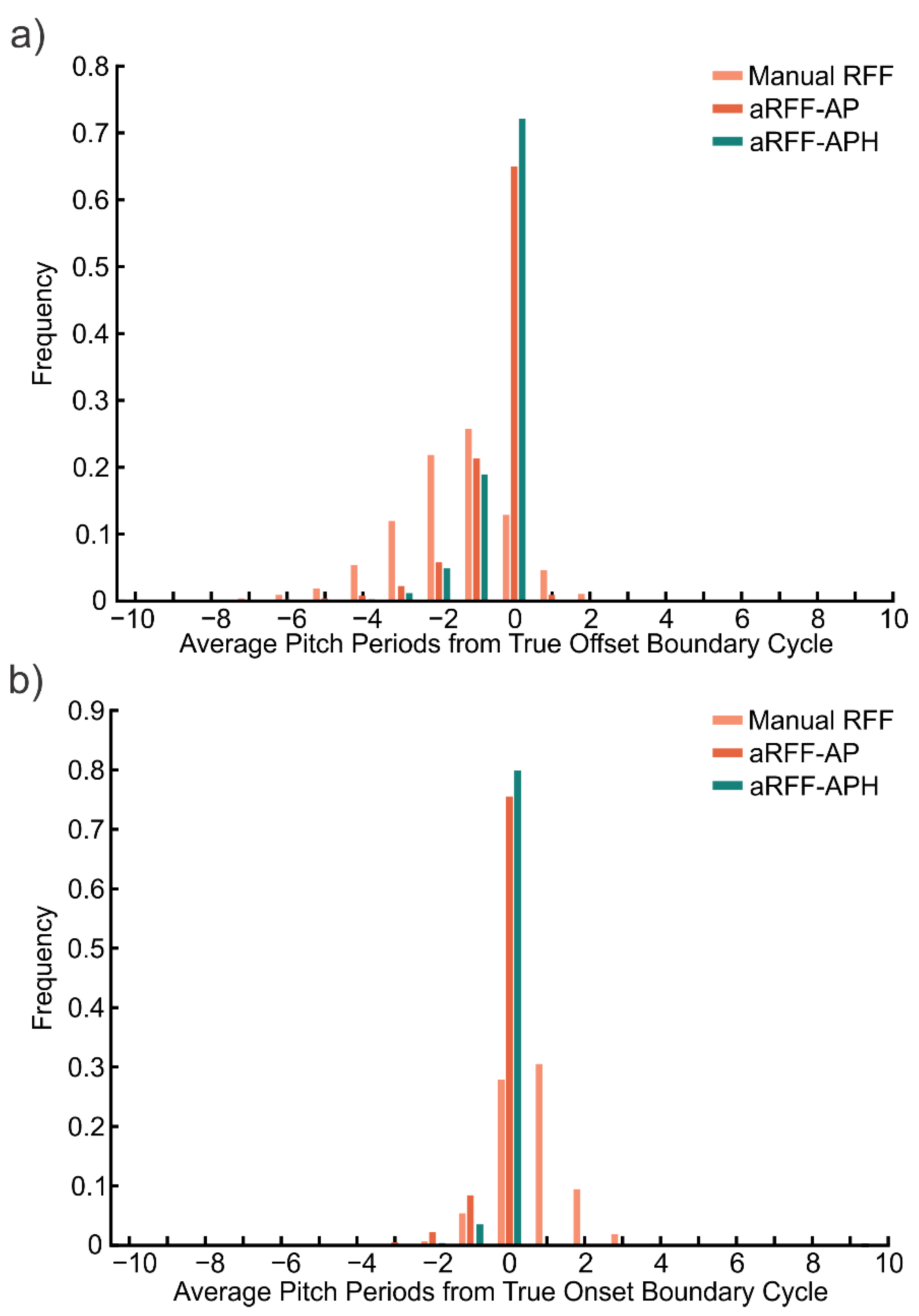
3.3. Performance of Manual and Semi-Automated RFF Estimation Methods
4. Discussion
4.1. Performance of RFF Estimation Methods
4.2. Manual RFF Estimation as a Gold Standard
4.3. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramig, L.O.; Verdolini, K. Treatment efficacy: Voice disorders. J. Speech Lang. Hear. Res. 1998, 41, S101–S116. [Google Scholar] [CrossRef] [Green Version]
- Aronson, A.E.; Bless, D.M. Clinical Voice Disorders, 4th ed.; Thieme Medical Publishers: New York, NY, USA, 2009. [Google Scholar]
- Nash, E.A.; Ludlow, C.L. Laryngeal muscle activity during speech breaks in adductor spasmodic dysphonia. Laryngoscope 1996, 106, 484–489. [Google Scholar] [CrossRef]
- Hillman, R.E.; Holmberg, E.B.; Perkell, J.S.; Walsh, M.; Vaughan, C. Objective assessment of vocal hyperfunction: An experimental framework and initial results. J. Speech Hear. Res. 1989, 32, 373–392. [Google Scholar] [CrossRef]
- Gallena, S.; Smith, P.J.; Zeffiro, T.; Ludlow, C.L. Effects of levodopa on laryngeal muscle activity for voice onset and offset in Parkinson disease. J. Speech Lang. Hear. Res. 2001, 44, 1284–1299. [Google Scholar] [CrossRef]
- Zraick, R.I.; Kempster, G.B.; Connor, N.P.; Thibeault, S.; Klaben, B.K.; Bursac, Z.; Thrush, C.R.; Glaze, L.E. Establishing validity of the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V). Am. J. Speech Lang. Pathol. 2011, 20, 14–22. [Google Scholar] [CrossRef]
- Dejonckere, P.H.; Remacle, M.; Fresnel-Elbaz, E.; Woisard, V.; Crevier-Buchman, L.; Millet, B. Differentiated perceptual evaluation of pathological voice quality: Reliability and correlations with acoustic measurements. Rev. Laryngol. Otol. Rhinol. 1996, 117, 219–224. [Google Scholar]
- Khoddami, S.M.; Ansari, N.N.; Jalaie, S. Review on laryngeal palpation methods in muscle tension dysphonia: Validity and reliability issues. J. Voice 2015, 29, 459–468. [Google Scholar] [CrossRef] [PubMed]
- Roy, N.; Fetrow, R.A.; Merrill, R.M.; Dromey, C. Exploring the clinical utility of relative fundamental frequency as an objective measure of vocal hyperfunction. J. Speech Lang. Hear. Res. 2016, 59, 1002–1017. [Google Scholar] [CrossRef]
- Stepp, C.E.; Sawin, D.E.; Eadie, T.L. The relationship between perception of vocal effort and relative fundamental frequency during voicing offset and onset. J. Speech Lang. Hear. Res. 2012, 55, 1887–1896. [Google Scholar] [CrossRef]
- Eadie, T.L.; Stepp, C.E. Acoustic correlate of vocal effort in spasmodic dysphonia. Ann. Otol. Rhinol. Laryngol. 2013, 122, 169–176. [Google Scholar] [CrossRef]
- Stepp, C.E.; Hillman, R.E.; Heaton, J.T. The impact of vocal hyperfunction on relative fundamental frequency during voicing offset and onset. J. Speech Lang. Hear. Res. 2010, 53, 1220–1226. [Google Scholar] [CrossRef]
- Murray, E.S.H.; Lien, Y.-A.S.; Van Stan, J.H.; Mehta, D.D.; Hillman, R.E.; Noordzij, J.P.; Stepp, C.E. Relative fundamental frequency distinguishes between phonotraumatic and non-phonotraumatic vocal hyperfunction. J. Speech Lang. Hear. Res. 2017, 60, 1507–1515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stepp, C.E. Relative fundamental frequency during vocal onset and offset in older speakers with and without Parkinson’s disease. J. Acoust. Soc. Am. 2013, 133, 1637–1643. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goberman, A.M.; Blomgren, M. Fundamental frequency change during offset and onset of voicing in individuals with Parkinson disease. J. Voice 2008, 22, 178–191. [Google Scholar] [CrossRef]
- Stepp, C.E.; Merchant, G.R.; Heaton, J.T.; Hillman, R.E. Effects of voice therapy on relative fundamental frequency during voicing offset and onset in patients with vocal hyperfunction. J. Speech Lang. Hear. Res. 2011, 54, 1260–1266. [Google Scholar] [CrossRef] [Green Version]
- Lien, Y.-A.S.; Michener, C.M.; Eadie, T.L.; Stepp, C.E. Individual monitoring of vocal effort with relative fundamental frequency: Relationships with aerodynamics and listener perception. J. Speech Lang. Hear. Res. 2015, 58, 566–575. [Google Scholar] [CrossRef] [Green Version]
- Hunter, E.J.; Cantor-Cutiva, L.C.; Van Leer, E.; Van Mersbergen, M.; Nanjundeswaran, C.D.; Bottalico, P.; Sandage, M.J.; Whitling, S. Toward a consensus description of vocal effort, vocal load, vocal loading, and vocal fatigue. J. Speech Lang. Hear. Res. 2020, 63, 509–532. [Google Scholar] [CrossRef]
- McKenna, V.S.; Murray, E.S.H.; Lien, Y.-A.S.; Stepp, C.E. The relationship between relative fundamental frequency and a kinematic estimate of laryngeal stiffness in healthy adults. J. Speech Lang. Hear. Res. 2016, 59, 1283–1294. [Google Scholar] [CrossRef] [Green Version]
- Boersma, P. Praat, a system for doing phonetics by computer. Glot Int. 2001, 5, 341–345. [Google Scholar]
- Lien, Y.S. Optimization and Automation of Relative Fundamental Frequency for Objective Assessment of Vocal Hyperfunction. Ph.D. Thesis, Biomedical Engineering, Boston University, Boston, MA, USA, 2015. [Google Scholar]
- Lien, Y.-A.S.; Murray, E.S.H.; Calabrese, C.R.; Michener, C.M.; Van Stan, J.H.; Mehta, D.D.; Hillman, R.E.; Noordzij, J.P.; Stepp, C.E. Validation of an algorithm for semi-automated estimation of voice relative fundamental frequency. Ann. Otol. Rhinol. Laryngol. 2017, 126, 712–716. [Google Scholar] [CrossRef]
- Rabiner, L. Use of autocorrelation analysis for pitch detection. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 24–33. (In English) [Google Scholar] [CrossRef] [Green Version]
- Vojtech, J.M.; Segina, R.K.; Buckley, D.P.; Kolin, K.R.; Tardif, M.C.; Noordzij, J.P.; Stepp, C.E. Refining algorithmic estimation of relative fundamental frequency: Accounting for sample characteristics and fundamental frequency estimation method. J. Acoust. Soc. Am. 2019, 146, 3184–3202. [Google Scholar] [CrossRef] [PubMed]
- Camacho, A. On the use of auditory models’ elements to enhance a sawtooth waveform inspired pitch estimator on telephone-quality signals. In Proceedings of the ISSPA-2012, Montreal, QC, Canada, 2–5 July 2012; pp. 1080–1085. [Google Scholar]
- Camacho, A.; Harris, J.G. A sawtooth waveform inspired pitch estimator for speech and music. J. Acoust. Soc. Am. 2008, 124, 1638–1652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheyne, H.A.; Hanson, H.M.; Genereux, R.P.; Stevens, K.N.; Hillman, R.E. Development and testing of a portable vocal accumulator. J. Speech Lang. Hear. Res. 2003, 46, 1457–1467. [Google Scholar] [CrossRef]
- Braunschweig, T.; Flaschka, J.; Schelhorn-Neise, P.; Döllinger, M. High-speed video analysis of the phonation onset, with an application to the diagnosis of functional dysphonias. Med. Eng. Phys. 2008, 30, 59–66. [Google Scholar] [CrossRef]
- Ikuma, T.; Kunduk, M.; McWhorter, A.J. Preprocessing techniques for high-speed videoendoscopy analysis. J. Voice 2013, 27, 500–505. [Google Scholar] [CrossRef]
- Kunduk, M.; Yan, Y.; McWhorter, A.J.; Bless, D. Investigation of voice initiation and voice offset characteristics with high-speed digital imaging. Logop. Phoniatr. Vocol. 2006, 31, 139–144. [Google Scholar] [CrossRef]
- Patel, R.R.; Forrest, K.; Hedges, D. Relationship between acoustic voice onset and offset and selected instances of oscillatory onset and offset in young healthy men and women. J. Voice 2017, 31, 389.e9–389.e17. [Google Scholar] [CrossRef] [Green Version]
- Löfqvist, A.; Koenig, L.L.; McGowan, R.S. Vocal tract aerodynamics in /aCa/ utterances: Measurements. Speech Commun. 1995, 16, 49–66. [Google Scholar] [CrossRef]
- Lien, Y.-A.S.; Gattuccio, C.I.; Stepp, C.E. Effects of phonetic context on relative fundamental frequency. J. Speech Lang. Hear. Res. 2014, 57, 1259–1267. [Google Scholar] [CrossRef] [Green Version]
- Stepp, C.E.; Hillman, R.E.; Heaton, J.T. A virtual trajectory model predicts differences in vocal fold kinematics in individuals with vocal hyperfunction. J. Acoust. Soc. Am. 2010, 127, 3166–3176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dworkin, J.P.; Meleca, R.J.; Simpson, M.L.; Garfield, I. Use of topical lidocaine in the treatment of muscle tension dysphonia. J. Voice 2000, 14, 567–574. [Google Scholar] [CrossRef]
- Baken, R.J.; Orlikoff, R.F. Clinical Measurement of Speech and Voice; Singular Thomson Learning: San Diego, CA, USA, 2000. [Google Scholar]
- McKenna, V.S.; Diaz-Cadiz, M.E.; Shembel, A.C.; Enos, N.M.; Stepp, C.E. The relationship between physiological mechanisms and the self-perception of vocal effort. J. Speech Lang. Hear. Res. 2019, 62, 815–834. [Google Scholar] [CrossRef]
- Diaz-Cadiz, M.; McKenna, V.S.; Vojtech, J.M.; Stepp, C.E. Adductory vocal fold kinematic trajectories during conventional versus high-speed videoendoscopy. J. Speech Lang. Hear. Res. 2019, 62, 1685–1706. [Google Scholar] [CrossRef] [PubMed]
- Vojtech, J.M.; Murray, E.S.H. Tutorial for Manual Relative Fundamental Frequency (RFF) Estimation Using Praat. 2019. Available online: https://sites.bu.edu/stepplab/research/rff/ (accessed on 6 August 2020).
- Nandhini, S.; Shenbagavalli, A. Voiced/Unvoiced Detection Using Short Term Processing, in ICIIECS-2014; International Journal of Computer Applications: Coimbatore, India, 2014; pp. 39–43. [Google Scholar]
- Jalil, M.; Butt, F.A.; Malik, A. Short-time energy, magnitude, zero crossing rate and autocorrelation measurement for discriminating voiced and unvoiced segments of speech signals. In Proceedings of the TAEECE-2013, Konya, Turkey, 9–11 May 2013; pp. 208–212. [Google Scholar]
- Camacho, A. SWIPE: A Sawtooth Waveform Inspired Pitch Estimator for Speech and Music. Ph.D. Thesis, Computer Engineering, University of Florida, Gainesville, FL, USA, 2007. [Google Scholar]
- Hillenbrand, J.M.; Houde, R.A. Acoustic correlates of breathy vocal quality: Dysphonic voices and continuous speech. J. Speech Lang. Hear. Res. 1996, 39, 311–321. [Google Scholar] [CrossRef] [PubMed]
- Samad, S.A.; Hussain, A.; Fah, L.K. Pitch detection of speech signals using the cross-correlation technique. In Proceedings of the 2000-TENCON, Kuala Lumpur, Malaysia, 24–27 September 2000; Volume 1, pp. 283–286. [Google Scholar]
- Ghaemmaghami, H.; Baker, B.J.; Vogt, R.J.; Sridharan, S. Noise robust voice activity detection using features extracted from the time-domain autocorrelation function. In Proceedings of the INTERSPEECH-2010, Makuhari, Chiba, Japan, 26–30 September 2010; pp. 3118–3121. [Google Scholar]
- Hillenbrand, J.; Cleveland, R.A.; Erickson, R.L. Acoustic correlates of breathy vocal quality. J. Speech Lang. Hear. Res. 1994, 37, 769–778. [Google Scholar] [CrossRef]
- Dong, E.; Liu, G.; Zhou, Y.; Cai, Y. Voice activity detection based on short-time energy and noise spectrum adaptation. In Proceedings of the ICSP-2002, Beijing, China, 26–30 August 2002; Volume 1, pp. 464–467. [Google Scholar]
- Swee, T.T.; Salleh, S.H.S.; Jamaludin, M.R. Speech pitch detection using short-time energy. In Proceedings of the ICCCS-2010, Kuala Lumpur, Malaysia, 11–12 May 2010. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Erlbaum: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Lien, Y.-A.S.; Calabrese, C.R.; Michener, C.M.; Murray, E.H.; Van Stan, J.H.; Mehta, D.D.; Hillman, R.E.; Noordzij, J.P.; Stepp, C.E. Voice relative fundamental frequency via neck-skin acceleration in individuals with voice disorders. J. Speech Lang. Hear. Res. 2015, 58, 1482–1487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortés, J.P.; Espinoza, V.M.; Ghassemi, M.; Mehta, D.D.; Van Stan, J.H.; Hillman, R.E.; Guttag, J.V.; Zañartu, M. Ambulatory assessment of phonotraumatic vocal hyperfunction using glottal airflow measures estimated from neck-surface acceleration. PLoS ONE 2018, 13, e0209017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fryd, A.S.; Van Stan, J.H.; Hillman, R.E.; Mehta, D.D. Estimating subglottal pressure from neck-surface acceleration during normal voice production. J. Speech Lang. Hear. Res. 2016, 59, 1335–1345. [Google Scholar] [CrossRef] [Green Version]
- Ghassemi, M.; Van Stan, J.H.; Mehta, D.D.; Zañartu, M.; Ii, H.A.C.; Hillman, R.E.; Guttag, J.V. Learning to detect vocal hyperfunction from ambulatory neck-surface acceleration features: Initial results for vocal fold nodules. IEEE Trans. Biomed. Eng. 2014, 61, 1668–1675. [Google Scholar] [CrossRef] [Green Version]
- Hillman, R.E.; Heaton, J.T.; Masaki, A.; Zeitels, S.M.; Cheyne, H.A. Ambulatory monitoring of disordered voices. Ann. Otol. Rhinol. Laryngol. 2006, 115, 795–801. [Google Scholar] [CrossRef]
- Mehta, D.D.; Van Stan, J.H.; Hillman, R.E. Relationships between vocal function measures derived from an acoustic microphone and a subglottal neck-surface accelerometer. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 659–668. [Google Scholar] [CrossRef]
- Mehta, D.D.; Van Stan, J.H.; Zanartu, M.; Ghassemi, M.; Guttag, J.V.; Espinoza, V.M.; Cortés, J.P.; Cheyne, H.A.I.; Hillman, R.E. Using ambulatory voice monitoring to investigate common voice disorders: Research update. Front. Bioeng. Biotechnol. 2015, 3, 155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, D.D.; Zanartu, M.; Feng, S.W.; Cheyne, H.A., 2nd; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Stan, J.H.; Mehta, D.D.; Zeitels, S.M.; Burns, J.A.; Barbu, A.M.; Hillman, R.E. Average ambulatory measures of sound pressure level, fundamental frequency, and vocal dose do not differ between adult females with phonotraumatic lesions and matched control subjects. Ann. Otol. Rhinol. Laryngol. 2015, 124, 864–874. [Google Scholar] [CrossRef] [Green Version]
- JŠvec, J.G.; Titze, I.R.; Popolo, P.S. Estimation of sound pressure levels of voiced speech from skin vibration of the neck. J. Acoust. Soc. Am. 2005, 117, 1386–1394. [Google Scholar]
- Popolo, P.S.; Svec, J.G.; Titze, I.R. Adaptation of a pocket PC for use as a wearable voice dosimeter. J. Speech Lang. Hear. Res. 2005, 48, 780–791. [Google Scholar] [CrossRef]
- Groll, M.D.; Vojtech, J.M.; Hablani, S.; Mehta, D.D.; Buckley, D.P.; Noordzij, J.P.; Stepp, C.E. Automated relative fundamental frequency algorithms for use with neck-surface accelerometer signals. J. Voice 2020. advanced online publication. [Google Scholar] [CrossRef] [PubMed]






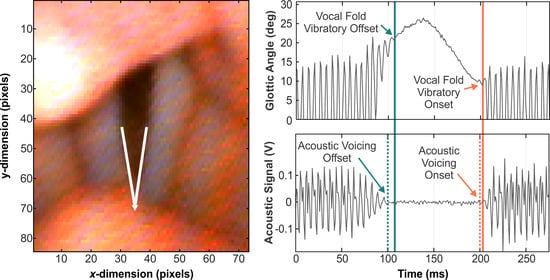
{kind=link}
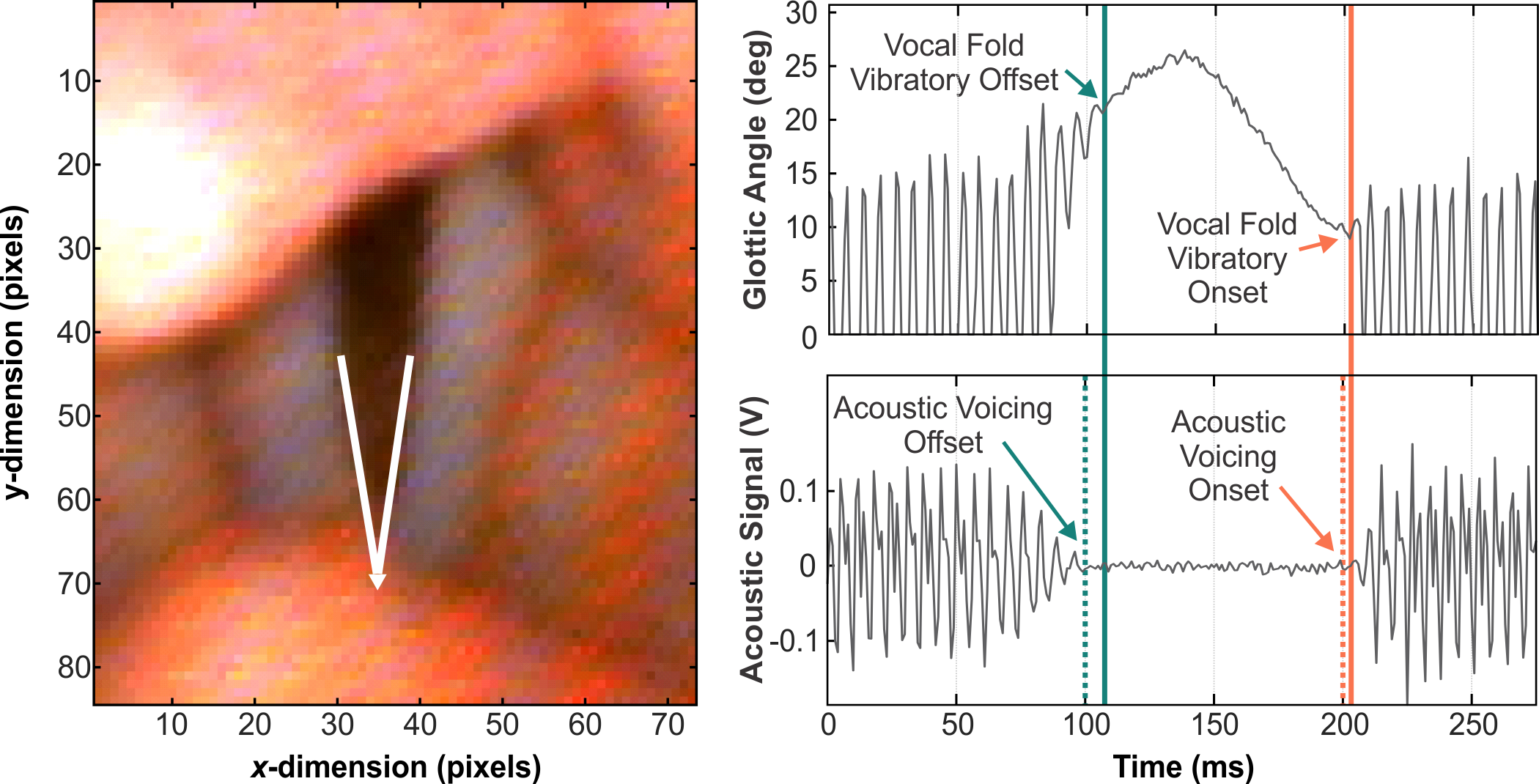
{kind=link}
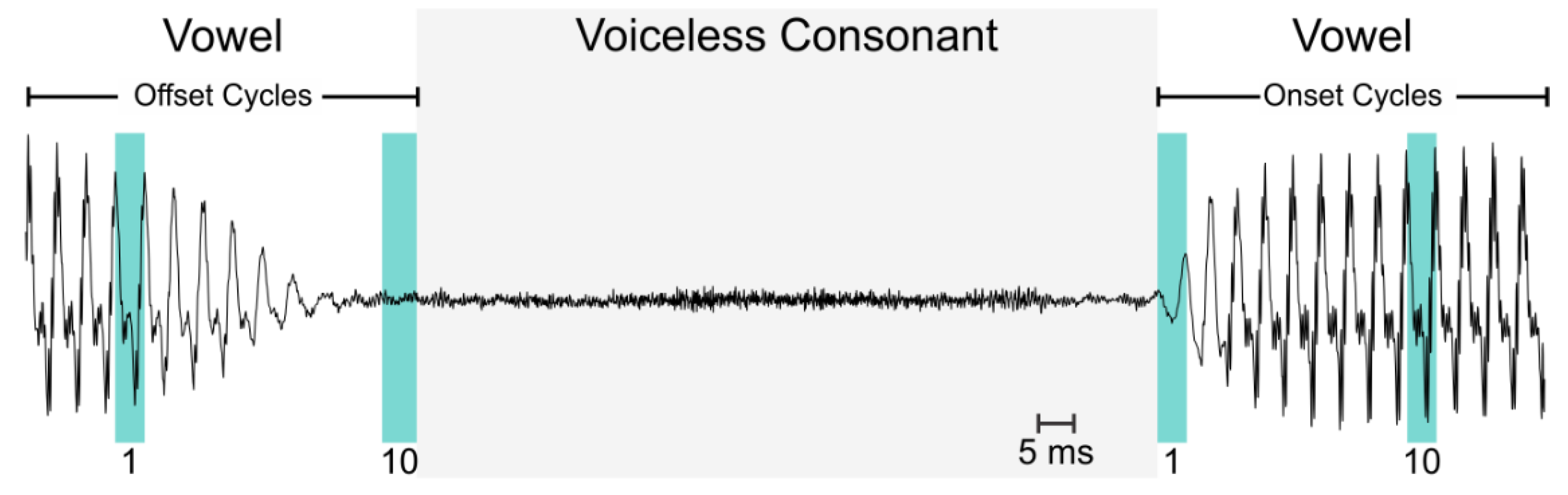
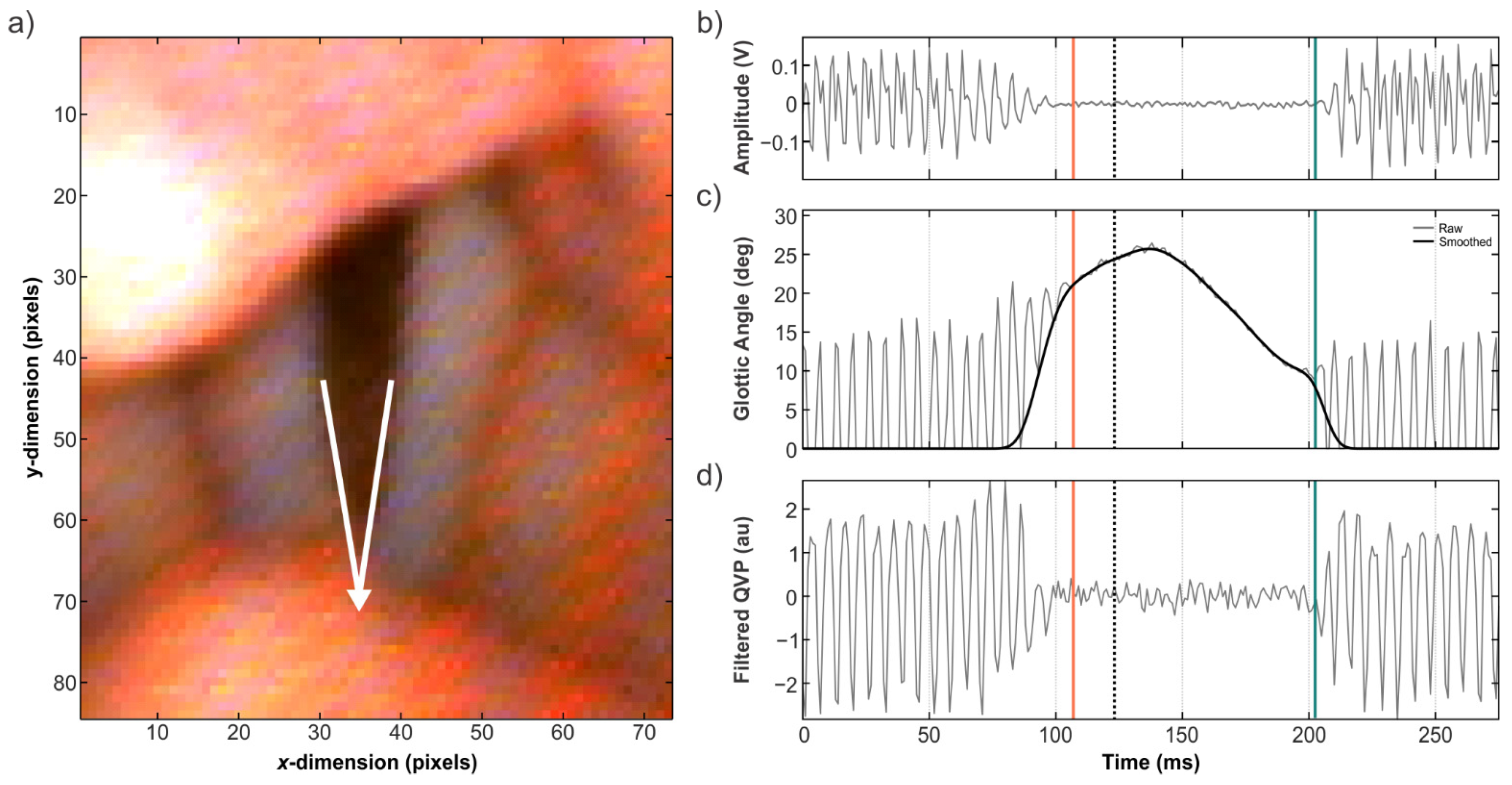{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cohort | Gender | Age | Overall Severity of Dysphonia | |||||
|---|---|---|---|---|---|---|---|---|
| M | F | Mean | SD | Range | Mean | SD | Range | |
| Young adults with typical voices | 18 | 17 | 22.8 | 5.5 | 18–31 | 5.4 | 3.8 | 0.6–23.5 |
| Older adults with typical voices | 18 | 16 | 65.6 | 10.8 | 41–91 | 11.4 | 7.7 | 1.7–34.2 |
| Adults with HVD 1 | 6 | 22 | 37.5 | 16.1 | 19–70 | 12.3 | 10.7 | 0.9–38.5 |
| Adults with PD 2 | 18 | 7 | 63.0 | 9.4 | 43–75 | 19.2 | 13.3 | 4.0–51.3 |
| Technician | Total Ratings | Number of Participants in Common between Technicians | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 1 | 37 | |||||
| 2 | 82 | 5 | ||||
| 3 | 79 | 18 | 53 | |||
| 4 | 29 | 14 | 13 | 2 | ||
| 5 | 17 | 0 | 11 | 6 | 0 | |
| Feature Name | Abbr. | Signals | Definition | Hypothesized Trend |
|---|---|---|---|---|
| Autocorrelation | ACO | Raw and Filtered Microphone | ACO is a comparison of a segment of a voice signal to a delayed copy of itself as a function of the delay [40,41,42]. | V > UV |
| Mean Cepstral Peak Prominence | CPP | Raw and Filtered Microphone | CCP reflects the distribution of energy at harmonically related frequencies [43] and is calculated as the magnitude of the peak with the highest amplitude in the cepstrum (i.e., Fourier transform of power spectrum). | V > UV |
| Average Pitch Strength | APS | Pitch Strength Contour | Pitch strength is calculated using Auditory-SWIPE′ [25] by correlating a voice signal with a sawtooth waveform constructed across a range of possible fo values; the fo value that elicits the greatest correlation is considered the fo of the signal, and the degree of this correlation is the pitch strength. APS is then calculated as the average pitch strength of the window. | V > UV |
| Average Voice fo | Afo | fo Contour | Afo was calculated in the current study using the Auditory-SWIPE′ algorithm (described above in APS). | V > UV |
| Cross-Correlation | XCO | Raw and Filtered Microphone | XCO is a comparison of a segment of a voice signal with a different segment of the signal [42,44,45]. | V > UV |
| Low-to-High Ratio of Spectral Energy | LHR | Raw and Filtered Microphone | LHR is calculated by comparing spectral energy above and below a specified frequency. Using a cut-off frequency of 4 kHz [43,46], the LHR may distinguish harmonic energy of the /i/ from high-frequency aspiration and frication noise (>2–3 kHz) of the /f/. | V > UV |
| Median Pitch Strength | MPS | Pitch Strength Contour | MPS was included as an alternative to APS. | V > UV |
| Median Voice fo | Mfo | fo Contour | Mfo was included as an alternative to Afo. | V > UV |
| Normalized Cross-Correlation | NXCO | Raw and Filtered Microphone | NXCO was included as an alternative to XCO, in which the amplitude of the compared windows is normalized to remove differences in signal amplitude. | V > UV |
| Normalized Peak-to-Peak Amplitude | PTP | Raw and Filtered Microphone | PTP is the range of the amplitude of a windowed voice signal. | V > UV |
| Number of Zero Crossings | NZC | Raw and Filtered Microphone | NZC refers to the number of sign changes of the windowed signal. | V < UV |
| Short-Time Energy | STE | Raw and Filtered Microphone | STE is the energy of a short voice segment [41,47,48]. | V > UV |
| Short-Time Log Energy | SLE | Raw and Filtered Microphone | SLE was included as an alternative to STE, and is calculated as the logarithm of the energy of a short voice segment. | V > UV |
| Short-Time Magnitude | STM | Raw and Filtered Microphone | STM is the magnitude of a short voice segment [41,47,48]. | V > UV |
| Signal-to-Noise Ratio | SNR | Raw and Filtered Microphone | SNR is an estimate of the power of a signal compared to that of a segment of noise. | V > UV |
| Standard Deviation of Cepstral Peak Prominence | SD CPP | Raw and Filtered Microphone | SD CPP is the standard deviation of CPP values within a window and may capture variations in periodicity due to aspiration and frication noise in the /f/ | V < UV |
| Standard Deviation of Voice fo | SD fo | fo Contour | SD fo is the standard deviation of fo values within a may be subject to fo estimation errors during the /f/ (as unvoiced segments would not have a valid fo value). | V < UV |
| Waveform Shape Similarity | WSS | Raw and Filtered Microphone | WSS is the normalized sum of square error between the current and previous window of time and is calculated relative to a window of time in the /f/. | V < UV |
| Model | Acoustic Feature | Coef | SE Coef | z | p | 95% Confidence Interval | VIF 1 | |
|---|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | |||||||
| Voicing Offset | Constant | 0.10 | 0.07 | 1.48 | 0.15 | −0.03 | 0.24 | — |
| Filtered Waveform Shape Similarity | −1.52 | 0.05 | −30.07 | <0.001 | −1.62 | −1.42 | 1.30 | |
| Median of Voice fo | 1.46 | 0.04 | 34.85 | <0.001 | 1.37 | 1.54 | 1.21 | |
| Cepstral Peak Prominence | 1.23 | 0.06 | 20.07 | <0.001 | 1.11 | 1.35 | 1.27 | |
| Number of Zero Crossings | −3.31 | 0.04 | −78.69 | <0.001 | −3.39 | −3.23 | 1.55 | |
| Short-Time Energy | −5.72 | 0.15 | −38.18 | <0.001 | −6.01 | −5.42 | 9.03 | |
| Average Pitch Strength | 9.24 | 0.12 | 78.52 | <0.001 | 9.01 | 9.47 | 4.81 | |
| Normalized Cross-Correlation | −0.84 | 0.05 | −16.77 | <0.001 | −0.93 | −0.74 | 1.53 | |
| Cross-Correlation | 1.00 | 0.16 | 6.25 | <0.001 | 0.69 | 1.31 | 7.74 | |
| Voicing Onset | Constant | −2.18 | 0.10 | −22.69 | <0.001 | −2.37 | −2.00 | — |
| Filtered Waveform Shape Similarity | 1.40 | 0.08 | 18.34 | <0.001 | 1.25 | 1.55 | 1.30 | |
| Median of Voice fo | 2.21 | 0.06 | 40.31 | <0.001 | 2.10 | 2.31 | 1.19 | |
| Cepstral Peak Prominence | 1.05 | 0.08 | 12.53 | <0.001 | 0.89 | 1.22 | 1.06 | |
| Number of Zero Crossings | −2.62 | 0.06 | −42.15 | <0.001 | −2.75 | −2.50 | 1.66 | |
| Average Pitch Strength | 8.94 | 0.15 | 59.45 | <0.001 | 8.65 | 9.24 | 2.83 | |
| Signal-to-Noise Ratio | 0.56 | 0.06 | 9.84 | <0.001 | 0.45 | 0.68 | 2.44 | |
| Filtered Short-Time Energy | −3.75 | 0.10 | −37.51 | <0.001 | −3.95 | −3.56 | 3.66 | |
| Filtered Short-Time Log Energy | 3.11 | 0.07 | 44.81 | <0.001 | 2.97 | 3.24 | 3.01 | |
| Model | Cohort | N | Proportion of Correctly Identified Boundary Cycles (%) by RFF Estimation Method | ||
|---|---|---|---|---|---|
| Manual | aRFF-AP | aRFF-APH | |||
| Voicing Offset | Typical voice | 69 | 14.7 | 66.9 | 72.8 |
| Parkinson’s disease | 25 | 10.9 | 58.9 | 72.0 | |
| Muscle tension dysphonia | 20 | 8.3 | 66.1 | 69.0 | |
| Nodules | 4 | 7.4 | 66.3 | 69.8 | |
| Polyp | 2 | 0.0 | 53.9 | 73.1 | |
| Scarring | 1 | 20.8 | 58.3 | 87.5 | |
| Lesion | 1 | 0.0 | 53.9 | 73.1 | |
| Voicing Onset | Typical voice | 69 | 30.4 | 72.4 | 76.8 |
| Parkinson’s disease | 25 | 27.2 | 78.1 | 81.9 | |
| Muscle tension dysphonia | 20 | 20.0 | 83.8 | 88.5 | |
| Nodules | 4 | 15.4 | 93.6 | 98.0 | |
| Polyp | 2 | 0.0 | 100.0 | 84.6 | |
| Scarring | 1 | 33.3 | 62.5 | 83.3 | |
| Lesion | 1 | 21.2 | 82.7 | 88.5 | |
| Model | RFF Estimation Methods | df | N | Χ2 | p | V | Effect Size Interpretation |
|---|---|---|---|---|---|---|---|
| Voicing Offset | Manual vs. aRFF-AP vs. aRFF-APH | 2 | 21793 | 5821.0 | <0.001 | 0.52 | Large |
| Manual vs. aRFF-AP | 1 | 14250 | 3928.0 | <0.001 | 0.53 | Large | |
| Manual vs. aRFF-APH | 1 | 14268 | 4982.0 | <0.001 | 0.59 | Large | |
| aRFF-AP vs. aRFF-APH | 1 | 15068 | 89.7 | <0.001 | 0.08 | Negligible | |
| Voicing Onset | Manual vs. aRFF-AP vs. aRFF-APH | 2 | 19112 | 6417.0 | <0.001 | 0.58 | Large |
| Manual vs. aRFF-AP | 1 | 12631 | 3420.0 | <0.001 | 0.52 | Large | |
| Manual vs. aRFF-APH | 1 | 12391 | 4831.0 | <0.001 | 0.62 | Large | |
| aRFF-AP vs. aRFF-APH | 1 | 13202 | 283.0 | <0.001 | 0.15 | Small |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vojtech, J.M.; Cilento, D.D.; Luong, A.T.; Noordzij, J.P., Jr.; Diaz-Cadiz, M.; Groll, M.D.; Buckley, D.P.; McKenna, V.S.; Noordzij, J.P.; Stepp, C.E. Acoustic Identification of the Voicing Boundary during Intervocalic Offsets and Onsets Based on Vocal Fold Vibratory Measures. Appl. Sci. 2021, 11, 3816. https://doi.org/10.3390/app11093816
Vojtech JM, Cilento DD, Luong AT, Noordzij JP Jr., Diaz-Cadiz M, Groll MD, Buckley DP, McKenna VS, Noordzij JP, Stepp CE. Acoustic Identification of the Voicing Boundary during Intervocalic Offsets and Onsets Based on Vocal Fold Vibratory Measures. Applied Sciences. 2021; 11(9):3816. https://doi.org/10.3390/app11093816
Chicago/Turabian StyleVojtech, Jennifer M., Dante D. Cilento, Austin T. Luong, Jacob P. Noordzij, Jr., Manuel Diaz-Cadiz, Matti D. Groll, Daniel P. Buckley, Victoria S. McKenna, J. Pieter Noordzij, and Cara E. Stepp. 2021. "Acoustic Identification of the Voicing Boundary during Intervocalic Offsets and Onsets Based on Vocal Fold Vibratory Measures" Applied Sciences 11, no. 9: 3816. https://doi.org/10.3390/app11093816
APA StyleVojtech, J. M., Cilento, D. D., Luong, A. T., Noordzij, J. P., Jr., Diaz-Cadiz, M., Groll, M. D., Buckley, D. P., McKenna, V. S., Noordzij, J. P., & Stepp, C. E. (2021). Acoustic Identification of the Voicing Boundary during Intervocalic Offsets and Onsets Based on Vocal Fold Vibratory Measures. Applied Sciences, 11(9), 3816. https://doi.org/10.3390/app11093816