
No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion


Abstract
:1. Introduction
1.1. Related Work
1.1.1. NSS-Based Methods
1.1.2. HVS-Based Methods
1.1.3. Learning-Based Methods
1.2. Contributions
1.3. Structure
2. Materials and Methods
2.1. Materials
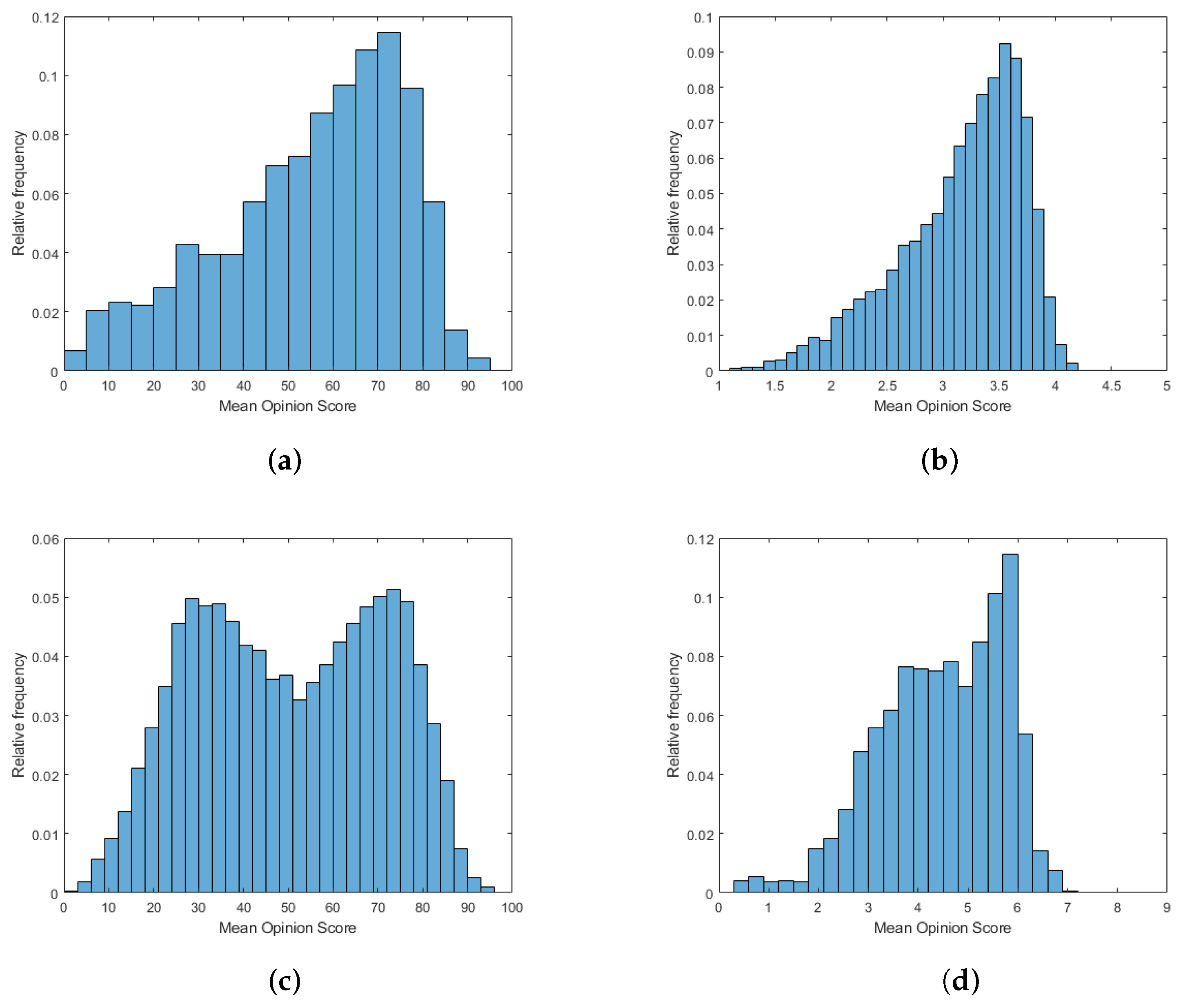
2.1.1. Databases
2.1.2. Evaluation Protocol and Implementation Details
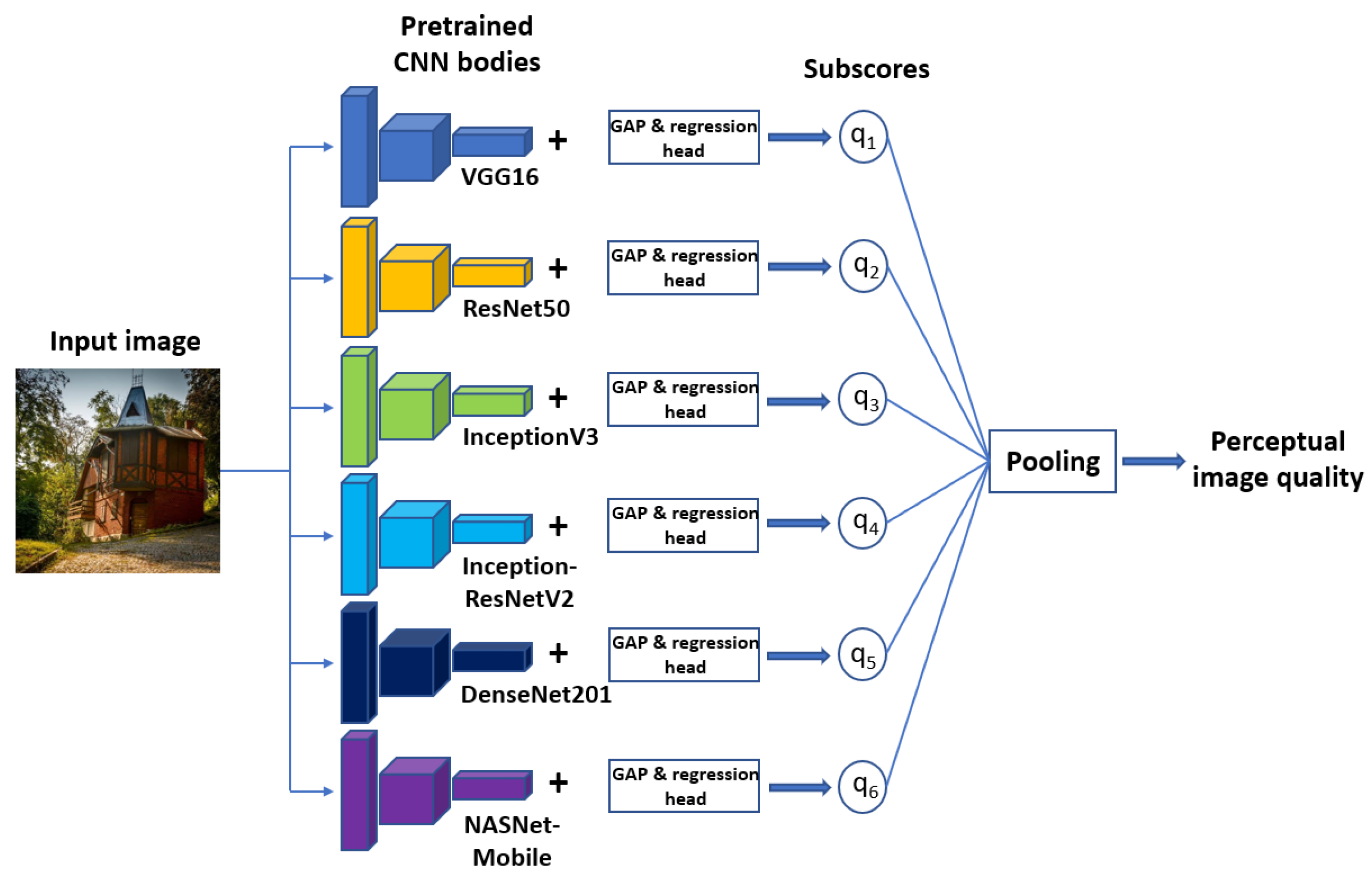
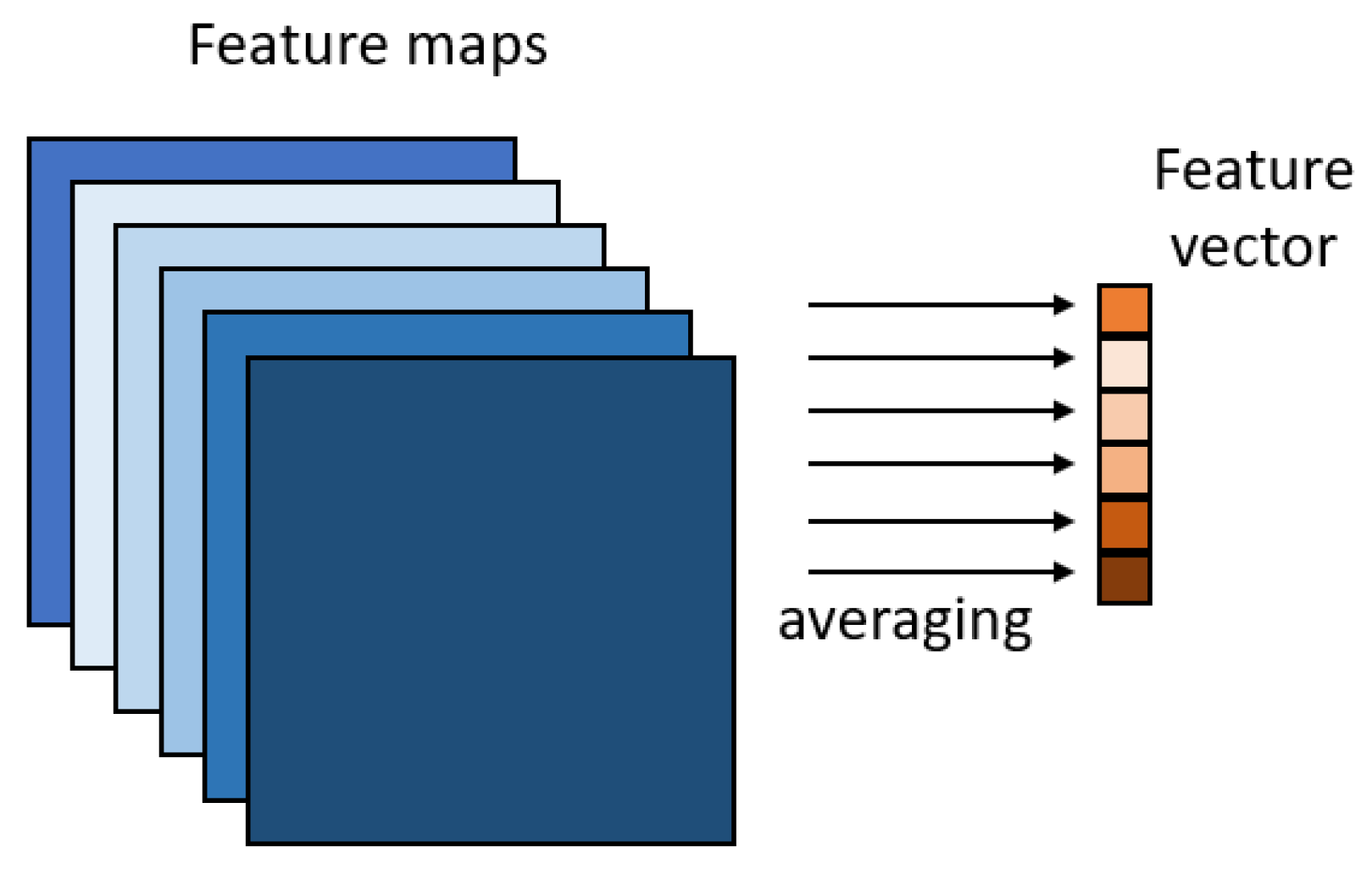
2.2. Methods
3. Experimental Results and Analysis
3.1. Parameter Study
3.2. Comparison to the State of the Art
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| CT | computer tomography |
| FR-IQA | full-reference image quality assessment |
| GGD | generalized Gaussian distribution |
| GPU | graphics processing unit |
| HVS | human visual system |
| IQA | image quality assessment |
| JPEG | joint photographic experts group |
| KROCC | Kendall rank order correlation coefficient |
| LIVE | Laboratory of Image and Video Engineering |
| MOS | mean opinion score |
| MRI | magnetic resonance imaging |
| MSE | mean squared error |
| NR-IQA | no-reference image quality assessment |
| NSS | natural scene statistics |
| PLCC | Pearson linear correlation coefficient |
| ReLU | rectified linear unit |
| RR-IQA | reduced-reference image quality assessment |
| SPAQ | smartphone photography attribute and quality |
| SROCC | Spearman rank order correlation coefficient |
| SVR | support vector regressor |
| TID | Tampere image database |
| YFCC-100m | Yahoo Flickr creative commons 100 million dataset |
References
- Keelan, B. Handbook of Image Quality: Characterization and Prediction; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Chubarau, A.; Akhavan, T.; Yoo, H.; Mantiuk, R.K.; Clark, J. Perceptual image quality assessment for various viewing conditions and display systems. Electron. Imaging 2020, 2020, 67-1–67-9. [Google Scholar] [CrossRef]
- Saupe, D.; Hahn, F.; Hosu, V.; Zingman, I.; Rana, M.; Li, S. Crowd workers proven useful: A comparative study of subjective video quality assessment. In Proceedings of the QoMEX 2016: 8th International Conference on Quality of Multimedia Experience, Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Lin, H.; Hosu, V.; Saupe, D. KonIQ-10K: Towards an ecologically valid and large-scale IQA database. arXiv 2018, arXiv:1803.08489. [Google Scholar]
- Fang, Y.; Zhu, H.; Zeng, Y.; Ma, K.; Wang, Z. Perceptual quality assessment of smartphone photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3677–3686. [Google Scholar]
- Serir, A.; Beghdadi, A.; Kerouh, F. No-reference blur image quality measure based on multiplicative multiresolution decomposition. J. Vis. Commun. Image Represent. 2013, 24, 911–925. [Google Scholar] [CrossRef]
- Babu, R.V.; Suresh, S.; Perkis, A. No-reference JPEG-image quality assessment using GAP-RBF. Signal Process. 2007, 87, 1493–1503. [Google Scholar] [CrossRef]
- Xu, L.; Lin, W.; Kuo, C.C.J. Visual Quality Assessment by Machine Learning; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, A.K.; Bovik, A.C. A two-step framework for constructing blind image quality indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Liu, L.; Dong, H.; Huang, H.; Bovik, A.C. No-reference image quality assessment in curvelet domain. Signal Process. Image Commun. 2014, 29, 494–505. [Google Scholar] [CrossRef]
- Lu, W.; Zeng, K.; Tao, D.; Yuan, Y.; Gao, X. No-reference image quality assessment in contourlet domain. Neurocomputing 2010, 73, 784–794. [Google Scholar] [CrossRef]
- Wang, H.; Li, C.; Guan, T.; Zhao, S. No-reference stereoscopic image quality assessment using quaternion wavelet transform and heterogeneous ensemble learning. Displays 2021, 69, 102058. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Zhai, G.; Wu, X.; Yang, X.; Lin, W.; Zhang, W. A psychovisual quality metric in free-energy principle. IEEE Trans. Image Process. 2011, 21, 41–52. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.; Kilner, J.; Harrison, L. A free energy principle for the brain. J. Physiol. 2006, 100, 70–87. [Google Scholar] [CrossRef] [Green Version]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W. Using free energy principle for blind image quality assessment. IEEE Trans. Multimed. 2014, 17, 50–63. [Google Scholar] [CrossRef]
- Li, Q.; Lin, W.; Xu, J.; Fang, Y. Blind image quality assessment using statistical structural and luminance features. IEEE Trans. Multimed. 2016, 18, 2457–2469. [Google Scholar] [CrossRef]
- Nothdurft, H. Sensitivity for structure gradient in texture discrimination tasks. Vis. Res. 1985, 25, 1957–1968. [Google Scholar] [CrossRef]
- Watson, A.B.; Solomon, J.A. Model of visual contrast gain control and pattern masking. JOSA A 1997, 14, 2379–2391. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Li, Q.; Lin, W.; Fang, Y. BSD: Blind image quality assessment based on structural degradation. Neurocomputing 2017, 236, 93–103. [Google Scholar] [CrossRef]
- Prewitt, J.M. Object enhancement and extraction. Pict. Process. Psychopictorics 1970, 10, 15–19. [Google Scholar]
- Lyu, S.; Simoncelli, E.P. Nonlinear image representation using divisive normalization. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Saha, A.; Wu, Q.M.J. Utilizing image scales towards totally training free blind image quality assessment. IEEE Trans. Image Process. 2015, 24, 1879–1892. [Google Scholar] [CrossRef] [PubMed]
- Ruderman, D.L.; Bialek, W. Statistics of natural images: Scaling in the woods. Phys. Rev. Lett. 1994, 73, 814. [Google Scholar] [CrossRef] [Green Version]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar]
- Bosse, S.; Maniry, D.; Wiegand, T.; Samek, W. A deep neural network for image quality assessment. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3773–3777. [Google Scholar]
- Jia, S.; Zhang, Y. Saliency-based deep convolutional neural network for no-reference image quality assessment. Multimed. Tools Appl. 2018, 77, 14859–14872. [Google Scholar] [CrossRef]
- Wang, X.; Liang, X.; Yang, B.; Li, F.W. No-reference synthetic image quality assessment with convolutional neural network and local image saliency. Comput. Vis. Media 2019, 5, 1. [Google Scholar] [CrossRef] [Green Version]
- Chetouani, A.; Li, L. On the use of a scanpath predictor and convolutional neural network for blind image quality assessment. Signal Process. Image Commun. 2020, 89, 115963. [Google Scholar] [CrossRef]
- Le Meur, O.; Liu, Z. Saccadic model of eye movements for free-viewing condition. Vis. Res. 2015, 116, 152–164. [Google Scholar] [CrossRef]
- Fan, C.; Zhang, Y.; Feng, L.; Jiang, Q. No reference image quality assessment based on multi-expert convolutional neural networks. IEEE Access 2018, 6, 8934–8943. [Google Scholar] [CrossRef]
- Bianco, S.; Celona, L.; Napoletano, P.; Schettini, R. On the use of deep learning for blind image quality assessment. Signal Image Video Process. 2018, 12, 355–362. [Google Scholar] [CrossRef]
- Varga, D. Multi-pooled inception features for no-reference image quality assessment. Appl. Sci. 2020, 10, 2186. [Google Scholar] [CrossRef] [Green Version]
- Sendjasni, A.; Larabi, M.C.; Cheikh, F.A. Convolutional Neural Networks for Omnidirectional Image Quality Assessment: Pre-Trained or Re-Trained? In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3413–3417. [Google Scholar]
- Jain, P.; Shikkenawis, G.; Mitra, S.K. Natural Scene Statistics And CNN Based Parallel Network For Image Quality Assessment. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1394–1398. [Google Scholar]
- Chetouani, A.; Pedersen, M. Image Quality Assessment without Reference by Combining Deep Learning-Based Features and Viewing Distance. Appl. Sci. 2021, 11, 4661. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Image Quality Assessment with Multi-Scale Orderless Pooling of Deep Features. J. Imaging 2021, 7, 112. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Su, Y.; Korhonen, J. Blind Natural Image Quality Prediction Using Convolutional Neural Networks And Weighted Spatial Pooling. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 191–195. [Google Scholar]
- Li, J.; Qiao, S.; Zhao, C.; Zhang, T. No-reference image quality assessment based on multiscale feature representation. IET Image Process. 2021, 15, 3318–3331. [Google Scholar] [CrossRef]
- Korhonen, J.; Su, Y.; You, J. Consumer image quality prediction using recurrent neural networks for spatial pooling. arXiv 2021, arXiv:2106.00918. [Google Scholar]
- Ying, Z.; Niu, H.; Gupta, P.; Mahajan, D.; Ghadiyaram, D.; Bovik, A. From patches to pictures (PaQ-2-PiQ): Mapping the perceptual space of picture quality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3575–3585. [Google Scholar]
- Winkler, S. Analysis of public image and video databases for quality assessment. IEEE J. Sel. Top. Signal Process. 2012, 6, 616–625. [Google Scholar] [CrossRef]
- Okarma, K. Image and video quality assessment with the use of various verification databases. New Electr. Electron. Technol. Ind. Implement. 2013, 89, 321–323. [Google Scholar]
- Lin, H.; Hosu, V.; Saupe, D. KADID-10k: A large-scale artificially distorted IQA database. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2019; pp. 1–3. [Google Scholar]
- Ghadiyaram, D.; Bovik, A.C. Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans. Image Process. 2015, 25, 372–387. [Google Scholar] [CrossRef] [Green Version]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Jin, L.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Color image database TID2013: Peculiarities and preliminary results. In Proceedings of the European Workshop on visual Information Processing (EUVIP), Paris, France, 10–12 June 2013; pp. 106–111. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 28 November 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Baldi, P.; Sadowski, P.J. Understanding dropout. Adv. Neural Inf. Process. Syst. 2013, 26, 2814–2822. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gao, F.; Yu, J.; Zhu, S.; Huang, Q.; Tian, Q. Blind image quality prediction by exploiting multi-level deep representations. Pattern Recognition 2018, 81, 432–442. [Google Scholar] [CrossRef]
- Varga, D.; Saupe, D.; Szirányi, T. DeepRN: A content preserving deep architecture for blind image quality assessment. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 June 2018; pp. 1–6. [Google Scholar]
- Min, X.; Zhai, G.; Gu, K.; Liu, Y.; Yang, X. Blind image quality estimation via distortion aggravation. IEEE Trans. Broadcast. 2018, 64, 508–517. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Q.; Lin, M.; Yang, G.; He, C. No-reference color image quality assessment: From entropy to perceptual quality. EURASIP J. Image Video Process. 2019, 2019, 77. [Google Scholar] [CrossRef] [Green Version]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Ou, F.Z.; Wang, Y.G.; Zhu, G. A novel blind image quality assessment method based on refined natural scene statistics. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 1004–1008. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind image quality assessment by relative gradient statistics and adaboosting neural network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Zhai, G.; Yang, X. Uncertainty-aware blind image quality assessment in the laboratory and wild. IEEE Trans. Image Process. 2021, 30, 3474–3486. [Google Scholar] [CrossRef]
- Madhusudana, P.C.; Birkbeck, N.; Wang, Y.; Adsumilli, B.; Bovik, A.C. Image Quality Assessment using Contrastive Learning. arXiv 2021, arXiv:2110.13266. [Google Scholar]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Hosu, V.; Saupe, D. DeepFL-IQA: Weak supervision for deep IQA feature learning. arXiv 2020, arXiv:2001.08113. [Google Scholar]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hosu, V.; Goldlucke, B.; Saupe, D. Effective aesthetics prediction with multi-level spatially pooled features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9375–9383. [Google Scholar]
- Zeng, H.; Zhang, L.; Bovik, A.C. A probabilistic quality representation approach to deep blind image quality prediction. arXiv 2017, arXiv:1708.08190. [Google Scholar]
- Su, S.; Hosu, V.; Lin, H.; Zhang, Y.; Saupe, D. KonIQ++: Boosting No-Reference Image Quality Assessment in the Wild by Jointly Predicting Image Quality and Defects. In Proceedings of the British Machine Vision Conference (BMVC), Virtual Conference, 23–25 November 2021. [Google Scholar]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman and Hall/CRC: Boca Raton, FL, USA, 2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | CLIVE [50] | KonIQ-10k [4] | SPAQ [5] | TID2013 [51] |
|---|---|---|---|---|
| Year | 2015 | 2018 | 2020 | 2013 |
| Number of images | 1169 | 10,073 | 11,125 | 3000 |
| Number of scenes | 1169 | 10,073 | 11,125 | 25 |
| Distortion type | authentic | authentic | authentic | artificial |
| Subjective framework | crowd-sourcing | crowd-sourcing | laboratory | laboratory |
| Number of annotators | 8000 | 350,000 | 600 | 540 |
| Number of annotations | 1400 | 1,200,000 | 186,400 | 524,340 |
| Resolution | ∼ | |||
| MOS range | 0–100 | 1–5 | 0–100 | 0–9 |
| CNN | Size (MByte) | Top-1 Accuracy | Top-5 Accuracy | Parameters | Depth |
|---|---|---|---|---|---|
| VGG16 [56] | 528 | 0.713 | 0.901 | 138,357,544 | 23 |
| ResNet50 [57] | 98 | 0.749 | 0.921 | 25,636,712 | - |
| InceptionV3 [58] | 92 | 0.779 | 0.937 | 23,851,784 | 159 |
| InceptionResNetV2 [59] | 215 | 0.803 | 0.953 | 55,873,736 | 572 |
| DenseNet201 [60] | 80 | 0.773 | 0.936 | 20,242,984 | 201 |
| NASNetMobile [61] | 23 | 0.774 | 0.919 | 5,326,716 | - |
| Architecture | SROCC |
|---|---|
| VGG16 | 0.861 |
| ResNet50 | 0.860 |
| InceptionV3 | 0.909 |
| InceptionResNetV2 | 0.918 |
| DenseNet201 | 0.914 |
| NASNetMobile | 0.899 |
| Average pooling of subscores | 0.927 |
| Median pooling of subscores | 0.931 |
| CLIVE [50] | KonIQ-10k [4] | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BLIINDER [66] | 0.782 | 0.763 | 0.576 | 0.876 | 0.864 | 0.668 |
| DeepRN [67] | 0.784 | 0.753 | 0.579 | 0.866 | 0.880 | 0.666 |
| BLIINDS-II [14] | 0.473 | 0.442 | 0.291 | 0.574 | 0.575 | 0.414 |
| BMPRI [68] | 0.541 | 0.487 | 0.333 | 0.637 | 0.619 | 0.421 |
| BRISQUE [15] | 0.524 | 0.497 | 0.345 | 0.707 | 0.677 | 0.494 |
| CurveletQA [11] | 0.636 | 0.621 | 0.421 | 0.730 | 0.718 | 0.495 |
| DIIVINE [9] | 0.617 | 0.580 | 0.405 | 0.709 | 0.693 | 0.471 |
| ENIQA [69] | 0.596 | 0.564 | 0.376 | 0.761 | 0.745 | 0.544 |
| GRAD-LOG-CP [70] | 0.607 | 0.604 | 0.383 | 0.705 | 0.696 | 0.501 |
| MultiGAP-NRIQA [36] | 0.841 | 0.813 | 0.626 | 0.915 | 0.911 | 0.732 |
| MSDF-IQA [40] | 0.831 | 0.801 | 0.607 | 0.901 | 0.885 | 0.703 |
| NBIQA [71] | 0.629 | 0.604 | 0.427 | 0.771 | 0.749 | 0.515 |
| PIQE [72] | 0.172 | 0.108 | 0.081 | 0.208 | 0.246 | 0.172 |
| OG-IQA [73] | 0.545 | 0.505 | 0.364 | 0.652 | 0.635 | 0.447 |
| SSEQ [74] | 0.487 | 0.436 | 0.309 | 0.589 | 0.572 | 0.423 |
| UNIQUE [75] | 0.891 | 0.855 | 0.633 | 0.900 | 0.897 | 0.664 |
| CONTRIQUE [76] | 0.857 | 0.845 | - | 0.906 | 0.894 | - |
| DB-CNN [77] | 0.869 | 0.851 | - | 0.884 | 0.875 | - |
| DeepFL-IQA [78] | 0.769 | 0.734 | - | 0.887 | 0.877 | - |
| KonCept512 [79,82] | 0.848 | 0.825 | - | 0.937 | 0.921 | - |
| MLSP [78,80] | 0.769 | 0.734 | - | 0.887 | 0.877 | - |
| PaQ-2-PiQ [46] | 0.850 | 0.840 | - | 0.880 | 0.870 | - |
| PQR [81] | 0.882 | 0.857 | - | 0.884 | 0.880 | - |
| WSP [43] | - | - | - | 0.931 | 0.918 | - |
| DF-CNN-IQA | 0.859 | 0.849 | 0.630 | 0.949 | 0.931 | 0.738 |
| SPAQ [5] | TID2013 [51] | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BLIINDER [66] | 0.872 | 0.869 | 0.683 | 0.834 | 0.816 | 0.720 |
| DeepRN [67] | 0.870 | 0.850 | 0.676 | 0.745 | 0.636 | 0.560 |
| BLIINDS-II [14] | 0.676 | 0.675 | 0.486 | 0.558 | 0.513 | 0.339 |
| BMPRI [68] | 0.739 | 0.734 | 0.506 | 0.701 | 0.588 | 0.427 |
| BRISQUE [15] | 0.726 | 0.720 | 0.518 | 0.478 | 0.427 | 0.278 |
| CurveletQA [11] | 0.793 | 0.774 | 0.503 | 0.553 | 0.505 | 0.359 |
| DIIVINE [9] | 0.774 | 0.756 | 0.514 | 0.692 | 0.599 | 0.431 |
| ENIQA [69] | 0.813 | 0.804 | 0.603 | 0.604 | 0.555 | 0.397 |
| GRAD-LOG-CP [70] | 0.786 | 0.782 | 0.572 | 0.671 | 0.627 | 0.470 |
| MultiGAP-NRIQA [36] | 0.909 | 0.903 | 0.693 | 0.710 | 0.433 | 0.302 |
| MSDF-IQA [40] | 0.900 | 0.894 | 0.692 | 0.727 | 0.448 | 0.311 |
| NBIQA [71] | 0.802 | 0.793 | 0.539 | 0.723 | 0.628 | 0.427 |
| PIQE [72] | 0.211 | 0.156 | 0.091 | 0.464 | 0.365 | 0.257 |
| OG-IQA [73] | 0.726 | 0.724 | 0.594 | 0.564 | 0.452 | 0.321 |
| SSEQ [74] | 0.745 | 0.742 | 0.549 | 0.618 | 0.520 | 0.375 |
| UNIQUE [75] | 0.907 | 0.906 | 0.687 | 0.812 | 0.826 | 0.578 |
| CONTRIQUE [76] | 0.919 | 0.914 | - | 0.857 | 0.843 | - |
| DB-CNN [77] | 0.915 | 0.914 | - | 0.865 | 0.816 | - |
| DeepFL-IQA [78] | - | - | - | 0.876 | 0.858 | - |
| KonCept512 [79] | - | - | - | - | - | - |
| MLSP [78,80] | - | - | - | - | - | - |
| PaQ-2-PiQ [46] | - | - | - | - | - | - |
| PQR [81] | - | - | - | 0.798 | 0.740 | - |
| WSP [43] | - | - | - | - | - | - |
| DF-CNN-IQA | 0.921 | 0.915 | 0.693 | 0.743 | 0.709 | 0.496 |
| Direct Average | Weighted Average | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BLIINDER [66] | 0.841 | 0.828 | 0.662 | 0.865 | 0.856 | 0.676 |
| DeepRN [67] | 0.816 | 0.780 | 0.620 | 0.850 | 0.832 | 0.654 |
| BLIINDS-II [14] | 0.570 | 0.551 | 0.383 | 0.612 | 0.605 | 0.431 |
| BMPRI [68] | 0.655 | 0.607 | 0.422 | 0.685 | 0.660 | 0.455 |
| BRISQUE [15] | 0.609 | 0.580 | 0.409 | 0.680 | 0.658 | 0.472 |
| CurveletQA [11] | 0.678 | 0.655 | 0.445 | 0.732 | 0.713 | 0.479 |
| DIIVINE [9] | 0.698 | 0.657 | 0.455 | 0.731 | 0.704 | 0.482 |
| ENIQA [69] | 0.694 | 0.667 | 0.480 | 0.758 | 0.740 | 0.545 |
| GRAD-LOG-CP [70] | 0.692 | 0.677 | 0.481 | 0.732 | 0.721 | 0.523 |
| MultiGAP-NRIQA [36] | 0.844 | 0.765 | 0.588 | 0.885 | 0.846 | 0.659 |
| MSDF-IQA [40] | 0.840 | 0.757 | 0.578 | 0.877 | 0.833 | 0.647 |
| NBIQA [71] | 0.731 | 0.694 | 0.477 | 0.772 | 0.747 | 0.511 |
| PIQE [72] | 0.264 | 0.219 | 0.150 | 0.238 | 0.214 | 0.142 |
| OG-IQA [73] | 0.622 | 0.579 | 0.432 | 0.669 | 0.646 | 0.493 |
| SSEQ [74] | 0.610 | 0.568 | 0.414 | 0.656 | 0.634 | 0.467 |
| UNIQUE [75] | 0.878 | 0.871 | 0.641 | 0.892 | 0.891 | 0.662 |
| CONTRIQUE [76] | 0.885 | 0.874 | - | 0.904 | 0.894 | - |
| DB-CNN [77] | 0.883 | 0.864 | - | 0.894 | 0.884 | - |
| DeepFL-IQA [78] | - | - | - | - | - | - |
| KonCept512 [79] | - | - | - | - | - | - |
| MLSP [78,80] | - | - | - | - | - | - |
| PaQ-2-PiQ [46] | - | - | - | - | - | - |
| PQR [81] | - | - | - | - | - | - |
| WSP [43] | - | - | - | - | - | - |
| DF-CNN-IQA | 0.868 | 0.851 | 0.639 | 0.908 | 0.894 | 0.685 |
| Method | CLIVE [50] | KonIQ-10k [4] | SPAQ [5] | TID2013 [51] |
|---|---|---|---|---|
| BLIINDER [66] | 1 | 1 | 1 | −1 |
| DeepRN [67] | 1 | 1 | 1 | 1 |
| BLIINDS-II [14] | 1 | 1 | 1 | 1 |
| BMPRI [68] | 1 | 1 | 1 | 1 |
| BRISQUE [15] | 1 | 1 | 1 | 1 |
| CurveletQA [11] | 1 | 1 | 1 | 1 |
| DIIVINE [9] | 1 | 1 | 1 | 1 |
| ENIQA [69] | 1 | 1 | 1 | 1 |
| GRAD-LOG-CP [70] | 1 | 1 | 1 | 1 |
| MultiGAP-NRIQA [36] | 1 | 1 | 1 | 1 |
| MSDF-IQA [40] | 1 | 1 | 1 | 1 |
| NBIQA [71] | 1 | 1 | 1 | 1 |
| PIQE [72] | 1 | 1 | 1 | 1 |
| OG-IQA [73] | 1 | 1 | 1 | 1 |
| SSEQ [74] | 1 | 1 | 1 | 1 |
| UNIQUE [75] | −1 | 1 | 1 | −1 |
| Method | PLCC | SROCC | KROCC |
|---|---|---|---|
| BLIINDER [66] | 0.748 | 0.730 | 0.503 |
| DeepRN [67] | 0.746 | 0.725 | 0.481 |
| BLIINDS-II [14] | 0.107 | 0.090 | 0.063 |
| BMPRI [68] | 0.453 | 0.389 | 0.298 |
| BRISQUE [15] | 0.509 | 0.460 | 0.310 |
| CurveletQA [11] | 0.496 | 0.505 | 0.347 |
| DIIVINE [9] | 0.479 | 0.434 | 0.299 |
| ENIQA [69] | 0.428 | 0.386 | 0.272 |
| GRAD-LOG-CP [70] | 0.427 | 0.384 | 0.261 |
| MultiGAP-NRIQA [36] | 0.841 | 0.813 | 0.585 |
| MSDF-IQA [40] | 0.764 | 0.749 | 0.552 |
| NBIQA [71] | 0.503 | 0.509 | 0.284 |
| OG-IQA [73] | 0.442 | 0.427 | 0.289 |
| SSEQ [74] | 0.270 | 0.256 | 0.170 |
| UNIQUE [75] | 0.842 | 0.826 | 0.589 |
| CONTRIQUE [76] | - | 0.731 | - |
| DB-CNN [77] | - | 0.755 | - |
| DeepFL-IQA [78] | - | 0.704 | - |
| KonCept512 [79] | 0.848 | 0.825 | - |
| PaQ-2-PiQ [46] | - | - | - |
| PQR [81] | - | 0.770 | - |
| WSP [43] | 0.840 | 0.820 | - |
| DF-CNN-IQA | 0.854 | 0.831 | 0.598 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varga, D. No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion. Appl. Sci. 2022, 12, 101. https://doi.org/10.3390/app12010101
Varga D. No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion. Applied Sciences. 2022; 12(1):101. https://doi.org/10.3390/app12010101
Chicago/Turabian StyleVarga, Domonkos. 2022. "No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion" Applied Sciences 12, no. 1: 101. https://doi.org/10.3390/app12010101
APA StyleVarga, D. (2022). No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion. Applied Sciences, 12(1), 101. https://doi.org/10.3390/app12010101