
Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection


Abstract
:1. Introduction
- We propose an alternative anchor strategy (dynamic anchor) to automatically generate anchor boxes without any hyper-parameters. Compared with the pre-defined anchor scheme, dynamic anchor would generate anchor boxes that are specific to the objects and avoid careful parameter tuning;
- We propose a feature enhancement module, which takes advantage of the high IoU scores of the predicted anchors. The module enables the network to focus on the region of anchors and extract more precise semantic features;
- We propose a quality branch, which is used to predict the quality scores of the predicted anchors. By investigating the influence of the anchor boxes with different quality, the scores are used to repress the low-quality anchors. The code will be available at https://github.com/LX-SZY/Dynamic-Anchor (accessed on 3 March 2022).
2. Related Work
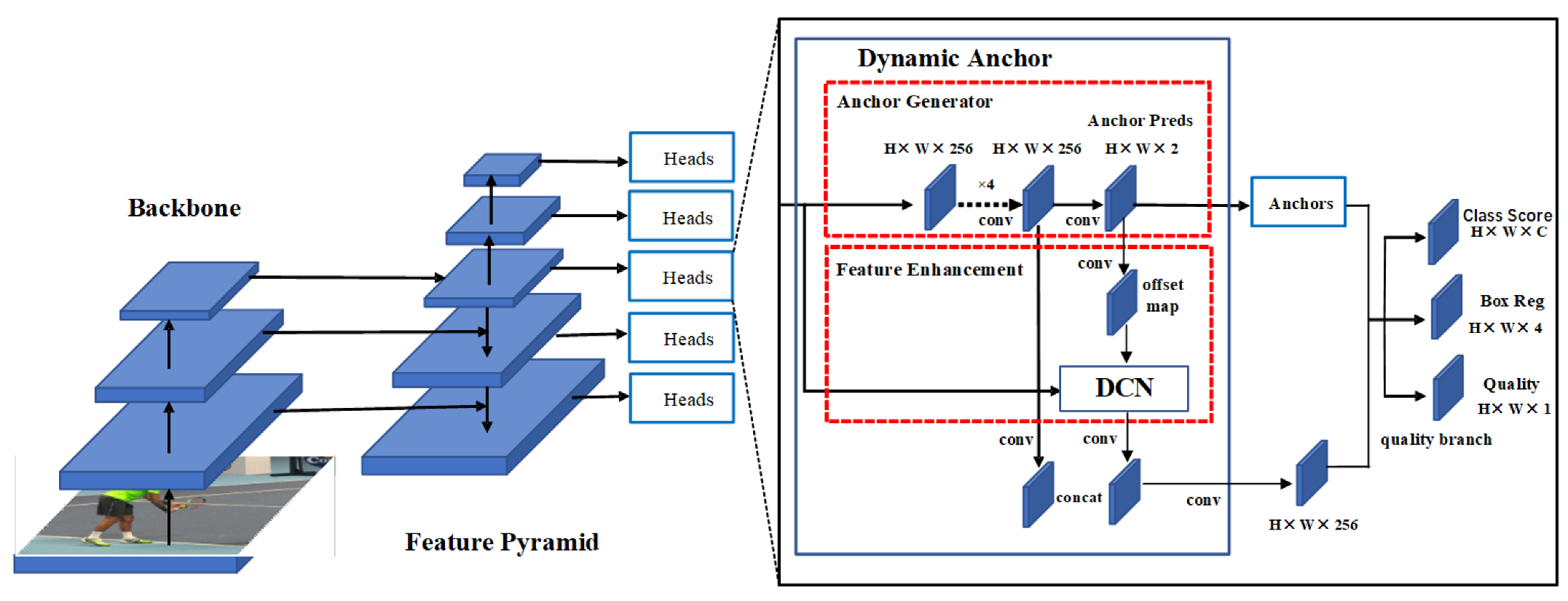
3. Dynamic Anchor
3.1. Anchor Generator
3.1.1. Anchor Shape Targets
3.1.2. Anchor Shape Prediction
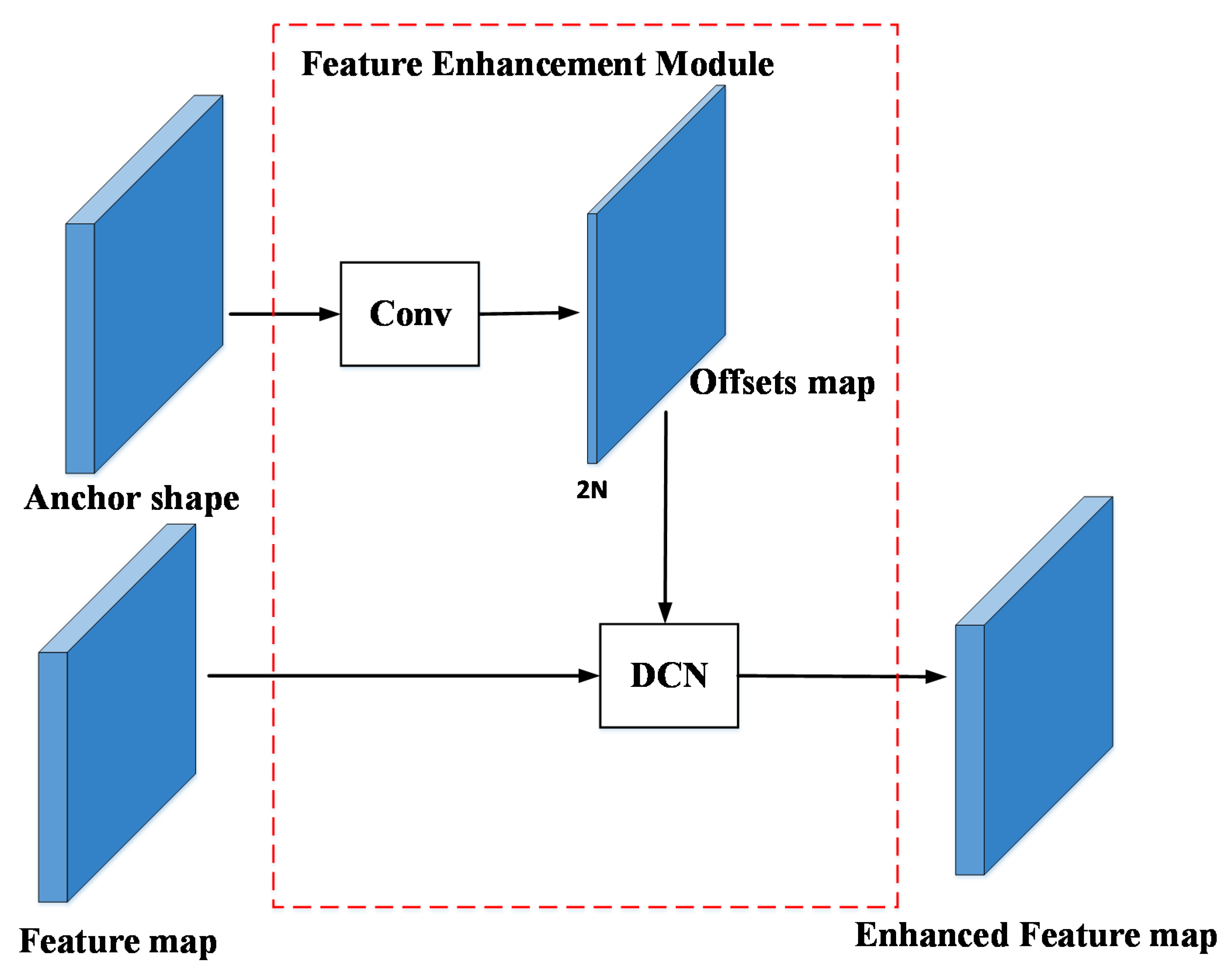
3.2. Feature Enhancement Module
3.3. Quality Branch
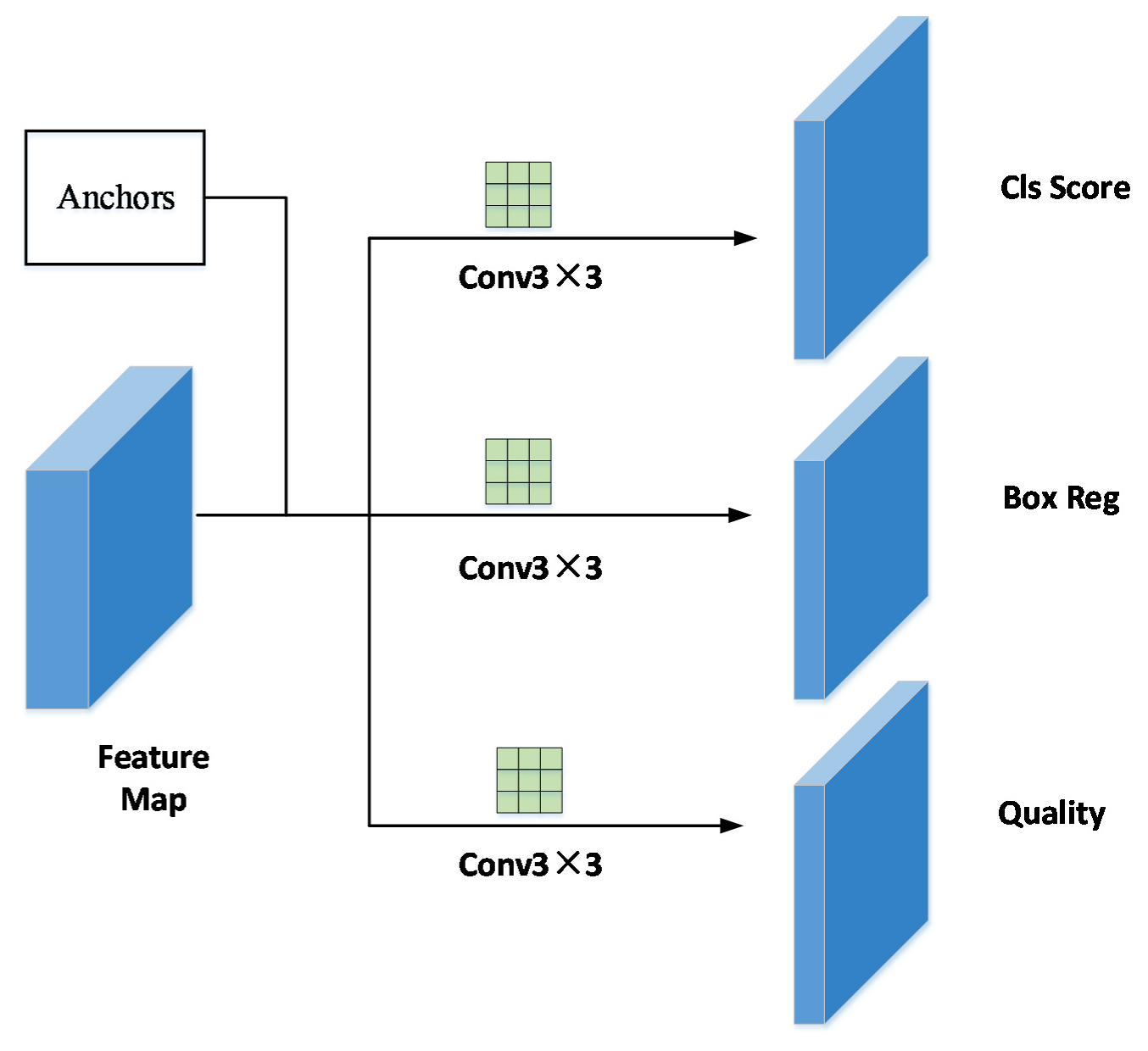
3.4. Model Train
3.4.1. Anchor with FPN
3.4.2. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Ablation Study on COCO
4.3. Visualizing Dynamic Anchor
4.4. Comparison
4.5. Visualization Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Huang, Z.; Chen, H.; Zhou, T.; Yang, Y.; Liu, B. Multi-level cross-modal interaction network for RGB-D salient object detection. Neurocomputing 2021, 452, 200–211. [Google Scholar] [CrossRef]
- Liu, B.; Chen, H.; Huang, Z.; Liu, X.; Yang, Y. ZoomInNet: A Novel Small Object Detector in Drone Images with Cross-Scale Knowledge Distillation. Remote Sens. 2021, 13, 1198. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolo9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, June 26–July 1 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; ACM: New York, NY, USA, 2016; pp. 516–520. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 734–750. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 840–849. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6569–6578. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 9759–9768. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region Proposal by Guided Anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2965–2974. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, January 27–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 9259–9266. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4203–4212. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object Detection via Region-Based Fully Convolutional Networks. In Advances in Neural Information Processing Systems, Proceedings of the 2016 Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; NIPS: Los Angeles, CA, USA, 2016; p. 3. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6154–6162. [Google Scholar]
- Zhong, Q.; Li, C.; Zhang, Y.; Xie, D.; Yang, S.; Pu, S. Cascade region proposal and global context for deep object detection. Neurocomputing 2020, 395, 170–177. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Lee, H.S. Probabilistic Anchor Assignment with Iou Prediction for Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 355–371. [Google Scholar]
- Yang, T.; Zhang, X.; Li, Z.; Zhang, W.; Sun, J. Metaanchor: Learning to Detect Objects with Customized Anchors. Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; NIPS: Los Angeles, CA, USA, 2018; p. 31. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 764–773. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 850–855. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Lin, D. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| *. | SAM | DCN | AP | AP50 | AP75 | APS | APM | APL | ARS | ARM | ARL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | 36.7 | 53.9 | 39.8 | 19.9 | 42.1 | 48.6 | 32.2 | 59.5 | 70.6 | ||
| √ | 36.4 | 53.4 | 39.2 | 19.4 | 41.8 | 47.8 | 32.0 | 58.9 | 69.6 | ||
| √ | 37.0 | 53.9 | 40.2 | 19.1 | 41.6 | 50.2 | 31.9 | 59.0 | 71.3 |
| AP | AP50 | AP75 | AR100 | AR300 | AR1000 | |
|---|---|---|---|---|---|---|
| None | 36.7 | 54.3 | 39.8 | 52.9 | 52.9 | 52.9 |
| Quality | 37.2 | 54.6 | 40.2 | 54.7 | 54.7 | 54.7 |
| Sampling Ratio | AP | AP50 | AP75 | APS | APM | APL | ARS | ARM | ARL |
|---|---|---|---|---|---|---|---|---|---|
| None | 37.2 | 54.4 | 40.2 | 20.2 | 41.6 | 50.4 | 33.5 | 59.0 | 70.6 |
| 1 | 37.2 | 54.6 | 40.2 | 20.5 | 42.3 | 49.5 | 32.6 | 59.9 | 71.4 |
| 1.5 | 37.3 | 54.8 | 40.2 | 20.1 | 42.1 | 49.6 | 33.2 | 59.6 | 70.6 |
| 2 | 37.5 | 54.9 | 40.5 | 20.1 | 42.4 | 50.7 | 32.5 | 59.3 | 70.8 |
| Method | Backbone | AP | AP50 | AP75 | APS | APM | APL | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| RetinaNet | ResNet-50 | 35.9 | 55.4 | 38.8 | 19.4 | 38.9 | 46.5 | 201.53 |
| GA-RetinaNet | ResNet-50 | 37.1 | 56.9 | 40.0 | 20.1 | 40.1 | 48.0 | 197.43 |
| DA-RetinaNet(ours) | ResNet-50 | 38.0 | 55.5 | 41.2 | 20.1 | 41.8 | 48.5 | 141.79 |
| RetinaNet | ResNet-101 | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 | 277.6 |
| GA-RetinaNet | ResNet-101 | 38.4 | 58.5 | 41.3 | 21.0 | 41.1 | 49.7 | 273.5 |
| DA-RetinaNet(ours) | ResNet-101 | 40.0 | 57.9 | 43.5 | 21.5 | 44.1 | 51.2 | 217.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Chen, H.-X.; Liu, B.-Y. Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection. Appl. Sci. 2022, 12, 4897. https://doi.org/10.3390/app12104897
Liu X, Chen H-X, Liu B-Y. Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection. Applied Sciences. 2022; 12(10):4897. https://doi.org/10.3390/app12104897
Chicago/Turabian StyleLiu, Xing, Huai-Xin Chen, and Bi-Yuan Liu. 2022. "Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection" Applied Sciences 12, no. 10: 4897. https://doi.org/10.3390/app12104897
APA StyleLiu, X., Chen, H. -X., & Liu, B. -Y. (2022). Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection. Applied Sciences, 12(10), 4897. https://doi.org/10.3390/app12104897