
Trusted Electronic Contract for Enabling Peer-to-Peer HPC Resource Sharing


Abstract
:1. Introduction
- Present architecture design of trusted network based on blockchain technology, smart contract logic, and role-based permission for restricting entities’ actions on network resources and function calls.
- Present a secure gateway service for enabling communication between HPC clusters and blockchain. It facilitates authentication, initiating a secure connection, and asynchronously performing actions according to blockchain events.
- Present a system monitoring service that periodically sends out updates on the cluster’s data states to the blockchain (i.e., cluster health, job status). The service will help monitor HPC’s states without interfering with the operational pipeline.
2. Literature Review
3. Proposed Design
3.1. Overview of System Architecture and Components in Trusted Computing Resource Sharing
- Majority voting-replicate job execution on multiple compute workers (let us say, n workers). The results obtained by the majority are assumed to be correct. The drawback of the scheme is intensive resource consumption as the computational resources needed are multiplied by a factor of n.
- Result validation—in this option, a user must implement a module to validate if the results he/she obtained are correct. However, the implementation of such a scheme is complex and requires efforts from users to some extent.
3.2. Smart Contract Design and Communication Flow
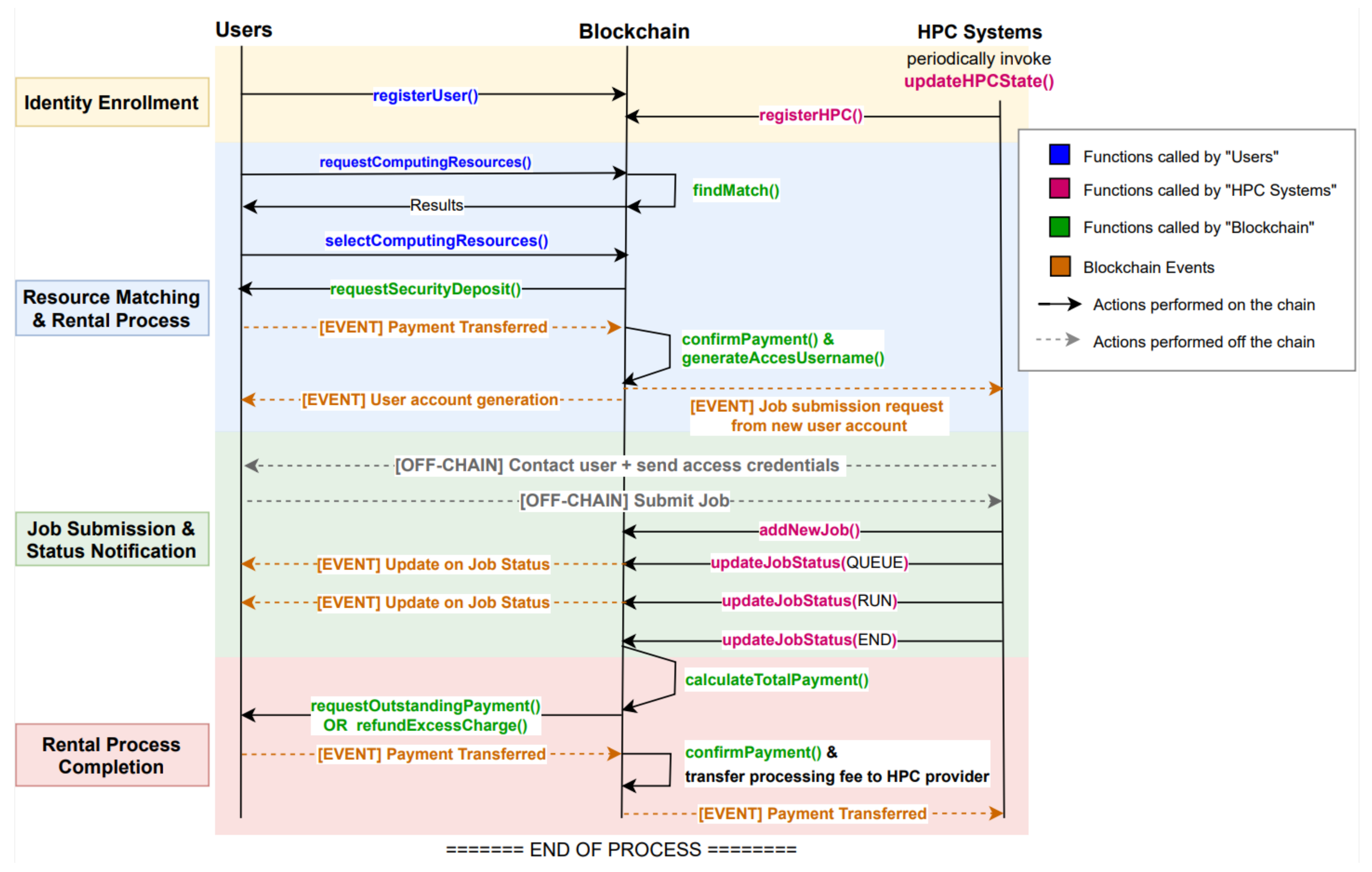
- Identity enrolment For the first time entering the system, clients (users and HPC systems) are required to go through a registration process which could be carried out manually or automatically depending on the level of strictness of the onboarding process. Once the consideration process is passed, clients will be assigned to a specific role and cryptographic credentials corresponding to identity will be generated. The private key will be stored locally on client machines, while public credentials will be sent to the blockchain. These cryptographic materials will be used in signing transactions produced by clients, allowing the blockchain to validate if the transaction’s owner is permitted before executing the requested functions. Displayed in Table 1, role-based permission is defined on network resources and business logic execution.
- Resource Matching The system needs to ensure users are matched to the suitable resources at satisfactory rental prices and providers can benefit from renting computing resources. On user requests for job submission, the blockchain will perform searching through the HPC system information (obtained during the HPC registration process (Figure 5a) to find a set of candidates based on the user’s requirements (e.g., resource spec, programs, etc.). The result set will be returned along with the latest cluster state (Figure 5b) and rental price, which is slightly adjusted according to the distance between user location and the HPC system to encourage utilizing local resources. Users can select the options based solely on system information (without revealing provider names) to promote competitiveness and encourage new providers to compete in the ecosystem. Pseudocode for finding a candidate set of HPC systems is presented as follows:
| Algorithm 1.Pseudocode of findResourceMatching(). |
| Return Lists of Resources That Match to User’s Job Requirement |
| Input: Object containing desired resources spec from user (DRuser) |
| 1: MatchedSpec ← query list of matched_cluster’s IDs in which PR<matched_cluster> exists some queues that has max_cores > DRuser.cores and gpu == DRuser.require_gpu |
| 2: Candidates = a subset of MatchedSpec in which DRuser.program ∊ PR<matched_cluster>.programs |
| 3: if Candidates == ø then |
| 4: for all IDs ∈ MatchedSpec do |
| 5: if PRID .willingToInstallAdditionalPrograms then |
| 6: Candidates.push(ID) |
| 7: return Candidates |
| Algorithm 2. Pseudocode of displayResourcesAndRentalPrice() |
| Return List of Clusters (with the Adjusted Rental Price and Utilization State) That Match to User’s Job |
| Input: Object containing desired resources spec from user (DRuser), current user location |
| 1: results = [] |
| 2: Candidates = findResourceMatching(DRuser) |
| 3: for all IDs ∊ Candidates do |
| 4: differentDistance = calculate approximated distance between 2 IPs (user and PRID.IP) |
| 5: [adjustedCPUprice, adjustedGPUprice] = weighPriceByDistance (differentDistance , [PRID.rate.cpu_core_per_hr, PRID.rate.gpu_core_per_hr(*optional)]) // adjust price based on distance |
| 6: HSID ← query HealthState Object by cluster ID |
| 7: results.push({ID: PRID.clusterID, queues:{ available: PRID.queues, current_state: HSID.queues], rate: {cpu: adjustedCPUprice, gpu: adjustedGPUprice }}) |
| 8: return results |
- 3.
- Rental Process Once the user chooses an HPC system and a preferred queue type from the candidate list, he/she then composes and submits a transactional request to the blockchain. The user will then be requested to pay a security deposit which calculated from
3.3. Job Submission & Status Notification
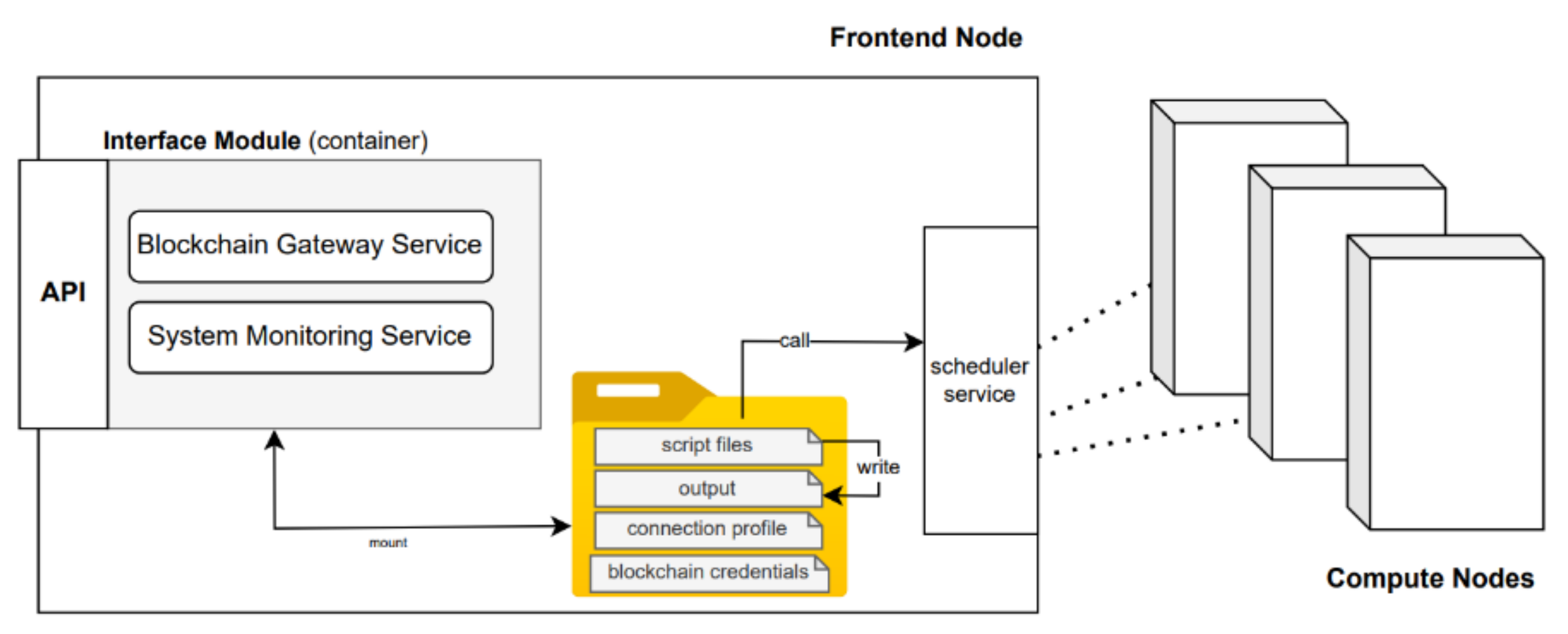
Design of Interface Module
- Blockchain Gateway Service—is a service that facilitates data exchange between HPC and blockchain. Its key functionalities are composing, signing, and submitting transactions to the blockchain on behalf of the HPC cluster. It also subscribes to blockchain’s event hub to listen for smart contract events. Upon a new event arrival, it will send a request to the system monitoring service to perform system actions corresponding to the event types. It uses a network connection profile* for discovering peers in the network and uses cryptographic materials* for presenting eligibility in performing on-chained actions. (* these files are available in a mounted directory).
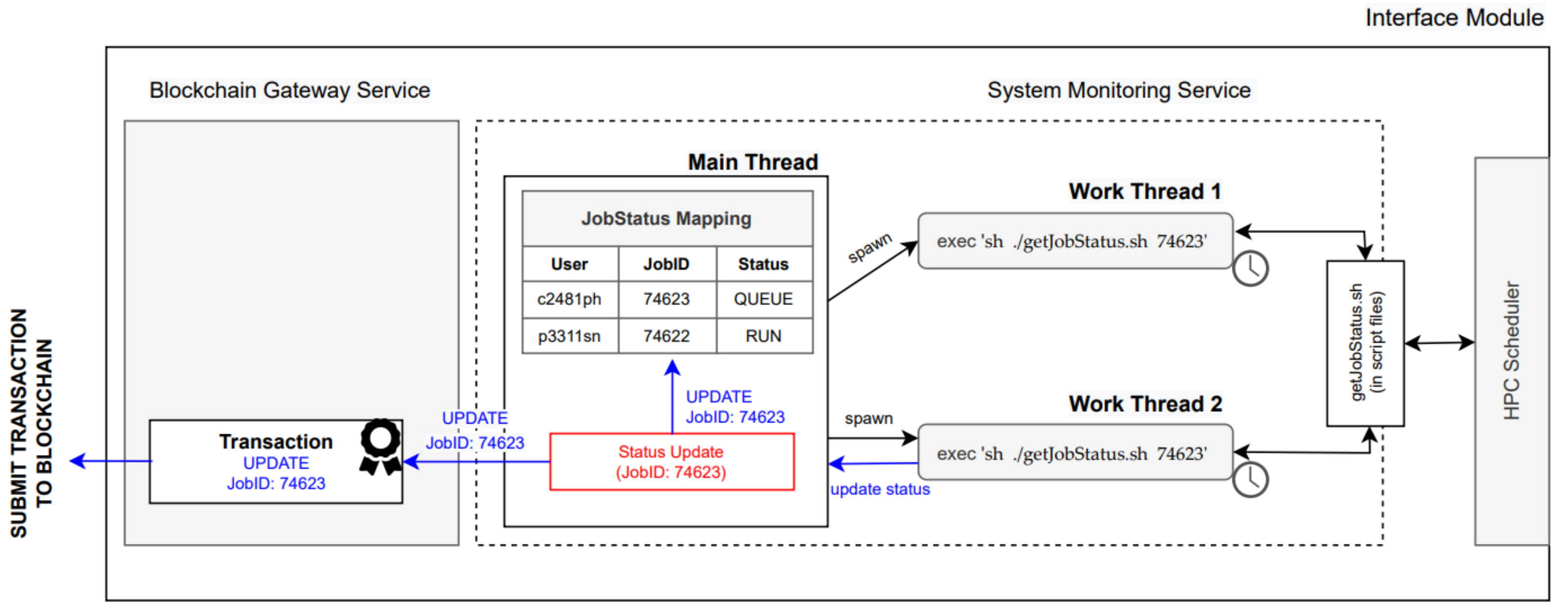
- System Monitoring Service—helps monitor changes in system states by spawning threads to monitor attentive processes. It also opens a port for listening to the incoming requests. There are two types of operations performed in this module. The first is an asynchronous operation that will execute once there is an incoming request from the blockchain gateway service. For example, blockchain gateway service has received an event notifying new job submission from blockchain, it will then call /addJobMonitoring endpoint on the port listening by system monitoring service. The service then executes the command from bash scripts* to perform system action and return the result back correspondingly. The second type is scheduling operation. For example, for all jobs that are submitted to the system, the service will periodically perform checking if the states of jobs are changed (illustrated in Figure 7). If there are, the changes will be packed and sent to the Blockchain Gateway Service to update the job’s states on the blockchain.
- Action Scripts—These are the scripts that are called by System Monitoring Service. It helps perform querying on the scheduler to attain the overall status of HPC components as well as job and queue state. Regardless of the differences in scheduler commands that vary according to scheduler brands, we define a standard structure format for output (i.e, stdout) produced by scripts to ensure the results are understandable by other dependent services.
- Blockchain’s Crypto Materials—Used by Blockchain Gateway Service, crypto materials (e.g., public key, private key, and certificates) are files that were used to represent HPC identity in blockchain space. Any transaction generated by the cluster must be digitally signed before being published out to the network. As mentioned earlier, these credentials are registered to a specific role according to RBAC policy to prohibit an entity from performing irrelevant or unauthorized on-chained actions.
- Network Connection Profile—contains network topology, allows the cluster to discover and be discovered by other peers in the blockchain network.
4. Implementation
4.1. Blockchain Network Setup
1: const ClientIdentity = require(‘fabric-shim’).ClientIdentity; (Smart Contract – function)
2: function requestComputingResources(arguments) {
3: let cid = new ClientIdentity(stub);
4: if (cid.assertAttributeValue(‘node_name’, ‘HPC_user){ // assert if the requester is user of HPC service
5: // perform matching
6: } else { throw new Error(‘Invoking Entity is Unauthorized’);}
7: }
4.2. Implementation of Interface Module
- Sub-module #1: Blockchain Gateway Service
1: const enrollment = await ca.enroll({ enrollmentID: <username>, enrollmentSecret: <secret>}); // request enrolment to CA
2: const identity = X509WalletMixin.createIdentity(<clusterMSP>, enrollment.certificate, enrollment.key.toBytes());
3: wallet.import(<username>, identity); // import identity to wallet
- Sub-module #2: System Monitoring Service
1: var listOfActiveJobs = [ {"jobID": "57714", "status": "RUN", "owner": "kajornsak", “isMonitored”: true }, ….] // job monitoring list (app.js)
2: app.post('/addJobMonitoring', (req, res) => { // endpoint for requesting adding new job
3: listOfActiveJobs.push({"jobID": req.body.job_id, "status": null, owner": req.body.username, “isMonitored”: false })
4: res.send(`jobID "${jobID}" is being added`); });
5: function createMonitoringWorker(jobID, status) {
6: let worker = new Worker('./worker.js', { workerData: { jobID: jobID, currentStatus: status } }); // create job monitoring worker
7: worker.once("message", result => { // worker return an update in job status
8: let newStatus = result[jobID] // sample result { "jid01234": "QUEUE" }
9: if(newStatus === "END"){ // if the job’s computing is done, send update to blockchain service and remove job from monitor list
10: axios.post('localhost:5000/updateJobStatus', result).then((response)=>{ console.log(response.data) })
11: listOfActiveJobs = listOfActiveJobs.filter(obj => obj["jobID"] != jobID);
12: }else{ // if the job’s status is changed, send update to blockchain service and update the local list of job status
13: axios.post('localhost:5000/updateJobStatus', result).then((response)=>{ console.log(response.data) })
14: listOfActiveJobs = listOfActiveJobs.map(obj => obj["jobID"] === jobID? { ...obj, status: newStatus} : obj );
15: }});
16: }
17: while (listOfActiveJobs.length !== 0) { listOfActiveJobs.map((job) => { if ( ! job. isMonitored) { createMonitoringWorker(job.jobID, job.status) }}) }
18: app.listen(3000, () => { console.log(`Listening at http://localhost:3000`); });
1: function getJobStatusUpdate(){ (worker.js)
2: exec("sh ~/getJobStatus.sh " + workerData.jobID, function (err, stdout, stderr) {
3: stdout.on('data', (data) => {
4: let latestStatus = data
5: if (latestStatus !== workerData.currentStatus) {
6: parentPort.postMessage({"jobID": workerData.jobID, "new_status": latestStatus}) // all jobs of the user with the states
7: }else{ setTimeout(getJobStatusUpdate, 3600000); }
8: }); }); }
9: getJobStatusUpdate()
- Script Files
1: #!/bin/bash (getResourceUtilization.sh – for TORQUE scheduler) 2: PBS_PROGRAM="/opt/torque/bin"; USER_NAME=$(whoami); COMPUTE=Compute-name; # Select scheduler, Specify username and compute node name 3: for i in {0..x} # Loop through all compute nodes (0-x) 4: do # 1. Get raw output of CPU cores usage per job 5: mapfile -t jobs < <($PBS_PROGRAM/pbsnodes $COMPUTE-$i-ib | grep "jobs ="); # Output: “corestart - coreend /<PID>.<compute_node_name>” 6: echo $(jobs[0])|sed -e 's/… Formatting raw data until obtain array of jobs’ cores …/$COMPUTE-$i.raw > ./$COMPUTE-$i.cores; # 2. Output: [ Job1’s corestart–Job1’s coreend , ….] 7: mapfile -t state < <($PBS_PROGRAM/pbsnodes $COMPUTE-$i-ib | grep "state =" | head -n 1 | awk '{print $3}'); # 3. Get node status 8: mapfile -t np < <($PBS_PROGRAM/pbsnodes $COMPUTE-$i-ib | grep "np =" | awk '{print $3}'); # 4. Get node’s max CPU cores 9: IFS=', ' read -r -a array <<< "$(cat ./$COMPUTE-$i.cores)" # Read jobs’ cpu cores to array 10: total_cores = 0; 11: for j in ${!array[@]}; # Loop through elements in array (ex. [“2”,”58”, “68-69”, “73-84”] ) 12: do 13: if [[ "$((array[$j]))" =~ [-] ]]; then # CASE : Multiple cores (ex. “73-84”) 14: item=$((array[$j])); # “73-84” 15: used_cores=$((item*(-1)+1)); # Turn string into math operation : 73-84 = -11 (-11)*(-1) 11 + 1 16: total_cores=$(( total_cores + used_cores)); 17: else # CASE : Single cores (ex. “2”) 18: total_cores =$(( total_cores +1)); 19: fi 20: done 21: echo -e "$COMPUTE-0$i: : { “utilization”: $total_cores/$(cat . /$COMPUTE-$i.max_cores) , “status”: $(cat . /$COMPUTE-$i.status)} 22: done
5. Performance Evaluation and Security Analysis
5.1. Performance Evaluation
- Blockchain Network
- b
- HPC Interface Module
5.2. Security Analysis
- Access Control on Blockchain Network Resources
- 2
- Event Subscription—HTTP Systems, Users
- 3
- Account Generation
- 3
- HPC Interface Module
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Razzaq, S.; Wahid, A.; Khan, F.; Amin, N.; Shah, M.; Akhunzada, A.; Ihsan, A. Scheduling Algorithms for High-Performance Computing: An Application Perspective of Fog Computing. In Recent Trends and Advances in Wireless and IoT-Enabled Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 107–117. [Google Scholar]
- Park, J. Queue Waiting Time Prediction for Large-scale High-performance Computing System. In Proceedings of the 2019 International Conference on High Performance Computing Simulation (HPCS 2019), Dublin, Ireland, 15–19 July 2019; pp. 850–855. [Google Scholar]
- Hovestadt, M.; Kao, O.; Keller, A.; Streit, A. Scheduling in HPC Resource Management Systems: Queuing vs. Planning. In Proceedings of the Job Scheduling Strategies for Parallel Processing (JSSPP), Seattle, WA, USA, 24 June 2003. [Google Scholar]
- Piyounkorn, K.; Kasisopha, N.; Thaenkaew, P.; Vorakulpipat, C. Automating Job Monitoring System for an Ecosystem of High Performance Computing. In Proceedings of the 9th International Conference on Management of Digital EcoSystems (MEDES ‘17), Bangkok, Thailand, 7–10 November 2017; pp. 281–286. [Google Scholar]
- Piyoungkorn, K.; Thaenkaew, P.; Vorakulpipat, C. A Resource-saving Job Monitoring System of High Performance Computing using Parent and Child Process. In Proceedings of the International Symposium on Grids & Clouds 2019, Taipei, Taiwan, 31 March–5 April 2019. [Google Scholar]
- Valles, D.; Williams, D.; Nava, P. Scheduling Modifications for Improvement of Performance on a Beowulf Cluster Single Node. In Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, Washington, DC, USA, 10–16 November 2012. [Google Scholar]
- Valles, D.; Williams, D.; Nava, P. Load Balancing Approach Based on Limitations and Bottlenecks of Multi-core Architectures on a Beowulf Cluster Compute-Node. In Proceedings of the 2012 International Conference on Parallel and Distributed Processing Techniques and Applications, Las Vegas, NV, USA, 16–19 July 2012. [Google Scholar]
- Ferro, M.; Klôh, V.; Gritz, M.; Sá, V.; Schulze, B. Predicting Runtime in HPC Environments for an Efficient Use of Computational Resources. In Proceedings of the XXII Symposium on High Performance Computing Systems, Belo Horizonte, Brazil, 26–28 October 2021. [Google Scholar]
- Liu, D.; Zhang, Y.; Zhang, H.; Lou, F. User behavior control method for HPC system. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 2918–2922. [Google Scholar]
- Digital Government Development Agency. Open Government Data of Thailand. Available online: https://data.go.th/en/ (accessed on 28 March 2022).
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 28 March 2022).
- Zikratov, I.; Kuzmin, A.; Akimenko, V.; Niculichev, V.; Yalansky, L. Ensuring data integrity using Blockchain technology. In Proceedings of the 20th Conference of Open Innovations Association (FRUCT), Saint Petersburg, Russia, 3–7 April 2017; pp. 534–539. [Google Scholar]
- Ralph, C.M. A digital signature based on a conventional encryption function. In Proceedings of the Advances in Cryptology-CRYPTO ‘87, Santa Barbara, CA, USA, 16–20 August 1987. [Google Scholar]
- Arthur, G.; Ghassan, O.K.; Karl, W.; Vasileios, G.; Hubert, R.; Srdjan, C. On the Security and Performance of Proof of Work Blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘16), Vienna, Austria, 24–28 October 2016; pp. 3–16. [Google Scholar]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A Provably Secure Proof-of-Stake Blockchain Protocol. In Proceedings of the 37th Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017. [Google Scholar]
- Castro, M.; Liskov, B. Practical Byzantine fault tolerance. In Proceedings of the Third Symposium on Operating Systems Design and Implementation, New Orleans, LA, USA, 22–25 February 1999; pp. 173–186. [Google Scholar]
- Sasin School of Management. Thailand’s First Centralized Blockchain Transcript Verification Platform. Available online: https://www.sasin.edu/content/news/thailands-first-centralized-blockchain-platform-to-verify-transcripts (accessed on 20 March 2022).
- Bank of Thailand. DLT Scripless Bond. Available online: https://www.bot.or.th/Thai/DebtSecurities/Documents/DLT%20Scripless%20Bond.pdf (accessed on 20 March 2022).
- BCI (Thailand) Co., Ltd. Thailand Launches Blockchain Letters of Guarantee Network for 22 Banks. Available online: https://www.bci.network/post/thailand-launches-blockchain-letters-of-guarantee-network-for-22-banks (accessed on 20 March 2022).
- Ministry of Public Health, Thailand. eHealth Strategy. Available online: https://ict.moph.go.th/upload_file/files/eHealth_Strategy_ENG_141117.pdf (accessed on 20 March 2022).
- Electricity Generating Authority of Thailand. National Energy Trading Platform. Available online: https://www.egat.co.th/home/en/national-energy-trading-platform/ (accessed on 20 March 2022).
- Bangkok Post Public Company Limited. Blockchain easing customs process. Available online: https://www.bangkokpost.com/tech/1738611/blockchain-easing-customs-process (accessed on 20 March 2022).
- Abdullah, A.M.; Feng, Y.; Dongfang, Z. BAASH: Lightweight, efficient, and reliable blockchain-as-a-service for HPC systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’21), St. Louis, MO, USA, 14–19 November 2021; pp. 1–18. [Google Scholar]
- Al-Mamun, A.; Li, T.; Sadoghi, M.; Jiang, L.; Shen, H.; Zhao, D. HPChain: An MPI-Based Blockchain Framework for Data Fidelity in High-Performance Computing Systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’19), Denver, CO, USA, 17–19 November 2019. [Google Scholar]
- Toyoda, K.; Mathiopoulos, P.T.; Sasase, I.; Ohtsuki, T. A Novel Blockchain-Based Product Ownership Management System (POMS) for Anti-Counterfeits in the Post Supply Chain. IEEE Access 2017, 5, 17465–17477. [Google Scholar] [CrossRef]
- Al-Mamun, A.; Li, T.; Sadoghi, M.; Zhao, D. In-memory Blockchain: Toward Efficient and Trustworthy Data Provenance for HPC Systems. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3808–3813. [Google Scholar]
- Khalil, A.; Maher, K.; Abdullah, B.; Fathy, E.; Kamal, M.J.; Khalid, A. Big Data Security and Privacy: A Taxonomy with Some HPC and Blockchain Perspectives. IJCSNS 2021, 21, 43–55. [Google Scholar]
- Sarmenta, L.F.G. Sabotage-tolerance mechanisms for volunteer computing systems. In Proceedings of the First IEEE/ACM International Symposium on Cluster Computing and the Grid, Brisbane, QLD, Australia, 15–18 May 2001; pp. 337–346. [Google Scholar]
- iExec. Whitepaper: Blockchain-Based Decentralized Cloud Computing. Available online: https://iex.ec/wp-content/uploads/pdf/iExec-WPv3.0-English.pdf (accessed on 20 March 2022).
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains. In Proceedings of the 13th EuroSys Conference, Porto, Portugal, 23–26 April 2018. [Google Scholar]
- The Linux Foundation. The Ordering Service. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/orderer/ordering_service.html (accessed on 20 March 2022).
- Diego, O.; John, O. In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference, Philadelphia, PA, USA, 19–20 June 2014; pp. 305–320. Available online: https://raft.github.io/raft.pdf (accessed on 20 March 2022).
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- The Linux Foundation. Kubernetes. Available online: https://kubernetes.io/ (accessed on 20 March 2022).
- The Linux Foundation. Hyperledger Caliper. Available online: https://www.hyperledger.org/use/caliper (accessed on 20 March 2022).
- Apache Software Foundation. Apache Kafka. Available online: https://kafka.apache.org/documentation (accessed on 20 March 2022).
- Kurtzer, G.M.; Sochat, V.; Bauer, M.W. Singularity: Scientific containers for mobility of compute. PLoS ONE 2017, 12, e0177459. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blockchain Resources | Network Resources | Smart Contract Functions | |||
|---|---|---|---|---|---|
| User Role | Transactions | System Activities | Event Hub | ||
| HPC provider | Able to submit READ & WRITE transactions | - | Able to subscribe to events | Functions specified in “HPC System” Object in Figure 3 | |
| User | Able to submit READ & WRITE transactions | - | Able to subscribe to events | Functions specified in “User” Object in Figure 3 | |
| Admin | Able to submit READ-only transactions | Able to register new clients | - | getHpcSystemDetail(),getUserDetail(), listAllHpcSystems(),listAllUsers() | |
| System Node | - | Able to perform system action | Able to publish events | Functions specified in “ResourceSharingContract” in Figure 3 | |
| Transaction Types | Ordering Service Type | ||
|---|---|---|---|
| Single-Node | Multi-Node | ||
| Solo | Kafka | Raft | |
| Query | 0.01s | 0.06s | 0.02s |
| Invoke | 0.34s | 0.85s | 0.68s |
| Network Deployment | Query Transaction Latency | Invoke Transaction Latency | ||||
|---|---|---|---|---|---|---|
| Min | Max | Avg. | Min | Max | Avg. | |
| Single Host | 0.01s | 0.05s | 0.01s | 0.57s | 0.88s | 0.68s |
| Multiple Hosts | 0.08s | 0.36s | 0.18s | 0.61s | 1.96s | 1.24s |
| Test Round # | Execution Time (ms) | |||
|---|---|---|---|---|
| 1 | 9.519627 | 36.556 | 616.693 | 0.175355 |
| 2 | 8.422683 | 39.495 | 718.583 | 0.378252 |
| 3 | 7.491831 | 38.483 | 681.012 | 0.28282 |
| 4 | 9.348326 | 38.234 | 649.233 | 0.325491 |
| 5 | 8.6374 | 37.424 | 672.796 | 0.29372 |
| Average | 8.6839734 | 38.0384 | 667.663 | 0.2911276 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piyoungkorn, K.; Chaisawat, S.; Vorakulpipat, C. Trusted Electronic Contract for Enabling Peer-to-Peer HPC Resource Sharing. Appl. Sci. 2022, 12, 5153. https://doi.org/10.3390/app12105153
Piyoungkorn K, Chaisawat S, Vorakulpipat C. Trusted Electronic Contract for Enabling Peer-to-Peer HPC Resource Sharing. Applied Sciences. 2022; 12(10):5153. https://doi.org/10.3390/app12105153
Chicago/Turabian StylePiyoungkorn, Kajornsak, Siriboon Chaisawat, and Chalee Vorakulpipat. 2022. "Trusted Electronic Contract for Enabling Peer-to-Peer HPC Resource Sharing" Applied Sciences 12, no. 10: 5153. https://doi.org/10.3390/app12105153
APA StylePiyoungkorn, K., Chaisawat, S., & Vorakulpipat, C. (2022). Trusted Electronic Contract for Enabling Peer-to-Peer HPC Resource Sharing. Applied Sciences, 12(10), 5153. https://doi.org/10.3390/app12105153