1. Introduction
The Bangla language is well-known around the world, and it is the fifth most spoken language on the planet [
1]. The population of Bangladesh speak two different varieties of Bangla. Few people speak the local language of their region. The mainstream Bangla language, which is spoken by about 290 million people, is another variety. There are 55 regional languages spoken in Bangladesh’s 64 districts. A regional language, also known as a dialect, is a language a child learns organically without the use of written grammar, and that varies by region. It is a characteristic of languages that are widely spoken in a given location [
1] that causes morphological differences in the sounds of the ideal language or literary language. Despite regional variations, the Bangla language can be divided into six classes: Bangla, Manbhumi, Varendri, Rachi, Rangpuri, and Sundarbani. This study primarily focused on seven regional languages; Khulna, Bogra, Rangpur, Sylhet, Chittagong, Noakhali, and Mymensingh divisions, which all belong to one of these classes, and one was chosen at random. A person’s regional language can be identified by the wave frequency (pronunciation) of a word pronounced in Bangla.
On a global scale, the human voice is the most widely used method of communication between machines and humans. Dialects are what bind individuals together. Dialects help people convey their ideas more effectively. As stated by Honnet et al. [
2], speech recognition is the ability of a machine or computer software to recognize phrases and words in spoken language and translate them into machine-readable form. Voice signals contain not only information about the content of speech, but also about the speaker’s identity, emotions, age, gender, and geographical location. In human-computer interaction (HCI), voice signals are also crucial.
Identifying characteristics of audio streams automatically has recently been a hot topic of research for the Bangla language [
1,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. Application development based on consumer regional language, age, or gender, as well as a caller-agent coupling in contact centers that correctly allocates agents according to the caller’s identity, are made possible by an accurate and efficient extraction of speaker identification from a voice signal. However, in most of these studies, the speaker’s regional language is not categorized or a method for detecting synthetic Bangla speech audio signals is not presented. Several works have been done on creating synthesized Bangla speech. According to Rahut [
13], Sharma [
17], and Gutkin [
12], the result is a deficient automatic speech recognition (ASR) and text-to-speech (TTS) system for the Bangla language. Bangla sentence grammar and phonetic construction differ from English sentence grammar and phonetic construction. A typical Bangla sentence has a subject followed by an object and then a verb. Bangla sentences do not use the auxiliary verb, and the subject comes before the object, as it has been pointed out by Ohi [
6]. Additionally, the preposition must be placed before a noun or else noun-equivalent words must be used when constructing regional Bangla language sentences. It takes a large vocabulary and a lot of phoneme patterns to recognize speech in Bangla.
In a detailed work published on the challenges and opportunities for Bangla language speech recognition [
18], it was noted that, in order for any system to recognize the features in Bangla speech, it must understand the structure of Bangla language grammatically and phonetically to build a flawless ASR and TTS system. Previous researchers have also encountered language-dependent and language-independent challenges when trying to recognize Bangla speech.
For creating a flawless ASR system that produces clean artificial Bangla speech, Mridha et al. [
18] emphasized the importance of a large grammatical and phonetic database. One has to use a database with a large vocabulary and phoneme patterns in the Bangla language in order to build an ASR [
7,
19] system that works flawlessly for the Bangla language. There are no public or private databases available for Bangla speech that contain extensive jargon. This is one of the many reasons why research carried out over the past decade on recognition features in Bangla speech has failed to investigate regional language during Bangla speech feature classification because of database limitations.
There is a comprehensive study of Bangla speech recognition, presented in [
14] classification of Bengali accent using deep learning (DL). Hence, the authors failed to build or use the broad corpus necessary to distinguish regional dialects, receiving an accuracy score of 86%. The authors in [
20] used neural networks to detect hate speech in social media and achieved an accuracy rate of 77 percent. Rahut, Riffat, and Ridma in [
13] reported an accuracy score of 98.16% for the classification of abusive words in Bangla speech by using VGG-16. The Deep CNN model developed by Sharmin et al. in [
5] was able to classify Bangla spoken digits with 98.3% accuracy.
For unsupervised learning of sparse and temporal hierarchical features to audio signals, autoencoder neural networks were used [
21,
22,
23,
24,
25,
26,
27,
28]. In [
21] , the authors used a convolutional autoencoder along with Mel Frequency Energy Coefficients (MFEC) data to identify anomalies in different types of machine sounds. Their method produced better results than the baseline. Researchers previously developed a variety of methods for recognizing the gender and age of speakers in Bangla. They focused on two key parts: identifying the optimal features and building a model that is able to recognize those features across various types of speech communication. They achieved an accuracy of 90% for gender and age classification. Anvarjon et al. [
29] built an end-to-end CNN with a multi-attention module, able to extract the salient spatial and temporal features and recognize age and gender from speech signals. Due to the use of MFECs input data, the authors in [
30] used multi-layers perceptron (MLP) to learn the gender and speaker identity features and it outperformed the CNNs model [
29]. To the best of our knowledge, the classification of dialects in Bangla language and detection of synthesized Bangla speech has never been done.
Therefore, the previous work [
13] influenced our proposed model for Bangla audio classification of regional language in Bangla speech based on acoustic features and for detecting artificial Bangla speech from audio signals in this paper. The understanding of how to approach this problem was gained from the work done by authors in [
31,
32] to classify regional languages from American English and Chinese speech.
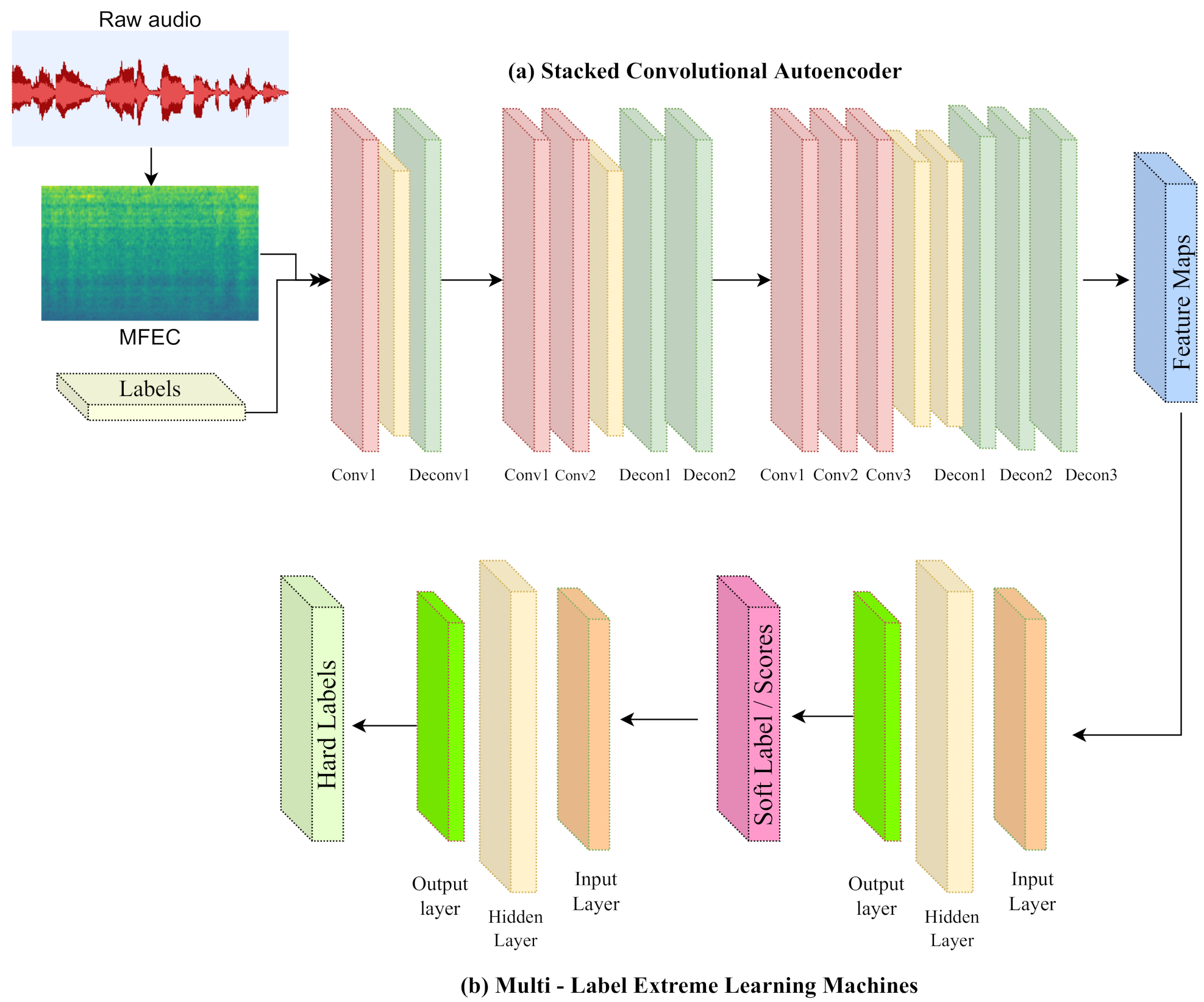
The proposed method uses convolutional autoencoders stacked with MLELMs to locate the important information from MFECs and recognize it efficiently from synthesized audio and dialect from Bangla speech. The model also outperforms accuracy scores for dialect, age, and gender achieved by previous researchers. Furthermore, the model addresses the issue of a limited Bangla speech dataset. From the seven dialects of the division above, we create a database containing extensive jargon and phoneme patterns. Over 100,000 Bangla spoken utterances were recorded within the institution. There is no ambiguity in the Bangla statement made by the speakers. The input signals are labeled according to the class to which they belong. Afterward, we discuss the proposed approach for recognizing the speaker’s regional language and audio authenticity (machine or actual voice), as well as extensive testing to confirm the recommended system’s performance on current models and publicly available datasets, as well as future work.
The rest of this paper is organized as follows. In
Section 2, we describe the detailed construction of the dataset build and used in this research paper, the architecture of the proposed model and the various experimentation conducted on the dataset, before achieving the accuracy results shown in the following section.
Section 3, contains the results obtained for classifying the regional language, synthesized speech, age and gender. Additionally, the results obtained during the comparison with existing models and dataset. Last but not the least the conclusion.
3. Results and Discussion
Python is used to implement all networks on three different GPUs; GeForce RTX 3090, Radeon RX 590, and NVidia GeForce RTX 3070. VoxCeleb [
34] dataset is used to synthesize English speech for the proposed model. In the VoxCeleb dataset, there are approximately 2000 h of 100,000 phrases taken from YouTube videos narrated by 1,251 celebrities with American, European, and Asian dialects. We compare the proposed model SCAE-MLELMs to two existing models, dense autoencoder (DAE) and convolutional autoencoder (CAE), and used Area Under the Curve (AUC) and partial Area Under the Curve (pAUC) metrics. The AUC provides an aggregate measure of performance across all possible classification thresholds. While pAUC would consider the areas of Receiver Operating Characteristic (ROC) space where data is observed or is a clinically relevant value of test sensitivity or specificity.
The confusion matrix displays the true positive (TP) value, which indicates the number of positively predicted samples that match the true positive labels, and the false negative (FN) value, which indicates the number of positively predicted samples that do not match the positive ground truth labels. TN samples are those that were accurately predicted as negative and had positive values, whereas FP samples are those that were predicted as negative but had positive labels. The accuracy score is determined by the number of positively predicted labels for test data. The rows in the confusion matrices represent genuine labels, while the columns represent anticipated labels. Only the diagonal cells will be the darkest in a perfect confusion matrix, while the rest will be white. The confusion matrix can also be used to determine which classes are most and least mislabeled. It can help identify certain issues in the dataset. We can see this from the confusion matrix below. As the number of recorded and synthesized audio samples for each region is not equal. As a result of the imbalanced distribution of classes in the dataset, there is a slight failure in classification accuracy in each cell of the confusion matrix. As can be seen from the confusion matrix below, the column and row do not add up to 100%.
Moreover, recall (R), precision (P), and F1-score (FS) measurements were used to evaluate the effectiveness of the model, since accuracy alone cannot measure the effectiveness and performance of a model. The following sections provide discussion, confusion matrix and tables with values of the matrix obtained from the models for each specific type of class and its categories, as well as correlation of age with dialect class classification. As previously, researchers used MFCC input format to test their models. In order to compare available datasets and existing algorithms, we use both MFCC and MFEC input data. The model is trained and tested using Bangla and English speech datasets.
3.1. Type of Audio
For the Bangla speech datasets, audio classification is a two-class category problem; original or synthetic. By using the proposed method, actual Bangla voices can be distinguished from generated voices at a high rate. The highest values for precision, recall, and F1-score are obtained for Bangla speech at 91%, 94%, and 93% respectively, with a mean accuracy of 93%. For the English speech dataset, the model produced precision, recall, F1-score, and mean accuracy of 94%, 97%, 94%, 96%, respectively, as shown in
Table 3.
Figure 5 shows the confusion matrix obtained from the model prediction for both Bangla and English speech. For Bangla speech, the best category-wise accuracy is 94% for original voices and 97% for synthesized voices.
3.2. Dialect
Bangla dialects are classified into seven categories: Khulna, Bogra, Rangpur, Sylhet, Chittagong, Noakhali, and Mymensingh. According to
Table 4, the highest values obtained for Bangla speech were 78% precision, 78% recall, and 72% F1-score. For Bangla speech, the mean recognition accuracy is 75%. English is a three-category classification problem; Asian (Bangladesh, India, Pakistan, China, Korean), American and European (United Kingdom, Germany, Russia) and the precision, recall, F1-score and mean accuracy were 81%, 88%, 85%, and 81%, respectively.
The larger the variation in dialect type, the better the recognition rate. Because all of the regional languages are spoken in Bangla in the Bangla speech dataset, it can be difficult to distinguish the input audio at a high rate. The situation is different with English, where the dialects are quite diverse, making the process of recognition relatively straightforward.
Figure 6 provides the confusion matrix obtained from the model prediction for dialect classification. M, N, C, S, R, B, and K stand for Mymensingh, Noakhali, Sylhet, Rangpur, Bogra, and Khulna, respectively. In English, European, American, and Asian are denoted with the following keywords: EU, AM, AS, respectively. In terms of accuracy, Noakhali (78%) is the best followed by Bogra (66%). As a result, the proposed model confused Bogra with Rangpur and Sylhet with Chittagong, 23% and 32%, respectively, incorrectly predicted. There is a significant amount of confusion due to the similarity of the acoustic features, frequency, and intensity between the words used in those regional parts [
9]. There are also similarities between American and European dialects when it comes to English speech dialect prediction since they have a few similar words.
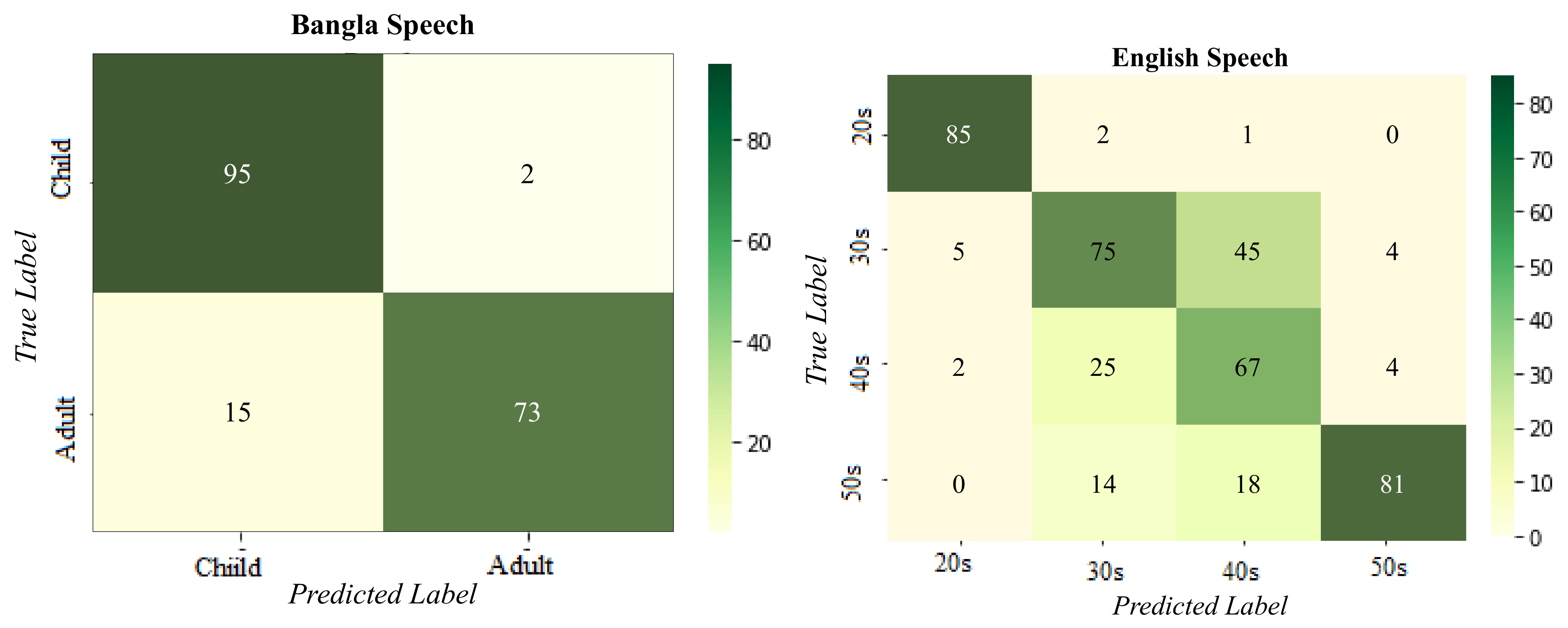
3.3. Dialect and Age Correlations Classification
Findings indicate that the recognition rate for a speaker’s dialect increases with age. Children have a smoother acoustic characteristic compared to adults, who have a high pitch-shift. Hanjun, Nichole, and Charles [
18] state that aging has physiological changes that affect how auditory feedback is processed in the brain. Therefore, considering the age feature maps when predicting the dialect of a speaker yields a higher accuracy rate than predicting classes alone. As a result, low false predictions were observed for dialects between Sylhet-Chittagong and Bogra-Rangpur regional languages, as well as American and European speakers. Also, the confusion between close age groups 30s and 40s is reduced when two class labels are considered.
The age and dialect classification for Bangla speech is a fourteen class classification problem; Khulna-Bogra-Rangpur-Sylhet-Chittagong-Noakhali-Mymensingh. There are 12 categories in the English Speech dataset; 20s-30s-40s-50s; Asian-American-European. For Bangla speech, precision, recall, and F1-score are highest at 86%, 78%, 75%, while for English speech they are 83%, 87%, 86% respectively, as shown in
Table 5. For Bangla and English speech, the average accuracy is 81 and 87 percent, respectively.
Figure 7 shows the confusion matrix obtained from the model prediction for dialect classification. In Bangla speech; CK, CB, CR, CS, CC, CN, CM, AK, AB, AR, AS, AC, AN, AM stands for Child-Khulna, Child-Bogra, Child-Rangpur, Child-Sylhet, Child-Chittagong, Child-Noakhali, Child-Mymensingh, Adult-Khulna, Adult-Bogra, Adult-Rangpur, Adult-Sylhet, Adult-Chittagong, Adult-Noakhali, Adult-Mymensingh, respectively. 2AS, 2AM, 2EU, 3AS, 3AM, 3EU, 4AS, 4AM, 4EU, 5AS, 5AM, 5EU stand for 20s-Asian, 20s-American, 20s-European, 30s-Asian, 30s-American, 30s-European, 40s-Asian, 40s-American, 40s-European, 50s-Asian, 50s-American, 50s-European, respectively.
3.4. Age
The age classification problem for English Speech datasets consists of four classes; 20s, 30s, 40s, and 50s. The age difference between the classes is 10 years. For each age group, Bangla Speech has a different age range. Children’s ages range from 12 to 20, while adults’ ages range from 30 to 50. The highest values obtained for precision, recall and F1-score for English speech are 88%, 85%, 86% respectively, while for Bangla speech 89%,95%, 92% respectively, as observed in
Table 6. The greater the difference in age range, the greater the recognition rate. The mean accuracy for recognition is 82% and 91% for English and Bangla speech respectively.
The confusion matrix obtained from the model prediction for age classification problem is present in
Figure 8 for both English and Bangla speech. The best category-wise accuracy for English speech is achieved by twenties (85%) followed by fifties (81%). However, the accuracy rates for thirties and forties 75% and 67%, respectively. The proposed model confuses the prediction for thirties age group with forties, 45% were falsely predicted. One of the main reasons for this confusion is that the acoustic pitch features are similar between the ages [
6,
18]. According to the MFEC data log-energies of the audio signals, the frequency features for the two age groups are very similar. Due to its increased difference in age range among categories, this similarity cannot be observed in Bangla speech age prediction.
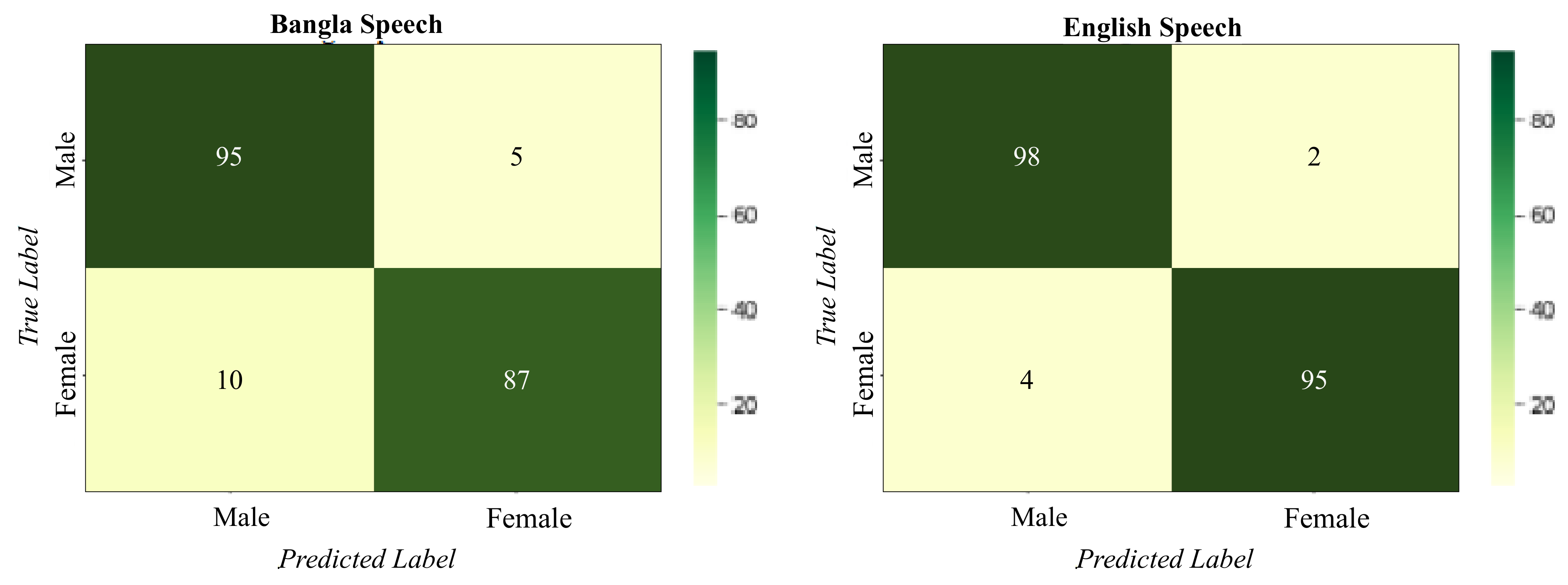
3.5. Gender
There are two gender categories for the Bangla and English speech datasets; male and female. The highest values obtained for precision, recall and F1-score for for Bangla speech 85%,94%, 93%, while for English speech are 96%, 98%, 96% respectively, as observed in
Table 7. The mean accuracy for recognition is 92% and 96% for Bangla and English speech respectively. Confusion matrix obtained from the model prediction for age classification problem is present in
Figure 9 for both speeches. The best category-wise accuracy for both speeches is achieved by male category, 87% Bangla and 98% English speech. In comparison to the English speech dataset, the proposed model has more false predictions for Bangla speech.
3.6. Comparison Among Datasets
The number of Convolutional Autoencoders in the SCAE-MLELMs model is varied to evaluate the accuracy of the prediction of the class label for the test data as well as the impact the input data format has on the suggested system. MFCCs and MFECs are selected as input data types. They are the most commonly used data formats in audio recognition studies. The dataset mentioned earlier is used to analyze Bangla’s speech. While for English Speech, freely available datasets from Google AudioSet and VoxCeleb is utilized [
34].
Table 8 shows the categorization accuracy in the specifics of the experiment with MFCCs as data input format and
Table 9 for MFECs data format.
Model 1 employs only one CAE network with MLELMs to evaluate the efficiency of the suggested methods; Model 2 employs three CAE networks with MLELMs. In models 2, 3, and 4, three, four, and six CAE networks are followed by MLELM networks; a comprehensive architectural description can be found in this paper’s proposed model section. For all datasets in the MFCCs data format, Model 4 gives the highest classification accuracy for all class labels for both types of speeches. It requires more convolutional autoencoders to detect the prominent aspects of an audio stream in an MFCCs spectrogram. The MFECs data has the highest classification accuracy when using Model 2, since its log-mel-energy properties are easier to discern. As the number of CAE networks for MFECs input data format increases, the model tends to overfit as well. The accuracy of Model 3 and Model 4 is superior to Model 2. Across all datasets of Bangla and English speech, dialect and type of audio have the greatest accuracy in prediction.
3.7. Comparison between Existing Algorithms
For each classification category, it is compared with the models developed by Sharmin et al. [
35], a Deep CNN model, and Tursunov [
29], a multi-attention module CNN model. We compare the performance and robustness of the techniques using AUC and pAUC measurements.
Table 10 shows the AUC and pAUC values for each class category with spectrogram input data format, while
Table 11 shows the MFEC data format for both Bangla and English audios. The average AUC and pAUC matrices for each class category for both data formats demonstrate that SCAE-MLELMs model outperforms the current model for both speeches.
In addition, MFECs data formats had greater AUC and pAUC values than MFCCs data formats for all model types. Compared to other classes, the Deep CNN model [
36] has the lowest AUC and pAUC performance values for dialect class labels. For dialect class labels, the Deep CNN model [
36] has the lowest AUC and pAUC values compared to other classes. In comparison to the approach in [
36], the Multi-attention module CNN model [
29] produced some of the best results for a few classification labels; age, gender, and audio type. Existing approaches have difficulty distinguishing dialect in speech regardless of language due to their single-label model structure and inability to learn characteristics that include age and dialect in audio frequency patterns. Employing multi-label extreme learning machine networks, as suggested in the model. Moreover, the existing methods do not perform as well with Bangla speech audio input as they do with English speech audio input. The proposed method performs consistently in both languages.
4. Conclusions
In this paper, a dataset was presented with seven regional Bangla languages. In addition, a Stacked Convolution Autoencoder followed by MFECs for the classification of synthesized voices and regional Bangla languages was proposed. The propopsed method can extract essential features from unsupervised data and classify them accordingly. From the given input data, the SCAE identifies relevant features for class labeling and produces detailed feature maps. The MLELM networks in the suggested method learn from the training data to produce multi-label classification in a single pass. We used two MLELM networks because the first performs soft classification scores and soft labels. The second MLELM network matches the soft label to hard labels. We conducted extensive training and testing to evaluate the performance, efficiency, and robustness of the system. The suggested method outperforms the existing algorithms (Sharmin et al. [
35], a Deep CNN model, and Tursunov [
29], a multi-attention module CNN model) with an accuracy score of 91%, 89%, 89%, 92% for synthesized/original audio type, dialect, age, and gender classification, respectively for Bangla Speech, for the spectrogram input data type. While for MFECs input format the accuracy scores are synthesized/original audio type, 92%, dialect, 92%, age 90%, gender 91%. Consequently, MFEC’s data input format is more reliable when it comes to recognizing relevant salient features from audio inputs. In addition, the proposed model can improve the classification accuracy score for dialect class to 95% by using detailed feature maps produced from the SCAE, which produces the correlated acoustic feature patterns between dialect class and age. As aging has a physiological change that impacts the processing of auditory feedback in the brain. Hence with the help of MLELM networks, the multi-label data was used to create correlated feature maps of the data. The model also achieves the highest accuracy score against the existing models for the English speech dataset. 93%, 94% 88% and 91% for synthesized/original audio type, dialect, age, gender classification, respectively, for MFECs. The proposed method can be applied to the concept of ASR, TTS and speech recognition and processing in the future, including customer care, health care devices, etc.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}