
SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture



Abstract
:1. Introduction
- a system model that improves resiliency specially suited for disaster/crisis scenarios,
- the model provides low-latency events processing,
- an utilization-based scheduling mechanism to balance load among processing nodes.
2. Background and Related Work
2.1. Stream Processing Systems
2.2. Edge Computing Architectures
2.3. Mobile Stream Processing
3. SLedge Model
3.1. Application Scenario
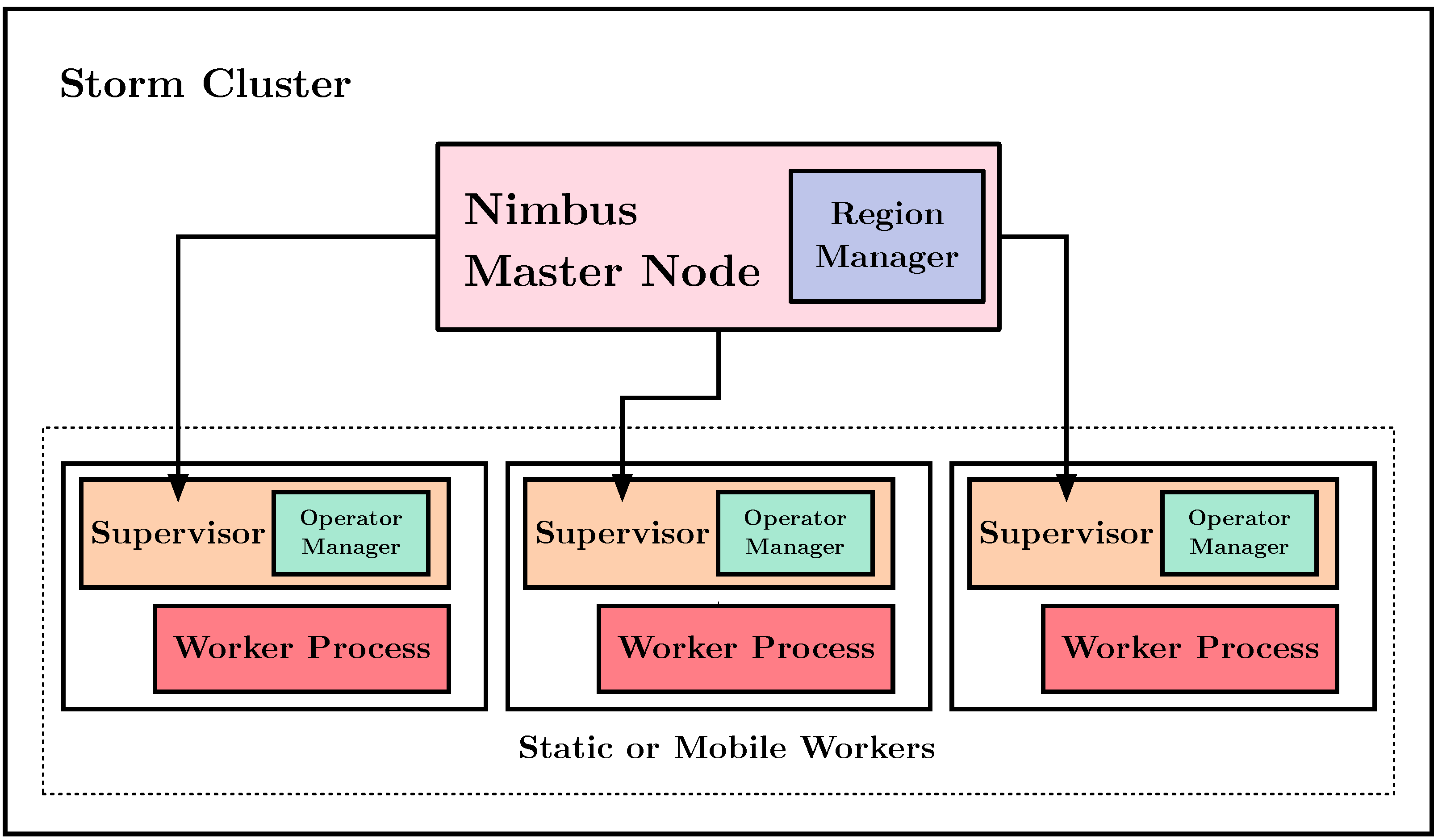
3.2. Architecture
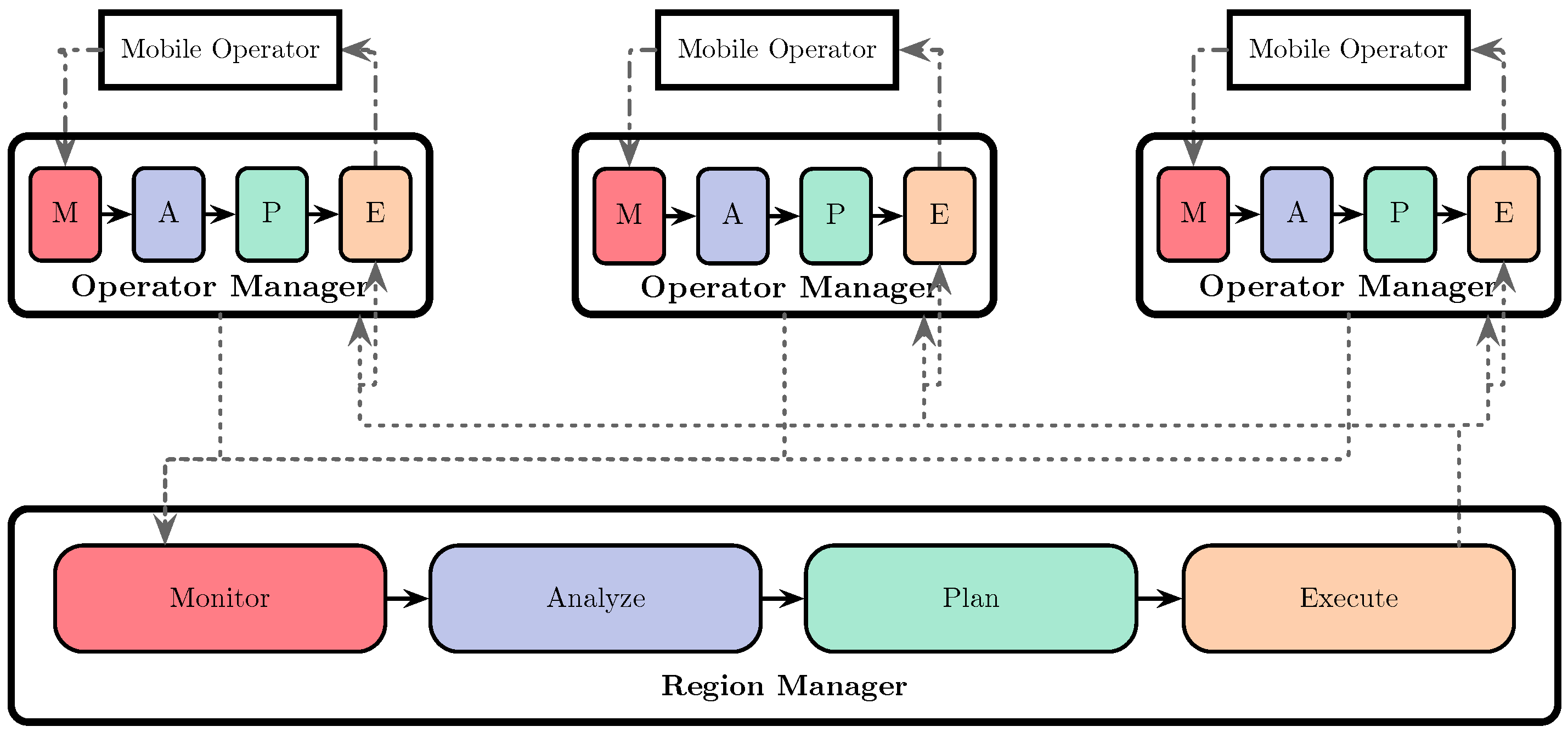
- Region Manager (RM): It is located in a static node and coordinates and monitors the region.
- Operator Manager (OM): It is located in the nodes that interact with the processing operator hosted by mobile devices. It is responsible for the communication with the RM and OMs of the nodes connected downstream and upstream in the processing graph. This component manages load balance among mobile devices.
- Monitor: The RM recollects the resource state of the mobile nodes using asynchronous communication. At each loop, the monitor phase considers the devices with updated information.
- Analyze: The RM uses the information of the monitor phase to create a list of mobile nodes categorizing their resources (i.e., energy and signal strength) into normal or low compared to a pre-defined threshold (Algorithm 1).
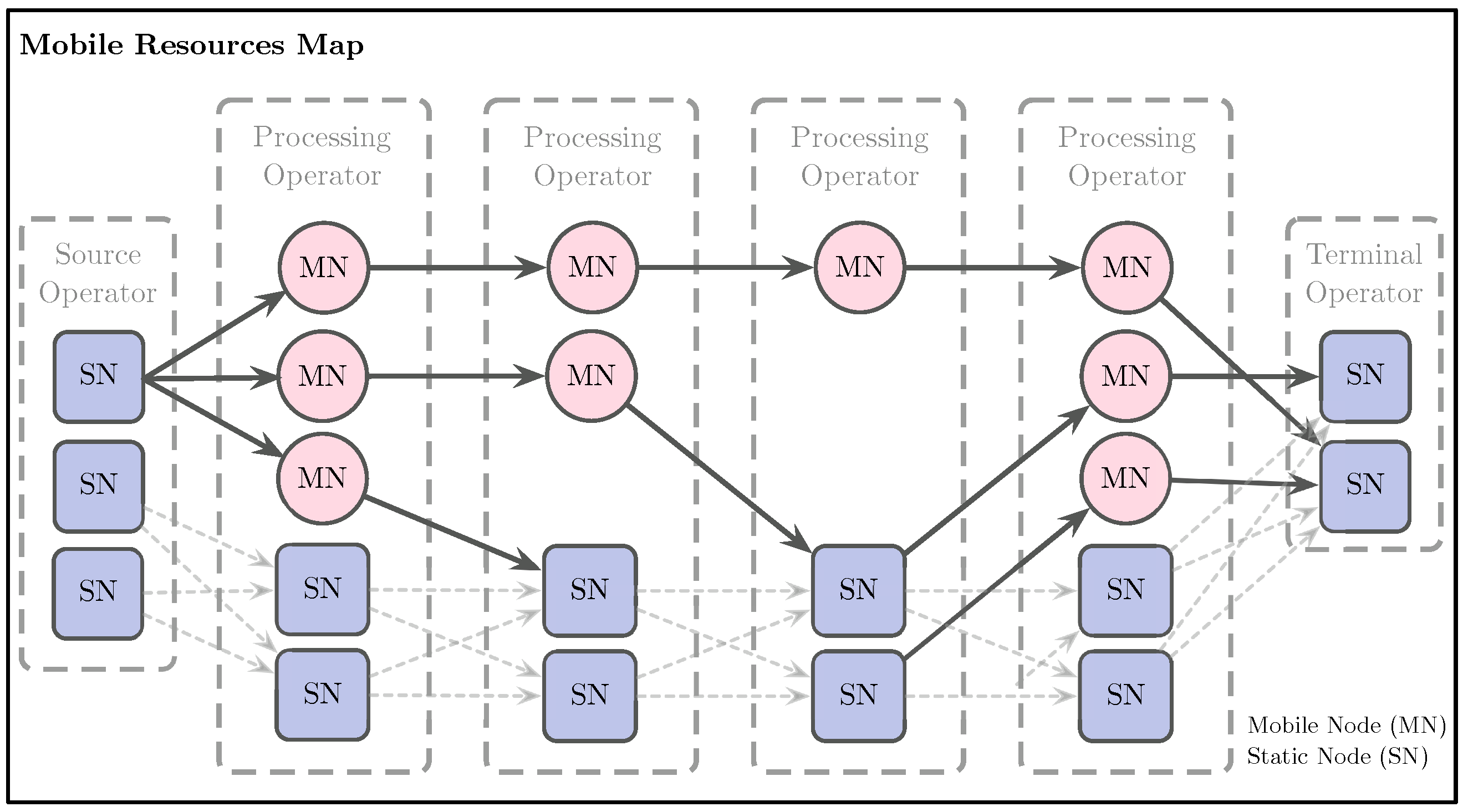
- Plan: The system activates and deactivates mobile nodes according to the categorization obtained in the Analyze phase. The system only uses mobile devices in a normal state. Deactivation prevents using devices with dangerous energy levels and low signal strength (outside the coverage cell). The activation of mobile nodes indicates that they can host processing operators. The system builds a mapping between the mobile nodes available and the processing operators of the graph topology. In our model, we consider that a processing operator may require replication many times. Mobile nodes are assigned with processing operators considering the task complexity and the mobile device’s resources. We categorize mobile devices as high-end, those devices with specs similar or higher than a Samsung S10 (see Table 1). On the other hand, low-end devices are those with lower specs than Samsung S10. Algorithm 2 describes this procedure. Figure 3 shows how the RM maintains the node’s state and the assigned operators using a virtual map and other operators’ downstream connections.
- Execute: The system sends the order to the corresponding OMs to remove operators from their mobile nodes or create new operators using the deactivation and activation lists. Moreover, the RM sends the system’s information to the OMs to make them aware of the downstream operators’ location.
| Algorithm 1 Critical resources’ state categorization |
| Require: |
| Ensure: |
|
| Algorithm 2 Operator selection |
| Require: |
| Ensure: |
|
3.3. Event Flow and Load Balancing
- Monitor: The OM measures CPU utilization considering the processor state, the I/O operations, and the memory usage.
- Analysis: The OM decides if a mobile operator is overloaded, healthy, or underloaded using two CPU utilization thresholds (high and low). This mechanism avoids consuming all the mobile node resources with the load assigned by the RM and assigns a sufficient amount of load to under-utilized nodes.
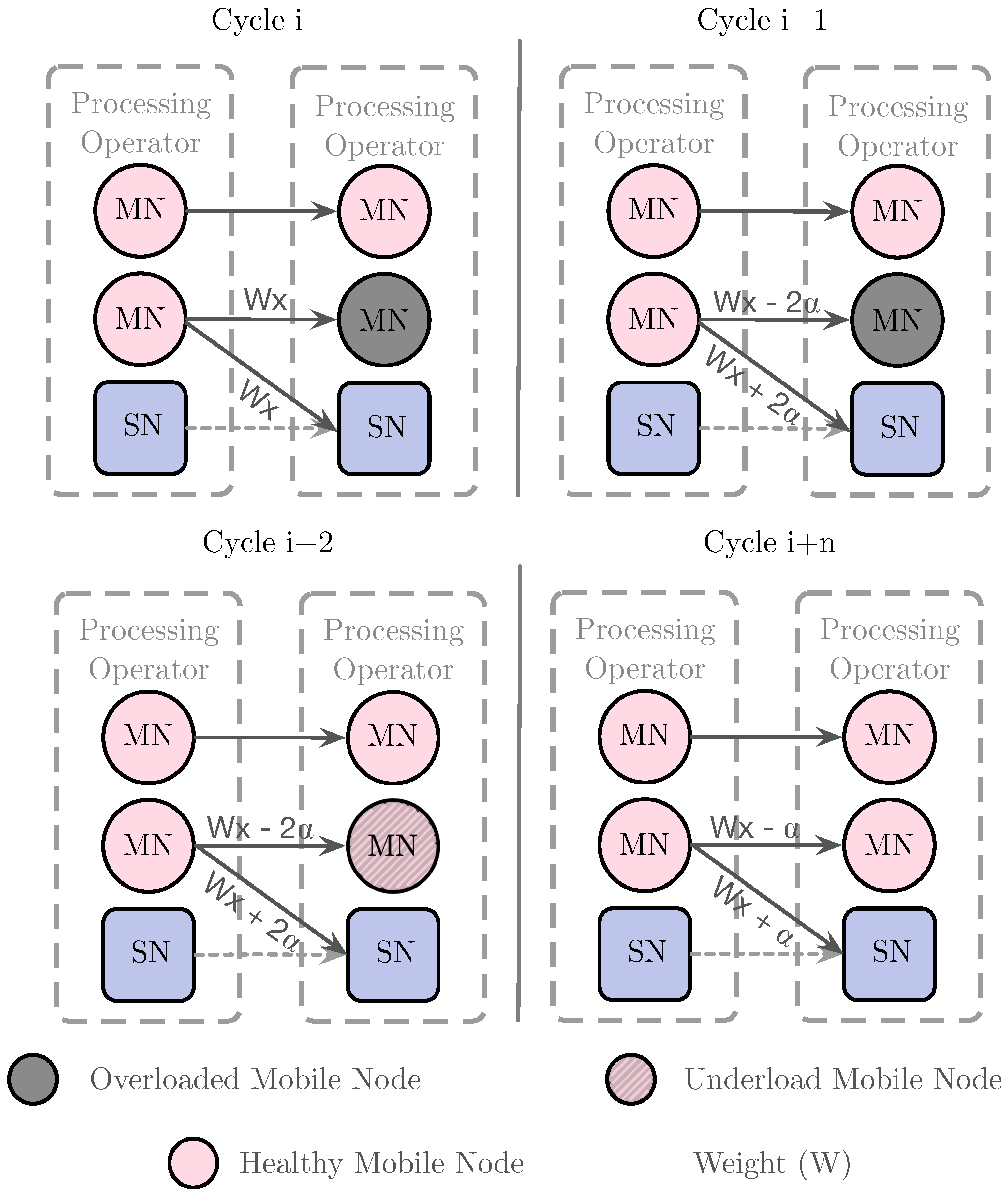
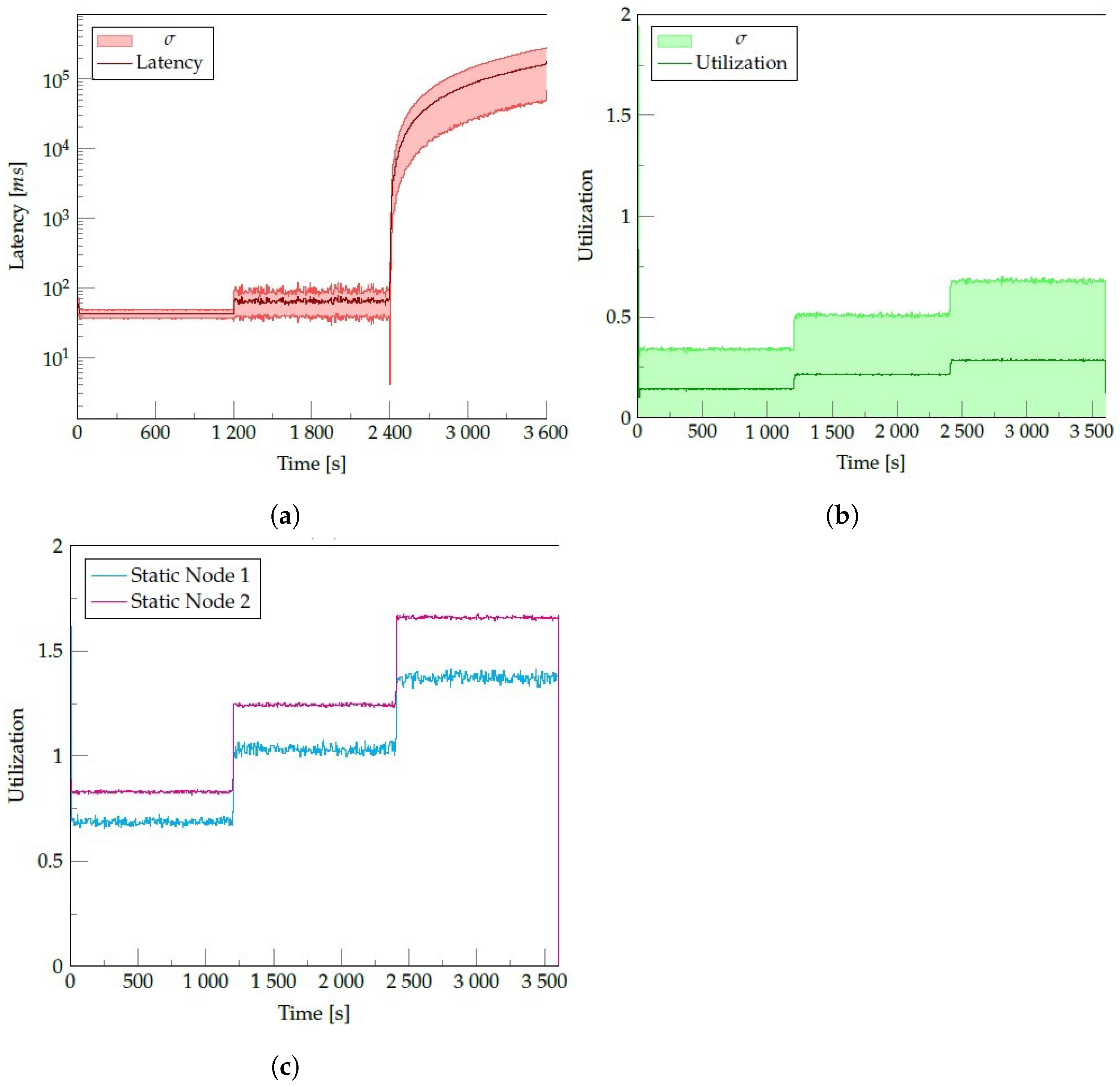
- Planning: If the mobile node is overloaded, the OM changes the upstream node’s scheduling algorithm to decrease the number of events received. The system offloads the remaining events to a static node that deploys a processing operator’s replica. We use the weighted round-robin load algorithm that adapts the weights (representing the load of events) at each MAPE loop cycle. The algorithm decreases the number of events sent to an overloaded node while increasing the static replica’s events. The scheduling process starts with equal weights and changes them in each loop until the device is no longer overloaded.In case a mobile node is underloaded, the system increases the weight of the underloaded node in the upstream node connection, so the number of events received by the node also increases. Figure 4 shows this process: In the ith cycle, a mobile node is overloaded, so the system divides the flow of events between the node and a static node, giving both of them a weight of ; in the th cycle, the mobile node still is overloaded, so the system increases in the weight of the static node decreasing the flow that is sent to the mobile node; in the th cycle, the mobile node is underloaded, then the system increases the weight of the mobile node by ; in the th cycle, the mobile node is in a healthy state.
- Execution: The OM performs the actions defined in the previous phase.
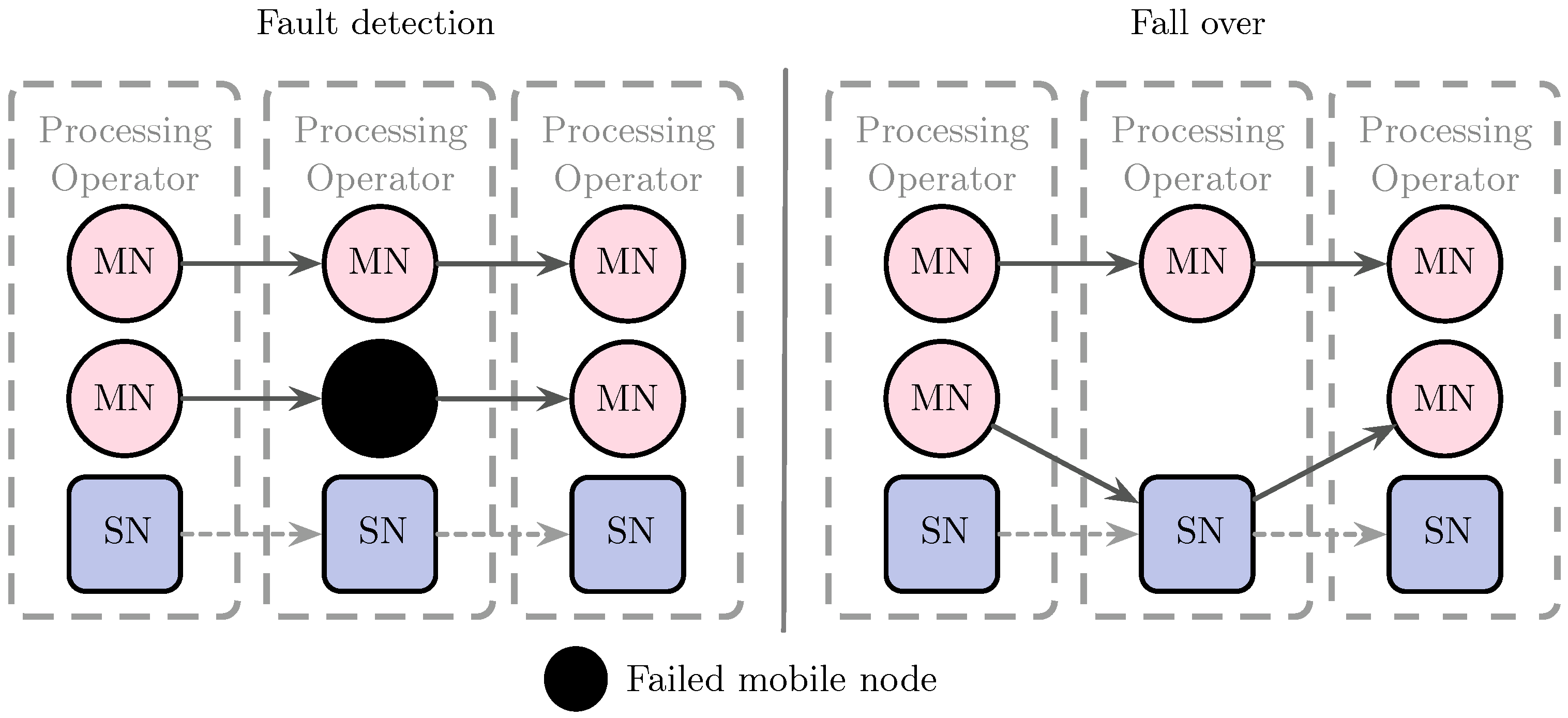
3.4. Fault Tolerance
4. Experimental Evaluation
4.1. Experimental Design
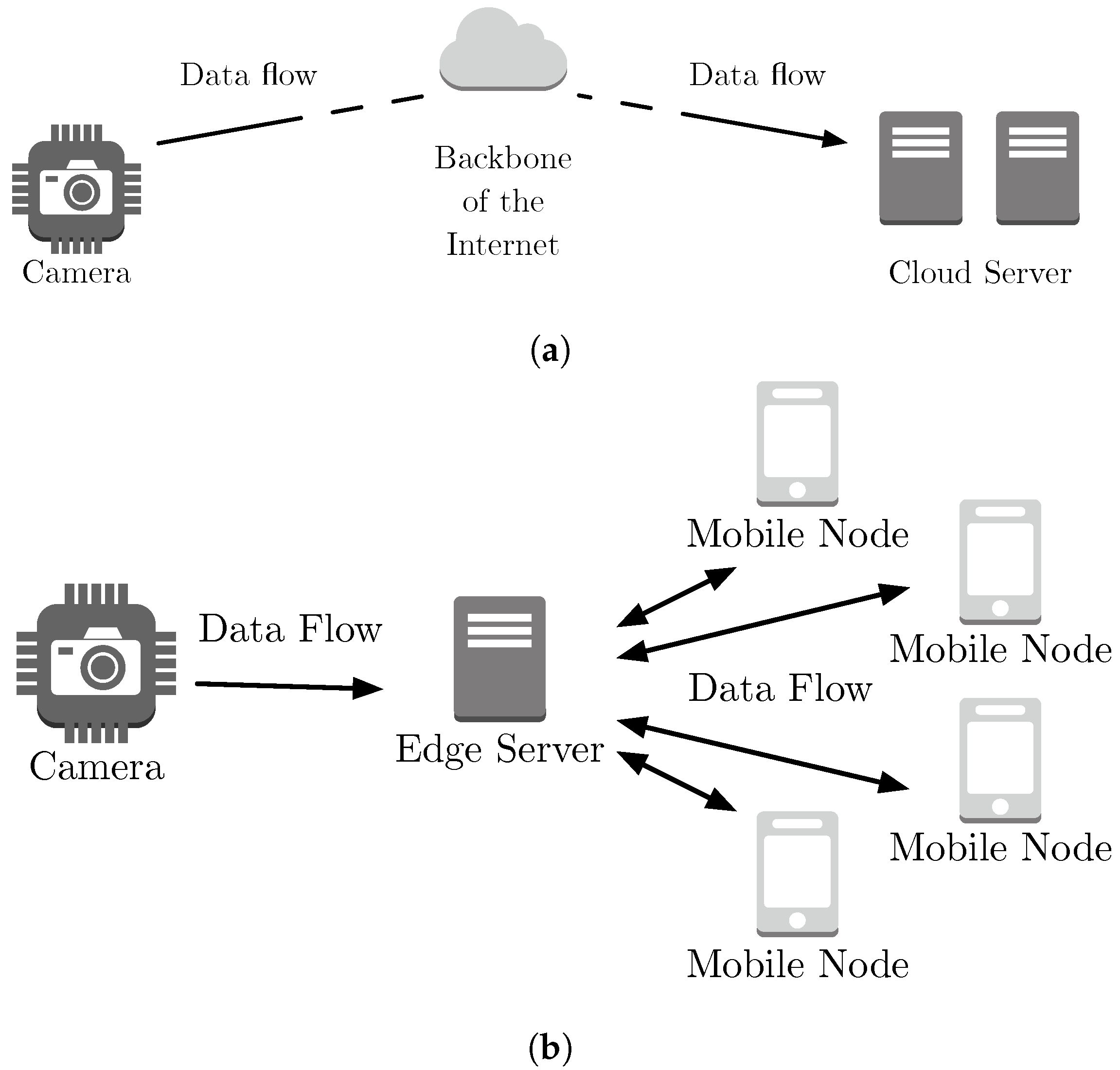
- Compare a stream processing system executing in a cloud architecture versus SLedge, an edge architecture with integrated mobile devices. We aim at measuring the resources required at the edge to achieve an equal or greater performance than the cloud architecture and identify the trade-offs involved. Figure 6 shows both considered architectures. We represent the cloud architecture with a server at the Internet core that dedicates resources to execute more workers than one edge server or one mobile device can dedicate.
- Evaluate the SLedge performance under different settings, such as the overload of mobile devices, increasing or decreasing the flow of events into the system, adding or removing devices to the pool of available resources, and failure of mobile nodes that are working as part of SLedge.
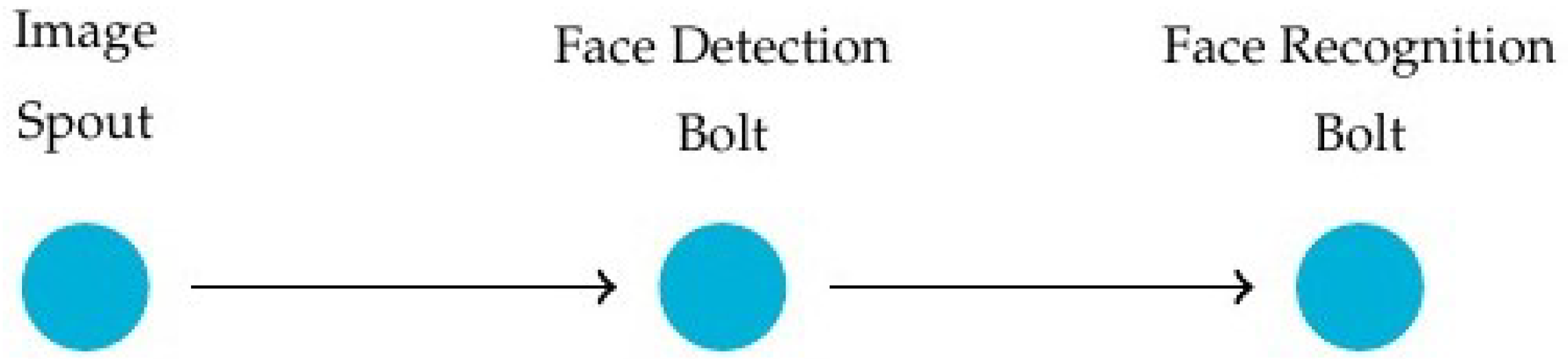
4.2. Benchmarks and Parameterization
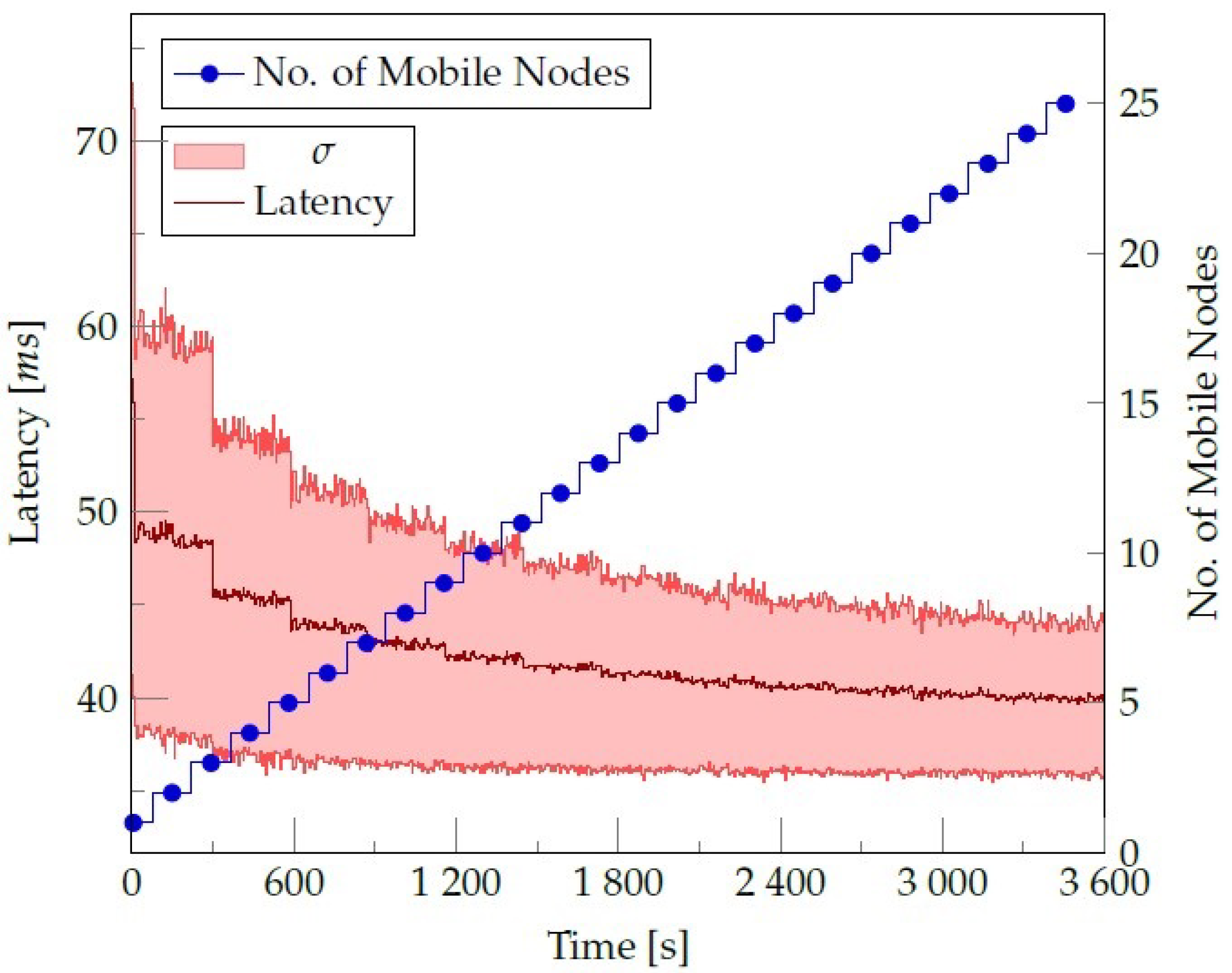
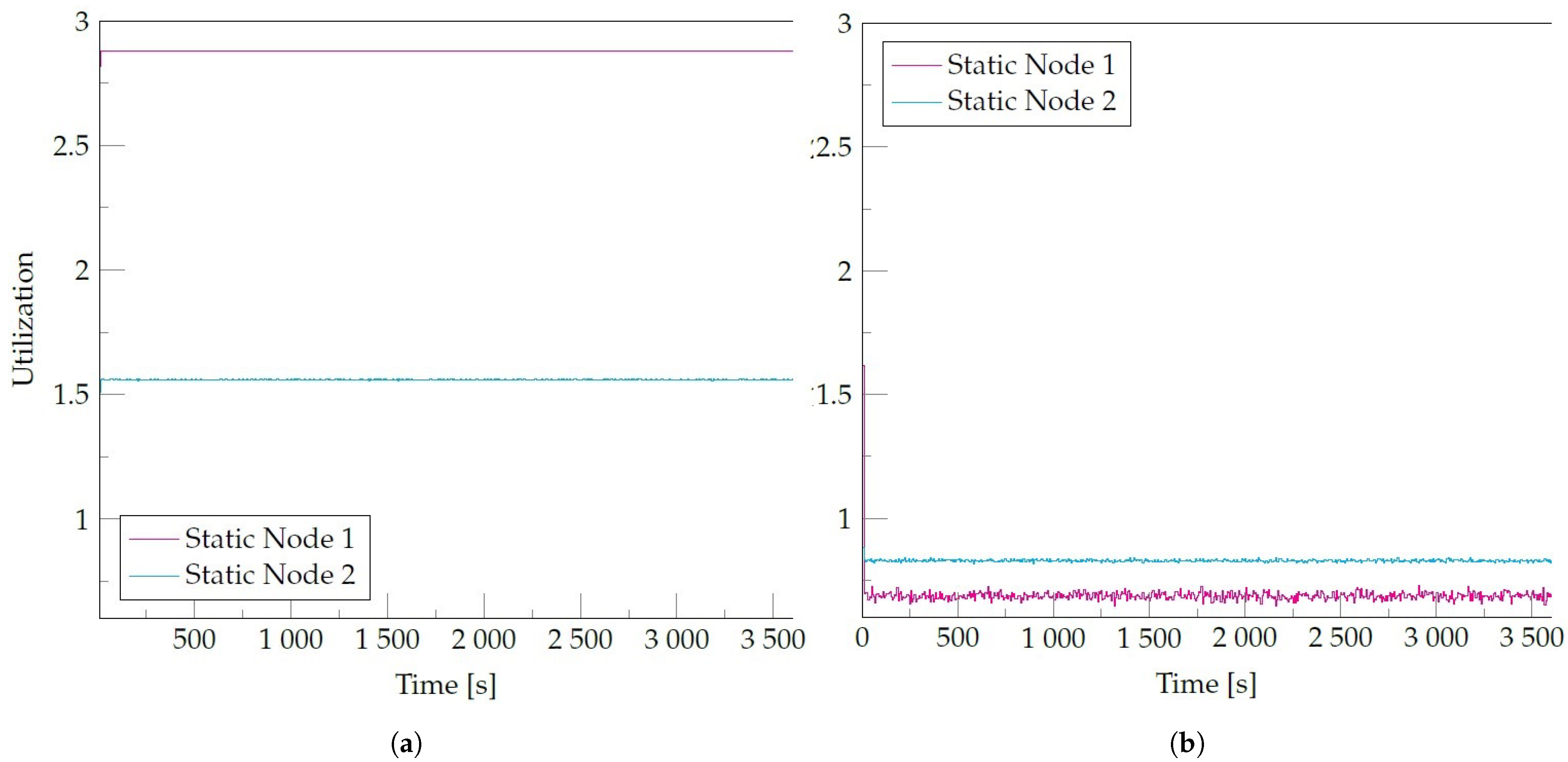
4.3. Experiments and Results
- The number of events per second emitted by the camera is 60, corresponding to the number of frames per second.
- Nodes are static during the participation in the SLedge system so no mobility model is required.
- CPU utilization thresholds are 0.4 and 0.9 for low and high thresholds, respectively.
- is 15%. We employ the basic energy model provided by NS3. This model determines the energy spent in the transmission of a message (tx), in the reception of a message (rx), and a harvester (hv), that drains energy periodically from the device. We configured the values based on the benchmark results (Energy model parametrization values: rx = 3.373, tx = 3.373, hv = −0.179). We assigned an initial battery power randomly between 15% and 100% of the maximum device capacity (3400 mAh).
- RM’s MAPE cycle is 5 s.
- OM’s MAPE cycle is 6 s.
- CHECKPOINT: a checkpoint is performed.
- OVERLOAD: a node becomes overloaded.
- DELETE: to discard an active connection.
- UPDATE: to update the node.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Aitsi-Selmi, A.; Egawa, S.; Sasaki, H.; Wannous, C.; Murray, V. The Sendai Framework for Disaster Risk Reduction: Renewing the Global Commitment to People’s Resilience, Health, and Well-being. Int. J. Disaster Risk Sci. 2015, 6, 164–176. [Google Scholar] [CrossRef] [Green Version]
- Storm Concepts. 2020. Available online: https://storm.incubator.apache.org/documentation/Concepts.html (accessed on 12 March 2022).
- Association, G. The Mobile Economy 2020, Tech Report. 2020. Available online: https://www.gsma.com/mobileeconomy/ (accessed on 12 March 2022).
- Comito, C.; Falcone, D.; Talia, D.; Trunfio, P. Energy-aware task allocation for small devices in wireless networks. Concurr. Comput. 2017, 29, e3831. [Google Scholar] [CrossRef]
- Ning, Q.; Chen, C.; Stoleru, R.; Chen, C. Mobile storm: Distributed real-time stream processing for mobile clouds. In Proceedings of the 2015 IEEE 4th International Conference on Cloud Networking (CloudNet), Niagara Falls, ON, Canada, 5–7 October 2015; pp. 139–145. [Google Scholar]
- Wang, H.; Peh, L.S. MobiStreams: A Reliable Distributed Stream Processing System for Mobile Devices. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 51–60. [Google Scholar]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter under crisis: Can we trust what we RT? In Proceedings of the first workshop on social media analytics, Washington, DC, USA, 25 July 2010; pp. 71–79. [Google Scholar]
- Domdouzis, K.; Akhgar, B.; Andrews, S.; Gibson, H.; Hirsch, L. A social media and crowdsourcing data mining system for crime prevention during and post-crisis situations. J. Syst. Inf. Technol. 2016, 18, 364–382. [Google Scholar] [CrossRef]
- Park, Y.E. Developing a COVID-19 crisis management strategy using news media and social media in big data analytics. Soc. Sci. Comput. Rev. 2021, 21, 08944393211007314. [Google Scholar] [CrossRef]
- Al-Omoush, K.S.; Zardini, A.; Al-Qirem, R.M.; Ribeiro-Navarrete, S. Big crisis data, contradictions and perceived value of social media crowdsourcing in pandemics. Econ. Res. Ekon. Istraž. 2021, 34, 450–468. [Google Scholar] [CrossRef]
- Castillo, C. Big Crisis Data: Social Media in Disasters and Time-Critical Situations; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Hunt, P.; Konar, M.; Junqueira, F.P.; Reed, B. ZooKeeper: Wait-Free Coordination for Internet-Scale Systems. In USENIX ATC; USENIX Association: Berkeley, CA, USA, 2010; pp. 1–11. [Google Scholar]
- Rychlý, M.; Skoda, P.; Smrz, P. Heterogeneity-aware scheduler for stream processing frameworks. Int. J. Big Data Intell. 2015, 2, 70–80. [Google Scholar] [CrossRef]
- Cardellini, V.; Grassi, V.; Presti, F.L.; Nardelli, M. On QoS-aware scheduling of data stream applications over fog computing infrastructures. In Proceedings of the 2015 IEEE Symposium on Computers and Communication (ISCC), Larnaca, Cyprus, 6–9 July 2015; pp. 271–276. [Google Scholar]
- Talebkhah, M.; Sali, A.; Marjani, M.; Gordan, M.; Hashim, S.J.; Rokhani, F.Z. Edge computing: Architecture, Applications and Future Perspectives. In Proceedings of the 2020 IEEE 2nd International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 26–27 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hamdan, S.; Ayyash, M.; Almajali, S. Edge-Computing Architectures for Internet of Things Applications: A Survey. Sensors 2020, 20, 6441. [Google Scholar] [CrossRef] [PubMed]
- Bonomi, F.; Milito, R.A.; Natarajan, P.; Zhu, J. Fog Computing: A Platform for Internet of Things and Analytics. In Big Data and Internet of Things: A Roadmap for Smart Environments; Springer: Berlin/Heidelberg, Germany, 2014; Volume 546, pp. 169–186. [Google Scholar]
- Salem, A.; Salonidis, T.; Desai, N.; Nadeem, T. Kinaara: Distributed Discovery and Allocation of Mobile Edge Resources. In Proceedings of the 2017 IEEE 14th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Orlando, FL, USA, 22–25 October 2017; pp. 153–161. [Google Scholar] [CrossRef]
- Goldstein, O.; Shah, A.; Shiell, D.; Rad, M.A.; Pressly, W.; Sarrafzadeh, M. Edge Architecture for Dynamic Data Stream Analysis and Manipulation. In Edge Computing—EDGE 2020; Katangur, A., Lin, S.C., Wei, J., Yang, S., Zhang, L.J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 33–49. [Google Scholar]
- Chao, M.; Stoleru, R. R-MStorm: A Resilient Mobile Stream Processing System for Dynamic Edge Networks. In Proceedings of the 2020 IEEE International Conference on Fog Computing (ICFC), Sydney, Australia, 21–24 April 2020; pp. 64–72. [Google Scholar] [CrossRef]
- Marah, B.D.; Jing, Z.; Ma, T.; Alsabri, R.; Anaadumba, R.; Al-Dhelaan, A.; Al-Dhelaan, M. Smartphone Architecture for Edge-Centric IoT Analytics. Sensors 2020, 20, 892. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Busching, F.; Schildt, S.; Wolf, L. DroidCluster: Towards Smartphone Cluster Computing—The Streets Are Paved with Potential Computer Clusters. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops, Macau, China, 18–21 June 2012; pp. 114–117. [Google Scholar]
- Szpakowski, M. Native Port of the Boinc Client for Android Devices. 2013. Available online: http://nativeboinc.org/site/uncat/start (accessed on 12 March 2022).
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Yunsheng, M.; Chen, S.; Hou, P. A new deep learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Trans. Serv. Comput. 2017, 11, 249–261. [Google Scholar] [CrossRef]
- Morales, J.; Rosas, E.; Hidalgo, N. Symbiosis: Sharing mobile resources for stream processing. In Proceedings of the 2014 IEEE Symposium on Computers and Communications (ISCC), Madeira, Portugal, 23–26 June 2014; pp. 1–6. [Google Scholar]
- Hiessl, T.; Karagiannis, V.; Hochreiner, C.; Schulte, S.; Nardelli, M. Optimal placement of stream processing operators in the fog. In Proceedings of the 2019 IEEE 3rd International Conference on Fog and Edge Computing (ICFEC), Larnaca, Cyprus, 14–17 May 2019; pp. 1–10. [Google Scholar]
- Weyns, D.; Schmerl, B.; Grassi, V.; Malek, S.; Mirandola, R.; Prehofer, C.E.A. On Patterns for Decentralized Control in Self-Adaptive Systems. In Software Engineering for Self-Adaptive Systems II; Springer: Berlin/Heidelberg, Germany, 2013; pp. 76–107. [Google Scholar]
- Cardellini, V.; Grbac, T.G.; Nardelli, M.; Tanković, N.; Truong, H.L. QoS-Based elasticity for service chains in distributed edge cloud environments. In Autonomous Control for a Reliable Internet of Services; Springer: Cham, Switzerland, 2018; pp. 182–211. [Google Scholar]
- Cardellini, V.; Lo Presti, F.; Nardelli, M.; Russo Russo, G. Optimal operator deployment and replication for elastic distributed data stream processing. Concurr. Comput. Pract. Exp. 2018, 30, e4334. [Google Scholar] [CrossRef]
- Soo, S. Object detection using Haar-cascade Classifier. Inst. Comput. Sci. Univ. Tartu 2014, 2, 1–12. [Google Scholar]
- Zhao, X.; Wei, C. A real-time face recognition system based on the improved LBPH algorithm. In Proceedings of the 2017 IEEE 2nd International Conference on Signal and Image Processing (ICSIP), Singapore, 4–6 August 2017; pp. 72–76. [Google Scholar]
- Ahmadpour, S.; Wan, T.C.; Toghrayee, Z.; HematiGazafi, F. Statistical analysis of video frame size distribution originating from scalable video codec (SVC). Complexity 2017, 2017, 8098574. [Google Scholar] [CrossRef]
- Hidalgo, N.; Wladdimiro, D.; Rosas, E. Self-adaptive processing graph with operator fission for elastic stream processing. J. Stat. Softw. 2017, 127, 205–216. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cloud Server | Edge Server | Mobile Device | |
|---|---|---|---|
| Processor | 2× Intel Xeon Silver 4116 | AMD Ryzen 7 3700× | Exynos 9820 |
| Total Cores | 2 × 24 | 8 | 8 |
| Frequency | 48 × 2.1 GHz | 8 × 3.6 GHz | 2 × 2.73 GHz 2 × 2.31 GHz 4 × 1.95 GHz |
| RAM | 128 GB | 16 GB | 8 GB |
| Model | - | - | Samsung Galaxy S10 |
| Face Detection Bolt | Face Recognition Bolt | Number of Workers | |
|---|---|---|---|
| Cloud Server | 25.871 ms | 47.462 ms | 12 |
| Edge Server | 15.272 ms | 29.171 ms | 6 |
| Mobile Device | 10.220 ms | 23.365 ms | 1 |
| Face Detection Bolt | Face Recognition Bolt | |
|---|---|---|
| Cloud Server | 25.5–26.5 ms | 47.5–48.5 ms |
| Edge Server | 14.5–15.5 ms | 29.5–30.5 ms |
| Mobile Device | 9.5–10.5 ms | 22.5–23.5 ms |
| No of Message | ||
|---|---|---|
| CHECKPOINT | 3220.80 | 920.64 |
| OVERLOAD | 8359.50 | 828.25 |
| DELETE | 2016.00 | 531.87 |
| UPDATE | 8631.00 | 670.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hidalgo, N.; Rosas, E.; Saavedra, T.; Morales, J. SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture. Appl. Sci. 2022, 12, 6474. https://doi.org/10.3390/app12136474
Hidalgo N, Rosas E, Saavedra T, Morales J. SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture. Applied Sciences. 2022; 12(13):6474. https://doi.org/10.3390/app12136474
Chicago/Turabian StyleHidalgo, Nicolas, Erika Rosas, Teodoro Saavedra, and Jefferson Morales. 2022. "SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture" Applied Sciences 12, no. 13: 6474. https://doi.org/10.3390/app12136474
APA StyleHidalgo, N., Rosas, E., Saavedra, T., & Morales, J. (2022). SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture. Applied Sciences, 12(13), 6474. https://doi.org/10.3390/app12136474