
Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm



Abstract
:Featured Application
Abstract
1. Introduction
- To introduce a Real Coded Genetic Algorithm aimed at automatic text summarization for the Hindi language.
- To work with extensive and novel Hindi language features that generate more accurate text summarization than generic features.
- To compute better and faster convergence for text summarization using Simulating Binary Crossover and Polynomial Mutation in RCGA.
- To evaluate summarization results using Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics.
2. Related Work
2.1. Types of Extractive Methods
- Statistical methods: Statistical-based text summarization [18,19,20] relies on the statistical distribution of specified features without understanding of the whole document. For the selection of a sentence in a document summary, weight is assigned to the sentence as per its level of importance. Examples of statistical features are title words, sentence length, thematic topic, etc.
- Linguistic methods: Linguistic-based text summarization [19,21] relies on deep linguistic knowledge to analyze sentences and then decide which sentences to select. Sentences that contain proper nouns and pronouns have a greater chance to be included in the document summary. Examples of linguistic features are named entity features, sentence-to-sentence similarity features, etc.
- Hybrid methods: Hybrid-based text summarization [22] relies on optimizing the best of both the previous methods. It incorporates the combination of statistical and linguistic features for a meaningful and short summary.
2.2. Genetic Algorithm for Summarization
2.3. ATS for the Hindi Language
2.4. Tools for Text Summarization
- Newsblaster: Newsblaster [51] is a summarizing system which is developed at Columbia University. It generates news updates on a daily basis by scraping data from different news websites, filtering out news from non-news aspects such as advertisements, and combining them to generate a summary for each event. The evaluation measures for the Newsblaster multilingual summarization system [52] are computed for the English, Russian and Japanese languages (Table 2).
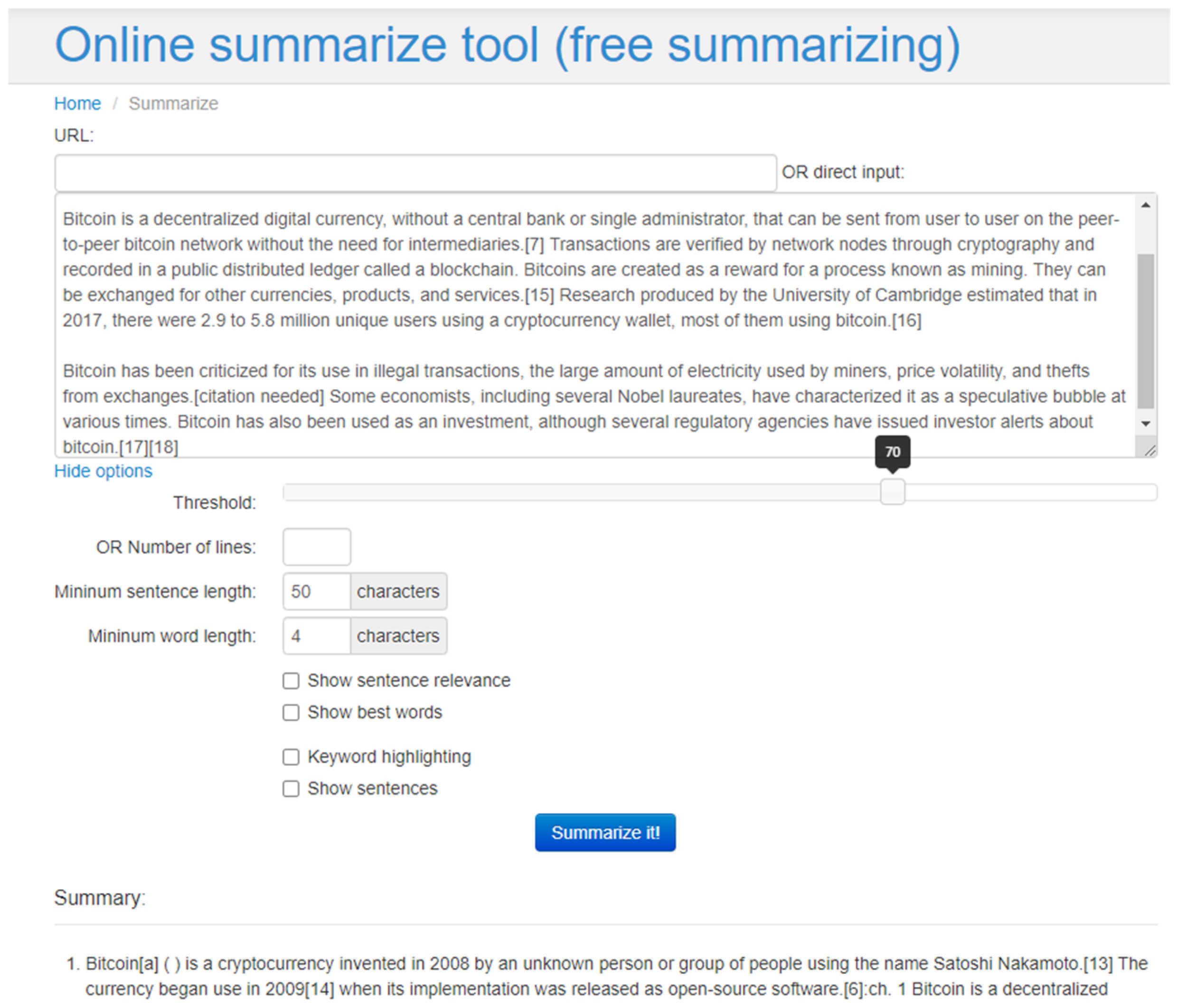
- Tool4Noobs: Tool4Noobs [53] is another tool to summarize text documents while setting different parameters (Figure 1). These parameters are threshold value or number of lines, minimum sentence length, minimum word length, number of keywords, etc. The evaluation measures for Tool4Noobs are computed as precision (61.4%), recall (63.2%), and F-Measure (62.2%), respectively.
- Free Summarizer: Free Summarizer [54] is a free service, an online tool developed to summarize mono-lingual texts quickly. This tool generates an extractive summary of generic types from a single text document and is widely used by various users worldwide.
- M-HITS: M-HITS [56] is a Hindi text summarizer that incorporates supervised learning algorithms such as Support Vector Machine (SVM), Random Forest (RF), AdaBoost, Gradient Boost, K-Nearest Neighbor (KNN), Logistic Regression (LR), Extremely Randomized Trees, along with graph-based similarity to extract main text chunks using various statistical features. These features are- cue words, bigrams, topic features, sentence position, proper nouns, unknown words, and TF-IDF. This tool enables ATS even without requiring a deep understanding of the text.
3. Proposed Methodology
3.1. Pre-Processing Phase
3.1.1. Sentence Segmentation
3.1.2. Word Tokenization
3.1.3. Stemming
3.1.4. POS Tagging
3.1.5. Stop-Words Removal
3.2. Feature Extraction Phase
3.2.1. Sentence Paragraph Position (Fsp)
- n: no. of sentences in paragraph;
- i: range from 0 to n;
- si: ith sentence within a paragraph.
3.2.2. Numerical Data within Sentence (Fnd)
- n_si: total no. of numeric values in si;
- w_si: total no. of words in si;
- nd_si: numeric data within the sentence.
3.2.3. Length of Sentence (Fls)
- w_si: total no. of words in si;
- lg_si: total no. of words in the longest sentence;
- ln_si: length of si.
3.2.4. Keywords within Sentence (Fkw)
- k_si: total no. of keywords in si;
- w_si: total no. of words in si;
- kw_si: keywords data within a sentence.
3.2.5. Sentence Similarity (Fss)
- sa, sb: ath, bth HHD sentences;
- sem_sim: semantic similarity using LSA;
- syn_sim: syntactic similarity using cosine function;
- sen_sim(sa,sb): similarity between the sentences-sa and sb;
- δ: parameter measuring contribution of semantic and syntactic information to overall sentence similarity, .
3.2.6. Named Entities within Sentence (Fne)
- ne_si: total no. of NEs in si;
- w_si: total no. of words in si;
- nw_si: NEs data within the sentence.
3.2.7. English Hindi Words within Sentence (Feh)
- teh_si: total English-Hindi words in a sentence;
- ln_si: length of si;
- deh_si: English-Hindi data within a sentence.
3.2.8. TF-ISF (Fti)
- : frequency of ith word in jth sentence;
- w_sj: number of words in sentence sj;
- tns: total number of sentences;
- ns_ti: number of sentences with ith word;
- Tfi: term frequency of ith word;
- Isfi: inverse sentence frequency of ith word.
3.3. Processing Phase
Genetic Algorithm
- String Representation: In this research, Chromosome size C (=8) represents the total number of features or length of a chromosome. Each chromosome is a combination of 8 computed feature values. For a specific sentence, each value is in the range of 0 to 1. Based on this fact, consider the chromosome value at i = 3 position is 0.37 is the length of sentence (Fls) feature value. So, each feature value for a specific sentence participates in the text summarization process. In a given population, all its chromosomes are initialized in the same manner.
- Fitness Function: In the genetic algorithm, the fitness function is a unit measure that determines a chromosome that leads to the best solution among a pool of chromosomes and, hence, has its chance to be chosen as the next generation chromosome. In this research, for each input, maximum value of each C is 1 and minimum is 0 where C represents a number of features, and each C is a real value. The topmost chromosome having the highest recall is selected, and the fitness function is defined using Equation (10).
- fj(s): jth feature of the sentence;
- C: total number of features;
- F: fitness function.
- Selection of Best Chromosome: The selection operator determines which individual chromosomes can survive and continue to the next generation. In this research, the top two chromosomes are chosen as parents for the new generation since they give the highest recall measure through the fitness function. For the selection of parents, the most frequently used selection method—the roulette wheel method [66] is chosen, which gives a chance to all the chromosomes without rejecting any of them. In this selection strategy, the whole population is partitioned through several individuals, where each sector of the roulette wheel represents an individual. The proportion of individual fitness to total fitness of the entire population decides—the area of the sector for the individual and the probability of the individual being selected for the next generation. So, at first, it calculates the sum of fitness values of all the chromosomes, i.e., cumulative fitness of the entire population, and then calculates the probability of each chromosome using Equation (11).
- fj(s): jth feature of the sentence;
- C: total number of features;
- P: the probability of a chromosome.
- Crossover: The binary-coded genetic crossover operations cannot be used in real coded GA. Deb and Agrawal [67] have developed a real coded crossover technique, i.e., Simulating Binary crossover (SBX). The considered crossover probability Pc = 0.8 and distribution index of crossover . The procedure of SBX crossover is as follows:
- -
- Randomly select a pair of parents Pa and Pb from the mating pool;
- -
- Generate a random number r between 0 and 1;
- -
- If r ≤ Pc, copy the parent as offspring;
- -
- If r ≥ Pc, generate a new random number u, for each feature;
- -
- Determine spread factor β of each variable using Equation (12):
- -
- Generate two offspring Oa and Ob using Equations (13) and (14):
- -
- Contracting crossover, i.e., β < 1, offspring are closer;
- -
- β = 1, offspring will be original parents;
- -
- Β > 1, offspring are far.
- Mutation: Deb and Agarwal [68] advised polynomial mutation which has been used for variation in population for the research work. The considered mutation probability Pm = 0.2 and distribution index of mutation . High crossover probability and low mutation probability is taken for better outcome. The step of polynomial mutation are as follows:
- -
- Generate a random number u between 0 and 1;
- -
- If , then no change in population;
- -
- If , new random number corresponding to each feature;
- -
- Determine δ of each variable using Equation (15):
- -
- Modify offspring using Equation (16):
Pa is the parent, ub and lb are the upper and lower bound values of each feature in the chromosome. In our case, lower bound lb is 0 and upper bound ub is 1, as all feature values lie in the range of 0 and 1.
3.4. Sentence Ranking Phase
3.5. Summary Generation Phase
4. Experimental Setup
4.1. Dataset
4.2. Evaluation Metrics
- RS: reference sentence;
- Ng: length of n-gram;
- Count(gramng): total number of n-grams in reference sentence;
- Countmatch(gramng): possible number of n-grams shared between system and reference sentence.
4.3. Results and Discussion
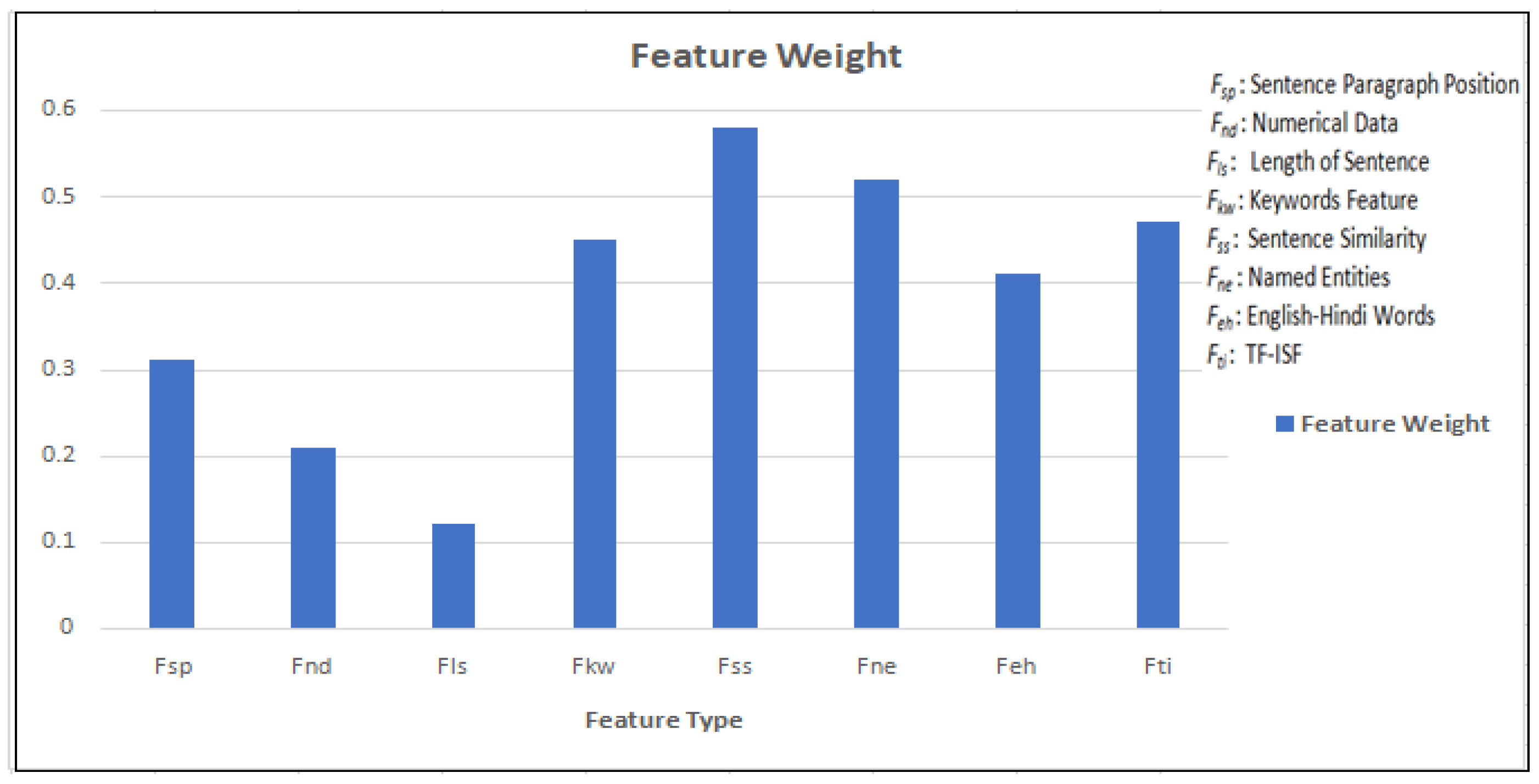
4.3.1. Feature Weights
4.3.2. Summary of Compression Rates
4.3.3. ROUGE-N Evaluation Measure
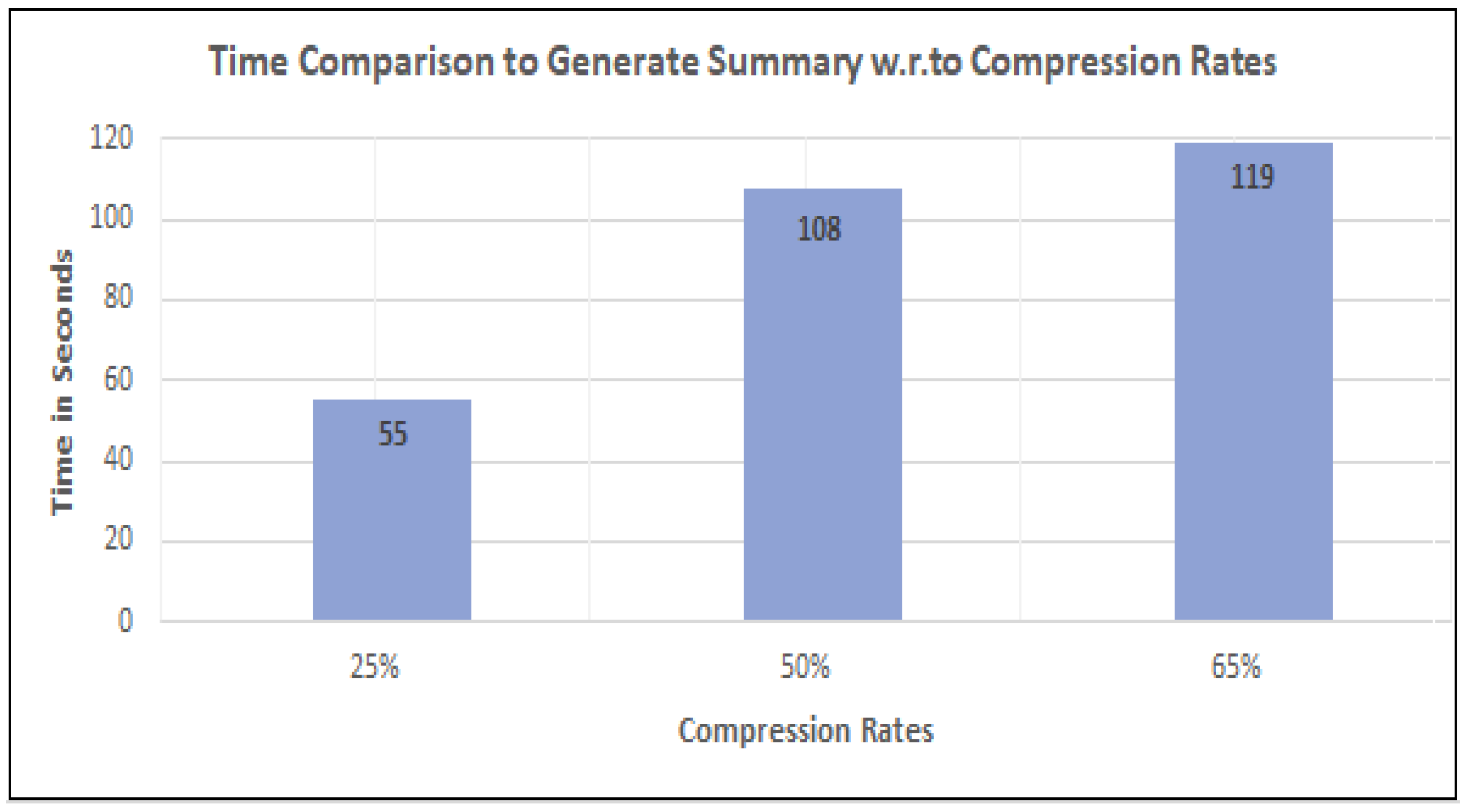
4.3.4. Time Comparison to Generate Summary
4.3.5. Comparison of Summary among Tools
5. Conclusions
6. Future Work
- ▪
- The automatic text summarization system can be applied to other domains such as finance, education, business, etc.
- ▪
- Based upon the choice of domain, prominent features can be identified using RCGA.
- ▪
- The ATS system can be portable to other Indian languages, such as Punjabi, Bengali, and Tamil.
- ▪
- The hold-out cross-validation can be extended to k-fold cross-validation.
- ▪
- The genetic algorithm optimized deep learning models, such as Recurrent Neural Network (RNN) and Long-Short Term Memory (LSTM), can be applied to improve the evaluation metrics.
- ▪
- An interesting aspect to develop in the future is the impact of Rogue-L in Hindi, a metric that often does not appear in the ATS articles in this language. Already in Lin’s article [74] the impact of some parameters on the computation of 17 Rogue-like indicators was compared showing the variation in English under different configurations. However, in languages where sentence order is more flexible or ellipsis are more frequent, an impact on this metric is to be expected. Thus, the aim is to evaluate Rogue-L under different configurations and languages to analyze its behavior.
- ▪
- Additional features need to be taken into account in the model. It is a known fact that evaluation metrics do not always detect the accuracy of the summary, the use of terminological equivalences, readability or coherence are aspects to be included in a correct analysis and evaluation of ATS.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yadav, D.; Desai, J.; Yadav, A.K. Automatic Text Summarization Methods: A Comprehensive Review. arXiv 2022, arXiv:2204.01849. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic Text Summarization: A Comprehensive Survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Abdulateef, S.; Khan, N.A.; Chen, B.; Shang, X. Multidocument Arabic Text Summarization Based on Clustering and Word2Vec to Reduce Redundancy. Information 2020, 11, 59. [Google Scholar] [CrossRef] [Green Version]
- Mohsin, M.; Latif, S.; Haneef, M.; Tariq, U.; Khan, M.A.; Kadry, S.; Yong, H.-S.; Choi, J.-I. Improved Text Summarization of News Articles Using GA-HC and PSO-HC. Appl. Sci. 2021, 11, 10511. [Google Scholar] [CrossRef]
- Verma, P.; Verma, A.; Pal, S. An Approach for Extractive Text Summarization Using Fuzzy Evolutionary and Clustering Algorithms. Appl. Soft Comput. 2022, 120, 108670. [Google Scholar] [CrossRef]
- Baykara, B.; Güngör, T. Abstractive Text Summarization and New Large-Scale Datasets for Agglutinative Languages Turkish and Hungarian. Lang. Resour. Eval. 2022, 1–35. [Google Scholar] [CrossRef]
- Gupta, J.; Tayal, D.K.; Gupta, A. A TENGRAM method based part-of-speech tagging of multi-category words in Hindi language. Expert Syst. Appl. 2011, 38, 15084–15093. [Google Scholar] [CrossRef]
- Dhankhar, S.; Gupta, M.K. Automatic Extractive Summarization for English Text: A Brief Survey. In Proceedings of the Second Doctoral Symposium on Computational Intelligence (DoSCI-2021), Lucknow, India, 6 March 2021; Gupta, D., Khanna, A., Kansal, V., Fortino, G., Hassanien, A.E., Eds.; Springer: Singapore, 2021; Volume 1374, pp. 183–198. [Google Scholar] [CrossRef]
- Alomari, A.; Idris, N.; Sabri, A.Q.M.; Alsmadi, I. Deep reinforcement and transfer learning for abstractive text summarization: A review. Comput. Speech Lang. 2021, 71, 101276. [Google Scholar] [CrossRef]
- Simmons, G. Etnologue. 2022. Available online: https://www.ethnologue.com/ethnoblog/gary-simons/welcome-25th-edition (accessed on 25 June 2022).
- Jain, A.; Tayal, D.K.; Yadav, D.; Arora, A. Research Trends for Named Entity Recognition in Hindi Language. In Data Visualization and Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2020; pp. 223–248. [Google Scholar] [CrossRef]
- Jain, A.; Yadav, D.; Arora, A.; Tayal, D.K. Named-Entity Recognition for Hindi Language Using Context Pattern-based Maximum Entropy. Comput. Sci. 2022, 23, 81–116. [Google Scholar] [CrossRef]
- Sarkar, S.; Pramanik, A.; Khatedi, N.; Balu, A.S.M.; Maiti, J. GSEL: A Genetic Stacking-Based Ensemble Learning Approach for Incident Classification. In Proceedings of the ICETIT 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 719–730. [Google Scholar] [CrossRef]
- Jain, A. Named Entity Recognition for Hindi Language Using NLP Techniques. Ph.D. Thesis, Jaypee Institute of Information Technology, Noida, India, 2019. [Google Scholar]
- Goldberg, D.E. Real-Coded Genetic Algorithms, Virtual Alphabets and Blocking; University of Illinois at Urbana Champaign: Champaign, IL, USA, 1990. [Google Scholar]
- Jain, A.; Arora, A.; Yadav, D.; Morato, J.; Kaur, A. Text Summarization Technique for Punjabi Language Using Neural Networks. Int. Arab. J. Inf. Technol. 2021, 18, 807–818. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text Summarization with Pre-trained Encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar] [CrossRef]
- Desai, N.; Shah, P. Automatic Text Summarization Using Supervised Machine Learning Technique for Hindi Language. Int. J. Res. Eng. Technol. (IJRET) 2016, 5, 361–367. [Google Scholar]
- Patil, N.R.; Patnaik, G.K. Automatic Text Summarization with Statistical, Linguistic and Cohesion Features. Int. J. Comput. Sci. Inf. Technol. 2017, 8, 194–198. [Google Scholar]
- Jain, A.; Yadav, D.; Arora, A. Particle Swarm Optimization for Punjabi Text Summarization. Int. J. Oper. Res. Inf. Syst. (IJORIS) 2021, 12, 1–17. [Google Scholar] [CrossRef]
- Gupta, M.; Garg, N.K. Text Summarization of Hindi Documents Using Rule-Based Approach. In Proceedings of the International Conference on Micro-Electronics and Telecommunication Engineering (ICMETE), Ghaziabad, India, 22–23 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 366–370. [Google Scholar] [CrossRef]
- Anitha, J.; Prasad Reddy, P.V.G.D.; Prasad Babu, M.S. An Approach for Summarizing Hindi Text through a Hybrid Fuzzy Neural Network Algorithm. J. Inf. Knowl. Manag. (JIKM) 2014, 13, 1450036. [Google Scholar] [CrossRef]
- Lutimath, N.M.; Ramachandra, H.V.; Raghav, S.; Sharma, N. Prediction of Heart Disease Using Genetic Algorithm. In Proceedings of the Second Doctoral Symposium on Computational Intelligence, Lucknow, India, 6 March 2021; Springer: Singapore, 2022; pp. 49–58. [Google Scholar] [CrossRef]
- Lotf, J.J.; Azgomi, M.A.; Dishabi, M.R.E. An improved influence maximization method for social networks based on genetic algorithm. Phys. A Stat. Mech. Its Appl. 2021, 586, 126480. [Google Scholar] [CrossRef]
- Mustafi, D.; Mustafi, A.; Sahoo, G. A Novel Approach to Text Clustering Using Genetic Algorithm Based on the Nearest Neighbour Heuristic. Int. J. Comput. Appl. 2022, 44, 291–303. [Google Scholar] [CrossRef]
- Ilyas, Q.M.; Ahmad, M.; Rauf, S.; Irfan, D. RDF Query Path Optimization Using Hybrid Genetic Algorithms: Semantic Web vs. Data-Intensive Cloud Computing. Int. J. Cloud Appl. Comput. (IJCAC) 2022, 12, 1–16. [Google Scholar] [CrossRef]
- Si, L.; Hu, X.; Liu, B. Image Matching Algorithm Based on the Pattern Recognition Genetic Algorithm. Comput. Intell. Neurosci. 2022, 2022, 7760437. [Google Scholar] [CrossRef]
- Bu, S.J.; Kang, H.B.; Cho, S.B. Ensemble of Deep Convolutional Learning Classifier System Based on Genetic Algorithm for Database Intrusion Detection. Electronics 2022, 11, 745. [Google Scholar] [CrossRef]
- Litvak, M.; Last, M.; Friedman, M. A New Approach to Improving Multilingual Summarization Using a Genetic Algorithm. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 927–936. [Google Scholar]
- Suanmali, L.; Salim, N.; Binwahlan, M.S. Fuzzy Genetic Semantic Based Text Summarization. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Sydney, NSW, Australia, 12–14 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1184–1191. [Google Scholar] [CrossRef]
- Abuobieda, A.; Salim, N.; Albaham, A.T.; Osman, A.H.; Kumar, Y.J. Text Summarization Features Selection Method Using Pseudo Genetic Based Model. In Proceedings of the International Conference on Information Retrieval & Knowledge Management, Kuala Lumpur, Malaysia, 13–15 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 193–197. [Google Scholar] [CrossRef] [Green Version]
- García-Hernández, R.A.; Ledeneva, Y. Single Extractive Text Summarization based on a Genetic Algorithm. In Proceedings of the Mexican Conference on Pattern Recognition, Cancun, Mexico, 25–28 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 374–383. [Google Scholar] [CrossRef] [Green Version]
- Thaokar, C.; Malik, L. Test Model for Summarizing Hindi Text Using Extraction Method. In Proceedings of the 2013 IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–12 April 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1138–1143. [Google Scholar] [CrossRef]
- Kadam, D.P.; Patil, N.; Gulathi, A. A Comparative Study of Hindi Text Summarization Techniques: Genetic Algorithm and Neural Network. Int. J. Innov. Adv. Comput. Sci. (IJIACS) 2015, 4, 541–548. [Google Scholar]
- Pareek, G.; Modi, D.; Athaiya, A. A Meticulous Approach for Extractive Based Hindi Text Summarization Using Genetic Algorithm. Int. J. Innov. Adv. Comput. Sci. (IJACS) 2017, 6, 264–273. [Google Scholar]
- Vázquez, E.; Arnulfo Garcia-Hernandez, R.; Ledeneva, Y. Sentence Features Relevance for Extractive Text Summarization Using Genetic Algorithms. J. Intell. Fuzzy Syst. 2018, 35, 353–365. [Google Scholar] [CrossRef]
- Simón, J.R.; Ledeneva, Y.; García-Hernández, R.A. Calculating the Significance of Automatic Extractive Text Summarization Using a Genetic Algorithm. J. Intell. Fuzzy Syst. 2018, 35, 293–304. [Google Scholar] [CrossRef]
- Anh, B.T.M.; My, N.T.; Trang, N.T.T. Enhanced Genetic Algorithm for Single Document Extractive Summarization. In Proceedings of the Tenth International Symposium on Information and Communication Technology, Hanoi Ha Long Bay, Viet Nam, 4–6 December 2019; pp. 370–376. [Google Scholar] [CrossRef]
- Hernández-Castañeda, Á.; García-Hernández, R.A.; Ledeneva, Y.; Millán-Hernández, C.E. Extractive Automatic Text Summarization Based on Lexical-Semantic Keywords. IEEE Access 2020, 8, 49896–49907. [Google Scholar] [CrossRef]
- Chen, W.; Ramos, K.; Mullaguri, K.N. Genetic Algorithms for Extractive Summarization. arXiv 2021, arXiv:2105.02365. [Google Scholar] [CrossRef]
- Tanfouri, I.; Tlik, G.; Jarray, F. An Automatic Arabic Text Summarization System Based on Genetic Algorithms. Procedia Comput. Sci. 2021, 189, 195–202. [Google Scholar] [CrossRef]
- Khotimah, N.; Girsang, A.S. Indonesian News Articles Summarization Using Genetic Algorithm. Eng. Lett. 2022, 30. Available online: http://www.engineeringletters.com/issues_v30/issue_1/EL_30_1_17.pdf (accessed on 15 December 2021).
- Ewees, A.A.; Al-qaness, M.A.; Abualigah, L.; Oliva, D.; Algamal, Z.Y.; Anter, A.M.; Ibrahim, R.A.; Ghoniem, R.M.; Abd Elaziz, M. Boosting Arithmetic Optimization Algorithm with Genetic Algorithm Operators for Feature Selection: Case Study on Cox Proportional Hazards Model. Mathematics 2021, 9, 2321. [Google Scholar] [CrossRef]
- Abuobieda, A.; Salim, N.; Kumar, Y.J.; Osman, A.H. An Improved Evolutionary Algorithm for Extractive Text Summarization. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Kuala Lumpur, Malaysia, 18–20 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 78–89. [Google Scholar] [CrossRef]
- Jain, A.; Tayal, D.K.; Arora, A. OntoHindi NER—An Ontology Based Novel Approach for Hindi Named Entity Recognition. Int. J. Artif. Intell. (IJAI) 2018, 16, 106–135. [Google Scholar]
- Kumar, K.V.; Yadav, D.; Sharma, A. Graph-Based Technique for Hindi Text Summarization. In Information Systems Design and Intelligent Applications-Volume 339 of the series Advances in Intelligent Systems and Computing (AISC); Springer: New Delhi, India, 2015; pp. 301–310. [Google Scholar] [CrossRef]
- Sargule, S.; Kagalkar, R.M. Strategy for Hindi Text Summarization using Content-Based Indexing Approach. Int. J. Comput. Sci. Eng. 2016, 4, 36–42. [Google Scholar]
- Giradkar, A.; Sawarkar, S.D.; Gulati, A. Multi-Document Text Summarization Using Backpropagation Network. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 3512–3516. [Google Scholar]
- Dalal, V.; Malik, L. Automatic Summarization for Hindi Text Documents using Bio-inspired Computing. Int. J. Adv. Res. Comput. Commun. Eng. (IJARCCE) 2017, 6, 682–688. [Google Scholar] [CrossRef]
- Rani, R.; Lobiyal, D.K. An Extractive Text Summarization Approach Using Tagged-LDA Based Topic Modeling. Multimed. Tools Appl. 2021, 80, 3275–3305. [Google Scholar] [CrossRef]
- McKeown, K.R.; Barzilay, R.; Evans, D.; Hatzivassiloglou, V.; Klavans, J.L.; Nenkova, A.; Sable, C.; Schiffman, B.; Sigelman, S. Tracking and Summarizing News on a Daily Basis with Columbia’s Newsblaster. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 March 2002; Morgan Kaufmann Publishers Inc.: San Diego, CA, USA, 2002; pp. 280–285. [Google Scholar]
- Abhiman, B.D.; Rokade, P.P. A Text Summarization Using Modern Features and Fuzzy Logic. Int. J. Comput. Sci. Mob. Comput. (IJCSMC) 2015, 4, 1013–1022. [Google Scholar]
- Online Summarize Tool (tools4noobs.com). Available online: https://www.tools4noobs.com/summarize (accessed on 25 June 2022).
- Free Summarizer. Available online: http://www.freesummarizer.com/ (accessed on 25 June 2022).
- SMMRY. Available online: https://smmry.com/ (accessed on 25 June 2022).
- M-HITS: Hindi Text Summarizer. Available online: https://github.com/harshshah1306/Text-Summarizer (accessed on 25 June 2022).
- Mishra, U.; Prakash, C. MAULIK: An Effective Stemmer for Hindi Language. Int. J. Comput. Sci. Eng. 2012, 4, 711–717. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.641.4331&rep=rep1&type=pdf (accessed on 25 June 2022).
- Hindi Stop-Words. Available online: https://github.com/stopwords-iso/stopwords-hi/blob/master/stopwords-hi.txt/ (accessed on 25 June 2022).
- Pareek, G.; Modi, D. Feature Extraction in Hindi Text Summarization. Ski. Res. J. 2016, 6, 14–19. [Google Scholar]
- Li, Y.; Bandar, Z.; McLean, D.; O’shea, J. A Method for Measuring Sentence Similarity and its Application to Conversational Agents. In Proceedings of the FLAIRS Conference, Miami Beach, FL, USA, 12–14 May 2004; pp. 820–825. Available online: https://www.aaai.org/Papers/FLAIRS/2004/Flairs04-139.pdf (accessed on 25 June 2022).
- Kumar, K.V.; Yadav, D. An Improvised Extractive Approach to Hindi Text Summarization. In Information Systems Design and Intelligent Applications, -Volume 339 of the Series Advances in Intelligent Systems and Computing (AISC); Springer: New Delhi, India, 2015; pp. 291–300. [Google Scholar] [CrossRef]
- Alguliev, R.M.; Aliguliyev, R.M. Effective Summarization Method of Text Documents. In Proceedings of the 2005 IEEE/WIC/ACM International Conference on Web Intelligence (WI’05), Compiegne, France, 19–22 September 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 264–271. [Google Scholar] [CrossRef]
- Jain, A.; Yadav, D.; Tayal, D.K. NER for Hindi Language Using Association Rules. In Proceedings of the International Conference on Data Mining and Intelligent Computing (ICDMIC), Delhi, India, 5–6 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Jain, A.; Arora, A. Named Entity System for Tweets in Hindi Language. Int. J. Intell. Inf. Technol. (IJIIT) 2018, 14, 55–76. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.; Arora, A. Named Entity Recognition in Hindi Using Hyperspace Analogue to Language and Conditional Random Field. Pertanika J. Sci. Technol. 2018, 26, 1801–1822. [Google Scholar]
- Mohammed, A.A. Text Summarization by Using Genetic Algorithm Method. Ph.D. Thesis, Sudan University of Science and Technology, Khartoum, Sudan, 2015. Available online: http://repository.sustech.edu/handle/123456789/11226 (accessed on 25 June 2022).
- Deb, K.; Agrawal, R.B. Simulated Binary Crossover for Continuous Search Space. Complex Syst. 1995, 9, 115–148. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.26.8485&rep=rep1&type=pdf (accessed on 25 June 2022).
- Deb, K.; Agrawal, S. A Niched-Penalty Approach for Constraint Handling in Genetic Algorithms. In Artificial Neural Nets and Genetic Algorithms; Springer: Vienna, Austria, 1999; pp. 235–243. [Google Scholar] [CrossRef]
- Kaggle: Hindi Health Dataset. Available online: https://www.kaggle.com/datasets/aijain/hindi-health-dataset (accessed on 25 June 2022).
- Chui, K.T.; Gupta, B.B.; Vasant, P. A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine. Electronics 2021, 10, 285. [Google Scholar] [CrossRef]
- Ganesan, K. An Intro to ROUGE, and How to Use it to Evaluate Summaries. 2017. Available online: https://www.freecodecamp.org/news/what-is-rouge-and-how-it-works-for-evaluation-of-summaries-e059fb8ac840/#:~:text=If%20you%20are%20working%20on%20extractive%20summarization%20with,stemming%20and%20stop%20word%20removal.%20Papers%20to%20Read (accessed on 25 June 2022).
- European Commission. Directorate-General for Translation. In How to Write Clearly; Publications Office of the European Commission: Maastricht, The Netherlands, 2011. [Google Scholar]
- Verma, P.; Pal, S.; Om, H. A Comparative Analysis on Hindi and English Extractive Text Summarization. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 18, 30. [Google Scholar] [CrossRef]
- Lin, C. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Dataset(s) | Language(s) | Features Extraction | Evaluation Measures | |||
|---|---|---|---|---|---|---|---|
| Litvak et al., 2010 [29] | DUC 2002—533 news articles; Haaretz newspaper—50 news articles | English Hebrew | 31 sentence scoring metrics | ROUGE-1 English: 44.61% ROUGE-1: 59.21% | |||
| Suanmali et al., 2011 [30] | DUC 2002—100 documents | English | title feature, sentence length, term weight, sentence position, sentence-to-sentence similarity, proper noun, numerical data, thematic word | Precision: 49.80% Recall: 44.64% F-score: 46.62% | |||
| Abuobieda et al., 2012 [31] | DUC 2002—100 documents | English | title feature, sentence length, sentence position, numerical data, thematic words | ROUGE-1 | |||
| García-Hernández and Ledeneva, 2013 [32] | DUC 2002—567 news articles | English | n-gram, frequency of words, sentence position | F-score (48.27%) | |||
| Thaokar and Malik, 2013 [33] | - | Hindi | statistical features: TF-ISF, sentence length, sentence position, numerical data, sentence-to-sentence similarity, title feature; linguistic features: SOV qualification, subject similarity | Precision Recall | |||
| Kadam et al., 2015 [34] | - | Hindi | statistical features: TF-ISF, sentence length, sentence position, numerical data, sentence-to-sentence similarity, title word; linguistic features: proper noun, thematic words | Suggest ROUGE (unspecified) | |||
| Pareek et al., 2017 [35] | Dainik Bhaskar, Patrika, Zee news- 15 text documents with categories: sports, Bollywood, politics, science, history | Hindi | statistical features: TF-ISF, sentence length, sentence position, numerical data, sentence to sentence similarity, title word, adjective feature; linguistic features: SOV qualification, subject similarity | Com. Rate (%) | Precision (%) | Recall (%) | Accuracy (%) |
| 25 | 69 | 62 | 67 | ||||
| 50 | 73 | 67 | 71 | ||||
| 60 | 78 | 79 | 80 | ||||
| Vázquez et al., 2018 [36] | DUC01—309 news articles; DUC02—567 news articles | English | similarity to title, sentence position, sentence length, term length, coverage | DUC | ROUGE-1 (%) | ROUGE-2 (%) | |
| 2001 | 45.058 | 19.619 | |||||
| 2002 | 48.423 | 22.471 | |||||
| Simón et al., 2018 [37] | DUC01—309 news articles; DUC02—567 news articles | English | term frequency (document and summary), sentence position | DUC | ROUGE-1 (%) | ROUGE-2 (%) | |
| 2001 | 37.39 | 38.39762 | |||||
| 2002 | 41.06 | 40.6138 | |||||
| Anh et al., 2019 [38] | CNN/DailyMail | English | TF-ISF, similarity to topic, sentence length, proper noun, sentence position | Precision (%) | Recall (%) | F-measure (%) | |
| 84.3 | 48.3 | 58.0 | |||||
| Hernández-Castañeda et al., 2020 [39] | DUC02 and TAC11 | English Arabic, Czech, French, Greek, Hebrew, and Hindi | TF-IDF, one-hot encoding, latent dirichlet allocation, Doc2Vec | ROUGE-1 | English | 0.48681 | |
| Arabic | 0.33913 | ||||||
| Czech | 0.43643 | ||||||
| French | 0.49841 | ||||||
| Greek | 0.32770 | ||||||
| Hebrew | 0.30576 | ||||||
| Hindi | 0.11351 | ||||||
| Chen et al., 2021 [40] | CNN/DailyMail | English | vocabulary set | Training Size | Vocab Size | ROUGE-1 Score | |
| 100 | 90,000 | 23.59 | |||||
| 50 | 90,000 | 22.6 | |||||
| Tanfouri et al., 2021 [41] | EASC—153 articles and Multilingual Pilot Corpus 2013 | Arabic | - | ROUGE-1 | ROUGE-2 | ||
| EASC | 0.41 | 0.30 | |||||
| Multilingual | 0.16 | 0.029 | |||||
| Khotimah and Girsang, 2022 [42] | IndoSum—60 documents with 6 different topics | Indonesian | Com. Rate (%) | Precision (%) | Recall (%) | F-score (%) | |
| 10 | 48.9 | 40.6 | 42.6 | ||||
| 20 | 38.7 | 53.9 | 43.4 | ||||
| 30 | 33.0 | 64.0 | 42.1 | ||||
| Language | No. of Articles | Precision | Recall |
|---|---|---|---|
| English | 353 | 89.10% | 90.70% |
| Russian | 112 | 90.59% | 95.06% |
| Japanese | 67 | 89.66% | 100% |
| NE Type | HHD Example(s) | |
|---|---|---|
| Disease | “दमा” | (dama/asthma) |
| “मधुमेह” | (madhumeh/diabetes) | |
| Symptom | “कमजोरी” | (kamajoree/weakness) |
| “थकान” | (thakaan/fatigue) | |
| Consumable | “कालीमिर्च” | (kaaleemirch/black pepper) |
| “गाजर” | (gaajar/carrot) | |
| Person | “चिकित्सक” | (chikitsak/doctor) |
| “मरीज” | (mareej/patient) | |
| Fsp | Fnd | Fls | Fkw | Fss | Fne | Feh | Fti |
|---|---|---|---|---|---|---|---|
| 0.40 | 0.39 | 0.43 | 0.76 | 0.21 | 0.34 | 0.73 | 0.81 |
| Feature | Fsp | Fnd | Fls | Fkw | Fss | Fne | Feh | Fti |
|---|---|---|---|---|---|---|---|---|
| Chromosome | 0.40 | 0.39 | 0.43 | 0.76 | 0.21 | 0.34 | 0.73 | 0.81 |
| Offspring (population size = 4) | 0.956 | 0.951 | 0.97 | 1.16 | 0.84 | 0.925 | 1.13 | 1.21 |
| Feature | Fsp | Fnd | Fls | Fkw | Fss | Fne | Feh | Fti |
|---|---|---|---|---|---|---|---|---|
| Chromosome | 0.40 | 0.39 | 0.43 | 0.76 | 0.21 | 0.34 | 0.73 | 0.81 |
| Offspring SBX (population size = 4) | 0.956 | 0.951 | 0.97 | 1.16 | 0.84 | 0.925 | 1.13 | 1.21 |
| Offspring (mutation) | 0.385 | 0.371 | 0.43 | 0.183 | 0.21 | 0.315 | 0.177 | 0.19 |
| Feature Set | Features | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Set1 | Fsp | 0.54 | 0.51 | 0.52 |
| Set2 | Fsp, Fnd | 0.64 | 0.53 | 0.58 |
| Set3 | Fsp, Fnd, Fls | 0.57 | 0.54 | 0.55 |
| Set4 | Fsp, Fnd, Fkw | 0.62 | 0.59 | 0.60 |
| Set5 | Fsp, Fkw, Fss | 0.66 | 0.63 | 0.64 |
| Set6 | Fsp, Fnd, Fls, Fkw | 0.63 | 0.66 | 0.64 |
| Set7 | Fss, Fne | 0.71 | 0.65 | 0.68 |
| Set8 | Fnd, Fkw, Fss, Fne | 0.72 | 0.73 | 0.72 |
| Set9 | Fsp, Fls, Fkw, Fss, Fne | 0.63 | 0.64 | 0.63 |
| Set10 | Fkw, Fss, Fne, Feh | 0.74 | 0.76 | 0.75 |
| Set11 | Fsp, Fnd, Fls, Fkw, Fss, Feh | 0.69 | 0.62 | 0.65 |
| Set12 | Fnd, Fkw, Fss, Feh, Fti | 0.75 | 0.75 | 0.75 |
| Set13 | Fsp, Fkw, Fss, Fne, Feh, Fti | 0.81 | 0.76 | 0.78 |
| Set14 | Fsp, Fnd, Fls, Fkw, Fss, Fne, Feh, Fti | 0.79 | 0.78 | 0.78 |
| Feature Set | Features | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Set1 | Fsp | 0.62 | 0.61 | 0.61 |
| Set2 | Fsp, Fnd | 0.63 | 0.66 | 0.64 |
| Set3 | Fsp, Fnd, Fls | 0.62 | 0.62 | 0.62 |
| Set4 | Fsp, Fnd, Fkw | 0.65 | 0.66 | 0.65 |
| Set5 | Fsp, Fkw, Fss | 0.69 | 0.65 | 0.67 |
| Set6 | Fsp, Fnd, Fls, Fkw | 0.68 | 0.68 | 0.68 |
| Set7 | Fss, Fne | 0.70 | 0.73 | 0.71 |
| Set8 | Fnd, Fkw, Fss, Fne | 0.73 | 0.72 | 0.72 |
| Set9 | Fsp, Fls, Fkw, Fss, Fne | 0.64 | 0.63 | 0.63 |
| Set10 | Fkw, Fss, Fne, Feh | 0.73 | 0.75 | 0.74 |
| Set11 | Fsp, Fnd, Fls, Fkw, Fss, Feh | 0.62 | 0.69 | 0.65 |
| Set12 | Fnd, Fkw, Fss, Feh, Fti | 0.79 | 0.76 | 0.77 |
| Set13 | Fsp, Fkw, Fss, Fne, Feh, Fti | 0.84 | 0.79 | 0.81 |
| Set14 | Fsp, Fnd, Fls, Fkw, Fss, Fne, Feh, Fti | 0.83 | 0.84 | 0.83 |
| Feature Set | Features | Precision | Recall | F-measure |
|---|---|---|---|---|
| Set1 | Fsp | 0.62 | 0.69 | 0.65 |
| Set2 | Fsp, Fnd | 0.69 | 0.74 | 0.71 |
| Set3 | Fsp, Fnd, Fls | 0.69 | 0.68 | 0.68 |
| Set4 | Fsp, Fnd, Fkw | 0.73 | 0.78 | 0.75 |
| Set5 | Fsp, Fkw, Fss | 0.79 | 0.86 | 0.82 |
| Set6 | Fsp, Fnd, Fls, Fkw | 0.82 | 0.83 | 0.82 |
| Set7 | Fss, Fne | 0.87 | 0.81 | 0.84 |
| Set8 | Fnd, Fkw, Fss, Fne | 0.85 | 0.83 | 0.84 |
| Set9 | Fsp, Fls, Fkw, Fss, Fne | 0.72 | 0.79 | 0.75 |
| Set10 | Fkw, Fss, Fne, Feh | 0.84 | 0.86 | 0.85 |
| Set11 | Fsp, Fnd, Fls, Fkw, Fss, Feh | 0.76 | 0.84 | 0.80 |
| Set12 | Fnd, Fkw, Fss, Feh, Fti | 0.81 | 0.83 | 0.82 |
| Set13 | Fsp, Fkw, Fss, Fne, Feh, Fti | 0.84 | 0.88 | 0.86 |
| Set14 | Fsp, Fnd, Fls, Fkw, Fss, Fne, Feh, Fti | 0.83 | 0.91 | 0.87 |
| Average Precision | Average Recall | Average F-Measure | |
|---|---|---|---|
| ROUGE-1 | 81% | 78% | 79% |
| ROUGE-2 | 65% | 68% | 66% |
| Tools | Summary Reduction |
|---|---|
| Free Summarizer | 58% |
| Tool4Noobs | 66% |
| SMMRY | 63% |
| Proposed Work | 65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jain, A.; Arora, A.; Morato, J.; Yadav, D.; Kumar, K.V. Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm. Appl. Sci. 2022, 12, 6584. https://doi.org/10.3390/app12136584
Jain A, Arora A, Morato J, Yadav D, Kumar KV. Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm. Applied Sciences. 2022; 12(13):6584. https://doi.org/10.3390/app12136584
Chicago/Turabian StyleJain, Arti, Anuja Arora, Jorge Morato, Divakar Yadav, and Kumar Vimal Kumar. 2022. "Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm" Applied Sciences 12, no. 13: 6584. https://doi.org/10.3390/app12136584
APA StyleJain, A., Arora, A., Morato, J., Yadav, D., & Kumar, K. V. (2022). Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm. Applied Sciences, 12(13), 6584. https://doi.org/10.3390/app12136584