
Design and Implementation of Cloud Docker Application Architecture Based on Machine Learning in Container Management for Smart Manufacturing



Abstract
:1. Introduction
- By learning a container-based machine-learning application and building a defect inspection system, we aim to lower the barriers to entry into a digital transformation for small- and medium-sized manufacturers.
- We hope to help improve the quality of application building/distribution services (time/CPU/memory) for the use versus non-use of containers.
- We aim to contribute to container life-cycle management by predicting real-time anomalies and failures through container-monitoring management tools and visualizations.
2. Related Work
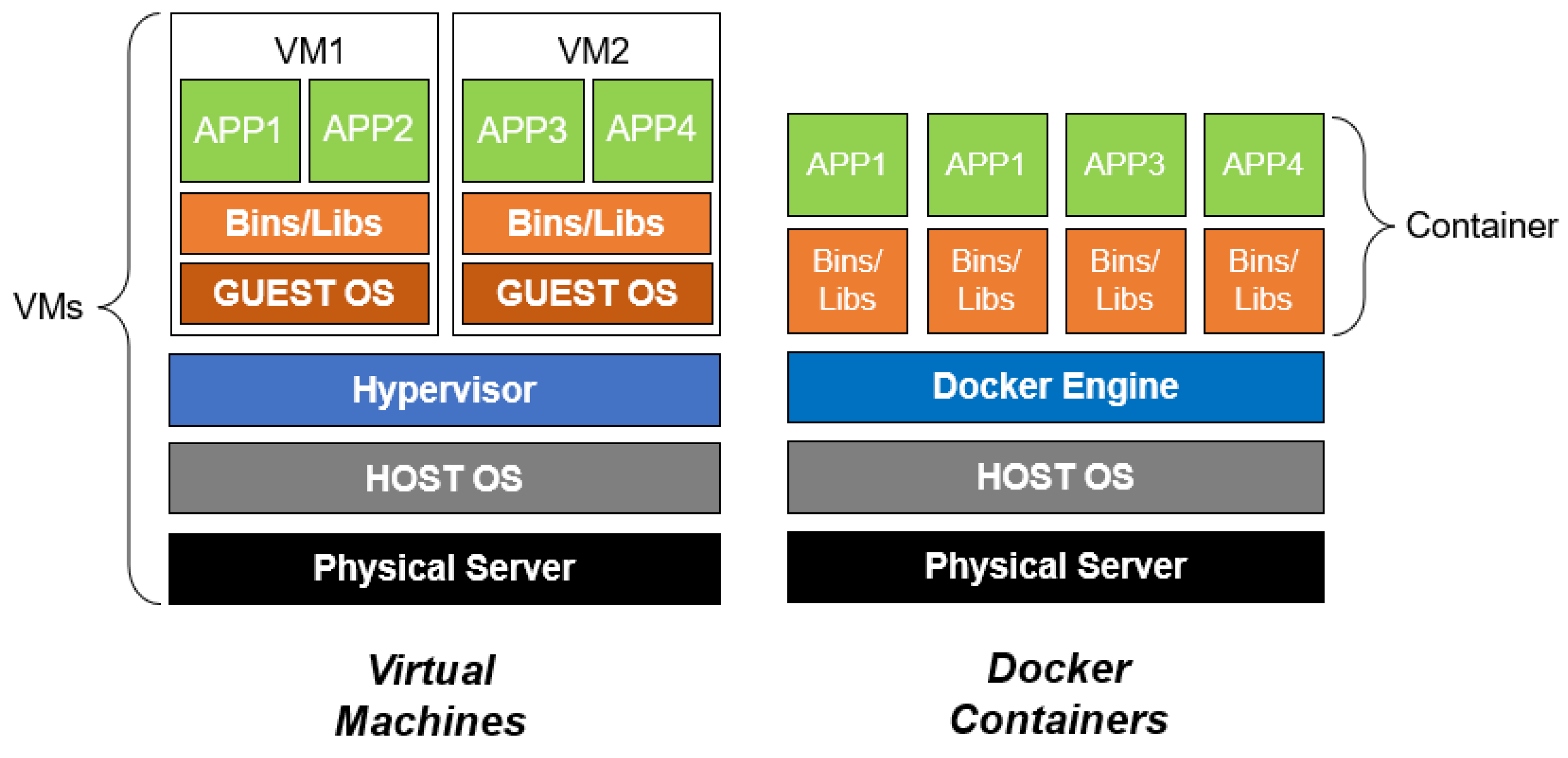
2.1. Docker Container
2.2. Docker Container Management Tool
2.3. Machine Learning
3. Cloud Docker Application Architecture Based on Machine Learning
3.1. System Architecture
3.2. Docker Container
3.3. Container Infrastructure
- Portainer: this is a Docker-paper used to manage the Docker clusters and Docker resources (e.g., containers, images, volumes, and networks). Portainer is an administrative web UI with a community edition that makes it easy to manage Docker clusters without writing multiple lines of script code [5].
- Jenkins: this is a popular Java-based server tool for automation with the help of plugins. Jenkins is considered a powerful application that helps automate software development processes through continuous integration and the delivery of papers, regardless of the platform being worked on [43]. It is automated to build and deploy machine-learning-based defect inspection applications and push them to the Docker Hub for container image management.
- Docker Hub: this is the largest group of container images available in the world. Images on Docker Hub are organized into repositories, which can be divided into official and community repositories. For each image in a Docker Hub repository, in addition to the image itself, meta-information is also available to the users, such as the repository description and history, in a Dockerfile [37].
- Jupyter Notebook: this is mainly used for service development for interactive computing across open-source software, open standards, and multiple programming languages. Jupyter Notebook supports the Julia, Python, and R programming languages. Jupyter Notebooks can potentially revolutionise the documentation and sharing of research software towards an unprecedented level of transparency for relatively low effort [44].
- DataDog: this is a monitoring service that collects metrics, such as the CPU utilization, memory, and I/O, for all containers. An agent-based system that only transmits data to the DataDog cloud makes monitoring operations completely dependent on this cloud [45].
- Docker Swarm Visualizer: this is an open-source paper that provides a user-friendly web UI for visualizing nodes belonging to a Docker cluster and containers deployed on such nodes [5].
4. Implementation and Results
4.1. System Configuration
4.2. Dataset and Machine-Learning Model
4.3. Docker Container-Based Defect Inspection System
- csv_to_json.py: the DataSet field consists of Line, defect, and feature1 30, and then converts the .csv file into a .json format.
- Api.py: learning is applied using four types of machine-learning models. In this study, four ML algorithms were applied to classify the test datasets. The SVC, LDA, NN, and KNN models were selected to solve the quaternary classification problem rather than binary classification. They were then combined.
4.4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jolak, R.; Rosenstatter, T.; Mohamad, M.; Strandberg, K.; Sangchoolie, B.; Nowdehi, N.; Scandariato, R. CONSERVE: A framework for the selection of techniques for monitoring containers security. J. Syst. Softw. 2022, 186, 111158. [Google Scholar] [CrossRef]
- Ahmad, I.; AlFailakawi, M.G.; AlMutawa, A.; Alsalman, L. Container scheduling techniques: A Survey and assessment. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3934–3947. [Google Scholar] [CrossRef]
- Li, Y.; Xia, Y. Auto-scaling web applications in hybrid cloud based on docker. In Proceedings of the 2016 5th International Conference on Computer Science and Network Technology (ICCSNT), Changchun, China, 10–11 December 2016; pp. 75–79. [Google Scholar]
- Swarm Mode Overview. Available online: https://docs.docker.com/engine/swarm/ (accessed on 20 May 2022).
- Martin, C.; Garrido, D.; Llopis, L.; Rubio, B.; Diaz, M. Facilitating the monitoring and management of structural health in civil infrastructures with an Edge/Fog/Cloud architecture. Comput. Stand. Interfaces 2022, 81, 103600. [Google Scholar] [CrossRef]
- Kubernetes vs. Docker: What Does It Really Mean. Available online: https://www.dynatrace.com/news/blog/kubernetes-vs-docker/ (accessed on 8 May 2022).
- Kubernetes vs. Mesos vs. Swarm. Available online: https://www.sumologickorea.com/insight/kubernetes-vs-mesos-vs-swarm/ (accessed on 10 March 2022).
- Anderson, C. Docker [software engineering]. IEEE Softw. 2015, 32, 102–105. [Google Scholar] [CrossRef]
- 8 Surprising Facts about Real Docker Adoption. Available online: https://www.datadoghq.com/docker-adoption/ (accessed on 9 May 2022).
- Open Source Container Management GUI for Kubernetes, Docker, Swarm. Available online: https://www.portainer.io/ (accessed on 9 May 2022).
- Brouwers, M. Security Considerations in Docker Swarm Networking. Master’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, 28 July 2017. [Google Scholar]
- Liu, X.; Shen, W.; Liu, B.; Li, Q.; Deng, R.; Ding, X. Research on Large Screen Visualization Based on Docker. J. Phys. Conf. Ser. 2018, 1169, 012052. [Google Scholar] [CrossRef]
- Docker Swarm Visualizer. Available online: https://github.com/dockersamples/docker-swarm-visualizer/ (accessed on 11 May 2022).
- 3 Pros and 3 Cons of Working with Docker Containers. Available online: https://sweetcode.io/3-pros-3-cons-working-docker-containers/ (accessed on 12 May 2022).
- Balatamoghna, B.; Jaganath, A.; Vaideeshwaran, S.; Subramanian, A.; Suganthi, K. Integrated balancing approach for hosting services with optimal efficiency—Self Hosting with Docker. Mater. Today Proc. 2022, 62, 4612–4619. [Google Scholar] [CrossRef]
- Gromann, M.; Klug, C. Monitoring Container Services at the Network Edge. In Proceedings of the 2017 29th International Teletraffic Congress (ITC 29), Genoa, Italy, 4–8 September 2017; pp. 130–133. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sijia, L.; Lan, T.; Yu, Z.; Xiuliang, Y. Comparison of the prediction effect between the Logistic Regressive model and SVM model. In Proceedings of the 2010 2nd IEEE International Conference on Information and Financial Engineering, Chongqing, China, 17–19 September 2010; pp. 316–318. [Google Scholar]
- Song, F.; Mei, D.; Li, H. Feature selection based on linear discriminant analysis. In Proceedings of the 2010 International Conference on Intelligent System Design and Engineering Application, Changsha, China, 13–14 October 2010; pp. 746–749. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Talukder, A.; Ahammed, B. Machine learning algorithms for predicting malnutrition among under-five children in Bangladesh. In Proceedings of the 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), Beni Suef, Egypt, 28–30 November 2015. [Google Scholar]
- Oommen, T.; Misra, D.; Twarakavi, N.K.; Prakash, A.; Sahoo, B.; Bandopadhyay, S. An Objective Analysis of Support Vector Machine Based Classification for Remote Sensing. Math. Geosci. 2008, 40, 409–424. [Google Scholar] [CrossRef]
- Tan, J.; Balasubramanian, B.; Sukha, D.; Ramkissoon, S.; Umaharan, P. Sensing fermentation degree of cocoa (Theobroma cacao L.) beans by machine learning classification models based electronic nose system. In Pattern Recognition and Neural Networks; Ripley, B.D., Ed.; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, T.M. Artificial neural networks. Mach. Learn. 1997, 45, 81–127. [Google Scholar]
- Cen, H.; Lu, R.; Zhu, Q.; Mendoza, F. Nondestructive detection of chilling injury in cucumber fruit using hyperspectral imaging with feature selection and supervised classification. Postharvest Biol. Technol. 2016, 111, 352–361. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Greco, N.; Oneto, L.; Ridella, S. Model selection for support vector machines: Advantages and disadvantages of the machine learning theory. In Proceedings of the 2010 International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Auria, L.; Moro, R.A. Support Vector Machines (SVM) as a Technique for Solvency Analysis; Discussion Papers of DIW Berlin 811; German Institute for Economic Research: Berlin, Germany, 2008. [Google Scholar]
- Lakshmi, M.R.; Prasad, T.; Prakash, D.V.C. Survey on EEG signal processing methods. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 84–91. [Google Scholar]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Imandoust, S.B.; Bolandraftar, M. Application of k-nearest neighbor (knn) approach for predicting economic events: Theoretical background. Int. J. Eng. Res. Appl. 2013, 3, 605–610. [Google Scholar]
- Mijwil, M.M. Artificial Neural Networks Advantages and Disadvantages. Linkedin 2018; pp. 1–2. Available online: https://www.linkedin.com/pulse/artificial-neural-networks-advantages-disadvantages-maad-m-mijwel/ (accessed on 27 June 2022).
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Wang, T.; Wang, H. Characterizing the Occurrence of Dockerfile Smells in Open-Source Software: An Empirical Study. IEEE Access 2020, 8, 34127–34139. [Google Scholar] [CrossRef]
- A Beginner-Friendly Introduction to Containers, VMs and Docker. Available online: https://www.freecodecamp.org/news/a-beginner-friendly-introduction-to-containers-vms-and-docker-79a9e3e119b/ (accessed on 2 February 2022).
- Docker Hub Documents. Available online: https://www.docker.com/products/docker-hub/ (accessed on 5 April 2022).
- Amazon ECR. Available online: https://aws.amazon.com/ecr/ (accessed on 22 June 2022).
- Oracle Container Registry. Available online: https://www.oracle.com/cloud/cloud-native/container-registry/ (accessed on 22 June 2022).
- Azure Container Registry. Available online: https://azure.microsoft.com/en-us/services/container-registry/ (accessed on 22 June 2022).
- Ebert, C.; Gallardo, G.; Hernantes, J.; Serrano, N. DevOps. IEEE Softw. 2016, 33, 94–100. [Google Scholar] [CrossRef]
- Morabito, R.; Petrolo, R.; Loscri, V.; Mitton, N. LEGIoT: A Lightweight Edge Gateway for the Internet of Things. Future Gener. Comput. Syst. 2018, 81, 1–15. [Google Scholar] [CrossRef] [Green Version]
- jenkins. Available online: https://wiki.jenkins-ci.org/display/JENKINS/Home/ (accessed on 21 February 2022).
- Penuela, A.; Hutton, C.; Pianosi, F. An open-source package with interactive Jupyter Notebooks to enhance the accessibility of reservoir operations simulation and optimisation. Environ. Model. Softw. 2021, 145, 105188. [Google Scholar] [CrossRef]
- Noor, A.; Mitra, K.; Solaiman, E.; Souza, A.; Jha, D.N.; Demirbaga, U.; Jayaraman, P.P.; Cacho, N.; Ranjan, R. Cyber-physical application monitoring across multiple clouds. Comput. Electr. Eng. 2019, 77, 314–324. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Advantages | Disadvantages |
|---|---|---|
| SVM/SVR | High performance, high accuracy, good handling of high dimensional data [17,28,29] | Lack of transparency in high dimensional data, extensive memory requirements [17,28,29] |
| linear discriminant analysis | Low computational cost Easy to implement Discriminate different groups Visual representation makes clear understanding [27,30] | Requires normal distribution Linear decision boundaries Limited to two classes [27,30] |
| K-Nearest Neighbors | Intuitive and simple, easy to implement for multiclass problems [31,32] | Computationally expensive in large datasets, performance depends on dimensionality [31,32] |
| Artificial Neural Networks | Good at handling large datasets, detect all possible interactions between prediction variables, implicit detection of complex non-linear relationships between dependent and independent variables [33,34] | High hardware dependencies (GPU), Unexplained behavior of the network, the duration of the network is unknown [33,34] |
| Item | Resource |
|---|---|
| Cloud | Amazon Web Service |
| Region | ap-northeast-2 |
| Service | EC2 |
| OS | Amazon Linux |
| Kernel | Linux |
| Instants type | T2.medium |
| Key Pairs | RSA |
| CPU | 2 |
| Storage | SSD(gp2) 25G |
| MEM | 4G |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.S.; Lee, S.H.; Lee, Y.R.; Park, Y.H.; Jeong, J. Design and Implementation of Cloud Docker Application Architecture Based on Machine Learning in Container Management for Smart Manufacturing. Appl. Sci. 2022, 12, 6737. https://doi.org/10.3390/app12136737
Kim BS, Lee SH, Lee YR, Park YH, Jeong J. Design and Implementation of Cloud Docker Application Architecture Based on Machine Learning in Container Management for Smart Manufacturing. Applied Sciences. 2022; 12(13):6737. https://doi.org/10.3390/app12136737
Chicago/Turabian StyleKim, Byoung Soo, Sang Hyeop Lee, Ye Rim Lee, Yong Hyun Park, and Jongpil Jeong. 2022. "Design and Implementation of Cloud Docker Application Architecture Based on Machine Learning in Container Management for Smart Manufacturing" Applied Sciences 12, no. 13: 6737. https://doi.org/10.3390/app12136737
APA StyleKim, B. S., Lee, S. H., Lee, Y. R., Park, Y. H., & Jeong, J. (2022). Design and Implementation of Cloud Docker Application Architecture Based on Machine Learning in Container Management for Smart Manufacturing. Applied Sciences, 12(13), 6737. https://doi.org/10.3390/app12136737