
Automatic False Alarm Detection Based on XAI and Reliability Analysis

Abstract
:1. Introduction
2. Related Work
2.1. AI Cyber Threat Detection
2.2. XAI
3. Materials and Methods
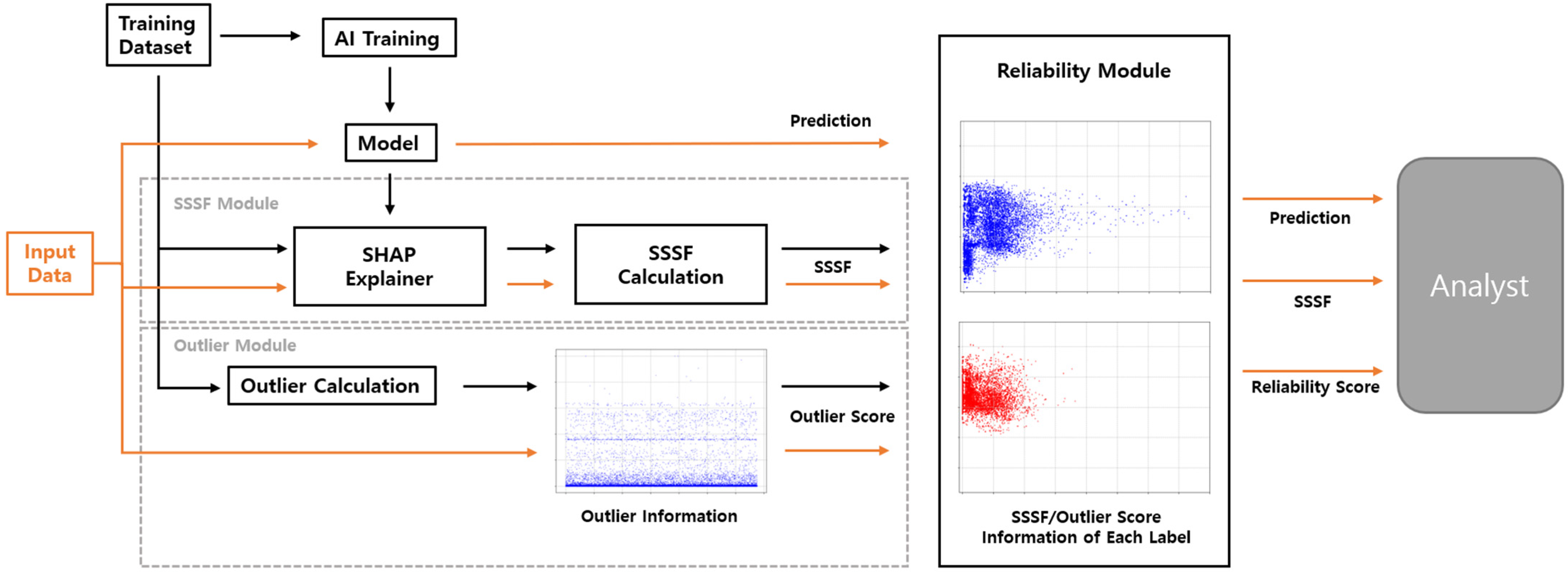
3.1. Overview
3.2. Preparing for Analysis
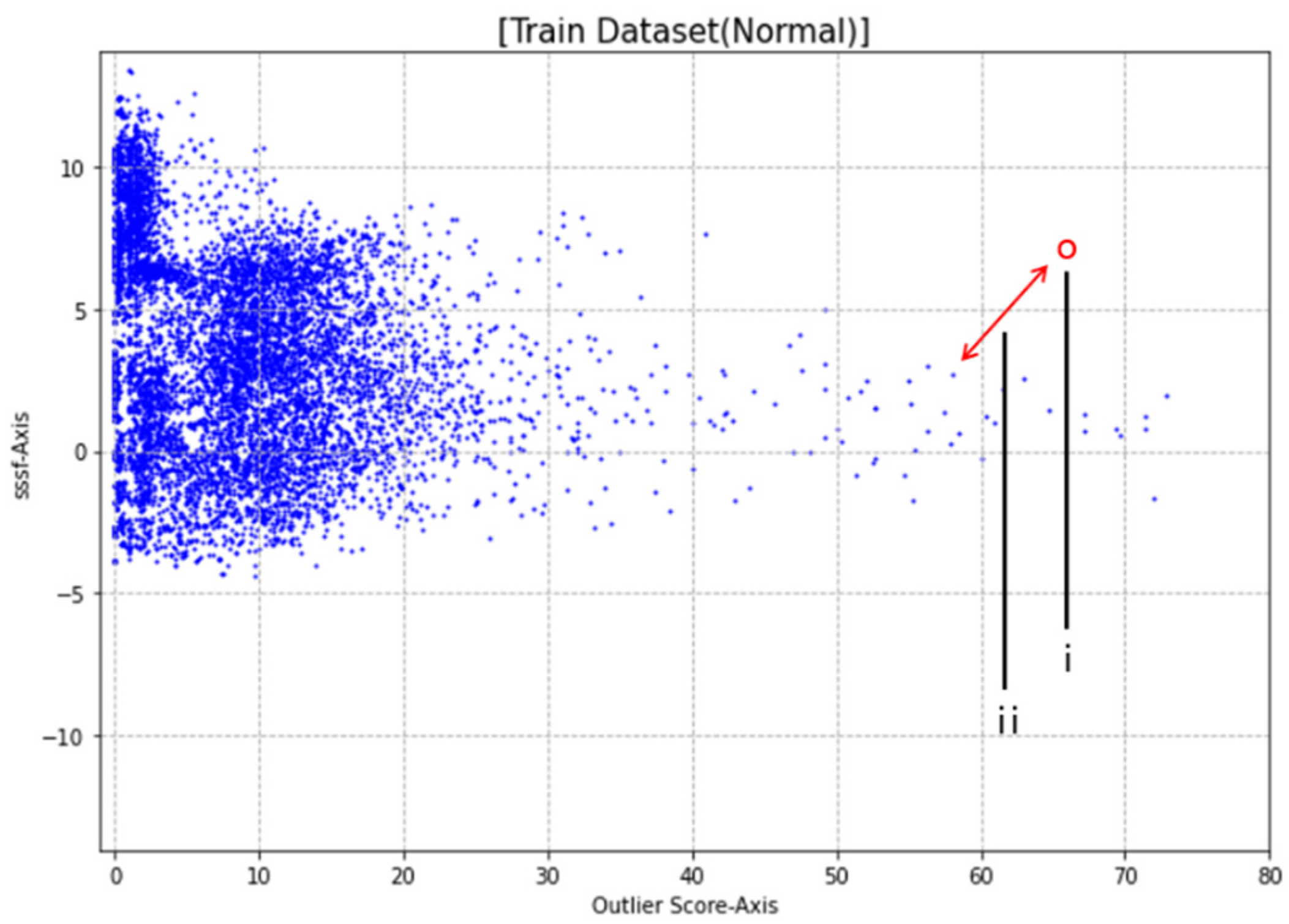
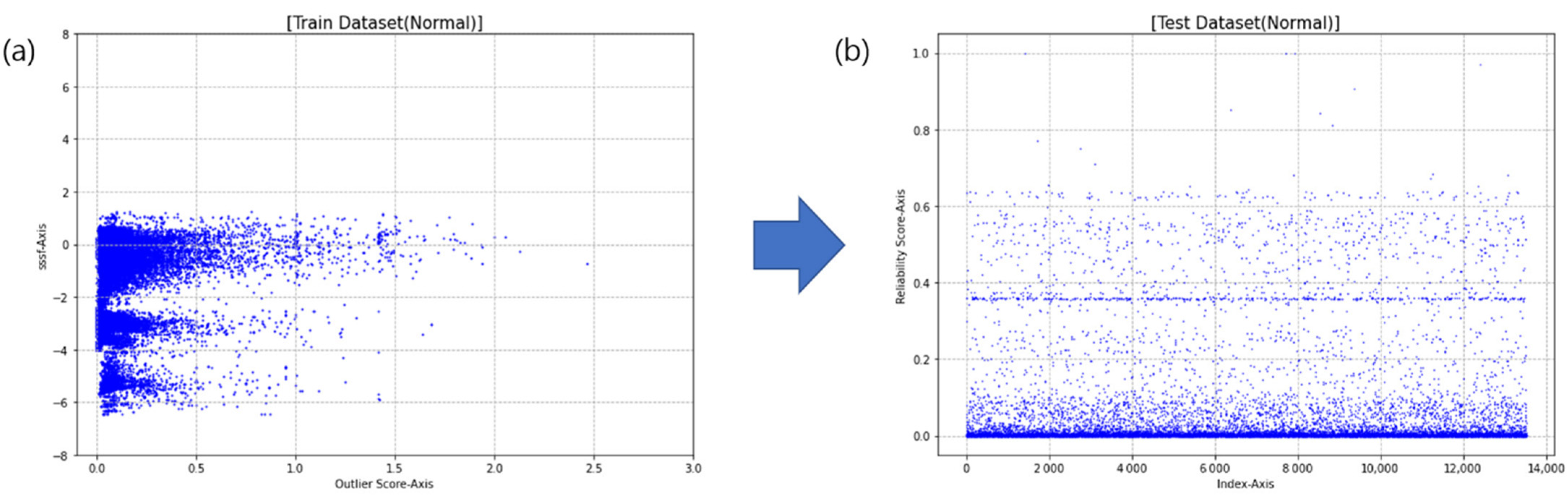
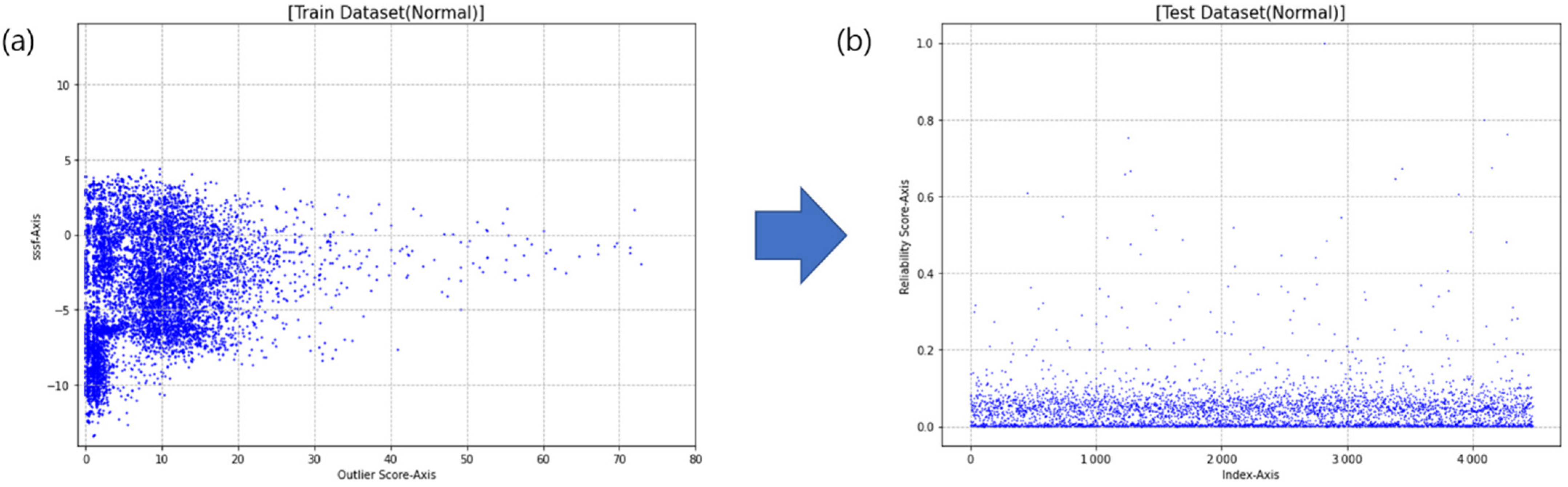
3.3. Reliability Analysis
4. Experimental Results
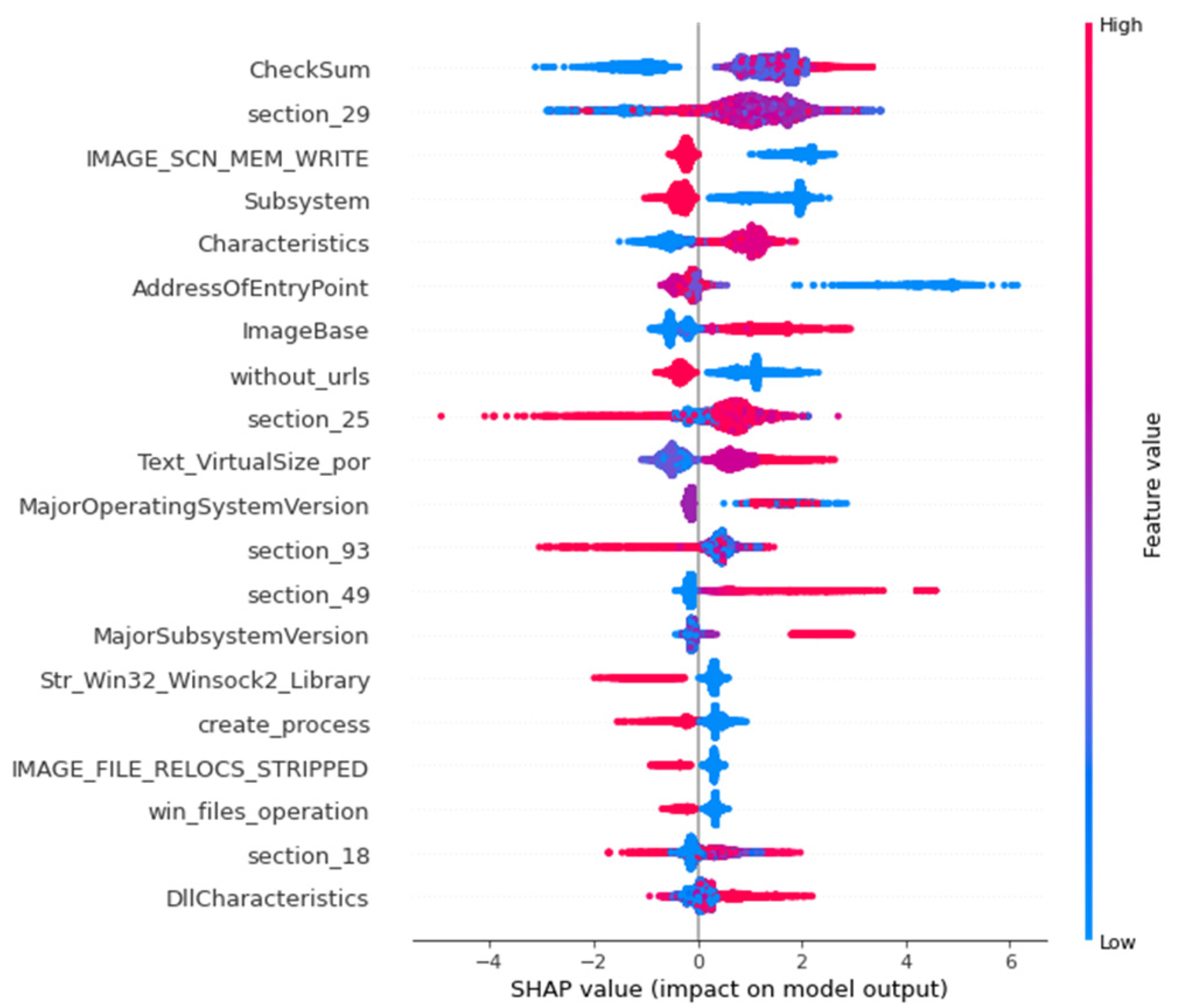
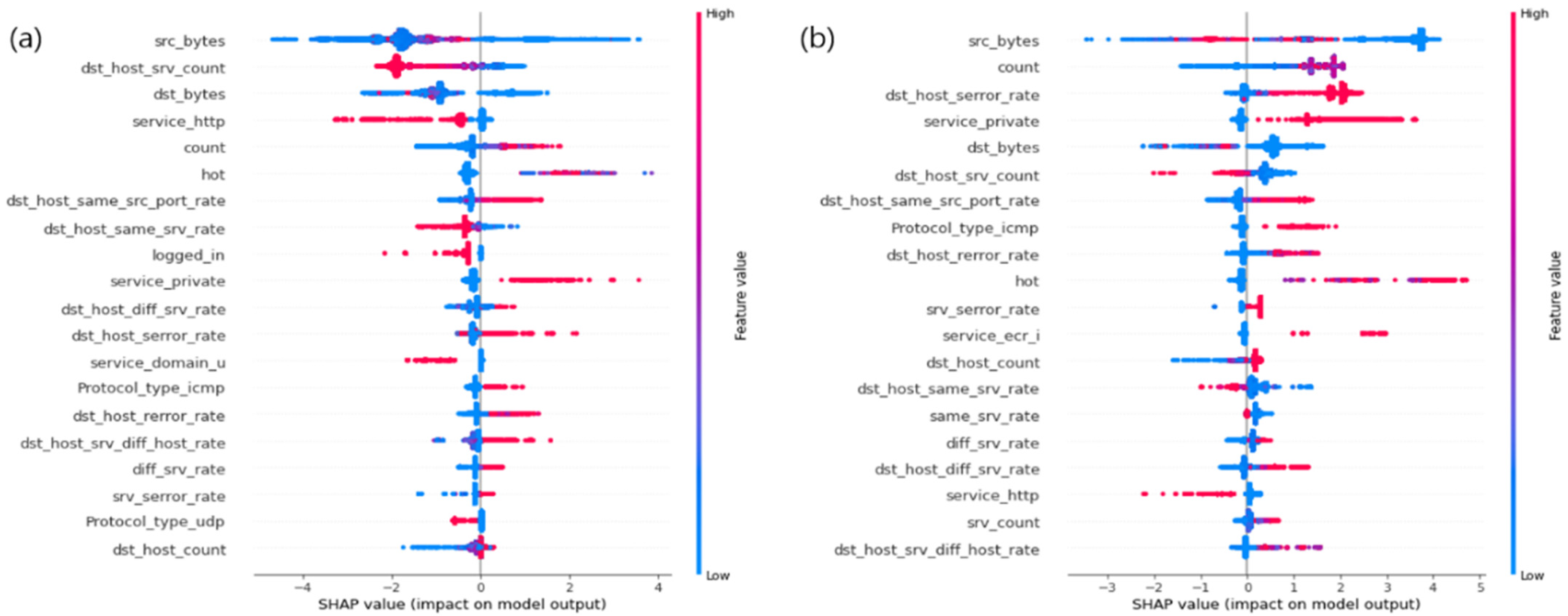
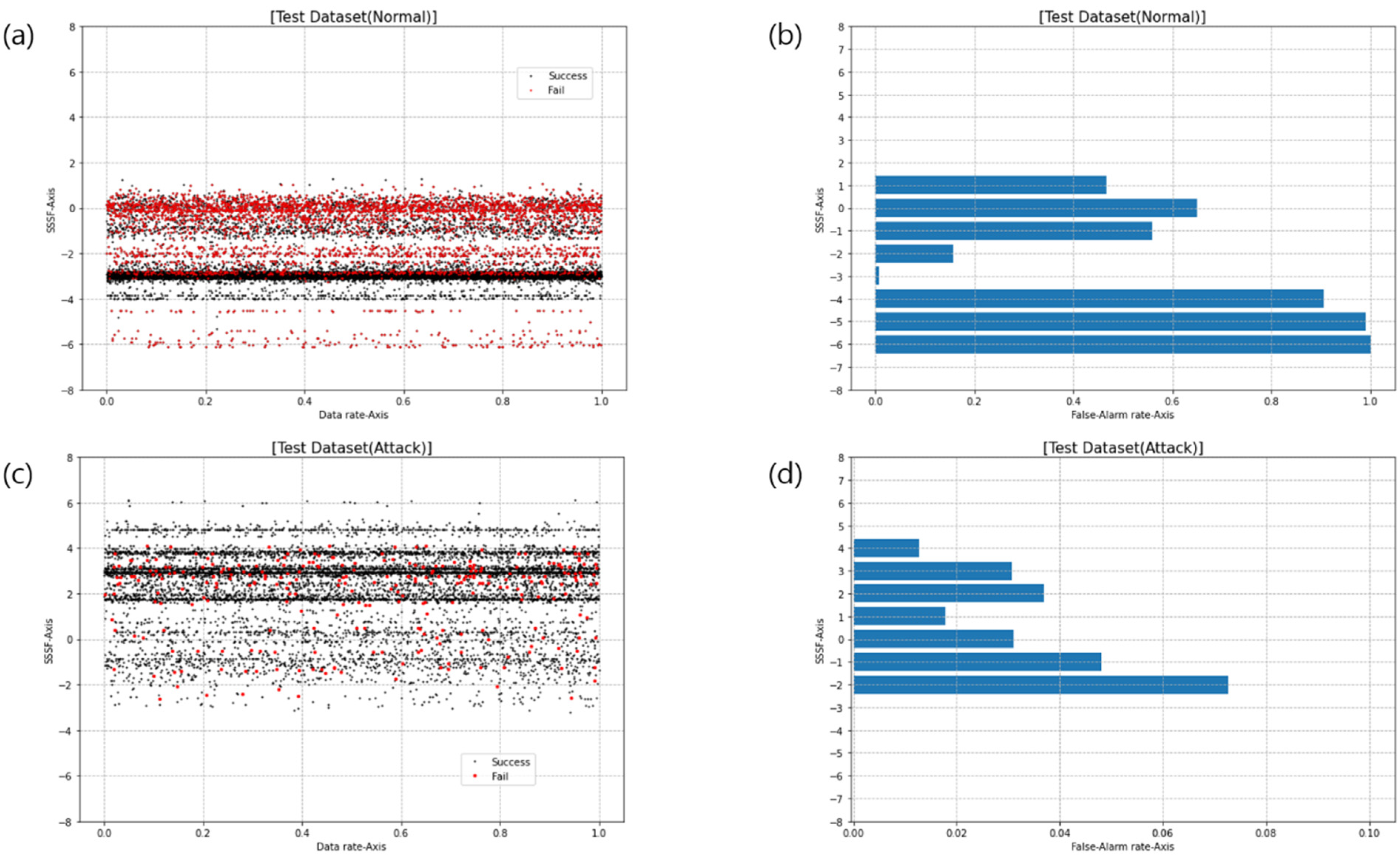
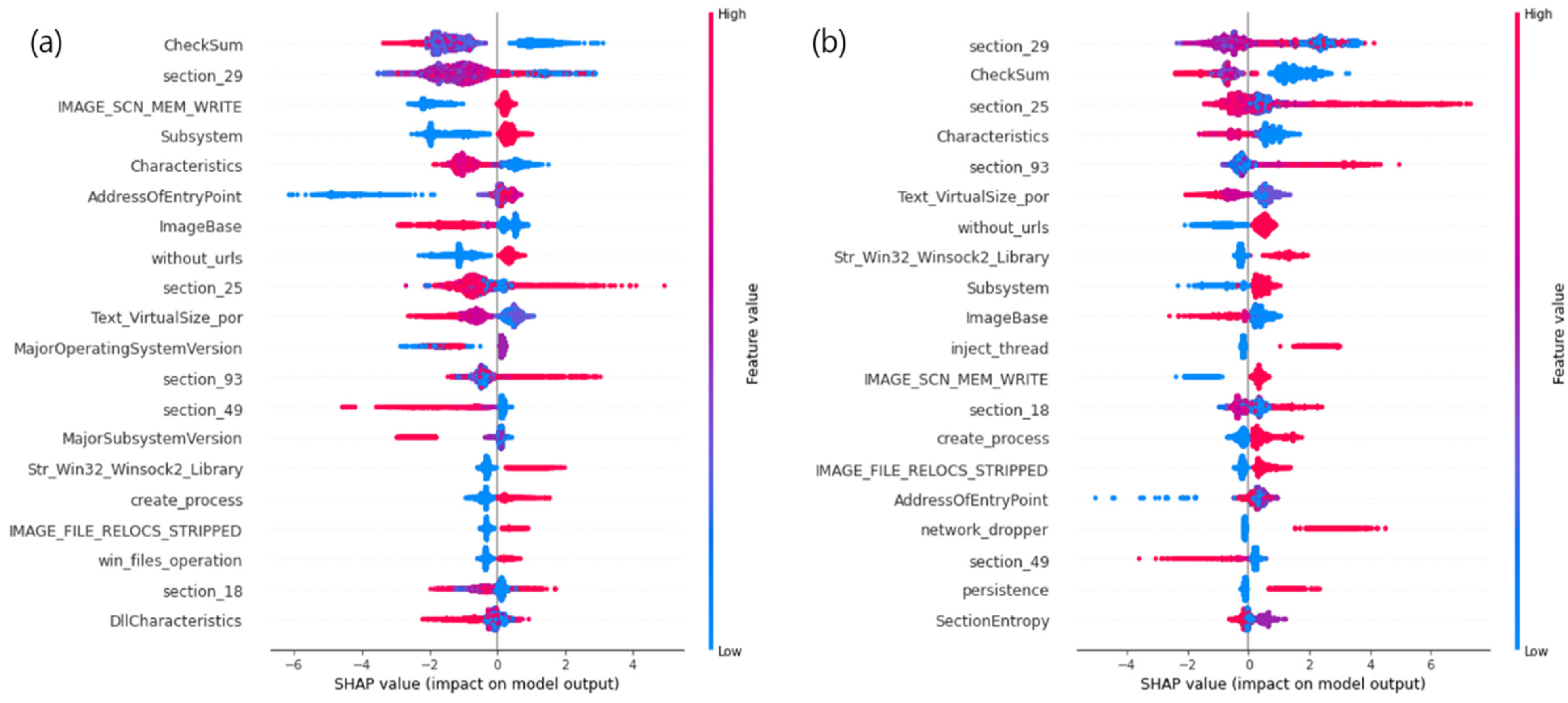
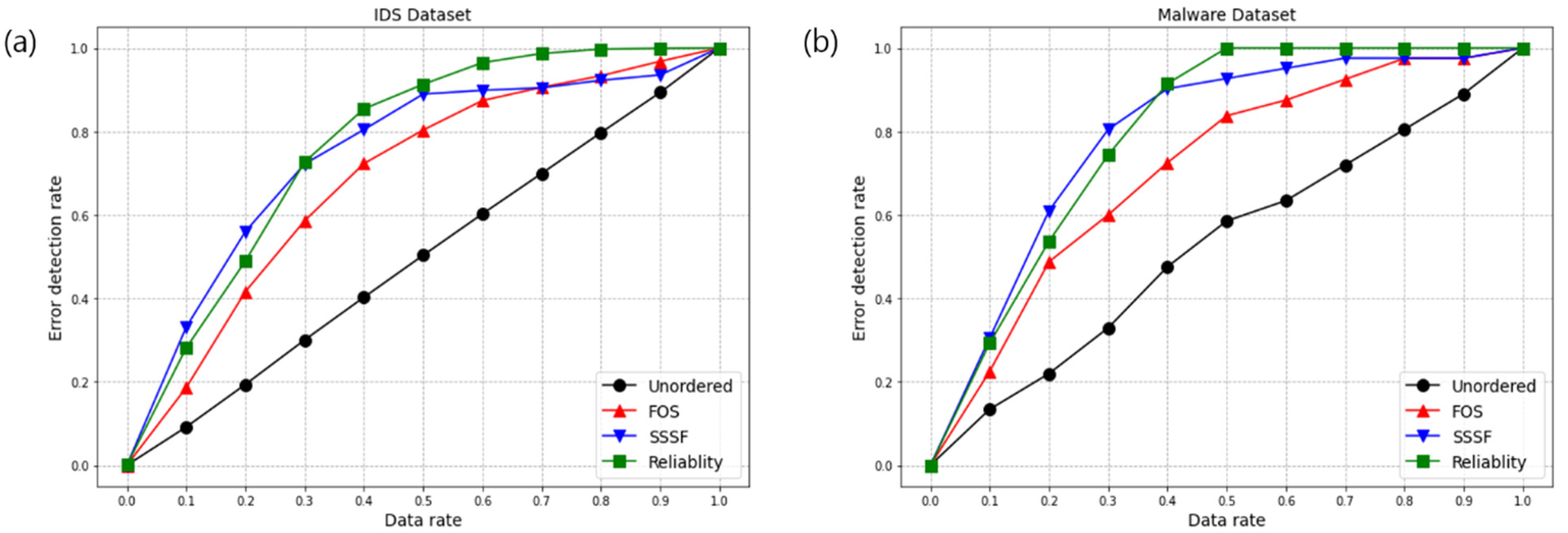
4.1. IDS Dataset Experiment
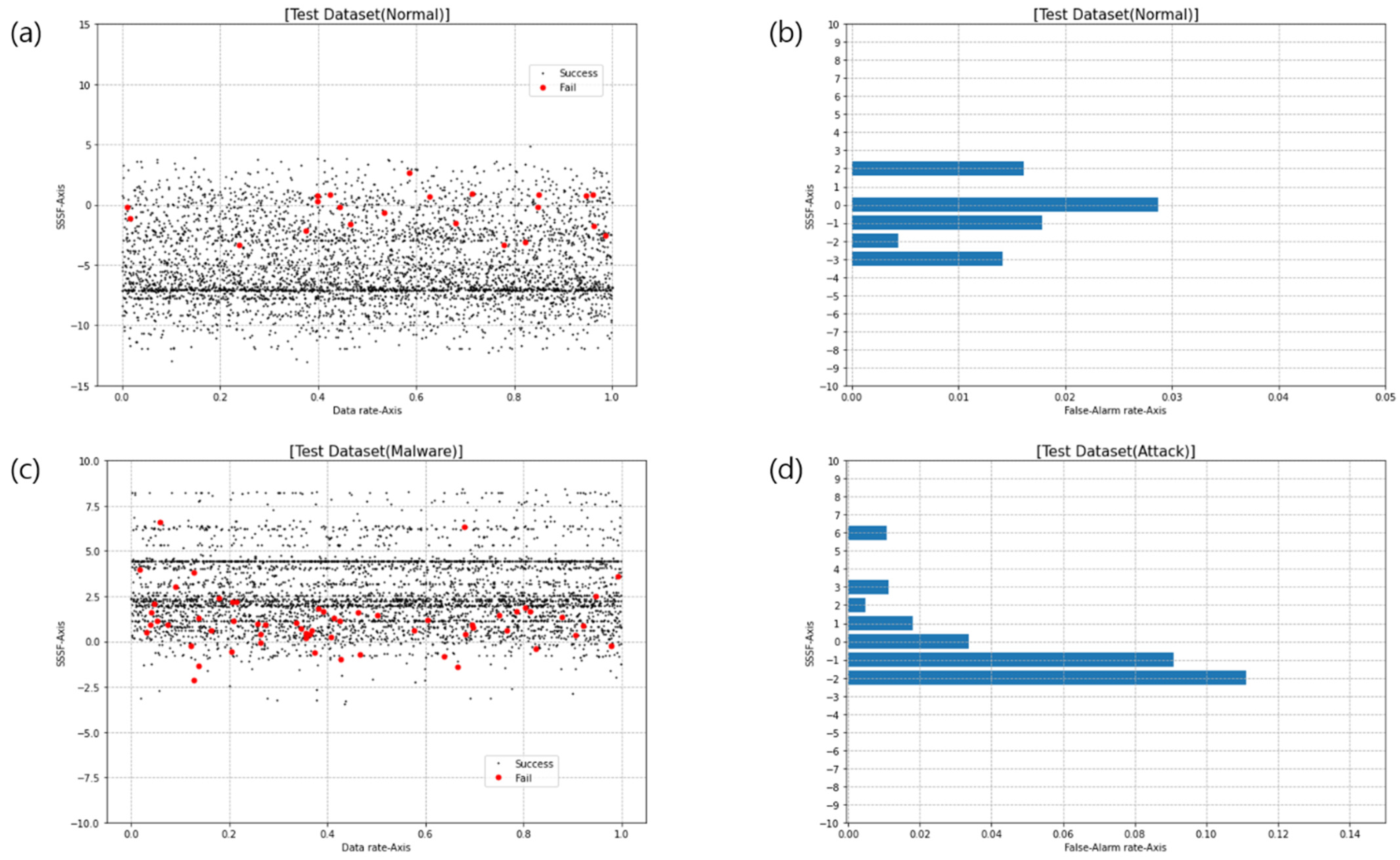
4.2. Malware Dataset Experiment
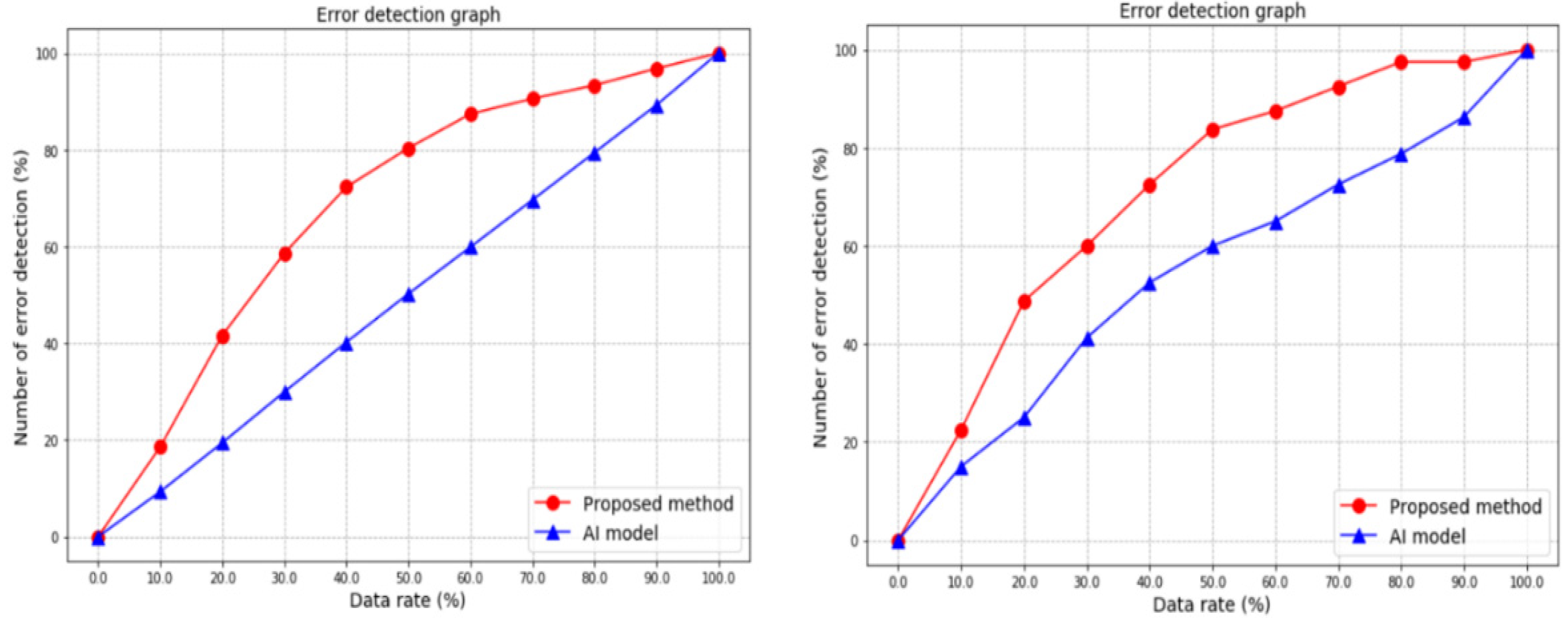
4.3. Comparative Analysis of AI Reliability Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McAfee, Inc. McAfee Labs Threats Report: November 2020, U.S, CA. 2020. Available online: https://www.mcafee.com/enterprise/en-us/assets/reports/rp-quarterly-threats-nov-2020.pdf (accessed on 27 June 2022).
- Check Point Research: Cyber Attacks Increased 50% Year over Year. Available online: https://blog.checkpoint.com/2022/01/10/check-point-research-cyber-attacks-increased-50-year-over-year/ (accessed on 27 June 2022).
- Shapley, L.S. A value for N-person games. In Contributions to the Theory of Games; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, NJ, USA, 1950; Volume I. [Google Scholar]
- Yang, Y.; Tresp, V.; Wunderle, M.; Fasching, P.A. Explaining Therapy Predictions with Layer-Wise Relevance Propagation in Neural Networks. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 152–162. [Google Scholar] [CrossRef]
- Zafar, M.R.; Khan, N.M. DLIME: A deterministic local interpretable model-agnostic explanations approach for computer-aided diagnosis systems. arXiv 2019, arXiv:1906.10263. [Google Scholar] [CrossRef]
- Survey: 27 Percent of IT Professionals Receive More Than 1 Million Security Alerts Daily. Available online: https://www.imperva.com/blog/27-percent-of-it-professionals-receive-more-than-1-million-security-alerts-daily/ (accessed on 27 June 2022).
- Kanimozhi, V.; Jacob, T.P. Artificial Intelligence based Network Intrusion Detection with Hyper-Parameter Optimization Tuning on the Realistic Cyber Dataset CSE-CIC-IDS2018 using Cloud Computing. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 0033–0036. [Google Scholar]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 28–30 May 2013; pp. 113–120. [Google Scholar]
- Venkatraman, S.; Alazab, M.; Vinayakumar, R. A hybrid deep learning image-based analysis for effective malware detection. J. Inf. Secur. Appl. 2019, 47, 377–389. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion Detection System for NSL-KDD Dataset Using Convolutional Neural Networks. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 81–85. [Google Scholar]
- Om, H.; Kundu, A. A hybrid system for reducing the false alarm rate of anomaly intrusion detection system. In Proceedings of the 2012 1st International Conference on Recent Advances in Information Technology(RAIT), Dhanbad, India, 15–17 March 2012; pp. 131–136. [Google Scholar]
- Hubballi, N.; Suryanarayanan, V. False alarm minimization techniques in signature-based intrusion detection systems: A survey. Comput. Commun. 2014, 49, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Spathoulas, G.P.; Katsikas, S.K. Reducing false positives in intrusion detection systems. Comput. Secur. 2010, 29, 35–44. [Google Scholar] [CrossRef]
- Suman, R.R.; Mall, R.; Sukumaran, S.; Satpathy, M. Extracting State Models for Black-Box Software Components. J. Object Technol. 2010, 9, 79–103. [Google Scholar] [CrossRef]
- Amarasinghe, K.; Manic, M. Improving User Trust on Deep Neural Networks Based Intrusion Detection Systems. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3262–3268. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. Assoc. Comput. Mach. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Arrieta, A.B.; Díaz-Rodríguez, N.; del Sera, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Arya, V.; Bellamy, R.K.E.; Chen, P.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilovi, A. AI Explainability 360: An Extensible Toolkit for Understanding Data and Machine Learning Models. J. Mach. Learn. Res. 2020, 21, 1–6. [Google Scholar]
- Wexler, J.; Pushkarna, M.; Bolukbasi, T.; Wattenberg, M.; Viégas, F.; Wilson, J. The What-If Tool: Interactive Probing of Machine Learning Models. IEEE Trans. Vis. Comput. Graph. 2020, 26, 56–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Páez, A. The Pragmatic Turn in Explainable Artificial Intelligence (XAI). Minds Mach. 2019, 29, 441–459. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D.; Aha, D. DARPA’s explainable artificial intelligence (XAI) program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Movahedi, A.; Derrible, S. Interrelated Patterns of Electricity, Gas, and Water Consumption in Large-Scale Buildings. engrXiv, 2020; under review. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An explainable machine learning framework for intrusion detection systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Kim, H.; Lee, Y.; Lee, E.; Lee, T. Cost-Effective Valuable Data Detection Based on the Reliability of Artificial Intelligence. IEEE Access 2021, 9, 108959–108974. [Google Scholar] [CrossRef]
- NSL-KDD. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 27 June 2022).
- 2019 KISA Data Challenge Dataset. Available online: http://datachallenge.kr/challenge19/rd-datachallenge/malware/introduction/ (accessed on 27 June 2022).
- YARA Rules. Available online: https://github.com/InQuest/awesome-yara (accessed on 27 June 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total No. of Instances | |||||
|---|---|---|---|---|---|---|
| Instance | Normal | DoS | Probe | U2R | R2L | |
| Train | 125,973 | 67,343 | 45,927 | 11,656 | 52 | 995 |
| Test | 22,544 | 9711 | 7460 | 2421 | 67 | 2885 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Booster | Gbtree | Subsample | 1 |
| Objective | Binary:logistic | Colsample_bytree | 1 |
| Max_depth | 4 | Learning_rate | 0.1 |
| Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|
| 0.8064 | 0.8523 | 0.8064 | 0.8055 |
| Dataset | Total No. of Instance | ||
|---|---|---|---|
| Instance | Normal | Malware | |
| Train | 29,130 | 11,568 | 17,562 |
| Test | 9301 | 4518 | 4513 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Boosting_type | gbdt | Learning_rate | 0.08 |
| Objective | binary | Feature_fraction | 0.9 |
| Metric | Auc | Bagging_fraction | 0.8 |
| Is_training_metric | True | Bagging_freq | 5 |
| Num_leaves | 31 | verbose | 1 |
| Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|
| 0.9909 | 0.9910 | 0.9909 | 0.9909 |
| Dataset | Data Rate | FOS | Reliability Score (Compared with FOS) | SSSF (Compared with FOS) |
|---|---|---|---|---|
| IDS Dataset | 10% | 103% | 207% (51%) | 262% (78%) |
| 20% | 115% | 153% (18%) | 189% (35%) | |
| 30% | 95% | 142% (24%) | 140% (23%) | |
| 40% | 80% | 112% (18%) | 100% (11%) | |
| Malware Dataset | 10% | 68% | 118% (30%) | 127% (36%) |
| 20% | 122% | 144% (10%) | 178% (25%) | |
| 30% | 82% | 126% (24%) | 144% (34%) | |
| 40% | 52% | 92% (26%) | 90% (24%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, E.; Lee, Y.; Lee, T. Automatic False Alarm Detection Based on XAI and Reliability Analysis. Appl. Sci. 2022, 12, 6761. https://doi.org/10.3390/app12136761
Lee E, Lee Y, Lee T. Automatic False Alarm Detection Based on XAI and Reliability Analysis. Applied Sciences. 2022; 12(13):6761. https://doi.org/10.3390/app12136761
Chicago/Turabian StyleLee, Eungyu, Yongsoo Lee, and Teajin Lee. 2022. "Automatic False Alarm Detection Based on XAI and Reliability Analysis" Applied Sciences 12, no. 13: 6761. https://doi.org/10.3390/app12136761
APA StyleLee, E., Lee, Y., & Lee, T. (2022). Automatic False Alarm Detection Based on XAI and Reliability Analysis. Applied Sciences, 12(13), 6761. https://doi.org/10.3390/app12136761