
Real-Time Object Tracking Algorithm Based on Siamese Network


Abstract
:1. Introduction
- (1)
- This study puts forward an optical flow pyramid Siamese network, which is able to enhance the character representation as well as tracking precision.
- (2)
- This paper trains the end-to-end feature pyramid optical flow network, which makes it better solve the occlusion problem of the objective.
- (3)
- Experiments on OTB2015 and VOT2016 reveal that compared to the current state-of-the-art approaches, the approach which is put forward possesses better performance.
2. Related Work
2.1. Deep Feature-Based Tracking
2.2. Siamese Network-Based Tracking
2.3. Optical Flow for Visual Tasks
3. Methodology
- (a)
- Feature pyramid extractor [25]. Given two input images I1 and I2, we generate L-level pyramids of feature representations, with the bottom (zeroth) level being the input images, i.e., . To generate feature representation at the lth layer, , we use layers of convolutional filters to downsample the features at the (l−1)th pyramid level, , by a factor of 2.
- (b)
- Optical flow network. The first and second frame images are used as the existing tracking frame and the prior frame to enter the optical flow estimation network to assess the approximate position of the target in the next frame. Then, the center of the search area is cropped in accordance with the assessed position with the intention of obtaining a more precise search area.
- (c)
- Siamese network. Input template image and search image into convolutional neural network to generate template feature map and search feature map.
- (d)
- Attention network. Template features and search features obtain new template features and search features through spatial and channel attention mechanism networks, respectively, and the new features perform cross-correlation operations to obtain response graphs.
3.1. Fully Convolutional Siamese Network
3.2. End-to-End Feature Pyramid Network
3.3. Attention Network
4. Experiments
4.1. Implementation Details
4.2. Ablation Experiments
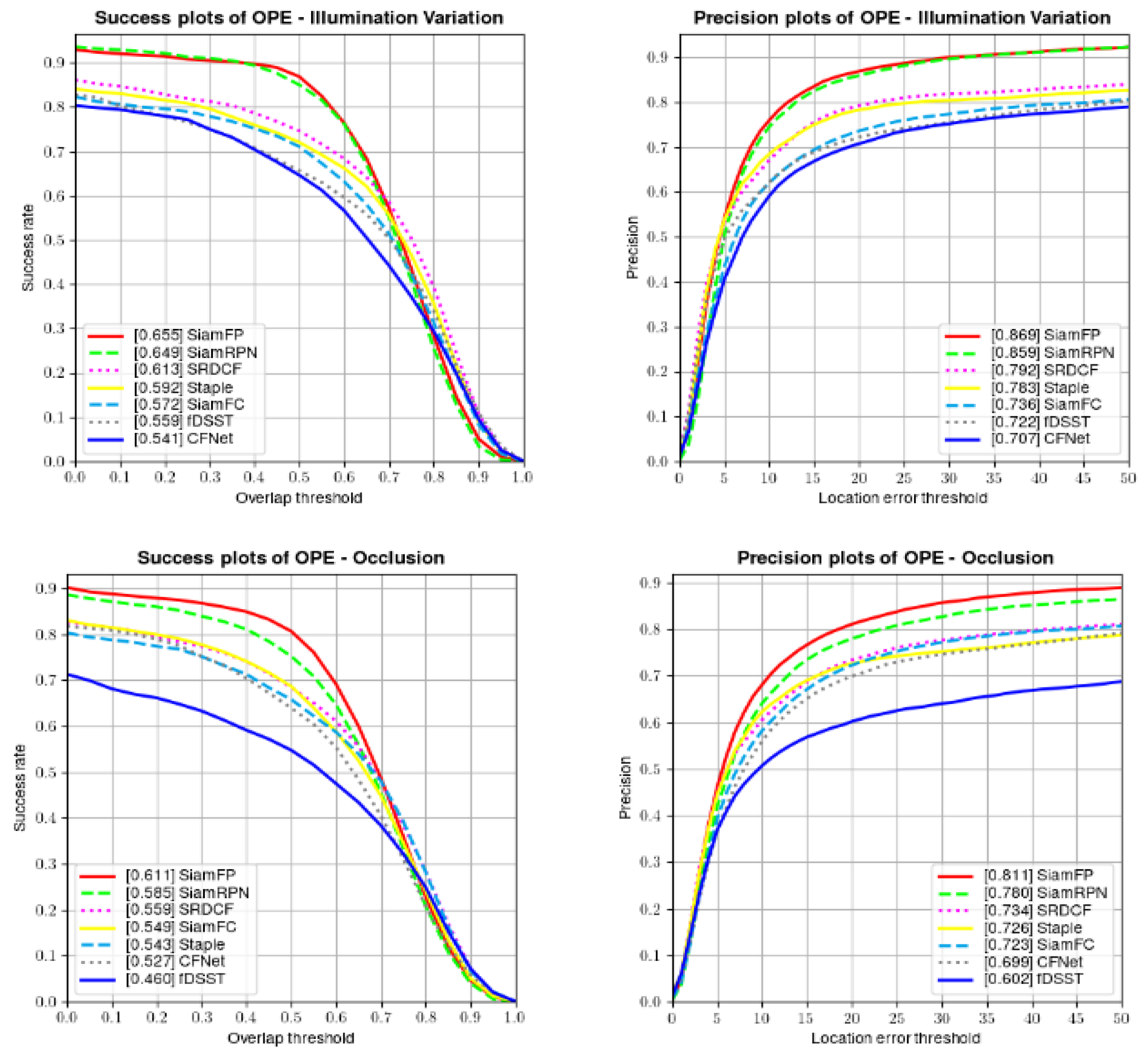
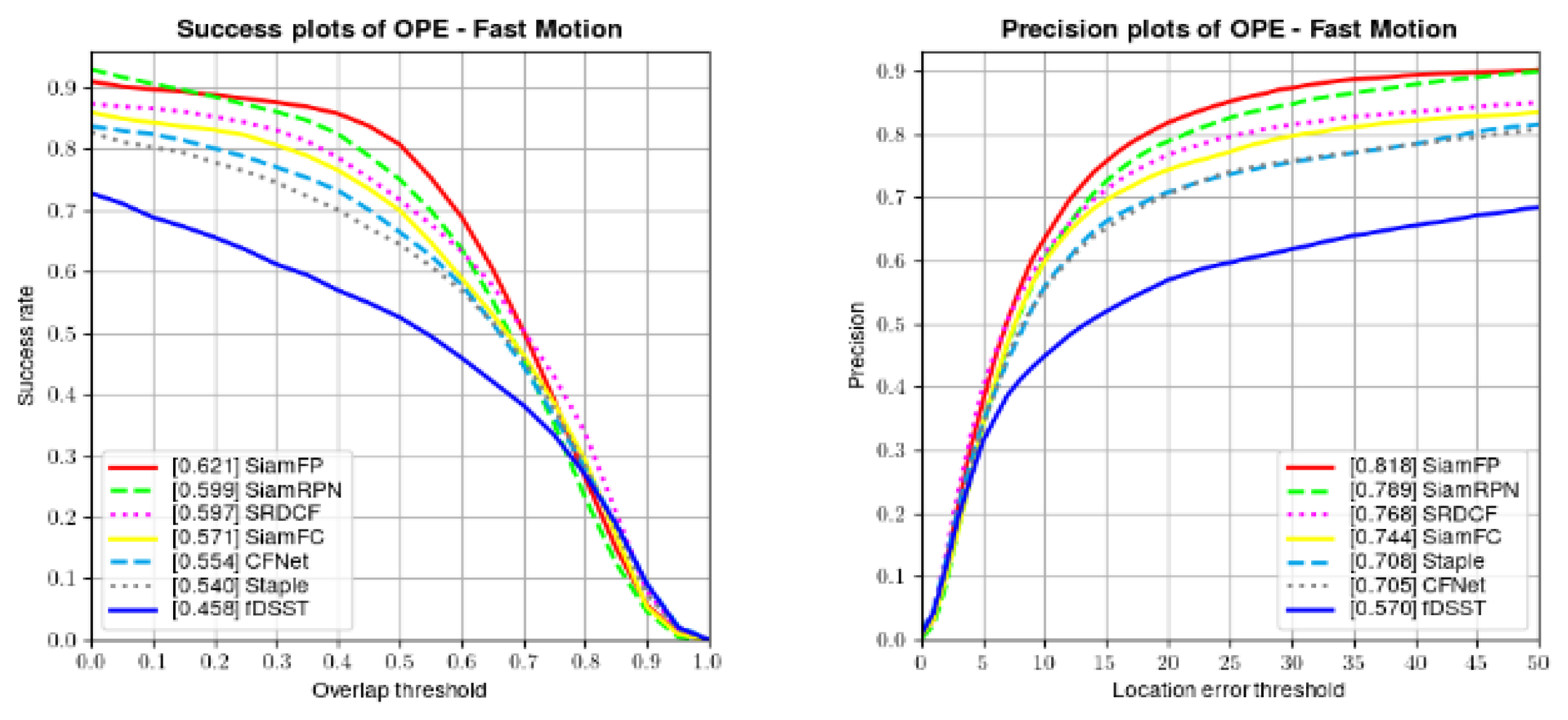
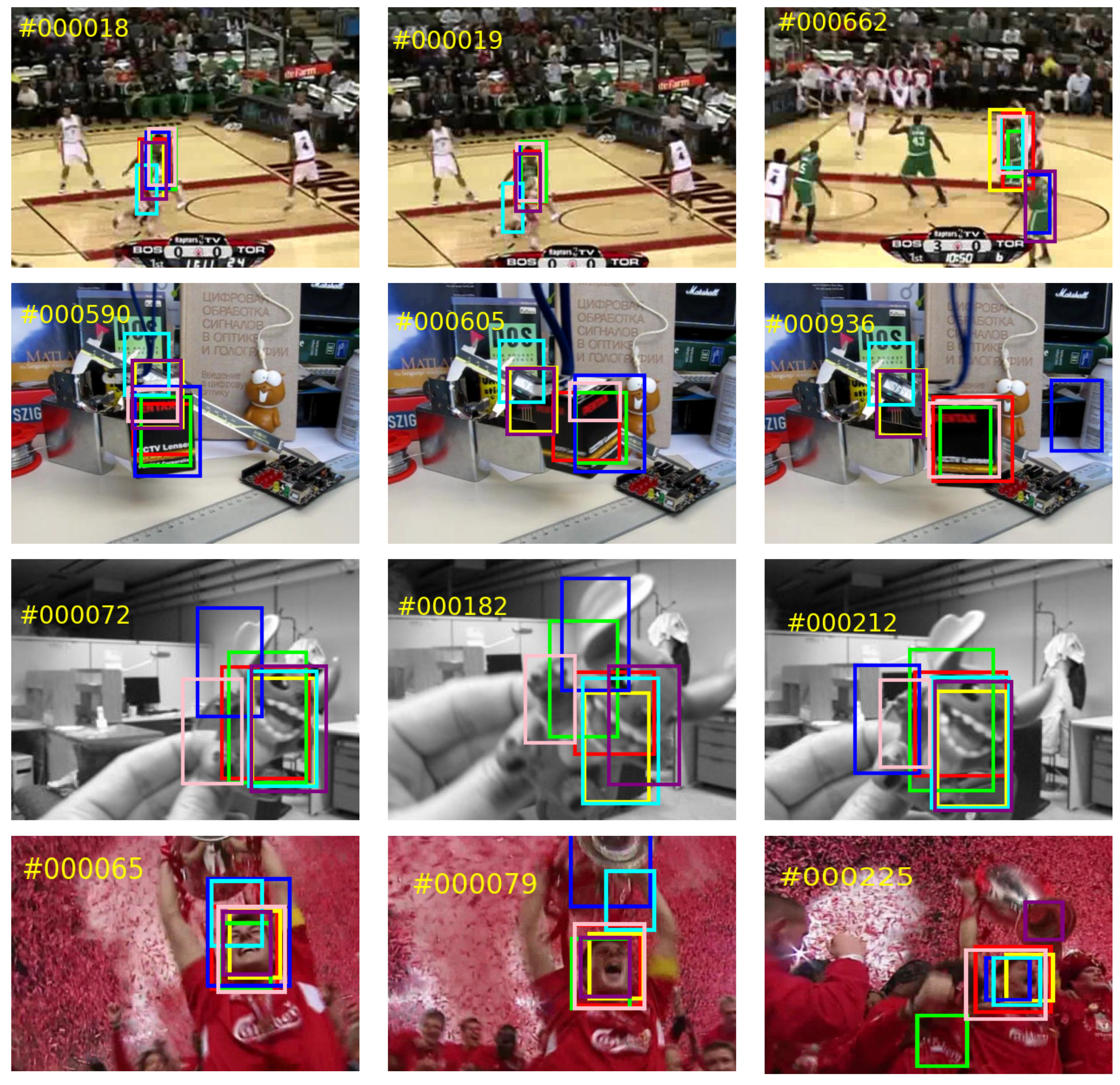
4.3. State-of-the-Art Comparison
4.3.1. Results on OTB
4.3.2. Results on VOT
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shen, Y.; Lin, W.; Wang, Z.; Li, J.; Sun, X.; Wu, X.; Wang, S.; Huang, F. Rapid Detection of Camouflaged Artificial Target Based on Polarization Imaging and Deep Learning. IEEE Photonics J. 2021, 13, 1–9. [Google Scholar] [CrossRef]
- Nama, M.K.; Nath, A.; Bechra, N.; Bhatia, J.; Tanwar, S.; Chaturvedi, M.; Sadoun, B. Machine learning-based traffic scheduling techniques for intelligent transportation system: Opportunities and challenges. Int. J. Commun. Syst. 2021, 34, e4814. [Google Scholar] [CrossRef]
- Coccoli, M.; Francesco, V.D.; Fusco, A.; Maresca, P. A cloud-based cognitive computing solution with interoperable applications to counteract illegal dumping in smart cities. Multimed. Tools Appl. 2022, 81, 95–113. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese Instance Search for Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by Tracking: Siamese CNN for Robust Target Association. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 418–425. [Google Scholar]
- Gladh, S.; Danelljan, M.; Khan, F.S.; Felsberg, M. Deep motion features for visual tracking. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 1243–1248. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Dai, K.; Wang, D.; Lu, H.; Sun, C.; Li, J. Visual Tracking via Adaptive Spatially-Regularized Correlation Filters. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4665–4674. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7-9 July 2015. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to Track at 100 FPS with Deep Regression Networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A.K. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3039–3048. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Ye, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. arXiv 2020, arXiv:1911.06188. [Google Scholar] [CrossRef]
- Wang, T.; Qiao, M.; Zhang, M.; Yang, Y.; Snoussi, H. Data-driven prognostic method based on self-supervised learning approaches for fault detection. J. Intell. Manuf. 2020, 31, 1611–1619. [Google Scholar] [CrossRef]
- Gao, P.; Ma, Y.; Yuan, R.; Xiao, L.; Wang, F. Siamese Attentional Keypoint Network for High Performance Visual Tracking. arXiv 2020, arXiv:1904.10128. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. arXiv 2018, arXiv:1804.00175. [Google Scholar]
- Piga, N.A.; Onyshchuk, Y.; Pasquale, G.; Pattacini, U.; Natale, L. ROFT: Real-Time Optical Flow-Aided 6D Object Pose and Velocity Tracking. IEEE Robot. Autom. Lett. 2022, 7, 159–166. [Google Scholar] [CrossRef]
- Zhu, Z.; Wu, W.; Zou, W.; Yan, J. End-to-End Flow Correlation Tracking with Spatial-Temporal Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 548–557. [Google Scholar]
- Zhou, L.; Yao, X.; Zhang, J. Accurate Positioning Siamese Network for Real-Time Object Tracking. IEEE Access 2019, 7, 84209–84216. [Google Scholar] [CrossRef]
- Chen, E.; Haik, O.; Yitzhaky, Y. Online Spatio-Temporal Action Detection in Long-Distance Imaging Affected by the Atmosphere. IEEE Access 2021, 9, 24531–24545. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.-Y.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar]
- Talwar, A.; Huys, Q.J.M.; Cormack, F.K.; Roiser, J.P. A Hierarchical Reinforcement Learning Model Explains Individual Differences in Attentional Set Shifting. bioRxiv 2021. [Google Scholar] [CrossRef]
- Womelsdorf, T.; Watson, M.; Tiesinga, P.H.E. Learning at Variable Attentional Load Requires Cooperation of Working Memory, Meta-learning, and Attention-augmented Reinforcement Learning. J. Cogn. Neurosci. 2021, 34, 79–107. [Google Scholar] [CrossRef] [PubMed]
- Bera, A.; Wharton, Z.; Liu, Y.; Bessis, N.; Behera, A. Attend and Guide (AG-Net): A Keypoints-Driven Attention-Based Deep Network for Image Recognition. IEEE Trans. Image Process. 2021, 30, 3691–3704. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wen, G.; Hu, Y.; Luo, M.; Dai, D.; Zhuang, Y.; Hall, W. Multiple Attentional Pyramid Networks for Chinese Herbal Recognition. Pattern Recognit. 2021, 110, 107558. [Google Scholar] [CrossRef]
- Lee, W.; Seong, J.J.; Ozlu, B.; Shim, B.S.; Marakhimov, A.; Lee, S. Biosignal Sensors and Deep Learning-Based Speech Recognition: A Review. Sensors 2021, 21, 1399. [Google Scholar] [CrossRef]
- Xiwen, Y. Design of Voice Recognition Acoustic Compression System Based on Neural Network. Wirel. Pers. Commun. 2021. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7464–7473. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Online Object Tracking: A Benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary Learners for Real-Time Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.P.; Cehovin, L.; Vojír, T.; Häger, G.; Lukežič, A.; Fernandez, G.J.; et al. The Visual Object Tracking VOT2016 Challenge Results. In Computer Vision—ECCV 2016 Workshops. ECCV 2016. Lecture Notes in Computer Science; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | OTB50 | OTB2015 | ||
|---|---|---|---|---|
| Success | Precision | Success | Precision | |
| baseline | 0.519 | 0.693 | 0.586 | 0.772 |
| +PW | 0.552 | 0.764 | 0.620 | 0.835 |
| +PW+FP | 0.577 | 0.781 | 0.634 | 0.857 |
| +PW+FP+Att | 0.604 | 0.829 | 0.658 | 0.880 |
| Tracker | OTB50 | OTB2015 | FPS | ||
|---|---|---|---|---|---|
| Success | Precision | Success | Precision | ||
| SiamFP | 0.604 0.829 | 0.829 0.829 | 0.658 0.829 | 0.880 0.829 | 50 0.829 |
| SiamRPN | 0.583 0.806 | 0.806 0.806 | 0.629 0.806 | 0.847 0.806 | 160 |
| SRDCF | 0.539 0.731 | 0.731 0.731 | 0.598 0.731 | 0.789 0.731 | 5 0.731 |
| CFNet | 0.535 0.724 | 0.724 0.724 | 0.587 0.724 | 0.783 0.724 | 75 |
| SiamFC | 0.519 0.693 | 0.693 0.693 | 0.586 0.693 | 0.778 0.693 | 86 |
| Staple | 0.506 0.683 | 0.683 0.683 | 0.578 0.683 | 0.772 0.683 | 80 |
| fDSST | 0.460 0.616 | 0.616 0.616 | 0.517 0.616 | 0.686 0.616 | 55 |
| Tracker | EAO | Accuracy | Robustness | FPS |
|---|---|---|---|---|
| SiamFP | 0.335 | 0.537 | 0.318 | 50 |
| CCOT | 0.331 | 0.529 | 0.238 | 0.3 |
| TCNN | 0.332 | 0.532 | 0.268 | 1.5 |
| SSAT | 0.321 | 0.534 | 0.496 | <25 |
| MLDF | 0.301 | 0.489 | 0.574 | <25 |
| Staple | 0.294 | 0.527 | 0.688 | 80 |
| DDC | 0.287 | 0.458 | 0.378 | 5 |
| EBT | 0.277 | 0.531 | 0.752 | >25 |
| SRBT | 0.258 | 0.528 | 0.900 | <25 |
| STAPLEp | 0.236 | 0.526 | 0.786 | 86 |
| DTN | 0.151 | 0.461 | 0.773 | >25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Deng, M.; Cheng, C.; Zhang, D. Real-Time Object Tracking Algorithm Based on Siamese Network. Appl. Sci. 2022, 12, 7338. https://doi.org/10.3390/app12147338
Zhao W, Deng M, Cheng C, Zhang D. Real-Time Object Tracking Algorithm Based on Siamese Network. Applied Sciences. 2022; 12(14):7338. https://doi.org/10.3390/app12147338
Chicago/Turabian StyleZhao, Wenjun, Miaolei Deng, Cong Cheng, and Dexian Zhang. 2022. "Real-Time Object Tracking Algorithm Based on Siamese Network" Applied Sciences 12, no. 14: 7338. https://doi.org/10.3390/app12147338
APA StyleZhao, W., Deng, M., Cheng, C., & Zhang, D. (2022). Real-Time Object Tracking Algorithm Based on Siamese Network. Applied Sciences, 12(14), 7338. https://doi.org/10.3390/app12147338