
Deep Neural Network-Based Prediction and Early Warning of Student Grades and Recommendations for Similar Learning Approaches


Abstract
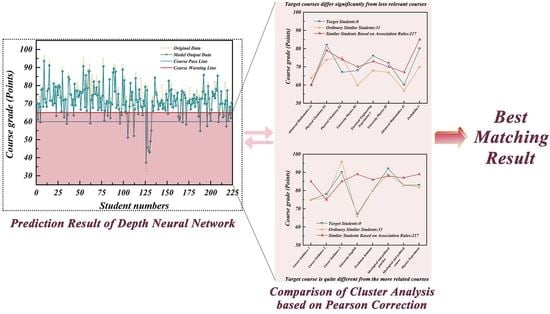
:
1. Introduction
2. Research Actuality
3. Dataset
3.1. Data Sources
3.2. Data Pre-Processing
- (1)
- Data integration. The data obtained from the school’s educational administration system is a single piece of score data containing several attributes of the course, which is first stored in the MySQL server of the student integrated management system independently developed by the college, and the current 21,350 scores are integrated and exported to the table using database statements.
- (2)
- Data cleaning. Data cleaning refers to screening and reviewing the original data, as well as addressing the inconsistency of data, missing data, wrong data, and duplicate data. It should be considered that as the training scheme evolves, the curriculum system in different grades will change, and some courses will be replaced or deleted from the perspective of professional personnel.
- (3)
- Data conversion and processing. Using the Python Pandas framework, the String type is converted to the double type, and the excellent (A), good (B), moderate (C), pass (D), and fail (E) types are converted to numerical values of 95, 85, 75, 65, and 55, respectively. Then, missed exams are converted to 0 points, and the missing values are converted into the average of the student’s average score and the average score of the course using the horizontal and vertical categories for the student’s grade data below 10 points. The mask and number start with student number 0.
- (4)
- Training data division. After the cleaned data are randomly disrupted, the original data are randomly divided into a training set and a verification set in a 3:1 ratio. The training set is used to train the DNN model, and the verification set is used to test the generalisation ability of the model after each iteration to prevent overfitting.
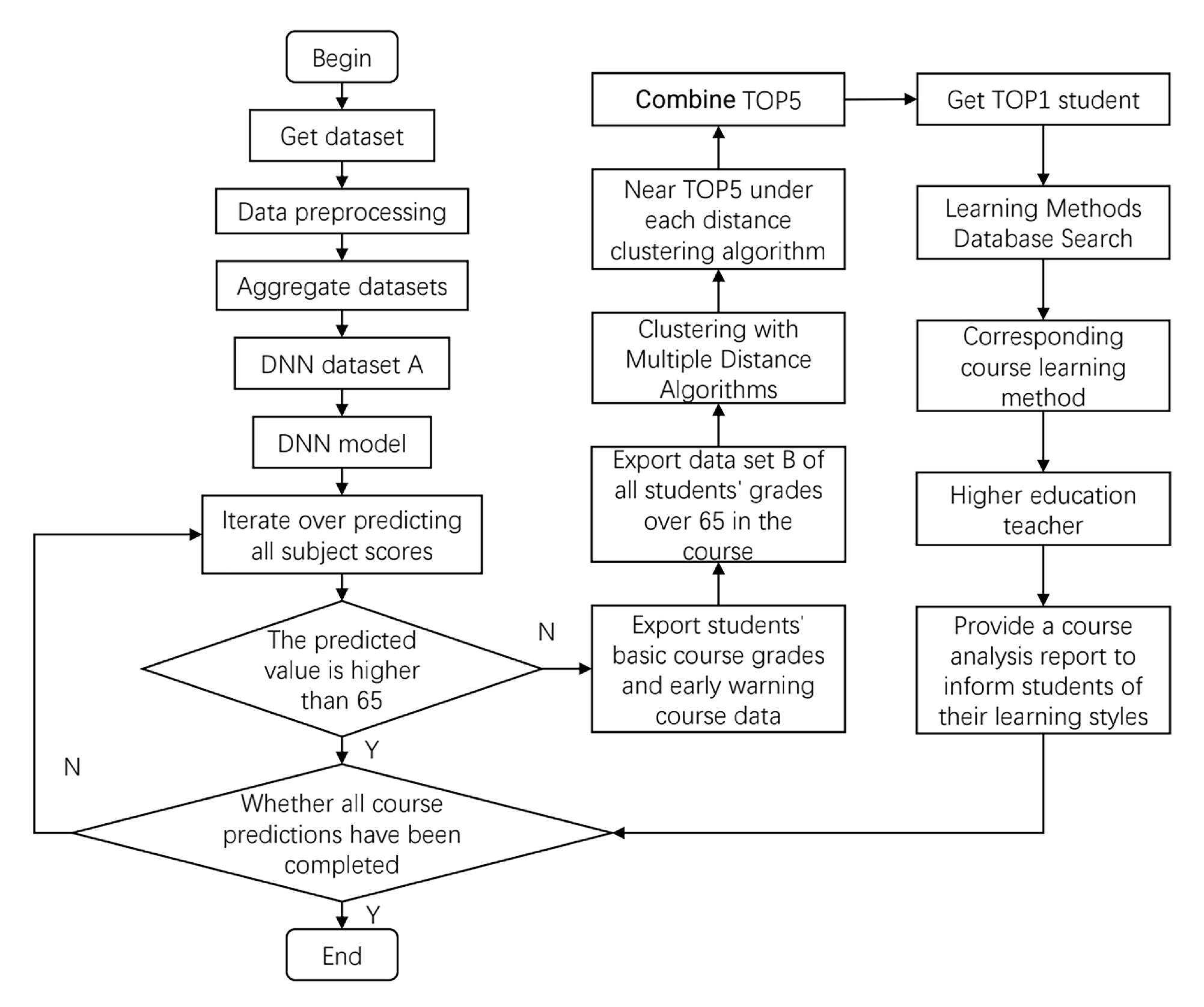
4. Grade Prediction Method Based on DNNs
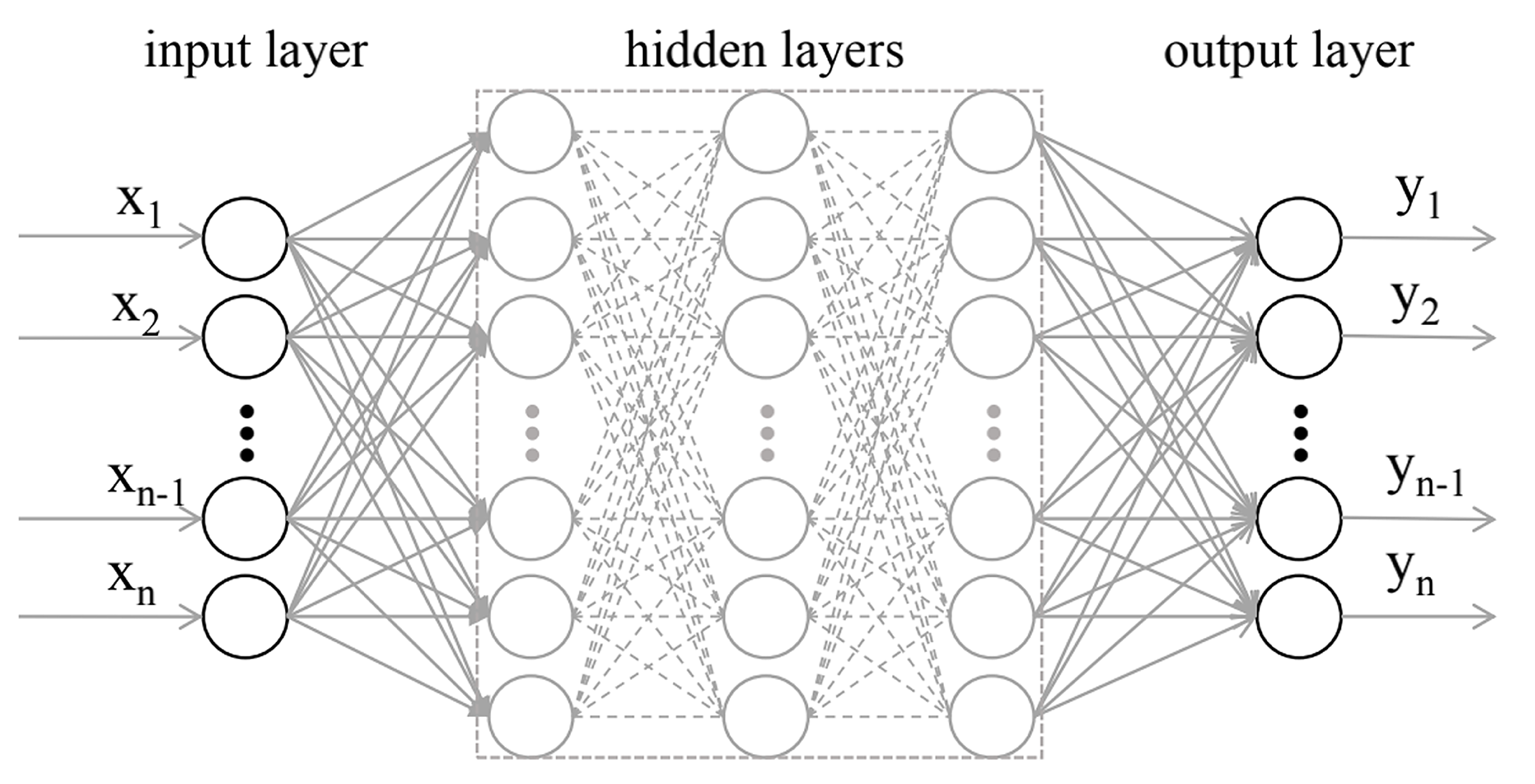
4.1. Introduction of DNN Algorithm
4.2. Grade Prediction Based on the DNN
| Algorithm 1 The Pseudocode of DNN Algorithm |
| Input: ‘data set’: the training set, validation set, test set; |
| 1: ‘epochs’: the maximum number of iterations; |
| 2: ‘batch size’: the minimum batch size of the data loader; |
| 3: ‘optimizer’: the optimisation algorithm (optimiser in torch.optim); |
| 4: ‘optim hparas’: the learning rate, momentum, regularisation factor; |
| 5: ‘early stop’: the number of epochs since the model was last improved; |
| 6: ‘save path’: the model will be saved here; |
| Output: The trained deep neural network model; |
| 7: initialize the parameters according to the input; |
| 8: data normalisation; |
| 9: create a network; |
| 10: train the network: |
| 11: repeat |
| 12: repeat for training process: |
| 13: forward-propagation; |
| 14: back-propagation; |
| 15: until for reaches the end condition |
| 16: Using the network; |
| 17: The data are reversely normalized; |
4.3. Comparative Experiment Based on LR
5. Most Similar Sample Recommendation Model Based on the Pearson Correlation Coefficient and Distance Proximity Algorithm
5.1. Pearson Correlation Coefficient, Definitions of Distance and Thought on the KNN Algorithm
5.1.1. Pearson Correlation Coefficients
5.1.2. Euclidean Distance
5.1.3. Manhattan Distance
5.1.4. Chebyshev Distance
5.1.5. KNN Algorithm
5.2. Most Similar Sample Recommendation Model Based on the Distance Proximity Algorithm Improved with the Pearson Correlation Coefficient
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, H. Big data development of tourism resources based on 5G network and internet of things system. Microprocess. Microsyst. 2021, 80, 103567. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. ACM Sigmod Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Kumar, S.; Mohbey, K.K. A review on big data based parallel and distributed approaches of pattern mining. J. King Saud-Univ.-Comput. Inf. Sci. 2019, 34, 1639–1662. [Google Scholar] [CrossRef]
- Hicham, A.; Jeghal, A.; Sabri, A.; Tairi, H. A survey on educational data mining [2014–2019]. In Proceedings of the 2020 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 9–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Crivei, L.M.; Czibula, G.; Ciubotariu, G.; Dindelegan, M. Unsupervised learning based mining of academic data sets for students’ performance analysis. In Proceedings of the 2020 IEEE 14th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 21–23 May 2020; pp. 000011–000016. [Google Scholar] [CrossRef]
- Figueroa-Cañas, J.; Sancho-Vinuesa, T. Early prediction of dropout and final exam performance in an online statistics course. IEEE Rev. Iberoam. Tecnol. Del Aprendiz. 2020, 15, 86–94. [Google Scholar] [CrossRef]
- Akour, I.; Alshurideh, M.; Al Kurdi, B.; Al Ali, A.; Salloum, S. Using machine learning algorithms to predict people’s intention to use mobile learning platforms during the COVID-19 pandemic: Machine learning approach. JMIR Med. Educ. 2021, 7, e24032. [Google Scholar] [CrossRef] [PubMed]
- Feldman-Maggor, Y.; Blonder, R.; Tuvi-Arad, I. Let them choose: Optional assignments and online learning patterns as predictors of success in online general chemistry courses. Internet High. Educ. 2022, 55, 100867. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Kwekha-Rashid, A.S.; Abduljabbar, H.N.; Alhayani, B. Coronavirus disease (COVID-19) cases analysis using machine-learning applications. Appl. Nanosci. 2021, 1–13. [Google Scholar] [CrossRef]
- Bell, J. What Is Machine Learning? In Machine Learning and the City: Applications in Architecture and Urban Design; John Wiley & Sons: Hoboken, NJ, USA, 2022; pp. 207–216. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Kwon, H.; Kim, Y. BlindNet backdoor: Attack on deep neural network using blind watermark. Multimed. Tools Appl. 2022, 81, 6217–6234. [Google Scholar] [CrossRef]
- Lieu, Q.X.; Nguyen, K.T.; Dang, K.D.; Lee, S.; Kang, J.; Lee, J. An adaptive surrogate model to structural reliability analysis using deep neural network. Expert Syst. Appl. 2022, 189, 116104. [Google Scholar] [CrossRef]
- Xia, L. Research on Optical Performance Monitoring Based on Deep Learning. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2020. Available online: https://cdmd.cnki.com.cn/Article/CDMD-10614-1020736441.htm (accessed on 10 June 2022).
- Jie, H. Large-scale task processing method based on big data deep neural network and agent. Comput. Technol. Autom. 2021. Available online: https://www.cnki.com.cn/Article/CJFDTotal-JSJH202104023.htm (accessed on 10 June 2022).
- Xu, W. Design and Implementation of Long Text Classification Algorithm Based on Deep Neural Network. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2020. Available online: https://cdmd.cnki.com.cn/Article/CDMD-10293-1020427857.htm (accessed on 10 June 2022).
- Gamarnik, D.; Kızıldağ, E.C.; Perkins, W.; Xu, C. Algorithms and Barriers in the Symmetric Binary Perceptron Model. arXiv 2022, arXiv:2203.15667. [Google Scholar]
- Tanha, J.; Van Someren, M.; Afsarmanesh, H. Semi-supervised self-training for decision tree classifiers. Int. J. Mach. Learn. Cybern. 2017, 8, 355–370. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.J.; Liang, Y.; Su, J.T.; Zhu, J.M. An Analysis of the Economic Impact of US Presidential Elections Based on Principal Component and Logical Regression. Complexity 2021, 2021, 5593967. [Google Scholar] [CrossRef]
- Hussain, S.; Khan, M.Q. Student-performulator: Predicting students’ academic performance at secondary and intermediate level using machine learning. Ann. Data Sci. 2021, 1–19. [Google Scholar] [CrossRef]
- Albreiki, B.; Habuza, T.; Shuqfa, Z.; Serhani, M.A.; Zaki, N.; Harous, S. Customized Rule-Based Model to Identify At-Risk Students and Propose Rational Remedial Actions. Big Data Cogn. Comput. 2021, 5, 71. [Google Scholar] [CrossRef]
- Alam, T.M.; Mushtaq, M.; Shaukat, K.; Hameed, I.A.; Umer Sarwar, M.; Luo, S. A novel method for performance measurement of public educational institutions using machine learning models. Appl. Sci. 2021, 11, 9296. [Google Scholar] [CrossRef]
- Khakata, E.; Omwenga, V.; Msanjila, S. Student performance prediction on internet mediated environments using decision trees. Int. J. Comput. Appl. 2019, 975, 8887. [Google Scholar] [CrossRef]
- Berens, J.; Schneider, K.; Görtz, S.; Oster, S.; Burghoff, J. Early Detection of Students at Risk–Predicting Student Dropouts Using Administrative Student Data and Machine Learning Methods. Available at SSRN 3275433. 2018. Available online: https://ssrn.com/abstract=3275433 (accessed on 10 June 2022). [CrossRef]
- Baashar, Y.; Alkawsi, G.; Mustafa, A.; Alkahtani, A.A.; Alsariera, Y.A.; Ali, A.Q.; Tiong, S.K. Toward predicting student’s academic performance using artificial neural networks (ANNs). Appl. Sci. 2022, 12, 1289. [Google Scholar] [CrossRef]
- Ma, Y.; Cui, C.; Yu, J.; Guo, J.; Yang, G.; Yin, Y. Multi-task MIML learning for pre-course student performance prediction. Front. Comput. Sci. 2020, 14, 1–10. [Google Scholar] [CrossRef]
- Bao, Y.; Lu, F.; Wang, Y.; Zeng, Q.; Liu, C. Student performance prediction based on behavior process similarity. Chin. J. Electron. 2020, 29, 1110–1118. [Google Scholar] [CrossRef]
- Wu, J. Prediction of Students’ Online Grades Based on Data Mining Technology. Master’s Thesis, Chang’an University, Xi’an, China, 2021. Available online: https://cdmd.cnki.com.cn/Article/CDMD-10710-1021890378.htm (accessed on 10 June 2022).
- Yu, J.; Bai, S.; Wu, D. Research on student achievement prediction based on machine learning in online teaching. Comput. Program. Ski. Maint. 2021. Available online: https://www.cnki.com.cn/Article/CJFDTotal-DNBC202108047.htm (accessed on 10 June 2022).
- Feng, G.; Pan, T.; Wu, W. Analysis of Online Learning Behavior Based on Bayesian Network Model. J. Guangdong Univ. Technol. 2022, 39, 41–48. [Google Scholar] [CrossRef]
- Luo, W. Research on Human Physiological Signal Classification Based on Genetic Algorithm and Multilayer Perceptron. Master’s Thesis, Xiamen University, Xiamen, China, 2018. Available online: https://cdmd.cnki.com.cn/Article/CDMD-10384-1018194858 (accessed on 10 June 2022).
- Talloen, J.; Dambre, J.V.; Esompele, A. PyTorch-Hebbian: Facilitating local learning in a deep learning framework. arXiv 2021, arXiv:2102.00428. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Linear regression. In An Introduction to Statistical Learning; Springer: New York, NY, USA, 2021; pp. 59–128. [Google Scholar] [CrossRef]
- Nachouki, M.; Abou Naaj, M. Predicting Student Performance to Improve Academic Advising Using the Random Forest Algorithm. Int. J. Distance Educ. Technol. (IJDET) 2022, 20, 1–17. [Google Scholar] [CrossRef]
- Liu, D.; Li, S.; You, K. Training Load Prediction in Physical Education Teaching Based on BP Neural Network Model. Mob. Inf. Syst. 2022, 2022, 4821208. [Google Scholar] [CrossRef]
- Deng, J.; Deng, Y.; Cheong, K.H. Combining conflicting evidence based on Pearson correlation coefficient and weighted graph. Int. J. Intell. Syst. 2021, 36, 7443–7460. [Google Scholar] [CrossRef]
- Maxim, L.G.; Rodriguez, J.I.; Wang, B. Euclidean distance degree of the multiview variety. SIAM J. Appl. Algebra Geom. 2020, 4, 28–48. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, K.; Hou, Y. Classification of iris by KNN algorithm based on different distance formulas. Wirel. Internet Technol. 2021, 18, 105–106. Available online: https://www.cnki.com.cn/Article/CJFDTotal-WXHK202113051.htm (accessed on 10 June 2022).
- Sun, Y.; Li, S.; Wang, X. Bearing fault diagnosis based on EMD and improved Chebyshev distance in SDP image. Measurement 2021, 176, 109100. [Google Scholar] [CrossRef]
- Zheng, T.; Yu, Y.; Lei, H.; Li, F.; Zhang, S.; Zhu, J.; Wu, J. Compositionally Graded KNN-Based Multilayer Composite with Excellent Piezoelectric Temperature Stability. Adv. Mater. 2022, 34, 2109175. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Features | Model Predictions | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | … | 27 | 28 | 1 | 2 | 3 | |
| 1 | 56 | 82 | … | 80 | 61 | 28.00 | 29.00 | 30.00 |
| 2 | 80 | 73 | … | 81 | 60 | 66.93 | 73.42 | 52.83 |
| 3 | 67 | 84 | … | 74 | 64 | 77.96 | 72.83 | 69.05 |
| 4 | 86 | 82 | … | 70 | 72 | 64.09 | 63.56 | 64.24 |
| 5 | 89 | 96 | … | 77 | 64 | 86.95 | 72.19 | 71.22 |
| … | … | … | … | … | … | … | … | … |
| 189 | 48 | 69 | … | 71 | 50 | 66.59 | 65.13 | 65.81 |
| 190 | 62 | 89 | … | 92 | 70 | 85.84 | 75.39 | 74.43 |
| 191 | 62 | 67 | … | 61 | 61 | 74.51 | 52.94 | 62.44 |
| 192 | 77 | 76 | … | 78 | 40 | 68.56 | 71.96 | 50.28 |
| 193 | 90 | 91 | … | 85 | 71 | 93.22 | 74.32 | 92.03 |
| Number | Indicator Name | Mathematical Meaning |
|---|---|---|
| 1 | MAE | |
| 2 | MSE | |
| 3 | MAPE | |
| 4 | PUDA |
| Number | Indicator Name | LR | RF | BPNN | DNN |
|---|---|---|---|---|---|
| 1 | Train MAE | 0.1364 | 0.0601 | 0.0738 | 0.0743 |
| 2 | Train MSE | 0.0289 | 0.0059 | 0.0099 | 0.0092 |
| 3 | Train MAPE | 21.55 | 31.70 | 353.1 | 35.68 |
| 4 | Train PUDA | 58.52 | 93.56 | 76.24 | 85.57 |
| 5 | Test MAE | 0.1499 | 0.1217 | 0.2036 | 0.0865 |
| 6 | Test MSE | 0.0319 | 0.0229 | 0.0966 | 0.0115 |
| 7 | Test MAPE | 22.60 | 19.45 | 33.31 | 34.59 |
| 8 | Test PUDA | 52.38 | 50.00 | 59.09 | 80.95 |
| Number | Course Name | Metallurgical Physical Chemistry 1 | College English 4 | Linear Algebra B |
|---|---|---|---|---|
| 1 | Advanced Mathematics A1 | 0.5121 | 0.3701 | 0.4000 |
| 2 | Basic Computer Science | 0.1870 | 0.3915 | 0.1566 |
| 3 | Physical Chemistry D1 | 0.5599 | 0.3543 | 0.4446 |
| 4 | University Physics B2 | 0.5956 | 0.3521 | 0.5446 |
| 5 | Career Development and Employment Guidance for College Students 1 | 0.2625 | 0.1713 | 0.1713 |
| 6 | Outline of Modern Chinese History | 0.1841 | 0.0846 | 0.1286 |
| … | … | … | … | … |
| 23 | Freshman Seminar[Y] | 0.2135 | 0.2049 | 0.0631 |
| 24 | Advanced Mathematics A2 | 0.5256 | 0.4032 | 0.4926 |
| 25 | Introduction to Business Management | 0.3046 | 0.4612 | 0.1180 |
| 26 | Engineering Graphics B | 0.3519 | 0.3216 | 0.3370 |
| 27 | Probability Theory and Mathematical Statistics C | 0.6296 | 0.2384 | 0.5973 |
| 28 | College English 2 | 0.3426 | 0.6213 | 0.2227 |
| Distance Type | Proximity Sort Top 5 | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Euclidean distance | 31 | 207 | 11 | 163 | 127 |
| Manhattan distance | 31 | 207 | 11 | 127 | 125 |
| Chebyshev distance | 31 | 207 | 11 | 112 | 192 |
| Euclidean distance based on the Pearson coefficient | 217 | 2 | 50 | 207 | 11 |
| Manhattan distance based on the Pearson coefficient | 217 | 11 | 207 | 2 | 125 |
| Chebyshev distance based on the Pearson coefficient | 2 | 31 | 217 | 50 | 164 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, T.; Sun, C.; Wu, Z.; Yang, J.; Wang, J. Deep Neural Network-Based Prediction and Early Warning of Student Grades and Recommendations for Similar Learning Approaches. Appl. Sci. 2022, 12, 7733. https://doi.org/10.3390/app12157733
Tao T, Sun C, Wu Z, Yang J, Wang J. Deep Neural Network-Based Prediction and Early Warning of Student Grades and Recommendations for Similar Learning Approaches. Applied Sciences. 2022; 12(15):7733. https://doi.org/10.3390/app12157733
Chicago/Turabian StyleTao, Tao, Chen Sun, Zhaoyang Wu, Jian Yang, and Jing Wang. 2022. "Deep Neural Network-Based Prediction and Early Warning of Student Grades and Recommendations for Similar Learning Approaches" Applied Sciences 12, no. 15: 7733. https://doi.org/10.3390/app12157733
APA StyleTao, T., Sun, C., Wu, Z., Yang, J., & Wang, J. (2022). Deep Neural Network-Based Prediction and Early Warning of Student Grades and Recommendations for Similar Learning Approaches. Applied Sciences, 12(15), 7733. https://doi.org/10.3390/app12157733